如何简单预估大模型运行所需的显存
模型消耗的显存主要来源于模型参数,前向/反向,梯度以及优化器……
1、为什么显存很重要
显存就是显卡的“仓库”和“高速公路”。 容量越大,能存储的图形数据就越多,就能支持更高分辨率、更高纹理质量的游戏或图形程序。 速度越快,GPU就能更快地访问和处理这些数据,从而提高并行运算的速度。
1.1 gpu与cpu
| 特性 | CPU | GPU |
|---|---|---|
| 设计目标 | 通用型处理器 | 图形处理器 |
| 核心数量 | 少,但每个核心性能强大 | 多,但每个核心性能相对较弱 |
| 擅长任务 | 复杂逻辑运算、串行计算、通用计算 | 并行计算、图形渲染、GPGPU |
| 应用场景 | 操作系统、应用程序、日常办公 | 游戏、视频编辑、机器学习、科学计算 |
| 形象比喻 | 通才型工程师 | 专才型工程师 |
在深度学习中,gpu提高了模型的运行和计算速度。
比如:使用CIFAR10数据集,模型为两个卷积层 + 一个池化层 + 三个线性层
Net((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)CPU 和 GPU 训练时间如下:
| Batch Size | Epochs | CPU Training Time (seconds) | GPU Training Time (seconds) |
|---|---|---|---|
| 4 | 2 | 144.4101 | 112.0614 |
| 64 | 2 | 38.8210 | 26.9846 |
| 64 | 10 | 190.9023 | 139.1529 |
2、模型参数
以上面的模型为例(Batch Size=4):
显存占用量可以通过以下公式计算:显存占用(字节) = 参数数量 × 每个参数的字节数
常见数据类型对应的大小如下:
float32: 4 字节float16: 2 字节bfloat16: 2 字节
Total number of trainable parameters: 62006
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
参数数量:
- 权重:3(输入通道)×5(高度)×5(宽度)×6(输出通道)=
- 偏置:6(输出通道)=6
- 这一层总共有 456 个参数
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
这一层 没有可学习的参数。
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
- 权重: 6 (输入通道) * 5 (高度) * 5 (宽度) * 16 (输出通道) = 2400
- 偏置: 16 (输出通道) = 16
- 这一层总共有 2416 个参数
(fc1): Linear(in_features=400, out_features=120, bias=True)
- 权重:
in_features(输入特征数量) *out_features(输出特征数量) = 400 * 120 = 48000 - 偏置:
out_features(输出特征数量) = 120 - 这一层总共有 48120 个参数
(fc2): Linear(in_features=120, out_features=84, bias=True)
- 权重:
in_features(输入特征数量) *out_features(输出特征数量) = 120 * 84 = 10080 - 偏置:
out_features(输出特征数量) = 84 - 这一层总共有 10164 个参数
(fc3): Linear(in_features=84, out_features=10, bias=True)
- 权重:
in_features(输入特征数量) *out_features(输出特征数量) = 84 * 10 = 840 - 偏置:
out_features(输出特征数量) = 10 - 这一层总共有 850 个参数
总参数量: 456 + 0 + 2416 + 48120 + 10164 + 850 = 62006 个参数
PyTorch 使用 32 位浮点数 (float32) 来存储参数。 每个 float32 数字占用 4 个字节。
- 参数占用空间: 62006 个参数 * 4 字节/参数 = 248024 字节
- 转换为 KB 和 MB:
- 248024 字节 / 1024 字节/KB = 242.21 KB
- 242.21 KB / 1024 KB/MB = 0.236 MB
3.激活值的显存占用
激活值是每一层在前向传播过程中生成的输出数据。这些激活值需要暂时存储,以供后续层使用,并在反向传播时计算梯度。
激活占用计算:显存占用(字节) = 激活数量 × 每个激活的字节数
