神经网络的数据集处理
离不开这个库torch.utils.data,这个库有两个类一个Dataset和Dataloader
Dataset(对单个样本处理)
Dataset 是一个非常重要的概念,它主要用于管理和组织数据,方便后续的数据加载和处理。以下以 PyTorch 为例,详细介绍 Dataset 相关内容。
概述
在 PyTorch 里,torch.utils.data.Dataset 是一个抽象类,所有自定义的数据集都应该继承这个类,并且至少要实现 __len__ 和 __getitem__ 这两个方法。
__len__方法:返回数据集的样本数量。__getitem__方法:根据给定的索引返回对应的样本和标签。(自定义)
内置的Dataset
这是用于加载手写数字 MNIST 数据集的类,常见参数如下:
root:指定数据集存储的根目录。如果数据不存在,下载的数据将保存到该目录下。train:一个布尔值,True表示加载训练集,False表示加载测试集。transform:用于对图像数据进行预处理的转换操作,例如将图像转换为张量、归一化等。target_transform:用于对标签数据进行预处理的转换操作。download:一个布尔值,True表示如果数据集不存在则自动下载,False表示不进行下载
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 加载 MNIST 训练集
train_dataset = datasets.MNIST(root='./data', train=True,download=True, transform=transform)自定义数据集(重点)
讲一下什么标注文件 就拿视频而言 我所见的到 一般都是两者 要么就是 你自己分好帧的文件路径 帧数 以及标签(这个标签一般是数字),要么就是视频路径(未分帧数)加上标签
今天拿简单的举例(引用X-CLIP源码)
1.父类初始化
class BaseDataset(Dataset, metaclass=ABCMeta):def __init__(self,ann_file,#标注文件pipeline,#管道操作repeat = 1,#数据重复次数data_prefix=None,#数据文件的前缀路径,用于指定视频数据存储的目录test_mode=False,#一个布尔值,指示是否处于测试模式,默认为 Falsemulti_class=False,#一个布尔值,指示是否为多分类任务,默认为 Falsenum_classes=None,#分类的类别数量,在多分类任务中需要指定,默认为 Nonestart_index=1,#视频帧的起始索引,默认为 1modality='RGB',#视频数据的模态,如 RGB 等,默认为 'RGB'sample_by_class=False,#个布尔值,指示是否按类别采样数据,默认为 Falsepower=0,#用于调整按类别采样的概率的幂次,默认为 0dynamic_length=False,):#个布尔值,指示是否使用动态长度的数据,默认为 False。super().__init__()#处理一下这里判断 data_prefix 中是否包含 .tar 字符串,如果包含则将 self.use_tar_format 设置为 True,表示使用 .tar 格式存储数据。#同时,将 data_prefix 中的 .tar 字符串替换为空,方便后续处理self.use_tar_format = True if ".tar" in data_prefix else Falsedata_prefix = data_prefix.replace(".tar", "")self.ann_file = ann_fileself.repeat = repeatself.data_prefix = osp.realpath(data_prefix) if data_prefix is not None and osp.isdir(data_prefix) else data_prefixself.test_mode = test_modeself.multi_class = multi_classself.num_classes = num_classesself.start_index = start_indexself.modality = modalityself.sample_by_class = sample_by_classself.power = powerself.dynamic_length = dynamic_lengthassert not (self.multi_class and self.sample_by_class)self.pipeline = Compose(pipeline)self.video_infos = self.load_annotations()if self.sample_by_class:self.video_infos_by_class = self.parse_by_class()class_prob = []for _, samples in self.video_infos_by_class.items():class_prob.append(len(samples) / len(self.video_infos))class_prob = [x**self.power for x in class_prob]summ = sum(class_prob)class_prob = [x / summ for x in class_prob]self.class_prob = dict(zip(self.video_infos_by_class, class_prob))1.在
BaseDataset类中,repeat参数的主要作用是控制数据的重复使用次数,通常用于数据增强或者调整数据集的有效规模2.
sample_by_class:在一些数据集里,不同类别的样本数量可能存在较大差异,即存在类别不平衡问题。按类别采样可以确保每个类别在训练过程中都有足够的样本被使用,避免模型过度偏向样本数量多的类别,有助于提高模型对各个类别的分类性能。3
power:作用:当sample_by_class为True时,不同类别的采样概率最初是根据该类别样本数量占总样本数量的比例来计算的。使用power参数可以对这些概率进行调整。如果power大于 1,会增大样本数量少的类别的采样概率,使得这些类别在采样中更有可能被选中;如果power小于 1 且大于 0,会减小样本数量少的类别的采样概率;当power等于 0 时,所有类别的采样概率相等。4
dynamic_length:在一些数据集中,数据样本的长度可能是不同的。例如,在处理文本数据时,不同句子的长度可能不一样;在处理视频数据时,不同视频的帧数也可能不同。使用动态长度的数据可以更灵活地处理这些情况,避免对数据进行不必要的截断或填充操作,从而保留更多的数据信息。但同时,动态长度的数据处理起来相对复杂,需要特殊的处理机制。
2.成员函数
1.处理标注文件 返回一个列表
