主流大语言模型中Token的生成过程本质是串行的
主流大语言模型中Token的生成过程本质是串行的
flyfish
1. 串行生成
-
自回归模型的核心逻辑:
大模型(如GPT-2)采用自回归架构,每个Token的生成必须基于已生成的完整历史序列。例如,生成“今天天气很好”时:输入:<start> 输出1:"今" → 输入更新:<start>今 输出2:"天" → 输入更新:<start>今天 输出3:"天" → 输入更新:<start>今天天 ...(重复或乱码可能因模型困惑导致)每个Token的生成必须依赖前一步的结果,形成严格的链式依赖。
-
计算与生成的分离:
虽然模型内部的矩阵运算(如注意力计算)通过GPU并行加速,但生成顺序必须严格串行。例如:- 第1步:计算第一个Token的概率分布(基于空输入)。
- 第2步:将第一个Token加入输入,计算第二个Token的概率分布。
- 依此类推,无法跳过或提前生成后续Token。
例如:
# 假设模型需生成 "ABC"
步骤1:生成A(依赖空输入)
步骤2:生成B(依赖A)
步骤3:生成C(依赖A+B)
即使步骤1和步骤2的计算在硬件层面并行,生成顺序仍必须是A→B→C。
2. 优化方法的局限性
Beam Search等算法通过维护多个候选序列提升效率,但本质仍是串行生成:
# Beam Search示例(Beam Size=2)
步骤1:生成2个候选("今", "天")
步骤2:基于每个候选生成下一个Token(如"今天" → "气","天天" → "气")
步骤3:依此类推,每次扩展候选序列的长度
每个候选序列的Token仍需按顺序生成,无法并行生成整个序列。
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer# 加载 GPT-2 模型和分词器
model_path = r"gpt2"tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 使用 top - k 采样生成文本
output = model.generate(input_ids,max_length=20,top_k=50,temperature=0.7
)generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("生成的文本:", generated_text)
生成的文本: Once upon a time, the world was a place of great beauty and great danger. The world was
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer# 加载 GPT-2 模型和分词器
model_path = r"gpt2"tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)# 输入文本
input_text = "Once upon a time"
# 对输入文本进行分词
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 初始化生成的序列
generated_sequence = input_ids# 定义最大生成长度
max_length = 20print("顺序生成的 token:")
for step in range(max_length):# 使用模型进行预测with torch.no_grad():outputs = model(generated_sequence)logits = outputs.logits[:, -1, :] # 获取最后一个 token 的预测结果# 选择概率最大的 tokennext_token_id = torch.argmax(logits, dim=-1).unsqueeze(0)# 将生成的 token 添加到序列中generated_sequence = torch.cat([generated_sequence, next_token_id], dim=-1)# 解码并打印生成的 token 及其位置next_token = tokenizer.decode(next_token_id[0].item())print(f"步骤 {step + 1}: 生成 token '{next_token}',当前序列长度: {generated_sequence.shape[1]}")# 解码并打印完整的生成序列
generated_text = tokenizer.decode(generated_sequence[0], skip_special_tokens=True)
print("\n完整生成的文本:", generated_text)