激活数量取决于:
- 批量大小(Batch Size)
- 输出特征图的尺寸(Height×Width)
- 输出通道数(C_out)
1. 确定每一层的输出尺寸和激活数量 (以 batch_size = 4 为例,使用 float32):
-
输入层:
- 尺寸: 32 x 32
- 通道: 3 (RGB)
- 激活数量 (用于计算显存): 4 * 32 * 32 * 3 = 12288
- 显存占用: 12288 * 4 字节 ≈ 0.047 MB
-
conv1:
- 输入: 32 x 32 x 3
- 卷积核: 5x5
- 输出通道: 6
- 计算输出尺寸: (32 - 5 + 0) / 1 + 1 = 28,输出特征图: 28 x 28
- 激活数量: 4 * 28 * 28 * 6 = 18816
- 显存占用: 18816 * 4 字节 ≈ 0.072 MB
-
pool (MaxPool2d):
- 输入: 28 x 28 x 6
- 池化核: 2x2
- 输出: (28 / 2) x (28 / 2) x 6 = 14 x 14 x 6
- 激活数量: 4 * 14 * 14 * 6 = 4704
- 显存占用: 4704 * 4 字节 ≈ 0.018 MB
-
conv2:
- 输入: 14 x 14 x 6
- 卷积核: 5x5
- 输出通道: 16
- 计算输出尺寸: (14 - 5 + 0) / 1 + 1 = 10,输出特征图: 10 x 10
- 激活数量: 4 * 10 * 10 * 16 = 6400
- 显存占用: 6400 * 4 字节 ≈ 0.025 MB
-
pool (MaxPool2d):
- 输入: 10 x 10 x 16
- 池化核: 2x2
- 输出: (10 / 2) x (10 / 2) x 16 = 5 x 5 x 16
- 激活数量: 4 * 5 * 5 * 16 = 1600
- 显存占用: 1600 * 4 字节 ≈ 0.006 MB
-
fc1 (Linear):
- 输入: 5 * 5 * 16 = 400 (这里需要展开特征图)
- 输出: 120
- 激活数量: 4 * 120 = 480
- 显存占用: 480 * 4 字节 ≈ 0.002 MB
-
fc2 (Linear):
- 输入: 120
- 输出: 84
- 激活数量: 4 * 84 = 336
- 显存占用: 336 * 4 字节 ≈ 0.0013 MB
-
fc3 (Linear):
- 输入: 84
- 输出: 10
- 激活数量: 4 * 10 = 40
- 显存占用: 40 * 4 字节 ≈ 0.00015 MB
总激活数量 = 12288 + 18816 + 4704 + 6400 + 1600 + 480 + 336 + 40 = 44664
总显存占用 ≈ 0.047 + 0.072 + 0.018 + 0.025 + 0.006 + 0.002 + 0.0013 + 0.00015 ≈ 0.171 MB
4.梯度信息的显存占用
梯度信息的显存占用是深度学习模型训练过程中一个重要的考虑因素。它与多个因素相关,包括模型结构、激活值的规模、批量大小以及是否使用混合精度训练等。
1. 梯度与参数/激活的关系:
- 每个可训练的参数都有一个梯度: 在反向传播过程中,损失函数对每个可训练的参数计算梯度,用于更新参数。因此,如果一个模型有 N 个可训练的参数,那么至少需要存储 N 个梯度值。
- 激活梯度 (激活函数的导数): 反向传播也需要计算激活函数输出的梯度 (或导数),以便将梯度传播到更早的层。 这些激活梯度与激活值本身的大小和形状相同。
2. 梯度显存占用计算:
-
参数梯度: 参数梯度显存占用与模型参数占用相同,在前面的计算中我们已经计算过了参数占用的显存空间。
-
激活梯度: 激活梯度显存占用和激活值占用相同,在前面的计算中我们也计算了激活值占用的显存空间。
-
因此总的来说,梯度信息至少需要和激活值以及参数相同的存储空间,但是实际情况会更加复杂。
3. 影响梯度显存占用的因素:
- 模型大小: 更大的模型 (更多的层、更多的参数) 会有更多的梯度需要存储。
- 批量大小: 梯度是针对每个小批量数据计算的,因此更大的批量大小通常需要更大的显存来存储梯度。
- 输入数据大小: 更大的输入图像或序列会导致更大的激活值,进而导致更大的梯度。
- 数据类型: 使用 32 位浮点数 (float32) 需要 4 个字节来存储一个梯度值,而使用 16 位浮点数 (float16) 只需要 2 个字节。
- 优化器状态: 有些优化器 (例如 Adam) 除了存储梯度之外,还需要存储额外的状态信息 (例如动量和方差)。这些状态信息通常与参数的大小相同,因此会显著增加显存占用。
4. 如何测量梯度显存占用?
