私有化部署大模型推理性能分析
从用户感知角度分析私有化部署的大模型推理性能,这里的用户感知包括响应速度、生成速度、系统可用性以及系统稳定性。大模型首先获取输入内容的字符串,将这部分内容转换为模型token,过模型推理,到最后输出第一个token的时间是ttft,从这以后,这个token就变成了下一个token的输入进行循环推理输出下一个token,这样两个token之间的速度就是tpot,大模型本质上就是不断把上面预测的输出作为下一个token的输入,有点像贪吃蛇。
- 响应速度:用户发出请求后,系统响应的快慢。
- 生成速度:模型生成内容的流畅度和速度。
- 系统可用性:系统是否能够同时服务多个用户。
- 系统稳定性:系统是否能稳定运行,不出现卡顿或崩溃。
核心性能指标对用户感知的影响包括
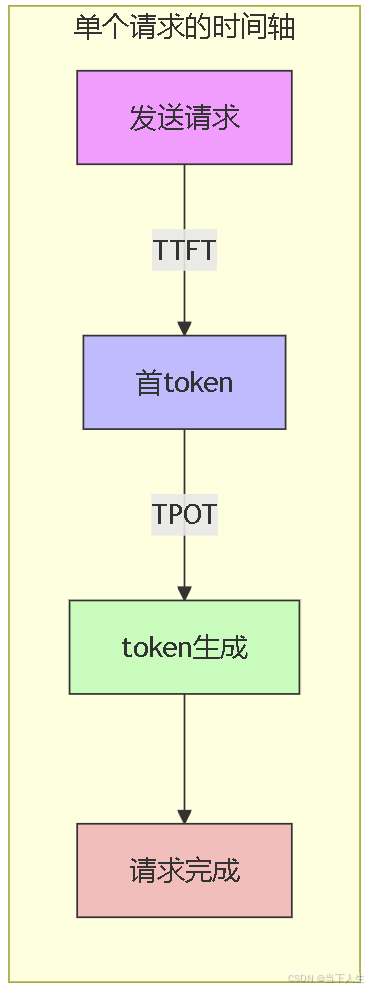
1、延迟指标
- 首token延迟(TTFT):从用户发出请求到模型生成第一个token的时间。TTFT越短,用户感受到的初始响应速度越快。
- token生成速度(TPOT):生成每个token所需的时间。TPOT越快,用户感受到的内容生成越流畅,尤其在长文本生成中表现明显。
- 端到端延迟(E2E):从请求发出到接收完整响应的总时间。E2E延迟越短,用户整体等待时间越少,响应速度越高。
2、吞吐量指标
- 预填充吞吐:模型在预填充阶段(处理输入数据)的处理能力。虽然对用户感知的影响较间接,但高预填充吞吐能加快输入处理,为后续生成奠定基础。
- prefill
- 解码吞吐:模型在生成token阶段的处理能力。解码吞吐越高,生成速度越快,用户体验更流畅。
- decode
- 总体吞吐:模型整体的处理能力,决定了系统能同时处理多少请求。总体吞吐越高,系统可用性越强,能支持更多用户。
3、资源利用
- GPU利用率:GPU资源的利用效率。高利用率能提升模型处理能力,从而间接提高响应速度和生成速度。
- 内存使用:内存使用效率影响模型能处理的数据量和请求数。高效的内存使用支持更多并发请求,提升系统可用性。
- 功耗效率:对用户感知影响较小,但影响系统运营成本和长期稳定性。
4、并发能力
- 最大批大小:系统能同时处理的请求数量。批大小越大,系统可用性越高,用户等待时间越短。
- 请求队列:管理等待处理的请求。优秀的队列管理能减少用户等待时间,提升响应速度和系统可用性。
- 负载均衡:将请求均匀分配到处理单元,避免过载。良好的负载均衡提高系统稳定性,间接提升用户体验。
性能指标与用户感知的映射关系
- 响应速度:主要受首token延迟(TTFT)和端到端延迟(E2E)**影响。
- 生成速度:主要受token生成速度(TPOT)和解码吞吐影响。
- 系统可用性:主要受总体吞吐、最大批大小和请求队列影响。
- 系统稳定性:主要受GPU利用率、内存使用和负载均衡影响。

