torch.einsum 的 10 个常见用法详解以及多头注意力实现
torch.einsum 是 PyTorch 提供的一个高效的张量运算函数,能够用紧凑的 Einstein Summation 约定(Einstein Summation Convention, Einsum)描述复杂的张量操作,例如矩阵乘法、转置、内积、外积、批量矩阵乘法等。
1. 基本语法
torch.einsum(equation, *operands)
• equation:爱因斯坦求和表示法的字符串,例如 “ij,jk->ik”
• operands:参与计算的张量,可以是多个
2. 基本概念
Einsum 使用 -> 将输入与输出模式分开:
• 左侧:表示输入张量的索引
• 右侧:表示输出张量的索引
• 省略求和索引:会自动对省略的索引进行求和(即 Einstein Summation 规则)
3. torch.einsum 的 10 个常见用法
(1) 矩阵乘法 (torch.mm)
import torchA = torch.randn(2, 3)
B = torch.randn(3, 4)C = torch.einsum("ij,jk->ik", A, B) # 矩阵乘法
print(C.shape) # torch.Size([2, 4])
解析:
• ij 表示 A 的形状 (2,3)
• jk 表示 B 的形状 (3,4)
• 由于 j 在 -> 右侧没有出现,因此对其求和,最终得到形状 (2,4)
(2) 向量点积 (torch.dot)
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])dot_product = torch.einsum("i,i->", a, b) # 向量点积
print(dot_product) # 输出: 32
解析:
• i,i-> 代表对应位置相乘并求和,等价于 torch.dot(a, b)
(3) 矩阵转置 (torch.transpose)
A = torch.randn(2, 3)A_T = torch.einsum("ij->ji", A) # 矩阵转置
print(A_T.shape) # torch.Size([3, 2])
解析:
• ij->ji 交换 i 和 j 维度,相当于 A.T
(4) 矩阵外积 (torch.outer)
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])outer_product = torch.einsum("i,j->ij", a, b) # 外积
print(outer_product)
# tensor([[ 4, 5, 6],
# [ 8, 10, 12],
# [12, 15, 18]])
解析:
• i,j->ij 生成形状 (3,3) 的矩阵
(5) 批量矩阵乘法 (torch.bmm)
A = torch.randn(5, 2, 3)
B = torch.randn(5, 3, 4)C = torch.einsum("bij,bjk->bik", A, B) # 批量矩阵乘法
print(C.shape) # torch.Size([5, 2, 4])
解析:
• b 代表 batch 维度,不求和,保持
• j 出现在两个输入中但未出现在输出中,所以对其求和
(6) 计算均值 (torch.mean)
A = torch.randn(3, 4)mean_A = torch.einsum("ij->", A) / A.numel() # 计算均值
print(mean_A)
解析:
• ij-> 表示所有元素求和
• A.numel() 是总元素数,等价于 torch.mean(A)
(7) 计算范数 (torch.norm)
A = torch.randn(3, 4)norm_A = torch.einsum("ij,ij->", A, A).sqrt() # Frobenius 范数
print(norm_A)
解析:
• ij,ij-> 表示 A 的所有元素平方求和
• .sqrt() 计算范数
(8) 计算 Softmax
A = torch.randn(3, 4)softmax_A = torch.einsum("ij->ij", torch.exp(A)) / torch.einsum("ij->i1", torch.exp(A))
