【人工智能学习之优化为什么会失败】
【人工智能学习之优化为什么会失败与方案建议】
- 一、优化为什么会失败?
- 1. 局部极小值和鞍点
- 2. 梯度消失/爆炸(Vanishing/Exploding Gradients)
- 2. 病态条件(Ill-Conditioning)
- 3. 参数初始化不当
- 4. 学习率不当
- 5. 过拟合(Overfitting)
- 二、直接与间接的优化方法
- 传统方法:基于梯度下降的改进
- 1. 随机梯度下降(SGD)
- 2. 动量法(Momentum)
- 3. Nesterov加速梯度(NAG)
- 现代优化器:自适应学习率与二阶方法
- 1. AdaGrad(自适应梯度)
- 2. RMSProp
- 3. Adam(自适应矩估计)
- 4. 二阶方法(如牛顿法)
- 逃离鞍点的特殊技巧
- 1. 随机扰动(Perturbed SGD)
- 2. 负曲率利用(Negative Curvature Descent)
- Hessian矩阵与逃离方向
- 模型设计与训练策略
- 1. 批归一化(Batch Normalization)
- 2. 残差连接(ResNet)
- 3. 学习率调度(Learning Rate Scheduling)
- 三、总结与实用建议
- 1. 优先选择的优化器
- 2. 逃离鞍点的组合策略
- 3. 模型训练的技巧
- 4. 实战案例
一、优化为什么会失败?
优化失败的原因多种多样,从网络设计到模型训练,每一步都有可能造成影响,被评估优秀的模型是非常严格非常精密的。
1. 局部极小值和鞍点
- 问题:在深度学习中损失不是只在局部极小值的梯度是零,还有其他可能会让梯度是零的点,比如鞍点(saddle point)。如果损失收敛在局部极小值,我们所在的位置已经是损失最低的点了,往四周走损失都会比较高,就没有路可以走了。但实际上这里可能只是一个“小水洼”,前方还有更深的“峡谷”,模型却在“水洼”处无法进一步降低损失。模型需要采取其他策略跳出“水洼”才能继续降低损失以达到更优解甚至最优解。另外对于鞍点来说,没有这个跳出“水洼”这种问题,旁边还是有路可以让损失更低的。所以只要逃离鞍点,就有可能让损失更低。
- 例子:鞍点得名于马鞍的形状。想象你坐在马鞍上:沿着马头方向(前后)是“下坡”,而沿着马背方向(左右)是“上坡”,对于鞍中心的 x x x 点而言,垂直观察前后截面可以发现 x x x 点是极大值点,垂直观察左右截面可以发现 x x x 点是极小值点,俩个方向观察同一个点却呈现不同的极值状态。所以不难理解:鞍点是一个梯度为零的点,但某些方向是极小值,另一些方向是极大值。
- 理解:【人工智能学习之局部极小值与鞍点】
2. 梯度消失/爆炸(Vanishing/Exploding Gradients)
- 问题:深层网络中,反向传播时梯度可能指数级缩小(消失)或增大(爆炸),导致参数无法有效更新。
- 例子:假设激活函数是Sigmoid,它的导数最大0.25。经过10层后,梯度可能缩小到 0.2 5 10 ≈ 1 e − 6 0.25¹⁰≈1e-6 0.2510≈1e−6,几乎为零。
- 数学:若权重矩阵 W W W 的最大特征值 λ > 1 \lambda >1 λ>1,梯度爆炸;若 λ < 1 \lambda <1 λ<1,梯度消失。
2. 病态条件(Ill-Conditioning)
- 问题:损失函数在不同方向上的曲率差异巨大(Hessian矩阵的条件数高),导致梯度下降震荡。
- 例子:想象一个狭长的山谷,沿山谷方向梯度小,垂直方向梯度大。普通梯度下降会反复横跳。
3. 参数初始化不当
- 问题:初始权重过大或过小,导致激活值饱和(如Sigmoid输出接近0或1),梯度消失。
- 例子:若权重初始化为全0,所有神经元的输出相同,反向传播时梯度也相同,失去多样性。
4. 学习率不当
- 太大:损失函数震荡甚至发散(步子太大跳过最低点)。
- 太小:收敛极慢,可能卡在平坦区域。
5. 过拟合(Overfitting)
- 问题:模型在训练集上表现好,但泛化差。本质是优化时过度拟合噪声。
- 例子:用高阶多项式拟合几个带噪声的数据点,曲线“完美”穿过所有点但毫无规律。
二、直接与间接的优化方法
如何跳出局部最优解?如何逃离鞍点?哪些优化方法行之有效?还有哪些其他的优化角度?
传统方法:基于梯度下降的改进
1. 随机梯度下降(SGD)
- 核心思想:利用mini-batch的随机性引入噪声,帮助逃离局部极小值和鞍点。
- 数学形式:
θ t + 1 = θ t − η ∇ L batch ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla L_{\text{batch}}(\theta_t) θt+1=θt−η∇Lbatch(θt)
其中 ∇ L batch \nabla L_{\text{batch}} ∇Lbatch 是随机小批量数据的梯度。 - 为什么有效:
- 噪声扰动可能将参数推离平坦区域(如鞍点)。
- 在局部极小值附近,噪声可能提供“跳出”的动力。
- 局限性:噪声可能使收敛不稳定,需要精细调整学习率。
2. 动量法(Momentum)
- 核心思想:引入“动量”积累历史梯度方向,帮助冲过平坦区域。
- 数学形式:
v t = β v t − 1 + ∇ L ( θ t ) θ t + 1 = θ t − η v t v_t = \beta v_{t-1} + \nabla L(\theta_t) \\ \theta_{t+1} = \theta_t - \eta v_t vt=βvt−1+∇L(θt)θt+1=θt−ηvt
