爬虫(持续更新ing)
爬虫(持续更新ing)
# 网络请求
# url统一资源定位符(如:https://www.baidu.com)
# 请求过程:客户端的web浏览器向服务器发起请求
# 请求又分为四部分:请求网址,请求方法(get、post、put等),请求头,请求体
# 浏览器中一般都在f12中去看,推荐谷歌会清晰一点
# 爬虫概念:模拟浏览器发送请求获取响应
# 反爬概念:保护重要数据,阻止恶意网络攻击
# 反反爬:针对反爬做防御措施
# 爬虫的作用:1、数据采集 2、软件测试 3、抢票 4、网络安全 5、web漏洞扫描
# 通过爬取网站的数量分类:通用爬虫(如搜索引擎)、聚焦爬虫(如12306抢票)就是专门爬某个网站的数据, 通用爬虫爬取网站数量没有上线,聚焦爬虫:爬取网站数量有限,有明确目标
# 聚焦爬虫根据获取数据为目的分类:功能性爬虫、数据增量爬虫 功能性爬虫不获取数据,只为了实现某种功能,如投票、抢票、短信轰炸等 数据增量爬虫获取数据用于后续分析,url与数据同时变化,则整条新数据,url不变,数据变化,数据部分更新
# 爬虫基本流程:url->对url发送网络请求,获取浏览器的请求响应->解析响应,提取数据->保存数据
# robots协议,有些时候无法获取时,可以修改robots# 网络通信
# 浏览器:url
# DNS服务器:ip地址标注服务器
# DNS服务器返回ip地址给浏览器
# 浏览器拿到ip地址去访问服务器,返回响应
# 服务器返回的数据可能是js,hmtl,jpg等等
# 网络通信的实际原理:一个请求对一个数据包(文件)
# 之后抓包可能会有很多个数据包,共同组成了这个页面# http协议和https协议
# http协议规定了服务器和客户端互相通信的规则
# http协议:超文本传输协议,默认端口80
# 超文本:不仅仅限于文本,还可以是图片、音频、视频
# 传输协议:使用共用约定的固定格式来传递换成字符串的超文本内容
# https协议:http+ssl(安全套接字层) 默认端口443
# ssl对传输内容进行加密
# https比http更安全,但是性能更低
# http请求/响应的步骤:1、客户端连接web服务器 2、发送http请求 3、服务器接收请求返回响应 4、释放连接tcp连接 5、客户端解析html内容# 请求头
# 请求方式 get/post、put等
# get一般来说都是想服务器要数据的详情接口,而post一般是给服务器数据,提交接口
# user-agent:这个是模拟正常用户的操作关键
# cookies:这个是登录保持,一般老一点的网站用这个,新的都用token
# referer:当前这一次请求是从哪个请求过来的
request模块
# 依赖安装 pip install requests
# 文本,html,css等字符串形式
import requests
url='https://www.baidu.com'
res=requests.get(url)
# text 这个方式内容会乱码,str类型,request模块自动根据http头部对响应编码做出有根据的推测
# res.encoding='utf-8' 当然你也可以指定编码类型
# print(res.text)
# content bytes类型,可以通过decode进行解码 打印响应,这个是解码后的,默认进行utf-8
print(res.content.decode())
# 这个就是把这个内容保存为html
# with open('baidu.html','w',encoding='utf-8') as h:
# h.write(res.content.decode())
#输出 这样就把所有的https://www.baidu.com请求拿到了
# 打印响应的url
print('url',res.url)
# 打印响应对象的请求头
print('request headers',res.request.headers)
# 打印响应头
print('res headers',res.headers)# 图片 把图片存到img下面
import requests
url='https://www.baidu.com/img/flexible/logo/pc/result.png'
res=requests.get(url)
with open('./img/jwq.png','wb') as img:img.write(res.content)# 模拟浏览器发送请求
import requests
url='https://www.baidu.com'
# 构建请求头 user-agent添加的目的是为了让服务器认为我们是浏览器发送的请求,而不是爬虫软件
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'
}
# headers参数接收字典形式的请求头
res=requests.get(url,headers=headers)
print(res.content.decode())
print(len(res.content.decode())) #查看这个响应内容的长度
print(res.request.headers) #查看响应对象的请求头# user-agent池 为了防止反爬
# 先演示手动添加的user_agents池
import requests
import random
url='https://www.baidu.com'
