PyTorch基础语法万字解析
第一章:张量基础(Tensor Fundamentals)
1.1 张量创建
在PyTorch中,张量(Tensor)是用于表示数据的基本单元。它类似于NumPy中的数组,但额外支持GPU加速和自动微分功能。以下是几种创建张量的方法:
import torch# 创建全零张量,形状为3x4
zeros_tensor = torch.zeros(3, 4)
print("Zero Tensor:\n", zeros_tensor)# 创建全一张量,形状为2x3,指定数据类型为float32
ones_tensor = torch.ones(2, 3, dtype=torch.float32)
print("Ones Tensor:\n", ones_tensor)# 创建均匀分布的随机数张量,形状为5x5,值域[0, 1)
rand_tensor = torch.rand(5, 5)
print("Random Uniform Tensor:\n", rand_tensor)# 创建标准正态分布的随机数张量,形状为2x2,均值为0,标准差为1
randn_tensor = torch.randn(2, 2)
print("Random Normal Tensor:\n", randn_tensor)# 根据现有数据创建张量,并可选择性地将其放置在GPU上
data_tensor = torch.tensor([[1, 2], [3, 4]], device='cuda' if torch.cuda.is_available() else 'cpu')
print("Data Tensor:\n", data_tensor)# 特殊张量
identity = torch.eye(3) # 生成3x3单位矩阵
linspace = torch.linspace(0, 10, 5) # 在0到10之间生成5个等间隔数值的向量
print("Identity Matrix:\n", identity)
print("Linspace Vector:", linspace)torch.tensor()不仅可以从列表或数组创建张量,还可以通过requires_grad=True参数来开启梯度计算。- 使用
device参数可以指定张量创建于CPU还是GPU,这对于加速深度学习模型训练至关重要。
1.2 张量属性
每个张量都有一些关键属性,了解这些属性对于正确操作张量至关重要:
x = torch.randn(3, 4)
print(f"Shape: {x.shape}") # 输出形状,例如torch.Size([3, 4])
print(f"Data type: {x.dtype}") # 数据类型,如torch.float32
print(f"Device: {x.device}") # 存储位置,可能是cpu或cuda
print(f"Requires grad: {x.requires_grad}") # 是否跟踪梯度,默认Falseshape: 描述张量的维度大小。dtype: 指定张量元素的数据类型,影响计算精度和内存占用。device: 表示张量所在的硬件设备,可以是CPU或者GPU。requires_grad: 决定了是否对这个张量进行梯度计算,适用于神经网络训练过程中。
1.3 张量运算
张量支持广泛的数学运算,包括基本算术运算、线性代数运算以及聚合操作等。
数学运算
a = torch.tensor([1., 2.], requires_grad=True)
b = torch.tensor([3., 4.], requires_grad=True)
c = a + b # 逐元素加法
d = torch.sin(c) # 对每个元素应用sin函数
e = d.mean() # 计算所有元素的平均值矩阵运算
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 4)
matmul = torch.mm(mat1, mat2) # 矩阵乘法广播机制
广播机制使得不同形状的张量之间能够进行算术运算,前提是它们满足一定的规则:
x = torch.ones(4, 1, 3)
y = torch.ones(2, 3)
result = x + y # 广播后,结果形状为(4, 2, 3)- 广播规则允许形状不完全相同的张量进行运算,但需满足特定条件:尺寸相等或者其中一个为1。
- PyTorch中的自动微分功能依赖于
requires_grad标记的张量,使得构建复杂的神经网络成为可能。
第二章:自动微分系统(Autograd)
自动微分是现代深度学习框架的核心之一,它使得复杂的神经网络训练成为可能。PyTorch通过其autograd包提供了强大的自动微分功能。本章将深入探讨计算图的原理、梯度计算以及高阶微分等内容。
2.1 计算图原理
动态计算图是PyTorch的一个关键特性,它允许用户在运行时定义和修改计算图。与静态计算图不同,动态计算图是在程序执行过程中构建的,这为调试和实验提供了极大的灵活性。
-
构建过程: 在PyTorch中,每个操作都会创建一个节点,并连接到前一个节点上形成计算图。例如,当我们执行
y = x**3 + 2*x时,实际上是在计算图中添加了两个操作:幂运算和加法。 -
叶子节点与非叶子节点: 叶子节点是指那些直接由用户创建或指定的张量,而非叶子节点则是通过一系列操作从叶子节点派生出来的。叶子节点通常具有
requires_grad=True标志,以便跟踪其参与的所有操作以供后续求导使用。 -
requires_grad标志位的级联特性: 当对某个张量设置了
requires_grad=True后,所有基于此张量进行的操作生成的新张量也会自动设置requires_grad=True,除非显式地关闭这个标志。这种级联机制确保了梯度能够沿着计算路径正确传播。
x = torch.tensor(2.0, requires_grad=True)
print(x.requires_grad) # True
y = x ** 3 + 2 * x
print(y.requires_grad) # True2.2 梯度计算
一旦计算图构建完成,我们就可以利用backward()方法来计算梯度。对于标量输出的情况,可以直接调用backward();而对于向量输出,则需要提供额外的参数。
x = torch.tensor(2.0, requires_grad=True)
y = x**3 + 2*x
y.backward() # 自动计算dy/dx
print(x.grad) # 输出应为14.0 (即3*2^2 + 2)这里,backward()函数根据链式法则自动计算了y相对于x的导数,并将其存储在x.grad属性中。
对于更复杂的情形,比如当输出是一个向量而不是一个标量时,我们需要传递一个权重向量给backward():
x = torch.tensor([1., 2., 3.], requires_grad=True)
y = x ** 2
gradient_output = torch.tensor([1., 1., 1.]) # 权重向量
y.backward(gradient=gradient_output)
print(x.grad) # 应输出[2, 4, 6]2.3 高阶微分
有时我们需要计算更高阶的导数,如二阶导数。为此,可以使用torch.autograd.grad函数,并且在第一次求导时设置create_graph=True以便保留计算图用于后续求导。
# 二阶导数计算
x = torch.tensor(3.0, requires_grad=True)
y = x**3
grad1 = torch.autograd.grad(y, x, create_graph=True)[0] # dy/dx = 3x²
grad2 = torch.autograd.grad(grad1, x)[0] # d²y/dx² = 6x → 18.0
print(grad2) # 输出18.0 在这个例子中,我们首先计算了一阶导数3x²,然后基于这个结果进一步求解得到了二阶导数6x。
第三章:神经网络模块(nn.Module)深度解析
3.1 模型定义范式
3.1.1 nn.Module的底层机制
PyTorch的神经网络模块化设计基于面向对象编程范式,其核心类nn.Module实现了以下关键特性。
-
参数自动化管理:
-
自动追踪所有继承自
nn.Parameter的对象 -
通过
parameters()方法实现参数遍历 -
示例验证:
-
class TestModule(nn.Module):def __init__(self):super().__init__()self.weight = nn.Parameter(torch.randn(3,3))self.bias = torch.randn(3) # 不会被识别为参数mod = TestModule()
print(list(mod.parameters())) # 仅显示weight参数2.计算图构建:
-
动态构建前向传播计算图
-
自动维护反向传播所需的梯度计算链
-
可视化理解:
Input│ Linear Layer (权重参数)│ ReLU激活│ Output
3.设备管理:
-
统一管理模块涉及的张量设备
-
通过
.to(device)实现整体迁移 -
跨设备验证:
model = MLP(784, 256, 10).to('cuda:0')
print(next(model.parameters()).device) # cuda:03.1.2 模型定义标准范式
完整模型定义应包含以下要素:
import torch
