FastGPT 源码:基于 LLM 实现 Rerank (含Prompt)
文章目录
- 基于 LLM 实现 Rerank
- 函数定义
- 预期输出
- 实现说明
- 使用建议
- 完整 Prompt
基于 LLM 实现 Rerank
下边通过设计 Prompt 让 LLM 实现重排序的功能。
函数定义
class LLMReranker:def __init__(self, llm_client):self.llm = llm_clientdef rerank(self, query: str, documents: list[dict]) -> list[dict]:# 构建 promptprompt = self._build_rerank_prompt(query, documents)# 调用 LLMresponse = self.llm.chat.completions.create(model="gpt-3.5-turbo",temperature=0, # 降低随机性messages=[{"role": "system", "content": """你是一个专业的搜索结果重排序专家。
你的任务是:
1. 评估每个文档与用户查询的相关性
2. 给出0-1之间的相关性分数
3. 解释评分理由
4. 按相关性从高到低排序评分标准:
- 0.8-1.0: 完全相关,直接回答问题
- 0.6-0.8: 高度相关,包含大部分所需信息
- 0.4-0.6: 部分相关,包含一些相关信息
- 0.0-0.4: 基本不相关请以JSON格式返回结果。"""},{"role": "user", "content": prompt}])# 解析响应try:results = eval(response.choices[0].message.content)return resultsexcept:return []def _build_rerank_prompt(self, query: str, documents: list[dict]) -> str:prompt = f"""请对以下文档进行重排序:用户查询: {query}待排序文档:
"""for i, doc in enumerate(documents, 1):prompt += f"""
文档{i}:
ID: {doc['id']}
内容: {doc['text']}
"""prompt += """
请以如下JSON格式返回重排序结果:
[{"id": "文档ID","score": 相关性分数,"reason": "评分理由"},...
]
"""return prompt# 使用示例
def main():# 初始化查询和文档query = "Python如何处理JSON数据?"documents = [{"id": "doc1","text": "Python提供了json模块来处理JSON数据。使用json.loads()可以将JSON字符串转换为Python对象,使用json.dumps()可以将Python对象转换为JSON字符串。",},{"id": "doc2", "text": "在Python中,字典(dict)是一种常用的数据结构,它的格式与JSON非常相似。你可以使用字典来存储键值对数据。",},{"id": "doc3","text": "Python是一种面向对象的编程语言,支持类和对象的概念。你可以创建自定义类来组织数据和行为。",}]# 初始化 LLM client (这里以 OpenAI 为例)from openai import OpenAIclient = OpenAI()# 执行重排序reranker = LLMReranker(client)results = reranker.rerank(query, documents)# 打印结果print("\n查询:", query)print("\n重排序结果:")for i, result in enumerate(results, 1):print(f"\n{i}. 文档ID: {result['id']}")print(f" 相关性分数: {result['score']}")print(f" 评分理由: {result['reason']}")预期输出
[{"id": "doc1","score": 0.95,"reason": "文档直接回答了如何处理JSON数据的问题,提供了具体的json模块使用方法(loads和dumps函数),信息完整且准确。"},{"id": "doc2","score": 0.65,"reason": "文档提到了Python字典与JSON的关系,对理解JSON处理有帮助,但没有直接说明处理方法。"},{"id": "doc3","score": 0.2,"reason": "文档只介绍了Python的面向对象特性,与JSON数据处理无直接关系。"}
