《Python实战进阶》No20: 网络爬虫开发:Scrapy框架详解
No20: 网络爬虫开发:Scrapy框架详解
摘要
本文深入解析Scrapy核心架构,通过中间件链式处理、布隆过滤器增量爬取、Splash动态渲染、分布式指纹策略四大核心技术,结合政府数据爬取与动态API逆向工程实战案例,构建企业级爬虫系统。提供完整代码与运行结果,包含法律合规设计与反爬对抗方案。
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。

运行环境与依赖说明
# 环境要求
Python 3.8+
Redis 6.0+ (分布式场景)# 依赖安装
pip install scrapy==2.8.0 scrapy-splash==0.9.0 scrapy-redis==0.7.2
pip install redis==4.5.5 requests==2.31.0 beautifulsoup4==4.12.2
核心概念与实战代码
1. 中间件链式处理机制
核心逻辑:通过process_request和process_response实现请求/响应预处理
# 中间件实现示例:随机User-Agent
class RandomUserAgentMiddleware:def __init__(self):self.user_agents = ["Mozilla/5.0 (Windows NT 10.0...)","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15...)"]def process_request(self, request, spider):request.headers['User-Agent'] = random.choice(self.user_agents)spider.logger.info(f"Using User-Agent: {request.headers['User-Agent']}")# settings.py配置
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.RandomUserAgentMiddleware': 543,
}
输出日志:
[scrapy.core.engine] INFO: Using User-Agent: Mozilla/5.0 (Windows NT 10.0...
2. 增量爬取与布隆过滤器
实现方案:基于Scrapy-Redis的BloomFilter去重
# 布隆过滤器配置(settings.py)
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.BloomFilter"
REDIS_URL = 'redis://localhost:6379'# 启动爬虫(保留历史指纹)
scrapy crawl gov_spider -s SCHEDULER_PERSIST=True
运行效果:
[scrapy_redis.scheduler] INFO: Resuming crawl (5678 requests scheduled)
3. Splash渲染与自动代理池
动态页面处理:集成Splash渲染JavaScript
# 使用SplashRequest爬取动态页面
import scrapy
from scrapy_splash import SplashRequestclass DynamicSpider(scrapy.Spider):name = 'dynamic_spider'def start_requests(self):yield SplashRequest(url="https://example.com/ajax-page",callback=self.parse,args={'wait': 2})def parse(self, response):yield {'content': response.xpath('//div[@class="dynamic-content"]/text()').get()}
输出结果:
{'content': '这是动态加载的内容'}
4. 分布式爬虫指纹策略
分布式架构:通过Redis共享指纹和队列
# 分布式配置(settings.py)
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
REDIS_HOST = '192.168.1.100'
运行命令:
# 在多台机器上启动
scrapy runspider myspider.py -a slave_id=1
scrapy runspider myspider.py -a slave_id=2