import torch.nn as nnclass DeepModel(nn.Module):def __init__(self, config):"""初始化DeepModel类。参数:config -- 配置参数字典,用于根据需要调整模型结构或参数"""super().__init__() # 调用父类(nn.Module)的构造函数,这是必须的self.config = config # 保存配置信息到实例变量中# 定义特征提取子模块# 使用Sequential容器来封装一系列层,简化前向传播定义self.feature_extractor = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3), # 第一层:卷积层,输入通道数为3,输出通道数为64,卷积核大小为3x3nn.BatchNorm2d(64), # 第二层:二维批量归一化层,处理64个通道的数据nn.ReLU(inplace=True) # 第三层:ReLU激活函数,inplace=True表示直接在原张量上进行操作以节省内存)# 定义注意力权重参数# 使用nn.Parameter确保该参数能够被优化器更新self.attention_weights = nn.Parameter(torch.randn(64, 64)) # 随机初始化一个64x64的权重矩阵def forward(self, x):"""前向传播函数,定义数据如何通过网络。参数:x -- 输入张量,预期是一个形状为(batch_size, channels, height, width)的4D张量返回:经过特征提取和注意力机制处理后的输出"""# 输入验证,确保输入是4维张量assert x.ndim == 4, "Input must be 4D tensor"# 通过特征提取层features = self.feature_extractor(x)# 注意力机制应用:将特征映射与注意力权重矩阵相乘# 这里假设features经过reshape或其他方式调整后能与attention_weights正确相乘attended = torch.matmul(features, self.attention_weights)# 应用clamp限制输出最小值为0,模拟ReLU激活效果(这里可能需要根据实际情况调整维度兼容性)return attended.clamp(min=0)最佳实践指南:
-
模块化设计原则:
-
单个模块不超过200行代码
-
使用
nn.Sequential组织简单层序列 -
复杂结构使用自定义子模块
-
-
前向传播规范:
-
禁止在
forward中修改参数值 -
避免在
forward中创建新参数 -
推荐使用函数式接口(如
F.relu)增加灵活性
-
-
类型一致性检查:
def forward(self, x):# 检查输入是否为torch.Tensor类型,确保输入数据格式正确if not isinstance(x, torch.Tensor):raise TypeError("Input must be torch.Tensor")# 如果输入的数据类型不是float32,则将其转换为float32类型。# 这一步很重要,因为模型中的运算通常是基于浮点数进行的,# 确保输入数据类型的一致性有助于避免潜在的计算错误或性能问题。if x.dtype != torch.float32:x = x.float() # 将输入数据类型转换为float32# ...后续处理3.1.3 复杂结构构建
案例1:残差连接
import torch.nn as nn
import torch.nn.functional as Fclass ResidualBlock(nn.Module):def __init__(self, in_channels):"""初始化残差块。参数:in_channels -- 输入通道数,同时也是输出通道数,因为这是残差块的特点之一"""super().__init__() # 调用父类(nn.Module)的构造函数# 定义第一个卷积层,输入和输出通道数相同,使用3x3卷积核,padding设置为1以保持空间尺寸不变self.conv1 = nn.Conv2d(in_channels, in_channels, 3, padding=1)# 定义第二个卷积层,其配置与第一个卷积层相同self.conv2 = nn.Conv2d(in_channels, in_channels, 3, padding=1)# 定义批量归一化层,用于处理卷积后的特征图self.bn = nn.BatchNorm2d(in_channels)def forward(self, x):"""前向传播函数,定义数据如何通过残差块。参数:x -- 输入张量返回:经过残差块处理后的输出张量"""residual = x # 保存输入张量作为残差连接的一部分# 第一步:通过第一层卷积层,然后应用ReLU激活函数x = F.relu(self.conv1(x))# 第二步:通过第二层卷积层,接着进行批量归一化x = self.bn(self.conv2(x))# 第三步:将原始输入(残差)加到经过两次卷积处理的结果上,并应用ReLU激活函数return F.relu(x + residual)案例2:动态计算路径
import torch.nn as nn
import torch.nn.functional as Fclass DynamicNet(nn.Module):def __init__(self):"""初始化DynamicNet类。该网络由一系列线性层(全连接层)组成,这些层可以通过不同的路径进行选择性地执行。"""super().__init__() # 调用父类(nn.Module)的构造函数# 使用ModuleList来包含5个相同的线性层(每个输入和输出大小均为10)# ModuleList允许我们动态地选择和使用这些层中的任意一个self.blocks = nn.ModuleList([nn.Linear(10, 10) for _ in range(5) # 创建5个线性层,每个层有10个输入和10个输出])def forward(self, x, route):"""前向传播函数,定义数据如何根据给定的路径通过网络。参数:x -- 输入张量route -- 一个列表或元组,指示应按顺序使用的线性层索引返回:经过指定路径处理后的输出张量"""# 根据输入的route参数决定计算路径# 对于route中的每个索引i,依次选取对应的线性层进行处理for i in route:# 对输入x应用第i个线性层,然后使用ReLU激活函数x = F.relu(self.blocks[i](x))# 返回经过所选路径处理后的最终输出return x3.1.4 模型检查与调试
-
计算图可视化:
import torch from torchviz import make_dotdef visualize_computation(x):"""可视化给定张量的计算图。参数:x -- 一个PyTorch张量,通常代表模型的某个输出或中间结果返回:dot -- 计算图的可视化表示,可以用于展示或保存为图片文件"""# 使用torchviz.make_dot创建x的计算图,并自动管理资源(通过with语句)with make_dot(x) as dot:# 返回生成的计算图对象,它包含了所有必要的信息来可视化计算过程return dot -
前向传播追踪:
with torch.autograd.graph.saved_tensors_hooks():# 使用上下文管理器torch.autograd.graph.saved_tensors_hooks来包裹模型的前向传播过程。# 这允许我们在执行过程中捕获所有中间张量(即,在前向传播期间计算并保存以供后向传播使用的张量)。out = model(inputs)# 执行模型的前向传播,将输入数据inputs传递给模型,并获取输出out。# 在这个过程中,所有必要的中间张量都会被自动捕获并保存。graph = torch.autograd.graph.saved_tensors# 获取在前向传播过程中保存的所有中间张量。# 这些张量对于理解模型的行为、调试或进一步分析计算图非常有用。 -
设备一致性检查:
def check_device_consistency(module):"""检查给定模块的所有参数是否位于同一设备上。参数:module -- 一个nn.Module实例,代表要检查的模型或子模块如果发现模块的参数分布在多个设备上,则抛出运行时错误。这有助于确保模型的所有部分都在同一个设备(如CPU或GPU)上,避免潜在的性能问题或错误。"""# 遍历模块的所有参数,并收集它们所在的设备到一个集合中。# 使用集合是因为它自动过滤掉重复的设备,只保留唯一的设备标识。devices = {p.device for p in module.parameters()}# 如果集合中的设备数量大于1,说明参数分布在多个设备上if len(devices) > 1:# 抛出运行时错误,提示用户参数位于多个设备上的问题raise RuntimeError("Parameters on multiple devices")3.2 参数管理
3.2.1 参数访问机制
PyTorch提供多层级参数访问接口:
-
基础访问方式:
# 获取所有参数迭代器
for param in model.parameters():print(param.shape)# 命名参数访问
for name, param in model.named_parameters():print(f"{name}: {param.size()}")2.递归访问子模块:
def recursive_parameters(module):for child in module.children():yield from child.parameters()3.选择性过滤:
# 获取所有偏置项
biases = [p for name, p in model.named_parameters() if 'bias' in name]3.2.2 参数冻结技术
方案对比表:

高级冻结模式:
def freeze_by_pattern(model, pattern):for name, param in model.named_parameters():if re.search(pattern, name):param.requires_grad_(False)freeze_by_pattern(model, r'\.bn\d+\.') # 冻结所有BN层3.2.3 参数初始化策略
PyTorch标准初始化方法库:
# 均匀初始化
nn.init.uniform_(weight, a=0, b=1)# 正交初始化
nn.init.orthogonal_(weight)# 截断正态分布
nn.init.trunc_normal_(weight, mean=0, std=0.1)# 自定义初始化
def my_init(tensor):with torch.no_grad():return tensor.normal_().clamp_(-2,2)nn.init._no_grad_trunc_normal_(weight, mean=0, std=1, a=-2, b=2)分层初始化案例:
def init_weights(m):if isinstance(m, nn.Linear):nn.init.xavier_normal_(m.weight)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Conv2d):nn.init.kaiming_uniform_(m.weight)model.apply(init_weights)3.2.4 参数保存与恢复
-
完整模型保存:
torch.save(model, 'model.pth') # 问题:包含类定义路径信息,可能引发版本兼容问题 -
状态字典保存(推荐):
torch.save({'model_state': model.state_dict(),'optim_state': optimizer.state_dict(),'config': model.config }, 'checkpoint.pth')
3.2.5 参数共享技术
import torch
import torch.nn as nnclass SharedWeightModel(nn.Module):def __init__(self):"""初始化SharedWeightModel类。该模型演示了如何在不同层之间共享权重。"""super().__init__() # 调用父类(nn.Module)的构造函数# 定义一个共享权重参数,形状为10x10,使用随机数初始化self.shared_weight = nn.Parameter(torch.randn(10, 10))# 定义第一个线性层,输入和输出大小均为10self.layer1 = nn.Linear(10, 10)# 将layer1的权重设置为共享权重,实现权重共享# 这意味着layer1将使用self.shared_weight作为其权重矩阵self.layer1.weight = self.shared_weight # 权重共享def forward(self, x):"""前向传播函数,定义数据如何通过网络。参数:x -- 输入张量返回:经过线性层和矩阵乘法处理后的输出张量"""# 第一步:通过第一个线性层(其权重已设为共享权重),对输入x进行变换x = self.layer1(x)# 第二步:将经过线性层处理的结果与共享权重的转置进行矩阵乘法# 这里使用转置是为了匹配矩阵乘法的维度要求x = torch.matmul(x, self.shared_weight.T)# 返回最终结果return x3.3 高级话题
3.3.1 混合精度训练
scaler = torch.cuda.amp.GradScaler()for inputs, labels in dataloader:with torch.autocast(device_type='cuda', dtype=torch.float16):outputs = model(inputs)loss = criterion(outputs, labels)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()3.3.2 模型并行化
class ParallelModel(nn.Module):def __init__(self):super().__init__()self.part1 = nn.Linear(1024, 2048).to('cuda:0')self.part2 = nn.Linear(2048, 1024).to('cuda:1')def forward(self, x):x = self.part1(x.to('cuda:0'))x = self.part2(x.to('cuda:1'))return x.to('cuda:0')3.3.3 梯度检查
from torch.autograd import gradcheckinputs = (torch.randn(20,20,dtype=torch.double, requires_grad=True),)
test = gradcheck(nn.Linear(20,10).double(), inputs, eps=1e-6, atol=1e-4)
print(test) # 输出应为True第四章:数据管道(Data Pipeline)深度解析
4.1 数据集抽象
4.1.1 Dataset类核心原理
PyTorch数据管道的基石是Dataset抽象类,其设计遵循以下原则:
-
惰性加载机制:
-
仅在
__getitem__调用时加载数据 -
支持大规模数据集处理
-
内存优化示意图:
-
原始数据存储 → 索引映射表 → 按需加载
(磁盘/数据库) (内存) (GPU显存)多模态支持:
class MultiModalDataset(Dataset):def __getitem__(self, idx):return {'image': self.images[idx],'text': self.texts[idx],'audio': self.audios[idx],'label': self.labels[idx]}分布式训练兼容:
# 自动处理分片
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)4.1.2 高级数据集模式
模式1:流式数据集
class StreamingDataset(Dataset):def __init__(self, data_path):self.data_path = data_pathself.index_map = self._build_index()def _build_index(self):# 建立文件偏移量索引return [(filename, offset) for ...]def __getitem__(self, idx):filename, offset = self.index_map[idx]with open(filename, 'rb') as f:f.seek(offset)return pickle.load(f)模式2:内存映射数据集
class MMapDataset(Dataset):def __init__(self, file_path):self.data = np.memmap(file_path, dtype='float32', mode='r')self.sample_size = 1024def __getitem__(self, idx):start = idx * self.sample_sizeend = (idx+1) * self.sample_sizereturn torch.from_numpy(self.data[start:end])4.1.3 数据预处理管道
from torchvision import transforms
from torch.utils.data import Datasetclass ProcessingPipeline:def __init__(self):"""初始化ProcessingPipeline类。定义了一系列用于图像预处理的变换,并将它们组合在一起。"""# 使用transforms.Compose将一系列图像变换操作组合成一个处理流程self.transforms = transforms.Compose([RandomResizedCrop(224), # 随机裁剪并调整大小到224x224ColorJitter(0.4, 0.4, 0.4), # 对图像的颜色、对比度和饱和度进行随机扰动RandomHorizontalFlip(), # 以50%的概率水平翻转图像transforms.ToTensor(), # 将PIL图像或numpy.ndarray转换为tensortransforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化图像张量])def __call__(self, sample):"""实现__call__方法,使类实例可以像函数一样被调用。参数:sample -- 包含图像数据的字典返回:经过预处理后的样本字典"""# 应用定义好的图像变换流程到样本中的'image'项,并更新样本sample['image'] = self.transforms(sample['image'])return sampleclass CustomDataset(Dataset):def __init__(self, pipeline):"""初始化CustomDataset类。参数:pipeline -- 图像预处理流水线,类型为ProcessingPipeline"""self.pipeline = pipeline # 保存传入的图像预处理流水线def __getitem__(self, idx):"""实现__getitem__方法,支持通过索引访问数据集中的元素。参数:idx -- 数据集中的索引返回:经过预处理后的数据样本"""# 加载原始数据(具体实现未给出)raw_data = self._load_raw(idx)# 使用预处理流水线对原始数据进行处理,并返回结果return self.pipeline(raw_data)4.2 数据加载优化
4.2.1 DataLoader架构解析
核心组件工作流程:
-
主进程:初始化数据加载器
-
子进程:
-
通过
worker_init_fn初始化 -
使用
collate_fn整理批次 -
通过共享内存传递数据
-
-
CUDA流:异步数据传输
4.2.2 关键参数优化指南

