深度学习分类回归(衣帽数据集)
一、步骤
1 加载数据集fashion_minst
2 搭建class NeuralNetwork模型
3 设置损失函数,优化器
4 编写评估函数
5 编写训练函数
6 开始训练
7 绘制损失,准确率曲线
二、代码
导包,打印版本号:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
from tqdm.auto import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as Fprint(sys.version_info)
for module in mpl, np, pd, sklearn, torch:print(module.__name__, module.__version__)device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print(device)torch的运算过程都是张量,也叫算子(tensor)
torchvision的包可以提供数据集,图片就是datasets:

这里下载到data目录,如果已有数据则不会下载。这段代码可以实现数据向tensor的转换:
做预处理的时候把图片变成tensor,啥都没写的时候就不会转换成tensor
from torchvision import datasets
from torchvision.transforms import ToTensor
from torchvision import transforms# 定义数据集的变换
transform = transforms.Compose([
])
# fashion_mnist图像分类数据集,衣服分类,60000张训练图片,10000张测试图片
train_ds = datasets.FashionMNIST(root="data",train=True,download=True,transform=transform
)test_ds = datasets.FashionMNIST(root="data",train=False,download=True,transform=transform
)# torchvision 数据集里没有提供训练集和验证集的划分
# 当然也可以用 torch.utils.data.Dataset 实现人为划分type(train_ds[0]) # 元组,第一个元素是图片,第二个元素是标签如果使用了数据类型变换:
img_tensor, label = train_ds[0]
img_tensor.shape #img这时是一个tensor,shape=(1, 28, 28)在PyTorch中,DataLoader是一个迭代器,它封装了数据的加载和预处理过程,使得在训练机器学习模型时可以方便地批量加载数据。DataLoader主要负责以下几个方面:
-
批量加载数据:
DataLoader可以将数据集(Dataset)切分为更小的批次(batch),每次迭代提供一小批量数据,而不是单个数据点。这有助于模型学习数据中的统计依赖性,并且可以更高效地利用GPU等硬件的并行计算能力。 -
数据打乱:默认情况下,
DataLoader会在每个epoch(训练周期)开始时打乱数据的顺序。这有助于模型训练时避免陷入局部最优解,并且可以提高模型的泛化能力。 -
多线程数据加载:
DataLoader支持多线程(通过参数num_workers)来并行地加载数据,这可以显著减少训练过程中的等待时间,尤其是在处理大规模数据集时。 -
数据预处理:
DataLoader可以与transforms结合使用,对加载的数据进行预处理,如归一化、标准化、数据增强等操作。 -
内存管理:
DataLoader负责管理数据的内存使用,确保在训练过程中不会耗尽内存资源。 -
易用性:
DataLoader提供了一个简单的接口,可以很容易地集成到训练循环中。
# 从数据集到dataloader
train_loader = torch.utils.data.DataLoader(train_ds, batch_size=32, shuffle=True) #batch_size分批,shuffle洗牌
val_loader = torch.utils.data.DataLoader(test_ds, batch_size=32, shuffle=False)这里每32个样本就会算一次平均损失,更新一次w。
定义模型:继承nn.Module
class NeuralNetwork(nn.Module):def __init__(self):super().__init__() # 继承父类的初始化方法,子类有父类的属性self.flatten = nn.Flatten() # 展平层self.linear_relu_stack = nn.Sequential(nn.Linear(784, 300), # in_features=784, out_features=300, 784是输入特征数,300是输出特征数nn.ReLU(), # 激活函数nn.Linear(300, 100),#隐藏层神经元数100nn.ReLU(), # 激活函数nn.Linear(100, 10),#输出层神经元数10 )def forward(self, x): # 前向计算,前向传播# x.shape [batch size, 1, 28, 28],1是通道数x = self.flatten(x) # print(f'x.shape--{x.shape}')# 展平后 x.shape [batch size, 784]logits = self.linear_relu_stack(x)# logits.shape [batch size, 10]return logits #没有经过softmax,称为logitsmodel = NeuralNetwork()model的结构:第一层是展平层,然后激活,然后隐藏层,激活,输出层