从网上搜索了一些信息汇总,
- 使用 vLLM 和 sglang 部署模型推理服务前,应测试延迟、吞吐量、资源利用率和并发能力等性能指标。
- 建议标准包括:首token延迟(TTFT)< 200 毫秒、token生成速度(TPOT)> 50 tokens/秒、端到端延迟(E2E)< 2 秒(100 tokens响应)、吞吐量> 20 请求/秒、GPU利用率> 80%、内存使用在分配范围内。
表:典型性能指标与建议标准
| 指标 | 描述 | 建议标准 |
|---|---|---|
| 首token延迟(TTFT) | 请求到第一个token生成时间 | < 200 毫秒 |
| token生成速度(TPOT) | 每秒生成token数量 | > 50 tokens/秒 |
| 端到端延迟(E2E) | 请求到完整响应总时间(100 tokens) | < 2 秒 |
| 吞吐量 | 每秒处理请求数量 | > 20 请求/秒 |
| GPU利用率 | GPU资源利用效率 | > 80% |
| 内存使用 | 系统内存占用情况 | 在分配范围内,无交换 |
对于DeepSeek R1 671B部署推理分析:
DeepSeek R1 671B 是一个 671B 参数的 MoE 模型,每 token 只激活约 37B 参数,设计用于高效推理,支持 128K token 输入和 32K token 生成。MoE 架构通过路由机制选择专家处理输入,相比密集型 LLM(所有参数均参与计算),其计算效率更高,尤其适合大规模模型。
vLLM 和 sglang 是两种高效的推理服务框架。vLLM 强调高吞吐量和内存效率,采用 PagedAttention 等技术;sglang 则提供 RadixAttention 和数据并行优化,支持多种模型,包括 DeepSeek 系列。两者均支持 MoE 模型,如 Mixtral 和 DeepSeek R1。
性能指标分析
响应速度(TTFT)
- 定义:从用户请求到生成第一个 token 的时间,直接影响用户感知的初始响应速度。
- MoE 模型特点:MoE 模型需要额外的专家选择过程,可能增加少量 TTFT 开销。但由于只激活部分参数,实际计算时间可能与活跃参数数量相当的密集型 LLM 相似或略好。
