Python教程(一):基本语法、流程控制、数据容器
Python(一)
文章目录
- Python(一)
- 一、基础语法
- 二、数据类型
- 2.1 字符串
- 2.2 空值
- 2.3 类型转换&运算符
- 三、流程控制
- 3.1 条件判断
- 3.2 循环
- 3.2.1 while循环
- 3.2.2 for循环
- 四、数据结构
- 4.1 字符串str
- 4.1.1 字符串的格式化输出
- 4.1.1.1 格式化运算符
- 4.1.1.2 format函数
- 4.1.1.3 快速格式化
- 4.1.2 字符串的下标和切片
- 4.1.3 字符串函数
- 4.2 元组tuple
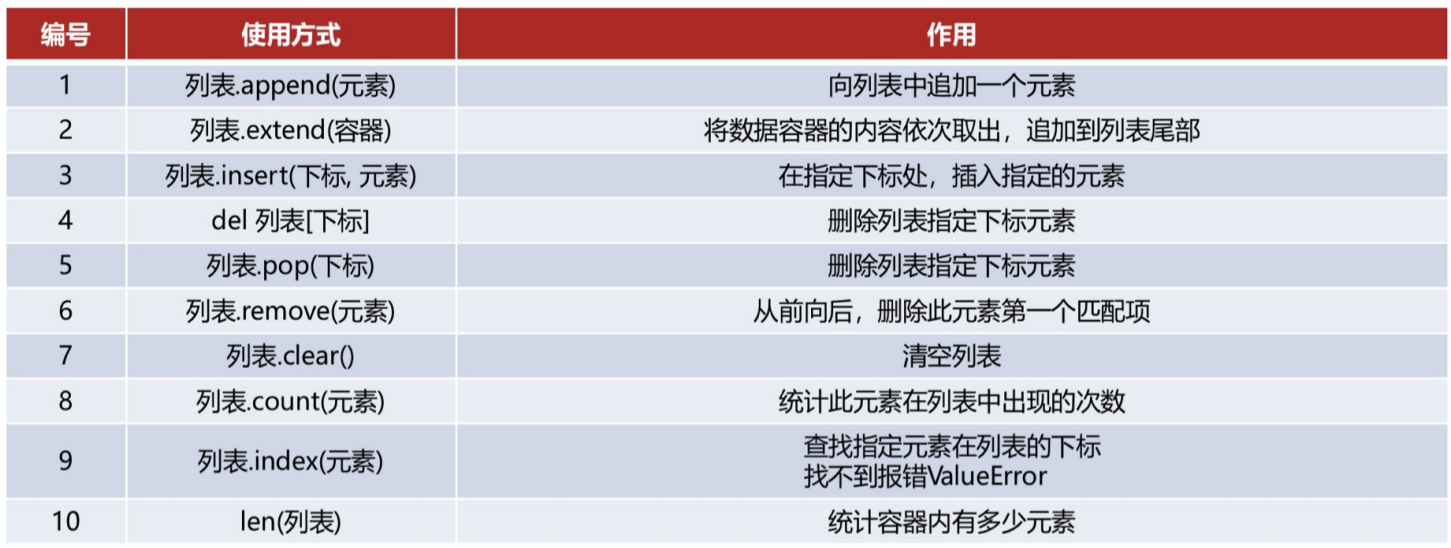
- 4.3 列表list
- 4.3.1 列表函数
- 4.3.2 列表表达式
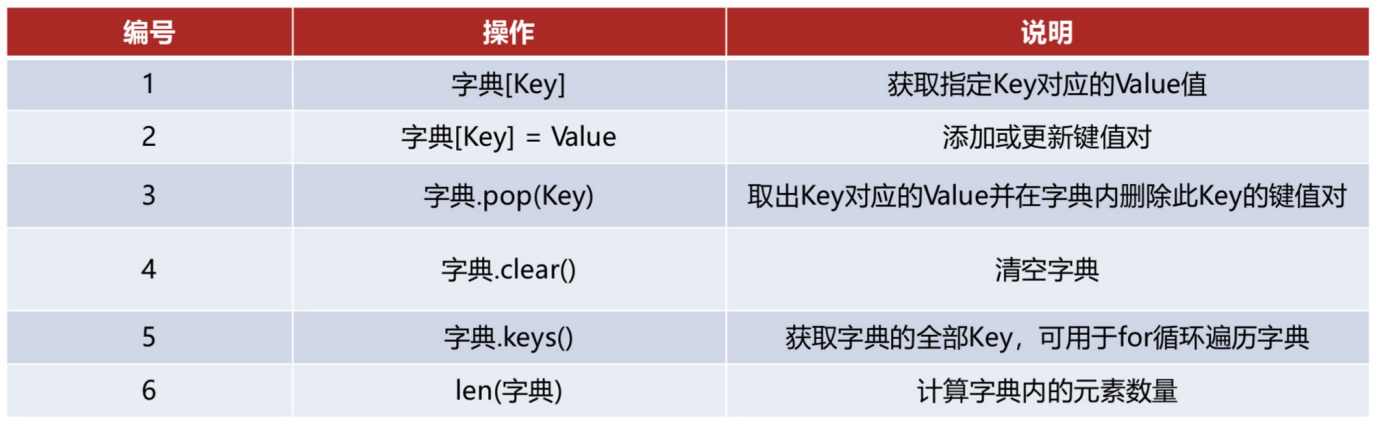
- 4.4 字典dict
- 4.4.1 遍历字典
- 4.4.2 字典函数
- 4.5 集合set
- 4.5.1 集合函数
- 4.6 总结
- 五、补充内容
一、基础语法
-
输出语句
print("Hello", "World")。 -
pass是Python里的关键字,表示什么都不做,只是用来填充语法结构。 -
Python注释:
- 单行注释使用
#。 - 多行注释使用三对双引号或三对单引号。
- 单行注释使用
-
Python定义变量、对象的时候不需要声明类型,Python中的变量是没有类型的,它的值有类型,会根据值自动识别类型。
# 定义两个变量 my_var1 = "你好哦" my_var2 = 22# 一行代码定义三个相同值的变量 a = b = c = "嘿嘿"# 一行代码定义三个不同值的变量 x, y, z = 12, '哈哈', "嗯嗯" -
Python中单引号和双引号意义完全⼀样。
-
Python语句的结尾不需要加分号。
-
Python中的字符串可以使用加号和逗号拼接:
- 加号:连接的字符串不添加空格。
- 逗号:连接的字符串之间自动加一个空格:
print("Hello", 12)。- 使用逗号拼接时,print函数会自动将数值先转换成字符串再输出,而使用加号不能直接将字符串和数值拼在一块。
-
要摧毁变量使用
del variable,一般无需手动的去销毁变量,Python的垃圾回收机制会自动处理掉那些不再使用的变量。 -
print语句默认都会在结尾增加一个换行符,所以print之后的语句都会另起一个新行。
print()表示输出一个空行。- print语句的end参数指定结尾的字符,比如
print('哈哈', end="")表示输出哈哈之后不添加任何东西(包括换行符),所以接下来的内容都会和哈哈同一行。
-
input函数表示要读取用户的输入
password = input('请输入你的密码:') # 在执行到这行代码时,控制台就变成光标闪烁的状态,会提示用户“请输入你的密码:”,用户可以用键盘进行字符的输入,输入完成后,再输入一个回车表示输入结束,输入的字符串赋给等号左边的变量。
二、数据类型
- 基本的数据类型有:数值(整数、浮点数)、字符串、布尔值、None。
- 只要有浮点数参与的运算,结果一定也是浮点数。
2.1 字符串
-
如果字符串含有特殊字符,比如双引号,可以加一个
\来进行转义:print("鲁迅曾经说过:\"读医救不了...\"") # 输出:鲁迅曾经说过:"读医救不了..." -
双引号中包含单引号,不用对单引号转义;单引号中包含双引号,不用对双引号转义:
print("鲁迅曾经说过:'读医救不了...'") # 输出:鲁迅曾经说过:'读医救不了...'print('鲁迅曾经说过:"读医救不了..."') # 输出:鲁迅曾经说过:"读医救不了..." -
字符串之前加
r表示表示不会对字符串里的特殊字符转义,原封不动的保留字符串的所有内容,比如写路径时,不对其中的斜杠进行转义非常有用:print(r"鲁迅曾经说过:\"读医救不了...\"" + r"c:\data\myfile.txt") # 输出:鲁迅曾经说过:\"读医救不了...\"c:\data\myfile.txt -
如果字符串比较长,超出了编译器一行的长度,在编写的时候使用一个反斜杠
\来连接多行(这个多行指的是编译器的多行,实际运行仍然在一行上):sentence = '超长的句子啊啊啊 \你看长不长' print(sentence) # 输出:超长的句子啊啊啊 你看长不长 -
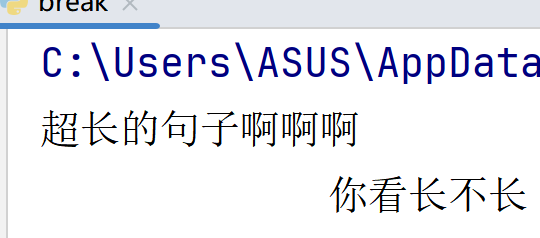
使用三对双引号,可以保留原格式(换行也会保留):
sentence = """超长的句子啊啊啊你看长不长""" print(sentence) # 三对双引号如果不赋值给变量,就是多行注释。输出:
-
使用
*运算符,表示将该字符串重复几次并拼接成一个字符串。# 运行结果是ababab print('ab' * 3)
2.2 空值
- 定义变量时还没想好给它赋什么值,甚至连它用什么类型也没决定好,这时可以先用None:
temp = None - None被输出的时候显示为一个字符串"None"
2.3 类型转换&运算符
-
要把其他类型转换成布尔值,需要使用一个内置函数
bool(),会返回 True 或 False。- 对于数值类型,非0的都是True,只有0才转换为False。
- 对于任何非空的字符串转换为布尔值都是True,空字符串转换成布尔值是False。
- None转换为布尔值永远都是False。
-
可以使用
str()函数将其他类型转换为字符串。 -
想要把一个整数字符串转换为int类型,使用
int()函数。 -
想要把一个带小数点的字符串转换为 float 类型,使用
float()函数。 -
int类型和float类型之间也可以相互转换。
-
float在被转换为int的过程中,它的小数部分精度将默认被丢弃,只取整数部分,而不是四舍五入。
- float在被转换为int的过程中,如果想要四舍五入转换,需要使用
round()函数。
- float在被转换为int的过程中,如果想要四舍五入转换,需要使用
-
int在被转换成float的过程中,会自动给整数后加一位小数点。
# 运行结果是3 print(int(3.78))# 运行结果是4.0 print(float(4))# 运行结果是4 print(round(3.78))# round函数还支持指定保留小数点后几位 # 保留两位小数四舍五入,运行结果是3.79 print(round(3.7856, 2))
-
-
布尔值也可以转换为int或者float,布尔值转换成数值都是 0或1,0.0或1.0。
int(True) # 结果是1 int(False) # 结果是0 float(True) # 结果是1.0 float(False) # 结果是0.0 -
运算符
**表示的是指数运算,比如 2 ** 3 相当于 2 * 2 * 2。 -
使用单斜杠除法运算符时,即使除数和被除数都是整数,它的返回结果也是一个浮点数。
-
0不能放在
%和/的右边来进行运算。 -
Python中的逻辑运算符是三个单词:
-
and:
x and y -
or:
x or y -
not:
not x -
逻辑运算符会自动的将第一个能得到整个式子的值赋值给左边的变量(短路运算符):
# a=100 a = 0 or 100# b=1 b = 1 or 2
-
三、流程控制
3.1 条件判断
-
写法(
elif可以省略):a = 100 # if后面的表达式不用加括号 if a > 100:pass elif a < 100:print(a * 2) elif a == 100:print(a * 3) else:print(a * 4) -
与逻辑运算符组合:
age = 18if age < 50 and age >= 18:pass # 上述的写法等同于如下,这是Python特有的简洁写法 if 18 <= age < 50:pass -
if 和 elif 的后面总是跟着一个表达式,这个表达式的结果必须是True或者False,如果表达式运算出来的结果不是一个布尔值,则会自动将结果转换为布尔值,无论它是什么类型的值。
count = '你好' if not count:pass else:print('我好') # 输出我好
3.2 循环
3.2.1 while循环

