transformer架构解析{掩码,(自)注意力机制,多头(自)注意力机制}(含代码)-3
目录
前言
掩码张量
什么是掩码张量
掩码张量的作用
生成掩码张量实现
注意力机制
学习目标
注意力计算规则
注意力和自注意力
注意力机制
注意力机制计算规则的代码实现
多头注意力机制
学习目标
什么是多头注意力机制
多头注意力计算机制的作用
多头注意力机制的代码实现
前言
在之前的小节中我们学习了词嵌入层(词向量编码)以及加入了位置编码的输入层的概念和代码实现的学习。在本小节中我们将学习transformer中最重要的部分-注意力机制
掩码张量
我们先学习掩码张量。现提出两个问题:什么是掩码张量?生成掩码张量的过程?
什么是掩码张量
张量尺寸不定,里面只有(0,1)元素,代表位置被遮掩或者不遮掩,它的作用就是让另外一张张量中的一些数值被遮掩,被替换,表现形式是一个张量。
掩码张量的作用
在transformer中掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性的Embedding,但是理论上的解码器的输出却并不是一次就能产生的最终结果的,而是一次次通过上一次结果综合得出的,因此,未来信息可能被提前利用,所以进行遮掩。
生成掩码张量实现
#生成掩码张量的代码分析
def subsequeent_mask(size):#生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,形成一个方阵#在函数中,首先定义掩码张量的形状attn_shape = (1,size,size)#使用np.ones方法像这个方阵中添加1元素,形成上三角阵#节约空间将数据类型变为无符号8位整型数字unit8subsequeent_mask = np.triu(np.ones(attn_shape),k=1 ).astype('uint8')#转换成tensor,内部做一个 1 - 操作实现反转return torch.from_numpy(1 - subsequeent_mask)size = 5
sm = subsequeent_mask(size)
print('sm:',sm)
#掩码张量的可视化
plt.figure(figsize=(5,5))
plt.imshow(subsequeent_mask(20)[0])
黄色是1的部分,这里代表被遮掩,紫色代表没有被遮掩,横坐标代表目标词汇的位置,纵坐标代表可查的位置。从上往下看,在0的位置看过去都是黄色,都被遮住了,1的位置望过去还是黄色,说明第一次词还没有产生,从第二位置看过去,就能看到位置1的词,其他位置看不到,以此类推
注意力机制
学习目标
掌握注意力计算规则和注意力机制
掌握注意力计算规则的实现过程(最具有辨识度的部分)
注意力计算规则
它需要3个指定的输入Q(query),K(key),V(value),通过公式计算得出注意力的计算结果
query在key和Value的作用下表示:
大家想要了解具体注意力计算规则可以去了解自然语言处理-BERT处理框架-transformer这篇文章,里面有具体的Q,K,V注意力计算规则介绍。
注意力和自注意力
这两者的区别在于Q,K,V矩阵。注意力,刚开始时Q矩阵输入原词向量,而K,V矩阵输入人为添加的已经总结好的特征向量且默认K=V。自注意力,开始时输入Q=K=V,K,V没有人为干扰完全自己去迭代。
注意力机制
之前我们都是纸上谈兵,要使注意力计算规则能够应用在深度学习的网络,成为载体,包括全连接层以及相关张量的处理。
注意力机制在网络中实现的图形表示:

注意力机制计算规则的代码实现
#注意力计算规则的代码分析
def attention(query,key,value,mask=None,dropout=None):#注意力机制实现:输入分别是query,key,value,mask:掩码张量#在函数中,首先取query的最后一维的大小,词嵌入的维度d_kd_k,来进行缩放d_k = query.size(-1)#按照公式,将query与key的转置相乘,这里面key是将最后两个维度进行转置,再除以缩放系数#得到得分张量scoresscores = torch.matmul(query,key.transpose(-2,-1)) / math.sqrt(d_k)#判断是否使用掩码张量if mask is not None:#使用tensor的masked_fill方法,将掩码张量和scores张量的每一个位置一一比较,如果等于0就一一替换#则对应的socers张量用-1e9这个值来代替scores = scores.masked_fill(mask == 0,-1e9)#对scores的最后一维进行softmax操作,使用F.softmax方法,第一个参数是softmax对象,#获得最终的注意力张量p_attn = F.softmax(scores,dim=-1)#判断是否使用dropout进行随机置0if dropout is not None:#将p_attn传入dropout对象进行‘丢弃’处理p_attn = dropout(p_attn)#最后,根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量return torch.matmul(p_attn,value), p_attnquery = key = value = pe_result #自注意力机制
print(query.shape)
mask = Variable(torch.zeros(2,4,4))
attn,p_attn = attention(query,key,value,mask=mask)
print('attn:',attn)
print(attn.shape)
print('p_attn:',p_attn)
print(p_attn.shape)
多头注意力机制
学习目标
了解多头注意力机制的作用,掌握多头注意力机制的实现过程
多头注意力机制结构图:

什么是多头注意力机制
在图中,我们可以看到,有一组Linear层进行线性变换,变换前后的维度不变,就当是一个方阵的张量,每个张量的值不同,那么变化后的结果也不同,特征就丰富起来了。变换后进入注意力计算机制,一组有多少个linear层并行,就代表有几个头,将计算结果最后一维()分割,然后组合成scores。
多头注意力计算机制的作用
这种结构的设计能够让每个注意力机制去优化每个词的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有更多元的表达,实验表明可以提升模型的效果。
多头注意力机制的代码实现
#多头注意力机制的实现#定义一个克隆函数,因为在多头注意力机制的实现中,用到多个结构相同的线性层
#我们将使用clone函数将他们一同初始化在一个网络层列表对象中,之后的结构中也会使用到该函数
def clones(module,N):#用于生成相同的网络层的克隆函数,它的参数module表示要克隆的目标网络层,N代表需要克隆的数量#在函数中,我们通过for循环对module进行N次的深度拷贝,使其每个module成为独立的层#然后将其放在nn.ModuleList类型的列表中存放return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])#使用一个类来实现多头注意力机制的处理
class MutiHeadedAttention(nn.Module):def __init__(self, head,embedding_dim,dropout=0.1):#在类的初始化时,会传入3个参数,head代表头数,embedding_dim代表词嵌入的维度#dropout代表进行dropout操作时置0比率super(MutiHeadedAttention,self).__init__()#在函数中,首先使用了一个测试中常用的assert语句,判断h是否能被d_model整除#这是因为我们之后要每个头分配等量的词特征,也就是emdedding_dim/head个assert embedding_dim % head == 0#得到每个头获得的分割词向量的维度d_kself.d_k = embedding_dim // head#传入头数self.head = headself.embedding_dim = embedding_dim#然后获得线性层的对象,通过nn.linear实例化,它的内部变换矩阵是embedding_dim x embedding_dim#为什么是4个呢,这是因为在多头注意力中Q,K,V各需要一个,拼接矩阵也需要一个self.linears = clones(nn.Linear(embedding_dim,embedding_dim),4)#self.attn为None,它代表最后获得的注意力张量self.attn = None#最后一个是self.dropout对象,它通过nn中的Dropout实例化而来,置0比率为传进来的的参数dropoutself.dropout = nn.Dropout(p=dropout)def forward(self,query,key,value,mask=None):#前向逻辑函数,它的输入参数有四个,前三个就是注意力机制需要的Q,K,V#最后一个是注意力机制中可能需要的mask掩码,默认是None#如果存在掩码张量maskif mask is not None:#使用unsqueeze拓展维度,代表多头中的第n个头mask = mask.unsqueeze(1)#接着,我们获得一个batch_size的变量,他是query尺寸的第一个数字,代表有多少条样本batch_size = query.size(0)#之后就进入多头处理环节#首先利用zip将QKV与三个线性层住到一起,然后使用for循环,将输入的QKV分别传到线性层中#做完线性变换后,开始为每个头分割输入,这里使用view方法对线性变换的结果进行维度重塑#这样就意味着每个头可以获得一部分词特征组成的句子,其中的-1代表自适应维度#计算机会根据这种变换自动计算这里的值,然后对第二维度和第三维度进行转置操作#为了句子长度维度和词向量维度能够相邻,这样注意力机制才能找到词义与句子位置的关系#从attention函数中可以看到,利用的是原始输入的倒数第一和第二维,这样我们就能得到每个头的query,key,value = \[model(x).view(batch_size,-1,self.head,self.d_k).transpose(1,2) for model,x in zip(self.linears,(query,key,value))]#print(query.shape)#print(key.shape)#print(value.shape)#得到每个头的输入后,接下来就是将他们传入到attention中#这里直接调用我们之前实现的attention函数。同时也将mask和dropout传入其中x,self.attn = attention(query,key,value,mask=mask,dropout=self.dropout)#通过多头注意力计算后,我们就得到每个头计算结果组成的4维张量,我们需要将其转换成为输入的格式#因此这里卡开始进行第一步处理:逆操作,先对第二第三维进行转置,然后使用contiguous方法#这个方法的作用就是让能够让转置后的张量应用view方法,否则将无法直接使用#所以,下一步就是使用view重塑,变成和输入形状相同x = x.transpose(1,2).contiguous().view(batch_size,-1,self.head * self.d_k)#最后使用线性层列表中的最后一个线性层对输入进行线性变换得到最终的多头注意力结构的输出return self.linears[-1](x)#实例化参数
head = 8
embedding_dim = 512
dropout = 0.2#若干输入参数的初始化
query = key = value = pe_resultmask = Variable(torch.zeros(2,4,4))mha = MutiHeadedAttention(head,embedding_dim,dropout)mha_result = mha(query,key,value,mask)print(mha_result)
print(mha_result.shape)
相关文章:
transformer架构解析{掩码,(自)注意力机制,多头(自)注意力机制}(含代码)-3
目录 前言 掩码张量 什么是掩码张量 掩码张量的作用 生成掩码张量实现 注意力机制 学习目标 注意力计算规则 注意力和自注意力 注意力机制 注意力机制计算规则的代码实现 多头注意力机制 学习目标 什么是多头注意力机制 多头注意力计算机制的作用 多头注意力机…...