顺序生成的 token:
步骤 1: 生成 token ',',当前序列长度: 5
步骤 2: 生成 token ' the',当前序列长度: 6
步骤 3: 生成 token ' world',当前序列长度: 7
步骤 4: 生成 token ' was',当前序列长度: 8
步骤 5: 生成 token ' a',当前序列长度: 9
步骤 6: 生成 token ' place',当前序列长度: 10
步骤 7: 生成 token ' of',当前序列长度: 11
步骤 8: 生成 token ' great',当前序列长度: 12
步骤 9: 生成 token ' beauty',当前序列长度: 13
步骤 10: 生成 token ' and',当前序列长度: 14
步骤 11: 生成 token ' great',当前序列长度: 15
步骤 12: 生成 token ' danger',当前序列长度: 16
步骤 13: 生成 token '.',当前序列长度: 17
步骤 14: 生成 token ' The',当前序列长度: 18
步骤 15: 生成 token ' world',当前序列长度: 19
步骤 16: 生成 token ' was',当前序列长度: 20
步骤 17: 生成 token ' a',当前序列长度: 21
步骤 18: 生成 token ' place',当前序列长度: 22
步骤 19: 生成 token ' of',当前序列长度: 23
自回归架构是许多大语言模型顺序生成Token的根本原因,并且其链式依赖特性确实有助于确保生成过程的逻辑连贯性。
自回归架构与Token生成
-
自回归机制:
- 在自回归模型中,比如GPT系列模型,生成下一个Token的过程依赖于前面已经生成的所有Token。具体来说,生成第 t t t个Token时,模型会基于前 t − 1 t-1 t−1个Token来计算概率分布,然后从中采样或选择最有可能的下一个Token。
- 这种链式依赖关系(即每个Token的生成依赖于之前的全部或部分Token)保证了文本生成的逻辑一致性和连贯性。
-
串行生成 vs 并行生成:
- 串行生成:传统的大语言模型如GPT系列,在推理阶段通常是逐个Token串行生成的。这是因为每个新Token的生成都需要利用到之前所有已生成的Token作为上下文输入,这种依赖关系限制了并行处理的可能性。
- 尝试并行化:尽管存在一些研究和方法试图提高生成效率,例如通过投机解码(Speculative Decoding)或者使用多个模型同时预测不同位置的Token,但这些方法并没有完全改变基本的自回归生成机制。大多数情况下,核心的Token生成步骤仍然是串行进行的,因为当前Token的生成必须等待前面的Token确定下来才能开始。
3. 数学本质的"自相关性"
自回归(Autoregressive)模型中的"自",自回归的核心在于当前输出仅依赖于自身历史输出。用数学公式表示为:
x t = ϕ 1 x t − 1 + ϕ 2 x t − 2 + ⋯ + ϕ p x t − p + ϵ t x_t = \phi_1 x_{t-1} + \phi_2 x_{t-2} + \dots + \phi_p x_{t-p} + \epsilon_t xt=ϕ1xt−1+ϕ2xt−2+⋯+ϕpxt−p+ϵt
- 自相关性:模型通过自身序列的滞后项( x t − 1 , x t − 2 x_{t-1}, x_{t-2} xt−1,xt−2等)预测当前值
- 内生性:所有变量均来自同一序列,区别于普通回归模型中的外生变量
例如,股票价格预测模型中, x t x_t xt(今日股价)仅依赖于过去5天的股价( x t − 1 x_{t-1} xt−1到 x t − 5 x_{t-5} xt−5),而非外部因素如新闻、财报等。
4. 生成过程的"自我迭代"
在自然语言处理中,这种"自"特性体现为:
- 链式生成:每个Token的生成必须基于已生成的Token序列
- 因果掩码:Transformer架构中,每个位置i的注意力被限制在1到i-1的位置
- 动态更新:每生成一个Token,模型的内部状态(隐藏层激活值)会被更新
以GPT-2生成句子为例:
输入:"今天天气"
生成过程:
1. 预测第一个Token:"很"(基于"今天天气")
2. 预测第二个Token:"好"(基于"今天天气很")
3. 预测第三个Token:"啊"(基于"今天天气很好")
5. 与其他模型的对比
| 模型类型 | 是否"自"依赖 | 典型应用场景 |
|---|---|---|
| 自回归模型 | 仅依赖自身历史 | 文本生成、时间序列预测 |
| 非自回归模型 | 不依赖自身历史 | 图像超分辨率、语音识别 |
| 混合模型 | 部分依赖自身历史 | 对话系统(结合外部知识) |
相关文章:

主流大语言模型中Token的生成过程本质是串行的
主流大语言模型中Token的生成过程本质是串行的 flyfish 1. 串行生成 自回归模型的核心逻辑: 大模型(如GPT-2)采用自回归架构,每个Token的生成必须基于已生成的完整历史序列。例如,生成“今天天气很好”时:…...

3.03-3.09 Web3 游戏周报:Sunflower Land 周留存率 74.2%,谁是本周最稳链游?
回顾上周的区块链游戏概况,查看 Footprint Analytics 与 ABGA 最新发布的数据报告。 【3.03–3.09】Web3 游戏行业动态 Sui 背后开发公司 Mysten Labs 宣布收购游戏开发平台 ParasolYescoin 创始人因合伙人纠纷被警方带走,案件升级为刑事案件Animoca B…...

高级java每日一道面试题-2025年2月18日-数据库篇-MySQL 如何做到高可用方案?
如果有遗漏,评论区告诉我进行补充 面试官: MySQL 如何做到高可用方案? 我回答: 在Java高级面试中,讨论MySQL如何实现高可用性方案是一个重要话题。这不仅涉及到数据库的稳定性和可靠性,还关系到系统的整体性能和用户体验。以下是结合提供的信息进行综…...

【编程题】7-5 堆中的路径
7-5 堆中的路径 1 题目原文2 思路解析3 代码实现 1 题目原文 题目链接:7-5 堆中的路径 将一系列给定数字插入一个初始为空的最小堆 h h h。随后对任意给定的下标 i i i,打印从第 i i i 个结点到根结点的路径。 输入格式: 每组测试第 1 1 1 行包含 …...

Scala 中的访问修饰符
在Scala中,面向对象的权限控制主要通过访问修饰符来实现。Scala提供了以下几种访问修饰符来控制类、对象、成员变量和方法的访问权限: 1. 默认访问权限(无修饰符) 如果没有指定任何访问修饰符,成员默认是public的&…...

flask_restx 定义任意类型参数
之前定义的content只是string,现在需要支持即可以string也可以list from flask_restx import fieldsclass Messages:def get_model(api):return api.model("Message",{"role": fields.String(requiredTrue, description"The role of messa…...

Unity3D网格简化与LOD技术详解
前言 在Unity3D游戏开发中,网格简化(Mesh Simplification)和细节层次(Level of Detail, LOD)技术是优化渲染性能的关键手段,尤其在处理复杂场景和高精度模型时至关重要。这两种技术通过减少模型的几何复杂…...

爬取数据时如何处理可能出现的异常?
在爬取数据时,处理可能出现的异常是确保爬虫稳定运行的关键。以下是一些常见的异常处理策略和具体实现方法,这些方法可以帮助你在爬虫开发中更有效地应对各种问题。 1. 使用 try-catch 块捕获异常 在PHP中,try-catch 块是处理异常的基本工具…...

TCP/IP原理详细解析
前言 TCP/IP是一种面向连接,可靠的传输,传输数据大小无限制的。通常情况下,系统与系统之间的http连接需要三次握手和四次挥手,这个执行过程会产生等待时间。这方面在日常开发时需要注意一下。 TCP/IP 是互联网的核心协议族&…...

MPPT与PWM充电原理及区别详解
MPPT(最大功率点跟踪)和PWM(脉宽调制)是太阳能充电控制器中常用的两种技术,它们在原理、效率和适用场景上有显著区别。以下是两者的详细对比: 1. 工作原理 PWM(脉宽调制) 核心机制…...