- 与密集型 LLM 比较:相比总参数为 671B 的密集型 LLM,MoE 模型的 TTFT 应显著更好,因为密集型模型需要处理所有参数,计算开销更大。相比 37B 参数的密集型 LLM,TTFT 可能相当,取决于框架优化。
- 框架支持:vLLM 和 sglang 的优化(如连续批处理)可能减少 MoE 模型的 TTFT 开销。研究表明,vLLM 在 Llama 8B 上 TTFT 可达 200 毫秒以下,MoE 模型可能类似 。
- 建议标准:TTFT 目标为 < 200 毫秒,与小型密集型 LLM 相当,确保实时应用的用户体验。
生成速度(TPOT)
- 定义:生成后续 token 的速度,单位为 tokens/秒,影响生成文本的流畅度。
- MoE 模型特点:MoE 模型每 token 只激活约 37B 参数,相比 37B 参数的密集型 LLM,计算效率更高,可能生成速度更快。相比 671B 参数的密集型 LLM,优势更明显,因为密集型模型计算开销巨大。
- 与密集型 LLM 比较:研究显示,MoE 模型在推理时因稀疏激活可实现更高 TPOT。例如,sglang 在 DeepSeek 模型上通过数据并行优化,解码吞吐量提升 1.9 倍 (SGLang v0.4 Blog)。vLLM 在 Llama 70B 上 TPOT 可达 50 tokens/秒,MoE 模型可能更优。
- 框架支持:sglang 提供 RadixAttention 和专家并行支持,vLLM 支持 Mixtral 等 MoE 模型,均能提升 TPOT。研究表明,MoE 模型在现代加速器上步长时间更短 。
- 建议标准:TPOT 目标为 > 50 tokens/秒,确保流畅生成,优于同等活跃参数的密集型 LLM。
系统可用性
- 定义:系统能同时处理多少用户请求,涉及吞吐量和最大批大小。
- MoE 模型特点:MoE 模型因稀疏激活可更高效利用资源,允许更大批处理和更高并发。专家复用可减少内存占用,提升吞吐量。
- 与密集型 LLM 比较:相比同等硬件的密集型 LLM,MoE 模型能服务更多用户。例如,sglang 在 8x H100 80GB GPU 上通过数据并行优化 DeepSeek 模型,吞吐量显著提升 (SGLang v0.4 Blog)。vLLM 报告在 Llama 70B 上吞吐量达 20 请求/秒,MoE 模型可能更高。