PyTorch 没有直接提供测量梯度显存占用的函数。 然而,您可以使用 torch.cuda.memory_allocated() 和 torch.cuda.max_memory_allocated() 来监控 GPU 显存的使用情况,并在训练的不同阶段 (例如前向传播之后、反向传播之后) 记录显存占用,以此来估算梯度信息的显存占用。
5.优化器状态占用计算
| 优化器 | 状态信息 | 状态显存占用 (与模型参数量相比) |
|---|---|---|
| SGD | 无 | 0 |
| Momentum | 动量 | 参数数量 |
| Adam | 动量、方差 | 参数数量 * 2 |
| RMSprop | 平方梯度的滑动平均 | 参数数量 |
我们使用之前定义的 Net 模型,其总参数量为 62006。
- SGD: 优化器状态占用 = 0
- Momentum: 优化器状态占用 = 62006 * 4 bytes (float32) ≈ 0.236 MB
- Adam: 优化器状态占用 = 62006 * 2 * 4 bytes (float32) ≈ 0.476 MB
- RMSprop: 优化器状态占用 = 62006 * 4 bytes (float32) ≈ 0.236 MB
| 批量大小 (Batch Size) | 优化器 | 激活值 (MB) (前向传播) | 梯度 (MB) (近似) | 优化器状态 (MB) | 参数 (MB) | 总计 (MB) |
|---|---|---|---|---|---|---|
| 4 | SGD | 0.171 | 0.171 | 0 | 0.236 | 0.578 |
| 4 | Momentum | 0.171 | 0.171 | 0.236 | 0.236 | 0.814 |
| 4 | Adam | 0.171 | 0.171 | 0.476 | 0.236 | 1.054 |
| 64 | SGD | 2.73 | 2.73 | 0 | 0.236 | 5.70 |
| 64 | Momentum | 2.73 | 2.73 | 0.236 | 0.236 | 5.93 |
| 64 | Adam | 2.73 | 2.73 | 0.476 | 0.236 | 6.17 |
由上面可以看出,显存的占用和Batch_Size有着明显的线性关系。
6.如何查看显存使用情况
建议使用 torch.cuda.memory_allocated() 和 torch.cuda.max_memory_allocated() 在训练过程中测量实际的显存占用,从而得到更准确的结果。
import torch# 检查 CUDA 是否可用
if not torch.cuda.is_available():print("CUDA is not available. This example requires a GPU.")exit()# 设置设备 (可以使用 torch.device('cuda:0') 等指定 GPU)
device = torch.device('cuda')# 定义一个简单的模型
model = torch.nn.Linear(10, 10).to(device)# 创建一些随机数据
input_tensor = torch.randn(1, 10).to(device)# 在运行模型之前记录显存使用情况
print(f"Before model run:")
print(f" Allocated: {torch.cuda.memory_allocated(device=device) / 1024**2:.2f} MB") # 转换为 MB
print(f" Max Allocated: {torch.cuda.max_memory_allocated(device=device) / 1024**2:.2f} MB")# 运行模型
output_tensor = model(input_tensor)# 在运行模型之后记录显存使用情况
print(f"\nAfter model run:")
print(f" Allocated: {torch.cuda.memory_allocated(device=device) / 1024**2:.2f} MB")
print(f" Max Allocated: {torch.cuda.max_memory_allocated(device=device) / 1024**2:.2f} MB")# 执行反向传播 (计算梯度)
loss = output_tensor.sum()
loss.backward()# 在反向传播之后记录显存使用情况
print(f"\nAfter backward pass:")
print(f" Allocated: {torch.cuda.memory_allocated(device=device) / 1024**2:.2f} MB")
