Work【2】:PGP-SAM —— 无需额外提示的自动化 SAM!
文章目录
- 前言
- Abstract
- Introduction
- Methods
- Contextual Feature Modulation
- Progressive Prototype Refinement
- Prototype-based Prompt Generator
- Experiment
- Datasets
- Implementation Details
- Results and Analysis
- Ablation Study
- 总结
前言
和大家分享一下我们发表在 ISBI 2025 上的论文:PGP-SAM: Prototype-Guided Prompt Learning for Efficient Few-Shot Medical Image Segmentation。
欢迎大家在 arxiv 上阅读:
PGP-SAM: Prototype-Guided Prompt Learning for Efficient Few-Shot Medical Image Segmentation
代码已经开源!!!期待您的 Star!!!
PGP-SAM
Abstract
Segment Anything Model (SAM) 展现了强大且多功能的图像分割能力,并支持直观的提示交互。然而,将SAM定制应用于医学图像分割需要大量像素级标注和精确的点/框提示设计。为解决这些挑战,我们提出了 PGP-SAM——一种基于原型的新型少样本调优方法,通过有限样本替代繁琐的手动提示设计。核心思想是利用类间和类内原型捕获类别特异性知识与关联关系。我们提出两个关键组件:(1) 即插即用的上下文调制模块,用于融合多尺度信息;(2) 类别引导的交叉注意力机制,通过原型与特征融合实现自动提示生成。在公开多器官数据集和私有脑室数据集上的实验表明,PGP-SAM 仅使用 10% 的 2D 切片即可超越现有无提示 SAM 变体的平均 Dice 分数。
Introduction
医学图像分割旨在实现对特定感兴趣区域(如组织、器官)的精准识别与轮廓勾画,为医生提供可靠的诊断依据和有效的治疗规划[1,2]。然而,实现精确分割通常需要大量标注数据,其收集与标注过程需要耗费大量时间、专业知识和资源。
分割一切模型(Segment Anything Model, SAM)凭借强大的分割能力和用户友好的提示交互机制,为图像分割领域带来了重大突破。然而,其在零样本医学图像分割中的表现被多项研究证实存在不足,这促使研究者探索如何有效适配SAM至医学领域。当前主流方法侧重于通过微调SAM的图像编码器来提升医学图像分割性能,同时保留其交互特性。这些方法在测试阶段常依赖真实标注数据生成提示。此外,针对SAM的无提示微调方法开始涌现,但这类方法对医学知识的利用尚不充分。尽管取得了显著进展,现有工作仍面临两大挑战:
- (1) 由于自然图像与医学图像存在显著领域差异,全参数或编码器重点微调需要大量标注医学数据;
- (2) SAM对输入点/框提示具有高度敏感性,即使提示存在细微偏差也会显著影响结果,这要求在训练和测试阶段必须设计精确的提示。
为应对这些挑战,H-SAM 采用两阶段分层掩码解码器并冻结图像编码器,该策略仅需 10% 的可用样本即可快速整合医学知识。然而,由于可学习参数量较大,H-SAM在有限数据下仍难以有效学习类别特异性信息。
基于上述少样本设定,我们提出 PGP-SAM(原型引导提示学习 SAM),旨在通过原型学习快速迁移类别特异性知识及器官关联关系。PGP-SAM包含两组原型:类内原型(intra-class prototypes)与类间原型(inter-class prototypes),分别学习 CT 图像中器官的类别特异性表征知识和共享知识。这些原型通过梯度反向传播在训练过程中更新。PGP-SAM 包含两个核心模块:(1) 上下文特征精炼模块(Contextual Feature Refinement),通过通道与空间维度的上下文融合使特征聚焦于感兴趣区域;(2) 渐进式原型优化模块(Progressive Prototype Refinement),通过将每个类内原型与最相似的类间原型匹配,并与图像特征、类别特征交互,最终生成增强型原型以产生精确提示。借助原型机制,我们能够从少量数据中学习核心特征。本方法在公开数据集和私有数据集上均取得优异结果,同时仅引入极少量额外参数。
总结而言,我们的主要贡献包括:
- 提出高效的上下文融合机制,帮助模型更好地学习全局信息
- 设计基于原型的提示编码器,无需额外知识即可为SAM提供精确提示
- 在公开与私有数据集上均达到最先进性能
Methods
本节通过微调 SAM 的图像编码器介绍 PGP-SAM 模型。该模型包含多尺度原型引导提示生成器和共享权重的掩码解码器,整体架构如下图所示。