其中 β \beta β 是动量系数(通常取0.9)。 - 为什么有效:
- 逃离鞍点:在鞍点附近,梯度为零,但动量项 v t v_t vt 可能保留之前的方向,推动参数继续移动。
- 穿越局部极小值:动量积累的“惯性”可能帮助跳过狭窄的局部极小。
- 例子:想象小球滚下山坡,遇到小坑(局部极小)时,动量可能让它滚过去。
3. Nesterov加速梯度(NAG)
- 核心思想:先根据动量方向“预览”未来位置,再计算梯度。
- 数学形式:
v t = β v t − 1 + ∇ L ( θ t − η β v t − 1 ) θ t + 1 = θ t − η v t v_t = \beta v_{t-1} + \nabla L(\theta_t - \eta \beta v_{t-1}) \\ \theta_{t+1} = \theta_t - \eta v_t vt=βvt−1+∇L(θt−ηβvt−1)θt+1=θt−ηvt - 优势:比普通动量法更“聪明”,减少震荡,更快收敛。
现代优化器:自适应学习率与二阶方法
1. AdaGrad(自适应梯度)
- 核心思想:为每个参数自适应调整学习率,适合稀疏数据。
- 数学形式:
G t = G t − 1 + ( ∇ L ( θ t ) ) 2 θ t + 1 = θ t − η G t + ϵ ∇ L ( θ t ) G_t = G_{t-1} + (\nabla L(\theta_t))^2 \\ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{G_t + \epsilon}} \nabla L(\theta_t) Gt=Gt−1+(∇L(θt))2θt+1=θt−Gt+ϵη∇L(θt)- G t G_t Gt 是历史梯度平方的累加。
- 为什么有效:
- 频繁更新的参数学习率降低(分母大),稀疏参数学习率保持较高。
- 在鞍点附近,梯度可能突然增大,自适应学习率能快速调整。
2. RMSProp
- 核心思想:改进AdaGrad,引入指数衰减平均,防止学习率过早下降。
- 数学形式:
G t = β G t − 1 + ( 1 − β ) ( ∇ L ( θ t ) ) 2 θ t + 1 = θ t − η G t + ϵ ∇ L ( θ t ) G_t = \beta G_{t-1} + (1-\beta)(\nabla L(\theta_t))^2 \\ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{G_t + \epsilon}} \nabla L(\theta_t) Gt=βGt−1+(1−β)(∇L(θt))2θt+1=θt−Gt+ϵη∇L(θt)- 通常 β = 0.9 \beta = 0.9 β=0.9。
3. Adam(自适应矩估计)
- 核心思想:结合动量与自适应学习率(目前最常用的优化器)。
- 数学形式:
m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ L ( θ t ) (一阶矩,动量) m_t = \beta_1 m_{t-1} + (1-\beta_1)\nabla L(\theta_t) \quad \text{ (一阶矩,动量)} mt=β1mt−1+(1−β1)∇L(θt) (一阶矩,动量)
v t = β 2 v t − 1 + ( 1 − β 2 ) ( ∇ L ( θ t ) ) 2 (二阶矩,自适应学习率) v_t = \beta_2 v_{t-1} + (1-\beta_2)(\nabla L(\theta_t))^2 \quad \text{ (二阶矩,自适应学习率)} vt=β2vt−1+(1−β2)(∇L(θt))2 (二阶矩,自适应学习率)
m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t (偏差修正) \hat{m}_t = \frac{m_t}{1-\beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1-\beta_2^t} \quad \text{ (偏差修正)} m^t=1−β1tmt,v^t=1−β2tvt (偏差修正)
θ t + 1 = θ t − η v ^ t + ϵ m ^ t \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θt+1=θt−v^t+ϵηm^t- 默认参数: β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 e − 8 \beta_1=0.9, \beta_2=0.999, \epsilon=1e-8 β1=0.9,β2=0.999,ϵ=1e−8。
- 为什么有效:
- 动量项帮助逃离鞍点和平坦区域。
- 自适应学习率在不同参数方向调整步长,适合病态曲率。
4. 二阶方法(如牛顿法)
- 核心思想:利用Hessian矩阵的曲率信息,直接找到下降方向。
- 数学形式:
θ t + 1 = θ t − η H − 1 ∇ L ( θ t ) \theta_{t+1} = \theta_t - \eta H^{-1} \nabla L(\theta_t) θt+1=θt−ηH−1∇L(θt)- H H H 是Hessian矩阵。
- 优势:
- 在鞍点处,Hessian矩阵的负特征值方向直接给出逃离方向。
- 收敛速度快(二次收敛)。
- 局限性:
- 计算Hessian矩阵及其逆的复杂度为 O ( D 3 ) O(D^3) O(D3),不适用于深度学习(参数维度 D D D 太大)。