3.2.2 for循环
-
for循环可以用来遍历任何序列,序列指的是一个可迭代的有序的集合,比如字符串就是一个序列。
# 遍历字符串中的所有字符 seq = 'Hello' for i in seq:print(i) -
range()函数提供一个迭代器:# 一个参数n,表示提供一个从0 → n-1的迭代器 # 打印出0到4 for e in range(5):print(e)# 两个参数表示左闭右开 # 打印出5到9 for e in range(5, 10):print(e)# 第三个参数表示左闭右开的步长 # 打印出5、7、9 for e in range(5, 10, 2):print(e) -
continue跳出本次循环继续下一次循环;break跳出整个循环。
四、数据结构
4.1 字符串str
- 字符串一旦被创建就不能被修改。
myPassword = 'abc'
inputPassword = 'fewvabcfvews'
# 字符串的in,可以检测字符或字符串是否包含在另一个字符串中
# 包含的话返回true
if myPassword in inputPassword:print('密码在里面!')
else:pass
注意:不要和 for 循环的 in 的作用搞混。
4.1.1 字符串的格式化输出
4.1.1.1 格式化运算符
用 % 隔开待格式化的字符串和具体要传入的内容:
print("我跑完了第 %d 圈" % 5)
# 输出:我跑完了第 5 圈
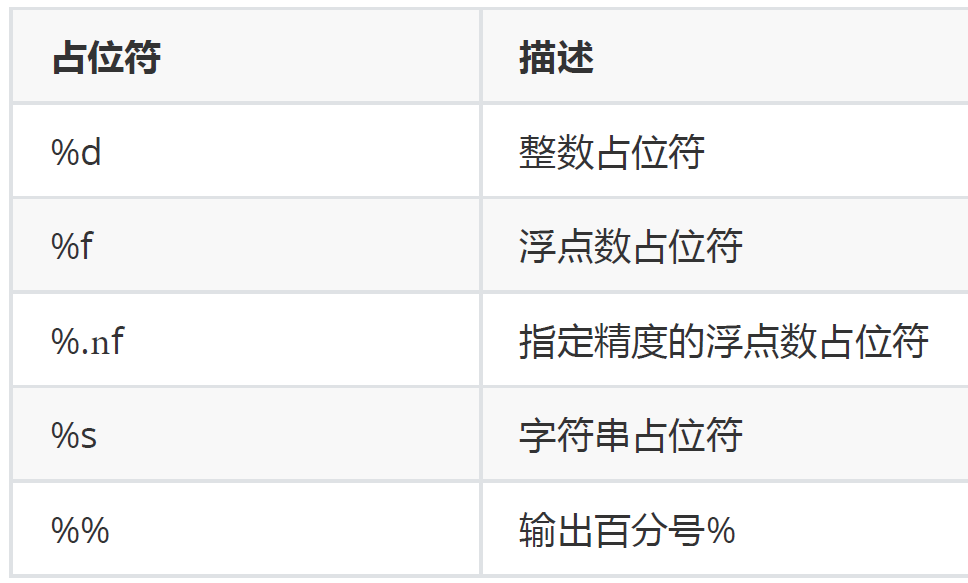
%d 是一种占位,表示要显示在这里的是一个整数,常用的占位符有以下几种:
# 如果给%d传入一个浮点数,那会自动将它截断转换成整数,而不是四舍五入
print("%d" % 3.78)
# 输出:3# 只想要浮点数的指定小数位数,会自动四舍五入
# 如果传入的浮点数的小数位数不够,则会自动补0
print("%.2f" % 3.7897) # 输出:3.79
print("%.3f" % 3.7) # 输出:3.700# %s是胜任最广泛的占位符,它可以对应任何类型的变量
print("%s" % '你好啊') # 输出:你好啊
print("%s" % 3.15) # 输出:3.15
print("%s" % True) # 输出:True# 在同一个字符串可以同时使用多个占位符
# 多个要传入的值使用括号括起来,并且只使用一个%号print("%s公司的第%d季度的营收是%.2f亿" % ('腾讯', 2, 3.78))
# 输出:腾讯公司的第2季度的营收是3.78亿
4.1.1.2 format函数
-
用法:
字符串.format(参数) -
格式化数字:
print('{:,}'.format(123456789)) # 输出:123,456,789:表示后面是一个格式说明,,表示在数字中插入千位分隔符。:后还有其他类型的格式说明,这里不赘述。 -
使用大括号加索引格式化参数:
"{0}公司的第{1}季度的营收是{2}亿".format('腾讯', 2, 3.78) # 运行结果:腾讯公司的第2季度的营收是3.78亿- {0}表示第一个参数,{1}{2}表示第二、第三个参数。
4.1.1.3 快速格式化
- 可以在字符串之前加
f来进行字符串的快速格式化。- 字符串中的变量使用大括号括起来。
name = 'Jay'
age = 22
school = 'Tsing Hua'# 进行快速格式化字符串
print(f"我的名字是{name},我今年{age}岁,我读的学校是{school}")
# 我的名字是Jay,我今年22岁,我读的学校是Tsing Hua
4.1.2 字符串的下标和切片
-
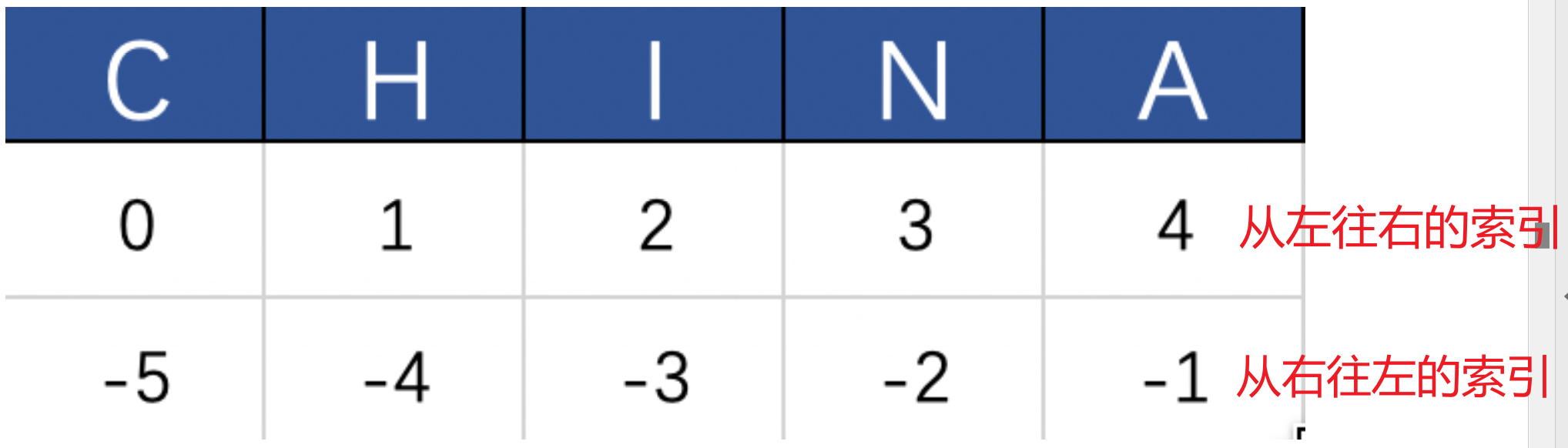
Python中引用序列的索引对应的值的写法是:
序列[索引],比如"China"[0]得到第一个字母C。 -
Python中的下标索引是从0开始的。
-
获取指定的字符/字符串(中括号中可以写1、2、3个参数):
name = 'China'# 一个数值表示取对应索引的值 print(name[-1]) # 输出a#两个变量表示取左闭右开范围内的字符串,使用:隔开 print(name[2:5]) # 输出ina print(name[0:-1]) # 输出Chin# 冒号左边为空表示从第一个字符开始截取 print(name[:4]) # 输出Chin# 冒号右边为空表示截取到最后一个字符 print(name[2:]) # 输出ina print(name[:]) # 输出China# 三个变量表示取左闭右开范围内的字符串,第三个值表示步长,使用:隔开 # 第一个字符一定会被截取到 print(name[::2]) # 输出Cia# 步长也可以为负数,如果传递了一个负数,则表示是从右往左进行截取 print(name[::-2]) # 输出aiC# 如果想倒序输出一个字符串,可以第三个参数写-1 print(name[::-1]) # 输出anihC
4.1.3 字符串函数
用法都是 字符串.函数。
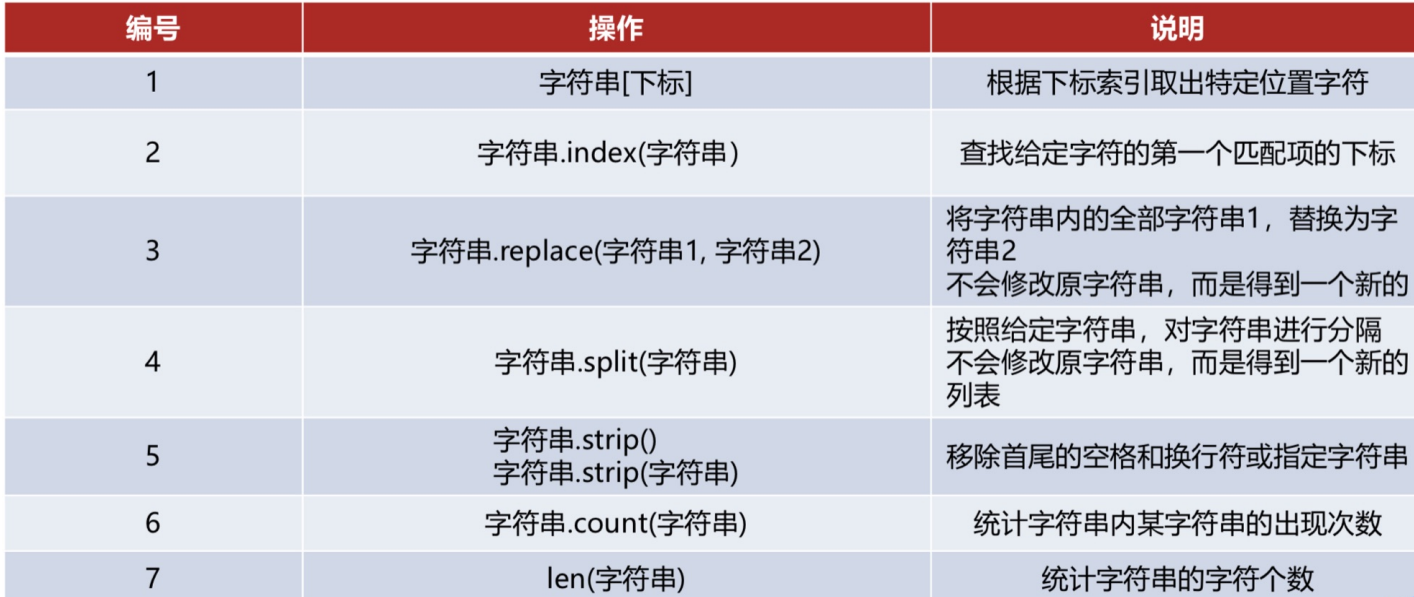
-
strip()函数的作用是去除字符串首尾的所有空白字符:# 输出abc ' abc '.strip()strip()函数并不会去掉字符串之间的空白字符。lstrip()和rstrip()函数分别去除字符串左边和右边的空白字符。
-
大小写操作:
# 将所有字母变成大写 print("china".upper()) # CHINA# 将首字母大写 print("china".capitalize()) # China# 将所有字母变成小写 print("china".lower()) # china# 将每个单词的首字母变成大写 print("china is good".title()) # China Is Good -
字符串判断,结果全部返回
True或False:

-
index()和find()函数可以找到字符串中任意字符/字符串的确切位置:- 字符串的 in 关键字的作用只能判断是否包含而不能找到确切位置。
# 会找到第一个匹配的位置 print("Chinain".find("in")) # 2# find函数没有找到会返回-1 print("China".find("l")) # -1# index函数没有找到会报错:substring not found print("China".index("l")) # 报错 -
count()函数能够找到指定的字符/字符串出现了几次:'abbaa'.count('a') # 3 -
replace()函数提供了替换部分字符串的功能(得到的是一个新的字符串):- 第一个参数是要被替换的字符串,第二个参数是将要替换成的字符串。
var1 = 'apple banana'print(var1.replace('apple', 'orange')) # orange banana print(var1) # 还是apple banana -
使用
len()函数获取序列长度,不光能统计字符串的,可以测量所有有长度的对象:print(len("hahah")) # 5 print(len("")) # 0 print(len(range(5))) # 5 -
使用
split()函数可以将字符串按照指定的分隔符进行分割,并将结果存入列表中:- 用法:
字符串.split(分隔符)
myStr = '我$今年$3$岁了' list1 = myStr.split('$') print(list1) # ['我', '今年', '3', '岁了'] print(type(list1)) # <class 'list'> - 用法:
4.2 元组tuple
-
元组是一种序列,其中的每一项叫做一个元素,元素从左到右按顺序排列。
-
字符串中的类型只能是字符,而元组中的元素可以是各种不同或相同的类型。
-
和字符串一样,元组一旦被创建无法被修改。
-
元组的定义方式:
t = ('my', "age" 'is', 18.0)- 括号里的每一个元素都使用逗号隔开。
-
访问元组的元素和字符串一致,也是使用中括号加索引,比如
t[1]得到"age"。 -
也可以通过切片来访问元组中的元素,注意切片返回的是一个包含切片片段的新元组(元组无法被修改):
t = ('my', 'is', 18.0)# 范围是左闭右开 print(t[1:3]) # ('is', 18.0) -
元组定义的时候也可以不用括号,但当元组中只有一个元素的时候,结尾必须要加一个逗号:
t = ('solo',)或者t = 'solo', -
可以使用
tuple()函数将一个序列转换为元组:print(tuple('abc')) # ('a', 'b', 'c') print(tuple(range(4))) # (0, 1, 2, 3) -
join()函数可以用指定的分隔符将序列拼接成字符串(不光元组,适用于所有的序列拼接成字符串):join()函数的返回结果是一个字符串。- 用法:
'分隔符'.join(要拼接的序列,可以是元组、列表等)。
myTuple = ('my', "name", "is", "Bruno")print(" ".join(myTuple)) # my name is Bruno print("$".join(myTuple)) # my$name$is$Bruno与split函数正好反过来,所以可以将字符串按照指定字符拼接,也可以按照指定字符分割。
-
字符串可用的函数在元组中也大多可用,比如 index函数、count函数、len函数、判断是否存在的in操作等。
-
遍历元组也可以和遍历字符串一样使用for循环或while循环:
lst = ('a', 'b', 'c', 'd', 'e') for i in lst:print(i) -
元组中可以嵌套元组:
sales = (("Peter", (78, 70, 65)),("John", (88, 80, 85)),("Tony", (90, 99, 95)),("Henry", (80, 70, 55)),("Mike", (95, 90, 95)), )# 拿到的是内层元组中的每一个元素 for name, values in sales:print(name, values) # Peter (78, 70, 65)break# 拿到的是内层元组整体 for whole in sales:print(whole) # ('Peter', (78, 70, 65))break -
sum()函数是Python内置函数,可以计算出一个序列里所有数值的总和:test = (1, 2, 3) print(sum(test)) # 6
4.3 列表list
-
列表可以理解为可变的元组,它的使用方式跟元组差不多,区别就是列表被创建之后可以动态的增删改。(原列表可以直接被修改)
-
列表的形式是使用
[]把数据包起来,里面的数据使用逗号隔开,列表中的元素可以是任意相同/不同的类型。 -
列表的定义方式:
-
方式一:直接使用
[]将数据包起来:myList1 = [1, "is", ("Name", 2.13), ['name', 2]] -
方式二:使用
list()函数:# 将元组转换成列表 myTuple = (1,2,3,"Test") print(list(myTuple)) # [1, 2, 3, 'Test']# 将字符串转换成列表 print(list('你好啊')) # ['你', '好', '啊']
-
-
访问列表中的元素,和字符串用法一样,中括号中填入要访问的索引(支持最多三个参数)。
-
修改列表中的元素(修改的是原列表):
-
使用
append()函数向列表末尾添加元素,原列表的长度也会+1:myList1 = [1, "is", ("Name", 2.13), ['name', 2]] myList1.append('Haha') print(myList1) # 输出:[1, 'is', ('Name', 2.13), ['name', 2], 'Haha'] -
修改列表中的元素:
myList1[0] = 'Test' -
删除列表中的元素:
del myList1[0]
-
4.3.1 列表函数
列表也是一种序列,它也具有 index 和 count 函数并且支持 len 函数,这些函数的用法和元组一样,它的循环遍历也和元组一样,不再赘述。下面来介绍一下列表特有的一些函数:
- 注意:列表函数修改的都是原列表。
insert()
-
insert函数可以向列表任意位置添加元素,而append函数只能在末尾添加元素。
-
该函数的第一个参数表示在原列表的哪一个索引之前插入新元素。
lst = ['a', 'c', 'e']# 在第二个元素之前插入元素
lst.insert(1, 'b')# 在最后一个元素之前插入元素
lst.insert(-1, 'd')print(lst) # ['a', 'b', 'c', 'd', 'e']
pop()
- pop函数不加参数默认会从列表中“弹”出最后一个元素。
- 参数中可以填写具体想要弹出的索引。
lst = ['a', 'c', 'e']# 弹出最后一个元素
lst.pop()# 弹出第一个元素
lst.pop(0)print(lst) # ['c']
remove()
- 想要删除指定内容的元素,需要使用 remove 函数。
- del 只能删除指定索引的元素。
- remove 函数会从左至右找到与指定的值相匹配的第一个元素。
lst = ['a', 'c', 'e']lst.remove('c')
print(lst) # ['a', 'e']
clear()
- clear 函数会清空列表内的所有元素。
lst = ['a', 'c', 'e']
lst.clear()
print(lst) # []
extend()
- extend 函数有点像 append 函数,但 append 函数每次只能添加一个元素,而 extend 可以添加一组元素。
lst = ['a', 'c', 'e']lst.extend(['d', 'e'])
lst.extend(range(2))
print(lst) # ['a', 'c', 'e', 'd', 'e', 0, 1]
reverse()
- reverse 函数可以将整个列表反转。
lst = ['a', 'c', 'e']
lst.reverse()
print(lst) # ['e', 'c', 'a']
sort()
-
python中可以使用内置函数将字符与其对应的ASCII值互转:
print(ord('A')) # 65 print(chr(65)) # A -
sort 按照一定的规则将列表中的元素重新排序:
- 对于数值,默认按从小到大的顺序排列(谐音“上”,升序)。
- 如果想要让列表从大到小排列,可以加上
reverse=True参数(降序)。
- 如果想要让列表从大到小排列,可以加上
lst = [5,78,1,8,3] lst.sort() print(lst) # [1, 3, 5, 8, 78]lst = [5,78,1,8,3] lst.sort(reverse=True) print(lst) # [78, 8, 5, 3, 1]- 对于字符串,则会按照它们的ASCII值的顺序排列。
- sort函数会比对每个字符串的第一个字符,如果第一个字符相同,则比对第二个字符…
fruits = ['apple', 'cherry', 'banana', 'blueberry'] fruits.sort() print(fruits)- 对于复杂的元素,需要传递key参数来定义排序的基准。
- key 参数接受一个函数,给他传递一个匿名函数,函数的返回值决定依据什么来排序。
- 这个匿名函数接受一个参数,这个参数表示的是列表中的每一个元素。
- key 参数接受一个函数,给他传递一个匿名函数,函数的返回值决定依据什么来排序。
revenue = [('1月', 5610000), ('2月', 4850000), ('3月', 6220000)]# 依据元组的第二个元素(收入)降序排序 revenue.sort(key=lambda x: x[1], reverse=True) print(revenue) # 输出:[('3月', 6220000), ('1月', 5610000), ('2月', 4850000)]words = ["apple", "banana", "cherry", "date"]# 依据字符串的长度进行升序排序 words.sort(key=lambda x: len(x)) print(words) # 输出: ['date', 'apple', 'cherry', 'banana'] - 对于数值,默认按从小到大的顺序排列(谐音“上”,升序)。
copy()
- 将列表赋值给另一个变量时,实际上会创建一个指向相同列表对象的引用,也就是说两个变量都引用同一个列表对象,对列表进行的任何修改都会同时反映在两个列表中,如下所示。
list1 = [1, 2, 3, 4]
# 变量之间进行赋值
list2 = list1
list1.append(5)
# 修改list1之后list2也跟着变了
print(list2) # [1, 2, 3, 4, 5]
- 想要创建一个跟lst1一模一样的新列表,且不再受它以后操作的影响,就可以使用copy函数,如下所示。
list1 = [1, 2, 3, 4]
# 使用copy函数
list2 = list1.copy()
list1.append(5)
# 修改list1之后list2不变
print(list2) # [1, 2, 3, 4]
4.3.2 列表表达式
-
列表表达式指的是使用for循环和条件判断来生成列表元素。
- 语法:
[expression for item in iterable if condition]
# 生成列表[0, 4] [i * 2 for i in range(3) if i % 2 == 0]# 上述代码底层原理,使用了append函数 even_nums = [] for i in range(3):if i % 2 == 0:even_nums.append(i * 2)# 再来个例子 # 生成列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [i for i in range(10)] - 语法:
4.4 字典dict
-
字典中存放的是键值对,使用大括号包起来,每一行冒号左边的是键(key),右边的是值(value),每个键值对用逗号分隔开,键不可重复,值可重复。
-
字典的两种定义方式:
- 使用大括号定义键值对:
myDict = {'key1': 'value1','key2': (1, 2, 3),'key3': ['哈辉', 3.18], }- 使用
dict()函数进行转换:
myList = [('key1', 'value1'), ('key2', (1, 2, 3)), ('key3', ['哈辉', 3.18])] # 使用dict函数转换列表 myDict = dict(myList) # 结果和上述直接用花括号定义一致 -
获取字典的key的值要使用中括号把key包起来,比如
myDict['key1']- 如果是嵌套字典的话,使用两层或多层中括号即可:
myDict = {'Jay':{'语文': 88, '数学':90} } print(myDict['Jay']['语文']) # 88 -
修改字典中的值:
myDict['key1'] = 'NewValue' -
删除字典中的键值对:
del myDict['key1']
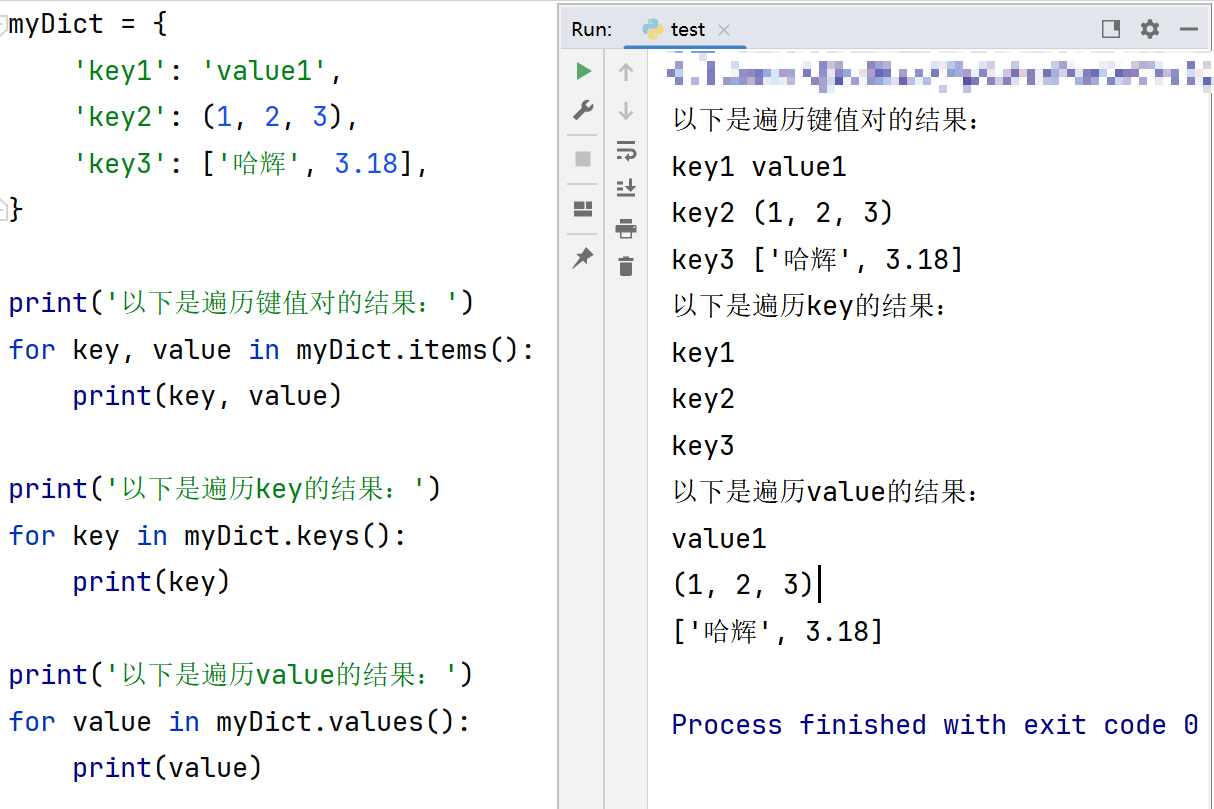
4.4.1 遍历字典
-
遍历字典时使用
items()、keys()、values()三种函数:- 三个函数分别用来获取字典的所有键值对、所有key、所有value。
- 故分别表示遍历键值对、key、value:
4.4.2 字典函数
- 字典直接进行变量的赋值和列表是一样的(修改的是同一个字典),所以也有 copy 函数,不再赘述
- 字典也有clear、len、in(是否包含某个key)等和列表通用的函数,不再赘述。
get()
- get函数用来获取key的值,第二个参数表示如果字典中不存在想要获取的key,则返回的值:
myDict.get('key1')
myDict.get('key5', 100)
4.5 集合set
-
集合在Python中是一个无序的、不重复的序列,一般用来删除重复数据,还可以计算交集、并集等。
-
集合也是使用大括号把数据包起来,而字典虽然也是大括号但都是键值对。
-
集合的两种定义方式:
- 方式一:直接使用大括号:
mySet = {1, 2, '哈哈', (3, 4)}- 方式二:使用set函数:
set()函数的参数可以是任何可迭代对象,包括但不限于元组、列表、字符串、集合、字典和生成器。它会自动消除重复元素,并保持集合中的元素无序。- 集合最常用的用法是用来消除列表或者元组中的重复元素。
myTuple = (1, 2, 3, 4, 1, 2, 3, 4) mySet = set(myTuple) # {1, 2, 3, 4} -
遍历集合和列表、元组一致,使用for循环。
-
集合也有len函数以及in关键字判断是否包含某一元素。
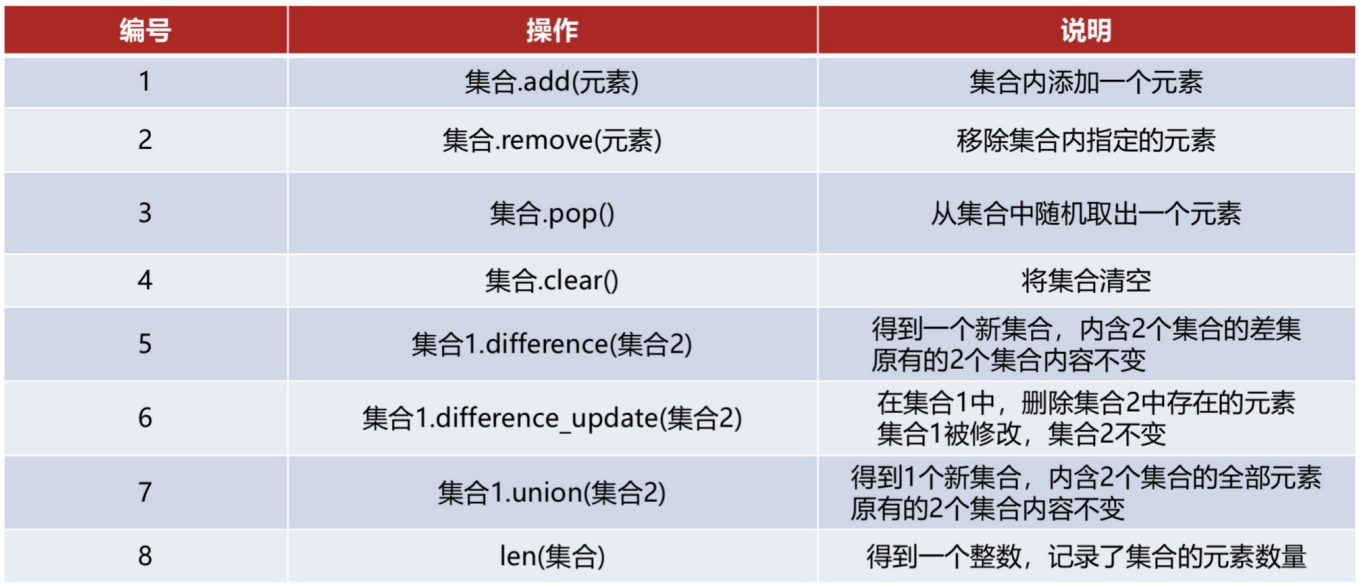
4.5.1 集合函数
增删改查
-
使用add函数向集合中添加元素,如果集合里已经有这个元素了,则什么也不做。
mySet = {1, 2, '哈哈', (3, 4)} mySet.add(5) # 并没有添加到末尾,注意集合无序 print(mySet) # {1, 2, 5, (3, 4), '哈哈'} -
已经加入集合的元素不能修改,只能删除。
- 集合的主要特性之一是其元素必须是可哈希的(hashable),为了保证哈希表的一致性,集合中的元素必须是不可变的。想要修改元素的话,可以先删除后添加。
- remove函数会从集合里删除指定元素,但如果元素不存在,则会报错。
- 如果不想报错,可以使用discard函数。
mySet = {1, 2, '哈哈', (3, 4)} mySet.remove(1) mySet.discard(2) -
使用pop函数从集合中移除并返回一个任意元素:
mySet = {1, 2, '哈哈', (3, 4)}# 可以使用pop函数来迭代一个集合 # 这样的好处是可以保证每个元素只被使用一次,不会重复使用。 while len(mySet) > 0:print(mySet.pop())# 变成空集合 print(mySet)
intersection()
- 该函数用来求交集:
s1 = {1, 2, 3}
s2 = {3, 4, 5}
s1.intersection(s2) # 3
union()
- 求并集:
print(s1.union(s2)) # {1, 2, 3, 4, 5}
issubset
- 判断是否是子集:
print(s1.issubset(s2)) # False
issuperset
- 判断是否是父集:
print(s1.issuperset(s2)) # False
集合常用函数汇总:
4.6 总结
- 字符串和元组是不可变的,列表、字典、集合都是可变的。
- 列表、字典、集合都有copy方法。
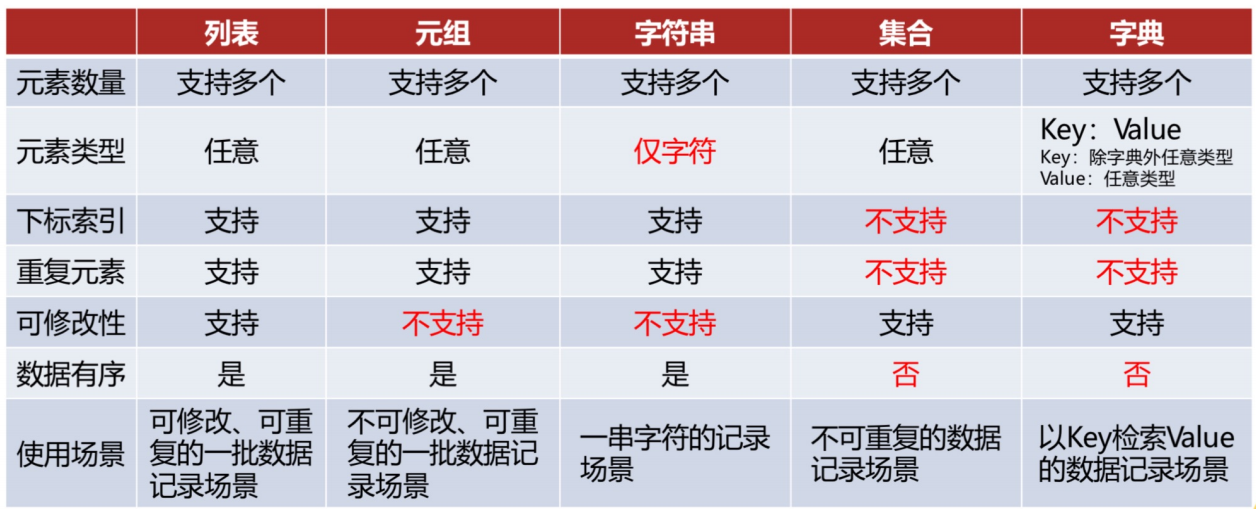
通用功能:
-
数据容器都支持for循环遍历。
-
容器都支持len方法,同时还都支持max和min方法:
- max统计容器的最大元素。
- min统计容器的最小元素。
-
容器都支持
sorted()方法进行排序,排序后都会得到list对象。- 注意是sorted方法,而不是sort方法。
myTuple = (1,4,3,2) print(sorted(myTuple, reverse=True)) # [4, 3, 2, 1]
五、补充内容
数据类型
-
type函数可以得到数据的类型:
print(type("哈哈")) # <class 'str'> print(type(3.18)) # <class 'float'> print(type([1, 2, 3])) # <class 'list'>
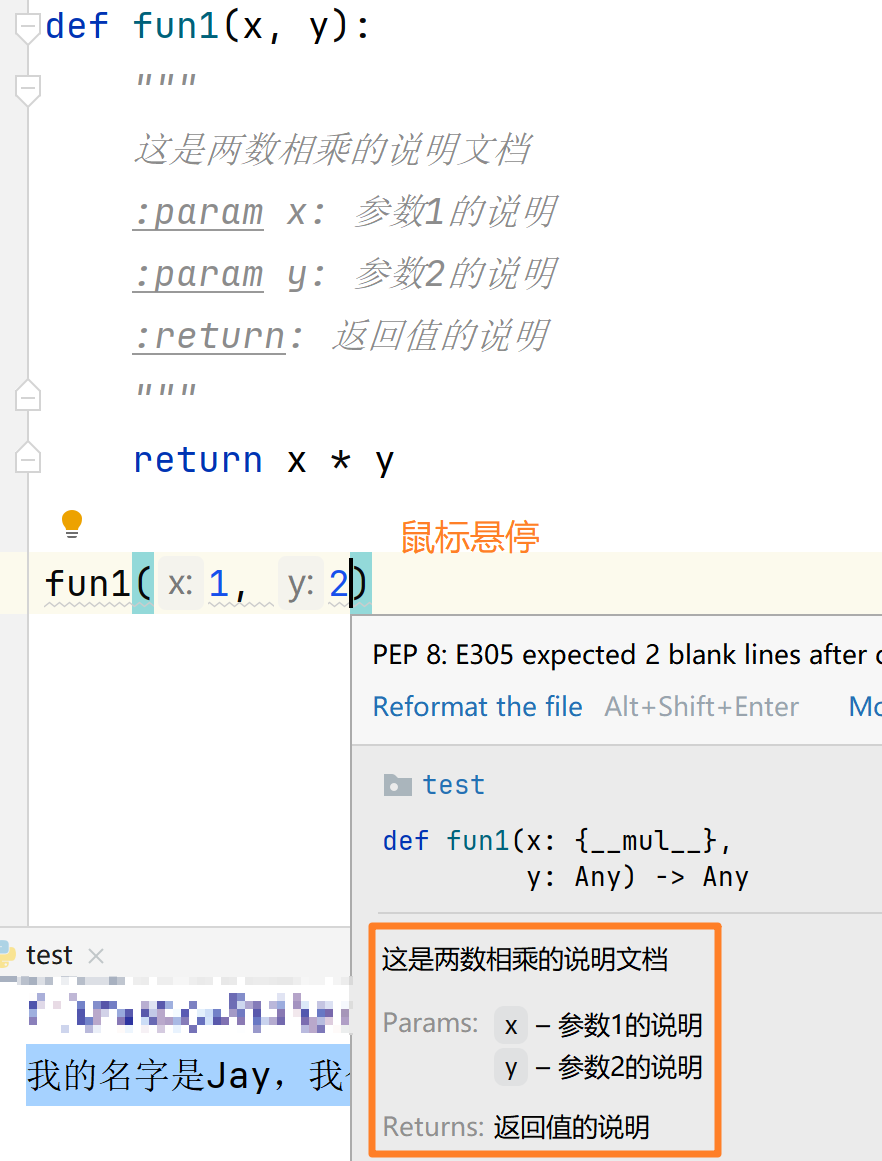
说明文档
- 可以通过多行注释给函数添加说明:
- 函数说明应该写在函数体之前。
- 函数说明的格式是
:param、:return。
局部&全局变量
- 局部变量指的是在函数体内定义的变量,函数执行完会销毁,在函数体外访问会报错。
- 函数体内对变量的修改当函数执行完出栈后,修改也不会生效。
num = 100def fuc1():num = 200print('函数体内的num值:' + str(num)) # 200fuc1()
print('函数执行完后的num值:' + str(num)) # 100
global关键字
- global可以把函数体内的变量声明为全局变量。
num = 100def fuc1():global numnum = 200print('函数体内的num值:' + str(num)) # 200fuc1()
print('函数执行完后的num值:' + str(num)) # 200
嵌套的索引