在训练之前需要测试一下模型能不能用,所以我们随机一个或者从样本拿一个,同尺寸就行:
#为了查看模型运算的tensor尺寸
x = torch.randn(32, 1, 28, 28)
print(x.shape)
logits = model(x) # 把x输入到模型中,得到logits
print(logits.shape)然后开始训练,pytorch的训练需要自行实现,包括定义损失函数、优化器、训练步,训练
# 1. 定义损失函数 采用交叉熵损失
loss_fct = nn.CrossEntropyLoss() #内部先做softmax,然后计算交叉熵
# 2. 定义优化器 采用SGD
# Optimizers specified in the torch.optim package,随机梯度下降
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)from sklearn.metrics import accuracy_score # sk里面有一个算子,可以计算准确率@torch.no_grad() # 装饰器,禁止反向传播,节省内存,就是不求导的意思
def evaluating(model, dataloader, loss_fct): # 评估函数,评估也要做一次向前计算,不需要求梯度loss_list = [] # 记录损失pred_list = [] # 记录预测label_list = [] # 记录标签for datas, labels in dataloader:#10000/32=312datas = datas.to(device) # 转到GPUlabels = labels.to(device) # 转到GPU 这两行代码torch必写,把tensor放到GPU上# 前向计算logits = model(datas) # 进行前向计算loss = loss_fct(logits, labels) # 验证集损失,loss尺寸是一个数值loss_list.append(loss.item()) # 记录损失,item是把tensor转换为数值preds = logits.argmax(axis=-1) # 验证集预测,argmax返回最大值索引,-1就是最后一个维度print(f'评估中的preds.shape--{preds.shape}')pred_list.extend(preds.cpu().numpy().tolist())#将PyTorch张量转换为NumPy数组。只有当张量在CPU上时,这个转换才是合法的# print(preds.cpu().numpy().tolist())label_list.extend(labels.cpu().numpy().tolist())acc = accuracy_score(label_list, pred_list) # 计算准确率return np.mean(loss_list), acc# 训练
def training(model, train_loader, val_loader, epoch, loss_fct, optimizer, eval_step=500):#参数分别是模型,训练集,验证集,训练epoch,损失函数,优化器,评估步数(500评估一次)record_dict = { # 记录字典,用于记录训练过程中的信息"train": [],"val": []}global_step = 0 # 全局步数,记录训练的步数model.train() # 进入训练模式,模型可以切换模式#tqdm是一个进度条库with tqdm(total=epoch * len(train_loader)) as pbar: # 进度条 加入epoch等于10,就是所有样本搞10次,不断地把样本带进去学习,1875*10,60000/32=1875for epoch_id in range(epoch): # 训练epoch次# trainingfor datas, labels in train_loader: #执行次数是60000/32=1875datas = datas.to(device) #datas尺寸是[batch_size,1,28,28]labels = labels.to(device) #labels尺寸是[batch_size]# 梯度清空optimizer.zero_grad() # 每次训练前都要把梯度清空,不然会累加# 模型前向计算logits = model(datas)# 计算损失loss = loss_fct(logits, labels)# 梯度回传,loss.backward()会计算梯度,loss对模型参数求导loss.backward()# 调整优化器,包括学习率的变动等,优化器的学习率会随着训练的进行而减小,更新w,boptimizer.step() #梯度是计算并存储在模型参数的 .grad 属性中,优化器使用这些存储的梯度来更新模型参数preds = logits.argmax(axis=-1) # 训练集预测acc = accuracy_score(labels.cpu().numpy(), preds.cpu().numpy()) # 计算准确率,numpy可以,每个step都算一次loss = loss.cpu().item() # 损失转到CPU,item()取值,一个数值# tensor如果只有一个值(标量),一维是向量,二维是矩阵,可以用item()取出值,如果有多个值,则需要用tolist()转为列表# record# recordrecord_dict["train"].append({"loss": loss, "acc": acc, "step": global_step}) # 记录训练集信息,每一步的损失,准确率,步数# evaluatingif global_step % eval_step == 0:model.eval() # 进入评估模式,不会求梯度val_loss, val_acc = evaluating(model, val_loader, loss_fct)record_dict["val"].append({"loss": val_loss, "acc": val_acc, "step": global_step})model.train() # 进入训练模式# udate stepglobal_step += 1 # 全局步数加1pbar.update(1) # 更新进度条pbar.set_postfix({"epoch": epoch_id}) # 设置进度条显示信息return record_dictepoch = 20 #改为40
model = model.to(device)
record = training(model, train_loader, val_loader, epoch, loss_fct, optimizer, eval_step=1000)#画线要注意的是损失是不一定在零到1之间的
def plot_learning_curves(record_dict, sample_step=1000):# build DataFrametrain_df = pd.DataFrame(record_dict["train"]).set_index("step").iloc[::sample_step]val_df = pd.DataFrame(record_dict["val"]).set_index("step")last_step = train_df.index[-1] # 最后一步的步数# print(train_df.columns)print(train_df['acc'])print(val_df['acc'])# plotfig_num = len(train_df.columns) # 画几张图,分别是损失和准确率fig, axs = plt.subplots(1, fig_num, figsize=(5 * fig_num, 5))for idx, item in enumerate(train_df.columns):# print(train_df[item].values)axs[idx].plot(train_df.index, train_df[item], label=f"train_{item}")axs[idx].plot(val_df.index, val_df[item], label=f"val_{item}")axs[idx].grid() # 显示网格axs[idx].legend() # 显示图例axs[idx].set_xticks(range(0, train_df.index[-1], 5000)) # 设置x轴刻度axs[idx].set_xticklabels(map(lambda x: f"{int(x/1000)}k", range(0, last_step, 5000))) # 设置x轴标签axs[idx].set_xlabel("step")plt.show()plot_learning_curves(record) #横坐标是 steps
# dataload for evaluatingmodel.eval() # 进入评估模式
loss, acc = evaluating(model, val_loader, loss_fct)
print(f"loss: {loss:.4f}\naccuracy: {acc:.4f}")相关文章:
深度学习分类回归(衣帽数据集)
一、步骤 1 加载数据集fashion_minst 2 搭建class NeuralNetwork模型 3 设置损失函数,优化器 4 编写评估函数 5 编写训练函数 6 开始训练 7 绘制损失,准确率曲线 二、代码 导包,打印版本号: import matplotlib as mpl im…...