- 框架支持:vLLM 和 sglang 支持连续批处理和张量并行,MoE 模型的效率进一步放大。研究显示,MoE 模型在高负载下表现更优
- 建议标准:吞吐量目标 > 20 请求/秒,最大批大小需测试以确保高并发场景下性能。
稳定性
- 定义:系统在负载下的可靠性,避免崩溃或性能下降,涉及 GPU 利用率、内存使用和负载均衡。
- MoE 模型特点:MoE 模型的动态专家选择可能增加负载管理复杂性,但因稀疏激活,资源利用率可能更高。专家并行和数据并行需妥善管理以避免瓶颈。
- 与密集型 LLM 比较:稳定性应与密集型 LLM 相当,vLLM 和 sglang 设计上注重资源管理。研究显示,MoE 模型在现代加速器上通过 3D 分片保持步长时间增加在可控范围内 。
- 框架支持:sglang 提供缓存感知负载均衡,vLLM 支持多 GPU 配置,均能确保稳定性。研究表明,MoE 模型在高负载下表现稳定 。
- 建议标准:GPU 利用率 > 80%,内存使用在分配范围内,确保系统稳定运行。
对比表:MoE vs 密集型 LLM 性能要求
| 指标 | MoE 模型 (DeepSeek R1 671B) | 密集型 LLM (同等活跃参数) |
|---|---|---|
| 响应速度 (TTFT) | 可能相似或略好,目标 < 200 毫秒 | 类似,依赖硬件和框架优化 |
| 生成速度 (TPOT) | 可能更快,目标 > 50 tokens/秒 | 类似,但计算开销可能更高 |
| 系统可用性 | 更好,可服务更多用户,吞吐量目标 > 20 请求/秒 | 受限于资源,可能吞吐量较低 |
| 稳定性 | 相当,需注意专家选择动态性,GPU 利用率 > 80% | 类似,但资源管理可能更简单 |
实际测试,私有化部署对算力要求相当之高,效果距离行业通用标准而言堪忧,还有很大的提升空间,主要体现在TTFT和E2E指标,我可以理解为推理类模型的E2E就不可能和chat类模型一样,因为传统模型没有思考时间。下图为测试架构。
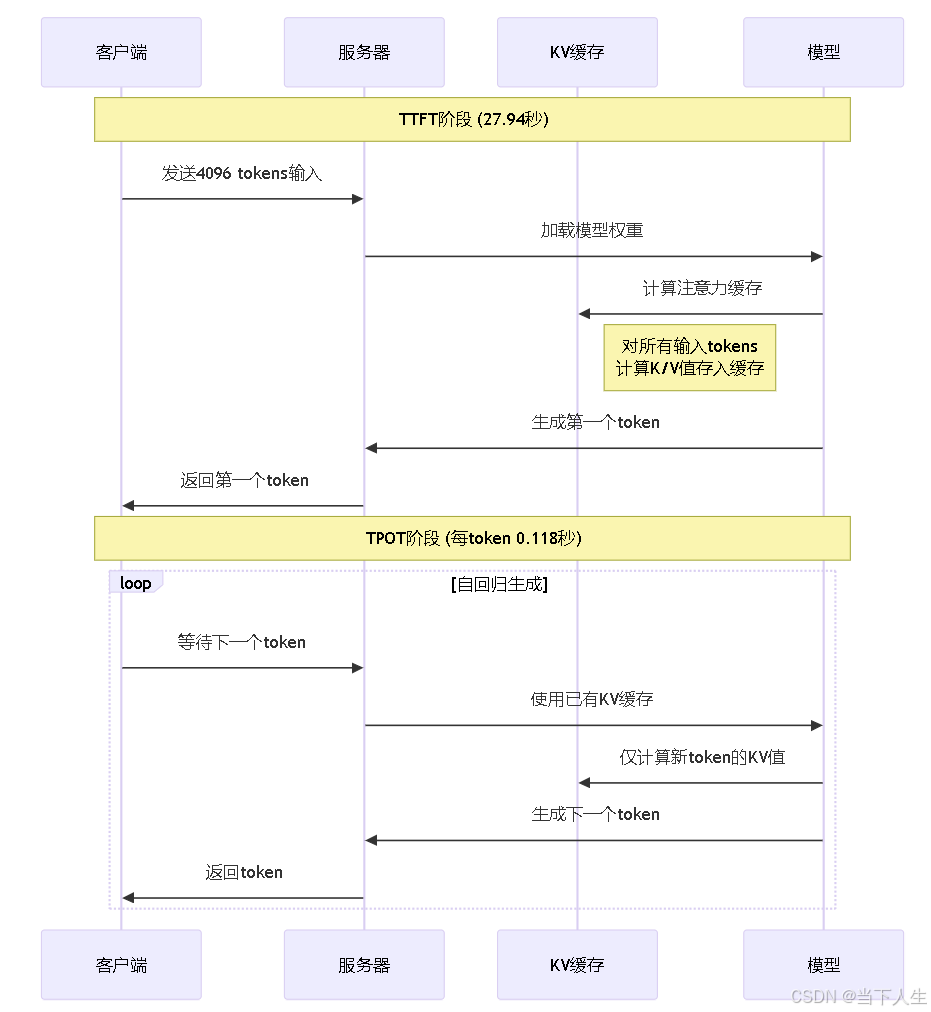
下面是测试原理图
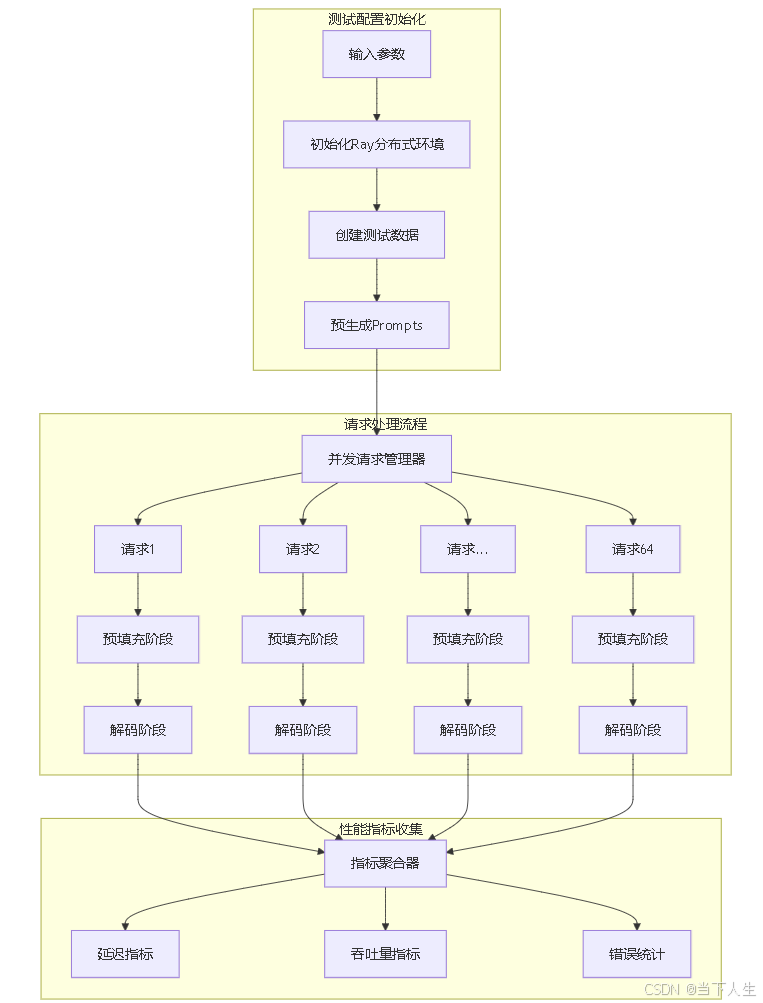
下面是不同输入长度token情况下的趋势。
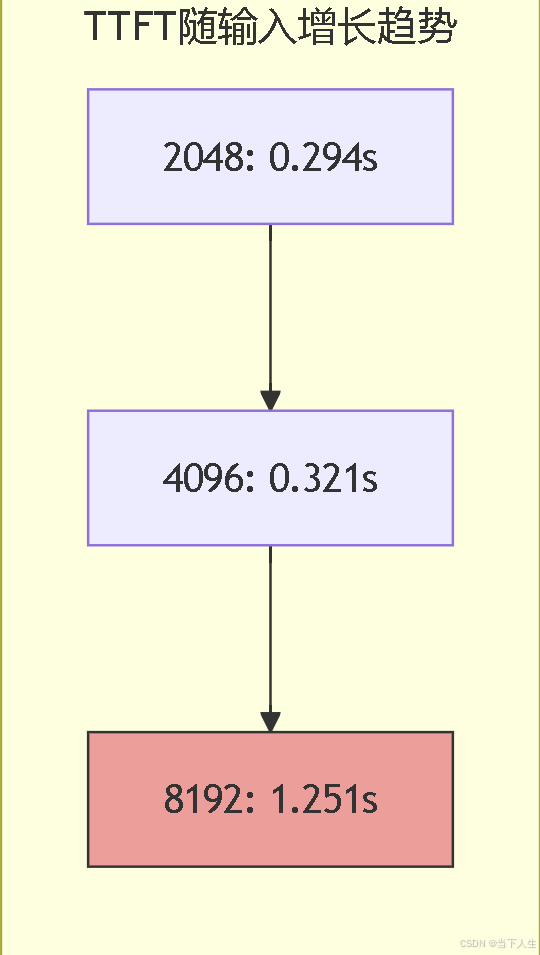