使用DiskGenius工具来实现物理机多硬盘虚拟化迁移
使用DiskGenius工具来实现物理机多硬盘虚拟化迁移 概述准备工作注意事项实操过程记录1、Win7虚拟机,安装有两个硬盘(硬盘0和硬盘1),各分了一个区,磁盘2是一块未使用的磁盘2、运行DiskGenius程序,记录现有各…...

iOS安全和逆向系列教程 第5篇 iOS基础开发知识速览 - 理解你要逆向的目标
iOS安全和逆向系列教程 第5篇 iOS基础开发知识速览 - 理解你要逆向的目标 正如上一篇文章结尾所预告的,在完成环境搭建后,我们需要了解iOS开发的基础知识。这不是要求你成为一名iOS开发者,而是为了让你在逆向分析过程中能够理解应用的代码结…...

计算机常用单词
文章目录 计算机单词1-100101-200201-300301-400401-500501-600601-700701-800801-900901-10001001-11001101-12001201-13001301-14001401-15001501-16001601-1695 计算机单词 参考 1-100 1. file [英faɪl 美faɪl] n. 文件;v. 保存文件 2. command [英kəˈmɑ…...

TS的接口 泛型 自定义类型 在接口中定义一个非必须的属性
TS的接口 泛型 自定义类型 接口 新建一个ts文件,在里面定义一个接口 export interface PersonInter{id:string,name:string,age:number }在vue文件中引入这个ts文件 <script lang"ts" setup name"Person">import {type PersonInter} …...

76.读取计时器运行时间 C#例子 WPF例子
TimerManager:一个增强的定时器类,带时间管理功能 在使用定时器时,我们常常需要知道定时器的运行状态,比如它已经运行了多久,或者还剩下多少时间。然而,.NET 的 System.Timers.Timer 类本身并没有直接提供…...

