Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录
- 前言
- 1 创建conda环境安装Selenium库
- 2 浏览器驱动下载(以Chrome和Edge为例)
- 3 基础使用(以Chrome为例演示)
- 3.1 与浏览器相关的操作
- 3.1.1 打开/关闭浏览器
- 3.1.2 访问指定域名的网页
- 3.1.3 控制浏览器的窗口大小
- 3.1.4 前进/后退/刷新页面
- 3.1.5 获取网页基本信息
- 3.1.6 打开新窗口、窗口切换
- 3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- 3.2 定位并访问、操作网页元素
- 3.2.1 通过XPath定位网页元素(CSDN首页为例)
- 3.2.2 点击元素
- 3.2.3 清空输入框、输入文本
- 3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- 3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
- 3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+...)
- 3.3 滚轮操作
- 3.4 延时等待
- 4 实战
- 4.1 实战一:自动化搜索并统计打印结果
- 4.2 实战二:知网论文信息查询
前言
- 本文介绍Windows系统下Python的Selenium库的使用,并且附带网页爬虫、web自动化操作等实战教程,图文详细,内容全面。如有错误欢迎指正,有相关问题欢迎评论私信交流。
- 什么是Selenium库:Selenium是一个用于Web应用程序测试和网页爬虫的自动化测试工具。它可以驱动浏览器执行特定的行为,模拟真实用户操作网页的场景。
- Selenium的常见用途:
- 网络爬虫:从动态网页获取信息、采集社交平台的公开信息等,并通过程序自动处理保存。
- 自动化操作:自动完成重复的表单输入、验证网站各项功能是否正常运行、验证不同浏览器的表现等
- 官方教程文档:官方教程文档
1 创建conda环境安装Selenium库
- conda创建一个新的python环境:
conda create -n selenium python=3.11
- 激活创建的python环境:
conda activate selenium
- 安装selenium:
pip install selenium
2 浏览器驱动下载(以Chrome和Edge为例)
- 驱动的作用:驱动充当Selenium代码和浏览器之间的翻译器,其提供了统一的接口来控制不同的浏览器
- Selenium程序、驱动、浏览器之间的关系
Selenium程序 → 浏览器驱动 → 浏览器↑ ↑ ↑
发送命令 → 转换命令 → 执行操作↓ ↓ ↓
接收结果 ← 转换结果 ← 返回结果
- 下载Chrome浏览器驱动:
- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):


我这里版本是131.0.6778.265(正式版本) - 进入下载页面,选择与Chrome版本最接近的驱动版本复制链接进行下载:
选择与Chrome版本最接近的驱动版本,复制操作系统对应的驱动的链接

在浏览器地址栏输入上述链接回车,浏览器会自动下载驱动

下载完成会得到这样一个压缩文件,这里面就是驱动:

解压压缩包得到这样三个文件,记住驱动文件夹的位置:

- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):
- 下载Edge浏览器驱动
-
查看Edge版本信息(打开Edge浏览器 → 点击右上角三个点 → 设置 → 关于Microsoft Edge):


我这儿版本是131.0.2903.146 -
进入下载页面,选择与Edge版本最接近的版本点击对应的下载按钮即可:

得到如下压缩包:

解压后得到如下文件,记住驱动的位置:

-
3 基础使用(以Chrome为例演示)
3.1 与浏览器相关的操作
3.1.1 打开/关闭浏览器
- webdriver.Chrome():初始化并打开浏览器
- quit():关闭浏览器
# 导入必要的库
from selenium import webdriver # Selenium的核心包
from selenium.webdriver.chrome.service import Service # Chrome驱动服务类# 设置ChromeDriver路径
# driver_path指定了ChromeDriver可执行文件的本地路径
# Service类用于创建ChromeDriver服务实例
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化Chrome浏览器
# webdriver.Chrome()会启动一个新的Chrome浏览器实例
# service参数告诉Selenium使用哪个ChromeDriver服务
browser = webdriver.Chrome(service=service)# 关闭浏览器
# quit()方法会完全关闭浏览器及其所有相关进程
browser.quit()
3.1.2 访问指定域名的网页
- get():打开网页
# 导入和初始化部分与3.1相同
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Servicedriver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)
browser = webdriver.Chrome(service=service)# 使用get()方法访问指定URL
# get()方法会等待页面加载完成后才继续执行后续代码
browser.get("https://www.baidu.com")# time.sleep()添加延时
# 程序会在此处暂停5秒,方便观察页面加载情况
# 注意:在实际项目中应该使用显式等待或隐式等待替代sleep
time.sleep(5)# 关闭浏览器
browser.quit()
3.1.3 控制浏览器的窗口大小
- set_window_size():设置窗口的固定长宽
- maximize_window():最大化窗口
- minimize_window():最小化窗口
- fullscreen_window():全屏显示窗口
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 打开百度
browser.get("https://www.baidu.com")# 方法1:设置固定大小
browser.set_window_size(800, 600) # 设置为800x600像素
time.sleep(2) # 等待2秒观察效果# 方法2:最大化窗口
browser.maximize_window()
time.sleep(2)# 方法3:最小化窗口
browser.minimize_window()
time.sleep(2)# 方法4:全屏显示
browser.fullscreen_window()
time.sleep(2)# 获取当前窗口大小
window_size = browser.get_window_size()
print(f"当前窗口大小:宽度={window_size['width']}px,高度={window_size['height']}px")# 关闭浏览器
browser.quit()
3.1.4 前进/后退/刷新页面
- back():后退
- forward():前进
- refresh():刷新
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问第一个页面:百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 访问第二个页面:必应
browser.get("https://www.bing.com")
time.sleep(2)# 后退到百度
browser.back()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否回到百度# 前进到必应
browser.forward()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否前进到必应# 刷新当前页面
browser.refresh()
time.sleep(2)# 关闭浏览器
browser.quit()
3.1.5 获取网页基本信息
- title():获取网页标题
- current_url():获取当前网址
- name():获取浏览器名称
- page_source():获取页面源码
- window_handles():获取所有窗口句柄
- current_window_handle():获取当前窗口句柄
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 1. 获取网页标题
title = browser.title
print("网页标题:", title)# 2. 获取当前网址
current_url = browser.current_url
print("当前网址:", current_url)# 3. 获取浏览器名称
browser_name = browser.name
print("浏览器名称:", browser_name)# 4. 获取页面源码(前50个字符)
page_source = browser.page_source
print("页面源码(前50个字符):", page_source[:50])# 5. 获取当前窗口句柄
current_handle = browser.current_window_handle
print("当前窗口句柄:", current_handle)# 6. 获取所有窗口句柄
all_handles = browser.window_handles
print("所有窗口句柄:", all_handles)# 7. 获取浏览器的能力(capabilities)
capabilities = browser.capabilities
print("浏览器版本:", capabilities.get('browserVersion', 'Unknown'))
print("浏览器名称:", capabilities.get('browserName', 'Unknown'))
print("平台名称:", capabilities.get('platformName', 'Unknown'))# 关闭浏览器
browser.quit()
3.1.6 打开新窗口、窗口切换
在Selenium中,我们可以通过以下方法实现窗口切换:
- window_handles:获取所有窗口句柄
- current_window_handle:获取当前窗口句柄
- switch_to.window():切换到指定窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import time# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.baidu.com")try:# 1. 获取初始窗口句柄main_window = browser.current_window_handleprint("主窗口句柄:", main_window)# 2. 打开新窗口(点击链接在新窗口打开)browser.execute_script("window.open('https://www.bing.com', '_blank');")time.sleep(2)# 3. 获取所有窗口句柄all_handles = browser.window_handlesprint("所有窗口句柄:", all_handles)# 4. 切换到新窗口(最后打开的窗口)browser.switch_to.window(all_handles[-1])print("当前页面标题:", browser.title) # 应显示必应的标题time.sleep(2)# 5. 切回主窗口browser.switch_to.window(main_window)print("切回主窗口,当前页面标题:", browser.title) # 应显示百度的标题time.sleep(2)# 6. 遍历所有窗口示例print("\n遍历所有窗口:")for handle in all_handles:browser.switch_to.window(handle)print(f"窗口句柄: {handle}")print(f"页面标题: {browser.title}")print(f"当前URL: {browser.current_url}")print("---")time.sleep(1)except Exception as e:print(f"发生错误: {e}")finally:browser.quit()

3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- add_argument():添加一些其他设置选项。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options # 导入 Options# 配置无头浏览器、禁用GPU加速、禁用沙盒、禁用共享内存
chrome_options = Options()
chrome_options.add_argument('--headless') # 启用无头模式
chrome_options.add_argument('--disable-gpu') # 禁用GPU加速
chrome_options.add_argument('--no-sandbox') # 禁用沙盒
chrome_options.add_argument('--disable-dev-shm-usage') # 禁用共享内存# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器时传入配置
browser = webdriver.Chrome(service=service, options=chrome_options)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
3.2 定位并访问、操作网页元素
- 网页元素是构成网页的基本组成部分,是HTML文档中的各种标签所创建的对象。在自动化测试和网页操作中,我们需要定位元素以便进行交互操作,获取其相关信息。
- Selenium定位网页元素的方法:
- ID定位:find_element(By.ID, “element-id”)
- 名称定位:find_element(By.NAME, “element-name”)
- 类名定位:find_element(By.CLASS_NAME, “class-name”)
- 标签名定位:find_element(By.TAG_NAME, “tag-name”)
- XPath定位:find_element(By.XPATH, “//xpath-expression”)
- CSS选择器定位:find_element(By.CSS_SELECTOR, “css-selector”)
- 链接文本定位:find_element(By.LINK_TEXT, “link-text”)
- 部分链接文本定位:find_element(By.PARTIAL_LINK_TEXT, “partial-text”)
3.2.1 通过XPath定位网页元素(CSDN首页为例)
XPath是一种在XML和HTML文档中查找元素的强大语言,其结合浏览器不用去看网页源码就能很方便的定位网页元素。
-
首先通过浏览器打开需要定位的元素所在的网页:

-
按F12进入开发者模式,点击图中开发者窗口左上角的图标,点击元素,这时鼠标滑过网页的每一个元素下面的源码都会快速定位到该元素的对应源码


-
这时我们把鼠标移动到需要定位的元素上面,点击鼠标左键,然后鼠标移动到该元素的源码部分,鼠标右键单击打开菜单,在菜单中选择复制-复制XPath(或者复制完整 XPath)即可得到该元素的XPath


-
有了元素的XPath,便可以通过selenium的find_element方法获取这个元素,随后对其进行交互操作、获取相关信息等。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Servicedef locate_search_button():# 设置 ChromeDriver 的路径driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"service = Service(driver_path)# 初始化 Chrome 浏览器并打开browser = webdriver.Chrome(service=service)browser.get("https://www.csdn.net/")# 通过xpath定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')# 打印元素文本print("找到搜索按钮,文本内容:", element.text)# 关闭浏览器browser.quit()if __name__ == "__main__":locate_search_button()

3.2.2 点击元素
- click():点击元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位并点击搜索按钮search_button = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')search_button.click()print("成功点击搜索按钮")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()

3.2.3 清空输入框、输入文本
- clear():清空输入框
- send_keys():输入文本
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 清空输入框search_input.clear()# 输入文本search_input.send_keys("Python Selenium")print("成功输入文本")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()


3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- text():获取元素文本
- get_attribute():获取元素某些属性
- tag_name():获取元素标签名
- size():获取元素大小
- location():获取元素位置
- is_displayed():判断元素是否显示
- is_enabled():判断元素是否启用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 获取元素的各种属性print("元素文本:", element.text)print("class属性:", element.get_attribute("class"))print("标签名:", element.tag_name)print("元素大小:", element.size)print("元素位置:", element.location)print("是否显示:", element.is_displayed())print("是否启用:", element.is_enabled())except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
使用 ActionChains 类可以对元素执行以下鼠标操作:
- move_to_element():鼠标悬停
- click():鼠标左键点击
- context_click():鼠标右键点击
- double_click():鼠标双击
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 创建 ActionChains 对象actions = ActionChains(browser)# 鼠标悬停actions.move_to_element(element).perform()print("执行鼠标悬停")time.sleep(1)# 鼠标点击actions.click(element).perform()print("执行鼠标点击")time.sleep(1)# 鼠标右键actions.context_click(element).perform()print("执行鼠标右键")time.sleep(1)# 双击actions.double_click(element).perform()print("执行鼠标双击")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+…)
使用 Keys 类可以执行以下键盘操作:
- send_keys():输入文本
- Keys.BACK_SPACE:退格键
- Keys.SPACE:空格键
- Keys.TAB:制表键
- Keys.ENTER/Keys.RETURN:回车键
- Keys.CONTROL + ‘a’:全选(Ctrl+A)
- Keys.CONTROL + ‘c’:复制(Ctrl+C)
- Keys.CONTROL + ‘v’:粘贴(Ctrl+V)
- Keys.CONTROL + ‘x’:剪切(Ctrl+X)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 1. 基本输入search_input.send_keys("Python")print("输入文本:Python")time.sleep(1)# 2. 空格search_input.send_keys(Keys.SPACE)search_input.send_keys("Selenium")print("输入空格和文本:Python Selenium")time.sleep(1)# 3. 全选文本 (Ctrl+A)actions = ActionChains(browser)actions.key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL).perform()print("全选文本")time.sleep(1)# 4. 复制文本 (Ctrl+C)actions.key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()print("复制文本")time.sleep(1)# 5. 删除文本(退格键)search_input.send_keys(Keys.BACK_SPACE)print("删除文本")time.sleep(1)# 6. 粘贴文本 (Ctrl+V)actions.key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()print("粘贴文本")time.sleep(1)# 7. 制表键search_input.send_keys(Keys.TAB)print("按下Tab键")time.sleep(1)# 8. 回车搜索search_input.send_keys(Keys.RETURN)print("按下回车键执行搜索")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.3 滚轮操作
- 最常用且最可靠的方法是使用 JavaScript 来控制滚动
- execute_script():执行JavaScript脚本
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 1. 滚动到页面底部browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print("滚动到页面底部")time.sleep(1)# 2. 滚动到页面顶部browser.execute_script("window.scrollTo(0, 0);")print("滚动到页面顶部")time.sleep(1)# 3. 向下滚动500像素browser.execute_script("window.scrollBy(0, 500);")print("向下滚动500像素")time.sleep(1)# 4. 使用 PageDown 键滚动actions = ActionChains(browser)actions.send_keys(Keys.PAGE_DOWN).perform()print("使用 PageDown 键滚动")time.sleep(1)# 5. 滚动到特定元素try:element = browser.find_element(By.CLASS_NAME, "toolbar-container")browser.execute_script("arguments[0].scrollIntoView();", element)print("滚动到特定元素位置")time.sleep(1)except Exception as e:print(f"未找到目标元素: {e}")# 6. 平滑滚动到底部browser.execute_script("""window.scrollTo({top: document.body.scrollHeight,behavior: 'smooth'});""")print("平滑滚动到底部")time.sleep(2)# 7. 模拟无限滚动加载last_height = browser.execute_script("return document.body.scrollHeight")scroll_attempts = 3 # 限制滚动次数,避免无限循环for i in range(scroll_attempts):browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print(f"执行第 {i+1} 次滚动加载")time.sleep(2)new_height = browser.execute_script("return document.body.scrollHeight")if new_height == last_height:print("已到达页面底部")breaklast_height = new_heightexcept Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