]
实现说明
-
简单易用:
- 不需要额外的模型
- 只依赖LLM API
- 实现逻辑清晰
-
灵活性强:
- 可以通过修改prompt调整评分标准
- 可以获取评分理由
- 支持多维度评估
-
可解释性好:
- 每个分数都有明确的理由
- 评分标准透明
- 便于调试和优化
-
适应性强:
- 可处理各种领域的问题
- 不需要领域特定训练
- 支持多语言
使用建议
- Prompt优化:
# 可以添加更多评分维度
"""
评分维度:
1. 相关性: 内容与查询的关联程度
2. 完整性: 信息的完整程度
3. 准确性: 信息的准确程度
4. 时效性: 信息的新旧程度
"""
- 批量处理:
# 对于大量文档,可以分批处理
def batch_rerank(self, query: str, documents: list, batch_size: int = 5):results = []for i in range(0, len(documents), batch_size):batch = documents[i:i + batch_size]batch_results = self.rerank(query, batch)results.extend(batch_results)return sorted(results, key=lambda x: x['score'], reverse=True)
- 错误处理:
try:response = self.llm.chat.completions.create(...)results = eval(response.choices[0].message.content)
except Exception as e:print(f"重排序错误: {str(e)}")# 返回原始顺序return [{"id": doc["id"], "score": 0.5} for doc in documents]
- 缓存结果:
from functools import lru_cache@lru_cache(maxsize=1000)
def cached_rerank(self, query: str, doc_key: str):# 实现缓存逻辑pass
这种基于LLM的重排序方案特别适合:
- 快速原型验证
- 小规模应用
- 需要高可解释性的场景
- 多语言或跨领域应用
完整 Prompt
你是一个专业的搜索结果重排序专家。你的任务是评估每个文档与用户查询的相关性,并给出排序。评分标准:
1. 相关性分数范围: 0.0-1.0
- 0.8-1.0: 完全相关,直接回答问题
- 0.6-0.8: 高度相关,包含大部分所需信息
- 0.4-0.6: 部分相关,包含一些相关信息
- 0.0-0.4: 基本不相关2. 评分维度:
- 相关性: 文档内容是否直接回答查询问题
- 完整性: 回答的信息是否完整
- 准确性: 信息是否准确专业
- 直接性: 是否需要用户进一步推理或处理用户查询: Python如何处理JSON数据?待评估文档:
文档1:
ID: doc1
内容: Python提供了json模块来处理JSON数据。使用json.loads()可以将JSON字符串转换为Python对象,使用json.dumps()可以将Python对象转换为JSON字符串。文档2:
ID: doc2
内容: 在Python中,字典(dict)是一种常用的数据结构,它的格式与JSON非常相似。你可以使用字典来存储键值对数据。文档3:
ID: doc3
内容: Python是一种面向对象的编程语言,支持类和对象的概念。你可以创建自定义类来组织数据和行为。请按以下JSON格式返回重排序结果,必须包含id字段:
[
"文档ID",
...
]注意:
1. 结果必须按score从高到低排序
2. 结果中只需要给出id字段
3. 返回格式必须是合法的JSON格式,不要做任何解释
相关文章:
)
FastGPT 源码:基于 LLM 实现 Rerank (含Prompt)
文章目录 基于 LLM 实现 Rerank函数定义预期输出实现说明使用建议完整 Prompt 基于 LLM 实现 Rerank 下边通过设计 Prompt 让 LLM 实现重排序的功能。 函数定义 class LLMReranker:def __init__(self, llm_client):self.llm llm_clientdef rerank(self, query: str, docume…...