输入2048:
- 端到端延迟: 47.96s
- 请求完成率: 1.25次/分钟
- 输出吞吐: 23.17 tokens/s
输入4096:
- 端到端延迟: 49.56s
- 请求完成率: 1.21次/分钟
- 输出吞吐: 22.24 tokens/s
输入8192:
- 端到端延迟: 53.59s
- 请求完成率: 1.12次/分钟
- 输出吞吐: 20.69 tokens/s
结论:
- 输入从4096到8192时性能下降明显
- TTFT在8192时急剧增加(约4倍)
- 预填充吞吐在4096时达到峰值
- TPOT基本保持线性增长
- 端到端延迟随输入增加而非线性增长
- 解码吞吐略有下降但相对稳定
优化方向:
A. 输入长度选择
- 一般场景建议控制在4096以内
- 超长输入考虑分段处理
B. 性能优化方向
- 针对8192+场景优化预填充性能
- 改进长序列的注意力计算
- 提升KV Cache利用效率
C. 应用部署建议
- 根据实际输入长度特点选择配置
- 考虑输入长度动态分配资源
- 监控TTFT作为关键指标
vllm 和 sglang的对比:
- vLLM的优势:
- 解码吞吐量略高(+6.5%)
- 单token生成时间更短(-7%)
- 端到端延迟更低(-4.1%)
- 整体吞吐量更好(+4%)
- SGLang的优势:
- TTFT显著更低(-55.7%)
- 预填充吞吐量更高(+125%)
- 性能波动更小 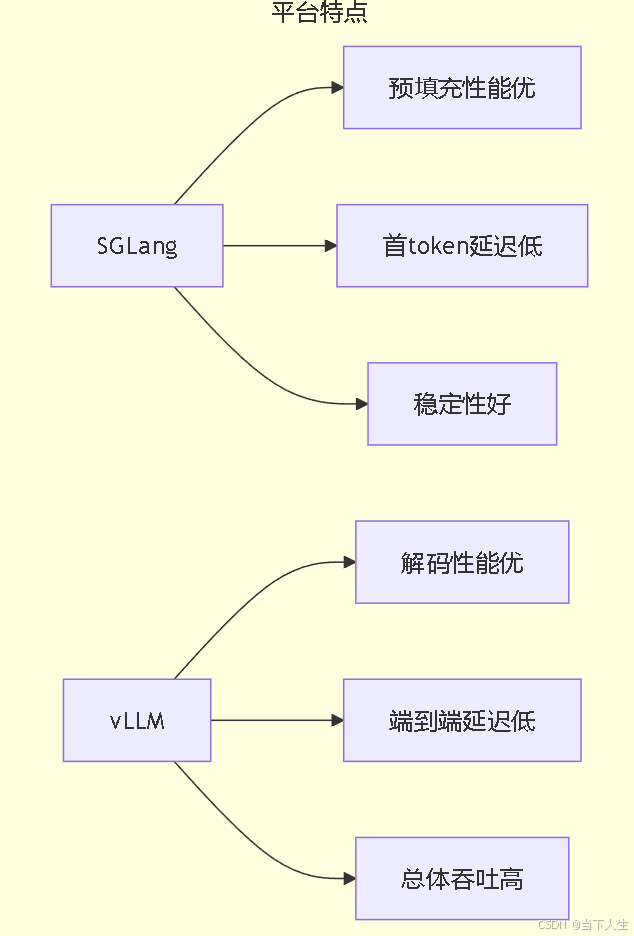
建议和结论:
- 场景选择:
SGLang适合:
- 对首次响应速度敏感的场景
- 需要稳定性能的场景
- 批处理场景vLLM适合:
- 持续对话场景
- 追求高吞吐的场景
- 长文本生成场景
- 性能优化方向:
SGLang:
- 提升解码阶段性能
- 优化端到端延迟vLLM:
- 改进TTFT
- 提升预填充效率
- 减少性能波动总体可以得出结论,输入输出序列越短,ttft和e2e指标越好,并发性能和吞吐量越高