数据量过大的时候导出数据很慢
原因解析 速度慢无非两个原因: sql取数很慢程序很慢 sql很慢有3种原因: sql本身查询不合理,需要优化数据库没有索引多次频繁访问数据,造成了不必要的开销 取消多次获取数据,一次获取 框定一个大致的范围,获取此次查询的所有数据使用map设置数据,没有主键使用傅和主键拼接数据 /…...
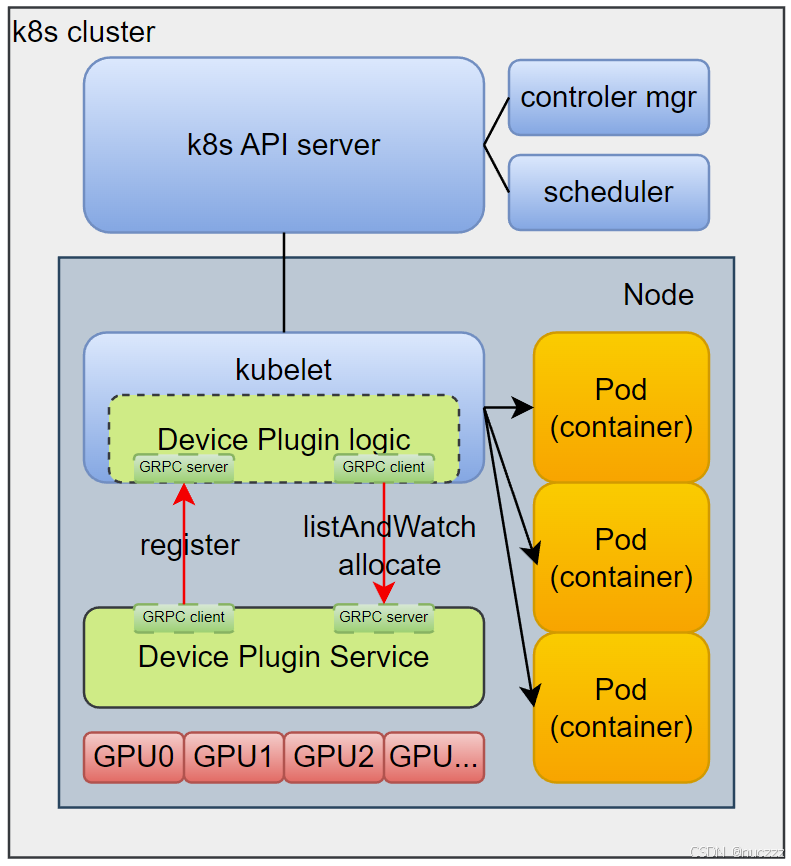
NVIDIA k8s-device-plugin源码分析与安装部署
在《kubernetes Device Plugin原理与源码分析》一文中,我们从源码层面了解了kubelet侧关于device plugin逻辑的实现逻辑,本文以nvidia管理GPU的开源github项目k8s-device-plugin为例,来看看设备插件侧的实现示例。 一、Kubernetes Device Pl…...

langChainv0.3学习笔记(初级篇)
LangChain自0.1版本发布以来,已经历了显著的进化,特别是向AI时代的适应性提升。在0.1版本中,LangChain主要聚焦于提供基本的链式操作和工具集成,帮助开发者构建简单的语言模型应用。该版本适用于处理简单任务,但在应对…...

聚焦两会:科技与发展并进,赛逸展2025成创新新舞台
在十四届全国人大三次会议和全国政协十四届三次会议期间,代表委员们围绕多个关键议题展开深入讨论,为国家未来发展谋篇布局。其中,技术竞争加剧与经济转型需求成为两会焦点,将在首都北京举办的2025第七届亚洲消费电子技术贸易展&a…...
)
Xilinx ZYNQ FSBL解读:LoadBootImage()
篇首 最近突发奇想,Xilinx 的集成开发环境已经很好了,很多必要的代码都直接生成了,这给开发者带来了巨大便利的同时,也让人错过了很多代码的精彩,可能有很多人用了很多年了,都还无法清楚的理解其中过程。博…...

flutter的HTTP headers用法介绍
flutter的HTTP headers用法介绍 在 Flutter 中,HTTP headers 是用于在发送 HTTP 请求时传递额外信息的关键部分。它们可以用于身份验证、缓存控制、内容类型声明等。以下是关于 Flutter 中 HTTP headers 的详细说明和用法。 1. 什么是 HTTP Headers? H…...