# 构建 user_agents池
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60','Opera/8.0 (Windows NT 5.1; U; en)','Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0','Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11','Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) ',
]
ua=random.choice(user_agents)
# 构建请求头 user-agent添加的目的是为了让服务器认为我们是浏览器发送的请求,而不是爬虫软件
headers={'user-agent':ua
}
# headers参数接收字典形式的请求头
res=requests.get(url,headers=headers)
# print(res.content.decode())
print(len(res.content.decode()))
print(res.request.headers)# 使用三方库 fake-useragent
# 安装 pip install fake-useragent
from fake_useragent import UserAgent
# 构建 user_agents池
ua = UserAgent()
# 获取随机浏览器用户代理字符串
print(ua.random)# 使用param携带参数 quote 明文转密文 unquote 密文转明文
import requests
from fake_useragent import UserAgent
from urllib.parse import quote,unquote
# quote 明文转密文
# unquote 密文转明文
# print(quote('学习'))
# print(unquote('%E5%AD%A6%E4%B9%A0'))
# 构建 user_agents池
ua = UserAgent()
url='https://www.baidu.com/s'
# 你要是不想使用params的话,你可以使用模板语法
# url=f'https://www.baidu.com/s?wd={name}'
#构建请求参数
name=input('请输入关键词:')
params={'wd':name
}
headers={'user-agent':ua.random
}
# 通过params携带参数
res=requests.get(url,headers=headers,params=params)
print(res.content.decode())# 获取网易云的图片
import requests
from fake_useragent import UserAgent
ua = UserAgent()
url='https://p1.music.126.net/_JcHT6u-TYhxjDbO3IhVQA==/109951170537166630.jpg?imageView&quality=89'
headers={# 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36''user-agent':ua.random
}
# 通过params携带参数
res=requests.get(url,headers=headers)
# print(res.content.decode())
with open('img/网易云.jpg','wb') as f:f.write(res.content)# 获取qq音乐音频
import requests
from fake_useragent import UserAgent
ua = UserAgent()
url='https://ws6.stream.qqmusic.qq.com/RS02064dfdIM38rSZY.mp3?guid=7976864250&vkey=AE4590431EAD34766DBAA9BA1A3715B3B45721EE23180669EA694EB7CA1F0DB4C8DE867A9883D4E897ED4E6F2ECF600CDFD34C78F2C07E09__v215192d1e&uin=554242051&fromtag=120052'
headers={# 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36''user-agent':ua.random
}
# 通过params携带参数
res=requests.get(url,headers=headers)
# print(res.content.decode())
with open('video/晴天.mp3','wb') as f:f.write(res.content)# 获取qq音乐mv
import requests
from fake_useragent import UserAgent
ua = UserAgent()
url='https://mv6.music.tc.qq.com/44B177558A20632E722F75FB6A67025F0BFC15AB98CC0B58FD3FC79E00B2EEDC9FAC3DF26DD0A319EACA6B2A30D24E2CZZqqmusic_default__v21ea05e5a/qmmv_0b53feaagaaao4ae4d5t4vtvikiaamuqaa2a.f9944.ts'
headers={# 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36''user-agent':ua.random
}