深入解析ECDSA与RSA公钥算法:原理、对比及AWS最佳实践
一、公钥加密算法概述 在HTTPS通信和数字证书领域,ECDSA(椭圆曲线数字签名算法)和RSA(Rivest-Shamir-Adleman)是最主流的两种非对称加密算法。它们共同构成了现代网络安全的基础,但设计理念和技术实现存在显著差异。 © ivwdcwso (ID: u012172506) 二、RSA算法详解…...

preloaded-classes裁剪
系统预加载了哪些class类?system/etc/preloaded-classes 修改源代码? frameworks\base\config\preloaded-classes 默认位置,如果改了不生效,可能有其它模块的mk文件指定了preloaded-classes覆盖了framework模块,例如…...

在Linux中开发OpenGL——检查开发环境对OpenGL ES的支持
由于移动端GPU规模有限,厂商并没有实现完整的OpenGL特性,而是实现了它的子集——OpenGL ES。因此如果需要开发的程序要支持移动端平台,最好使用OpenGL ES开发。 1、 下载支持库、OpenGL ES Demo 1.1、下载PowerVRSDK支持库作为准备ÿ…...

HJ C++11 Day2
Initializer Lists 对于一个类P class P{P(int a, int b){cout << "P(int, int), a" << a << ", b " << b << endl;}P(initializer_list<int> initlist){cout << "P(initializer_list<int>), val…...

基于Spring Boot的学院商铺管理系统的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

os-copilot安装和使用体验测评
简介: OS Copilot是阿里云基于大模型构建的Linux系统智能助手,支持自然语言问答、命令执行和系统运维调优。本文介绍其产品优势、功能及使用方法,并分享个人开发者在云服务器资源管理中的实际应用体验。通过-t/-f/管道功能,OS Cop…...

Geo3D建筑材质切换+屋顶纹理
一、简介 基于Threejs开发封装建筑渲染管线,利用简单二维建筑矢量面轮廓程序化生成3D建筑,支持材质一键切换,支持多样化建筑墙面材质和屋顶材质,支持建筑透明,支持地形高程适配,支持按空间范围裁剪挖洞等。…...
--跨平台解决方案)
工程化与框架系列(24)--跨平台解决方案
跨平台解决方案 🌐 引言 随着移动互联网的发展,跨平台开发已成为前端开发的重要趋势。本文将深入探讨前端跨平台开发的各种解决方案,包括响应式设计、混合开发、原生开发等方案,帮助开发者选择合适的跨平台策略。 跨平台开发概…...