想要访问嵌套的列表,需要使用两个或多个中括号:
myList = [[1, 2, 3], [4, 5, 6]]
print(myList[0]) # [1, 2, 3]
print(myList[1][2]) # 6
相关文章:
Python教程(一):基本语法、流程控制、数据容器
Python(一) 文章目录 Python(一)一、基础语法二、数据类型2.1 字符串2.2 空值2.3 类型转换&运算符 三、流程控制3.1 条件判断3.2 循环3.2.1 while循环3.2.2 for循环 四、数据结构4.1 字符串str4.1.1 字符串的格式化输出4.1.1.…...

Spring Boot 3.x 核心注解详解与最佳实践
Spring Boot 3.x 核心注解详解与最佳实践 前言 随着Spring Boot 3.x的正式发布,这个基于Spring Framework 6的里程碑版本带来了诸多新特性。本文将深入剖析Spring Boot 3.x的核心注解体系,结合代码示例讲解其作用及使用场景,助您快速掌握新…...

【AI深度学习基础】PyTorch初探
引言 PyTorch 是由 Facebook 开源的深度学习框架,专门针对 GPU 加速的深度神经网络编程,它的核心概念包括张量(Tensor)、计算图和自动求导机制。PyTorch作为Facebook开源的深度学习框架,凭借其动态计算图和直观的API设…...

