数据结构(蓝桥杯常考点)
数据结构
前言:这个是针对于蓝桥杯竞赛常考的数据结构内容,基础算法比如高精度这些会在下期给大家总结
数据结构
竞赛中,时间复杂度不能超过10的7次方(1秒)到10的8次方(2秒)
空间限制:int类型数组总大小不能超过3*10的7次方,二维数组不能超过5000*5000
顺序表就是一个数组加上标记数组中有多少元素的数(n)
eg:尾删就是n--
注意事项:在实行插入和删除操作时,记得检查数组中有无位置可以进行
vector容器创建变量常用的方法:<>中的类型可以换
vector<int>a;//搭建一个可变长的数组
vector<int>a;//指定好了一个空间,大小为N
vector<int>a[N];//创建N个vector,vector里存放的是int类型的数据
N个vector用时要eg:a[2].resize(3)
存在迭代器的容器才可以用范围for去遍历
程序超时,一般不考虑是容器的问题
链表的静态实现:单链表:要头指针,下一个元素的分配的位置,指针域和数据域 然后下标0位置是哨兵位
注意:在进行操作时,一直让h为头指针前提:h是头指针,id是下一个元素分配的位置,e[n]是数据域,ne[n]是指针域头插一个数据x:
将x放在e[++id]中 x的右指针指向哨兵位的后继 哨兵位的右指针指向x所在位置遍历链表:
for(int i = ne[h];i;i = ne[i])按值查找:
1.遍历链表
2.多次查询并且链表中没有重复数的话,可以用哈希表优化在任意位置之后插入元素:
(在存储位置p后插入一个元素x)
x放在e[++id]里面,把x位置指向p后面的位置,把p位置指向x删除任意元素之后的元素:
(删除存储位置为p后面的元素)
先判断p是不是最后一个元素,让p指向下一个元素的下一个元素双向链表:
比单链表加了一个前指针域pre[n]头插:
x所在位置id左指向哨兵位,右指向哨兵位的下一个位置
之后先修改头结点的指针,再修改哨兵位的在任意位置之后插入元素:
先让x的左指针指向p,右指针指向p的后继
先让p的后继的左指针指向id,再让p的右指针指向id在任意位置之前插入元素:
先让x的左指针指向p的前驱,右指针指向p
先p的前驱的右指针指向x,再让p的左指针指向id删除任意位置(q)的元素:
将q位置的左右指针那两端缝合在一起就可以了循环列表的话,就是让单链表的最后一个位置的右指针指向头结点就可以了
栈:只允许在栈顶进行数据插入和删除
STL中是stack
进栈和出栈时记得检查空间还有没有
有时写一行会好看些
eg:
int b = st.top();st.pop();
队列:
特性:先进先出
只允许在表尾进行插入操作,在表头进行删除操作
树:
孩子表示法:(用于在无根树中,即父子关系不明确,因为把与该结点相连的点全部保存下来)
实现方法:
1.用vector数组实现:
假如树有n个结点的话
创建一个n+1大小的vector数组edge[n+1]
vector<int>edge[n+1];
edge[i]中储存着i号结点所连接的结点
对于i的孩子,直接edge[i].push_back()进去即可2.用链式前向星(其本质是用数组来模拟链表)实现
用的是双向链表
链式前向星具体怎么实现的自己要知道
树的遍历:
1.DFS(深度优先遍历):
一条路走到黑 具体流程:
1.从根节点出发,依次遍历每一棵子树 2.遍历子树的时候,重复第一步
时间复杂度O(N)2.BFS(宽度优先搜索)
一层搜索完了再去下一层搞 具体流程:(借助队列):
1.初始化一个队列 2.根节点入队,同时标记该节点已经入队
3.当队列不为空时,拿出队头元素访问,然后将队头元素的孩子入队,同时打上标记
4.重复3过程,直到队列为空
这里标记其实是为了跟图结构那里统一,好记这两种方式的时间复杂度都是O(N)