optim_loader = DataLoader(dataset,batch_size=256,num_workers=8,pin_memory=True,prefetch_factor=4,persistent_workers=True,collate_fn=custom_collate
)4.2.3 高级批处理技术
动态填充(Dynamic Padding)
def collate_pad(batch):max_len = max(len(x['text']) for x in batch)padded_text = [x['text'] + [0]*(max_len-len(x['text'])) for x in batch]return {'text': torch.tensor(padded_text),'label': torch.tensor([x['label'] for x in batch])}混合精度批处理
def mixed_precision_collate(batch):images = torch.stack([x[0].to(torch.float16) for x in batch])labels = torch.stack([x[1].to(torch.int64) for x in batch])return images, labels4.2.4 多GPU加载策略
数据并行
在数据并行加载中,使用了DataLoader结合DistributedSampler来实现。具体来说,给定一个数据集dataset,通过设置sampler=DistributedSampler(dataset)来确保在分布式训练环境下每个GPU或进程都能访问到数据集的不同子集。这样可以避免多个进程加载相同的数据,提高数据加载效率。此外,设置了batch_size=per_gpu_batch用于指定每个GPU上的批次大小,并且通过num_workers=num_workers // world_size来分配工作线程数,这里的world_size通常指的是参与训练的GPU或进程总数。
流水线并行
对于流水线并行,定义了一个名为PipelineLoader的类。该类旨在支持一系列数据加载器(loaders)之间的流水线式操作。在初始化时,它接收多个数据加载器作为输入,并为每个加载器创建一个迭代器,保存在self.stages列表中。当遍历PipelineLoader实例时,首先从第一个阶段开始,逐个向后续阶段传递数据(batch)。每个阶段通过调用stage.send(batch)方法处理传入的数据,并将处理结果传递给下一个阶段,直到最后一个阶段处理完毕后产出最终结果(yield batch)。这种方式可以有效利用不同阶段的计算资源,尤其是在某些阶段的处理速度明显慢于其他阶段的情况下,提升整体的数据处理效率。
但send方法并非为python的方法 我们只是举了一个例子用于解释
# 数据并行加载
loader = DataLoader(dataset,sampler=DistributedSampler(dataset),batch_size=per_gpu_batch,num_workers=num_workers // world_size
)# 流水线并行
class PipelineLoader:def __init__(self, loaders):self.stages = [iter(l) for l in loaders]def __iter__(self):batch = Nonefor stage in self.stages:batch = stage.send(batch)yield batch4.3 性能优化技巧
4.3.1 数据预取模式
class PrefetchLoader:def __init__(self, loader, device):self.loader = loaderself.device = deviceself.stream = torch.cuda.Stream()def __iter__(self):for batch in self.loader:with torch.cuda.stream(self.stream):batch = to_device(batch, self.device)yield batch4.3.2 内存优化策略
共享内存缓存:
shm = torch.multiprocessing.Manager().dict()
def worker_init_fn(worker_id):if worker_id == 0:shm['data'] = load_all_data()torch.multiprocessing.barrier()分块加载机制:
class ChunkedLoader:def __init__(self, dataset, chunk_size=1000):self.chunks = [dataset[i:i+chunk_size] for i in range(0, len(dataset), chunk_size)]def __iter__(self):for chunk in self.chunks:yield from DataLoader(chunk, num_workers=0)4.4 调试与错误处理
4.4.1 常见问题排查
# 数据损坏检测
def validate_sample(sample):if torch.isnan(sample['image']).any():raise ValueError("Invalid image data at index {}".format(idx))# 死锁检测
import faulthandler
faulthandler.enable()第五章:训练流程(Training Loop)
5.1 典型训练结构
在深度学习中,模型的训练过程通常遵循一个典型的工作流,包括定义模型、损失函数、优化器,以及迭代地通过数据集进行前向传播、计算损失、反向传播和参数更新。下面是一个典型的训练结构示例及其详细注释。
# 定义模型实例
model = Model()# 定义损失函数,这里使用交叉熵损失函数,适用于分类任务
criterion = nn.CrossEntropyLoss()# 定义优化器,Adam优化器被广泛用于加速训练过程,并且对初始学习率不那么敏感
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)# 训练循环,外层循环遍历epoch,内层循环遍历dataloader中的batch