快手,得物,三七互娱,科锐国际,作业帮等25春招内推
得物,三七互娱,快手,作业帮,科锐国际26届实习内推 ①快手 【在招岗位】运营、市场、产品、战略分析、职能、工程、设计、算法、项目管理、销售、游戏等类 【一键内推】https://sourl.cn/Qi5pm2 【内推码】campuswQrLOMvHE ②得物 …...
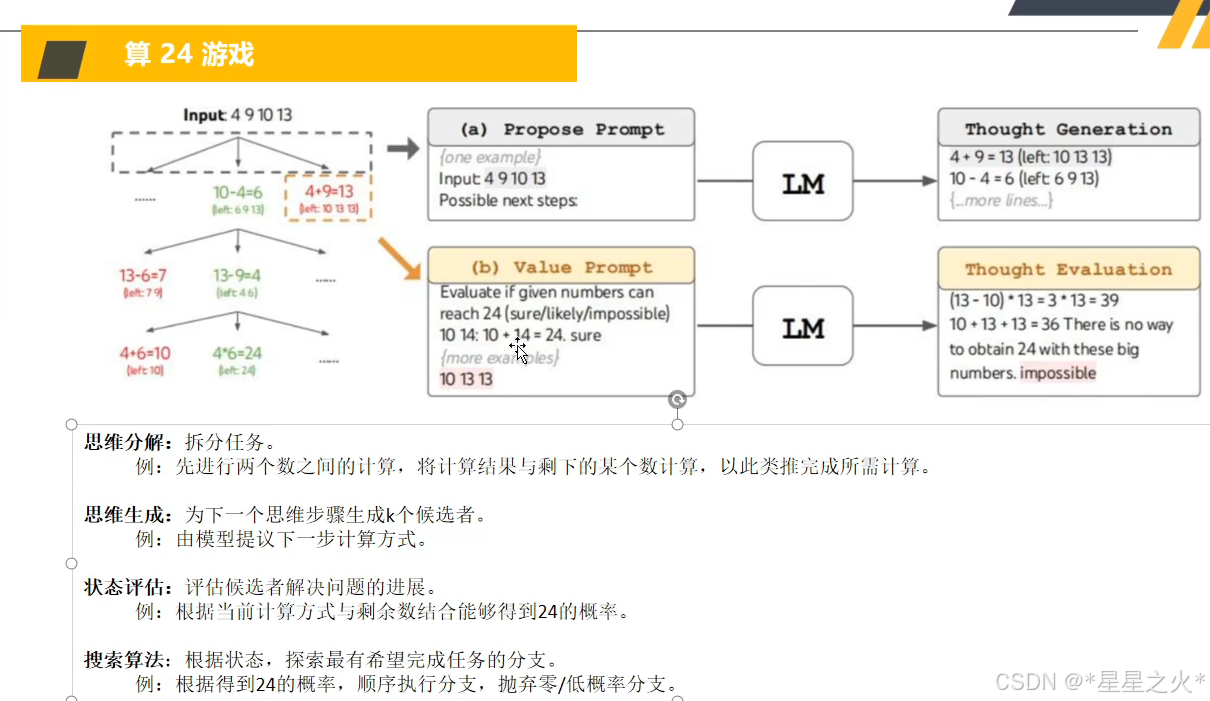
【GPT入门】第9课 思维树概念与原理
【GPT入门】第9课 思维树概念与原理 1.思维树概念与原理2. 算24游戏的方法 1.思维树概念与原理 思维树(Tree of Thought,ToT )是一种大模型推理框架,旨在解决更加复杂的多步骤推理任务,让大模型能够探索多种可能的解决…...

SolidWorks 转 PDF3D 技术详解
在现代工程设计与制造流程中,不同软件间的数据交互与格式转换至关重要。将 SolidWorks 模型转换为 PDF3D 格式,能有效解决模型展示、数据共享以及跨平台协作等问题。本文将深入探讨 SolidWorks 转 PDF3D 的技术原理、操作流程及相关注意事项,…...