像这种有英文简写的,在设置自定义函数时,直接写eg:bfs就很不错
二叉树:
分类:满二叉树、完全二叉树等
一般用顺序存储和链式存储
1.顺序存储(一般只用于接近满的二叉树或者满二叉树):
其实就是用数组去存储
规则:针对与结点i来说:
如果父存在,父结点的下标为i/2;
如果左孩子存在,其结点下标为i*2;
如果右孩子存在,其结点下标位为i*2+1;
2.链式存储:
也是用数组模拟
创建两个数组l[N],r[N];
l[i]表示结点i的左孩子,r[i]表示结点i的右孩子
二叉树的遍历:
1.DFS:(分为三种)
先序遍历的顺序;根 左 右
中序遍历的顺序:左 根 右
后序遍历的顺序:左 右 根
先中后其实就是看根被插在哪(一直是左右)
eg:自定义命名可以先序遍历dfs1
自己手动模拟的话:
先序遍历就是经过一次就行
中序遍历的话就是经过两次才那啥
后序遍历的话就是经过三次2.BFS
跟常规树的方法差不多,借助队列
堆:
1.是完全二叉树
2.要么是大根堆,要么是小根堆
存储方式的话一般用顺序储存
优先级队列(即堆):priority_queue
当优先级队列中存储结构体时,要重载<运算符才行
eg:
struct node
{int a,b,c;
//以b为基准,定义大根堆
bool operator<(const node&x)const
{
return b < x.b;}//以b为基准定义小根堆
bool operator<(const node&x)const
{
return b > x.b;//第一个b是调用<的那个数}
当然,这里只能要一个}
结构体在里面的使用方法
eg:
priority_queue<node>heap;
heap.push({2,3,4})
二叉搜索树的性质:(BST的性质)
1.左子树的结点值<根结点<右子树的结点值
2.左子树和右子树也分别是一颗二叉搜索树
AVL和常规的二叉搜索树很少用,一般用STL里面的红黑树
红黑树简称BST:其规则:
1.左根右
2.根叶黑(这里的根节点指最上面那一个{一般都是指这个},叶子结点指的是补为满二叉树时的空结点)("最后"的叶子结点下面要补上空节点,这个建议看一下图)
3.不红红
4.黑路同
5.为二叉搜索树
其的两个性质:
1.从根结点到叶结点的最长路径不大于最短路径的两倍(理解)
2.有n个结点的红黑树,高度h<=2log2(n+1)
排序的话一般都是用的sort
像插入排序 选择排序 冒泡排序 堆排序 快速排序 归并排序这些没有sort快
sort是综合了三种排序的
C++中的随机函数:
#include<ctime>
srand(time(0));//种下一个随机数种子
b = rand();//会生成一个随机值给b
c = b%m+n//获得的是在[n,m+n]的随机数
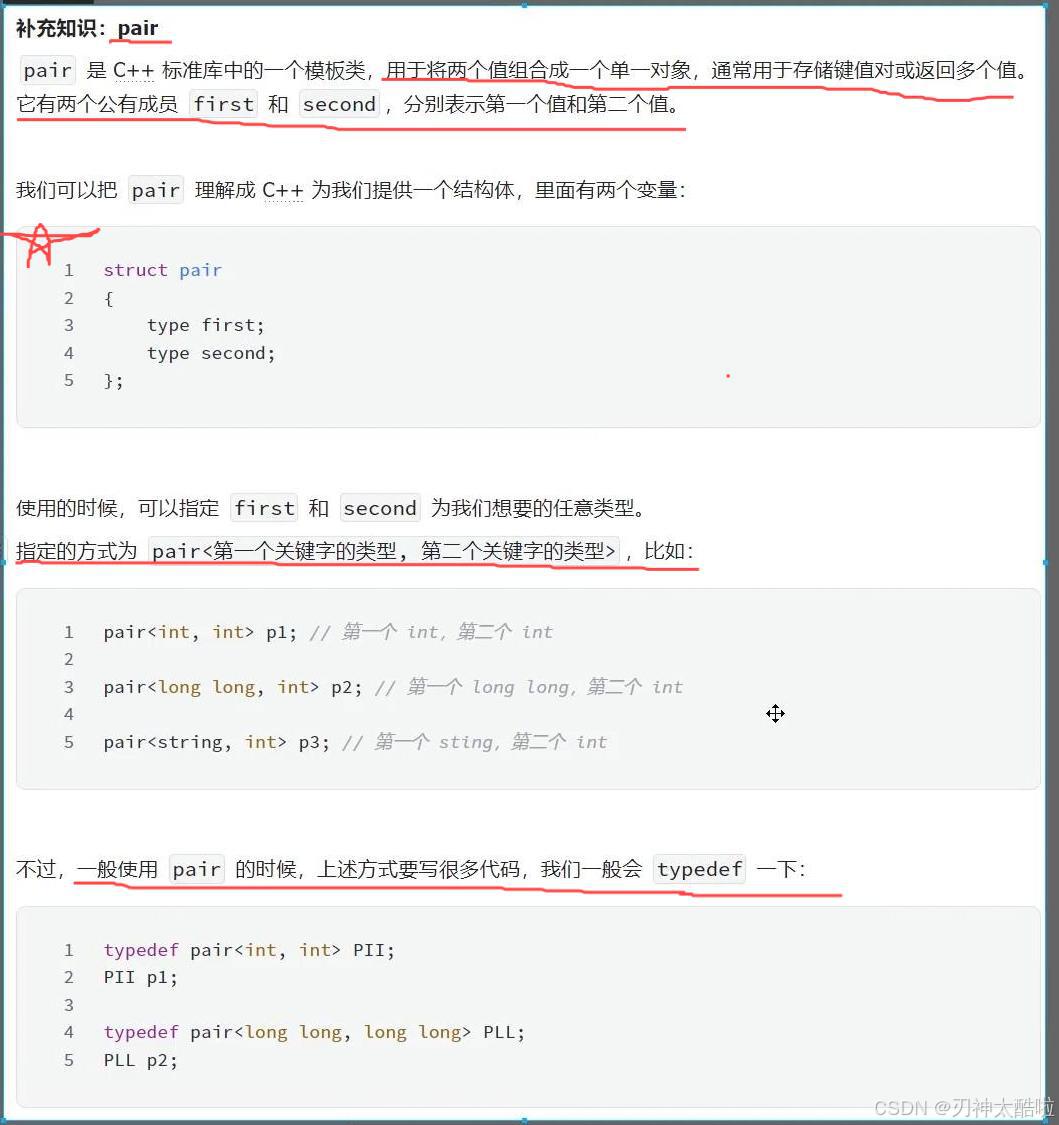
pair类型的的重命名方式一般是采用eg:两个都是int类型的话就是PII,(I为int的首字母的大写)
vector<int> a[10];
在C++中声明了一个数组,这个数组有10个元素,每个元素都是一个 vector<int> 。
每个vector<int>里可以存很多个数,但是要扩容才行
这种数据结构在需要固定数量的动态数组时非常有用
例如,当你有一个固定数量的学生,但每个学生的成绩数量不固定时。
常见的算法知识
前面的数据先不验,从某个相邻(有多少搞多少)开始才逐个向外验
这种题通常要用栈
eg:题目:有效的括号(leetcode里面有)、后缀表达式(洛谷里面有)
还原字符串中整数的方法:
eg:ch = '9';t = '9'-'0';
常用bool st[N]来表示i这个元素是否已经在了
用此可以解决快速查找i是不是已经在了或者有无被访问过