for epoch in range(100): # 进行100个epoch的训练model.train() # 设置模型为训练模式,这会影响dropout和batch normalization的行为for batch in dataloader: # 遍历每个batch的数据inputs = batch['features'].to(device) # 将输入特征移动到指定设备(CPU或GPU)labels = batch['target'].to(device) # 同样将标签移动到指定设备outputs = model(inputs) # 前向传播:计算模型输出loss = criterion(outputs, labels) # 计算损失值,衡量模型预测与真实标签之间的差距optimizer.zero_grad() # 清空梯度缓存,避免累加梯度loss.backward() # 反向传播:计算每个参数的梯度optimizer.step() # 根据计算出的梯度更新模型参数# 损失函数L可表示为:# L = -Σ(y_true * log(y_pred))# 其中y_true是真实的类别标签,y_pred是模型预测的概率分布。5.2 验证与测试
在训练过程中定期评估模型性能是非常重要的,这样可以监控模型是否过拟合或欠拟合,并据此调整超参数。验证和测试阶段通常禁用梯度计算以节省内存并加快速度。
# 设置模型为评估模式
model.eval()with torch.no_grad(): # 禁用梯度计算,减少内存占用并加速推理total_correct = 0 # 统计正确预测的数量for val_batch in val_loader: # 遍历验证集的每个batchinputs = val_batch['features'].to(device) # 移动输入特征到指定设备labels = val_batch['target'].to(device) # 移动标签到指定设备outputs = model(inputs) # 前向传播:计算模型输出preds = torch.argmax(outputs, dim=1) # 获取每行的最大值索引作为预测类别# 统计正确预测的数量total_correct += (preds == labels).sum().item()# 计算准确率accuracy = total_correct / len(val_dataset)# 准确率Acc可表示为:# Acc = correct_predictions / total_predictions# 其中correct_predictions是在验证集中正确预测的样本数,total_predictions是验证集中的总样本数。第六章:模型部署(Model Deployment)
在深度学习项目中,完成模型训练后,下一步通常是将模型部署到生产环境中,以便进行实际应用。这一过程包括模型的保存与加载、转换为适合部署的形式(如TorchScript),以及最终部署到目标平台。
6.1 模型保存与加载
保存和加载模型是确保模型可以在不同环境中使用的关键步骤。PyTorch提供了多种方式来保存模型的状态,其中最推荐的方式是保存模型的状态字典,这样可以更灵活地恢复训练或推理。
# 保存完整模型
# 直接保存整个模型结构和参数,但不推荐用于长期存储或跨版本兼容性。
torch.save(model, 'model.pth')# 保存状态字典(推荐方式)
# 保存模型参数和优化器状态,便于后续恢复训练或仅用于推理。
torch.save({'model_state': model.state_dict(), # 保存模型的所有参数'optimizer_state': optimizer.state_dict() # 同时保存优化器状态
}, 'checkpoint.pth')# 加载模型
model = Model() # 初始化一个新模型实例
checkpoint = torch.load('checkpoint.pth') # 加载之前保存的checkpoint文件
model.load_state_dict(checkpoint['model_state']) # 使用保存的参数更新模型
optimizer.load_state_dict(checkpoint['optimizer_state']) # 如果需要继续训练,还需恢复优化器状态# 注意:如果是在不同的设备上加载模型(例如从GPU切换到CPU),需要添加map_location参数:
# checkpoint = torch.load('checkpoint.pth', map_location=torch.device('cpu'))6.2 TorchScript
为了提高模型在生产环境中的性能和可移植性,PyTorch引入了TorchScript,它可以将PyTorch模型转换为一种独立于Python运行时的格式,从而支持更多的部署场景。
import torch# 假设我们有一个已经训练好的模型实例:model 和一个示例输入:example_input
# 追踪模型
# 通过提供一个具体的输入样例,追踪模型的前向计算图,生成优化后的模型表示。
traced_model = torch.jit.trace(model, example_input)# 脚本化
# 将模型定义直接转换为TorchScript代码,适用于包含控制流的模型。
scripted_model = torch.jit.script(model)# 保存部署模型
# 保存追踪或脚本化的模型到磁盘,方便后续加载和部署。
traced_model.save('model.pt') # 保存追踪后的模型
# scripted_model.save('scripted_model.pt') # 或者保存脚本化的模型# 加载已保存的TorchScript模型
loaded_model = torch.jit.load('model.pt') # 加载模型
output = loaded_model(example_input) # 使用加载的模型进行预测# 注释:
# - traced_model 和 scripted_model 提供了两种不同的方式来转换模型为TorchScript格式。
# - "trace" 方法更适合简单的前馈网络,因为它依赖于具体的输入样例来记录操作。
# - "script" 方法更加灵活,能够处理复杂的逻辑和循环等,但它要求模型代码符合TorchScript的语言特性。第七章:性能优化(Performance Tuning)
为了提高深度学习模型的训练效率和推理速度,优化策略是必不可少的一部分。本章节将探讨两种常见的性能优化方法:混合精度训练和并行计算。
7.1 混合精度训练
混合精度训练是一种利用半精度浮点数(FP16)来加速训练过程同时减少显存占用的技术。通过这种方法,可以显著加快GPU上的计算速度,并允许更大规模的模型训练或在相同的硬件上训练更大的批次大小。
import torch
from torch.cuda.amp import GradScaler, autocast# 初始化梯度缩放器
# GradScaler用于自动调整损失比例以防止梯度下溢或上溢。
scaler = GradScaler()for inputs, labels in dataloader: # 遍历数据集中的每个batch# 使用autocast上下文管理器启用自动混合精度# 在此上下文中,运算符会根据需要自动选择合适的精度with autocast():outputs = model(inputs) # 前向传播:计算模型输出loss = criterion(outputs, labels) # 计算损失值# 反向传播与参数更新scaler.scale(loss).backward() # 缩放损失值,然后执行反向传播scaler.step(optimizer) # 更新模型参数scaler.update() # 根据最近几次迭代的表现调整缩放比例# 注释:
# - autocast() 自动转换某些操作为半精度,对于其他操作保持全精度(FP32),以确保数值稳定性。
# - GradScaler 的 scale 方法通过乘以一个大的标量来防止梯度值过小导致的下溢问题。
# - 这种方法特别适用于现代GPU架构,如NVIDIA Volta和Ampere系列,它们对FP16有专门的硬件加速支持。7.2 并行计算
为了充分利用多GPU或多节点集群的强大计算能力,PyTorch提供了多种并行计算的方式,包括数据并行(Data Parallelism)和分布式数据并行(Distributed Data Parallel)。
分布式数据并行(Distributed Data Parallel)
相比4.2.4的数据并行,分布式数据并行更加高效,尤其适合大规模集群环境。它不仅能够更均匀地分布工作负载,还减少了通信开销,并且支持多节点训练。
import torch.distributed as dist
import torch.nn.parallel as parallel# 初始化分布式环境(通常在每个进程中调用)
dist.init_process_group(backend='nccl') # 'nccl' 是针对NVIDIA GPU优化的后端# 将模型包装在DistributedDataParallel中
model = parallel.DistributedDataParallel(model)for inputs, labels in dataloader:outputs = model(inputs) # 前向传播:计算模型输出loss = criterion(outputs, labels) # 计算损失值optimizer.zero_grad() # 清空之前的梯度loss.backward() # 反向传播:计算梯度optimizer.step() # 更新模型参数# 注意事项:
# - DistributedDataParallel 需要在每个参与训练的进程中分别初始化,并且每个进程负责一部分数据集。
# - 初始化过程组时指定的 backend 参数应根据你的硬件环境进行选择,例如 'nccl' 对于 NVIDIA GPU 更加高效。
第八章:调试技巧(Debugging Techniques)
在开发深度学习模型的过程中,调试是确保模型正确性和性能的关键步骤。本章节将介绍两种重要的调试技术:梯度检查和数值稳定性检查。
8.1 梯度检查
梯度检查是一种验证反向传播实现是否正确的有效方法。通过比较有限差分法计算的梯度与自动微分得到的梯度,可以检测出潜在的实现错误。PyTorch 提供了 gradcheck 函数来简化这一过程。
from torch.autograd import gradcheck# 创建一个双精度浮点数类型的随机输入张量,并设置requires_grad=True以便追踪其上的操作
input = torch.randn(3, dtype=torch.double, requires_grad=True)# 使用gradcheck函数来验证给定函数(此处为torch.sin)的梯度计算是否正确
# 参数包括待检验的函数、输入变量以及用于数值微分的步长eps
test = gradcheck(torch.sin, (input,), eps=1e-6)print(test) # 如果梯度计算正确,则输出True;否则输出False# 注释:
# - gradcheck 是一种基于有限差分的方法来近似计算梯度,并将其与PyTorch的自动求导结果进行比较。
# - eps 参数决定了数值微分时使用的步长,较小的值可以提高精度但可能会增加计算误差的风险。
# - 将输入张量的数据类型设为double可以提高数值精度,有助于更准确地进行梯度检查。8.2 数值稳定性检查
数值稳定性是指算法在面对有限精度的计算机算术运算时仍能保持稳定的能力。对于深度学习模型来说,确保数值稳定性至关重要,以避免诸如梯度消失、梯度爆炸以及NaN值等问题。
# 检测NaN值
# 在训练过程中定期检查张量是否包含NaN值是一个好习惯,因为这通常意味着存在数值不稳定的问题。
if torch.isnan(tensor).any():raise ValueError("Tensor contains NaN values")# 可采取措施如调整学习率、检查数据预处理步骤或修改模型结构等。# 梯度爆炸检测
# 当模型参数的梯度过大时,可能导致权重更新过大,从而引起训练过程中的不稳定性。
grad_norms = [p.grad.norm() for p in model.parameters()]
if max(grad_norms) > 1e4: # 设定一个阈值,超过该值认为发生了梯度爆炸print("Gradient explosion detected!")# 解决方案可能包括使用梯度裁剪(gradient clipping)、降低学习率或改进模型架构等。# 扩展示例:梯度裁剪实现
def clip_gradients(model, max_norm):"""对模型的所有参数梯度进行裁剪,防止梯度爆炸。参数:model -- 要应用梯度裁剪的模型max_norm -- 梯度的最大范数限制"""parameters = list(filter(lambda p: p.grad is not None, model.parameters()))total_norm = 0for p in parameters:param_norm = p.grad.data.norm(2)total_norm += param_norm.item() ** 2total_norm = total_norm ** (1. / 2)clip_coef = max_norm / (total_norm + 1e-6)if clip_coef < 1:for p in parameters:p.grad.data.mul_(clip_coef)# 在训练循环中调用clip_gradients函数
optimizer.zero_grad()
loss.backward()
clip_gradients(model, max_norm=5) # 设置最大梯度范数为5
optimizer.step()以上就是关于pytorch的相关基础内容 如有不对 欢迎评论区指正 !
更多文章请关注小lo爱吃棒棒糖主页!
相关文章:
PyTorch基础语法万字解析
第一章:张量基础(Tensor Fundamentals) 1.1 张量创建 在PyTorch中,张量(Tensor)是用于表示数据的基本单元。它类似于NumPy中的数组,但额外支持GPU加速和自动微分功能。以下是几种创建张量的方…...