DE2115实现4位全加器和3-8译码器(FPGA)
一、配置环境 1、Quartus 18.1安装教程 软件:Quartus版本:Quartus 18.1语言:英文大小:5.78G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.0GHz 内存4G(或更高) 下载通道①百度网盘丨64位下载…...
如何赋能时间序列分析?)
大语言模型(LLM)如何赋能时间序列分析?
引言 近年来,大语言模型(LLM)在文本生成、推理和跨模态任务中展现了惊人能力。与此同时,时间序列分析作为工业、金融、物联网等领域的核心技术,长期依赖传统统计模型(如ARIMA)或深度学习模型&a…...

【AI大模型】DeepSeek + Kimi 高效制作PPT实战详解
目录 一、前言 二、传统 PPT 制作问题 2.1 传统方式制作 PPT 2.2 AI 大模型辅助制作 PPT 2.3 适用场景对比分析 2.4 最佳实践与推荐 三、DeepSeek Kimi 高效制作PPT操作实践 3.1 Kimi 简介 3.2 DeepSeek Kimi 制作PPT优势 3.2.1 DeepSeek 优势 3.2.2 Kimi 制作PPT优…...

如何快速上手RabbitMQ 笔记250304
如何快速上手RabbitMQ 要快速上手 RabbitMQ,可以按照以下步骤进行,从安装到基本使用逐步掌握核心概念和操作: 1. 理解核心概念 Producer(生产者):发送消息的程序。Consumer(消费者)…...
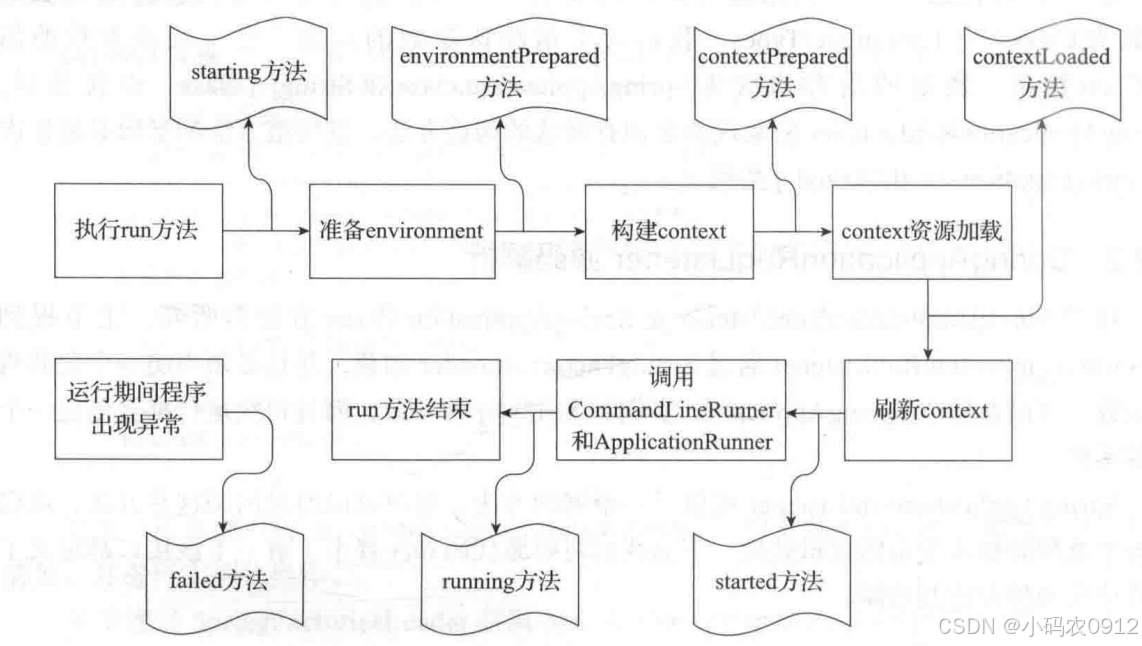
run方法执行过程分析
文章目录 run方法核心流程SpringApplicationRunListener监听器监听器的配置与加载SpringApplicationRunListener源码解析实现类EventPublishingRunListener 初始化ApplicationArguments初始化ConfigurableEnvironment获取或创建环境配置环境 打印BannerSpring应用上下文的创建S…...

面试-----每日一题
一、字节一面(操作系统) 什么是死锁?如何处理死锁问题? 死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通讯而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。…...

学习与事务平衡技巧
当学习过程中需要处理其他事务时,关键在于平衡专注与灵活性,避免中断打乱学习节奏。以下是具体建议: 一、快速判断事务优先级 紧急且重要(如突发工作、紧急回复): 立刻处理,但完成后用5分钟快速…...