Contextual Feature Modulation
图像编码器提取的特征通常包含丰富的空间细节,但缺乏全局语义理解。受前人工作[15]启发,我们提出上下文特征调制机制(Contextual Feature Modulation, CFM),在空间和通道维度将全局语义信息注入多尺度特征。
给定每个阶段输入特征 F i ∈ R H × W × C F_{i}\in \mathbb{R}^{H\times W\times C} Fi∈RH×W×C(其中 i ∈ { 1 , 2 } i\in\{1,2\} i∈{1,2}),我们分别在空间和通道维度进行增强。此处采用第一和第四图像块[16]后的特征。在空间维度,通过对高度和宽度方向进行平均池化并求和得到 F s ∈ R H × W × C F_{s}\in \mathbb{R}^{H\times W\times C} Fs∈RH×W×C,进而计算空间特征调制矩阵 F i s ∈ R H × W × C F_{i}^{s}\in \mathbb{R}^{H\times W\times C} Fis∈RH×W×C:
F i s = F i ⊙ δ ( φ k × 1 ( ϕ ( φ 1 × k ( F s ) ) ) ) ( 1 ) F_{i}^{s}=F_{i}\odot\delta(\varphi_{k\times 1}(\phi(\varphi_{1\times k}(F_{s})))) \qquad(1) Fis=Fi⊙δ(φk×1(ϕ(φ1×k(Fs))))(1)
其中 φ \varphi φ 表示条带卷积, k k k 为卷积核尺寸, ϕ \phi ϕ 表示层归一化与ReLU激活, δ \delta δ 为Sigmoid函数。类似地,通道维度通过平均池化得到 F c ∈ R 1 × 1 × C F_{c}\in \mathbb{R}^{1\times 1\times C} Fc∈R1×1×C,计算通道特征调制矩阵 F i c ∈ R H × W × C F_{i}^{c}\in \mathbb{R}^{H\times W\times C} Fic∈RH×W×C:
F i c = F i ⊙ δ ( φ 1 × 1 ( ϕ ( φ 1 × 1 ( F c ) ) ) ) ( 2 ) F_{i}^{c}=F_{i}\odot\delta(\varphi_{1\times 1}(\phi(\varphi_{1\times 1}(F_{c})))) \qquad(2) Fic=Fi⊙δ(φ1×1(ϕ(φ1×1(Fc))))(2)
最终将空间调制特征 F i s F_{i}^{s} Fis 和通道调制特征 F i c F_{i}^{c} Fic 与原始特征 F i F_{i} Fi 相加,得到上下文增强特征 F ~ i \tilde{F}_{i} F~i。通过水平和垂直轴的全局池化,CFM捕获轴向上下文信息,使网络聚焦于前景区域,辅助后续原型学习识别最相关的类别特征。
Progressive Prototype Refinement
SAM 的性能依赖于精确提示,微小偏差即影响分割结果[1,13]。为此,我们引入两组原型:
- 类内原型 P intra ∈ R N × C P_{\text{intra}}\in \mathbb{R}^{N\times C} Pintra∈RN×C( N N N为类别数)
- 类间原型 P inter ∈ R Q × C P_{\text{inter}}\in \mathbb{R}^{Q\times C} Pinter∈RQ×C( Q = α × N Q=\alpha\times N Q=α×N, α = 8 \alpha=8 α=8)
Step 1: 原型匹配
计算 P intra P_{\text{intra}} Pintra 与 P inter P_{\text{inter}} Pinter 的余弦相似度,为每个类内原型选取top-k最相似的类间原型,拼接形成增强原型 P ^ ∈ R Q × C \hat{P}\in \mathbb{R}^{Q\times C} P^∈RQ×C( Q = N × ( k + 1 ) Q=N\times(k+1) Q=N×(k+1))。
Step 2: 双路径交叉注意力
设计类别引导双路径交叉注意力,融合图像特征 F I ∈ R H × W × C F_{I}\in \mathbb{R}^{H\times W\times C} FI∈RH×W×C 与类别特征 F M ∈ R H × W × N F_{M}\in \mathbb{R}^{H\times W\times N} FM∈RH×W×N:
- 类别注意力权重 W c W_{c} Wc 计算:
F Θ ′ ′ = ζ ( reshape ( φ ( F Θ ) ) ) , Θ ∈ { I , M } ( 3 ) F_{\Theta}^{\prime\prime}=\zeta\left(\text{reshape}\left(\varphi\left(F_{\Theta}\right)\right)\right),\ \Theta\in\{I,M\} \qquad(3) FΘ′′=ζ(reshape(φ(FΘ))), Θ∈{I,M}(3)
W c = softmax ( φ ( F I ′ ′ ⊗ F M ′ ′ ) ) ( 4 ) W_c=\text{softmax}\left(\varphi\left(F_I^{\prime\prime} \otimes F_M^{\prime\prime}\right)\right) \qquad(4) Wc=softmax(φ(FI′′⊗FM′′))(4) - 查询生成:
W q = softmax ( P ^ F ^ T ) P ^ ′ = ( α ⋅ W c + β ⋅ W q ) ⊙ F ^ ( 5 ) \begin{align*} W_{q}&=\text{softmax}(\hat{P}\hat{F}^{T}) \\ \hat{P}^{\prime}&=(\alpha\cdot W_{c}+\beta\cdot W_{q})\odot\hat{F} \end{align*} \qquad(5) WqP^′=softmax(P^F^T)=(α⋅Wc+β⋅Wq)⊙F^(5)
其中 F ^ \hat{F} F^ 为 F I F_I FI 与 F M F_M FM 融合后的特征。
Step 3: 原型更新
将 P ^ ′ \hat{P}^{\prime} P^′ 重塑为 N × ( k + 1 ) × C N\times(k+1)\times C N×(k+1)×C,分离得到更新后的类内原型 P ^ intra \hat{P}_{\text{intra}} P^intra 和类间原型 P ^ inter \hat{P}_{\text{inter}} P^inter,通过索引匹配更新原始原型库。
Prototype-based Prompt Generator
为避免信息混淆,我们为密集提示和稀疏提示设计独立生成路径:
密集提示生成
通过类间原型与查询交互生成:
D = MLP ( softmax ( F I ⋅ P ^ inter T ) ⋅ P ^ inter ) ( 6 ) D=\text{MLP}(\text{softmax}(F_{I}\cdot\hat{P}_{\text{inter}}^{T})\cdot\hat{P}_{\text{inter}}) \qquad(6) D=MLP(softmax(FI⋅P^interT)⋅P^inter)(6)
其中MLP包含两个点卷积层与GELU激活函数。
稀疏提示生成
通过类内原型与特征交互生成:
S = MLP ( softmax ( P ^ intra T ⋅ F I ) ⋅ F I ) ( 7 ) S=\text{MLP}(\text{softmax}(\hat{P}_{\text{intra}}^{T}\cdot F_{I})\cdot F_{I}) \qquad(7) S=MLP(softmax(P^intraT⋅FI)⋅FI)(7)
双路径设计使提示生成过程既能捕获局部细节(密集提示),又能保持类别区分度(稀疏提示)。
Experiment
本节通过在两个分割任务上的实验评估 PGP-SAM 的性能,与现有 SAM 变体进行对比,并通过消融实验分析模块贡献。
Datasets
我们在公开的 Synapse 多器官 CT 数据集和私有脑室 CT 数据集上进行多器官分割实验:
- Synapse数据集:包含18个训练案例和12个测试案例,每个案例约含70个有效切片
- 脑室数据集:包含400个训练案例和100个测试案例,每个案例约含10个有效切片
所有数据在少样本训练中均调整为 512×512 分辨率。
Implementation Details
所有模型在单张 RTX 3090 GPU 上训练,采用数据增强策略(弹性形变、旋转、缩放)。损失函数为交叉熵损失与 Dice 损失的加权组合。我们使用 LoRA 配置(rank=4)对 ViT-b 模型进行微调,优化器选择 AdamW(初始学习率 3e-4,权重衰减 1e-4),训练 50 个 epoch,批量大小为 8。
Results and Analysis
表1和表2分别展示了在Synapse和脑室数据集上的定量结果(Dice系数%):


