SparkStreaming之04:调优
SparkStreaming调优
一 、要点
4.1 SparkStreaming运行原理

深入理解

4.2 调优策略
4.2.1 调整BlockReceiver的数量

案例演示:
object MultiReceiverNetworkWordCount {def main(args: Array[String]) {val sparkConf = new SparkConf().setAppName("NetworkWordCount")val sc = new SparkContext(sparkConf)// Create the context with a 1 second batch sizeval ssc = new StreamingContext(sc, Seconds(5))//创建多个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER)val lines = lines1.union(lines2)lines.repartition(100)//处理的逻辑,就是简单的进行word countval words = lines.repartition(100).flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))//将结果输出到控制台wordCounts.print()//启动Streaming处理流ssc.start()//等待Streaming程序终止ssc.awaitTermination()ssc.stop(false)}
}
⭐️4.2.2 调整Block的数量
batchInterval : 触发批处理的时间间隔
blockInterval :将接收到的数据生成Block的时间间隔,spark.streaming.blockInterval(默认是200ms),那么,BlockRDD的分区数 = batchInterval / blockInterval,即一个Block就是RDD的一个分区,就是一个task
比如,batchInterval是2秒,而blockInterval是200ms,那么task数为10,如果task的数量太少,比一个executor的core数还少的话,那么可以减少blockInterval,blockInterval最好不要小于50ms,太小的话导致task数太多,那么launch task的时间久多了
4.2.3 调整Receiver的接受速率
pps:permits per second 每秒允许接受的数据量(QPS -> queries per second)
Spark Streaming默认的PPS是没有限制的,可以通过参数spark.streaming.receiver.maxRate来控制,默认是Long.Maxvalue
⭐️4.2.3 调整数据处理的并行度
BlockRDD的分区数
a. 通过Receiver接受数据的特点决定
b. 也可以自己通过repartition设置
ShuffleRDD的分区数
a. 默认的分区数为spark.default.parallelism(core的大小)
b. 通过我们自己设置决定
val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))
4.2.4 数据的序列化
SparkStreaming两种需要序列化的数据:
a. 输入的数据:默认是以StorageLevel.MEMORY_AND_DISK_SER_2的形式存储在executor上的内存中
b. 缓存的数据:默认是以StorageLevel.MEMORY_ONLY_SER的形式存储的内存中
使用Kryo序列化机制,比Java序列化机制性能好
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
4.2.5 内存调优
(1)需要内存大小
和transformation的类型有关,如果使用的是updateStateByKey,Window这样的算子,那么内存就要设置得偏大
(2)数据存储级别
如果把接收到的数据设置的存储级别是MEMORY_DISK这种级别,也就是说如果内存不够可以把数据存储到磁盘上,其实性能还是不好的,性能最好的就是所有的数据都在内存里面,所以如果在资源允许的情况下,把内存调大一点,让所有的数据都存在内存里面。
4.2.6 Outout性能
(1)MySQL,HBase



(2)Kafka(0.8版本)
虽然现在的Kafka的版本已经到2.x版本了,但是很多公司因为历史遗留的原因,公司里面还是会有0.8x的Kafka。比如本人公司里面有两个Kafka集群,一个是0.8x的kafka,一个是1.x的Kafka。开发的时候有时候需要我们使用SparkStreaming做实时的ETL,然后再把数据打回Kafka,0.8版本的kafka默认是没有批量提交的功能的。本人公司里面一个真实的案例,一位同学写的SparkStreaming程序将数据处理完了以后通过ForeachRDD把数据写回到0.8Kafka。但是数据处理得很慢,经常会收到延时告警。最终发现他把数据写到Kafka的时候是一条数据一条数据提交的性能很差。最终手动实现了批量提交的功能。从此再也没有收到过告警。
4.2.7 Backpressure(压力反馈)


Feedback Loop : 动态使得Streaming app从unstable状态回到stable状态

从Spark1.5版本开始:spark.streaming.backpressure.enabled = true
4.2.8 Elastic Scaling(资源动态分配)
动态分配资源:
批处理动态的决定这个application中需要多少个Executors:
- 当一个Executor空闲的时候,将这个Executor杀掉
- 当task太多的时候,动态的启动Executors
Streaming分配Executor的原则是比对 process time / batchInterval 的比率