# 通过params携带参数
res=requests.get(url,headers=headers)
# print(res.content.decode())
with open('video/qq音乐.mp4','wb') as f:f.write(res.content)# 获取百度贴吧 翻页
import requests
from fake_useragent import UserAgent
ua = UserAgent()
url='https://tieba.baidu.com/f?'
name=input('请输入关键词:')
page=int(input('请输入要保存的页数:'))
for i in range(page):params = {'kw': name,'ie': 'utf-8','pn': 0}headers = {'user-agent': ua.random}# 通过params携带参数res = requests.get(url, headers=headers,params=params)# print(res.content.decode())with open(f'html/{name}{i+1}.html', 'wb') as f:f.write(res.content)# 获取百度贴吧转换为面向对象方式
import requests
from fake_useragent import UserAgent
class TieBa:def __init__(self):self.url='https://tieba.baidu.com/f?'self.headers = {'user-agent': UserAgent().random}# 发起请求def send(self,params):# 通过params携带参数res = requests.get(self.url, headers=self.headers,params=params)return res.text# 保存def save(self,page,con):with open(f'html/{page}.html', 'w',encoding='utf-8') as f:f.write(con)# 程序运行def run(self):name = input('请输入关键词:')pages = int(input('请输入要保存的页数:'))for page in range(pages):params = {'kw': name,'ie': 'utf-8','pn': pages * 50}data=self.send(params)self.save(page,data)
te =TieBa()
te.run()# 金山翻译 post
import requests
from fake_useragent import UserAgent
import jsonurl = 'https://ifanyi.iciba.com/index.php?c=trans'
headers = {'user-agent': UserAgent().random
}
name=input('请输入翻译内容:')
post_data = {'from': 'zh','to': 'en','q': name,
}
res = requests.post(url, headers=headers,data=post_data)
res.encoding = 'utf-8'
dict=json.loads(res.text)
print(dict['out'])# 下面就是中文的翻译
#输入 请输入翻译内容:中文
#输出 the Chinese language# 代理
# 分为正向代理和反向代理
# 正向代理:给客户端做代理,让服务器不知道客户端的真实身份(说句实在话就是保护自己的ip不会暴露,要封也是封代理ip)
# 反向代理:给服务器做代理,让浏览器不知道服务器的真实地址
# 正向代理保护客户端,反向代理保护服务端
# 实际上理论应该分为三类:透明代理(服务器知道我们使用了代理ip,也知道真实ip)、匿名代理(服务器能够检测到代理ip,但是无法知道真实ip)、高匿代理(服务器既不知代理ip,也不知道真实ip)
# proxies代理
import requests
from fake_useragent import UserAgent
url='https://www.baidu.com'
headers={'user-agent':UserAgent().random
}
# 构建代理字典
proxies={'http':'1.1.1.1:9527','https':'1.1.1.1:9527'
}
res=requests.get(url,headers=headers,proxies=proxies)
print(res.content.decode())
相关文章:
)
爬虫(持续更新ing)
爬虫(持续更新ing) # 网络请求 # url统一资源定位符(如:https://www.baidu.com) # 请求过程:客户端的web浏览器向服务器发起请求 # 请求又分为四部分:请求网址,请求方法(…...
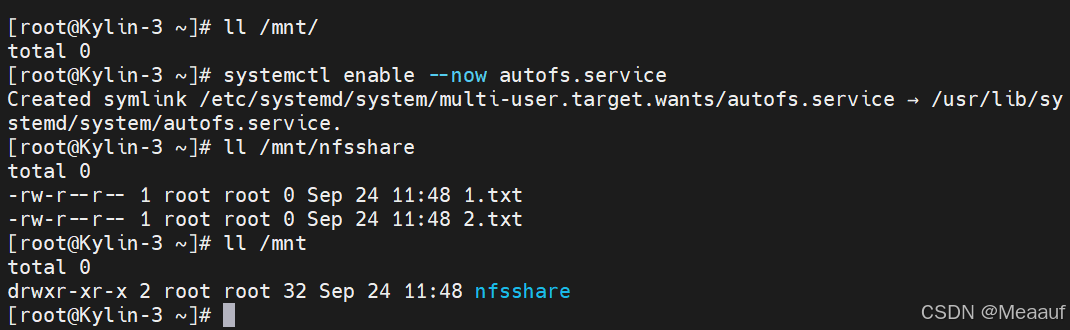
Kylin麒麟操作系统服务部署 | NFS服务部署
以下所使用的环境为: 虚拟化软件:VMware Workstation 17 Pro 麒麟系统版本:Kylin-Server-V10-SP3-2403-Release-20240426-x86_64 一、 NFS服务概述 NFS(Network File System),即网络文件系统。是一种使用于…...