CentOS 7中安装Dify
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。尤其是我们本地部署DeepSeek等大模型时,会需要用到Dify来帮我们快捷的开发和应用。 大家可以参考学习它的中…...

qt-C++笔记之Linux下Qt环境变量设置及与QtCreator的关系
qt-C++笔记之Linux下Qt环境变量设置及与QtCreator的关系 code review! 文章目录 qt-C++笔记之Linux下Qt环境变量设置及与QtCreator的关系一.Qt关键的环境变量1.1.PATH1.2.LD_LIBRARY_PATH1.3.QML2_IMPORT_PATH二.若不手动设置这三个环境变量2.1.PATH 的默认路径2.2.LD_LIBRARY_…...

问deepseek:有哪些支持OpenMP多线程并行的AMG代数多重网格软件库
AMG(Algebraic Multigrid)是一种用于求解大规模稀疏线性方程组的有效方法,广泛应用于科学计算和工程领域。OpenMP 是一种用于共享内存并行编程的 API,支持多线程并行计算。 以下是一些支持 OpenMP 多线程的开源 AMG 软件包&#…...

【Flink银行反欺诈系统设计方案】1.短时间内多次大额交易场景的flink与cep的实现
【flink应用系列】1.Flink银行反欺诈系统设计方案 1. 经典案例:短时间内多次大额交易1.1 场景描述1.2 风险判定逻辑 2. 使用Flink实现2.1 实现思路2.2 代码实现2.3 使用Flink流处理 3. 使用Flink CEP实现3.1 实现思路3.2 代码实现 4. 总结 1. 经典案例:短…...

Android 系统开发的指导文档
Android 系统开发的指导文档 文章目录 Android 系统开发的指导文档一、基础准备1、学习编程语言2、熟悉开发环境 二、核心知识学习1、Android 系统架构:2、四大组件(1)Activity:是 Android 应用中最基本的组件,用于实现…...

网络编程——http
在Linux系统中使用C语言实现HTTP客户端或服务器通常涉及使用套接字编程和一些HTTP协议的基本知识。下面是一个简单的示例,展示了如何用C语言实现一个HTTP客户端,向一个HTTP服务器发送请求并接收响应。 1. HTTP客户端示例 (C语言) 这个例子展示了如何用C…...

Flutter 学习之旅 之 flutter 使用 carousel_slider 简单实现轮播图效果
Flutter 学习之旅 之 flutter 使用 carousel_slider 简单实现轮播图效果 目录 Flutter 学习之旅 之 flutter 使用 carousel_slider 简单实现轮播图效果 一、简单介绍 二、简单介绍 carousel_slider 三、安装 carousel_slider 四、简单案例实现 五、关键代码 一、简单介…...

【JavaScript—前端快速入门】JavaScript 对象与函数
JavaScript 对象 1. JavaScripe 数组 创建数组的方式 使用 new 关键字创建 使用字面量方式创建 [常用] 注意,JavaScipt 不要求数组元素类型都相同; 数组操作 读:使用下标的方式访问数组元素(从0开始) 保存代码,打开…...

java中的局部变量
文章目录 一、定义二、作用域和作用位置三、声明周期和初始化四、内存管理五、Java内存区域划分六、例子 一、定义 在java中,局部变量指在方法、构造方法、代码块(如{}包裹的语句块)内部声明的变量 class work {{int a 10;}public work() {i…...

【芯片设计】AI芯片前端设计工程师面试记录·20250303
【芯片前端设计面试经验专栏介绍】 专栏聚焦数字芯片前端设计核心技术与面试方法论,涵盖架构设计、RTL开发、验证方法学、低功耗设计、时序收敛等高频考点,深入解析行业头部企业的面试真题与设计场景。内容包含但不限于: 知识点系统梳理 :从Verilog/SV语法陷阱、FSM设计模式…...

(IDE接入DeepSeek)简单了解DeepSeek接入辅助开发与本地部署建议
重点:IDE接入DeepSeek是否收费 收费! 本文章主要是为了给小白避雷,目前很多文章告诉大家怎么接入DeepSeek,但是并未告知大家是否收费。如果是想白嫖的,就可以不用去接入了。 一、引言 最近爆火的AI人工智能工具DeepSe…...

