基于提示驱动的潜在领域泛化的医学图像分类方法(Python实现代码和数据分析)
摘要
医学图像分析中的深度学习模型易受数据集伪影偏差、相机差异、成像设备差异等导致的分布偏移影响,导致在真实临床环境中诊断不可靠。领域泛化(Domain Generalization, DG)方法旨在通过多领域训练提升模型在未知领域的性能,但其依赖精确的领域标签,而医学数据通常缺乏此类标签。为此,我们提出一种无需领域标签的领域泛化框架——提示驱动的潜在领域泛化(Prompt-driven Latent Domain Generalization, PLDG)。该框架包含无监督领域发现与提示学习:首先通过聚类与偏差相关的风格特征生成伪领域标签,随后利用协作式领域提示引导视觉变换器(ViT)从多样化的潜在领域学习知识。通过领域提示生成器实现跨领域知识共享,并采用领域混合策略缓解伪标签噪声问题。在皮肤癌分类、糖尿病视网膜病变分类和组织病理学癌症检测等任务上的实验表明,PLDG无需领域标签即可达到或超越传统DG方法的性能。
关键词:领域泛化,提示学习,皮肤病学,皮肤癌,糖尿病视网膜病变
I. 引言
深度学习在医学图像分析中取得了显著进展,但其性能易受分布偏移的影响。例如,皮肤镜图像分类模型可能过度依赖标尺、凝胶气泡等伪影而非实际病灶特征;糖尿病视网膜病变(Diabetic Retinopathy, DR)分类模型可能过拟合特定相机的成像风格。此类偏差导致模型在真实临床场景中的泛化能力受限。传统领域泛化方法旨在通过多领域训练提升模型对未知领域的适应性,但其依赖预定义的领域标签。然而,医学数据中领域标签常面临以下挑战:
-
获取成本高:领域标签需人工标注,耗时费力;
-
定义模糊:医学图像的领域划分(如伪影类型、医院来源)缺乏统一标准,不同专家可能存在分歧;
-
任务依赖性:领域划分与下游任务强相关,难以跨任务迁移。
现有方法存在两大局限性:
-
数据集层面:依赖领域标签的假设不切实际;
-
算法层面:领域不变特征学习可能忽略对未知领域有用的信号,而集成学习方法未充分利用跨领域信息。
为此,我们提出潜在领域泛化(Latent Domain Generalization, LDG),通过无监督方式自动发现潜在领域并实现模型泛化。本文的核心贡献如下:
-
无需领域标签的框架:提出PLDG,通过聚类ViT浅层风格特征生成伪领域标签,结合提示学习实现跨领域知识迁移;
-
领域提示生成器:通过低秩分解促进领域提示间的知识共享;
-
领域混合策略:缓解伪标签噪声问题,增强决策边界灵活性;
-
广泛验证:在皮肤病变、DR分类、癌症检测及去偏任务中验证有效性,性能超越传统DG方法。
II. 相关工作
A. 领域泛化
传统方法包括:
-
领域对抗训练:如DANN通过对抗损失对齐特征分布;
-
统计对齐:如CORAL匹配二阶统计量;
-
元学习:通过模拟领域偏移优化模型鲁棒性。
近期研究表明,ViT因其对纹理偏差的弱敏感性,在DG任务中表现优于CNN。然而,现有方法仍依赖领域标签,且医学图像领域泛化研究较少。
B. 医学图像中的领域泛化
现有工作多依赖人工标注的伪影标签或数据集差异作为领域标签,但存在噪声和定义不准确问题。例如,Bissoto等人通过二元分类器标注皮肤数据集的伪影标签,但标注结果可能存在误差;Mohammad等人将不同DR数据集直接视为不同领域,忽略了数据集内部相机多样性。本文首次提出基于ViT风格特征的无监督领域发现方法,摆脱对预定义标签的依赖。
C. 提示学习
提示学习通过添加可学习向量适配预训练模型至下游任务。例如,VPT在ViT中插入可学习提示以微调模型;Doprompt为不同领域设计独立提示以捕获领域特定知识。与现有方法不同,PLDG引入领域提示生成器,通过共享提示与低秩分解实现跨领域协作学习。
III. 方法
A. 问题定义

B. 整体框架
PLDG框架如图1所示,包含以下步骤:
-
无监督领域发现:基于ViT浅层CLS令牌的风格特征聚类生成伪领域标签;
-
领域提示学习:通过领域提示生成器与混合策略优化模型,提升跨领域泛化能力。
C. 基于简约性偏差的伪领域标签聚类
深度学习模型存在简约性偏差(Simplicity Bias),即倾向于学习简单特征(如背景伪影)而非复杂语义特征。本文利用该特性,从ViT浅层(如第1层)提取CLS令牌风格特征,通过k-means聚类生成伪领域标签。风格特征对齐损失定义为:

D. 基于ViT的领域提示学习


2. 损失函数

IV. 实验结果
A. 实验设置

B. 对比实验
1. 皮肤癌分类(表I)
PLDG在Derm7pt_derm和PAD数据集上分别提升3.46%和14.18%,平均ROC-AUC达84.32%,优于DANN、CORAL等传统方法。
2. DR分类(表II)
PLDG平均准确率达75.6%,显著高于依赖领域标签的方法(如ERM++:72.1%),表明其在领域标签噪声场景下的优势。
3. 癌症检测(表III)
PLDG在Camelyon17-WILDS上准确率为89.7%,仅次于使用领域标签的EPVT(90.2%),验证其实际应用价值。
C. 消融实验(表IV、V)
逐步添加提示(P)、适配器(A)、混合(M)、生成器(G)组件,结果显示:
-
+P:平均ROC-AUC提升3.39%;
-
+P+A+M:进一步提升0.87%;
-
+P+A+M+G:最终提升1.26%,验证各模块的有效性。
D. 超参数分析(图4)
-
提示长度:4时性能最优;
-
聚类数:4时平均ROC-AUC最高,且对聚类数不敏感(2~5均表现良好)。
E. 领域提示权重分析(图5)
领域距离(Fr'echet距离)与提示权重呈负相关,表明模型能自适应关注与目标领域相似的源领域。
F. 聚类分析(图6、7)
-
ViT浅层(L1)CLS令牌聚类结果与类别标签无关(NMI=0.12),主要反映风格特征;
-
t-SNE可视化显示伪领域对应“墨水标记”、“暗角”、“深肤色”等医学相关偏差。
G. 去偏评估(图8)
在陷阱数据集中,PLDG在最高偏差等级(Bias=1)时ROC-AUC为68.5%,显著优于ERM(62.37%),表明其对分布偏移的鲁棒性。
V. 结论
本文提出PLDG框架,首次在医学图像分类中实现无需领域标签的潜在领域泛化。实验表明:
-
领域标签非必要:通过伪标签发现,PLDG性能媲美甚至超越传统DG方法;
-
跨领域知识共享:领域提示生成器有效促进知识迁移;
-
鲁棒性:领域混合策略缓解伪标签噪声,提升模型泛化能力。未来工作将扩展至多模态医学数据与实时部署场景。(代码QQandweichat)
 |  |
参考文献
图1 传统领域泛化与潜在领域泛化对比

图2 PLDG算法流程
图3 领域提示生成器与混合策略示意图

图4 提示长度与聚类数对性能的影响

图5 领域提示权重与领域距离的关系
图6 伪领域标签与类别/领域标签的标准化互信息(NMI)

图7 伪领域标签的t-SNE可视化

图8 陷阱数据集去偏性能对比

相关文章:
基于提示驱动的潜在领域泛化的医学图像分类方法(Python实现代码和数据分析)
摘要 医学图像分析中的深度学习模型易受数据集伪影偏差、相机差异、成像设备差异等导致的分布偏移影响,导致在真实临床环境中诊断不可靠。领域泛化(Domain Generalization, DG)方法旨在通过多领域训练提升模型在未知领域的性能,但…...

深度学习-大白话解释循环神经网络RNN
目录 一、RNN的思想 二、RNN的基本结构 网络架构 关键点 三、RNN的前向传播 四、RNN的挑战:梯度爆炸和梯度消失 问题分析 示例推导 五、LSTM:RNN的改进 核心组件 网络架构 3. LSTM 的工作流程 4. 数学公式总结 5. LSTM 的优缺点 优点 缺点 6. LSTM 的…...
Spring统一格式返回
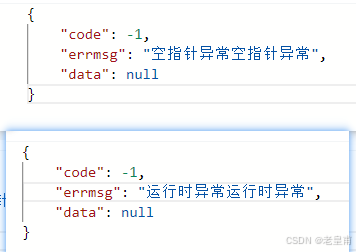
目录 一:统一结果返回 1:统一结果返回写法 2:String类型报错问题 解决方法 二:统一异常返回 统一异常返回写法 三:总结 同志们,今天咱来讲一讲统一格式返回啊,也是好久没有讲过统一格式返…...

IPOIB 驱动中的发送完成处理机制
1. ipoib_napi_add_rss 函数 ipoib_napi_add_rss 函数的主要作用是为 InfiniBand 设备的每个接收队列和发送队列添加 NAPI 结构,并注册相应的轮询函数。NAPI(New API)是一种网络接口卡(NIC)的轮询机制,用于高效处理网络数据包,避免频繁的中断处理开销。 static void i…...

