Node JS 调用模型Xenova_all-MiniLM-L6-v2实战
本篇通过将句子数组转换为句子的向量表示,并通过平均池化和归一化处理,生成适合机器学习或深度学习任务使用的特征向量为例,演示通过NodeJS 的方式调用Xenova/all-MiniLM-L6-v2 的过程。
关于 all-MiniLM-L6-v2 的介绍,可以参照上一篇:
一篇吃透模型:all-MiniLM-L6-v2
可以访问 Hugging Face的状况
Hugging 的站点是:
https://huggingface.co/
如果可以访问该站点的话,则直接安装 Hugging Face 的 Transformers 库。
npm i @huggingface/transformers
之后就可以编写代码:
import { pipeline } from '@huggingface/transformers';// Create a feature-extraction pipeline
const extractor = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2');// Compute sentence embeddings
const sentences = ['This is an example sentence', 'Each sentence is converted'];
const output = await extractor(sentences, { pooling: 'mean', normalize: true });
console.log(output);
上面代码作用就是加载模型,将语句转换为向量,细节的部分下面再介绍,执行的效果如下:

到此,就成功的运行了。
但是如果无法访问Hugging Face 的化, 运行就会出现如下错误:

PS D:\devworkspace\vs\ai_ency\ai_nodejs_ency> node .\src\llm\minilm\huggingface-minilm.js
node:internal/deps/undici/undici:12502Error.captureStackTrace(err, this);^TypeError: fetch failedat node:internal/deps/undici/undici:12502:13at processTicksAndRejections (node:internal/process/task_queues:95:5)at runNextTicks (node:internal/process/task_queues:64:3)at process.processImmediate (node:internal/timers:449:9)at async getModelFile (file:///D:/devworkspace/vs/ai_ency/ai_nodejs_ency/node_modules/@huggingface/transformers/dist/transformers.mjs:31325:24)at async getModelJSON (file:///D:/devworkspace/vs/ai_ency/ai_nodejs_ency/node_modules/@huggingface/transformers/dist/transformers.mjs:31427:18)at async Promise.all (index 0)at async loadTokenizer (file:///D:/devworkspace/vs/ai_ency/ai_nodejs_ency/node_modules/@huggingface/transformers/dist/transformers.mjs:24731:18)at async AutoTokenizer.from_pretrained (file:///D:/devworkspace/vs/ai_ency/ai_nodejs_ency/node_modules/@huggingface/transformers/dist/transformers.mjs:29020:50)at async Promise.all (index 0) {[cause]: ConnectTimeoutError: Connect Timeout Errorat onConnectTimeout (node:internal/deps/undici/undici:6635:28)at node:internal/deps/undici/undici:6587:50at Immediate._onImmediate (node:internal/deps/undici/undici:6617:37)at process.processImmediate (node:internal/timers:478:21) {code: 'UND_ERR_CONNECT_TIMEOUT'}
}因为默认会从Hugging Face下载模型文件,无法下载,报上面的fetch 获取错误, 有解决方法吗?
答案就是从ModelScope 下载模型文件。
从 ModelScope 下载模型文件
ModelScope上面也维护了 Xenova/all-MiniLM-L6-v2 的模型文件, 地址是:
https://www.modelscope.cn/models/Xenova/all-MiniLM-L6-v2/files

但是,ModelScope提供了Python的库,却没有NodeJS的库,所以无法直接通过ModelScope的来下载,但是可以下载模型的文件,下载方式就是先安装ModelScope,然后用ModelScope 的命令行下载模型文件:
modelscope download --model Xenova/all-MiniLM-L6-v2下载后的文件目录如下图:

下载后,将这个目录中的内容复制到NodeJS 项目的node_modules 目录下的 node_modules@huggingface\transformers.cache 目录下, 这也是Hugging Face下载模型文件的目录,结构如下图:

复制完成之后,就可以正常运行了。
补充介绍: Transformers 是什么?
Transformers 是由 Hugging Face 团队开发的开源 库,专注于提供基于 Transformer 架构 的预训练模型和工具。它简化了自然语言处理(NLP)任务的实现流程,支持文本生成、翻译、分类、问答等场景,并兼容 PyTorch、TensorFlow 等深度学习框架。
Transformers 有Python 和 NodeJS 两个版本。
如果Hugging Face无法访问
- Python 版本可以使用ModelScope提供的库
- NodeJS
补充介绍: 代码详细解释
const extractor = await pipeline(...) 是使用 Hugging Face Transformers.js 库的核心方法之一,用于创建一个 预训练模型的推理管道。通过 pipeline,可以轻松加载模型并执行各种任务(如文本分类、特征提取、问答等)。
pipeline 的作用是:
- 加载模型:从本地或远程加载预训练模型和分词器。
- 封装推理逻辑:将模型的输入预处理、推理和后处理逻辑封装成一个简单的接口。
- 执行任务:根据任务类型(如
feature-extraction、text-classification等),对输入数据进行处理并返回结果。
参数详解
pipeline 方法的完整签名如下:
const pipeline = await transformers.pipeline(task, model, options);
1. task(必需)
指定要执行的任务类型。常见的任务包括:
feature-extraction:特征提取(生成句子或词的嵌入向量)。text-classification:文本分类。question-answering:问答任务。translation:翻译任务。text-generation:文本生成。- 其他任务:如
summarization、fill-mask等。
示例:
const extractor = await pipeline('feature-extraction');
2. model(可选)
指定要加载的模型。可以是以下之一:
- 模型名称:从 Hugging Face Hub 加载的模型名称(如
Xenova/all-MiniLM-L6-v2)。 - 本地路径:本地模型文件的路径(如
./custom_model)。 - 未指定:如果不提供,库会加载默认模型。
示例:
// 从 Hugging Face Hub 加载模型
const extractor = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2');// 从本地路径加载模型
const extractor = await pipeline('feature-extraction', './custom_model');
3. options(可选)
一个配置对象,用于自定义模型加载和推理行为。常见选项包括:
| 选项 | 类型 | 描述 |
|---|---|---|
local_files_only | boolean | 是否仅从本地加载模型(默认 false)。设置为 true 可禁用网络请求。 |
revision | string | 模型版本(如 main 或特定 commit hash)。 |
cache_dir | string | 缓存目录路径。设置为 null 可禁用缓存。 |
quantized | boolean | 是否加载量化模型(默认 false)。 |
progress_callback | function | 加载模型时的进度回调函数。 |
device | string | 推理设备(如 cpu 或 gpu)。 |
pooling | string | 特征提取时的池化方式(如 mean、max)。 |
normalize | boolean | 是否对特征向量进行归一化(默认 false)。 |
示例:
const extractor = await pipeline('feature-extraction', 'Xenova/all-MiniLM-L6-v2', {local_files_only: true, // 仅从本地加载revision: 'main', // 使用主分支版本pooling: 'mean', // 使用均值池化normalize: true, // 对输出向量归一化
});
返回值
pipeline 返回一个 推理函数,可以直接用于处理输入数据。具体返回值类型取决于任务类型。
示例:
// 特征提取任务
const extractor = await pipeline('feature-extraction');// 使用推理函数
const sentences = ['This is an example sentence'];
const embeddings = await extractor(sentences, { pooling: 'mean' });
console.log(embeddings);
相关文章:
Node JS 调用模型Xenova_all-MiniLM-L6-v2实战
本篇通过将句子数组转换为句子的向量表示,并通过平均池化和归一化处理,生成适合机器学习或深度学习任务使用的特征向量为例,演示通过NodeJS 的方式调用Xenova/all-MiniLM-L6-v2 的过程。 关于 all-MiniLM-L6-v2 的介绍,可以参照上…...