3.4 延时等待
- implicitly_wait:设置隐式等待时间。隐式等待是一个全局设置,设置后对整个浏览器会话中的所有操作都生效;它告诉WebDriver在查找元素时,如果元素不存在,应该等待多长时间;在设定的时间内,WebDriver会定期重试查找元素的操作。
- WebDriverWait:创建显式等待对象。它允许我们设置最长等待时间和检查的时间间隔;与隐式等待不同,显式等待可以针对特定元素设置具体的等待条件;它提供了更精确的等待控制。
- until:等待直到条件满足。它接受一个期望条件(EC)作为参数,在超时之前反复检查该条件是否满足;如果条件满足则返回结果,如果超时则抛出TimeoutException异常。
- until_not:等待直到条件不满足。与until相反,它等待一个条件变为false;常用于等待某个元素消失或某个状态结束的场景。
- expected_conditions:预定义的期望条件集合。包含多种常用的等待条件,如:
- presence_of_element_located:等待元素在DOM中出现
- visibility_of_element_located:等待元素可见
- element_to_be_clickable:等待元素可点击
- all_of:等待多个条件同时满足
- poll_frequency:设置轮询频率。定义了在显式等待过程中检查条件的时间间隔;默认是0.5秒检查一次;可以根据实际需求调整以优化性能。
- ignored_exceptions:设置要忽略的异常。在等待过程中可以指定某些异常被忽略而继续等待;常用于处理特定的临时性错误,如StaleElementReferenceException。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 1. 设置隐式等待时间(全局设置)browser.implicitly_wait(10)print("设置隐式等待时间:10秒")# 打开测试网页browser.get("https://www.csdn.net/")# 2. 显式等待 - 等待特定元素可见try:search_input = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("成功找到搜索框元素")except TimeoutException:print("等待搜索框超时")# 3. 显式等待 - 等待元素可点击try:login_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.CLASS_NAME, "login-btn")))print("登录按钮可以点击")except TimeoutException:print("等待登录按钮可点击超时")# 4. 自定义等待条件def custom_condition(driver):element = driver.find_element(By.CLASS_NAME, "toolbar-container")return element.is_displayed() and element.get_attribute("style") != "display: none;"try:WebDriverWait(browser, 8).until(custom_condition)print("自定义条件满足")except TimeoutException:print("等待自定义条件超时")# 5. 多条件组合等待try:# 等待多个条件都满足wait = WebDriverWait(browser, 10)condition = wait.until(EC.all_of(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")),EC.visibility_of_element_located((By.ID, "toolbar-search-input"))))print("多个条件都满足")except TimeoutException:print("等待多个条件超时")# 6. 使用until_not等待条件不成立try:# 等待加载动画消失loading_spinner = WebDriverWait(browser, 5).until_not(EC.presence_of_element_located((By.CLASS_NAME, "loading-spinner")))print("加载动画已消失")except TimeoutException:print("等待加载动画消失超时")# 7. 带有轮询间隔的等待try:# 设置轮询间隔为0.5秒wait = WebDriverWait(browser, timeout=10, poll_frequency=0.5)element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")))print("使用自定义轮询间隔成功找到元素")except TimeoutException:print("使用自定义轮询间隔等待超时")# 8. 忽略特定异常的等待try:# 忽略 StaleElementReferenceException 异常wait = WebDriverWait(browser, 10, ignored_exceptions=[NoSuchElementException])element = wait.until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("忽略特定异常后成功找到元素")except TimeoutException:print("忽略特定异常后等待超时")except Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