print(f" Max Allocated: {torch.cuda.max_memory_allocated(device=device) / 1024**2:.2f} MB")# 释放显存 (如果需要)
del model, input_tensor, output_tensor, loss
torch.cuda.empty_cache() # 尝试释放未使用的显存print(f"\nAfter clearing cache:")
print(f" Allocated: {torch.cuda.memory_allocated(device=device) / 1024**2:.2f} MB")
print(f" Max Allocated: {torch.cuda.max_memory_allocated(device=device) / 1024**2:.2f} MB")
7.如何优化显存占用策略
1. 减小批量大小 (Reduce Batch Size)
- 原理: 批量大小直接影响了每次迭代中需要存储的激活值和梯度数量。 减小批量大小可以线性地减少显存占用。
- 优点: 实现简单,效果明显。
- 缺点: 可能会影响训练的稳定性和收敛速度,需要调整学习率和其他超参数。 小批量还可能导致 GPU 利用率不足。
- 适用场景: 当遇到显存溢出 (OOM) 错误时,这是最先尝试的策略。
2. 混合精度训练 (Mixed Precision Training)
- 原理: 使用 16 位浮点数 (float16) 替代 32 位浮点数 (float32) 来存储参数、激活值和梯度。 float16 占用更少的显存 (一半),并且在支持的硬件上可以加速计算。
- 优点: 显著减少显存占用,通常也能加速训练 (尤其是在 NVIDIA Tensor Core 上)。
- 缺点: 可能会降低模型的精度。 需要仔细处理缩放问题,以避免梯度消失或溢出。
- 适用场景: 大部分现代 GPU 都支持混合精度训练。 这是在不显著影响精度的情况下减少显存占用的有效方法。
3. 梯度累积 (Gradient Accumulation)
- 原理: 将多个小批量的梯度累积起来,然后再更新模型参数。 这样可以模拟更大的批量大小,而无需一次性将所有数据加载到显存中。
- 优点: 在不增加显存占用的情况下,获得与更大批量大小相似的训练效果。
- 缺点: 增加了训练时间,因为需要多次前向和反向传播才能更新参数。
4. 模型并行化 (Model Parallelism)
- 原理: 将模型的不同部分分配到不同的 GPU 上进行训练。 每个 GPU 只需存储模型的一部分和相应的数据。
- 优点: 可以训练非常大的模型,这些模型无法在单个 GPU 上容纳。
- 缺点: 实现复杂,需要仔细设计模型划分和数据通信策略。 GPU 之间的通信可能成为瓶颈。
- 适用场景: 当模型非常大,并且有多个 GPU 可用时。 PyTorch 提供了
torch.nn.DataParallel和torch.nn.DistributedDataParallel来实现模型并行化。torch.distributed包提供了更高级的分布式训练功能。
5. 数据并行化 (Data Parallelism)
- 原理: 将数据分成多个小批量,并将每个小批量分配到不同的 GPU 上进行训练。 每个 GPU 存储完整的模型副本,并独立计算梯度。 然后,将梯度进行同步,并更新所有 GPU 上的模型参数。
- 优点: 实现相对简单,可以加速训练。
- 缺点: 每个 GPU 都需要存储完整的模型副本,因此显存占用与单 GPU 训练相同。
- 适用场景: 当数据量很大,但模型可以容纳在单个 GPU 上时。
6. 量化 (Quantization)
- 原理: 使用更低精度的数据类型 (例如,int8) 来表示模型参数和激活值。
- 优点: 显著减少模型大小和显存占用,通常也能加速推理。
- 缺点: 可能会降低模型的精度。 需要仔细训练和调整量化参数。
- 适用场景: 当需要部署模型到资源受限的设备上时,或者需要进一步压缩模型大小时。 PyTorch 提供了量化工具包来实现量化。
大模型参数对照表
精度对照
| dtype | 1B(10亿)参数所需占用显存 |
|---|---|
| float32(全精度) | 4G |
| bf16/fl16(半精度) | 2G |
| int8 | 1G |
| int4 | 0.5G |
模型显存对照
参考
深入解析神经网络的GPU显存占用与优化-CSDN博客
深入解析大模型显存占用大小:公式、推导及实例分析_模型参数 显卡 计算公式-CSDN博客
百度安全验证
相关文章:
如何简单预估大模型运行所需的显存
模型消耗的显存主要来源于模型参数,前向/反向,梯度以及优化器…… 1、为什么显存很重要 显存就是显卡的“仓库”和“高速公路”。 容量越大,能存储的图形数据就越多,就能支持更高分辨率、更高纹理质量的游戏或图形程序。 速度越…...