实战案例
案例1:政府公开数据结构化爬取
目标:爬取国家统计局季度GDP数据
# items.py定义结构
class GovDataItem(scrapy.Item):quarter = scrapy.Field()gdp = scrapy.Field()growth_rate = scrapy.Field()# spiders/gov_spider.py
class GovSpider(scrapy.Spider):name = 'gov_spider'start_urls = ['http://www.stats.gov.cn/tjsj/zxfb/']def parse(self, response):for row in response.css('table.data-table tr'):yield GovDataItem({'quarter': row.xpath('td[1]/text()').get(),'gdp': row.xpath('td[2]/text()').get(),'growth_rate': row.xpath('td[3]/text()').get()})
输出示例:
[{"quarter": "2023-Q1", "gdp": "284997", "growth_rate": "4.5%"},{"quarter": "2023-Q2", "gdp": "308038", "growth_rate": "6.3%"}
]
案例2:动态API逆向工程
目标:破解某电商商品列表加密参数
# 逆向分析加密参数
import requests
from bs4 import BeautifulSoupdef get_token():response = requests.get('https://api.example.com/init')soup = BeautifulSoup(response.text, 'html.parser')return soup.find('script')['data-token']# 在Scrapy中使用
class ApiSpider(scrapy.Spider):def parse(self, response):token = get_token()yield scrapy.FormRequest(url="https://api.example.com/data",formdata={'token': token, 'page': '1'},callback=self.parse_data)
响应示例:
{"data": [{"id": 1001, "name": "智能手机", "price": 2999},{"id": 1002, "name": "笔记本电脑", "price": 8999}]
}
扩展思考
1. 法律合规设计
# robots.txt遵守中间件
class RobotsTxtMiddleware:def process_request(self, request, spider):if not spider.allowed_domains:return# 校验robots协议rp = RobotFileParser()rp.set_url(f"http://{spider.allowed_domains[0]}/robots.txt")rp.read()if not rp.can_fetch("*", request.url):spider.logger.warning(f"Blocked by robots.txt: {request.url}")return scrapy.Request(url=request.url, dont_filter=True, callback=lambda _: None)
2. 反爬虫对抗测试框架
测试方案:模拟IP封禁、验证码场景
# 使用Selenium测试反爬
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("https://example.com/protected-page")# 检测是否出现验证码
if "验证码" in driver.page_source:print("触发验证码防护")# 调用第三方验证码识别APIcaptcha = solve_captcha(driver.find_element(By.ID, "captcha-img"))driver.find_element(By.ID, "captcha-input").send_keys(captcha)
总结
本文构建了完整的Scrapy技术体系:
- 中间件系统:实现请求指纹管理、动态渲染、代理切换
- 增量机制:通过Redis+BloomFilter实现百亿级URL去重
- 合规设计:内置robots协议校验与速率限制
- 分布式扩展:支持跨服务器协同爬取
📌 实战建议:
- 优先使用
scrapy shell调试Selector- 动态页面优先尝试逆向API而非直接渲染
- 企业级项目建议结合Scrapy-Redis+Gerapy分布式部署
相关阅读:No19-时间序列预测 | No21-微服务架构设计
相关文章:
《Python实战进阶》No20: 网络爬虫开发:Scrapy框架详解
No20: 网络爬虫开发:Scrapy框架详解 摘要 本文深入解析Scrapy核心架构,通过中间件链式处理、布隆过滤器增量爬取、Splash动态渲染、分布式指纹策略四大核心技术,结合政府数据爬取与动态API逆向工程实战案例,构建企业级爬虫系统。…...

2021 年 9 月青少年软编等考 C 语言六级真题解析
目录 T1. 合法出栈序列思路分析T2. 奇怪的括号思路分析T3. 区间合并思路分析T4. 双端队列思路分析T1. 合法出栈序列 题目链接:SOJ D1110 给定一个由不同小写字母构成的长度不超过 8 8 8 的字符串 x x x,现在要将该字符串的字符依次压入栈中,然后再全部弹出。要求左边的字…...

Linux:多线程(单例模式,其他常见的锁,读者写者问题)
目录 单例模式 什么是设计模式 单例模式介绍 饿汉实现方式和懒汉实现方式 其他常见的各种锁 自旋锁 读者写者问题 逻辑过程 接口介绍 单例模式 什么是设计模式 设计模式就是一些大佬在编写代码的过程中,针对一些经典常见场景,给定对应解决方案&…...

shell 脚本的编写学习
学习编写 Shell 脚本是 Linux/Unix 系统管理和自动化的一个非常有用的技能。Shell 脚本是一些 Shell 命令的集合,用户可以用它来自动执行任务、简化工作流程、管理系统等。下面是一个 Shell 脚本学习的入门指南: 1. Shell 脚本基础 Shell 脚本通常是以…...