【算法学习之路】5.贪心算法
贪心算法 前言一.什么是贪心算法二.例题1.合并果子2.跳跳!3. 老鼠和奶酪 前言 我会将一些常用的算法以及对应的题单给写完,形成一套完整的算法体系,以及大量的各个难度的题目,目前算法也写了几篇,题单正在更新…...

0x03 http协议和分层架构
HTTP协议 简介 Hyper Text Transfer Protocol,超文本传输协议,规定了浏览器和服务器之间数据传输的规则 http协议基于TCP协议:面向连接,安全基于请求-响应模型:一次请求对应一次响应HTTP协议是无状态的协议ÿ…...

ES批量查询
在 Elasticsearch 中,multi_search(也称为 msearch)是一种允许你在单个请求中执行多个搜索操作的 API。它可以显著减少网络开销,尤其是在需要执行多个查询时。multi_search 会将多个查询打包成一个请求发送给 Elasticsearch&#…...

React Refs:深入理解与最佳实践
React Refs:深入理解与最佳实践 引言 在React中,refs是用于访问DOM元素或组件实例的一种方式。与类组件的ref属性不同,函数组件的ref需要使用useRef钩子。正确使用refs可以大大提升React应用的性能和可维护性。本文将深入探讨React Refs的原…...

智能合约安全指南 [特殊字符]️
智能合约安全指南 🛡️ 1. 安全基础 1.1 常见漏洞类型 重入攻击整数溢出权限控制缺陷随机数漏洞前后运行攻击签名重放 1.2 安全开发原则 最小权限原则检查-生效-交互模式状态机安全失败保护机制 2. 重入攻击防护 2.1 基本防护模式 contract ReentrancyGuarde…...

【Python项目】基于Python的书籍售卖系统
【Python项目】基于Python的书籍售卖系统 技术简介:采用Python技术、MYSQL数据库等实现。 系统简介:书籍售卖系统是一个基于B/S结构的在线图书销售平台,主要分为前台和后台两部分。前台系统功能模块分为(1)用户中心模…...

【Linux】【网络】UDP打洞-->不同子网下的客户端和服务器通信(未成功版)
【Linux】【网络】UDP打洞–>不同子网下的客户端和服务器通信(未成功版) 上次说基于UDP的打洞程序改了五版一直没有成功,要写一下问题所在,但是我后续又查询了一些资料,成功实现了,这次先写一下未成功的…...

(1)udp双向通信(2)udp实现文件复制(3)udp实现聊天室
一.udp双向通信 1.fork进程实现双向通信 【1】head.h 【2】client客户端 (1)父进程从键盘获取字符串 (2)输入quit,发送结束子进程信号 (3)exit退出父进程 (1)子进程接受…...

c高级第五天
1> 在终端提示输入一个成绩,通过shell判断该成绩的等级 [90,100] : A [80, 90) : B [70, 80) : C [60, 70) : D [0, 60) : 不及格 #!/bin/bash# 提示用户输入成绩 read -p "请输入成绩(0-100):" score# 判断成…...
【JQuery—前端快速入门】JQuery 操作元素
JQuery 操作元素 1. 获取/修改元素内容 三个简单的获取元素的方法: 这三个方法即可以获取元素的内容,又可以设置元素的内容. 有参数时,就进行元素的值设置,没有参数时,就进行元素内容的获取. 接下来,我们需…...

深度学习-139-RAG技术之Agentic Chunking分块技术的工作原理及简单实现
文章目录 1 传统分块的问题2 Agentic Chunking的工作原理3 Agentic Chunking怎么实现3.1 Propositioning文本3.1.1 大语言模型3.1.2 官方提示词模板3.1.3 抽取链3.2 使用LLM Agent创建文本块3.2.1 创建新文本块3.2.2 将proposition添加到文本块3.2.3 将proposition推送到合适的…...