Flutter开发避坑指南:高频问题排查与性能调优实战
目录 一、使用中常见问题 1.环境与配置问题 2.Widget 重建与状态管理 3.布局与绘制问题 4.动画与卡顿(Jank)问题 5.平台相关问题 二、Flutter实战14问 1.如何使用 Flutter 进行多语言支持? 1. 添加依赖 2. 配置 Material App 3. 创…...

Uniapp实现地图获取定位功能
摘要:本文将手把手教你如何在Uniapp项目中集成地图功能、实现定位获取,并解决微信小程序、APP、H5三端的兼容性问题🚀🚀🚀 一、环境准备 地图平台选择 微信小程序:腾讯地图(强制使用)…...

Ubuntu 24.04 安装与配置 JetBrains Toolbox 指南
📌 1. JetBrains Toolbox 介绍 JetBrains Toolbox 是 JetBrains 开发的工具管理器,可用于安装、更新和管理 IntelliJ IDEA、PyCharm、WebStorm、CLion 等。本指南记录了 JetBrains Toolbox 在 Ubuntu 24.04 上的 安装、路径调整、权限管理 及 遇到的问题…...

【AI】神经网络|机器学习——图解Transformer(完整版)
Transformer是一种基于注意力机制的序列模型,最初由Google的研究团队提出并应用于机器翻译任务。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer仅使用自注意力机制(self-attention)来处理输入序列和输出序列,因此可以并行计算,极大地提高了计算效率…...

【VUE2】第二期——生命周期及工程化
目录 1 生命周期 1.1 介绍 1.2 钩子 2 可视化图表库 3 脚手架Vue CLI 3.1 使用步骤 3.2 项目目录介绍 3.3 main.js入口文件代码介绍 4 组件化开发 4.1 组件 4.2 普通组件注册 4.2.1 局部注册 4.2.2 全局注册 1 生命周期 1.1 介绍 Vue生命周期:就是…...

贪心算法三
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解什么是贪心算法,并且掌握贪心算法。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! >…...
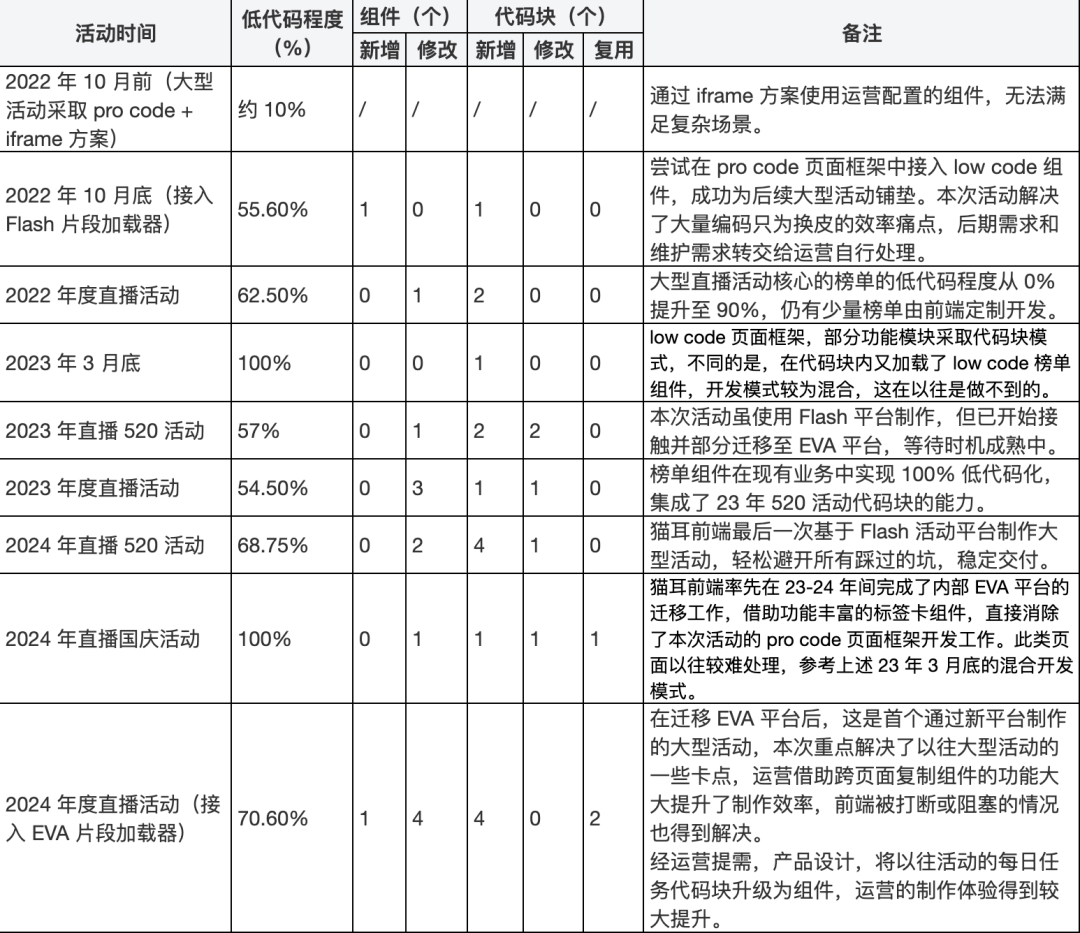
猫耳大型活动提效——组件低代码化
1. 引言 猫耳前端在开发活动的过程中,经历过传统的 pro code 阶段,即活动页面完全由前端开发编码实现,直到 2020 年接入公司内部的低代码活动平台,满足了大部分日常活动的需求,运营可自主配置活动并上线,释…...