如果延迟了,那么就自动增加资源


从Spark2.0有这个功能:: spark.streaming.dynamicAllocation.enabled = true
⭐️4.2.8 数据倾斜调优(重要)
因为SparkStreaming的底层就是RDD,之前SparkCore的所有的数据倾斜的调优策略(见Spark之数据倾斜调优)都适合于SparkStreaming,需要灵活掌握,在实际开发的工作当中用得频率较高。
二 、总结
面试问题:你在工作当中有SparkStreaming调优过项目吗?怎么调优的?效果怎么样?
- 比如举foreachRDD的例子
- 比如举个数据倾斜的例子
- 用Xmind整理调优的策略
相关文章:
SparkStreaming之04:调优
SparkStreaming调优 一 、要点 4.1 SparkStreaming运行原理 深入理解 4.2 调优策略 4.2.1 调整BlockReceiver的数量 案例演示: object MultiReceiverNetworkWordCount {def main(args: Array[String]) {val sparkConf new SparkConf().setAppName("Networ…...

开发博客系统
前言 准备工作 数据库表分为实体表和关系表 第一,建数据库表 然后导入前端页面 创建公共模块 就是统一返回值,异常那些东西 自己造一个自定义异常 普通类 mapper 获取全部博客 我们只需要返回id,title,content,us…...

微信小程序上如何使用图形验证码
1、php服务器生成图片验证码的代码片段如下: 注意红框部分的代码,生成的是ArrayBuffer类型的二进制图片 2、显示验证码 显示验证码,不要直接image组件加上src显示,那样拿不到cookie,没有办法做图形验证码的验证&…...

IntelliJ IDEA 构建项目时内存溢出问题
问题现象 在使用 IntelliJ IDEA 构建 Java 项目时,遇到了以下错误: java: java.lang.OutOfMemoryError: Java heap space java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space这是一个典型的 Java 堆内存不足错误,表…...
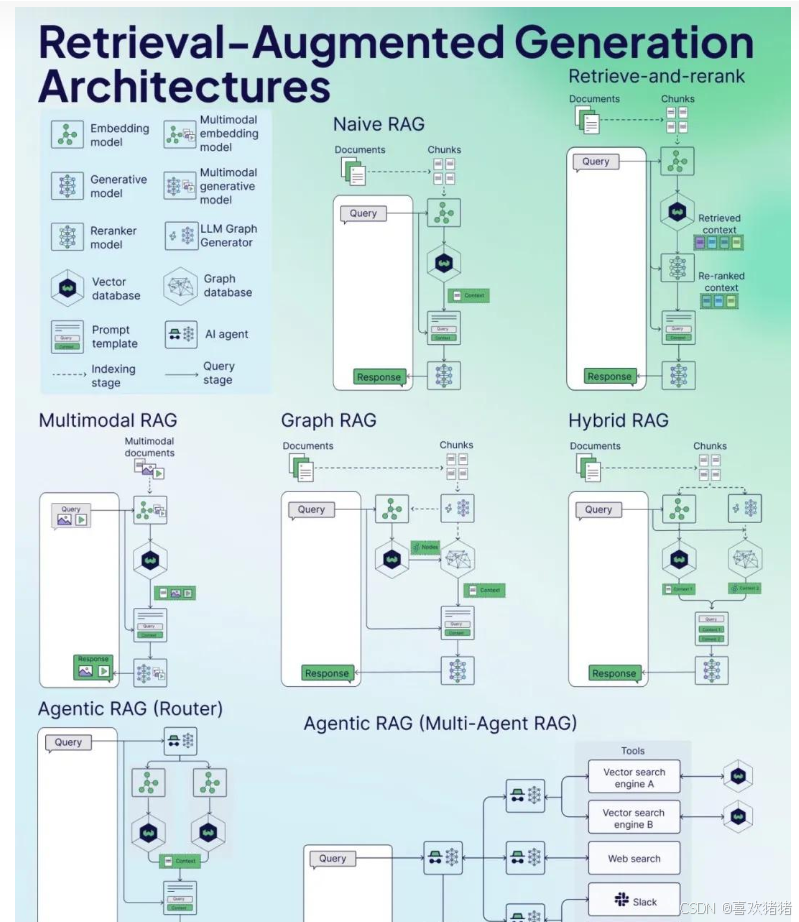
大模型微调与RAG检索增强技术深度解析
一、引言 随着人工智能技术的飞速发展,大模型(如BERT、GPT等)在自然语言处理、计算机视觉等领域取得了显著成效。然而,这些预训练好的大模型往往难以直接应用于特定业务场景,因此,大模型微调(F…...