@abstractmethoddef load_annotations(self):"""Load the annotation according to ann_file into video_infos."""# json annotations already looks like video_infos, so for each dataset,# this func should be the samevideo_infos = []with open(self.ann_file, 'r') as fin:for line in fin:line_split = line.strip().split()if self.multi_class:assert self.num_classes is not Nonefilename, label = line_split[0], line_split[1:]label = list(map(int, label))else:filename, label = line_splitlabel = int(label)if self.data_prefix is not None:filename = osp.join(self.data_prefix, filename)video_infos.append(dict(filename=filename, label=label, tar=self.use_tar_format))return video_infos [{'filename': 'videos/sample_01.mp4', 'label': 0, 'tar': False},{'filename': 'videos/sample_02.mp4', 'label': 1, 'tar': True}
]
2.parse_by_class
将 video_infos 中的数据按类别进行分组,返回一个字典,键为类别标签,值为该类别对应的视频信息列表
def parse_by_class(self):video_infos_by_class = defaultdict(list)#defaultdict 是 Python 中 collections 模块提供的一个特殊字典,当访问一个不存在的键时,它会自动创建一个默认值。这里指定默认值为一个空列表 list。for item in self.video_infos:label = item['label']video_infos_by_class[label].append(item)return video_infos_by_class3.def label2array(num, label) one-hot数据
def label2array(num, label):arr = np.zeros(num, dtype=np.float32)arr[label] = 1.return arr4.dump_results 储存数据
@staticmethoddef dump_results(results, out):"""Dump data to json/yaml/pickle strings or files."""return mmcv.dump(results, out)5.准备训练帧( self.video_infos = self.load_annotations())他是一个列表
def prepare_train_frames(self, idx):"""Prepare the frames for training given the index."""results = copy.deepcopy(self.video_infos[idx])results['modality'] = self.modalityresults['start_index'] = self.start_index# prepare tensor in getitem# If HVU, type(results['label']) is dictif self.multi_class and isinstance(results['label'], list):onehot = torch.zeros(self.num_classes)onehot[results['label']] = 1.results['label'] = onehotaug1 = self.pipeline(results)if self.repeat > 1:aug2 = self.pipeline(results)ret = {"imgs": torch.cat((aug1['imgs'], aug2['imgs']), 0),"label": aug1['label'].repeat(2),}return retelse:return aug1def prepare_test_frames(self, idx):"""Prepare the frames for testing given the index."""results = copy.deepcopy(self.video_infos[idx])results['modality'] = self.modalityresults['start_index'] = self.start_index# prepare tensor in getitem# If HVU, type(results['label']) is dictif self.multi_class and isinstance(results['label'], list):onehot = torch.zeros(self.num_classes)onehot[results['label']] = 1.results['label'] = onehotreturn self.pipeline(results)
子类:处理video
class VideoDataset(BaseDataset):def __init__(self, ann_file, pipeline, labels_file, start_index=0, **kwargs):super().__init__(ann_file, pipeline, start_index=start_index, **kwargs)self.labels_file = labels_file@propertydef classes(self):classes_all = pd.read_csv(self.labels_file)return classes_all.values.tolist()def load_annotations(self):"""Load annotation file to get video information."""if self.ann_file.endswith('.json'):return self.load_json_annotations()video_infos = []with open(self.ann_file, 'r') as fin:for line in fin:line_split = line.strip().split()if self.multi_class:assert self.num_classes is not Nonefilename, label = line_split[0], line_split[1:]label = list(map(int, label))else:filename, label = line_splitlabel = int(label)if self.data_prefix is not None:filename = osp.join(self.data_prefix, filename)video_infos.append(dict(filename=filename, label=label, tar=self.use_tar_format))return video_infos最终:
train_data = VideoDataset(ann_file=config.DATA.TRAIN_FILE, data_prefix=config.DATA.ROOT,labels_file=config.DATA.LABEL_LIST, pipeline=train_pipeline)怎么看数据集返回什么? 看子类实现了了__getitem__(video没有实现,去上面找发现
返回了管道操作(等下数据增强的时候讲)之后的数据