React封装通用Table组件,支持搜索(多条件)、筛选、自动序号、数据量统计等功能。未采用二次封装调整灵活,包含使用文档
封装通用组件 一、封装思想二、react代码三、css代码四、实现效果五、使用文档 BasicTableModal 表格模态框组件1.组件简介2.功能特点3.使用方法基础用法宽度控制示例带筛选功能搜索功能示例自定义单元格渲染 4.API 说明PropsColumn 配置项Filter 配置项 5.注意事项 一、封装思…...

【JavaEE】-- 多线程(初阶)4
文章目录 8.多线程案例8.1 单例模式8.1.1 饿汉模式8.1.2 懒汉模式 8.2 阻塞队列8.2.1 什么是阻塞队列8.2.2 生产者消费者模型8.2.3 标准库中的阻塞队列8.2.4 阻塞队列的应用场景8.2.4.1 消息队列 8.2.5 异步操作8.2.5 自定义实现阻塞队列8.2.6 阻塞队列--生产者消费者模型 8.3 …...

WP 高级摘要插件:助力 WordPress 文章摘要精准自定义显示
wordpress插件介绍 “WP高级摘要插件”功能丰富,它允许用户在WordPress后台自定义文章摘要。 可设置摘要长度,灵活调整展示字数;设定摘要最后的显示字符, 如常用的省略号等以提示内容未完整展示;指定允许在摘要中显示…...

论文阅读 EEG-Inception
EEG-Inception: A Novel Deep Convolutional Neural Network for Assistive ERP-Based Brain-Computer Interfaces EEG-Inception是第一个集成Inception模块进行ERP检测的模型,它有效地结合了轻型架构中的其他结构,提高了我们方法的性能。 本研究的主要目…...

FFmpeg入门:最简单的音频播放器
FFmpeg入门:最简单的音频播放器 欢迎大家来到FFmpeg入门的第二章,今天只做一个最简单的FFmpeg音频播放器;同样,话不多说,先上流程图 流程图 以上流程和视频播放器的解码过程基本上是一致的; 不同点在于 S…...

物联网感应层数据采集器实现协议转换 数据格式化
数据采集器的核心功能实现涉及多个技术层面的协同工作,以下是各模块的详细实现解析: 协议转换实现 协议解析引擎:采用插件式架构,例如: P r o t o c o l P a r...

基于Linux系统的物联网智能终端
背景 产品研发和项目研发有什么区别?一个令人发指的问题,刚开始工作时项目开发居多,认为项目开发和产品开发区别不大,待后来随着自身能力的提升,逐步感到要开发一个好产品还是比较难的,我认为项目开发的目的…...

8.1.STM32_OLED
4.STM32_OLED 跟着江协科大的视频,无法点亮OLED屏幕解决办法 每个人使用的0.96寸OLED屏幕信号不一样,存在很多兼容性问题 归根结底就是驱动的问题! 本人的OLED是SSD1306,在淘宝店铺找了驱动文件后成功点亮,示例见文末 请针对自…...

Netty笔记9:粘包半包
Netty笔记1:线程模型 Netty笔记2:零拷贝 Netty笔记3:NIO编程 Netty笔记4:Epoll Netty笔记5:Netty开发实例 Netty笔记6:Netty组件 Netty笔记7:ChannelPromise通知处理 Netty笔记8…...

【算法方法总结·三】滑动窗口的一些技巧和注意事项
【算法方法总结三】滑动窗口的一些技巧和注意事项 【算法方法总结一】二分法的一些技巧和注意事项【算法方法总结二】双指针的一些技巧和注意事项【算法方法总结三】滑动窗口的一些技巧和注意事项 【滑动窗口】 数组的和 随着 右边指针 移动一定是 非递减 的,就是 …...

LabVIEW虚拟弗兰克赫兹实验仪
随着信息技术的飞速发展,虚拟仿真技术已经成为教学和研究中不可或缺的工具。开发了一种基于LabVIEW平台开发的虚拟弗兰克赫兹实验仪,该系统不仅能模拟实验操作,还能实时绘制数据图形,极大地丰富了物理实验的教学内容和方式。 …...

spring boot + vue 搭建环境
参考文档:https://blog.csdn.net/weixin_44215249/article/details/117376417?fromshareblogdetail&sharetypeblogdetail&sharerId117376417&sharereferPC&sharesourceqxpapt&sharefromfrom_link. spring boot vue 搭建环境 一、浏览器二、jd…...