如何配置虚拟机IP?
以下是在虚拟机中配置IP地址的一般步骤,以常见的Linux虚拟机为例: 查看当前网络配置 使用命令 ifconfig 或 ip addr show 查看当前虚拟机的网络接口及相关配置信息,确定要配置IP的网络接口名称,如 eth0 或 ens33 等。 编辑网…...

十一、Spring Boot:使用JWT实现用户认证深度解析
Spring Boot JWT(JSON Web Token):无状态认证 在现代 Web 开发中,无状态认证是一种重要的安全机制,它允许服务器在不存储会话信息的情况下验证用户身份。JSON Web Token(JWT)是一种常用的无状态…...

涨薪技术|持续集成Git使用详解
Git介绍 Git 是一个开源的分布式版本控制系统,用以有效、高速的处理从很小到非常大的项目版本管理。 Git 的特点: 分支更快、更容易。 支持离线工作;本地提交可以稍后提交到服务器上。 Git 提交都是原子的,且是整个项目范围的,…...

批量对 Word 优化与压缩,减少 Word 文件大小
在编辑 Word 文档的时候,我们通常会插入一些图片或者一些样式,这可能会导致 Word 文档的体积变得非常的庞大,不利于我们对 Word 文档进行分享、传输或者存档等操作,因此我们通常会碰到需要优化或者压缩 Word 文档的需求。那如何才…...

CSS定位详解上
1. 相对定位 1.1 如何设置相对定位? 给元素设置 position:relative 即可实现相对定位。 可以使用 left 、 right 、 top 、 bottom 四个属性调整位置。 1.2 相对定位的参考点在哪里? 相对自己原来的位置 1.3 相对定位的特点࿱…...

DeepSeek、Grok 和 ChatGPT 对比分析:从技术与应用场景的角度深入探讨
文章目录 一、DeepSeek:知识图谱与高效信息检索1. 核心技术2. 主要特点3. 应用场景4. 实际案例 二、Grok:通用人工智能框架1. 核心技术2. 主要特点3. 应用场景4. 实际案例 三、ChatGPT:聊天机器人与通用对话系统1. 核心技术2. 主要特点3. 应用…...

Unix Domain Socket和eventfd
在Linux开发中,Unix Domain Socket和eventfd是两种不同的通信机制,它们的设计目标和适用场景有显著差异。以下分点解释并配合示例说明: 一、Unix Domain Socket(UDS) 1. 是什么? 一种**本地进程间通信&am…...

【万字长文】基于大模型的数据合成(增强)及标注
写在前面 由于合成数据目前是一个热门的研究方向,越来越多的研究者开始通过大模型合成数据来丰富训练集,为了能够从一个系统的角度去理解这个方向和目前的研究方法便写了这篇播客,希望能对这个领域感兴趣的同学有帮助! 欢迎点赞&…...

2025年能源工作指导意见
2025年是“十四五”规划收官之年,做好全年能源工作意义重大。为深入贯彻落实党中央、国务院决策部署,以能源高质量发展和高水平安全助力我国经济持续回升向好,满足人民群众日益增长的美好生活用能需求,制定本意见。 一、总体要求…...

【Elasticsearch】Elasticsearch 中使用 HDFS 存储快照
在 Elasticsearch 中使用 HDFS 存储快照的步骤如下: 1.安装 HDFS 插件 要使用 HDFS 存储 Elasticsearch 的索引快照,需要在 Elasticsearch 集群的所有节点上安装 HDFS 插件。 • 在线安装:适用于网络环境良好的场景,执行以下命…...
:分组与联表查询的深度探索(下))
Oracle 数据库基础入门(四):分组与联表查询的深度探索(下)
在 Oracle 数据库的操作中,联合查询与子查询是获取复杂数据的关键手段。当单表数据无法满足业务需求时,联合查询允许我们从多张表中提取关联信息,而子查询则能以嵌套的方式实现更灵活的数据筛选。对于 Java 全栈开发者而言,掌握这…...