Excel 中如何实现数据透视表?
Excel 中如何实现数据透视表? 数据透视表(PivotTable)是 Excel 中强大的数据分析工具,能够快速汇总、分析和展示大量数据。本文将详细介绍如何在 Excel 中创建和使用数据透视表。 1. 数据透视表的基本概念 数据透视表是一种交互…...
)
C语言中getchar和putchar函数详解,理解多组数据输入的问题中的EOF(-1)
引言 C语言中getchar和putchar函数详解,理解多组数据输入的问题中的EOF(-1)。 1.getchar() 函数原型: int getchar ( void ); getchar() 函数返回用户从键盘输入的一个字符,使用时不带有任何参数。 程序运行到这个命…...

python基础知识补充
一.区分列表、元组、集合、字典: 二.输出: <1>格式化输出字符串: 格式符号转换%s字符串%d有符号的十进制整数%f浮点数%c字符%u无符号十进制整数%o八进制整数%x十六进制整数(小写ox)%X十六进制整数(大写OX)%e科…...

MySql自动安装脚本
一、脚本安装流程 1. 添加MySQL的Repository 使用wget命令从MySQL官方网站下载Yum Repository的RPM包。使用rpm -ivh命令安装下载的RPM包,以添加MySQL的Yum Repository。 2. 安装mysql-community-server 使用yum install -y mysql-community-server --nogpgchec…...