print(softmax_A)
解析:
• torch.exp(A) 计算指数
• torch.einsum(“ij->i1”, torch.exp(A)) 计算行和
(9) 对角线提取 (torch.diagonal)
A = torch.randn(3, 3)diag_A = torch.einsum("ii->i", A) # 提取主对角线
print(diag_A)
解析:
• ii->i 只保留对角线元素,等价于 torch.diagonal(A)
(10) 计算张量 Hadamard 积(逐元素乘法)
A = torch.randn(3, 4)
B = torch.randn(3, 4)hadamard_product = torch.einsum("ij,ij->ij", A, B) # 逐元素乘法
print(hadamard_product)
解析:
• ij,ij->ij 表示对相同索引位置元素相乘
总结
| Einsum 公式 | 作用 | 等价 PyTorch 代码 |
|---|---|---|
ij,jk->ik | 矩阵乘法 | torch.mm(A, B) |
i,i-> | 向量点积 | torch.dot(a, b) |
i,j->ji | 矩阵转置 | A.T |
bij,bjk->bik | 批量矩阵乘法 | torch.bmm(A, B) |
ii-> | 提取对角线 | torch.diagonal(A) |
ij-> | 矩阵所有元素求和 | A.sum() |
ij,ij->ij | Hadamard 乘法 | A * B |
ij,ij-> | Frobenius 范数的平方 | (A**2).sum() |
使用 torch.einsum 计算多头注意力中的点积相似性
下面的代码示例演示如何使用 PyTorch 的 torch.einsum 函数来计算 Transformer 多头注意力机制中的点积注意力分数和输出。代码包含以下步骤:
1. 定义输入 Q, K, V:随机初始化查询(Query)、键(Key)、值(Value)张量,形状符合多头注意力的规范(包含 batch 维度和多头维度)。
2. 计算 QK^T / sqrt(d_k):使用 torch.einsum 计算每个注意力头的 Q 与 K 转置的点积相似性,并除以 d k \sqrt{d_k} dk(注意力头维度的平方根)进行缩放。
3. 计算 softmax 注意力权重:对第2步得到的相似性分数应用 softmax(在最后一个维度上),得到注意力权重分布。
4. 计算最终的注意力输出:将 softmax 得到的注意力权重与值 V 相乘(加权求和)得到每个头的输出。
5. 完整代码注释:代码中包含详尽的注释,解释每一步的用途。
6. 可视化注意力权重:使用 Matplotlib 可视化一个头的注意力权重矩阵,以便更好地理解注意力分布。
7. 具体参数设置:在代码开头指定 batch_size、sequence_length、embedding_dim、num_heads 等参数,便于调整。
import torch
import torch.nn.functional as F
import math
import numpy as np
import matplotlib.pyplot as plt# 7. 参数设置:定义 batch 大小、序列长度、嵌入维度、注意力头数等
batch_size = 2 # 批处理大小
sequence_length = 5 # 序列长度(假设查询和键序列长度相同)
embedding_dim = 16 # 整体嵌入维度(embedding维度)
num_heads = 4 # 注意力头数量
head_dim = embedding_dim // num_heads # 每个注意力头的维度 d_k(需保证能够整除)# 1. 定义输入 Q, K, V 张量(随机初始化)
# 形状约定:[batch_size, num_heads, seq_len, head_dim]
Q = torch.randn(batch_size, num_heads, sequence_length, head_dim)
K = torch.randn(batch_size, num_heads, sequence_length, head_dim)