(在第一次录入时,改成true)
先进先出'数组'问题一般用队列去解决
eg:海港(洛谷)
处理一个地方不同种人进出时,种类个数:
int cnt[N];//cnt[i]表示这个地方第i个种类的有多少个
int kinds;//统计种类个数
cnt[i]从1变成0时,kinds--;从0变成1时,kinds++;
例题:海港(洛谷)
树的问题一般都要用到递归
堆适合用于每次取出最大或者最小,(再将最大或最小衍生的给放进去)
想把一组数变成堆的话,有两种方法:
1.用数组存下这组数,然后把数组调整成一个堆
2.创建一个堆,然后将这组数依次插入到堆中
topK问题:
用堆解决
如果是求第k小,就用大根堆
1.维护一个大小为k的大根堆
2.对于每次来的元素,先进堆,再删除堆顶元素,此时堆顶元素就是第k小(每个元素都要放进来过)
如果是求第k大,就用小根堆,...
像这种可以用单调性简化问题的题的做法:
1.先存认为小的数(怎么写方便怎么来,就算跟后面的比又不是特别小了)
2.堆中一般还要存关系量(3要用)
3.将堆顶弹出后,搞入与堆顶关系量相近的
有时要设置左右护法,防止越界访问
eg:做++--时 特别是红黑树那里找小于等于x的最大值
模加模:
解决取模之后的模变成负数的问题(让他变为正数):
(key%N+N)%N
哈希表常用来解决一个东西有没有重复出现或者重复出现了几次的问题
算法题中的经典操作:用空间代替时间
模拟得到浮点数的小数部分p
double d = 6.5;
int q = (int)d;
double p = d - q;小数四舍五入成整数的方法
假设a是四舍五入之后的,b是四舍五入之前的
有a = (int)(b+0.5);
数据结构这里常用的头文件和容器以及其接口
这个点的话是C++比C语言在解题时优越的地方,可以用容器来省略很多过程
而且使用容器的话,一般比赛是不会无聊到用容器去卡你的时间,也就是说,如果超时了,大概率不是容器的问题
#include<vector>
size-返回实际元素个数
empty-返回顺序表是否为空,空则返回true,非空则返回false
begin-返回起始位置的迭代器
end-返回终点位置的下一个位置的迭代器
push_back-尾部插入一个元素
pop_back-尾部删除一个元素
front-返回首元素
back-返回尾元素
resize-修改vector的大小
clear-清空vector(把大小搞为1)
stack容器(栈)
头文件:#include<stack>
创建:stack<T>st;//st是变量名,可以改;T是任意类型的数据
size empty
push:进栈
pop:出栈
top:返回栈顶元素,但是不会删除栈顶元素
queue(队列):
头文件:#include<queue>
创建:queue<T>q;//q是变量名,T是任意类型的数据
size empty push pop
front:返回队头元素,但不会删除
back:返回队尾元素,但不会删除
不可以用clear来直接清除队列
deque(双端队列):
头文件#include<deque>
创建-和queue方式一样
size empty front back
push_front-头插
push_back-尾插
pop_front-头删
pop_back-尾删
clear-清除队列
priority_queue(优先级队列)
头文件:#include<queue>
size empty
push-往优先级队列里面添加一个元素(自动排序了)
pop-删除优先级最高的元素(也会自动排序)
top-获取优先级最高的元素
创建:
priority_queue<数据类型,存数据的结构,数据之间的比较方式>
存数据的结构没写时,默认是vector
数据之间比较方式没写时,默认是大根堆