STM32-I2C通信外设
目录 一:I2C外设简介 二:I2C外设数据收发 三:I2C的复用端口 四:主机发送和接收 五:硬件I2C读写MPU6050 相关函数: 1.I2C_ GenerateSTART 2.I2C_ GenerateSTOP 3.I2C_ AcknowledgeConfig 4.I2C…...

【脚本】Linux一键扩大虚拟内存的大小
Linux增加虚拟内存其实很简单 就那几个命令,free、mkswap、swapon 但是方便起见我写成了脚本 使用方法 进入你的目录, nano ./install_swap.sh 下面的脚本全文复制,粘贴进去之后,按ctrlx后按y保存 然后运行以下命令 sudo bash …...

信号隔离器 0-20mA/0-10V模拟信号隔离模块变送器 一进二出高精度
信号隔离器 0-20mA/0-10V模拟信号隔离模块变送器 一进二出高精度https://item.taobao.com/item.htm?ftt&id766022047828 型号 一进二出 0-20mA 转0-20mA/0-10V MS-C12 一进二出 0-10V 转 0-20mA/0-10V MS-V12 信号隔离器 单组输出 MS-C1/V1 双组输出 MS-C12/V12 用于…...

Nat. Methods | scPerturb——单细胞扰动数据的标准化资源与统计分析方法
《Nature Methods》提出scPerturb资源平台,整合44个单细胞扰动数据集(涵盖转录组、表观组、蛋白组读值),并通过能量统计量(E-statistics)量化扰动效应,旨在解决单细胞扰动数据的互操作性差、缺乏…...

【易康eCognition实验教程】005:影像波段组合显示与单波段显示
文章目录 一、加载多波段影像二、单波段显示三、彩色显示一、加载多波段影像 二、单波段显示 如果导入的影像数据具有三个或者更多的波段,影像场景将自动以RGB(红绿蓝)模式默认显示,如上图所示。在视图设置(View Settings)窗口中使用单波段灰度显示(Single LayuerGrays…...
使用Process Explorer、Dependency Walker和PE信息查看工具快速排查dll动态库因库与库版本不一致导致的加载失败问题
目录 1、问题说明 2、使用Process Explorer查看目标dll动态库有没有动态加载起来 3、使用Dependency Walker查看xxpadll.dll库的库依赖关系,找到xxpadll.dll加载失败的原因 4、使用PE信息查看工具查看目标dll库的时间戳 5、关于xxsipstack2.dll中调用xxdatanet…...

Git的命令学习——适用小白版
浅要了解一下Git是什么: Git是目前世界上最先进的的分布式控制系统。Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。Git 并不保存这些前后变化的差异数据。实际上…...

如何安全处置旧设备?
每年,数百万台旧设备因老化、故障或被新产品取代而被丢弃,这些设备上存储的数据可能带来安全风险。 如果设备没有被正确删除数据,这些数据往往仍可被恢复。因此,安全处置旧设备至关重要。 旧设备可能包含的敏感数据 旧设备中可能…...

Java 学习记录:基础到进阶之路(一)
今天,让我们深入到 Java 项目构建、基础语法及核心编程概念的领域,一探究竟。 软件安装及环境配置请查看之前更新的博客有着详细的介绍: IDEA软件安装&环境配置&中文插件-CSDN博客 目录 1.Java 项目构建基础 1.项目中的 SRC 目录…...

3.3-3.9 蓝桥杯备赛周记
斜率关系 14届省赛 ![[Pasted image 20250205145241.png]] NE555频率解算温度 频率范围外 无效 unsigned int Freq; if(Freq<200) {humnity0;} else if(Freq>2000) {humnity0;} else{ humnity80.0/1800.0 *(float)(Freq-200)10.0;} 斜率计算题 需要类型转换 和数据需要…...