深搜专题6:迷宫问题
描述 设有一个N*N方格的迷宫,入口和出口分别在左上角和右上角。 迷宫格子中分别放有0和1,0表示可通,1表示不能,迷宫走的规则如下: 即从某点开始,有八个方向可走,前进方格中数字为0时表示可通过…...

【每日学点HarmonyOS Next知识】web滚动、事件回调、selectable属性、监听H5内部router、Grid嵌套时高度设置
【每日学点HarmonyOS Next知识】web滚动、事件回调、selectable属性、监听H5内部router、Grid嵌套时高度设置 1、HarmonyOS WebView加载url无法滚动? scroll 里面嵌套webView,demo参考: // xxx.ets import web_webview from ohos.web.webv…...

MacBook上API调⽤⼯具推荐
在当今的软件开发中,API调用工具已经成为了开发者不可或缺的助手。无论是前端、后端还是全栈开发,API的调试、测试和管理都是日常工作中的重要环节。想象一下,如果没有这些工具,开发者可能需要手动编写复杂的CURL命令,…...

如何构建一个 Docker 镜像?
1. 创建 Dockerfile 文件 (1)选择工作目录 首先,创建一个项目目录,并进入该目录: mkdir my-docker-project cd my-docker-project(2)创建 Dockerfile 使用任何文本编辑器(如 nano、…...
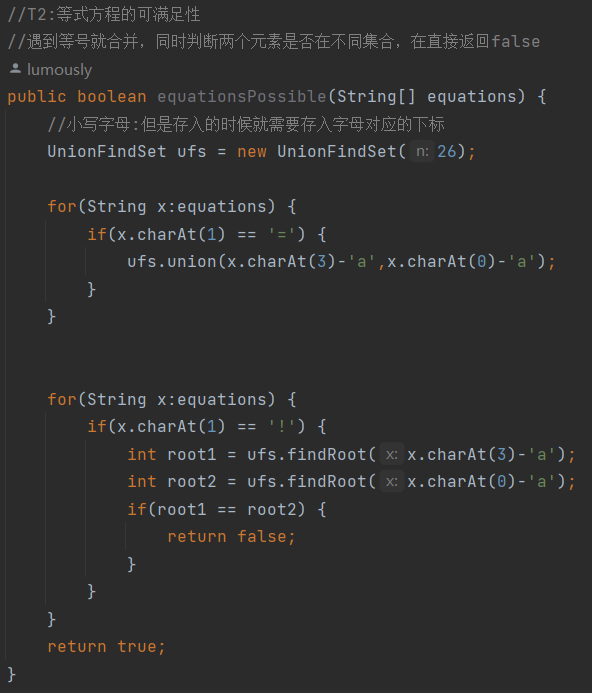
【数据结构】LRUCache|并查集
目录 一、LRUCache 1.概念 2.实现:哈希表双向链表 3.JDK中类似LRUCahe的数据结构LinkedHashMap 🔥4.OJ练习 二、并查集 1. 并查集原理 2.并查集代码实现 3.并查集OJ 一、LRUCache 1.概念 最近最少使用的,一直Cache替换算法 LRU是Least Recent…...

go数组的声明和初始化
1.数组简介 数组是可以存放多个同一类型的数据。数组也是一种数据类型,在go中,数组是值类型。数组的长度也是数组类型的一部分,所以[2]int和[3]int属于不同的数据类型。 2.数组的长度也是类型的一部分 var arr1 [2]intvar arr2 [3]intfmt.P…...

基于STM32的智能家居中控系统
基于STM32的智能家居中控系统 下载源文件 链接:博客 第1章 绪论 1.1 研究背景与意义(扩增至1500字) • 市场数据支撑:引用IDC报告数据显示,中国智能家居设备市场年增长率达25%(2022年市场规模超6500亿元) …...

初识Qt · 信号与槽 · 基础知识
目录 前言: 信号和槽初识 两个问题 前言: 本文我们正式开始介绍信号与槽这个概念,在谈及Qt中的信号与槽这个概念之前,我们不妨回顾一下Linux中的信号,比如发生了除0错误,OS就会给该进程发送一个信号&am…...