- 近似方法:
- L-BFGS:有限内存BFGS,适用于中小规模问题。
- K-FAC:自然梯度法的近似,用于深度学习。
逃离鞍点的特殊技巧
1. 随机扰动(Perturbed SGD)
- 核心思想:主动向参数添加噪声,增加探索能力。
- 数学形式:
θ t + 1 = θ t − η ∇ L ( θ t ) + ϵ t , ϵ t ∼ N ( 0 , σ 2 ) \theta_{t+1} = \theta_t - \eta \nabla L(\theta_t) + \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, \sigma^2) θt+1=θt−η∇L(θt)+ϵt,ϵt∼N(0,σ2) - 为什么有效:
- 在鞍点附近,随机扰动可能将参数推到负曲率方向,从而开始下降。
- 论文支持:Google Brain的《Adding Gradient Noise Improves Learning》证明了噪声的有效性。
2. 负曲率利用(Negative Curvature Descent)
- 核心思想:显式检测负曲率方向,并沿该方向下降。
- 步骤:
- 计算Hessian矩阵的最小特征值 λ min \lambda_{\min} λmin 和对应特征向量 v v v。
- 如果 λ min < 0 \lambda_{\min} < 0 λmin<0,沿 v v v 方向更新:
θ t + 1 = θ t − η ⋅ sign ( v T ∇ L ) ⋅ v \theta_{t+1} = \theta_t - \eta \cdot \text{sign}(v^T \nabla L) \cdot v θt+1=θt−η⋅sign(vT∇L)⋅v
- 适用场景:小规模问题或理论分析。
Hessian矩阵与逃离方向
假设在鞍点 θ ∗ \theta^* θ∗,Hessian矩阵 H H H 有负特征值 λ < 0 \lambda < 0 λ<0,对应特征向量 v v v。沿 v v v 方向的更新:
θ = θ ∗ + ϵ v ⇒ L ( θ ) ≈ L ( θ ∗ ) + 1 2 ϵ 2 λ < L ( θ ∗ ) \theta = \theta^* + \epsilon v \quad \Rightarrow \quad L(\theta) \approx L(\theta^*) + \frac{1}{2} \epsilon^2 \lambda < L(\theta^*) θ=θ∗+ϵv⇒L(θ)≈L(θ∗)+21ϵ2λ<L(θ∗)
此时损失函数会下降,这就是逃离鞍点的数学原理。
模型设计与训练策略
1. 批归一化(Batch Normalization)
- 核心思想:标准化每层输入,减少内部协变量偏移。
- 操作:
x ^ = x − μ σ 2 + ϵ , y = γ x ^ + β \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}, \quad y = \gamma \hat{x} + \beta x^=σ2+ϵx−μ,y=γx^+β - 为什么有效:
- 保持激活值的稳定分布,防止梯度消失/爆炸。
- 允许使用更大的学习率,间接帮助逃离局部极小。
2. 残差连接(ResNet)
- 核心思想:通过跳跃连接传递原始输入,确保梯度可以直通深层。
- 数学形式:
y = f ( x ) + x y = f(x) + x y=f(x)+x - 为什么有效:
- 即使 f ( x ) f(x) f(x) 的梯度消失, x x x 的直连路径仍能传递梯度,保证了梯度不会消失。
3. 学习率调度(Learning Rate Scheduling)
- 常用策略与为什么有效:
- 预热(Warmup):初始阶段逐步增大学习率,防止早期震荡。
- 余弦退火(Cosine Annealing):利用余弦周期,周期性地重置学习率,在某一周期以较大学习率跳出局部极小。
- 周期性重启(SGDR):类似模拟退火,周期性增加学习率。
三、总结与实用建议
具体任务中的优化困境,是需要再结合代码和实验结果分析原因的。
1. 优先选择的优化器
- Adam:适合大多数任务,尤其是初始学习阶段。
- 带动量的SGD:在精细调参后可能达到更高精度(如训练ResNet)。
2. 逃离鞍点的组合策略
- 使用Adam或带动量的优化器:逃离鞍点和局部极小。
- 添加批归一化层:防止梯度消失或爆炸,稳定训练过程。
- 引入随机扰动:如梯度噪声,增加探索能力。
- 周期性放大学习率:采用如余弦退火的训练策略跳出局部极小。
3. 模型训练的技巧
- 初始化:用Xavier/He初始化,避免激活值饱和。
- 优化器:首选Adam(自适应学习率+动量),复杂任务可试RMSprop。
- 学习率调整:使用学习率预热(Warmup)或余弦退火(Cosine Annealing)。
- 监控训练:用TensorBoard跟踪损失/梯度分布,发现异常及时调整。
- 模型设计:深层网络用残差连接,激活函数用Mish/ReLU/LeakyReLU。
4. 实战案例
例一:假设你训练一个CNN时,损失卡在某个值不再下降:
- 检查梯度是否接近零(可能是鞍点或局部极小)。
- 尝试增大学习率或添加动量(帮助冲过平坦区)。
- 插入批归一化层或改用残差结构。
- 启用余弦退火学习率调度。
例二:训练一个10层全连接网络,如果损失不降,可能是梯度消失。这时可以:
- 改用He初始化;
- 添加批归一化层;
- 将Sigmoid换成ReLU;
- 选择Adam优化器。
希望这些能帮你少走弯路!
相关文章:

【人工智能学习之优化为什么会失败】
【人工智能学习之优化为什么会失败与方案建议】 一、优化为什么会失败?1. 局部极小值和鞍点2. 梯度消失/爆炸(Vanishing/Exploding Gradients)2. 病态条件(Ill-Conditioning)3. 参数初始化不当4. 学习率不当5. 过拟合&…...
)
flask学习2-应用(博客)
flask学习2-应用(博客) 项目目录应用程序工厂连接到数据库建表初始化数据库文件蓝图和视图第一个视图:注册注册登录根据用户id查询用户注销模板基本布局注册登录注册用户静态文件博客蓝图索引创建更新-根据id查询更新-根据id更新删除使项目可安装描述项目安装项目测试覆盖率…...

Next.js项目实战-ai助手帮我写文章发布视频第1节(共89节)
😂Ai在国内外已经杀疯了,老板要求我们把速度再提升快一些,哪怕是几秒,几百毫秒也行~现在,马上就要,就地就要,只好搬出前端服务端(大保健)😓。没错,今天我要分…...

探秘Transformer系列之(9)--- 位置编码分类
探秘Transformer系列之(9)— 位置编码分类 文章目录 探秘Transformer系列之(9)--- 位置编码分类0x00 概述0x01 区别1.1 从直观角度来看1.2 从模型处理角度来看1.3 优劣 0x02 绝对位置编码2.1 基础方案2.2 训练式2.3 三角函数式2.4…...
(2/2))
文件操作(详细讲解)(2/2)
你好呀这里是我说风俗,各位客官走过路过,关关注,点点赞,收收藏,您的鼓励是对我最大的认可,我也会努力更行下去的!!!大一学生不易(》《) 5. 文件的…...