V = torch.randn(batch_size, num_heads, sequence_length, head_dim)# 打印 Q, K, V 的形状以验证
print("Q shape:", Q.shape) # 预期: (batch_size, num_heads, sequence_length, head_dim)
print("K shape:", K.shape) # 预期: (batch_size, num_heads, sequence_length, head_dim)
print("V shape:", V.shape) # 预期: (batch_size, num_heads, sequence_length, head_dim)# 2. 计算 QK^T / sqrt(d_k)
# 使用 torch.einsum 进行张量乘法:
# 'b h q d, b h k d -> b h q k' 表示:
# - b: batch维度
# - h: 多头维度
# - q: 查询序列长度维度
# - k: 键序列长度维度
# - d: 每个头的维度(将对该维度进行求和,相当于点积)
# Q 的形状是 [b, h, q, d],K 的形状是 [b, h, k, d]。
# einsum 根据 'd' 维度对 Q 和 K 相乘并求和,输出形状 [b, h, q, k],即每个头的 Q 与每个 K 的点积。
scores = torch.einsum('b h q d, b h k d -> b h q k', Q, K) # 点积 Q * K^T (尚未除以 sqrt(d_k))
scores = scores / math.sqrt(head_dim) # 缩放除以 sqrt(d_k)# 3. 计算 softmax 注意力权重
# 对最后一个维度 k 应用 softmax,得到注意力权重矩阵 (对每个 query位置,在所有 key位置上的权重分布和为1)
attention_weights = F.softmax(scores, dim=-1)# 打印注意力权重矩阵的形状以验证
print("Attention weights shape:", attention_weights.shape) # 预期: (batch_size, num_heads, seq_len, seq_len)# 4. 计算最终的注意力输出
# 将注意力权重矩阵与值 V 相乘,得到每个查询位置的加权值。
# 我们再次使用 einsum:
# 'b h q k, b h k d -> b h q d' 表示:
# - 将 attention_weights [b, h, q, k] 与 V [b, h, k, d] 在 k 维相乘并对 k 求和,
# 得到输出形状 [b, h, q, d](每个头针对每个查询位置输出一个长度为d的向量)。
attention_output = torch.einsum('b h q k, b h k d -> b h q d', attention_weights, V)# (可选)如果需要将多头的输出合并为一个张量,可以进一步 reshape/transpose
# 并通过线性层投影。但这里我们仅关注多头内部的注意力计算。
# 合并示例: 将 out 从 [b, h, q, d] 变形为 [b, q, h*d],再通过线性层投影回 [b, q, embedding_dim]。
combined_output = attention_output.permute(0, 2, 1, 3).reshape(batch_size, sequence_length, -1)
# 上面这行代码将 [b, h, q, d] 先变为 [b, q, h, d],再合并h和d维度为[h*d]。
print("Combined output shape (after concatenating heads):", combined_output.shape)
# 注意:combined_output 的最后一维大小应当等于 embedding_dim(num_heads * head_dim)。# 打印一个注意力输出张量的示例值(比如第一个 batch,第一头,第一查询位置的输出向量)
print("Sample attention output (batch 0, head 0, query 0):", attention_output[0, 0, 0])# 5. 完整代码注释已在上方各步骤体现。# 6. 可视化注意力权重