清华团队提出HistoCell,从组织学图像推断超分辨率细胞空间分布助力癌症研究|顶刊精析·25-03-02
小罗碎碎念 今天和大家分享一篇2025-02-21发表于nature communications的文章,内容涉及病理空转单细胞。 从组织学图像推断细胞空间分布对癌症研究意义重大,但现有方法存在标注工作量大、分辨率或特征挖掘不足等局限。研究旨在开发一种高效准确的方法。 …...

分布式锁—2.Redisson的可重入锁一
大纲 1.Redisson可重入锁RedissonLock概述 2.可重入锁源码之创建RedissonClient实例 3.可重入锁源码之lua脚本加锁逻辑 4.可重入锁源码之WatchDog维持加锁逻辑 5.可重入锁源码之可重入加锁逻辑 6.可重入锁源码之锁的互斥阻塞逻辑 7.可重入锁源码之释放锁逻辑 8.可重入锁…...

html+js 轮播图
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>轮播图示例</title><style>/* 基本样式…...

vue3:初学 vue-router 路由配置
承上一篇:nodejs:express js-mdict 作为后端,vue 3 vite 作为前端,在线查询英汉词典 安装 cnpm install vue-router -S 现在讲一讲 vue3:vue-router 路由配置 cd \js\mydict-web\src mkdir router cd router 我还…...
》在c#中的应用及理解)
23种设计模式之《备忘录模式(Memento)》在c#中的应用及理解
程序设计中的主要设计模式通常分为三大类,共23种: 1. 创建型模式(Creational Patterns) 单例模式(Singleton):确保一个类只有一个实例,并提供全局访问点。 工厂方法模式࿰…...

Python 爬取唐诗宋词三百首
你可以使用 requests 和 BeautifulSoup 来爬取《唐诗三百首》和《宋词三百首》的数据。以下是一个基本的 Python 爬虫示例,它从 中华诗词网 或类似的网站获取数据并保存为 JSON 文件。 import requests from bs4 import BeautifulSoup import json import time# 爬取…...