【氮化镓】高输入功率应力诱导的GaN 在下的退化LNA退化
2019年,中国工程物理研究院电子工程研究所的Tong等人基于实验与第一性原理计算方法,研究了Ka波段GaN低噪声放大器(LNA)在高输入功率应力下的退化机制。实验结果表明,在27 GHz下施加1 W连续波(CW)输入功率应力后,LNA的增益下降约1 dB,噪声系数(NF)增加约0.7 dB。进一…...

根据开始和结束日期,获取每一天和每个月的开始和结束日期的list
获取开始日期与结束日期之间每天的list /*** 根据传入的开始时间和结束时间,筛选出所有的天的list;** param startTime* param endTime*/public Map<String, List<String>> fetchDayListBetweenStartAndEnd(String startTime, String endTime) {// 创建mapMap<…...

Javaweb后端文件上传@value注解
文件本地存储磁盘 阿里云oss准备工作 阿里云oss入门程序 要重启一下idea,上面有cmd 阿里云oss案例集成 优化 用spring中的value注解...

git规范提交之commitizen conventional-changelog-cli 安装
一、引言 使用规范的提交信息可以让项目更加模块化、易于维护和理解,同时也便于自动化工具(如发布工具或 Changelog 生成器)解析和处理提交记录。 通过编写符合规范的提交消息,可以让团队和协作者更好地理解项目的变更历史和版本…...

Java/Kotlin逆向基础与Smali语法精解
1. 法律警示与道德边界 1.1 司法判例深度剖析 案例一:2021年某游戏外挂团伙刑事案 犯罪手法:逆向《王者荣耀》通信协议,修改战斗数据包 技术细节:Hook libil2cpp.so的SendPacket函数 量刑依据:非法经营罪ÿ…...

非软件开发项目快速上手:14款管理软件精选
文章介绍了以下14款项目管理系统:1.Worktile;2.Teambition;3.Microsoft Project;4.Forbes;5.WorkOtter;6.Trello;7.Smartsheet;8.Taiga;9.ClickUp;10.Monday.…...

Redis四种模式在Spring Boot框架下的配置
在Spring Boot框架下配置Redis的四种模式(单机模式、主从模式、哨兵模式、集群模式)可以通过以下方式实现: 1. 单机模式 在application.properties或application.yml中配置Redis的连接信息: # application.properties spring.redi…...

夸父工具箱(安卓版) 手机超强工具箱
如今,人们的互联网活动日益频繁,导致手机内存即便频繁清理,也会莫名其妙地迅速填满,许多无用的垃圾信息悄然占据空间。那么,如何有效应对这一难题呢?答案就是今天新推出的这款工具软件,它能从根…...

混元图生视频-腾讯混元开源的图生视频模型
混元图生视频是什么 混元图生视频是腾讯混元推出的开源图生视频模型,用户可以通过上传一张图片进行简短描述,让图片动起来生成5秒的短视频。模型支持对口型、动作驱动和背景音效自动生成等功能。模型适用于写实、动漫和CGI等多种角色和场景,…...

从零开始打造一个通用的 Vue 卡片组件
前言 大家好,最近在做项目的时候发现我们系统里到处都是各种卡片样式的 UI 元素,每次都要重写一遍真的很烦。于是我花了点时间,封装了一个通用的卡片组件,今天就来分享一下我的开发思路和实现过程。希望能对大家有所帮助…...

选择排序算法OpenMP并行优化
一 选择排序算法原理 时间复杂度,O(n 2)。 每次从未排序序列中选择最小元素,交换到已排序序列末尾。 二 具体步骤 1)初始状态 已排序区间为空,未排序区间为[0,n-1]。 2)第i次迭代 在未排序区间[i, n-1]中找最小值索引min_idx 交换arr[i]与arr[min_idx]。 3)重复…...

Debian系统grub新增启动项
参考链接 给grub添加自定义启动项_linux grub定制 启动项名称自定义-CSDN博客 www.cnblogs.com 1. boot里面的grub.cfg 使用vim打开boot里面的grub.cfg sudo vim /boot/grub/grub.cfg 这时候会看到文件最上方的提示 2. 真正配置grub的文件 从刚才看到的文件提示中&#x…...