栈概念和结构
文章目录 1. 栈的概念2. 栈的分类3. 栈的实现(数组栈)3.1 接口设计(Stack.h)3.2 接口实现(Stack.c)1)初始化销毁2)栈顶插入删除3)栈顶元素、空栈、大小 3.3 完整代码Stac…...

Trae 是一款由 AI 驱动的 IDE,让编程更加愉悦和高效。国际版集成了 GPT-4 和 Claude 3.5,国内版集成了DeepSeek-r1
Trae 是一款由 AI 驱动的 IDE,让编程更加愉悦和高效。国际版集成了 GPT-4 和 Claude 3.5,国内版继承了DeepSeek-r1,支持实时代码建议和无缝 GitHub 集成。 当前国内和国际版的AI都是免费的。 安装 国际版安装 国际版下载:下载…...

Spring (八)AOP-切面编程的使用
目录 实现步骤: 1 导入AOP依赖 2 编写切面Aspect 3 编写通知方法 4 指定切入点表达式 5 测试AOP动态织入 图示: 实现步骤: 1 导入AOP依赖 <!-- Spring Boot AOP依赖 --><dependency><groupId>org.springframework.b…...

VS Code连接服务器教程
VS Code是什么 VS Code(全称 Visual Studio Code)是一款由微软推出的免费、开源、跨平台的代码编辑神器。VS Code 支持 所有主流操作系统,拥有强大的功能和灵活的扩展性。 官网:https://code.visualstudio.com/插件市场࿱…...

leetcode69.x 的平方根
题目: 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。…...

HttpServletRequest 和 HttpServletResponse 区别和作用
一、核心作用对比 对象HttpServletRequest(请求对象)HttpServletResponse(响应对象)本质客户端发给服务器的 HTTP 请求信息(输入)服务器返回客户端的 HTTP 响应信息(输出)生命周期一…...

国家二级运动员证书有什么用·棒球1号位
以棒球运动为例,国家二级棒球运动员证书是由中国国家体育总局颁发的运动员技术等级认证,主要作用体现在以下几个方面: 一、升学优势 体育特招资格:符合条件者可报考高校高水平运动队或体育单招,部分院校对二级运动员有…...

Windsuf 连接失败问题:[unavailable] unavailable: dial tcp...
问题描述 3月6日,在使用Windsuf 时,遇到以下网络连接错误: [unavailable] unavailable: dial tcp 35.223.238.178:443: connectex: A connection attempt failed because the connected party did not properly respond after a period of…...

docker中kibana启动后,通过浏览器访问,出现server is not ready yet
问题:当我在浏览器访问kibana时,浏览器给我报了server is not ready yet. 在网上试了很多方法,都未能解决,下面是我的方法: 查看kibana日志: docker logs -f kibana从控制台打印的日志可以发现ÿ…...
更多文章请查看
更多文章知识请移步至下面链接,期待你的关注 如需查看新文章,请前往: 博主知识库https://www.yuque.com/xinzaigeek...

(十 九)趣学设计模式 之 中介者模式!
目录 一、 啥是中介者模式?二、 为什么要用中介者模式?三、 中介者模式的实现方式四、 中介者模式的优缺点五、 中介者模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,…...

博弈论算法
一、减法游戏 初始有一个数 n。 两个玩家轮流操作,每次可以减去 1 到 9 之间的任意整数。 将数减到 0 的玩家获胜。 可以发现规律: 减法游戏只需要判断当前数取模是否为0,即可快速判断胜负。 例题: Leetcode 292. Nim 游戏 …...

【网络】HTTP协议、HTTPS协议
HTTP与HTTPS HTTP协议概述 HTTP(超文本传输协议):工作在OSI顶层应用层,用于客户端(浏览器)与服务器之间的通信,B/S模式 无状态:每次请求独立,服务器不保存客户端状态(通…...

GitCode 助力 vue3-element-admin:开启中后台管理前端开发新征程
源码仓库: https://gitcode.com/youlai/vue3-element-admin 后端仓库: https://gitcode.com/youlai/youlai-boot 开源助力,开启中后台快速开发之旅 vue3-element-admin 是一款精心打造的免费开源中后台管理前端模板,它紧密贴合…...