React + TypeScript 实战指南:用类型守护你的组件
TypeScript 为 React 开发带来了强大的类型安全保障,这里解析常见的一些TS写法: 一、组件基础类型 1. 函数组件定义 // 显式声明 Props 类型并标注返回值 interface WelcomeProps {name: string;age?: number; // 可选属性 }const Welcome: React.FC…...
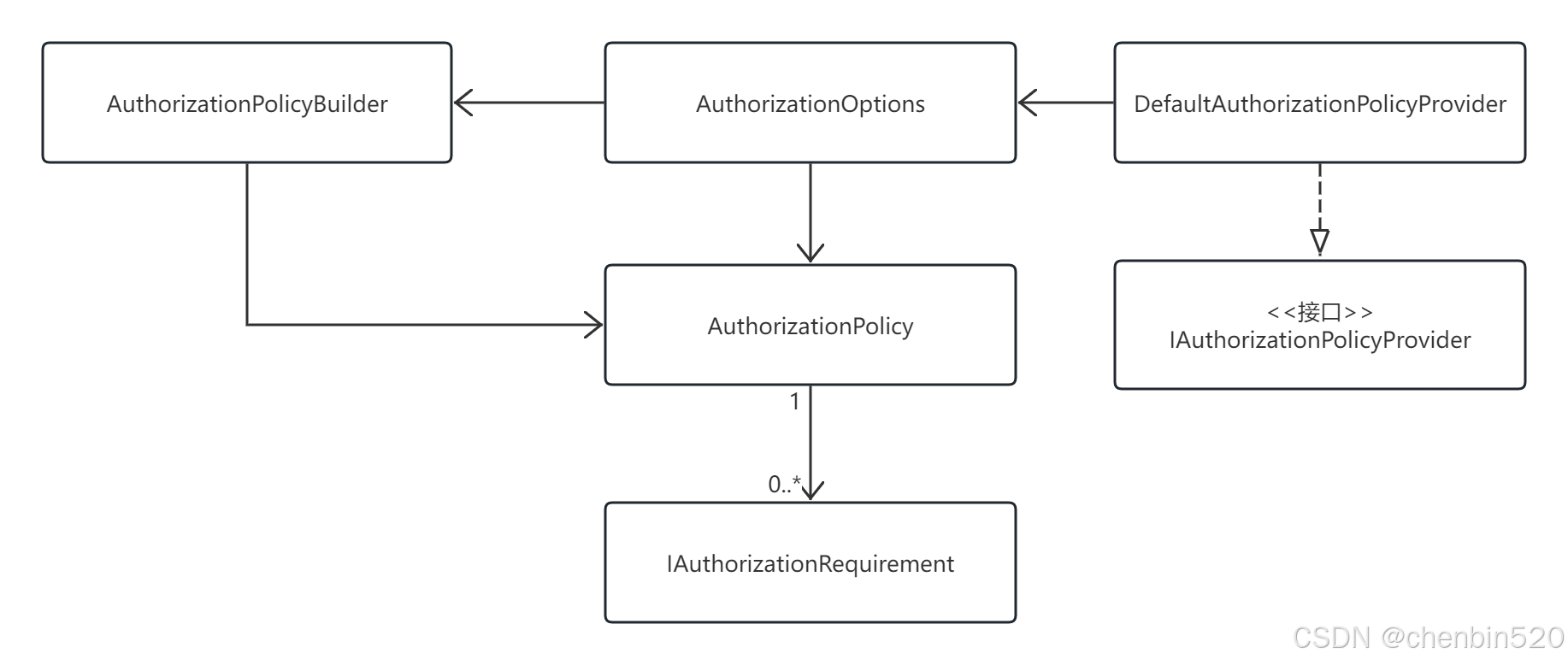
ASP.NET Core JWT认证与授权
1.JWT结构 JSON Web Token(JWT)是一种用于在网络应用之间安全传输声明的开放标准(RFC 7519)。它通常由三部分组成,以紧凑的字符串形式表示,在身份验证、信息交换等场景中广泛应用。 2.JWT权限认证 2.1添…...

【车规芯片】如何引导时钟树生长方向
12nm车规DFTAPR项目中,我们可以看到,绝大部分的sink都受控于xxxx_tessent_occ_clk_cpu_inst/tessent_persistent_cell_clock_out_mux/C10_ctmi_1这个mux,这是我们DFT设计结果: 这里我们重新打开place的数据 Anchor,也就…...

突破传统:用Polars解锁ICU医疗数据分析新范式
一、ICU数据革命的临界点 在重症监护室(ICU),每秒都在产生关乎生死的关键数据:从持续监测的生命体征到高频更新的实验室指标,从呼吸机参数到血管活性药物剂量,现代ICU每天产生的数据量级已突破TB级别。传统…...