系统架构设计师—系统架构设计篇—软件架构风格
文章目录 概述经典体系结构风格数据流风格批处理管道过滤器对比 调用/返回风格主程序/子程序面向对象架构风格层次架构风格 独立构件风格进程通信事件驱动的系统 虚拟机风格解释器基于规则的系统 仓库风格(数据共享风格)数据库系统黑板系统超文本系统 闭…...
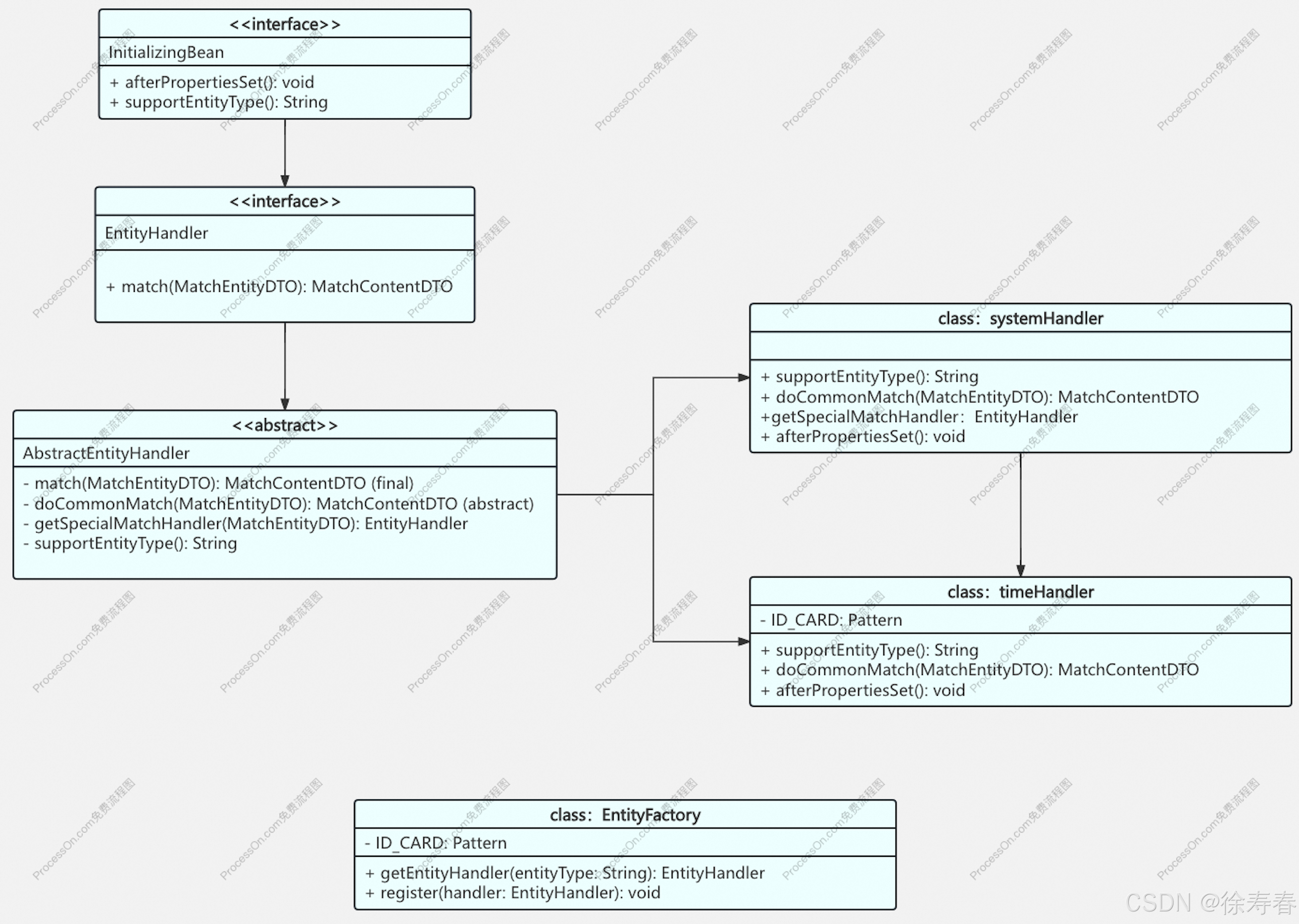
工厂模式加策略模式 -- 具体实现
这里写目录标题 定义接口定义抽象类定义主处理器分支处理器定义工厂demo 定义接口 public interface EntityHandler extends InitializingBean {MatchContentDTO match(MatchEntityDTO matchEntityDTO);String supportEntityType(); }定义抽象类 public abstract class Abstr…...
STM32---FreeRTOS消息队列
一、简介 1、队列简介: 队列:是任务到任务,任务到中断、中断到任务数据交流的一种机制(消息传递)。 FreeRTOS基于队列,实现了多种功能,其中包括队列集、互斥信号量、计数型信号量、二值信号量…...

python-leetcode-删掉一个元素以后全为 1 的最长子数组
1493. 删掉一个元素以后全为 1 的最长子数组 - 力扣(LeetCode) 可以使用滑动窗口的方式来解决这个问题。我们要找到最长的全 1 子数组,但必须删除一个元素,因此可以将问题转化为寻找最多包含一个 0 的最长子数组。 解题思路 使用双指针(滑动窗口),维护窗口内最多包含一…...