4 实战
4.1 实战一:自动化搜索并统计打印结果
- 本代码演示打开bing搜索界面搜索关键词“CSDN”,获取搜索结果并打印每个结果的基本信息。
- 代码思路:
- 使用
get()方法打开bing搜索界面 - 使用
find_element()方法定位搜索输入框元素 - 使用
send_keys()方法输入关键字和回车按键执行搜索 - 使用
find_elements()方法通过"b_algo"类名进行筛选,查看搜索界面源码可以知道搜索结果元素都是"b_algo"类。 - 综合使用
find_element()、text()、get_attribute()方法获取每个搜索结果的标题、链接、描述等信息,所使用的属性值、类名也是通过查看源码获得的,通过前文介绍的元素定位方法可以很容易的知道。
- 使用
- 注意:由于不同搜索结果之间存在一定的差异,所以不一定每一个搜索结果都能获得完整的信息,这个需要自己结合源码对示例代码进行修改。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")# 查找搜索框并输入关键词search_input = browser.find_element(By.ID, "sb_form_q")search_input.send_keys("CSDN")search_input.send_keys(Keys.RETURN)print("已输入搜索关键词:CSDN")# 稍等待搜索结果加载time.sleep(2)# 获取搜索结果search_results = browser.find_elements(By.CLASS_NAME, "b_algo")print(f"\n找到 {len(search_results)} 条搜索结果:\n")# 打印搜索结果for index, result in enumerate(search_results, 1):try:# 获取标题和链接title_element = result.find_element(By.CSS_SELECTOR, "h2 a")title = title_element.textlink = title_element.get_attribute("href")# 获取描述 (直接获取 b_caption 的文本内容)description = result.find_element(By.CLASS_NAME, "b_caption").text# 打印结果print(f"结果 {index}:")print(f"标题: {title}")print(f"链接: {link}")print(f"描述: {description}")print("-" * 80)except Exception as e:print(f"处理第 {index} 条结果时出错: {str(e)}")continueexcept Exception as e:print(f"发生错误: {e}")finally:# 等待一段时间后关闭浏览器time.sleep(2)browser.quit()print("浏览器已关闭")