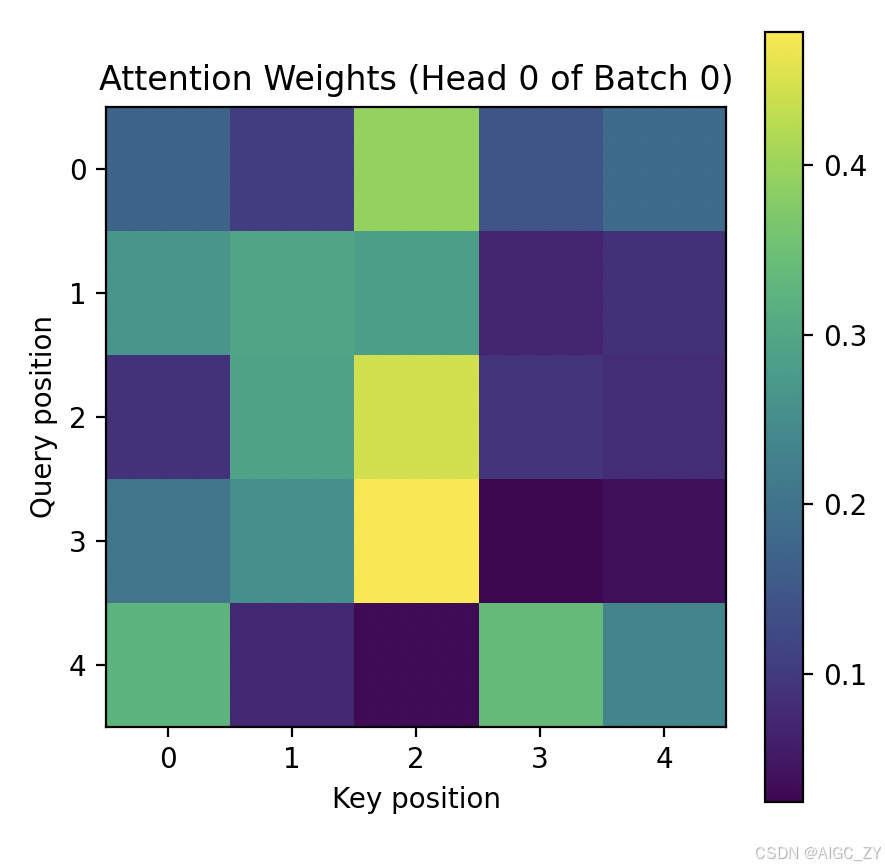
# 我们以第一个样本(batch 0)的第一个注意力头(head 0)的注意力权重矩阵为例进行可视化。
# 这个矩阵形状为 [seq_len, seq_len],其中每行表示查询位置,每列表示键位置。
attn_matrix = attention_weights[0, 0].detach().numpy() # 取出 batch 0, head 0 的注意力权重矩阵并转换为 numpyplt.figure(figsize=(5,5))
plt.imshow(attn_matrix, cmap='viridis', origin='upper')
plt.colorbar()
plt.title("Attention Weights (Head 0 of Batch 0)")
plt.xlabel("Key position")
plt.ylabel("Query position")
plt.show()
运行上述代码后,您将看到打印的张量形状和示例值,以及一幅可视化的注意力权重热力图。图中纵轴为查询序列的位置,横轴为键序列的位置,颜色越亮表示注意力权重越高。通过该示例,您可以直观理解多头注意力机制中各查询对不同键“关注”的程度。
输出:
Q shape: torch.Size([2, 4, 5, 4])
K shape: torch.Size([2, 4, 5, 4])
V shape: torch.Size([2, 4, 5, 4])
Attention weights shape: torch.Size([2, 4, 5, 5])
Combined output shape (after concatenating heads): torch.Size([2, 5, 16])
Sample attention output (batch 0, head 0, query 0): tensor([-0.8224, -1.1715, -0.0423, -0.0106])
多头部分的计算:
import torch# 定义多头注意力机制的点积计算函数
def compute_attention_scores(queries, keys):# 计算点积相似性分数energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])return energy# 示例数据
N = 1 # 批次大小
q = 2 # 查询序列长度
k = 3 # 键序列长度
h = 2 # 注意力头数量
d = 4 # 每个注意力头的维度# 随机生成 queries 和 keys
queries = torch.rand((N, q, h, d)) # Shape (1, 2, 2, 4)
keys = torch.rand((N, k, h, d)) # Shape (1, 3, 2, 4)# 计算注意力分数
energy = compute_attention_scores(queries, keys)print("Energy shape:", energy.shape)
print(energy)输出
# Energy shape: torch.Size([1, 2, 2, 3])
# tensor([[[[0.7102, 0.3867, 0.5860],
# [0.9586, 0.5920, 0.6626]],# [[1.3163, 0.9486, 0.5482],
# [1.0403, 0.4555, 0.3656]]]])
更多资料:
torch.einsum用法详解
多头注意力:torch.einsum详解
一文学会 Pytorch 中的 einsum
Python广播机制
相关文章:
torch.einsum 的 10 个常见用法详解以及多头注意力实现
torch.einsum 是 PyTorch 提供的一个高效的张量运算函数,能够用紧凑的 Einstein Summation 约定(Einstein Summation Convention, Einsum)描述复杂的张量操作,例如矩阵乘法、转置、内积、外积、批量矩阵乘法等。 1. 基本语法 tor…...