[liorf_localization_imuPreintegration-2] process has died
使用liorf,编译没报错,但是roslaunch报错如下: 解决方法: step1: 如果你之前没有安装 GTSAM,可以尝试安装它 step2: 检查是否缺少依赖库 ldd /home/zz/1210/devel/lib/liorf_localization/liorf_localization_imuPr…...

2024 年 MySQL 8.0.40 安装配置、Workbench汉化教程最简易(保姆级)
首先到官网上下载安装包:http://www.mysql.com 点击下载,拉到最下面,点击社区版下载 windows用户点击下面适用于windows的安装程序 点击下载,网络条件好可以点第一个,怕下着下着断了点第二个离线下载 双击下载好的安装…...

数列极限入门习题
数列极限入门习题 lim n → ∞ ( 1 1 2 1 3 ⋯ 1 n ) 1 n \lim\limits_{n\rightarrow\infty}(1 \frac{1}{2}\frac{1}{3}\cdots\frac{1}{n})^{\frac{1}{n}} n→∞lim(12131⋯n1)n1 lim n → ∞ ( 1 n 1 1 n 2 ⋯ 1 n n ) \lim\limits_{n\rightarrow\…...

【Python/Pytorch】-- 创建3090Ti显卡所需环境
文章目录 文章目录 01 服务器上,存在三个anaconda,如何选择合适的,创建python环境?02 conda、anaconda、cuda、cudnn区别03 用到一些指令04 如何指定cuda的版本?05 conda跟pip的区别?06 pycharm控制台07 服…...
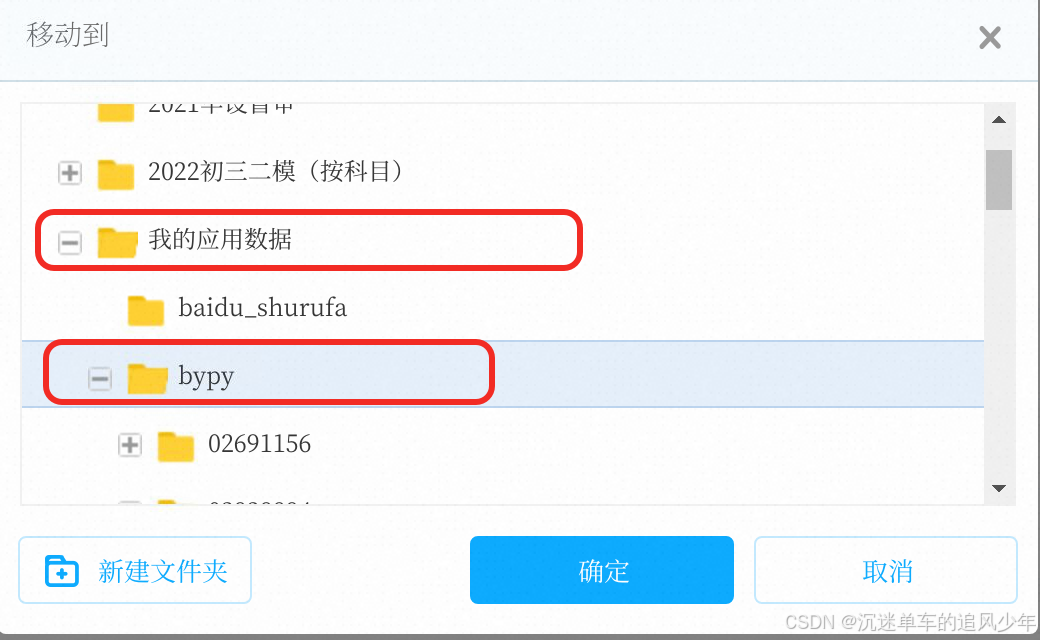
如何在无图形化界面的服务器上下载百度网盘的超大文件(10GB以上)?
目录 登录百度网盘账号 进入特定的文件夹 下载 完整教程 登录百度网盘账号 第一次登录的时候会展示: Please visit: https://openapi.baidu.com/oauth/2.0/authorize?client_idxxx And authorize this app Paste the Authorization Code here within 10 minut…...