相关文章:
私有化部署大模型推理性能分析
从用户感知角度分析私有化部署的大模型推理性能,这里的用户感知包括响应速度、生成速度、系统可用性以及系统稳定性。大模型首先获取输入内容的字符串,将这部分内容转换为模型token,过模型推理,到最后输出第一个token的时间是ttft,从这以后&a…...

版图自动化连接算法开发 00001 ------ 直接连接两个给定的坐标点
版图自动化连接算法开发 00001 ------ 直接连接两个给定的坐标点 引言正文定义坐标点的类绘图显示代码直接连接两个坐标点引言 由于人工智能的加速普及,每次手动绘制版图都会觉得特别繁琐,作者本人在想可否搞一个自动化连接器件端口的算法,后期可以根据一些设定的限制进行避…...

UniApp 按钮组件 open-type 属性详解:功能、场景与平台差异
文章目录 引言一、open-type 基础概念1.1 核心作用1.2 通用使用模板 二、主流 open-type 值详解2.1 contact - 客服会话功能说明平台支持代码示例 2.2 share - 内容转发功能说明平台支持注意事项 2.3 getUserInfo - 获取用户信息功能说明平台支持代码示例 2.4 getPhoneNumber -…...
EtherCAT总线绝对值伺服如何使用
EtherCAT总线掉线如何自动重启。 EtherCAT总线掉线如何自动重启_ethercat从站断线-CSDN博客文章浏览阅读1.2k次。本文介绍了在EtherCAT通信中,当从站出现掉线情况时,如何通过设置自动重启功能来解决这一问题。详细步骤包括在CODESYS环境中启用从站的自动重启选项。https://r…...

可商用街头文化艺术海报封面手写涂鸦标题LOGO排版英文字体 FS163 TYPE FACE
Freestyle 163 (FS163)是一个受街头文化和城市艺术启发的视觉宣言。该字体旨在突出我们的文化和创意根源,反映了街头运动、城市艺术以及来自社会和边缘的故事。 FS163与面临挑战、质疑规范、放大被忽视声音的品牌和个人联系在一起,…...