网络HTTP
HTTP Network Request Library A Retrofit-based HTTP network request encapsulation library that provides simple and easy-to-use API interfaces with complete network request functionality. 基于Retrofit的HTTP网络请求封装库,提供简单易用的API接口和完…...
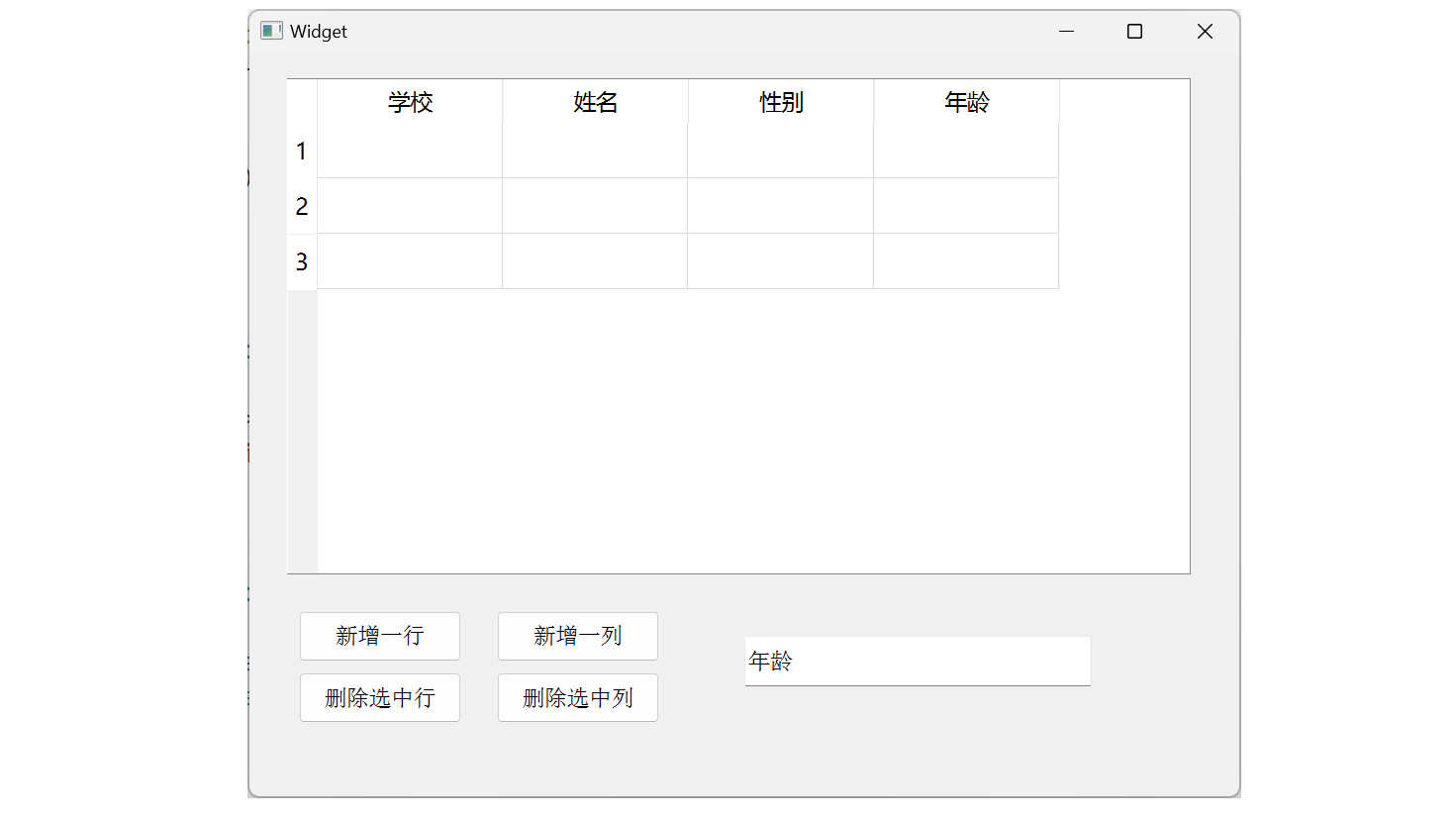