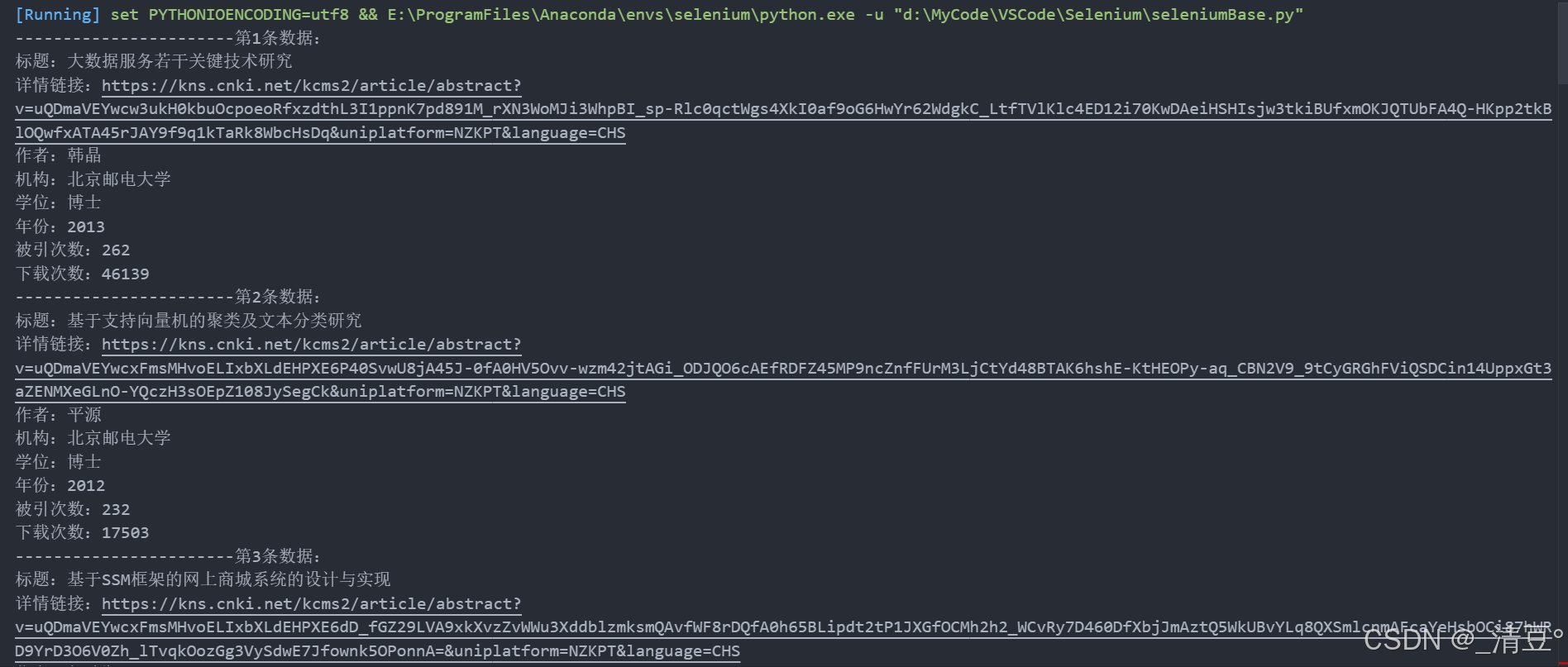
4.2 实战二:知网论文信息查询
- 本代码演示打开知网高级检索界面,通过设置学科专业(计算机)和学校单位(北京邮电大学)进行论文检索,并按下载量排序获取前20条论文的详细信息。
- 代码思路:
- 使用get()方法打开知网高级检索界面
- 使用maximize_window()方法将窗口最大化,确保所有元素可见
- 通过XPATH定位并点击"学科专业导航",清除已选学科,展开工学类别并选中计算机专业
- 使用send_keys()方法在学校单位输入框中填入"北京邮电大学"
- 点击检索按钮开始搜索
- 点击下载量排序选项,对结果进行排序
- 使用execute_script()方法控制页面向下滚动700像素
- 使用循环遍历前20条搜索结果,通过XPATH定位每条论文的各项信息
- 注意事项:
- 代码中使用了多处time.sleep()来确保页面加载完成,实际使用时可根据网络情况调整等待时间
- XPATH路径的获取是通过浏览器开发者工具复制得到,需要注意网页结构变化可能导致定位失效
- 使用try-except结构进行异常处理,确保程序运行的稳定性
- 最后使用quit()方法关闭浏览器,释放资源
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)browser.get("https://epub.cnki.net/kns/advsearch?classid=RDS33BAY")time.sleep(1)# 窗口最大化browser.maximize_window()time.sleep(1)# 点击学科专业导航browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[1]/a[2]').click()time.sleep(1)# 点击清除取消所有选中的学科browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[2]/a[2]').click()time.sleep(1)# 点击展开工学browser.find_element(By.XPATH, '//*[@id="08"]').click()time.sleep(1)# 点击选中计算机browser.find_element(By.XPATH, '//*[@id="9UG2UB8R"]/li[8]/ul/li[12]/div/i[2]').click()time.sleep(1)# 往学校单位输入框填写内容browser.find_element(By.XPATH, '//*[@id="inputAndSelect"]/input').send_keys("北京邮电大学")time.sleep(1)# 点击检索按钮browser.find_element(By.XPATH, "/html/body/div[2]/div[3]/div/div[3]/div[1]/div[2]/div[1]/div[9]").click()time.sleep(1)# 点击按照下载量排序browser.find_element(By.XPATH, '//*[@id="orderList"]/li[6]').click()time.sleep(1)# 向下翻动700pxbrowser.execute_script("window.scrollBy(0, 700);")time.sleep(1)for i in range(20):title = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).textdetail_link = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).get_attribute("href")author = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[3]/a',).textinstitution = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[4]/a/font',).textdegree = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[5]',).textyear = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[6]',).textcited_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[7]',).textdownload_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[8]',).textprint(f"-----------------------第{i+1}条数据:")print(f"标题:{title}")print(f"详情链接:{detail_link}")print(f"作者:{author}")print(f"机构:{institution}")print(f"学位:{degree}")print(f"年份:{year}")print(f"被引次数:{cited_count}")print(f"下载次数:{download_count}")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
相关文章:
Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录 前言1 创建conda环境安装Selenium库2 浏览器驱动下载(以Chrome和Edge为例)3 基础使用(以Chrome为例演示)3.1 与浏览器相关的操作3.1.1 打开/关闭浏览器3.1.2 访问指定域名的网页3.1.3 控制浏览器的窗口大小3.1.4 前进/后…...

聊天室Python脚本——ChatGPT,好用
下面提供两个 Python 脚本,一个作为服务器端(chat_server.py),一个作为客户端(chat_client.py)。你可以在一台电脑上运行服务器脚本,然后在不同电脑上运行客户端脚本(连接时指定服务…...

AI4CODE】3 Trae 锤一个贪吃蛇的小游戏
【AI4CODE】目录 【AI4CODE】1 Trae CN 锥安装配置与迁移 【AI4CODE】2 Trae 锤一个 To-Do-List 这次还是采用 HTML/CSS/JAVASCRIPT 技术栈 Trae 锤一个贪吃蛇的小游戏。 1 环境准备 创建一个 Snake 的子文件夹,清除以前的会话记录。 2 开始构建 2.1 输入会…...
)
【语料数据爬虫】Python爬虫|批量采集会议纪要数据(1)
前言 本文是该专栏的第2篇,后面会持续分享Python爬虫采集各种语料数据的的干货知识,值得关注。 在本文中,笔者将主要来介绍基于Python,来实现批量采集“会议纪要”数据。同时,本文也是采集“会议纪要”数据系列的第1篇。 采集相关数据的具体细节部分以及详细思路逻辑,笔…...