笔记四:C语言中的文件和文件操作
Faye:只要有正确的伴奏,什么都能变成好旋律。 ---------《寻找天堂》 目录 一、文件介绍 1.1程序文件 1.2 数据文件 1.3 文件名 二、文件的打开和关闭 2.1 文件指针 2.2.文件的打开和关闭 2.3 文件读取结束的判定 三、 文件的顺序读写 3.1 顺序读写…...

Zabbix+Deepseek实现AI告警分析(非本地部署大模型版)
目录 前言技术架构DeepSeek API获取1. 注册账号2. 申请API-Key Zabbix告警AI分析 实现1. 创建Scripts2. Scripts关键参数说明3. 需要注意 测试参考链接 前言 最近手伤了,更新频率下降…… 近期在Zabbix社区看到了一篇文章:张世宏老师分享的《Zabbix告警分…...

基于Celery+Supervisord的异步任务管理方案
一、架构设计背景 1.1 需求场景分析 在Web应用中,当遇到以下场景时需要异步任务处理方案: 高延迟操作(大文件解析/邮件发送/复杂计算)请求响应解耦(客户端快速响应)任务队列管理(任务优先级/…...
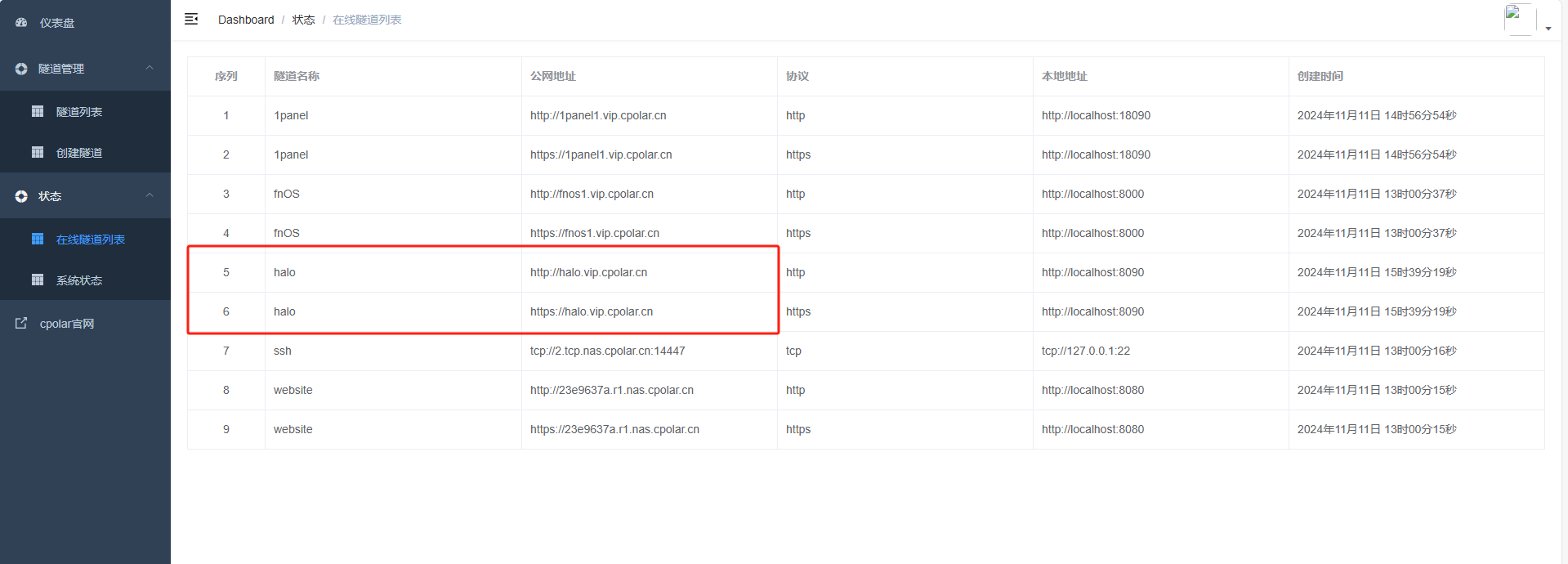
国产NAS系统飞牛云fnOS深度体验:从运维面板到博客生态全打通
文章目录 前言1. 飞牛云本地部署1Panel2. 1Panel功能介绍3. 公网访问1Panel控制面板4. 固定1Panel公网地址5. 1Panel搭建Halo博客6. 公网访问Halo个人博客 前言 嘿,小伙伴们!是不是厌倦了服务器管理的繁琐和搭建个人网站的复杂?今天就来一场…...