使用3090显卡部署Wan2.1生成视频
layout: post title: 使用3090显卡部署Wan2.1生成视频 catalog: true tag: [Kubernetes, GPU, AI] 使用3090显卡部署Wan2.1生成视频 1. 环境说明2. 模型下载3. 克隆仓库4. 安装依赖5. 生成视频 5.1. 使用generate脚本生成5.2. 使用gradio启动UI界面生成 5.2.1. 启动gradio服务5…...

js逆向常用代码
js逆向常用代码 加载 const loadingStyle #loadingDiv {position: fixed;z-index: 9999;top: 0;left: 0;width: 100%;height: 100%;background-color: rgba(255, 255, 255, 0.8);display: flex;align-items: center;justify-content: center;flex-direction: column;}.loade…...
Diffusion——扩散模型(未完待续)
论文链接:https://arxiv.org/abs/2006.11239 简介 扩散模型(Diffusion Model)是用于生成数据的一类深度生成模型,特别擅长于图像生成。其工作原理基于通过随机噪声的逐步转换来生成目标数据。扩散模型分为两部分:正向…...

Java内存管理与性能优化实践
Java内存管理与性能优化实践 Java作为一种广泛使用的编程语言,其内存管理和性能优化是开发者在日常工作中需要深入了解的重要内容。Java的内存管理机制借助于垃圾回收(GC)来自动处理内存的分配和释放,但要实现高效的内存管理和优…...

unsloth报错FileNotFoundError: [WinError 3] 系统找不到指定的路径。
运行平台 Windows 报错信息 Traceback (most recent call last): File “C:\Python312\Lib\site-packages\IPython\core\interactiveshell.py”, line 3577, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File “”, line 1, in runfile(‘D:\python_pr…...

不同规模企业如何精准选择AI工具: DeepSeek、Grok 和 ChatGPT 三款主流 AI 工具深度剖析与对比
本文深入探讨了最近国内外主流的 DeepSeek、Grok 和 ChatGPT 三款主流 AI 工具的技术细节、性能表现、应用场景及局限性,并从技术能力、功能需求、成本预算、数据安全和合规以及服务与支持五个关键维度,详细分析了不同规模企业在选择 AI 工具时的考量因素…...

各章节详细总结与 Vue 学习收尾
各章节详细总结与 Vue学习收尾 第一章:基础入门 通俗理解:这就像你刚踏入一个新的游戏世界,得先搞清楚游戏的基本规则和操作方法。在 Vue 3 的学习里,就是要搭建好开发环境,认识 Vue 3 的基本概念,比如模…...

c++ 文件及基本读写总结
在 C 中,文件操作是非常重要的一部分,主要用于将数据存储到文件中,或者从文件中读取数据。C 标准库提供了fstream头文件,其中包含了用于文件操作的类,主要有ifstream(用于输入文件流,即从文件读…...

如何调试Linux内核?
通过创建一个最小的根文件系统,并使用QEMU和GDB进行调试。 1.准备工作环境 确保系统上安装了所有必要的工具和依赖项。 sudo apt-get update //更新一下软件包 sudo apt-get install build-essential git libncurses-dev bison flex libssl-dev qemu-system-x…...

Docker入门指南:Windows下docker配置镜像源加速下载
Windows下docker配置镜像源加速下载 docker的官方镜像是海外仓库,默认下载耗时较长,而且经常出现断站的现象,因此需要配置国内镜像源。 国内镜像源概述 国内现有如下镜像源可以使用 "http://hub-mirror.c.163.com", "http…...

java后端开发day24--阶段项目(一)
(以下内容全部来自上述课程) GUI:Graphical User Interface 图形用户接口,采取图形化的方式显示操作界面 分为两套体系:AWT包(有兼容问题)和Swing包(常用) 拼图小游戏…...

TVbox蜂蜜影视:智能电视观影新选择,简洁界面与强大功能兼具
蜂蜜影视是一款基于猫影视开源项目 CatVodTVJarLoader 开发的智能电视软件,专为追求简洁与高效观影体验的用户设计。该软件从零开始编写,界面清爽,操作流畅,特别适合在智能电视上使用。其最大的亮点在于能够自动跳过失效的播放地址…...