def __getitem__(self, idx):"""Get the sample for either training or testing given index."""if self.test_mode:return self.prepare_test_frames(idx)return self.prepare_train_frames(idx)
->def prepare_test_frames(self, idx):"""Prepare the frames for testing given the index."""results = copy.deepcopy(self.video_infos[idx])results['modality'] = self.modalityresults['start_index'] = self.start_index# prepare tensor in getitem# If HVU, type(results['label']) is dictif self.multi_class and isinstance(results['label'], list):onehot = torch.zeros(self.num_classes)onehot[results['label']] = 1.results['label'] = onehotreturn self.pipeline(results)->self.pipeline = Compose(pipeline)
->train_pipeline = [dict(type='DecordInit'),dict(type='SampleFrames', clip_len=1, frame_interval=1, num_clips=config.DATA.NUM_FRAMES),dict(type='DecordDecode'),dict(type='Resize', scale=(-1, scale_resize)),dict(type='MultiScaleCrop',input_size=config.DATA.INPUT_SIZE,scales=(1, 0.875, 0.75, 0.66),random_crop=False,max_wh_scale_gap=1),dict(type='Resize', scale=(config.DATA.INPUT_SIZE, config.DATA.INPUT_SIZE), keep_ratio=False),dict(type='Flip', flip_ratio=0.5),dict(type='ColorJitter', p=config.AUG.COLOR_JITTER),dict(type='GrayScale', p=config.AUG.GRAY_SCALE),dict(type='Normalize', **img_norm_cfg),dict(type='FormatShape', input_format='NCHW'),dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),dict(type='ToTensor', keys=['imgs', 'label']),]->train_data = VideoDataset(ann_file=config.DATA.TRAIN_FILE, data_prefix=config.DATA.ROOT,labels_file=config.DATA.LABEL_LIST, pipeline=train_pipeline)结果返回了:返回一个字典:images:包含一个[N C H W]为一个采样帧数,labels:为一个独热张量
Dataloader(批次)
train_loader = DataLoader(train_data, sampler=sampler_train,batch_size=config.TRAIN.BATCH_SIZE,num_workers=16,pin_memory=True,drop_last=True,collate_fn=partial(mmcv_collate, samples_per_gpu=config.TRAIN.BATCH_SIZE),)参数解析:
dataset
类型:torch.utils.data.Dataset 子类的实例
作用:指定要加载的数据集,例如前面提到的自定义数据集类的实例。
batch_size
类型:int
作用:每个批次加载的样本数量,默认为 1。例如,如果 batch_size = 32,则每次从数据集中加载 32 个样本。
num_workers
类型:int
作用:使用的子进程数量来加载数据。设置为 0 表示数据将在主进程中加载,
大于 0 则使用多进程并行加载数据,提高数据加载速度,默认为 0
sampler
类型:torch.utils.data.Sampler 子类的实例
作用:自定义样本采样策略。如果指定了 sampler,则 shuffle 参数将被忽略。例如,可以使用 WeightedRandomSampler 进行加权随机采样。
collate_fn
类型:callable
作用:自定义批量数据整理函数,用于将多个样本组合成一个批次。
例如前面提到的 mmcv_collate 函数。如果不指定,将使用默认的整理函数。
drop_last
类型:bool
作用:如果数据集的样本数量不能被 batch_size 整除,是否丢弃最后一个不完整的批次。设置为 True 则丢弃,
设置为 False 则保留,默认为 False
返回值:
DataLoader 是一个可迭代对象,当使用 for 循环遍历 DataLoader 时,每次迭代会返回一个批次的数据。返回的数据格式取决于 dataset 的 __getitem__ 方法和 collate_fn 函数。
def mmcv_collate(batch, samples_per_gpu=1): if not isinstance(batch, Sequence):raise TypeError(f'{batch.dtype} is not supported.')if isinstance(batch[0], Sequence):transposed = zip(*batch)return [collate(samples, samples_per_gpu) for samples in transposed]elif isinstance(batch[0], Mapping):return {key: mmcv_collate([d[key] for d in batch], samples_per_gpu)for key in batch[0]}else:return default_collate(batch) mmcv_collate 函数将多个样本组合成一个批次,最终输出的 batch 是一个字典,包含 'img' 和 'label' 两个键,对应的值分别是批量处理后的图像数据和标签数据
常见的返回形式有元组(包含输入数据和标签)
这个是返回:字典{images:[B,T,C,H,W],labels:}
使用方法
字典:
for idx, batch_data in enumerate(train_loader):images = batch_data["imgs"].cuda(non_blocking=True)label_id = batch_data["label"].cuda(non_blocking=True)元组:
for iii, (image, class_id) in enumerate(tqdm(val_loader)):图像处理->视频
images = images.view((-1,config.DATA.NUM_FRAMES,3)+images.size()[-2:])由NCHW ->N T C H W 记住这个!!!
相关文章:

神经网络的数据集处理
离不开这个库torch.utils.data,这个库有两个类一个Dataset和Dataloader Dataset(对单个样本处理) Dataset 是一个非常重要的概念,它主要用于管理和组织数据,方便后续的数据加载和处理。以下以 PyTorch 为例ÿ…...

深入解析 JVM —— 从基础概念到实战调优的全链路学习指南
文章目录 一、为什么要学习 JVM?1. 面试必备与技能提升2. 性能优化与问题诊断3. 编写高质量代码 二、JVM 基础概念与体系结构1. JVM 简介2. JDK、JRE 与 JVM 三、JVM 内存模型1. 线程私有区2. 线程共享区 四、类加载机制与双亲委派1. 类加载过程2. 双亲委派模型3. 动…...
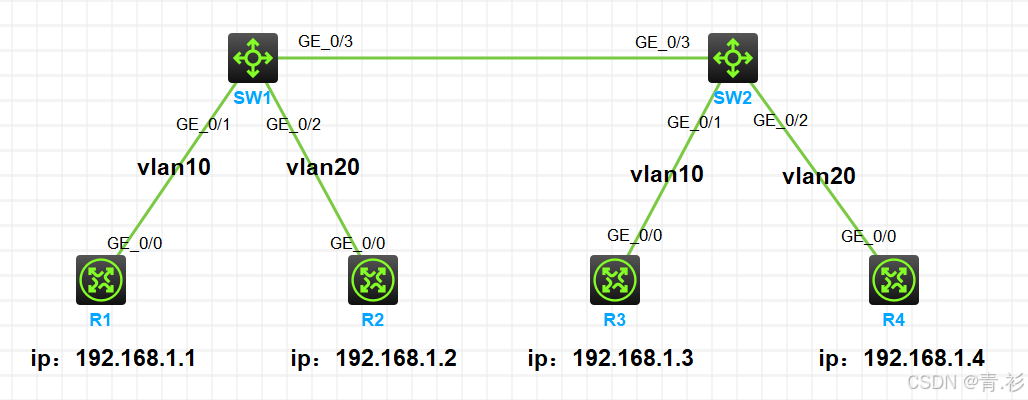
VLAN和Trunk实验
VLAN和Trunk实验 实验拓扑 实验需求 1.按照图示给所有路由器(此处充当pc机)配置IP地址 2.SW1和SW2上分别创建vlan10和vlan20,要求R1和R3属于vlan10,R2和R4属于vlan20 3.SW1和SW2相连的接口配置类型为trunk类型,允许…...
)
MongoDB 数据导出与导入实战指南(附完整命令)
1. 场景说明 在 MongoDB 运维中,数据备份与恢复是核心操作。本文使用 mongodump 和 mongorestore 工具,演示如何通过命令行导出和导入数据,解决副本集连接、路径指定等关键问题。 2. 数据导出(mongodump) 2.1 导出命…...