如果想改成小根堆,数据之间的比较方式这里就要写greater<数据类型>
红黑树:
set和multiset的区别:set不能存相同元素,multiset可以存相同元素
(其余使用方式完全一致),下面以set举例
头文件:#include<set>//multiset也为此
创建:set<T>q//T为任意数据类型,q为变量名
size empty begin end
可以用范围for遍历整个红黑树(遍历是按照中序遍历的顺序,因此是有序的序列)
insert:向红黑树中插入一个元素(时间复杂度logN)
erase:删除一个元素(时间复杂度:logN)
find:查找一个元素,返回的是迭代器(时间复杂度:logN)
count:查询元素出现的次数,一般用来判断元素是否在红黑树中(时间复杂度:logN)
如果想查找元素是否在set中,我们一般使用count(count不是返回的迭代器)
lower_bound(x):大于等于x的最小元素,返回的是迭代器(时间复杂度:logN)
upper_bound(x):大于x的最小元素,返回的是迭代器(时间复杂度:logN)
如果尝试向 set 中插入相同的元素, set 会忽略后续的插入操作,因为 set 中已经存在该元素。
红黑树:
map和multimap的区别:map不能存相同元素,multimap可以,其余使用方法一样
和set的区别:set里面存的一个关键字,map里面是一个关键字key 一个与关键字绑定的值value
头文件:#include<map>//multimap也为此
创建:map<key,value>mp1
eg:map<int,vector<int>>mp2;
size empty begin end erase find count lower_bound upper_bound//跟set使用方法差不多
用范围for遍历时,也为中序遍历,得到有序的序列
insert:向红黑树中插入一个pair类型的,要用{}形式
eg:mp.insert({1,2})
此外map 和multimap重载了[],使其能够像数组一样使用
eg:mp[2]=......//...这里的值是value的
但是注意:如果用[]插入的时候,[]里面的内容不存在于map里,会先插入,然后再拿值
插入的时候,第一个关键字就是[]里面的内容,第二个关键字是一个默认值
所以一般要eg:
if(mp.count('赵六')&&mp['赵六']==4)....如果单单后面那个,就会插入一个赵六了
找小于等于x的最大值的话要lower_bound的迭代器--即可
哈希表:
unordered_set 和unordered_multiset
和set的区别:set有序,unordered_set无序
头文件:#include<unordered_set>//unordered_multiset也为此
创建:unordered_set<T>q;
size empty begin end insert erase find count
也可以用范围for遍历,但是遍历出来的结果是无序的
哈希表:
unordered_map和unordered_multimap
和map的区别以及和map的共同点都和上面一样
除了范围for遍历出来是无序的以外,其他都和map的接口用途一样
查询库函数和容器用法的网站
查询具体用法:https://legacy.cplusplus.com/reference/
如果对用法还是不会的话,可以点击这个链接去查询具体用法
相关文章:
数据结构(蓝桥杯常考点)
数据结构 前言:这个是针对于蓝桥杯竞赛常考的数据结构内容,基础算法比如高精度这些会在下期给大家总结 数据结构 竞赛中,时间复杂度不能超过10的7次方(1秒)到10的8次方(2秒) 空间限制&#x…...