C语言408考研先行课第一课:数据类型
由于408要考数据结构……会有算法题…… 所以,需要C语言来进行一个预备…… 因为大一贪玩,C语言根本没学进去……谁能想到考研还用得到呢?【手动doge(bushi) 软件用的是Clion,可以自行搜索教程下载使用。…...
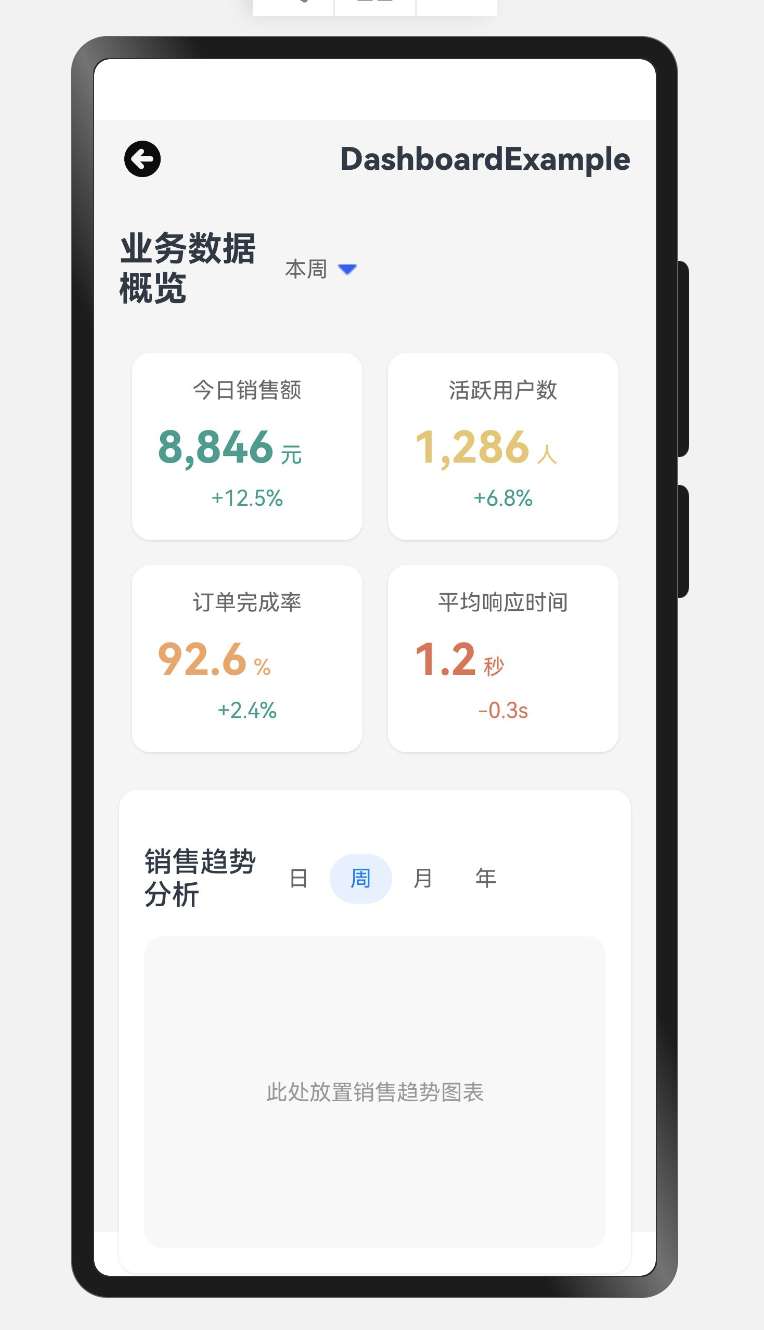
03 HarmonyOS Next仪表盘案例详解(二):进阶篇
温馨提示:本篇博客的详细代码已发布到 git : https://gitcode.com/nutpi/HarmonyosNext 可以下载运行哦! 文章目录 前言1. 响应式设计1.1 屏幕适配1.2 弹性布局 2. 数据展示与交互2.1 数据卡片渲染2.2 图表区域 3. 事件处理机制3.1 点击事件处理3.2 手势…...

探秘基带算法:从原理到5G时代的通信变革【四】Polar 编解码(一)
文章目录 2.3 Polar 编解码2.3.1 Polar 码简介与发展背景2.3.2 信道极化理论基础对称容量与巴氏参数对称容量 I ( W ) I(W) I(W)巴氏参数 Z ( W ) Z(W) Z(W)常见信道信道联合信道分裂信道极化 本博客为系列博客,主要讲解各基带算法的原理与应用,包括&…...

基础篇(一)强化学习是什么?从零开始理解智能体的学习过程
强化学习是什么?从零开始理解智能体的学习过程 你是否曾好奇过,人工智能是如何在复杂的环境中学会做出决策的?无论是打游戏的AI,还是自动驾驶的汽车,还是最近很火的DeepSeek它们的背后都离不开一种强大的技术——强化…...

如何直接导出某个conda环境中的包, 然后直接用 pip install -r requirements.txt 在新环境中安装
1. 导出 Conda 环境配置 conda list --export > conda_requirements.txt这将生成一个 conda_requirements.txt 文件,其中包含当前环境中所有包的列表及其版本信息。 2. 转换为 requirements.txt 文件 grep -v "^#" conda_requirements.txt | cut -d …...

基于 HTML、CSS 和 JavaScript 的智能九宫格图片分割系统
目录 1 前言 2 技术实现 2.1 HTML 结构 2.2 CSS 样式 2.3 JavaScript 交互 3 代码解析 3.1 HTML 部分 3.2 CSS 部分 3.3 JavaScript 部分 4 完整代码 5 运行结果 6 总结 6.1 系统特点 6.2 使用方法 1 前言 在当今数字化的时代,图片处理需求日益增长。…...