BambuStudio学习笔记:format格式化输出
# Slic3r::format 字符串格式化工具说明## 概述本头文件提供了基于 boost::format 的 C 字符串格式化工具封装,旨在简化多参数格式化操作,支持类似 C20 std::format 的调用语法。## 核心设计目标- **简化调用语法**:替代 boost::format 的链式…...
软件测试基础:功能测试知识总结
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 一、测试项目启动与研读需求文档 (一) 组建测试团队 1、测试团队中的角色 2、测试团队的基本责任 尽早地发现软件程序、系统或产品中…...

wheel_legged_genesis 开源项目复现与问题记录
Reinforcement learning of wheel-legged robots based on Genesis System Requirements Ubuntu 20.04/22.04/24.04 python > 3.10 开始配置环境! 点击releases后进入,下载对应最新版本的代码: 将下载后的代码包解压到你的自定义路径下&…...

【金融量化】Ptrade中如何量化策略的交易持久化?
交易持久化是指在实际交易中交易相关的数据(如订单信息、持仓状态、策略参数等)保存到本地或远程存储中,以便在程序重启、系统崩溃或网络中断后能够恢复交易状态,确保策略的连续性和稳定性。以下是如何在策略中实现交易持久化的方…...

qt实践教学(编写一个代码生成工具)持续更新至完成———
前言: 我的想法是搭建一个和STM32cubemux类似的图形化代码生成工具,可以把我平时用到的代码整合一下全部放入这个软件中,做一个我自己专门的代码生成工具,我初步的想法是在下拉选框中拉取需要配置的功能,然后就弹出对…...

设置 CursorRules 规则
为什么要设置CursorRules? 设置 CursorRules 可以帮助优化代码生成和开发流程,提升工作效率。具体的好处包括: 1、自动化代码生成 :通过定义规则,Cursor 可以根据你的开发需求自动生成符合规定的代码模板,…...

AI 芯片全解析:定义、市场趋势与主流芯片对比
1. 引言:什么是 AI 芯片? 随着人工智能(AI)的快速发展,AI 计算的需求不断增长,从云计算到边缘计算,AI 芯片成为推动智能化时代的核心动力。那么,什么样的芯片才算 AI 芯片ÿ…...

Axure高保真Element框架元件库
点击下载《Axure高保真Element框架元件库》 原型效果:https://axhub.im/ax9/9da2109b9c68749a/#g1 摘要 本文详细阐述了在 Axure 环境下打造的一套高度还原 Element 框架的组件元件集。通过对 Element 框架组件的深入剖析,结合 Axure 的强大功能&#…...

21.<基于Spring图书管理系统②(图书列表+删除图书+更改图书)(非强制登录版本完结)>
PS: 开闭原则 定义和背景 开闭原则(Open-Closed Principle, OCP),也称为开放封闭原则,是面向对象设计中的一个基本原则。该原则强调软件中的模块、类或函数应该对扩展开放,对修改封闭。这意味着一个软件实体…...

【2025年后端开发终极指南:云原生、AI融合与性能优化实战】
一、2025年后端开发的五大核心趋势 1. 云原生架构的全面普及 云原生(Cloud Native)已经成为企业级应用的核心底座。通过容器化技术(DockerKubernetes)和微服务架构,开发者能够实现应用的快速部署、弹性伸缩和故障自愈…...
)
Docker新手入门(持续更新中)
一、定义 快速构建、运行、管理应用的工具。 Docker可以帮助我们下载应用镜像,创建并运行镜像的容器,从而快速部署应用。 所谓镜像,就是将应用所需的函数库、依赖、配置等应用一起打包得到的。 所谓容器,为每个镜像的应用进程创建…...

微信小程序读取写入NFC文本,以及NFC直接启动小程序指定页面
一、微信小程序读取NFC文本(yyy优译小程序实现),网上有很多通过wx.getNFCAdapter方法来监听读取NFC卡信息,但怎么处理读取的message文本比较难找,现用下面方法来实现,同时还解决几个问题,1、在回调方法中this.setData不更新信息,因为this的指向问题,2、在退出页面时,…...

【Spring Boot 应用开发】-05 命令行参数
Spring Boot 常用命令行参数 Spring Boot 支持多种命令行参数,这些参数可以在启动应用时通过命令行直接传递。以下是一些常用的命令行参数及其详细说明: 1. 基本配置参数 --server.port端口号 指定应用程序运行的HTTP端口,默认为8080。 jav…...
DeepSeek提示词)
选择研究方向(28条)DeepSeek提示词
选择研究方向(28条) 在学术研究的旅程中,确定研究方向和主题是至关重要的第一步。一个明确且具有创新性的研究主题不仅能够为研究提供清晰的方向,还能激发研究者的热情和动力。以下是一些优化后的提示词,目的在于帮助…...