关键结论:
- PGP-SAM 在两类数据集上均取得最优 Dice 系数(Synapse: 78.75% vs 73.91%;脑室: 76.39% vs 73.36%)
- 对复杂器官(如胰腺、第三脑室)提升显著(Synapse 胰腺提升 11.29%,脑室第三脑室提升 3.23%)

Ablation Study

总结
本文提出了一种基于原型引导的高效少样本医学图像分割方法PGP-SAM。通过设计上下文特征调制模块(CFM)和渐进式原型优化机制(PPR),我们实现了以下突破:
- 高效上下文融合:CFM模块通过空间-通道双路径调制,使模型在有限数据下有效捕获全局语义信息,相比基线模型(71.92% Dice)提升6.83%。
- 精准提示生成:通过类内/类间原型交互,自动生成的密集与稀疏提示在Synapse和脑室数据集上分别达到78.75%和76.39% Dice,显著优于SAMed(73.91%/73.36%)。
- 低参数量适配:仅需微调0.8M参数(占SAM总参数0.6%),即实现跨数据集的稳定性能提升。
实验结果表明,PGP-SAM在复杂解剖结构(如胰腺、第三脑室)的分割任务中展现出更强的鲁棒性。未来工作将探索:
- 三维体积数据中的原型传递机制;
- 多模态医学图像的原型统一表示学习。
相关文章:
Work【2】:PGP-SAM —— 无需额外提示的自动化 SAM!
文章目录 前言AbstractIntroductionMethodsContextual Feature ModulationProgressive Prototype RefinementPrototype-based Prompt Generator ExperimentDatasetsImplementation DetailsResults and AnalysisAblation Study 总结 前言 和大家分享一下我们发表在 ISBI 2025 上…...

数据安全之策:备份文件的重要性与自动化实践
在信息化高速发展的今天,数据已成为企业运营和个人生活中不可或缺的重要资源。无论是企业的财务报表、客户资料,还是个人的家庭照片、学习笔记,数据的丢失或损坏都可能带来无法挽回的损失。因此,备份文件的重要性日益凸显…...

uniapp+Vue3 组件之间的传值方法
一、父子传值(props / $emit 、ref / $refs) 1、props / $emit 父组件通过 props 向子组件传递数据,子组件通过 $emit 触发事件向父组件传递数据。 父组件: // 父组件中<template><view class"container">…...

WebSocket生命周期和vue中使用
ing。。。晚点更新 进入页面,生命周期挂载后,window监听ws连接online 正常情况,心跳包检测避免断开 非正常情况,ws.onclose断开, 判断1000状态吗,触发重连函数。 定时器,重连,判断…...

blender使用初体验(甜甜圈教程)
使用blender 建模了甜甜圈,时间空闲了,但愿能创建点好玩的吸引人的东西...

web3区块链
Web3 是指下一代互联网,也被称为“去中心化互联网”或“区块链互联网”。它是基于区块链技术构建的,旨在创建一个更加开放、透明和用户主导的网络生态系统。以下是关于 Web3 的一些关键点: ### 1. **核心概念** - **去中心化**࿱…...