Windows下安装VMware Workstation 17并设置支持MacOS
VMware Workstation 17 介绍 VMware Workstation 17 是 VMware 公司推出的一款强大的桌面虚拟化软件,适用于 Windows 、 Linux 和FreeBSD等操作系统。它允许用户在单一物理计算机上创建、运行和管理多个虚拟机(VM),每个虚拟机都可…...

Mysql-主从搭建如何指定库表同步以及新增库表同步
背景: 当主库数据量过大,从库仅需要同步A库的所有表,并且在后续运行中,又提出需要在从库新增B库的users表进行同步。本文会详细列出过程与具体命令,并告诉你其中的深坑! 步骤一: 修改从库参数…...

爬虫逆向:脱壳工具Youpk的使用详解
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 1. Youpk 简介1.1 Youpk介绍1.2 Youpk支持场景1.3 Youpk基本流程1.4 使用 Youpk 脱壳步骤1.5 常用的脱壳工具对比2. Youpk 的安装与使用2.1 安装 Youpk2.2 使用 Youpk 脱壳3. 脱壳后的 Dex 文件分析3.1 使用 JADX 反编译…...

UE4 组件 (对话组件)
制作一个可以生成对话气泡,显示对话台词的简单组件。这个组件要的变量:台词(外部传入)。功能:开始对话(生成气泡UI) ,结束对话。 一、对话组件创建 二、开始对话事件 1、注意这里获…...
 + 哈希表)
LeetCode 2588.统计美丽子数组数目:前缀和 + 位运算(异或) + 哈希表
【LetMeFly】2588.统计美丽子数组数目:前缀和 位运算(异或) 哈希表 力扣题目链接:https://leetcode.cn/problems/count-the-number-of-beautiful-subarrays/ 给你一个下标从 0 开始的整数数组nums 。每次操作中,你可以: 选择…...

blender看不到导入的模型
参考:blender 快捷键 常见问题_blender材质预览快捷键-CSDN博客 方法一:视图-裁剪起点,设置一个很大的值 方法二:选中所有对象,对齐视图-视图对齐活动项-选择一个视图...