Qt常用控件之表格QTableWidget
表格QTableWidget QTableWidget 是一个表格控件,行和列交汇形成的每个单元格,是一个 QTableWidgetItem 对象。 1. QTableWidget属性 QTableWidget 的属性只有两个: 属性说明rowCount当前行的个数。columnCount当前列的个数。 2. QTableW…...
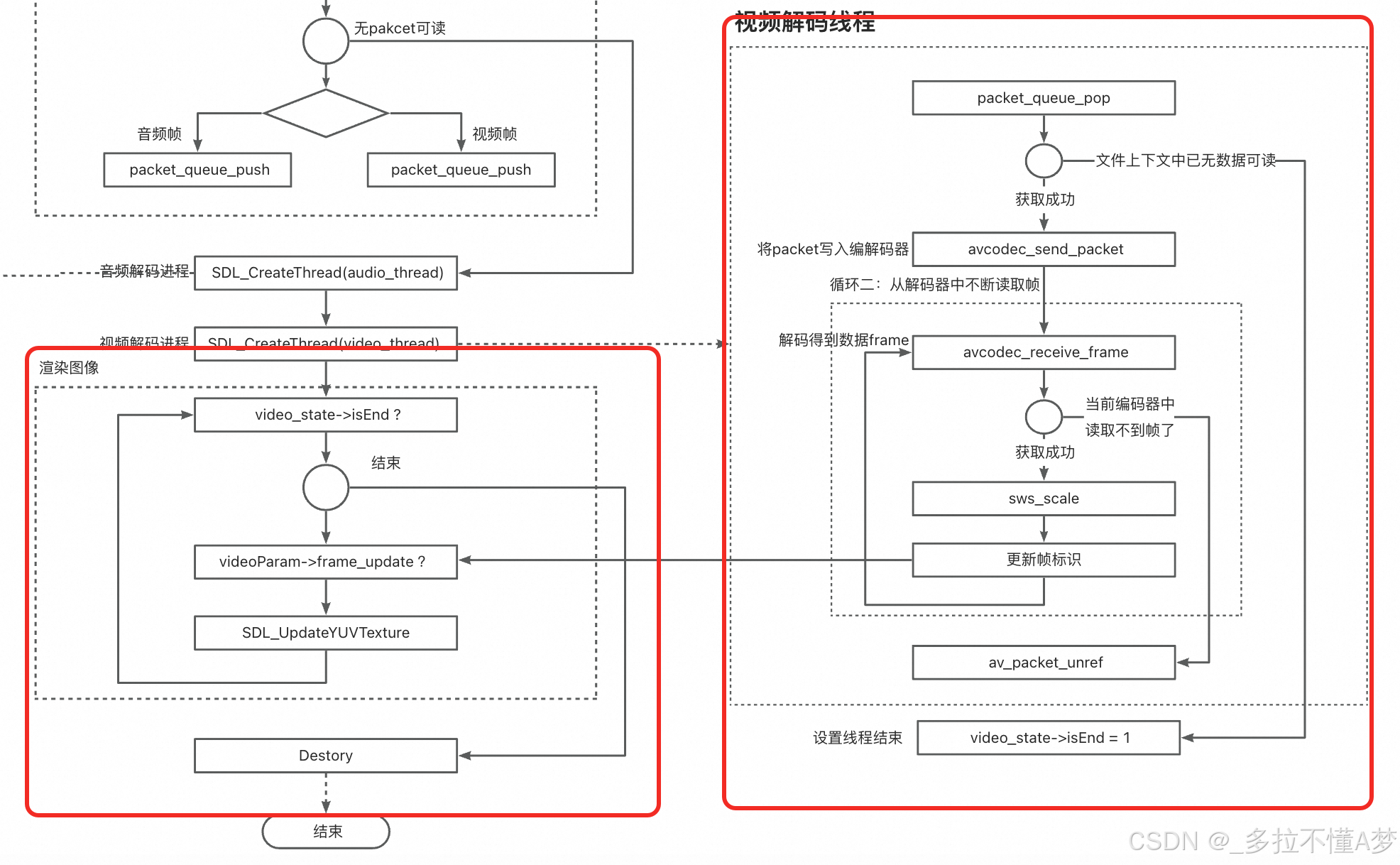
FFmpeg入门:最简单的音视频播放器