VSCode快捷键整理
VSCode快捷键整理 文章目录 VSCode快捷键整理1-VSCode 常用快捷键1-界面操作2-单词移动3-删除操作4-编程相关5-多光标操作6-文件、符号、函数跳转7-鼠标操作8-自动补全操作9-代码折叠操作 1-VSCode 常用快捷键 1-界面操作 文件资源管理器:Ctrl Shift E 跨文件搜…...

刘火良 FreeRTOS内核实现与应用之1——列表学习
重要数据 节点的命名都以_ITEM后缀进行,链表取消了后缀,直接LIST 普通的节点数据类型 /* 节点结构体定义 */ struct xLIST_ITEM { TickType_t xItemValue; /* 辅助值,用于帮助节点做顺序排列 */ struct xLIST_I…...
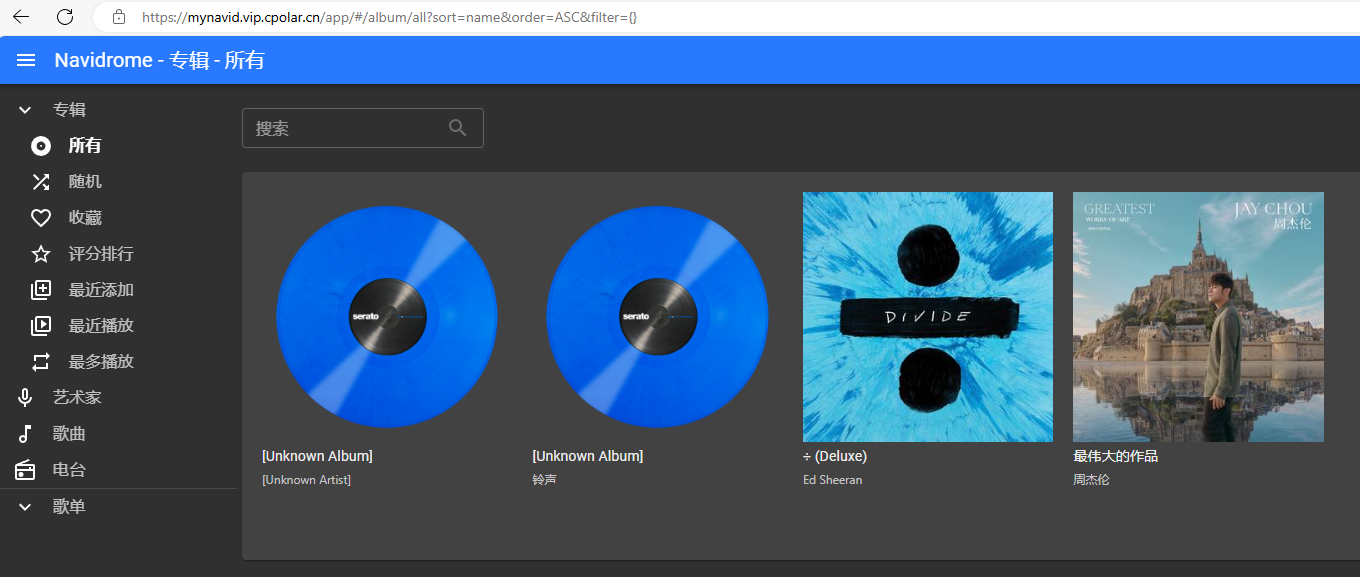
本地部署Navidrome个人云音乐平台随时随地畅听本地音乐文件
文章目录 前言1. 安装Docker2. 创建并启动Navidrome容器3. 公网远程访问本地Navidrome3.1 内网穿透工具安装3.2 创建远程连接公网地址3.3 使用固定公网地址远程访问 前言 今天我要给大家安利一个超酷的私有化音乐神器——Navidrome!它不仅让你随时随地畅享本地音乐…...