Linux 进程的一生(一):进程与线程的创建机制解析
在 Linux 操作系统中,每个任务都以「进程」的形式存在。但 Linux 下的「线程」又是什么?Linux 并没有单独定义一种全新数据结构来表示线程,而是将线程视为一种特殊的进程——一种共享资源的轻量级进程。然而,在具体实现和运行机制…...

【面试题集合】
目录 强缓存VS协商缓存**一、强缓存(本地缓存)**1. **定义**2. **核心 HTTP 头**3. **缓存生效流程**4. **应用场景** **二、协商缓存(条件请求)**1. **定义**2. **核心 HTTP 头**3. **缓存生效流程**4. **应用场景** **三、强缓存…...

【Academy】SSRF ------ Server-side request forgery
SSRF ------ Server-side request forgery 1. 什么是 SSRF?2. SSRF 攻击的影响是什么?3. 常见的 SSRF 攻击3.1 针对服务器的 SSRF 攻击3.2 针对其他后端系统的 SSRF 攻击 4. 规避常见的 SSRF 防御4.1 具有基于黑名单的输入过滤器的 SSRF4.2 具有基于白名…...

Git 的详细介绍及用法
一、Git 的优点 分布式版本控制 每个开发者都拥有完整的仓库副本,无需依赖中央服务器(如 SVN)。支持离线操作(提交、查看历史、创建分支等)。 高效的分支管理 创建和切换分支速度快(几乎是瞬间完成&#x…...

Ubuntu22.04安装数据
数据库安装步骤: sudo apt-get update sudo apt install mysql-server mysql-client sudo systemctl start mysql sudo systemctl status mysql (1)在命令行登录 MySQL 数据库,并使用 mysql 数据库 (必须使用这个…...

2025 ubuntu24系统宿主机上在线安装mysql数据库完整演示
说明:这是ubuntu24系统和安装后mysql的版本 rootmaster:/home/ubuntu# cat /etc/os-release PRETTY_NAME"Ubuntu 24.04.2 LTS" NAME"Ubuntu" VERSION_ID"24.04" VERSION"24.04.2 LTS (Noble Numbat)" VERSION_CODENAMEnob…...

STM32之I2C硬件外设
注意:硬件I2C的引脚是固定的 SDA和SCL都是复用到外部引脚。 SDA发送时数据寄存器的数据在数据移位寄存器空闲的状态下进入数据移位寄存器,此时会置状态寄存器的TXE为1,表示发送寄存器为空,然后往数据控制寄存器中一位一位的移送数…...

windows版本的时序数据库TDengine安装以及可视化工具
了解时序数据库TDengine,可以点击官方文档进行详细查阅 安装步骤 首先找到自己需要下载的版本,这边我暂时只写windows版本的安装 首先我们需要点开官网,找到发布历史,目前TDengine的windows版本只更新到3.0.7.1,我们…...

【AI】单台10卡4090 openEuler服务器离线部署kasm workspace 提供简单的GPU云服务 虚拟化桌面
下载网址 Downloads | Kasm Workspaces 文件连接 wget https://kasm-static-content.s3.amazonaws.com/kasm_release_plugin_images_amd64_1.16.1.98d6fa.tar.gz wget https://kasm-static-content.s3.amazonaws.com/kasm_release_1.16.1.98d6fa.tar.gz wget https://kasm-st…...

NetAssist 5.0.14网络助手基础使用及自动应答使用方案
以下是NetAssist v5.0.14自动应答功能的详细使用步骤: 一、基础准备: 工具下载网址页面:https://www.cmsoft.cn/resource/102.html 下载安装好后,根据需要可以创建多个server,双击程序图标运行即可,下面…...

《深度解析DeepSeek-M8:量子经典融合,重塑计算能效格局》
在科技飞速发展的今天,量子计算与经典算法的融合成为了前沿领域的焦点。DeepSeek-M8的“量子神经网络混合架构”,宛如一把钥匙,开启了经典算法与量子计算协同推理的全新大门,为诸多复杂问题的解决提供了前所未有的思路。 量子计算…...

力扣1251年
正确写法: select p.product_id, ifnull(round(sum(units*price)/sum(units),2),0) average_price from prices p left join unitssold u on u.product_idp.product_id and u.purchase_date between start_date and end_date group by p.product_id; 错误写法&a…...