FFmpeg入门:最简单的音视频播放器 前两章,我们已经了解了分别如何构建一个简单和音频播放器和视频播放器。 FFmpeg入门:最简单的音频播放器 FFmpeg入门:最简单的视频播放器 本章我们将结合上述两章的知识,看看如何融…...
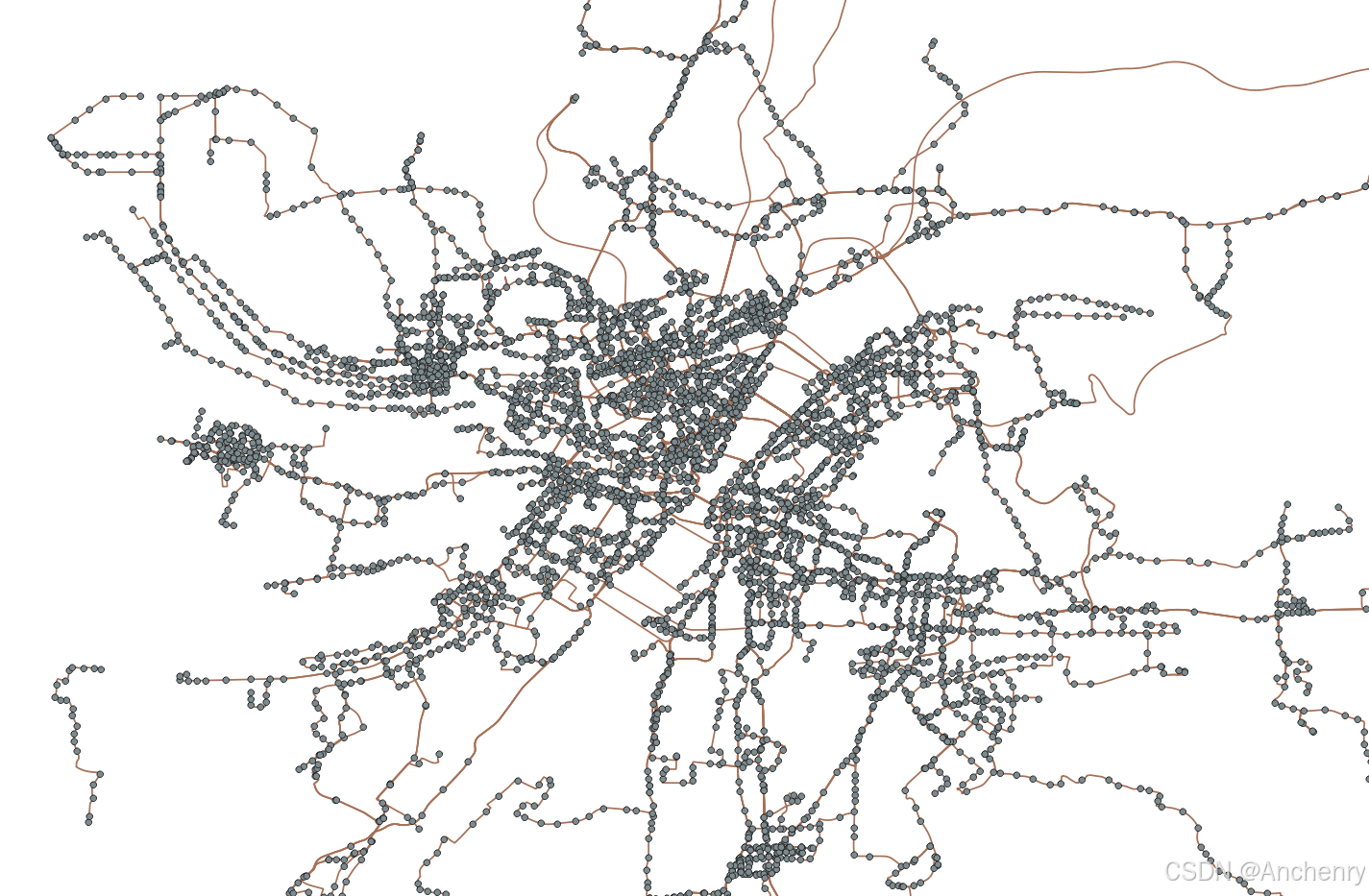
【Python爬虫】爬取公共交通路网数据
程序来自于Github,以下这篇博客作为完整的学习记录,也callback上一篇爬取公共交通站点的博文。 Bardbo/get_bus_lines_and_stations_data_from_gaode: 这个项目是基于高德开放平台和公交网获取公交线路及站点数据,并生成shp文件,…...