eclipse查看源码
查看 Collection 源码的步骤 打开 Eclipse。 在代码中定位到 Collection 接口: 例如,在代码中输入 Collection,然后按住 Ctrl 键并单击 Collection。 或者直接在代码中使用 Collection 的地方按 F3 键。 如果源码已关联: Ecl…...

robot:生而为奴
英文单词 robot,含义是”机器人“。 robot n.机器人 但其实,robot 这个单词的字面义,是生而为奴: robot rob打劫、搜刮 ot (天生)被剥削者 生而为奴 单词 bot,也指机器人,它是…...

计算机网络篇:基础知识总结与基于长期主义的内容更新
基础知识总结 和 MySQL 类似,我同样花了一周左右的时间根据 csview 对计算机网络部分的八股文进行了整理,主要的内容包括:概述、TCP 与 UDP、IP、HTTP,其中我个人认为最重要的是 TCP 这部分的内容。 在此做一篇目录索引…...

操作系统 2.3-用户级线程
多进程的回顾 多进程概念: 操作系统能够同时管理多个进程(PID:1, PID:2, PID:3),每个进程可以独立执行一系列指令。 进程结构: 每个进程拥有自己的代码段、数据段、堆和栈。 进程控制块(PCB)…...

解决火绒启动时,报安全服务异常,无法保障计算机安全
1.找到控制面板-安全和维护-更改用户账户控制设置 重启启动电脑解决。...

2025-03-07 :详细介绍一下 Databricks 的 Lakehouse
Databricks 的 Lakehouse 是一种结合了数据湖和数据仓库优势的现代数据架构。它旨在解决传统数据湖和数据仓库的局限性,提供高效、灵活且可扩展的数据管理解决方案。以下是关于 Databricks Lakehouse 的详细介绍: 1. Lakehouse 的概念 Lakehouse 是一种…...

小程序事件系统 —— 32 事件系统 - 事件分类以及阻止事件冒泡
在微信小程序中,事件分为 冒泡事件 和 非冒泡事件 : 冒泡事件:当一个组件的事件被触发后,该事件会向父节点传递;(如果父节点中也绑定了一个事件,父节点事件也会被触发,也就是说子组…...

STM32点亮LED灯
1.1 介绍: LED模块。它的控制方法非常简单,要想点亮LED,只要让它两端有一定的电压就可以;实验中,我们通过编程控制信号端S的高低电平,从而控制LED的亮灭。我们提供一个测试代码控制LED模块上实现闪烁的效果…...

C++ primer plus 第七节 函数探幽完结版
系列文章目录 C primer plus 第一节 步入C-CSDN博客 C primer plus 第二节 hello world刨析-CSDN博客 C primer plus 第三节 数据处理-CSDN博客 C primer plus 第四节 复合类型-CSDN博客 C primer plus 第五节 循环-CSDN博客 C primier plus 第七节 函数探幽第一部分-CSDN博客 …...

共聚焦显微镜的使用操作流程
一、使用前准备: 在使用显微镜进行细胞制片观察之前,一系列细致的准备工作是必不可少的。首先,将废液缸从框架内取出,清空并清洗,确保无残留液体干扰后续实验。接着,倒取适量的PBS(磷酸盐缓冲液…...

打破界限!家电行业3D数字化营销,线上线下无缝对接
家电行业正步入从增量市场向存量市场的转型期,消费者的观念日益成熟,对产品体验和服务质量的要求愈发严格。无论是线上电商平台还是线下实体店铺,提供个性化、增强体验感的产品与服务已成为家电市场未来发展的核心动力。51建模网凭借“3D数字…...

13 【HarmonyOS NEXT】 仿uv-ui组件开发之Avatar组件进阶指南(四)
温馨提示:本篇博客的详细代码已发布到 git : https://gitcode.com/nutpi/HarmonyosNext 可以下载运行哦! 文章目录 补充内容第四篇:打造高性能Avatar组件的终极优化秘籍1. 性能优化策略1.1 状态管理优化1.2 渲染性能优化 2. 资源优化2.1 图片…...

[Vue warn]: Duplicate keys detected: ‘xxx‘. This may cause an update error.
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

设计模式 - 工厂模式 精准梳理精准记忆
1、代码片段 - 带入理解 一、核心模式分类 简单工厂模式(编程习惯,非 GoF 设计模式)工厂方法模式(GoF 创建型模式)抽象工厂模式(GoF 创建型模式) 二、演变过程:咖啡店案例 初始实现…...