鸿蒙开发-一多开发之媒体查询功能
在HarmonyOS中,使用ArkTS语法实现响应式布局的媒体查询是一个强大的功能,它允许开发者根据不同的设备特征(如屏幕尺寸、屏幕方向等)动态地调整UI布局和样式。以下是一个使用媒体查询实现响应式布局的实例: 1. 导入必要…...

Spring Boot集成Spring Statemachine
Spring Statemachine 是 Spring 框架下的一个模块,用于简化状态机的创建和管理,它允许开发者使用 Spring 的特性(如依赖注入、AOP 等)来构建复杂的状态机应用。以下是关于 Spring Statemachine 的详细介绍: 主要特性 …...

【Go学习】04-1-Gin框架-路由请求响应参数
【Go学习】04-1-Gin框架 初识框架go流行的web框架GinirisBeegofiber Gin介绍Gin快速入门 路由RESTful API规范请求方法URI静态url路径参数模糊匹配 处理函数分组路由 请求参数GET请求参数普通参数数组参数map参数 POST请求参数表单参数JSON参数 路径参数文件参数 响应字符串方式…...

数据类设计_图片类设计之5_不规则类图形混合算法(前端架构)
前言 学的东西多了,要想办法用出来.C和C是偏向底层的语言,直接与数据打交道.尝试做一些和数据方面相关的内容 引入 接续上一篇,讨论图片类型设计出来后在场景中如何表达,以及不规则图片的混合算法. 图片示意图 图片是怎样表示的,这里把前面的补上 这里的数字1是不规则数据类对…...

零信任架构实战手册-企业安全升级
🔐 开篇痛点暴击: “又被黑客钓鱼了?VPN漏洞补到心累?😫” 传统边界安全像纸糊的墙,内鬼渗透、APT攻击防不胜防! 别慌!零信任架构(Zero Trust)用「永不信任,持续验证」原则,让安全等级飙升10倍! 🚦 零信任3大核心武器(附实操步骤): 1. 🌟 身份即边界!抛…...

【Qt】qApp简单介绍
1. 介绍 在Qt中,qApp是一个全局指针,它指向当前的QApplication或QGuiApplication对象。这个全局指针在Qt应用程序中非常有用,因为它可以让你在任何地方访问到应用程序对象。 在C中,全局指针是一个可以在程序的任何地方访问的指针…...

C++11 编译使用 aws-cpp-sdk
一、对sdk的编译前准备 1、软件需求 此文档针对于在Linux系统上使用源码进行编译开发操作系统使用原生的contos7Linux。机器配置建议 内存8G以上,CPU 4个 以上GCC 4.9.0 及以上版本Cmake 3.12以上 3.21以下apt install libcurl-devel openssl-devel libuuid-devel pulseaudio-…...

【模拟CMOS集成电路设计】带隙基准(Bandgap)设计与仿真(基于运放的电流模BGR)
【模拟CMOS集成电路设计】带隙基准(Bandgap)设计与仿真 前言工程文件&部分参数计算过程,私聊~ 一、 设计指标指标分析: 二、 电路分析三、 仿真3.1仿真电路图3.2仿真结果(1)运放增益(2)基准温度系数仿真(3)瞬态启动仿真(4)静态…...

版本控制器Git(4)
文章目录 前言一、分布式版本控制系统的概念二、克隆远程仓库三、多用户协作与公钥管理四、配置Git忽略特殊文件五、给命令配置别名总结 前言 加油加油,路在脚下!!! 一、分布式版本控制系统的概念 本地操作:所有操作&a…...

Rabbitmq--延迟消息
13.延迟消息 延迟消息:生产者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才会收到消息 延迟任务:一定时间之后才会执行的任务 1.死信交换机 当一个队列中的某条消息满足下列情况之一时,就会…...

springboot436-基于SpringBoot的汽车票网上预订系统(源码+数据库+纯前后端分离+部署讲解等)
💕💕作者: 爱笑学姐 💕💕个人简介:十年Java,Python美女程序员一枚,精通计算机专业前后端各类框架。 💕💕各类成品Java毕设 。javaweb,ssm…...

宇树ROS1开源模型在ROS2中Gazebo中仿真
以GO1为例 1. CMakelists.txt更新语法 cmake_minimum_required(VERSION 3.8) project(go1_description) if(CMAKE_COMPILER_IS_GNUCXX OR CMAKE_CXX_COMPILER_ID MATCHES "Clang")add_compile_options(-Wall -Wextra -Wpedantic) endif() # find dependencies find…...

Web网页制作之爱家居的设计(静态网页)
一、使用的是PyCharm来敲写的代码(布局) 二、主要的html代码的介绍 这段代码展示了如何使用HTML和CSS创建一个结构化的网页,包含导航栏、新闻内容、图片展示和页脚信息。通过引入外部CSS文件,可以进一步美化和布局这些元素。 HTM…...

Linux云计算SRE-第二十周
完成ELK综合案例里面的实验,搭建完整的环境 一、 1、安装nginx和filebeat,配置node0(10.0.0.100),node1(10.0.0.110),node2(10.0.0.120),采用filebeat收集nignx日志。 #node0、node1、node2采用以下相同方式收集ngin…...