大模型学习笔记------Llama 3模型架构之旋转编码(RoPE)
大模型学习笔记------Llama 3模型架构之旋转编码(RoPE) 1、位置编码简介1.1 绝对位置编码1.2 相对位置编码 2、旋转编码(RoPE)2.1 基本概念---旋转矩阵2.2 RoPE计算原理2.2.1 绝对位置编码2.2.2 相对位置编码 3、旋转编码…...

04 1个路由器配置一个子网的dhcp服务
前言 这是最近一个朋友的 ensp 相关的问题, 这里来大致了解一下 ensp, 计算机网络拓扑 相关基础知识 这里一系列文章, 主要是参照了这位博主的 ensp 专栏 这里 我只是做了一个记录, 自己实际操作了一遍, 增强了一些 自己的理解 当然 这里仅仅是一个 简单的示例, 实际场景…...

安装open-webui
open-webui是一个开源的大语言模型交互界面 前提:Ollama已安装,并下载了deepseek-r1:1.5b模型 拉取镜像 docker pull ghcr.io/open-webui/open-webui:main 配置docker-compose.yml services:open-webui:image: ghcr.io/open-webui/open-webui:mainv…...

HCIA-11.以太网链路聚合与交换机堆叠、集群
链路聚合背景 拓扑组网时为了高可用,需要网络的冗余备份。但增加冗余容易后会出现环路,所以我们部署了STP协议来破除环路。 但是,根据实际业务的需要,为网络不停的增加冗余是现实需要的一部分。 那么,为了让网络冗余…...
)
不与最大数相同的数字之和(信息学奥赛一本通-1113)
【题目描述】 输出一个整数数列中不与最大数相同的数字之和。 【输入】 输入分为两行: 第一行为N(N为接下来数的个数,N < 100); 第二行N个整数,数与数之间以一个空格分开,每个整数的范围是-1000,000到1000,000。 【…...

Blender学习方法与技巧
以下是针对Blender零基础用户的学习教程推荐与高效学习方法总结,结合了多个优质资源整理而成,帮助快速入门: 一、Blender学习方法与技巧 制定学习计划与目标 明确短期目标(如掌握基础操作)和长期目标(如独立…...

Amazon RDS ProxySQL 探索(一)
:::info 💡 在日常开发中,开发者们会涉及到数据库的连接,在使用Amazon RDS数据库时,若使用集群模式或者多数据库时,会出现一写多读多个Endpoint,在实际开发中, 开发者们配置数据库连接通常希望走…...
)
HTML嵌入CSS样式超详解(尊享)
一、行内样式(Inline CSS) 1. 定义与语法 行内样式是直接在HTML标签中使用style属性来定义样式。这种方式只对当前标签生效。 <tagname style"css 样式">2. 示例 <p style"color: red; font-size: 14px;">这是一个红…...

[C语言基础]13.动态内存管理
动态内存管理 1. 动态内存分配2. 动态内存函数的介绍2.1 malloc2.2 free2.3 calloc2.4 realloc 3. 动态内存错误3.1 NULL指针解引用3.2 动态开辟空间越界访问3.3 非动态开辟内存使用free释放3.4 free释放动态开辟内存的一部分3.5 同一块动态内存多次释放3.6 动态开辟内存未释放…...

200多种算法应用于二维和三维无线传感器网络(WSN)覆盖场景
2.1 二元感知模型 在当前无线传感器网络(WSN)覆盖场景中,最常见且理想的感知模型是二元感知模型[27]。如图2所示, Q 1 Q_1 Q1和 Q 2 Q_2 Q2代表平面区域内的两个随机点。 Q 1 Q_1 Q1位于传感器的检测区域内,其感…...

模拟类似 DeepSeek 的对话
以下是一个完整的 JavaScript 数据流式获取实现方案,模拟类似 DeepSeek 的对话式逐段返回效果。包含前端实现、后端模拟和详细注释: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><titl…...
开发实现 息屏/亮屏 详情)
鸿蒙(OpenHarmony)开发实现 息屏/亮屏 详情
官网参考链接 实现点击关闭屏幕,定时5秒后唤醒屏幕 权限 {"name": "ohos.permission.POWER_OPTIMIZATION"}代码实现 import power from ohos.power;Entry Component struct Page3 {private timeoutID: number | null null; // 初始化 timeout…...