Linux中读写锁详细介绍
读写锁介绍 Linux 中的读写锁(Read-Write Lock)是一种用于线程同步的机制,它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种机制在读操作远多于写操作的场景下,可以显著提高并发性能。读写锁主要有…...

flink分布式事务 - 两阶段提交
分布式事务与两阶段提交协议详解 分布式事务是分布式系统中保证数据一致性和可靠性的核心技术之一。在大数据处理、微服务架构以及实时流处理等领域,分布式事务的应用场景越来越广泛。两阶段提交协议(Two-Phase Commit, 2PC)作为一种经典的分布式事务管理协议,在保证强一致…...

《DataWorks:为人工智能算法筑牢高质量数据根基》
在当今数字化时代,人工智能(AI)技术的迅猛发展深刻地改变着各个行业的面貌。从智能推荐系统到医疗影像诊断,从自动驾驶到自然语言处理,AI正以前所未有的速度渗透到我们生活和工作的方方面面。而在这一系列AI应用的背后…...

机器学习(五)
一,多类(Multiclass) 多类是指输出不止有两个输出标签,想要对多个种类进行分类。 Softmax回归算法: Softmax回归算法是Logistic回归在多类问题上的推广,和线性回归一样,将输入的特征与权重进行…...

DeepSeek搭配Excel,制作自定义按钮,实现办公自动化!
今天跟大家分享下我们如何将DeepSeek生成的VBA代码,做成按钮,将其永久保存在我们的Excel表格中,下次遇到类似的问题,直接在Excel中点击按钮,就能10秒搞定,操作也非常的简单. 一、代码准备 代码可以直接询问…...

利用Git和wget批量下载网页数据
一、Git的下载(参考文章) 二. wget下载(网上很多链接) 三、git和wget结合使用 1.先建立一个文本,将代码写入文本(代码如下),将txt后缀改为sh(download_ssebop.sh…...

人工智能之数学基础:线性代数中的行列式的介绍
本文重点 行列式是一种重要的数学工具,更是连接众多数学概念和实际应用的桥梁。本文将介绍矩阵的行列式,你可以把它看成对方阵的一种运算,将方阵映射成一个标量。 行列式的定义 行列式是一个由数值组成的方阵所确定的一个标量值。对于一个n*n的矩阵A=(aij),其行列式记为d…...

[自然语言处理]pytorch概述--什么是张量(Tensor)和基本操作
pytorch概述 PyTorch 是⼀个开源的深度学习框架,由 Facebook 的⼈⼯智能研究团队开发和维护,于2017年在GitHub上开源,在学术界和⼯业界都得到了⼴泛应⽤ pytorch能做什么 GPU加速自动求导常用网络层 pytorch基础 量的概念 标量…...

[杂学笔记]HTTP1.0和HTTP1.1区别、socket系列接口与TCP协议、传输长数据的时候考虑网络问题、慢查询如何优化、C++的垃圾回收机制
目录 1.HTTP1.0和HTTP1.1区别 2.socket系列接口与TCP协议 3.传输长数据的时候考虑网络问题 4.慢查询如何优化 5.C的垃圾回收机制 1.HTTP1.0和HTTP1.1区别 在连接方式上,HTTP1.0默认采用的是短链接的方式,就建立一次通信,也就是说即使在…...

电商主图3秒法则
1. 基础铁律 ▸ 首图点击率曝光量/点击量 ▸ 黄金3秒:触发冲动 > 信息堆砌 2. 必守三原则 ✔ 单点爆破 → 1核心功能 > 10卖点叠加(反例:电子类目点击率↓18%) ✔ 场景植入 → 带场景主图点击率↑34%(数据源:20…...

DeepSeek DeepEP学习(一)low latency dispatch
背景 为了优化延迟,low lantency使用卡间直接收发cast成fp8的数据的方式,而不是使用normal算子的第一步执行机间同号卡网络发送,再通过nvlink进行转发的两阶段方式。进一步地,normal算子的dispatch包含了notify_dispatch传输meta…...

Metal学习笔记十:光照基础
光和阴影是使场景流行的重要要求。通过一些着色器艺术,您可以突出重要的对象、描述天气和一天中的时间并设置场景的气氛。即使您的场景由卡通对象组成,如果您没有正确地照亮它们,场景也会变得平淡无奇。 最简单的光照方法之一是 Phong 反射模…...