【DeepSeek】一文详解GRPO算法——为什么能减少大模型训练资源?
GRPO,一种新的强化学习方法,是DeepSeek R1使用到的训练方法。 今天的这篇博客文章,笔者会从零开始,层层递进地为各位介绍一种在强化学习中极具实用价值的技术——GRPO(Group Relative Policy Optimization)…...

C++基础系列【19】运算符重载
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...
 Flume传输数据到Kafka)
大数据环境(单机版) Flume传输数据到Kafka
文章目录 前言一、准备二、安装三、配置环境变量四、修改配置4.1、kafka配置4.2、Flume配置 五、启动程序5.1、启动zk5.2、启动kafka5.3、启动flume 六、测试6.1、启动一个kafka终端,用来消费消息6.2、写入日志 其他 前言 flume监控指定目录,传输数据到…...

Ollama 框架本地部署教程:开源定制,为AI 项目打造专属解决方案!
Ollama 是一款开源的本地大语言模型(LLM)运行框架,用于管理和运行语言模型。具有以下核心特点: 开源可定制:采用 MIT 开源协议,开发者能自由使用、阅读源码并定制,可根据自身需求进行功能扩展和…...

开发环境搭建-03.后端环境搭建-使用Git进行版本控制
一.Git进行版本控制 我们对项目开发就会产生很多代码,我们需要有效的将这些代码管理起来,因此我们真正开发代码前需要把我们的Git环境搭建好。通过Git来管理我们项目的版本,进而实现版本控制。 首先我们使用Git创建本地仓库,然后…...

[Lc(2)滑动窗口_1] 长度最小的数组 | 无重复字符的最长子串 | 最大连续1的个数 III | 将 x 减到 0 的最小操作数
目录 1. 长度最小的字数组 题解 代码 ⭕2.无重复字符的最长子串 题解 代码 3.最大连续1的个数 III 题解 代码 4.将 x 减到 0 的最小操作数 题解 代码 1. 长度最小的字数组 题目链接:209.长度最小的字数组 题目分析: 给定一个含有 n 个 正整数 的数组…...

互联网时代如何保证数字足迹的安全,以防个人信息泄露?
用户在网络上所做的几乎所有事情,包括浏览、社交媒体活动、搜索查询、在线订阅,甚至购物,都会留下一条数据线索,这些数据可用于创建用户在线身份的详细档案。如果这些信息暴露,恶意行为者可能会利用它们将用户置于各种…...

海康摄像头接入流媒体服务器实现https域名代理播放
环境 操作系统:Ubuntu 22.04流媒体服务器:srs 官网安装教程srs开启GB28181协议 官网开启教程进行海康摄像头的配置 官网配置教程srs使用systemctl实现开机自启 官网配置教程 nginx配置说明 server {listen 80;server_name a.com;return 301 https://$…...
)
【C++设计模式】第五篇:原型模式(Prototype)
注意:复现代码时,确保 VS2022 使用 C17/20 标准以支持现代特性。 克隆对象的效率革命 1. 模式定义与用途 核心思想 原型模式:通过复制现有对象(原型)来创建新对象,而非通过new构造。关键用…...

51单片机课综合项目
1、按键控制蜂鸣器实验 1、实验现象:下载程序后,按下K1键蜂鸣器发声一次,按下K2键,蜂鸣器连续发声,再次按下K2键,发声取消 2、使用到的外设模块:蜂鸣器模块beep 独立按键模块 key 3、编程框架(…...

【最大半连通子图——tarjan求最大连通分量,拓扑排序,树形DP】
题目 分析 最大连通分量肯定是满足半连通分量的要求,因此tarjan。 同时为了简化图,我们进行缩点,图一定变为拓扑图。 我们很容易看出,只要是一条不分叉的链,是满足条件的。 于是我们按照拓扑序不断树形DP 建边注意…...

一周学会Flask3 Python Web开发-在模板中渲染WTForms表单视图函数里获取表单数据
锋哥原创的Flask3 Python Web开发 Flask3视频教程: 2025版 Flask3 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 为了能够在模板中渲染表单,我们需要把表单类实例传入模板。首先在视图函数里实例化表单类LoginForm,然…...

DeepSeek R1助力,腾讯AI代码助手解锁音乐创作新
目录 1. DeepSeekR1模型简介2. 歌词创作流程2.1 准备工作2.2 歌词生成技巧 3. 音乐制作环节3.1 主流AI音乐生成平台 4. 歌曲欣赏5. 总结展望 1. DeepSeekR1模型简介 腾讯AI代码助手最新推出的DeepSeekR1模型不仅在代码生成方面表现出色,其强大的自然语言处理能力也…...

用户空间与内核空间切换机制详解
用户空间与内核空间切换机制详解 一、切换触发条件 用户态与内核态的切换由以下三类事件触发: 系统调用 用户程序主动通过int 0x80(x86)或ecall(RISC-V)等指令发起系统调用,请求内核服务(如文件读写、进程创建等)。此时CPU自动进入内核态处理请求,完成后返回用户…...

【微信小程序】每日心情笔记
个人团队的比赛项目,仅供学习交流使用 一、项目基本介绍 1. 项目简介 一款基于微信小程序的轻量化笔记工具,旨在帮助用户通过记录每日心情和事件,更好地管理情绪和生活。用户可以根据日期和心情分类(如开心、平静、难过等&#…...