AI应用测试:遇到类ChatGPT的流式接口要如何压测?
先说结论: 使用最普遍的JMeter 就能支持类 OpenAI 的流式接口(如 ChatGPT 的流式聊天接口)的测试 总体设置 JMeter 支持测试 OpenAI 的流式接口,但需要额外配置(如启用 KeepAlive 和调整超时)。如果需要实时处理流式响应,使用 Regular Expression Extractor 或自定义脚…...

Linux磁盘情况查询
一、查询系统整体磁盘使用情况 1、基本语法 df -h 2、示例 二、查询指定目录的磁盘占用情况 1、基本语法 du -h 查询指定目录的磁盘占用情况,默认为当前目录 2、常用选项 选项 说明 -h 以人类可读的格式显示磁盘使用情况(例如,KB、…...

数据库原理3
1.在SQL中,外模式对应于试图(VIEW)和部分基本表;模式对应于基本表;内模式对应于存储文件。 2.FETCH:实施游标推进 3.数据操纵:insert,update,delete 数据控制:grant,revoke 数据定义:create,drop,alter 4.物理结构…...

【3D格式转换SDK】HOOPS Exchange技术概览(二):3D数据处理高级功能
在当今数字化工程领域,HOOPS Exchange作为一款强大的SDK,为3D工程应用程序的开发提供了关键支持。本文将深入剖析其基本组件、特定功能以及数据结构,带您全面了解这一驱动3D数据处理的核心工具。 一、概述 HOOPS Exchange专注于访问和重…...

利用Adobe Acrobat 实现PPT中图片分辨率的提升
1. 下载适用于 Windows 的 64 位 Acrobat 注册方式参考:https://ca.whu.edu.cn/knowledge.html?type1 2. 将ppt中需要提高分辨率的图片复制粘贴到新建的pptx问价中,然后执行“文件—>导出---->创建PDF、XPS文档” 3. 我们会发现保存下来的distrib…...

Python frozenset介绍
在 Python 中,frozenset 是一种不可变(immutable)的集合类型,它是 set 的不可变版本。与普通的 set 类型不同,frozenset 的内容一旦创建就不能被修改,这使得它在某些场景下非常有用。 1. 特点 不可变性&am…...

docer swarm集群部署springboot项目
1.准备两台服务器,安装好docker、docker-compose 因为用到了docker仓库,安装harbor,可以从github下载离线安装包 2. 我这边用到了gitlab-ci,整体流程也都差不多 1)打包mvn clean install 2)打镜像 docker-compose -f docker-compo…...

Elasticsearch:解锁深度匹配,运用Elasticsearch DSL构建闪电般的高效模糊搜索体验
目录 Elasticsearch查询分类 叶子查询 全文检索查询 match查询 multi_match查询 精确查询 term查询 range查询 复杂查询 bool查询简单应用 bool查询实现排序和分页 bool查询实现高亮 场景分析 问题思考 解决方案 search_after方案(推荐) point in time方案 方案…...