从0到1入门Linux
一、常用命令 ls 列出目录内容 cd切换目录mkdir创建新目录rm删除文件或目录cp复制文件或目录mv移动或重命名文件和目录cat查看文件内容grep在文件中查找指定字符串ps查看当前进程状态top查看内存kill终止进程df -h查看磁盘空间存储情况iotop -o直接查看比较高的磁盘读写程序up…...

灰色地带规避:知识产权校验API的商标库模糊匹配算法
在反向海淘或其他电商业务场景中,为了规避知识产权方面的灰色地带,开发知识产权校验 API 并运用商标库模糊匹配算法是很有必要的。以下将详细介绍商标库模糊匹配算法的设计与实现: 算法设计思路 商标库模糊匹配算法的核心目标是在给定一个待匹…...

React:类组件(中)
dangerouslySetInnerHTML React写进{}内的东西,不允许被当作代码块解析,是为了防止xss攻击和代码注入 XSS(跨站脚本攻击,Cross-Site Scripting) 是一种常见的安全漏洞,攻击者通过注入恶意脚本到网页中&…...

第六次CCF-CSP认证(含C++源码)
第六次CCF-CSP认证 数位之和(easy)思路及AC代码遇到的问题 开心消消乐(easy)思路及AC代码 画图(mid)思路及AC代码 数位之和(easy) 题目链接 思路及AC代码 既然题目要求我们输出各位…...

SpringBoot 如何调用 WebService 接口
前言 调用WebService接口的方式有很多,今天记录一下,使用 Spring Web Services 调用 SOAP WebService接口 一.导入依赖 <!-- Spring Boot Web依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId…...

算法 之 树形dp 树的中心、重心
文章目录 重心实践题目小红的陡峭值 在树的算法中,求解树的中心和重心是一类十分重要的算法 求解树的重心 树的重心的定义:重心是树中的一个节点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点…...