Flutter PopScope对于iOS设置canPop为false无效问题
这个问题应该出现很久了,之前的组件WillPopScope用的好好的,flutter做优化打算“软性”处理禁用返回手势,出了PopScope,这个组件也能处理在安卓设备上的左滑返回事件。但是iOS上面左滑返回手势禁用,一直无效。 当然之…...

SpringBoot + ResponseBodyEmitter 实时异步流式推送,优雅!
ChatGPT 的火爆,让流式输出技术迅速走进大众视野。在那段时间里,许多热爱钻研技术的小伙伴纷纷开始学习和实践 SSE 异步处理。 我当时也写过相关文章,今天,咱们换一种更为简便的方式来实现流式输出,那就是 Respon…...

网络运维学习笔记(DeepSeek优化版) 016 HCIA-Datacom综合实验01
文章目录 综合实验1实验需求总部特性 分支8分支9 配置一、 基本配置(IP二层VLAN链路聚合)ACC_SWSW-S1SW-S2SW-Ser1SW-CoreSW8SW9DHCPISPGW 二、 单臂路由GW 三、 vlanifSW8SW9 四、 OSPFSW8SW9GW 五、 DHCPDHCPGW 六、 NAT缺省路由GW 七、 HTTPGW 综合实…...

02 windows qt配置ffmpeg开发环境搭建
版本说明 首先我使用ffmpeg版本是4.2.1 QT使用版本5.14.2 我选择是c编译 在02Day.pro⾥⾯添加ffmpeg头⽂件和库⽂件路径 win32 { INCLUDEPATH $$PWD/ffmpeg-4.2.1-win32-dev/include LIBS $$PWD/ffmpeg-4.2.1-win32-dev/lib/avformat.lib \$$PWD/ffmpeg-4.2.1-win32-dev/l…...

vue-treeselect 【单选/多选】的时候只选择最后一层(绑定的值只绑定最后一层)
欢迎访问我的个人博客 |snows_ls BLOGhttp://snows-l.site 一、单选 1、问题: vue-treeselect 单选的时候只选择最后一层(绑定的值只绑定最后一层) 2、方法 1、只需要加上 :disable-branch-nodes"true" 就行࿰…...