【写作模板】JosieBook的写作模板
文章目录 ⭐前言⭐一、设计模式怎样解决设计问题?🌟1、寻找合适的对象✨(1)✨(2)✨(3) 🌟2、决定对象的粒度🌟3、指定对象接口🌟4、描述对象的实现🌟5、运用复用机制🌟6、关联运行时和编译时的结…...

47.HarmonyOS NEXT 登录模块开发教程(二):一键登录页面实现
温馨提示:本篇博客的详细代码已发布到 git : https://gitcode.com/nutpi/HarmonyosNext 可以下载运行哦! HarmonyOS NEXT 登录模块开发教程(二):一键登录页面实现 文章目录 HarmonyOS NEXT 登录模块开发教程࿰…...

5.1 程序调试
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 本节中为了演示方便,使用的代码如下: 【例 5.1】【项目:code5-001】程序的调试。 static void Ma…...

Cursor初体验:excel转成CANoe的vsysvar文件
今天公司大佬先锋们给培训了cursor的使用,还给注册了官方账号!跃跃欲试,但是测试任务好重,结合第三方工具开发也是没有头绪。 但巧的是,刚好下午有同事有个需求,想要把一个几千行的excel转成canoe的系统变…...

vue3-element-admin 前后端本地启动联调
一、后端环境准备 1.1、下载地址 gitee 下载地址 1.2、环境要求 JDK 17 1.3、项目启动 克隆项目 git clone https://gitee.com/youlaiorg/youlai-boot.git数据库初始化 执行 youlai_boot.sql 脚本完成数据库创建、表结构和基础数据的初始化。 修改配置 application-dev.y…...

emacs使用mongosh的方便工具发布
github项目地址: GitHub - csfreebird/emacs_mongosh: 在emacs中使用mongosh快速登录mongodb数据库 * 用途 在emacs中使用mongosh快速登录mongodb数据库, 操作方法: M-x mongosh, 输入数据库名称,然后就可以自动登录,前提是你已经配置好了…...

《MySQL数据库从零搭建到高效管理|库的基本操作》
目录 一、数据库的操作 1.1 展示数据库 1.2 创建数据库 1.3 使用数据库 1.4 查看当前数据库 1.5 删除数据库 1.6 小结 二、常用数据类型 2.1 数值类型 2.2 字符串类型 2.3 日期类型 一、数据库的操作 打开MySQL命令行客户端,安装完MySQL后会有两个客户端…...

Linux Shell 脚本编程极简入门指南
一、学习前提准备 ✅ 环境要求: Linux系统(Ubuntu/CentOS等)或 WSL (Windows用户) 任意文本编辑器(推荐VSCode/Vim) 基础命令行操作能力 🔍 验证环境: # 查看系统默认Shell echo $SHELL #…...

多视图几何--相机标定--从0-1理解张正友标定法
1基本原理 1.1 单应性矩阵(Homography)的建立 相机模型:世界坐标系下棋盘格平面(Z0)到图像平面的投影关系为: s [ u v 1 ] K [ r 1 r 2 t ] [ X Y 1 ] s \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} K…...

Manus 一码难求,MetaGPT、OpenManus、Camel AI 会是替代方案吗?
Manus 一码难求,MetaGPT、OpenManus、Camel AI 会是替代方案吗? 一、Manus 的现象与问题 Manus 作为一款号称“全球首个通用 AI 智能体”的产品,凭借其强大的功能和新颖的营销策略迅速走红。然而,其封闭的邀请码机制和高昂的使用…...

mac使用Homebrew安装miniconda(mac搭建python环境),并在IDEA中集成miniconda环境
一、安装Homebrew mac安装brew 二、使用Homebrew安装miniconda brew search condabrew install miniconda安装完成后的截图: # 查看是否安装成功 brew list环境变量(无需手动配置) 先执行命令看能不能正常返回,如果不能正常…...

Linux基础开发工具—vim
目录 1、vim的概念 2、vim的常见模式 2.1 演示切换vim模式 3、vim命令模式常用操作 3.1 移动光标 3.2 删除文字 3.3 复制 3.4 替换 4、vim底行模式常用命令 4.1 查找字符 5、vim的配置文件 1、vim的概念 Vim全称是Vi IMproved,即说明它是Vi编辑器的增强…...

【C++】数据结构 队列的实现
本篇博客给大家带来的是用C语言来实现数据结构的队列的实现! 🐟🐟文章专栏:数据结构 🚀🚀若有问题评论区下讨论,我会及时回答 ❤❤欢迎大家点赞、收藏、分享! 今日思想:你…...

macOS 终端优化
macOS 安装、优化、还原、升级 Oh My Zsh 完全指南 🚀 Oh My Zsh 是 macOS 终端增强的利器,它能提供强大的自动补全、主题定制和插件支持,让你的终端更高效、更炫酷。本文将全面介绍 如何安装、优化、还原、重新安装和升级 Oh My Zsh&#x…...