数据集构建与训练前准备
训练数据集目录结构与格式 作者笨蛋学法,先将其公式化,后面逐步自己进行修改,读者觉得看不懂可以理解成,由结果去推过程,下面的这个yaml文件就是结果,我们去推需要的文件夹(名字可以不固定,但是…...

jenkins+ant+jmeter生成的测试报告空白
Jenkins能正常构建成功,但是打开Jenkins上的测试报告,则显示空白 在网上找了很多文章,结果跟别人对比测试报告的配置,发现自己跟别人写的不一样 所以跟着别人改,改成一样的再试试 结果,好家伙࿰…...

利用阿里云Atlas地区选择器与Plotly.js实现数据可视化与交互
在数据科学与可视化领域,交互式图表和地图应用越来越成为数据分析和展示的重要手段。本文将介绍如何结合阿里云Atlas地区选择器与Plotly.js,创建动态交互式的数据可视化应用。 一、阿里云Atlas地区选择器简介 阿里云Atlas是阿里云的一款数据可视化产品…...

行为级建模
1、结构化过程语句 verilog有两种结构化过程语句: always initial verilog本质上是并发的。 //声明初值//方法一 reg clk ; initialclk 1b0 ;//方法二 reg clk 1b0 ;2、过程赋值语句 阻塞赋值 非阻塞赋值 非阻塞赋值可以避免竞争:…...

linux安装java8 sdk,使用 tar.gz安装包手动安装
1. 下载 Java 8 SDK 首先,需要从 Oracle 的官方网站或 OpenJDK 的网站下载 Java 8 的 .tar.gz 文件。并上传到服务器 2. 解压 JDK 下载完成后,使用 tar 命令解压文件。打开服务器终端,然后使用以下命令: tar -xvzf jdk-8uXXX-…...

6.聊天室环境安装 - Ubuntu22.04 - elasticsearch(es)的安装和使用
目录 介绍安装安装kibana安装ES客户端使用 介绍 Elasticsearch, 简称 ES,它是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,res…...

【python爬虫】酷狗音乐爬取练习
注意:本次爬取的音乐仅有1分钟试听,仅作学习爬虫的原理,完整音乐需要自行下载客户端。 一、 初步分析 登陆酷狗音乐后随机选取一首歌,在请求里发现一段mp3文件,复制网址,确实是我们需要的url。 复制音频的…...

计算机视觉cv2入门之图像空域滤波(待补充)
空域滤波 空域滤波是指利用像素及像素领域组成的空间进行图像增强的方法。这里之所以用滤波这个词,是因为借助了频域里的概念。事实上空域滤波技术的效果与频域滤波技术的效果可以是等价的,而且有些原理和方法也常借助频域概念来解释。 原理和分类 空域滤波是在图…...

杂项知识笔记搜集
1.pygame pygame可以画出来图形界面,pygame Python仓库 PyGame游戏编程_游戏程序设计csdn-CSDN博客 2.V4L2库 V4L2是Linux上的Camera采集器的框架 Video for Linux ,是从Linux2.1版本开始支持的。HDMI视频采集卡采集到的视频通过USB3.0输出࿰…...

代码随想录算法训练营第六十一天 | 108. 冗余连接 109. 冗余连接II
108. 冗余连接 题目链接:KamaCoder 文档讲解:代码随想录 状态:AC Java代码: import java.util.*;class Main {public static int[] father;public static void main(String[] args) {Scanner scan new Scanner(System.in);int n…...

选择排序算法的SIMD优化
一、优化原理 将查找数组最小值索引的SIMD优化的函数嵌入选择排序主循环,优化最耗时的最小值查找环节,同时保留选择排序的交换逻辑。 二、关键改造步骤 1)最小值查找模块化 复用SIMD优化的 find_min_index_simd函数。 2)动态子数组处理 每次循环处理 arr[i..n-1] 子数…...