Docker 配置镜像源
》》Daemon {"registry-mirrors": ["https://docker.1ms.run","https://docker.xuanyuan.me"] }》》》然后在重新 docker systemctl restart docker...

Linux 离线部署Ollama和DeepSeek-r1模型
都在复制粘贴联网状态下linux部署deepseek,离线状态下需要下载Ollama和DeepSeek模型,然后将下载包上传到linux中。 1、下载Ollama https://github.com/ollama/ollama/releases 注意:如果CentOS7建议安装V0.5.11版本,V0.5.13需要…...

SQLAlchemy系列教程:如何执行原生SQL
Python中的数据库交互提供了高级API。但是,有时您可能需要执行原始SQL以提高效率或利用数据库特定的特性。本指南介绍在SQLAlchemy框架内执行原始SQL。 在SQLAlchemy中执行原生SQL SQLAlchemy虽然以其对象-关系映射(ORM)功能而闻名ÿ…...
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火 在区块链技术的浪潮中,RuleOS宛如一台强劲的“新引擎”,为个人和企业开发去中心化应用(DApp)注入了前所未有的动力。它以独特的设计理念和强大的功能特性&…...

【编译器】VSCODE烧录ESP32-C3——xiaozhi智能聊天机器人固件
【编译器】VSCODE烧录ESP32-C3——xiaozhi智能聊天机器人固件 文章目录 [TOC](文章目录) 前言一、方法一:使用固件烧录工具1. 安装CH340驱动2. 打开FLASH_DOWNLOAD文件3. 选择芯片类型和烧录方式4. 选择烧录文件5. 参数配置 二、方法二:VSCODE导入工程1.…...

设计模式文章汇总-Golang语言实现
Golang学习笔记_27——单例模式 Golang学习笔记_28——工厂方法模式 Golang学习笔记_29——抽象工厂模式 Golang学习笔记_30——建造者模式 Golang学习笔记_31——原型模式 Golang学习笔记_32——适配器模式 Golang学习笔记_33——桥接模式 Golang学习笔记_34——组合模式 Gola…...

显式 GC 的使用:留与去,如何选择?
目录 一、什么是显式 GC? (一) 垃圾回收的基本原理 (二)显式 GC 方法和行为 1. System.gc() 方法 2. 显式 GC 的行为 (三)显式 GC 的使用场景与风险 1. JVM 如何处理显式 GC 2. 显式 GC…...

SpringMVC概述以及入门案例
目录 SpringMVC概述 为什么需要Spring MVC? SpringMVC入门 工作流程分析 SpringMVC概述 SpringMVC技术与Servlet技术功能等同,均属于Web层开发技术。SpringMVC是一种基于java实现MVC模型的轻量级Web框架。 为什么需要Spring MVC? 在传统J…...

5. 前后端实现文件上传与解析
1. 说明 在实际开发中,比较常见的一个功能是需要在前端页面中选择系统中的某个文件上传到服务器中进行解析,解析后的文件内容可以用来在服务器中当作参数,或者传递给其它组件使用,或者需要存储到数据库中。所以本文就提供一种方式…...

⭐LeetCode周赛 3468. 可行数组的数目——暴力与数学⭐
⭐LeetCode周赛 3468. 可行数组的数目——暴力与数学⭐ 示例 1: 输入:original [1,2,3,4], bounds [[1,2],[2,3],[3,4],[4,5]] 输出:2 解释: 可能的数组为: [1, 2, 3, 4] [2, 3, 4, 5] 示例 2: 输入&…...

javaEE初阶————多线程进阶(2)
今天来继续带大家学习多线程进阶部分啦,今天是最后一期啦,下期带大家做一些多线程的题,我们就可以开始下一个环节啦; 1,JUC(java.util.concurrent)的常见类 1)Callable 接口 我们之…...