【MATLAB例程】AOA(到达角度)法,多个目标定位算法,三维空间、锚点数量自适应(附完整代码)
给出AOA方法下的多目标定位,适用三维空间,锚点数量>3即可,可自定义目标和锚点的数量、坐标等。 文章目录 运行结果源代码代码讲解概述功能代码结构运行结果 10个锚点、4个目标的情况: 100个锚点、10个目标的情况: 修改方便,只需调节下面的两个数字即可: 源代码 …...

Maven 构建 项目测试
Maven 构建 & 项目测试 引言 在当今的软件开发领域,Maven 作为一种流行的项目管理工具,已经得到了广泛的应用。它能够帮助开发者更好地组织和管理项目依赖,简化构建过程。同时,项目测试是确保软件质量的重要环节。本文将详细介绍 Maven 的构建流程以及项目测试的策略…...

Matlab:矩阵运算篇——矩阵数学运算
目录 1.矩阵的加法运算 实例——验证加法法则 实例——矩阵求和 实例——矩阵求差 2.矩阵的乘法运算 1.数乘运算 2.乘运算 3.点乘运算 实例——矩阵乘法运算 3.矩阵的除法运算 1.左除运算 实例——验证矩阵的除法 2.右除运算 实例——矩阵的除法 ヾ( ̄…...

MinIO问题总结(持续更新)
目录 Q: 之前使用正常,突然使用空间为0B,上传文件也是0B(部署在k8s中)Q: 无法上传大文件参考yaml Q: 之前使用正常,突然使用空间为0B,上传文件也是0B(部署在k8s中) A: 1、检查pod状态…...

IDE 使用技巧与插件推荐:全面提升开发效率
在软件开发领域,集成开发环境(IDE)已成为开发者不可或缺的工具。它集代码编辑、编译、调试、版本控制等多种功能于一身,极大地提升了开发效率。然而,许多开发者可能并未充分挖掘 IDE 的潜力。通过掌握一些实用的使用技…...

智算新纪元,腾讯云HAI-CPU助力法律援助
高性能应用服务 1. ChatbotUI 应用介绍 基于腾讯云 DeepSeek 模型的智能化对话界面,支持灵活集成到企业级应用或服务中,提供自然语言交互能力,适用于客服、知识检索、任务自动化等场景。 核心功能 多轮对话引擎:支持上下…...

android 调用wps打开文档并感知保存事件
需求场景 在项目开发中会碰到需要调用WPS打开Word,Excel,Ppt等Office系列文档的情况,网上目前少有正式介绍如何调用相关API打开文档,并实现文档编辑后回传给三方应用,本人在逛WPS社区时发现 解锁WPS二次开发新世界:Android开发用…...

无人机全景应用解析与技术演进趋势
无人机全景应用解析与技术演进趋势 ——从立体安防到万物互联的空中革命 一、现有应用场景全景解析 (一)公共安全领域 1. 立体安防体系 空中哨兵:搭载 77 GHz 77\text{GHz} 77GHz毫米波雷达(探测距离 5 km 5\text{km} 5km&…...

【fnOS飞牛云NAS本地部署跨平台视频下载工具MediaGo与远程访问下载视频流程】
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

PyQt基础——简单的窗口化界面搭建以及槽函数跳转
一、代码实现 import sysfrom PyQt6.QtGui import QPixmap from PyQt6.QtWidgets import QApplication, QWidget, QPushButton, QLabel, QLineEdit, QMessageBox from PyQt6.uic import loadUi from PyQt6.QtCore import Qtclass LoginWindow(QWidget):def __init__(self):sup…...

Powershell语言的Web性能优化
使用PowerShell进行Web性能优化 引言 在当今互联网高速发展的时代,网站和Web应用程序的性能直接影响到用户体验、搜索引擎排名和业务的成功。因此,Web性能优化成为了开发人员和运维工程师的重要任务之一。而PowerShell,作为一种强大的脚本语…...

【Java--数据结构】优先级队列( PriorityQueue)
一. 优先级队列 1.1 优先级队列的概念 优先级队列是一种特殊的队列,它在入队时会根据元素的优先级进行排序,优先级最高的元素排在队列的前面,出队时会优先出队优先级最高的元素。 1.2 优先级队列的区别 (1)与普通…...