【赵渝强老师】PostgreSQL的模板数据库
在PostgreSQL中,创建数据库时实际上通过拷贝一个已有数据库进行工作的。在默认情况下,将拷贝名为template1的标准系统数据库。所以该数据库是创建新数据库的“模板”。如果为template1数据库增加对象,这些对象将被拷贝到后续创建的用户数据库…...

vue2中,在table单元格上右键,对行、列的增删操作(模拟wps里的表格交互)
HTML <template><div><divclass"editable-area"v-html"htmlContent"contenteditableblur"handleBlur"contextmenu.prevent"showContextMenu"></div><button click"transformToMd">点击转成M…...

使用DeepSeek+蓝耘快速设计网页简易版《我的世界》小游戏
前言:如今,借助先进的人工智能模型与便捷的云平台,即便是新手开发者,也能开启创意游戏的设计之旅。DeepSeek 作为前沿的人工智能模型,具备强大的功能与潜力,而蓝耘智算云平台则为其提供了稳定高效的运行环境…...

解决微信小程序中调用流式接口,处理二进制数据时 TextDecoder 不兼容的问题
问题复现 最近在开发一个 AI 问答小程序时,由于接口返回的是流式二进制数据,因此我使用了 TextDecoder 的 decode 方法将二进制数据转换为文本。在开发环境中,数据处理一直没有问题,但在真机测试及上线后,发现调用接口…...

DeepSeek与QWQ大模型对比
题目为《deepseek和qwq大模型对比》1000字 DeepSeek与QWQ大模型对比 引言 在人工智能领域,大模型的发展日新月异。DeepSeek和QWQ作为两种具有代表性的大模型,各自在技术架构、应用场景和性能表现上展现出独特优势。本文将从多个维度对这两种模型进行详细…...

Java 大视界 -- Java 大数据在智慧农业农产品质量追溯与品牌建设中的应用(124)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

c++介绍信号六
信号量是c中实现对有限资源访问控制,现成通过信号量获得对资源访问的许可。可用资源大于0,线程可以对资源进行访问,此时计数器减1。当计数器为0时,不可访问资源,线程进入等待。当资源释放时,线程结束等待&a…...

DeepSeek 本地部署全流程指南:畅享专属AI体验
DeepSeek本地部署全流程指南:畅享专属AI体验 一、部署优势剖析 在本地部署DeepSeek大模型,能带来诸多好处。一方面,数据隐私更有保障,所有运算都在本地独立完成,无需联网,有效避免了数据泄露的风险。另一…...

GStreamer —— 2.18、Windows下Qt加载GStreamer库后运行 - “播放教程 6:音频可视化“(附:完整源码)
运行效果 介绍 GStreamer 带有一组将音频转换为视频的元素。他们 可用于科学可视化或为您的音乐增添趣味 player 的本教程展示了: • 如何启用音频可视化 • 如何选择可视化元素 启用音频可视化实际上非常简单。设置相应的标志,当纯音频流为 found&#…...

IP 地址与端口号:网络通信的双重坐标解析
IP 地址与端口号:网络通信的双重坐标解析 在互联网广袤无垠的世界里,数据恰似无数灵动的信息精灵,在复杂的网络脉络中穿梭往来。而确保这些数据能够精准无误地抵达目的地的关键,便是两个至关重要的核心标识符:IP 地址…...

用Deepseek写一个 HTML 和 JavaScript 实现一个简单的飞机游戏
大家好!今天我将分享如何使用 HTML 和 JavaScript 编写一个简单的飞机游戏。这个游戏的核心功能包括:控制飞机移动、发射子弹、敌机生成、碰撞检测和得分统计。代码简洁易懂,适合初学者学习和实践。 游戏功能概述 玩家控制:使用键…...