NVIDIA(英伟达) GPU 芯片架构发展史
GPU 性能的关键参数 CUDA 核心数量(个):决定了 GPU 并行处理能力,在 AI 等并行计算类业务下,CUDA 核心越多性能越好。 显存容量(GB):决定了 GPU 加载数据量的大小,在 AI…...

springboot项目使用中创InforSuiteAS替换tomcat
springboot项目使用中创InforSuiteAS替换tomcat 学习地址一、部署InforSuiteAS1、部署2、运行 二、springboot项目打包成war包 特殊处理1、pom文件处理1、排除内嵌的tomcat包2、新增tomcat、javax.servlet-api3、打包格式设置为war4、打包后的项目名称5、启动类修改1、原来的不…...

八、Redis 过期策略与淘汰机制:深入解析与优化实践
Redis 过期策略与淘汰机制:深入解析与优化实践 Redis 作为基于内存的高性能数据库,如何管理过期的键(key)和当内存不足时如何淘汰数据,是影响 Redis 性能和稳定性的关键因素。本篇文章将深入解析 Redis 的过期 key 处理方式和数据淘汰策略,并结合实际应用场景,帮助开发…...

Tomcat-web服务器介绍以及安装部署
一、Tomcat简介 Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun和其他一些公司及个人共同开发而成。 Tomcat服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用…...

C#释放内存空间的方法
目录 前言释放 C# 对象内存的六种方法1、手动释放内存空间2、使用 Using 语句3、使用 垃圾回收器4、GC.Collect() 方法5、GC.WaitForPendingFinalizers() 方法6、WeakReference 类 注意 前言 当不再需要对象时释放内存空间对于防止内存泄漏和提高应用程序性能至关重要。C# 提供…...

18类创新平台培育入库!长沙经开区2025年各类科技创新平台培育申报流程时间材料及申报条件
长沙经开区打算申报企业研发中心、技术创新中心、工程技术研究中心、新型研发机构、重点实验室、概念验证中心和中试平台、工程研究中心、企业技术中心、制造业创新中心、工业设计中心等创新平台的可先备案培育入库,2025年各类平台的认定将从培育库中优先推荐&#…...

使用 Elasticsearch 进行集成测试初始化数据时的注意事项
作者:来自 Elastic piotrprz 在创建应该使用 Elasticsearch 进行搜索、数据聚合或 BM25/vector/search 的软件时,创建至少少量的集成测试至关重要。虽然 “模拟索引” 看起来很诱人,因为测试甚至可以在几分之一秒内运行,但它们实际…...

PostgreSQL常用系统表
1.概念 * 系统表记录了数据库的各种信息,并由SQL命令关联的系统操作表操作会自动维护其中的内容。 * pg_catalog是postgres的系统表命名空间,用于存储系统函数和系统元数据,包含了所有的内置数据类型、函数、表、系统视图等。pg_catalog并不…...

9. Flink的性能优化
1. Flink的资源和代码优化 1.1 slot资源配置 Flink中具体跑任务的进程叫TaskManager,TM进程又会根据配置划分出诺干个TaskSlot,它是具体运行SubTask的地方。slot是Flink用来隔离各个subtask的资源集合,这里的资源一把指内存,TCP…...

【文生图】windows 部署stable-diffusion-webui
windows 部署stable-diffusion-webui AUTOMATIC1111 stable-diffusion-webui Detailed feature showcase with images: 带图片的详细功能展示: Original txt2img and img2img modes 原始的 txt2img 和 img2img 模式 One click install and run script (but you still must i…...

华为:Wireshark的OSPF抓包分析过程
一、OSPF 的5包7状态 5个数据包 1.Hello:发现、建立邻居(邻接)关系、维持、周期保活;存在全网唯一的RID,使用IP地址表示 2.DBD:本地的数据库的目录(摘要),LSDB的目录&…...

视频输入设备-V4L2的开发流程简述
一、摄像头的工作原理与应用 基本概念 V4L2的全称是Video For Linux Two,其实指的是V4L的升级版,是linux系统关于视频设备的内核驱动,同时V4L2也包含Linux系统下关于视频以及音频采集的接口,只需要配合对应的视频采集设备就可以实…...

python基础课程整理--元组的基础
好的,下面详细列举Python元组的特点,包括取值、增加、修改和删除操作: 元组(Tuple) 元组(Tuple)的特点如下: 定义:使用圆括号 () 包裹,可以存储多个元素。…...

Windows设置目录及子目录大小写不敏感暨git克隆报错同名文件已存在的解决办法
在Windows系统中设置目录及其子目录为大小写不敏感,可以通过以下步骤完成: 步骤说明: 以管理员身份运行命令提示符或PowerShell 右键点击“开始”菜单,选择“命令提示符(管理员)”或“Windows PowerShell&…...
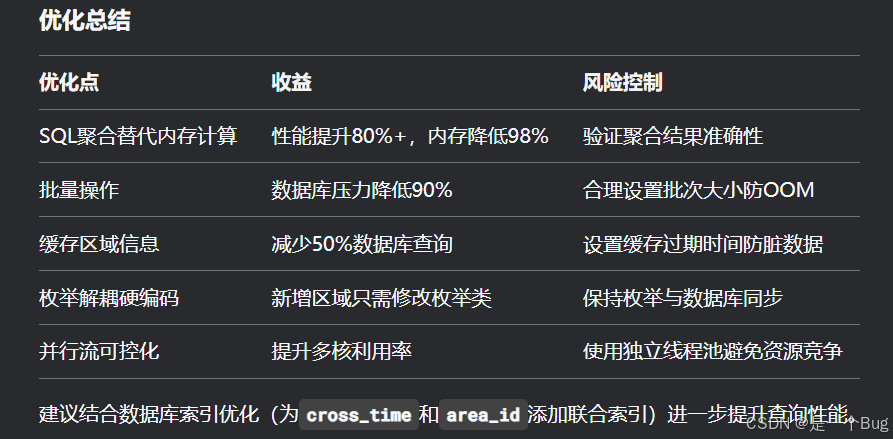
浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据库聚合替代内存计算(关键优化)二、批量处理优化四、区域特殊处理解耦五、防御性编程增强 前言 技术认知点:使用 XM…...