机器学习 Day02,matplotlib库绘图
1.matplotlib图像结构 容器层:画板,画布,坐标系辅助层:刻度,标题,网格,图例等图像层:折线图(主讲),饼图,直方图,柱状图等…...

MySQL中有哪几种锁?
大家好,我是锋哥。今天分享关于【MySQL中有哪几种锁?】面试题。希望对大家有帮助; MySQL中有哪几种锁? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 MySQL 中,锁是用于确保数据的一致性和并发控制的机…...

Unity单例模式更新金币数据
单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。在游戏开发中,单例模式非常适合用于管理全局唯一的数据,比如玩家的金币数量。通过使用单例…...

【javaEE】多线程(进阶)
1.❤️❤️前言~🥳🎉🎉🎉 Hello, Hello~ 亲爱的朋友们👋👋,这里是E绵绵呀✍️✍️。 如果你喜欢这篇文章,请别吝啬你的点赞❤️❤️和收藏📖📖。如果你对我的…...
:python爬虫实现登录功能)
python从入门到精通(二十四):python爬虫实现登录功能
这里写目录标题 requests实现登录功能selenium实现登录功能 requests实现登录功能 使用 requests 库结合会话(Session)来尝试登录。不过豆瓣有反爬虫机制,这种方式可能会受到验证码等因素的限制 import requests import re# 豆瓣登录页面 l…...

Flask Jinja语法总结篇
目录 1️⃣ 变量(Variables) 2️⃣ 条件语句(if 语句) 3️⃣ 循环(for 语句) 4️⃣ 过滤器(Filters) 5️⃣ 宏(Macros,类似于函数) 6️⃣ 模板继承(Template Inheritance) 7️⃣ 包含模板(Include) 8️⃣ Flask 结合 Jinja 总结 Jinja 是 Flask 默认使…...

Vue3实战学习(Element-Plus常用组件的使用(输入框、下拉框、单选框多选框、el-image图片))(上)(5)
目录 一、Vue3工程环境配置、项目基础脚手架搭建、Vue3基础语法、Vue3集成Element-Plus的详细教程。(博客链接如下) 二、Element-Plus常用组件使用。 (1)el-input。(input输入框) <1>正常状态的el-input。 <2>el-input的disable状态。 <3…...