《深度学习实战》第11集:AI大模型压缩与加速
深度学习实战 | 第11集:AI大模型压缩与加速 在深度学习领域,随着模型规模的不断增大,模型的推理速度和部署效率成为实际应用中的关键挑战。本篇博客将带你深入了解模型压缩与加速的核心技术,并通过一个实战项目展示如何使用知识蒸…...

golang进阶知识专项-理解值传递
在 Go 语言中,所有函数的参数传递都是值传递(Pass by Value)。当你将一个变量作为参数传递给函数时,实际上传递的是该变量的副本,而不是变量本身。理解这一点对于避免常见的编程错误至关重要。根据不同的类型ÿ…...
- 慧知开源充电桩平台)
OCPP与ISO 15118集成:实现即插即充与车网互动(V2G)- 慧知开源充电桩平台
OCPP与ISO 15118集成:实现即插即充与车网互动(V2G) 引言 随着电动汽车(EV)与电网双向能量交互(V2G)技术的成熟,OCPP协议与ISO 15118标准的协同成为智能充电基础设施的核心挑战。本文…...

大语言模型中温度参数(Temperature)的核心原理
大语言模型中温度参数(Temperature)的核心原理是通过调整模型输出的概率分布,控制生成结果的随机性和多样性。以下是其原理的详细说明: 一、定义与核心作用 温度参数是生成式模型(如GPT系列)中的一个超参数…...

K8s控制器Deployment详解
回顾 ReplicaSet 控制器,该控制器是用来维护集群中运行的 Pod 数量的,但是往往在实际操作的时候,我们反而不会去直接使用 RS,而是会使用更上层的控制器,比如说 Deployment。 Deployment 一个非常重要的功能就是实现了 Pod 的滚动…...

鸿蒙HarmonyOS评论功能小demo
评论页面小demo 效果展示 1.拆解组件,分层搭建 我们将整个评论页面拆解为三个组件,分别是头部导航,评论项,回复三个部分,然后统一在index界面导入 2.头部导航界面搭建 Preview Component struct HmNavBar {// 属性&a…...

基于PyTorch的深度学习3——基于autograd的反向传播
反向传播,可以理解为函数关系的反向传播。...

日期格式与字符串不匹配bug
异常特征:java.lang.IllegalArgumentException: invalid comparison: java.time.LocalDateTime and java.lang.String ### Error updating database. Cause: java.lang.IllegalArgumentException: invalid comparison: java.time.LocalDateTime and java.lang.Str…...

打印三角形及Debug
打印三角形及Debug package struct; public class TestDemo01 {public static void main(String[] args) {//打印三角形 五行 for (int i 1; i < 5; i) {for (int j 5 ; j >i; j--) {System.out.print(" ");}for (int k1;k<i;k) {System.out.print(&…...

大语言模型揭秘:从诞生到智能
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)无疑是技术领域最耀眼的明星之一。它们不仅能够理解人类的自然语言,还能生成流畅的文本,甚至在对话、翻译、创作等任务中表现出接近人类的智能…...
Collab-Overcooked:专注于多智能体协作的语言模型基准测试平台
2025-02-27,由北京邮电大学和理想汽车公司联合创建。该平台基于《Overcooked-AI》游戏环境,设计了更具挑战性和实用性的交互任务,目的通过自然语言沟通促进多智能体协作。 一、研究背景 近年来,基于大型语言模型的智能体系统在复…...

SpringBoot接入DeepSeek(硅基流动版)+ 前端页面调试(WebSocket连接模式)
文章目录 前言正文一、项目环境二、项目代码2.1 pom.xml2.2 DeepSeekController.java2.3 启动类2.4 logback-spring.xml2.5 application.yaml2.6 WebsocketConfig.java2.7 AiChatWebSocketHandler.java2.8 SaveChatSessionParamRequest.java2.9 index.html 三、页面调试3.1 主页…...

LINUX网络基础 [一] - 初识网络,理解网络协议
目录 前言 一. 计算机网络背景 1.1 发展历程 1.1.1 独立模式 1.1.2 网络互联 1.1.3 局域网LAN 1.1.4 广域网WAN 1.2 总结 二. "协议" 2.1 什么是协议 2.2 网络协议的理解 2.3 网络协议的分层结构 三. OSI七层模型(理论标准) …...
由麻省理工学院计算机科学与人工智能实验室等机构创建低成本、高效率的物理驱动数据生成框架,助力接触丰富的机器人操作任务
2025-02-28,由麻省理工学院计算机科学与人工智能实验室(CSAIL)和机器人与人工智能研究所的研究团队创建了一种低成本的数据生成框架,通过结合物理模拟、人类演示和基于模型的规划,高效生成大规模、高质量的接触丰富型机…...