解决局域网访问Dify却仅显示nginx页面的问题
为什么dify在本机可以正常访问,局域网通过ip访问却只看到欢迎使用nginx的提示,如果访问服务器ip/apps则直接提示404 Not Found。这是怎么回事该如何解决呢?文章中将一步步解决这些问题。 前言 之前在服务器部署了dify,也在服务器…...

deepseek思考,谁是下一个deepseek?
这两天连续看了两篇某B站up关于AI的分析,也是感触很多 讲得内容咱先不说,讲得是真好。怎么说呢,就“活该人家能赚到钱”就对了。 第一篇,他说了一个事儿,就是AI未来的趋势,1000天内,代替世界上…...

从小米汽车召回看智驾“命门”:智能化时代 — 时间就是安全
2025年1月,小米因车辆“授时同步异常”召回3万余辆小米SU7,成为其造车历程中的首个重大安全事件。 从小米SU7召回事件剖析,授时同步何以成为智能驾驶的命门? 2024年11月,多名车主反馈SU7标准版的智能泊车辅助功能出现…...

OpenAI 最后一代非推理模型:OpenAI 发布 GPT-4.5预览版
最后一代非推理大模型 在人工智能领域,OpenAI 一直以其创新的技术和卓越的产品引领着行业的发展。近期,OpenAI 正式发布了 GPT-4.5 研究预览版。不仅如此,官方还宣称 GPT-4.5 被定位为 “最后一代非推理模型”,这一消息再次引起了…...
)
React Native国际化实践(react-i18next)
React Native国际化实践 一、主流国际化方案选择 react-i18next react-native-localize react-i18next:功能强大的国际化框架,支持复数、插值、嵌套等复杂语法,且与React无缝集成。react-native-localize:用于获取设备语言和地区…...

ioday2----->标准io函数
思维导图: 练习: 1将当前的时间写入到time. txt的文件中,如果ctrlc退出之后,在再次执行支持断点续写 1.2022-04-26 19:10:20 2.2022-04-26 19:10:21 3.2022-04-26 19:10:22 //按下ctrlc停止,再次执行程序 4.2022…...

竞争只属于失败者
“竞争只属于失败者”这一观点源自知名投资人、PayPal联合创始人彼得蒂尔(Peter Thiel)。他在斯坦福大学的创业课程中提出,成功的企业应追求垄断地位,而非陷入激烈的市场竞争。蒂尔认为,垄断使企业能够专注于长期发展和…...

【代码分享】基于IRM和RRT*的无人机路径规划方法详解与Matlab实现
基于IRM和RRT*的无人机路径规划方法详解与Matlab实现 1. IRM与RRT*的概述及优势 IRM(Influence Region Map)通过建模障碍物的影响区域,量化环境中的安全风险,为RRT算法提供启发式引导。RRT(Rapidly-exploring Random…...

深度学习代码解读——自用
代码来自:GitHub - ChuHan89/WSSS-Tissue 借助了一些人工智能 2_generate_PM.py 功能总结 该代码用于 生成弱监督语义分割(WSSS)所需的伪掩码(Pseudo-Masks),是 Stage2 训练的前置步骤。其核心流程为&a…...

C++第六节:stack和queue
本节目标: stack的介绍与使用queue的介绍与使用priority_queue的介绍与使用容器适配器模拟实现与结语 1 stack(堆)的介绍 stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,只能从容器的一端进行元素的插…...

华宇“ITSS咨询服务标准助力政务服务区块链解决方案设计”案例成功入选ITSS典型应用案例库
近日,华宇“ITSS咨询服务标准助力政务服务区块链解决方案设计”案例经专家评审后成功入选由全国信息技术标准化技术委员会信息技术服务分技术委员会和中国电子工业标准化技术协会信息技术服务分会(以下简称“ITSS分会”)联合组织建立的“信息…...

从0到1构建AI深度学习视频分析系统--基于YOLO 目标检测的动作序列检查系统:(0)系统设计与工具链说明
文章大纲 系统简介Version 1Version2环境摄像机数据流websocket 发送图像帧RTSP 视频流树莓派windows消息队列参考文献项目地址提示词系统简介 Version 1 Version2 环境 # 配置 conda 源 # 配置conda安装源 conda config --add channels https://mirrors.tuna.tsinghua.edu.c…...