焊接机器人与线激光视觉系统搭配的详细教程
以下是关于焊接机器人与线激光视觉系统搭配的详细教程,包含核心程序框架、调参方法及源码实现思路。本文综合了多个技术文档与专利内容,结合工业应用场景进行系统化总结。 一、系统硬件配置与视觉系统搭建 1. 硬件组成 焊接机器人系统通常由以下模块构…...
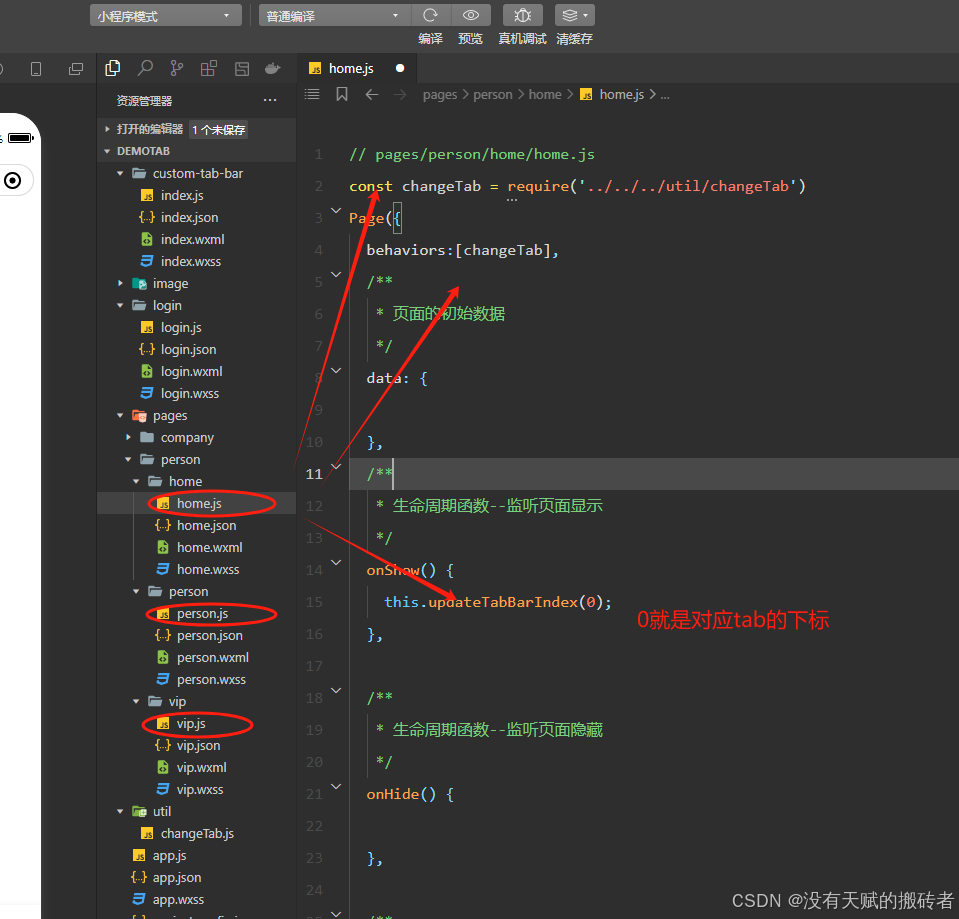
微信小程序实现根据不同的用户角色显示不同的tabbar并且可以完整的切换tabbar
直接上图上代码吧 // login/login.js const app getApp() Page({/*** 页面的初始数据*/data: {},/*** 生命周期函数--监听页面加载*/onLoad(options) {},/*** 生命周期函数--监听页面初次渲染完成*/onReady() {},/*** 生命周期函数--监听页面显示*/onShow() {},/*** 生命周期函…...

Git 本地常见快捷操作
Git 本地常见快捷操作 📌 1. 基本操作 操作命令初始化 Git 仓库git init查看 Git 状态git status添加所有文件到暂存区git add .添加指定文件git add <file>提交更改git commit -m "提交信息"修改最后一次提交信息git commit --amend -m "新…...

Elastic Stack 8.16.0 日志收集平台的搭建
简介 1.1 ELK 介绍 ELK 是 Elasticsearch、Logstash、Kibana 三款开源工具的首字母缩写,构成了一套完整的日志管理解决方案,主要用于日志的采集、存储、分析与可视化。 1)Logstash:数据管道工具,负责从…...

江科大51单片机笔记【16】AD/DA转换(下)
写在前言 此为博主自学江科大51单片机(B站)的笔记,方便后续重温知识 在后面的章节中,为了防止篇幅过长和易于查找,我把一个小节分成两部分来发,上章节主要是关于本节课的硬件介绍、电路图、原理图等理论知识…...

Podman 运行redis 报错
Podman 运行redis 报错 一、报错内容 find: .: Permission denied chown: changing ownership of .: Permission denied二、问题分析 SELinux 模式 SELinux(Security-Enhanced Linux)是一种安全模块,旨在通过强制访问控制(MAC)来增强 Linux 系统的安全性。SELinux 具有…...

基于深度学习的多模态人脸情绪识别研究与实现(视频+图像+语音)
这是一个结合图像和音频的情绪识别系统,从架构、数据准备、模型实现、训练等。包括数据收集、预处理、模型训练、融合方法、部署优化等全流程。确定完整系统的组成部分:数据收集与处理、模型设计与训练、多模态融合、系统集成、部署优化、用户界面等。详…...