【慕课网wiki项目学习笔记01】Spring Boot 项目搭建
2-2 新建SpringBoot项目 一、创建SpringBoot项目 (1)在SpringBoot官网创建 (2.1)在 IDEA 中创建 Group:公司名 Artifact:项目名 创建成功后开始下载Maven依赖(选择右下角的Import Changes&…...
)
后端架构模式之-BFF(Backend-For-Frontend)
Backend-for-Frontend(BFF) 的概念与意义 1. 什么是 Backend-for-Frontend(BFF)? Backend-for-Frontend(简称 BFF)是一种后端架构模式,它为特定的前端应用(Web、移动端…...

【高分论文密码】AI大模型和R语言的全类型科研图形绘制,从画图、标注、改图、美化、组合、排序分解科研绘图每个步骤
在科研成果竞争日益激烈的当下,「一图胜千言」已成为高水平SCI期刊的硬性门槛——数据显示很多情况的拒稿与图表质量直接相关。科研人员普遍面临的工具效率低、设计规范缺失、多维数据呈现难等痛点,因此科研绘图已成为成果撰写中的至关重要的一个环节&am…...

vue3-pc-template后台管理之角色管理与功能权限配置实践
在开发企业级应用时,权限控制无疑是至关重要且不可或缺的一部分。合理的权限控制不仅能够有效保障系统的安全性,还能确保不同用户角色在系统中拥有合适的操作权限,从而提高系统的使用效率和稳定性。本文将详细介绍如何在 Vue3 项目中实现功能…...

Android Flow 示例
在Android开发的世界里,处理异步数据流一直是一个挑战。随着Kotlin的流行,Flow作为Kotlin协程库的一部分,为开发者提供了一种全新的方式来处理这些问题。今天,我将深入探讨Flow的设计理念,并通过具体的例子展示如何在实…...

前端文件加载耗时过长解决方案
从你的 Network (网络) 面板 看到,许多 JS 文件的加载时间较长(1~2秒),可能的原因如下: ✅ 可能的原因 1. 过多的 JS 请求(多个小文件加载) 你当前页面加载了很多小 JS 文件(addSi…...

Visual Studio 2022新建c语言项目的详细步骤
步骤1:点击创建新项目 步骤2:到了项目模板 --> 选择“控制台应用” (在window终端运行代码。默认打印"Hello World") --> 点击 “下一步” 步骤3:到了配置新项目模块 --> 输入“项目名称” --> 更改“位置”路径&…...

物联网系统搭建
实验项目名称 构建物联网系统 实验目的 掌握物联网系统的一般构建方法。 实验要求: 1.构建物联网系统,实现前后端的交互。 实验内容: CS模式MQTT(不带数据分析处理功能) 实现智能设备与应用客户端的交…...

PostgreSQL中的事务隔离
1. 事务隔离的概念 在数据库管理系统中,事务隔离是一项重要的功能,它能确保在并发访问数据库时事务之间能够独立运行,不会相互干扰。数据库系统通常支持不同级别的事务隔离,用来满足不同应用程序之间的需求。 2. 事务隔离的种类…...

嵌入式硬件设计SPI时需要注意什么?
嵌入式硬件设计SPI时需要注意什么? 1. 硬件设计注意事项 关键点注意事项1. 信号完整性- 缩短SCK、MOSI、MISO的走线长度,避免反射干扰。- 使用屏蔽线或差分信号(高速场景)。- 阻抗匹配(特别是高频信号,如50Ω端接)。2. 电源与地线- 电源去耦:每个SPI芯片的VCC附近放置0…...

mysql新手常见问题解决方法总结
1. 安装与配置问题 1.1 无法安装MySQL Server MySQL Server安装失败是新手常见的问题之一,以下是具体原因及解决方案: 系统要求不满足:MySQL对操作系统有最低版本要求,如Windows 7 SP1及以上、macOS 10.13及以上。若系统版本过…...

Unity3D 资源加载与卸载策略详解
前言 在Unity3D开发中,资源加载与卸载(Asset Loading & Unloading)是优化游戏性能、减少内存占用、提升用户体验的关键环节。本文将详细探讨Unity3D中的资源加载与卸载策略,并提供相关的技术详解和代码实现。 对惹ÿ…...

AcWing 蓝桥杯集训·每日一题2025·5526. 平衡细菌
5526. 平衡细菌 题意 给定一个序列 ( a i ) (a_i) (ai),每次操作可以选择一个位置 (p),令从 ( a p ) (a_p) (ap) 开始的每个数都加上一个以 (1) 或者 (-1) 为公差的从 ( 1 / − 1 ) (1 / -1) (1/−1) 开始的等差数列。求最小化让序列归零的操作…...

Android15请求动态申请存储权限完整示例
效果: 1.修改AndroidManifest.xml增加如下内容: <uses-permission android:name="android.permission.MANAGE_EXTERNAL_STORAGE" /><uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" /><uses-perm...
)
UniApp如何判断平台的多种方法(2025最新指南)
摘要:在UniApp跨平台开发中,精准判断运行环境是实现多端差异化的关键。本文将介绍6种判断平台的实用方法,涵盖编译时与运行时场景,助你轻松处理多端兼容问题。 一、为什么需要判断平台? 在UniApp跨平台开发中…...

unity学习62,尝试做第一个小游戏项目:flappy bird
目录 学习参考 1 创建1个unity 2D项目 1.1 2D项目模板选择 1.1.1 2D(built-in-Render pipeline) 1.1.2 universe 2D 1.1.3 这次选择 2D(built-in-Render pipeline) 1.2 创建项目 1.2.1 注意点 1.2.2 如果想修改项目名 2 导入美术资源包 2.1 下载一个flappy bird的…...

设计模式说明
23种设计模式说明 以下是常见的 23 种设计模式 分类及其核心思想、应用场景和简单代码示例,帮助你在实际开发中灵活运用: 一、创建型模式(5种) 解决对象创建问题,降低对象耦合。 1. 单例模式(Singleton&…...

【STM32F103ZET6——库函数】11.捕获红外信号
目录 红外原理 数据码 引导码 连发码 配置捕获引脚 使能引脚时钟 配置定时器 使能定时器时钟 配置输入捕获 中断优先级分组 配置定时器4中断 定时器中断使能 使能定时器 重写定时器中断服务函数 清空定时器中断标志位 例程 例程说明 main.h main.c HongWai…...

unity调用本地部署deepseek全流程
unity调用本地部署deepseek全流程 deepseek本地部署 安装Ollama 搜索并打开Ollama官网[Ollama](https://ollama.com/download) 点击Download下载对应版本 下载后点击直接安装 安装deepseek大语言模型 官网选择Models 选择deepseek-r1,选择对应的模型࿰…...

Anaconda 部署 DeepSeek
可以通过 Anaconda 环境部署 DeepSeek 模型,但需结合 PyTorch 或 TensorFlow 等深度学习框架,并手动配置依赖项。 一、Anaconda 部署 DeepSeek 1. 创建并激活 Conda 环境 conda create -n deepseek python3.10 # 推荐 Python 3.8-3.10 conda activate…...

Mac OS升级后变慢了,如何恢复老系统?
我的一台Mac Air闲置很久了,原因是某次系统升级后用着会卡,有差不多10年没用了。今天想试着恢复一下出厂系统,目前看这条路可以走通。记录如下: 1、去哪里下载旧版系统? https://support.apple.com/zh-cn/102662 2、…...