【RAG从入门到精通系列】【RAG From Scratch 系列教程2:Query Transformations】
目录 前言一、概述1-1、RAG概念1-2、前置知识1-2-1、ModelScopeEmbeddings 词嵌入模型1-2-2、FAISS介绍&安装 (向量相似性搜索)1-2-3、Tiktoken 分词工具 二、Rag From Scratch:Query Transformations2-1、前置环境安装2-2、多查询检索器2-2-1、加载网页内容2-2…...

通过RK3588的cc-linaro-7.5.0交叉编译器搭建QT交叉编译环境QtCreator(无需编译QT源码)
当我们需要给新的电脑上部署RK3588的QT交叉编译环境时,我们可以将旧电脑上的编译好的qmake直接拷贝到新电脑上并配置好环境。 一、开发环境 1、ubuntu20.04 2、qt5.14.2 3、交叉编译器gcc-linaro-7.5.0 4、已编译好的qt交叉编译器 二、资料下载 链接: https:…...

前端基础之消息订阅与发布
需要下载npm I pubsub-js 在Student.vue中发送数据 <template> <div class"demo"> <h2 class"title">学生姓名:{{name}}</h2> <h2>学生性别:{{sex}}</h2> <button click"sendStudentName">将学生名给…...

51c自动驾驶~合集53
我自己的原文哦~ https://blog.51cto.com/whaosoft/13431196 #DriveTransformer 上交提出:以Decoder为核心的大一统架构写在前面 & 笔者的个人理解 当前端到端自动驾驶架构的串行设计导致训练稳定性问题,而且高度依赖于BEV,严重限…...

CS144 Lab Checkpoint 0: networking warm up
Set up GNU/Linux on your computer 我用的是Ubuntu,按照指导书上写的输入如下命令安装所需的软件包: sudo apt update && sudo apt install git cmake gdb build-essential clang \ clang-tidy clang-format gcc-doc pkg-config glibc-doc tc…...

Spring WebFlux 中 WebSocket 使用 DataBuffer 的注意事项
以下是修改后的完整文档,包含在多个多线程环境中使用 retain() 和 release() 方法的示例,且确保在 finally 块中调用 release(): 在 Spring WebFlux 中,WebSocketMessage 主要用于表示 WebSocket 的消息载体,其中 getP…...

Android ChatOn-v1.66.536-598-[构建于ChatGPT和GPT-4o之上]
ChatOn 链接:https://pan.xunlei.com/s/VOKYnq-i3C83CK-HJ1gfLf4gA1?pwdwzwc# 添加了最大无限积分 删除了所有调试信息 语言:全语言支持...

游戏树搜索与优化策略:Alpha-Beta剪枝及其实例分析
1.Alpha-Beta搜索 Alpha-Beta 搜索是一种用于对抗性游戏(比如象棋、围棋)的智能算法,目的是帮助计算机快速找到“最优走法”,同时避免不必要的计算。它的核心思想是:通过剪掉明显糟糕的分支,大幅减少需要计…...
基于Qwen-VL的手机智能体开发
先上Demo: vl_agent_demo 代码如下: 0 设置工作目录: 你的工作目录需要如下: 其中utils文件夹和qwenvl_agent.py均参考自 GitHub - QwenLM/Qwen2.5-VL: Qwen2.5-VL is the multimodal large language model series developed by …...

记录一次Spring事务失效导致的生产问题
一、背景介绍 公司做的是“聚合支付”业务,对接了微信、和包、数字人民币等等多家支付机构,我们提供统一的支付、退款、自动扣款签约、解约等能力给全国的省公司、机构、商户等。 同时,需要做对账功能,即支付机构将对账文件给到…...

深度学习实战:用TensorFlow构建高效CNN的完整指南
一、为什么每个开发者都要掌握CNN? 在自动驾驶汽车识别路标的0.1秒里,在医疗AI诊断肺部CT片的精准分析中,甚至在手机相册自动分类宠物的日常场景里,卷积神经网络(CNN)正悄然改变着我们的世界。本文将以工业…...