2025.3.2机器学习笔记:PINN文献阅读
2025.3.2周报 一、文献阅读题目信息摘要Abstract创新点网络架构实验结论不足以及展望 一、文献阅读 题目信息 题目: Physics-Informed Neural Networks of the Saint-Venant Equations for Downscaling a Large-Scale River Model期刊: Water Resource…...

2025AI 有哪些重要的发展趋势?
2025 年,AI 有哪些重要的发展趋势? 看看大佬们的看法: 马斯克:“人形机器人生产、自动驾驶突破、脑机接口进化” 奥特曼:“2025年,AGI即将到来” 黄仁勋:“通用机器人元年、能源效率的提升”…...

uni-app 全局请求封装:支持 Promise,自动刷新 Token,解决 401 过期问题
在 uni-app 中封装一个全局通用的 ajax 请求函数,支持 Promise,使用 uni.request() 进行请求,并且具备 自动刷新 token 的功能。以下是详细步骤: 实现步骤 创建 request.js 统一封装 ajax 请求管理 token(存储、获取、…...

IDEAPyCharm安装ProxyAI(CodeGPT)插件连接DeepSeek-R1教程
背景:最近DeepSeek比较火嘛,然后在githup上也看到了GitHub Copilot,就想着现在AI的准确率已经可以提高工作效率了。所以从网上找了一些编程插件,发现Proxy支持的模型比较多,通用性和适配性比较好。所以本文记录一下pro…...

【实战 ES】实战 Elasticsearch:快速上手与深度实践-2.1.2字段类型选择:keyword vs text、nested对象
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 第2章 数据建模与高效写入:ES字段类型选择最佳实践:keyword vs text与nested对象深度解析1. 索引设计核心原则2. keyword与text类型终极对决2.1 核心…...

【前端基础】Day 3 CSS-2
目录 1. Emmet语法 1.1 快速生成HTML结构语法 1.2 快速生成CSS样式语法 2. CSS的复合选择器 2.1 后代选择器 2.2 子选择器 2.3 并集选择器 2.4 伪类选择器 2.4.1 链接伪类选择器 2.4.2 focus伪类选择器 2.5 复合选择器总结 3. CSS的元素显示模式 3.1 什么是元素显示…...

windows电脑上安装llama-factory实现大模型微调
一、安装环境准备 这是官方给的llama-factory安装教程,安装 - LLaMA Factory,上面介绍了linux系统上以及windows系统上如何正确安装。大家依照安装步骤基本能够完成安装,但是可能由于缺少经验或者相关的知识导致启动webUi界面运行相应内容时…...

汽车无人驾驶系统中的防撞设计
一、系统方案介绍 无人驾驶汽车的防撞系统是保障行车安全的核心模块,本文设计的系统以STM32F103C8T6单片机为主控制器,结合超声波测距、WiFi通信、人机交互等模块,实现障碍物实时检测、动态阈值设置、多级报警和数据可视化功能。系统通过软…...

sql server 版本更新日期
SQL Server 2019 内部版本(KB4518398) - SQL Server | Microsoft Learn SQL Server 的最新更新和版本历史记录 - SQL Server | Microsoft Learn sql server 2019 版本更新时间和补丁版本号...

Linux网络 DNS
DNS(Domain Name System) TCP/IP 中使用 IP 地址和端口号来确定网络上的一台主机的一个程序 , 但是 IP 地址不方便记忆。于是人们发明了一种叫主机名的东西, 是一个字符串 , 并且使用 hosts 文件来描述主机名和 IP 地址的关系 。 最初 , 通过互连网信息中…...

EMQX中不同端口对应的接入协议
使用tcp接入时应使用mqtt://IP:1883 使用ws接入时应使用ws://IP:8083...

SpringBoot原理-03.自动配置-方案
一.自动配置原理 探究自动配置原理,就是探究spring是如何在运行时将要依赖JAR包提供的配置类和bean对象注入到IOC容器当中。我们当前准备一个maven项目itheima-utils,这里面定义了bean对象以及配置类,用来模拟第三方提供的依赖,首…...

Python 如何实现烟花效果的完整代码
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...