Java 虚拟机优化指南:CMS垃圾回收器参数调优与性能监控工具详解
Java 虚拟机优化指南:CMS垃圾回收器参数调优与性能监控工具详解 引言 在高并发、大流量的企业级Java应用中,JVM参数的调优对系统性能至关重要。合理的JVM配置不仅能提高应用响应速度,还能减少垃圾回收造成的停顿时间,提升用户体…...

maven无法解析插件 org.apache.maven.plugins:maven-jar-plugin:3.4.1
解决流程 1.修改maven仓库库地址 2.删除本地的maven仓库 maven插件一直加载有问题: 无法解析插件 org.apache.maven.plugins:maven-jar-plugin:3.4.1 开始以为maven版本有问题,重装了maven,重装了idea工具。结果问题还是没解决。研究之后发现…...

Android Studio右上角Gradle 的Task展示不全
Android Studio 版本如下:Android Studio lguana|2023.21, 发现Gradle 的Tasks阉割严重,如下图,只显示一个other 解决方法如下:**Setting>Experimental>勾选Configure all gradle tasks during Gradle Sync(this can make…...

UDP协议 TCP协议(格式 超时重传 滑动窗口 拥塞控制...)
UDP协议 格式 UDP协议头部格式由8个字节组成,由4个2字节大小的字段组成。 源端口(Source Port,16 位): 发送端的端口号,标识数据从哪个端口发出。如果不需要,则可以填 0。 目标端口࿰…...

爱普生温补晶振 TG5032CFN高精度稳定时钟的典范
在科技日新月异的当下,众多领域对时钟信号的稳定性与精准度提出了极为严苛的要求。爱普生温补晶振TG5032CFN是一款高稳定性温度补偿晶体振荡器(TCXO)。该器件通过内置温度补偿电路,有效抑制环境温度变化对频率稳定性的影响&#x…...

今日头条文章爬虫教程
今日头条文章爬虫教程 随着互联网的发展,新闻资讯类平台如今日头条积累了海量的数据。对于数据分析师、研究人员等群体来说,获取这些数据进行分析和研究具有重要的价值。本文将介绍如何使用Python编写爬虫,爬取今日头条的文章数据。 一、准…...

【网络安全工程】任务11:路由器配置与静态路由配置
目录 一、概念 二、路由器配置 三、配置静态路由CSDN 原创主页:不羁https://blog.csdn.net/2303_76492156?typeblog 一、概念 1、路由器的作用:通过路由表进行数据的转发。 2、交换机的作用:通过学习和识别 MAC 地址,依据 M…...

Compose 实践与探索二 —— 状态订阅与自动更新1
1、自定义 Composable 为什么所有组件都要加 Composable 注解才可以使用? 这是因为 Compose 需要通过 Compose 的编译器插件(Compose Compiler Plugin)在组件函数中增加一些参数,这些参数在调用时有用。通过编译器增加这些参数&…...

linux下文件读写操作
Linux下,文件I/O是操作系统与文件系统之间进行数据传输的关键部分。文件I/O操作允许程序读取和写入文件,管理文件的打开、关闭、创建和删除等操作。 1. 文件描述符 在Linux中,每个打开的文件都由一个文件描述符来表示。文件描述符是一个非负…...

嵌入式学习第二十四天--网络 服务器
服务器模型 tcp服务器: socket bind listen accept recv/send close 1.支持多客户端访问 //单循环服务器 socket bind listen while(1) { accept while(1) { recv/send } } close 2.支持多客户端同时访问 (并发能力) 并发服务器 socket bind …...

Uniapp组件 Textarea 字数统计和限制
Uniapp Textarea 字数统计和限制 在 Uniapp 中,可以通过监听 textarea 的 input 事件来实现字数统计功能。以下是一个简单的示例,展示如何在 textarea 的右下角显示输入的字符数。 示例代码 首先,在模板中定义一个 textarea 元素ÿ…...

【Java 面试 八股文】计算机网络篇
操作系统篇 1. 什么是HTTP? HTTP 和 HTTPS 的区别?2. 为什么说HTTPS比HTTP安全? HTTPS是如何保证安全的?3. 如何理解UDP 和 TCP? 区别? 应用场景?3.1 TCP 和 UDP 的特点3.2 适用场景 4. 如何理解TCP/IP协议?5. DNS协议 是什么?说说DNS 完整的查询…...