为AI聊天工具添加一个知识系统 之135 详细设计之76 通用编程语言 之6
本文要点 要点 通用编程语言设计 本设计通过三级符号系统的动态映射与静态验证的有机结合,实现了从文化表达到硬件优化的全链路支持。每个设计决策均可在[用户原始讨论]中找到对应依据,包括: 三级冒号语法 → 提升文化符号可读性圣灵三角…...

前端基础之组件
组件:实现应用中局部功能代码和资源的集合 非单文件组件 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"…...

spring boot整合flyway实现数据的动态维护
1、简单介绍一下flyway Flyway 是一款开源的数据库版本控制工具,主要用于管理数据库结构的变更(如创建表、修改字段、插入数据等)。它通过跟踪和执行版本化的迁移脚本,帮助团队实现数据库变更的自动化。接下来简单介绍一下flyway…...

通往 AI 之路:Python 机器学习入门-线性代数
2.1 线性代数(机器学习的核心) 线性代数是机器学习的基础之一,许多核心算法都依赖矩阵运算。本章将介绍线性代数中的基本概念,包括标量、向量、矩阵、矩阵运算、特征值与特征向量,以及奇异值分解(SVD&…...

Matlab中的均值函数mean
今天调了一个代码里的bug,根源居然是mean函数的使用细节没留意到~ 具体来说,写一个类似k均值聚类那样的程序,交替迭代,其中有一部是使用mean求一堆向量的均值,这些向量存在一个矩阵里,每行对应一个向量。若…...

数据结构知识学习小结
一、动态内存分配基本步骤 1、内存分配简单示例: 个人对于示例的理解: 定义一个整型的指针变量p(着重认为它是一个“变量”我觉得可能会更好理解),这个变量用来存地址的,而不是“值”,malloc函…...

高精算法的用法及其优势
高精度问题是指当数据的位数非常大(超出标准数据类型的范围)时,如何进行计算和存储的问题。常见场景包括大整数的加、减、乘、除、取模等操作。以下是解决高精度问题的常用方法与技巧: 一、数据存储 数组存储 用整型数组存储&am…...

【Spring AOP】_切点类的切点表达式
目录 1. 根据方法签名匹配编写切点表达式 1.1 具体语法 1.2 通配符表达规范 2. 根据注解匹配编写切点表达式 2.1 实现步骤 2.2 元注解及其常用取值含义 2.3 使用自定义注解 2.3.1 编写自定义注解MyAspect 2.3.2 编写切面类MyAspectDemo 2.3.3 编写测试类及测试方法 在…...

多线程-定时任务线程池源码
定时任务线程池 ScheduledThreadPoolExecutor,可以执行定时任务的线程池。这里学习它的基本原理。 定时任务线程池,和普通线程池不同的地方在于,它使用一个延迟队列,延迟队列使用最小堆作为它的数据结构,它会按照任务…...

初次使用 IDE 搭配 Lombok 注解的配置
前言 在 Java 开发的漫漫征程中,我们总会遇到各种提升效率的工具。Lombok 便是其中一款能让代码编写变得更加简洁高效的神奇库。它通过注解的方式,巧妙地在编译阶段为我们生成那些繁琐的样板代码,比如 getter、setter、构造函数等。然而&…...

云服数据存储接口:CloudSever
云服数据存储接口:CloudSever 迷你世界 更新时间: 2024-04-28 19:09:10 具体函数名及描述如下: 序号 函数名 函数描述 1 setOrderDataBykey(...) 设置排行榜中指定键的数值 2 removeOrderDataByKey(...) 删除排行榜中指定键的数值 …...

关于 QPalette设置按钮背景未显示出来 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/146047054 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

上传文件到对象存储是选择前端还是后端
对于云上对象存储的上传方式选择(前端直传或后端代理上传),需综合考虑安全性、性能、成本、业务需求等因素。 1. 推荐前端直传的场景 适用条件: 大文件上传(如视频、大型数据集)高并发场景(如…...

mysql下载与安装
一、mysql下载: MySQL获取: 官网:www.mysql.com 也可以从Oracle官方进入:https://www.oracle.com/ 下载地址:https://downloads.mysql.com/archives/community/ 选择对应的版本和对应的操作系统ÿ…...