使用QT + 文件IO + 鼠标拖拽事件 + 线程 ,实现大文件的传输
第一题、使用qss,通过线程,使进度条自己动起来 mythread.h #ifndef MYTHREAD_H #define MYTHREAD_H#include <QObject> #include <QThread> #include <QDebug>class mythread : public QThread {Q_OBJECT public:mythread(QObject* …...

【LeetCode 热题 100】438. 找到字符串中所有字母异位词 | python 【中等】
继续学!嗨起来!!!(正确率已经下30%了,我在干什么) 题目: 438. 找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的子串,返回这些子串的…...

博查搜索API日调用量突破3000万次,达到Bing API的1/3。
根据第三方机构统计,2024年Bing Search API 全球日均调用量为1.1亿次。截至2025年3月,博查 Search API日均调用量已达到3000万次(约为Bing的1/3),承接着国内AI应用60%的联网搜索请求。...

【蓝桥杯集训·每日一题2025】 AcWing 5539. 牛奶交换 python
AcWing 5539. 牛奶交换 Week 3 3月6日 题目描述 农夫约翰的 N N N 头奶牛排成一圈,使得对于 1 , 2 , … , N − 1 1,2,…,N−1 1,2,…,N−1 中的每个 i i i,奶牛 i i i 右边的奶牛是奶牛 i 1 i1 i1,而奶牛 N N N 右边的奶牛是奶牛 …...
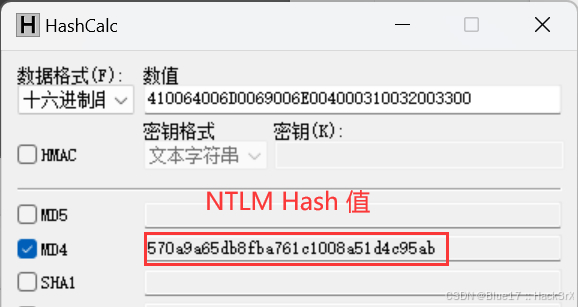
[内网安全] Windows 本地认证 — NTLM 哈希和 LM 哈希
关注这个专栏的其他相关笔记:[内网安全] 内网渗透 - 学习手册-CSDN博客 0x01:SAM 文件 & Windows 本地认证流程 0x0101:SAM 文件简介 Windows 本地账户的登录密码是存储在系统本地的 SAM 文件中的,在登录 Windows 的时候&am…...

输电线路杆塔倾斜智能监测:守护电网安全的智慧之眼
2023年夏,某超高压输电线路突发倒塔事故,导致三省市大面积停电,直接经济损失超2.3亿元。事后调查显示,杆塔倾斜角度早已超出安全阈值,但传统巡检未能及时发现。这个刺痛行业的案例,揭开了电力设施监…...

FastGPT 引申:奥运选手知识图谱构建与混合检索应用
目录 FastGPT 引申:奥运选手知识图谱构建与混合检索应用第一部分:数据构建流程1. 数据抽取与预处理2. 向量化处理3. 知识图谱构建4. 数据持久化 第二部分:混合检索应用1. 用户查询处理2. 混合检索技术细节3. 返回结果示例4. 性能指标 FastGPT…...

GitHub CI流水线
GitHub CI流水线 build.yml 路径:.github/workflows/build.yml name: Docker Image CIon:workflow_dispatch:jobs:build:runs-on: ubuntu-lateststeps:- uses: actions/checkoutv4- name: Set up JDK 8uses: actions/setup-javav4with:java-version: 8distributi…...

探索.NET 10 的新特性,开发效率再升级!
前言 最近,.NET 10 发布啦,作为长期支持(LTS)版本,接下来的 3 年里它会给开发者们稳稳的幸福。今天咱就来唠唠它都带来了哪些超实用的新特性。可在指定链接下载。 新特性 下面将介绍了.NET 10的新特性,其…...