Java高频面试之集合-03
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:说说ArrayList和LinkedList的区别 ArrayList 与 LinkedList 的详细对比 一、底层数据结构 特性ArrayListLinkedList存…...

常用的分布式ID设计方案
常用的分布式ID设计方案 在分布式系统中,生成全局唯一的ID是一个常见的需求。无论是数据库表中的主键,还是消息队列的消息ID,都需要一个高效且可靠的唯一标识符。本文将探讨几种常用的分布式ID设计方案,并分析它们的优缺点。 1. …...

宇树科技再落一子!天羿科技落地深圳,加速机器人创世纪
2025年3月5日,机器人行业龙头宇树科技(Unitree)在深圳再添新动作——全资子公司深圳天羿科技有限公司正式成立。这家注册资本10万元、法定代表人周昌慧的新公司,聚焦智能机器人研发与销售,标志着宇树科技在华南市场的战…...
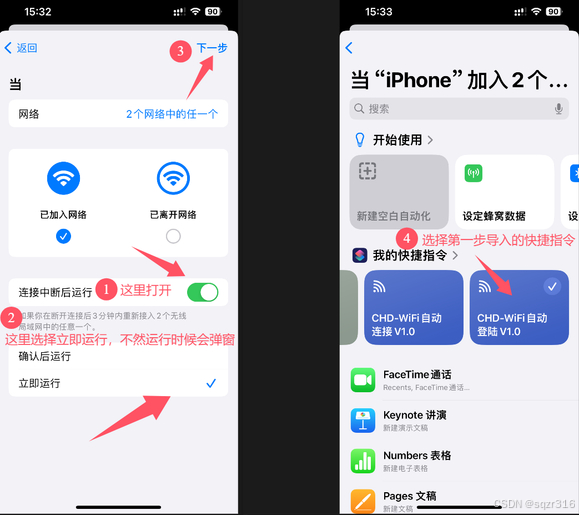
【长安大学】苹果手机/平板自动连接认证CHD-WIFI脚本(快捷指令)
背景: 已经用这个脚本的记得设置Wifi时候,关闭“自动登录” 前几天实在忍受不了CHD-WIFI动不动就断开,一天要重新连接,点登陆好几次。试了下在网上搜有没有CHD-WIFI的自动连接WIFI自动认证脚本,那样我就可以解放双手&…...

基于遗传算法的无人机三维路径规划仿真步骤详解
基于遗传算法的无人机三维路径规划仿真步骤详解 一、问题定义 目标:在三维空间内,寻找从起点到终点的最优路径,需满足: 避障:避开所有障碍物。路径最短:总飞行距离尽可能短。平滑性:转折角度不宜过大,降低机动能耗。输入: 三维地图(含障碍物,如立方体、圆柱体)。起…...
)
【Elasticsearch】索引生命周期管理相关的操作(Index Lifecycle Actions)
Elasticsearch 的Index Lifecycle Management(ILM)是一种用于管理索引生命周期的工具,它允许用户根据索引的使用阶段(如热、温、冷、冻结)自动执行一系列操作。以下是详细解释 Elasticsearch 中的索引生命周期操作(Index Lifecycl…...

计算机毕业设计SpringBoot+Vue.js电商平台(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【杂谈】信创电脑华为w515(统信系统)登录锁定及忘记密码处理
华为w515麒麟芯片版,还有非麒麟芯片版本,是一款信创电脑,一般安装的UOS系统。 准备一个空U盘,先下载镜像文件及启动盘制作工具,连接如下: 百度网盘 请输入提取码 http://livecd.uostools.com/img/apps/l…...

初始提示词(Prompting)
理解LLM架构 在自然语言处理领域,LLM(Large Memory Language Model,大型记忆语言模型)架构代表了最前沿的技术。它结合了存储和检索外部知识的能力以及大规模语言模型的强大实力。 LLM架构由外部记忆模块、注意力机制和语…...