算法·搜索
搜索问题 搜索问题本质也是暴力枚举,一般想到暴力也要想到利用回溯枚举。 排序和组合问题 回溯法 去重问题:定义全局变量visited还是局部变量visited实现去重? 回溯问题 图论中的搜索问题 与一般的搜索问题一致,只不过要多…...

【图像处理与OpenCV:技术栈、应用和实现】
引言 图像处理作为计算机视觉领域的重要分支,在各个行业中扮演着越来越重要的角色。从医疗诊断、自动驾驶、安防监控到人工智能领域的图像识别,图像处理无处不在。随着计算机硬件性能的提升和深度学习的快速发展,图像处理技术也在不断演进&a…...

《水利水电安全员考试各题型对比分析及应对攻略》
《水利水电安全员考试各题型对比分析及应对攻略》 单选题: 特点:四个选项中只有一个正确答案,相对难度较小。主要考查对基础知识的掌握程度。 应对攻略:认真审题,看清题目要求。对于熟悉的知识点,直接选择…...

鸿蒙HarmonyOS-Navagation基本用法
Navagation基本用法 Navigation组件是路由导航的根视图容器,一般作为Page页面的根容器使用,其内部默认包含了标题栏,内容栏和公工具栏,其中内容区默认首页显示导航内容(Navigation的子组件)或非首页显示&am…...

第16章 直接定址表
目录 16.1 描述了单元长度的标号16.2 在其它段中使用数据标号16.3 直接定址表16.4 程序入口地址的直接定址表实验16 编写包含多个功能子程序的中断例程 16.1 描述了单元长度的标号 assume cs:code code segment a db 1,2,3,4,5,6,7,8 b dw 0 start: mov si,0 mov cx…...

【AI深度学习网络】卷积神经网络(CNN)入门指南:从生物启发的原理到现代架构演进
深度神经网络系列文章 【AI深度学习网络】卷积神经网络(CNN)入门指南:从生物启发的原理到现代架构演进【AI实践】基于TensorFlow/Keras的CNN(卷积神经网络)简单实现:手写数字识别的工程实践 引言 在当今…...

江科大51单片机笔记【10】蜂鸣器播放提示器音乐(下)
一、蜂鸣器播放提示器 这里我们要用Key,Delay,Nixie模块 并且把Nixie.c函数里的这两句注释,因为之前是动态显示,延时后马上清零,现在是静态显示,所以需要把他注释掉 // Delay(1); // P00x00; 先验…...

Milvus JSON数据存储优化方案
无论是json数据还是string/varchar 类型数据,其长度都不能超过65536,这是根本,不像ES的text类型数据一样,可以无限长。 总结 数据类型适用场景最大长度STRINGMilvus <2.2.x 的短文本(<65KB)隐式 ≈65,535 字节VARCHAR(N)Milvus ≥2.2.x 的文本显式 N≤65,535 字符…...

MySQL 数据库连接池爆满问题排查与解决
目录 MySQL 数据库连接池爆满问题排查与解决 一、问题影响 二、问题确认 三、收集信息 四、SQL 语句分析 五、应用层代码分析 六、连接池配置检查 七、监控工具使用 八、案例分析 在实际的应用开发中,我们可能会遇到 MySQL 数据库连接池爆满的情况。这种情…...

PyTorch深度学习的梯度消失和梯度爆炸的识别、解决和最佳实践
通过结合梯度监控、网络架构改进和优化策略,可以有效应对梯度消失/爆炸问题。建议在模型开发初期就加入梯度监控机制,这有助于快速定位问题层。对于超深网络(>50层),建议优先考虑使用预激活残差结构(Res…...

Nginx1.19.2不适配OPENSSL3.0问题
Nginx 1.19.2 是较老的版本,而 Nginx 1.21 版本已经适配 OpenSSL 3.0,所以建议 升级 Nginx 到 1.25.0 或更高版本: wget http://nginx.org/download/nginx-1.25.0.tar.gz tar -xzf nginx-1.25.0.tar.gz cd nginx-1.25.0 ./configure --prefix…...

蓝桥杯 Excel地址
Excel地址 题目描述 Excel 单元格的地址表示很有趣,它使用字母来表示列号。 比如, A 表示第 1 列, B 表示第 2 列, Z 表示第 26 列, AA 表示第 27 列, AB 表示第 28 列, BA 表示第 53 列&#x…...