爬虫——playwright获取亚马逊数据
目录
- playwright简介
- 使用playwright初窥亚马逊
- 安装playwright
- 打开亚马逊页面
- 搞数据
- 搜索
- 修改bug
- 数据获取
- 翻页
- 优化结构
- 简单保存
playwright简介
playwright是微软新出的一个测试工具,与selenium类似,不过与selenium比起来还是有其自身的优势的(除了教程少是弱项)。
-
任何浏览器 • 任何平台 • 一个 API
- 跨浏览器。 Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit 和 Firefox。
- 跨平台。 在 Windows、Linux 和 macOS 上进行本地或 CI 测试,无头或有头。
- 跨语言。 在 TypeScript、JavaScript、Python、.NET、Java 中使用 Playwright API。
- 测试移动网络。 适用于 Android 的 Google Chrome 和 Mobile Safari 的原生移动模拟。 相同的渲染引擎可以在桌面和云端运行。
(上面是抄官网的, 下面才是个人的使用体验)
-
方便
- 配置方便。与
selenium的配置相比较的话,不需要下载额外的驱动,也不需要下载对应版本的浏览器。(就是配置地址不能修改)。 - 可以异步。
selenium是只能阻塞式的执行,而playwright可以执行异步。 - 内存占用少。好像确实是比较少一点。
- 配置方便。与
使用playwright初窥亚马逊
通常情况,每家电商平台都有自己的反爬措施,亚马逊也不例外,所以要尝试一下,当然如果是scrapy这个爬虫框架的话,似乎可以越过反爬措施,内部的逻辑代码是什么没有深究,现在先拿过来用用。
安装playwright
同样的,这个第三方库也要安装,直接使用pip安装就行
pip install playwright
安装完毕之后,还需要安装一些依赖,只要执行一句话即可。这样就能安装了。
playwright install
如果不能安装,或者安装卡进度条了,可以查看这个教程
打开亚马逊页面
小试牛刀一把,看看这个库怎么样
import asyncio
import time
import traceback
from playwright.async_api import async_playwrightclass AmazonBrowser:def __init__(self, headless=True):self.headless = headlessself.browser = Noneself.page = Noneself.playwright = Noneasync def start(self):self.playwright = await async_playwright().start()self.browser = await self.playwright.chromium.launch(headless=False)self.page = await self.browser.new_page()await self.page.goto("https://www.amazon.com/")time.sleep(60)await self.browser.close()if __name__ == "__main__":asyncio.run(AmazonBrowser().start())
what!!! 不愧是美国注明的电商平台,上来就是验证码=。=还有点不好搞定。
那试试添加headers,应该可以
class AmazonBrowser:def __init__(self, headless=True):self.headless = headlessself.browser = Noneself.page = Noneself.playwright = Noneself.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36","Accept-Language": "en-US,en;q=0.9","Accept-Encoding": "gzip, deflate, br","Referer": "https://www.google.com/", # 伪造,告诉亚马逊网站,说我是从Google搜索页面点击进来的。}

诶嘿! 来了!
搞数据
在第一个页面里面,没有我们想要的数据,所以我们需要输入内容,然后从新的页面中搞到要的数据。
获取元素 → 搜索 → 搞数据 应该是这个思路。
搜索
我们需要获取2个元素,一个元素是搜索框,另一个元素是搜索按钮(当然搞回车按键也行),从F12里面可以得知,搜索框是下面的内容:

搜索按钮是下面的:

先搞定输入框:
import random # 引入random库
class AmazonBrowser:async def start(self):self.playwright = await async_playwright().start()self.browser = await self.playwright.chromium.launch(headless=False)self.page = await self.browser.new_page()await self.page.set_extra_http_headers(self.headers)await self.page.goto("https://www.amazon.com/")search_box = self.page.locator("input#twotabsearchtextbox")# 这里的input有个id,就是twotabsearchtextbox,这个id应该是独立的,所以直接用它。await search_box.wait_for(state="visible")await search_box.type('键盘', delay=random.uniform(50, 200)) time.sleep(60)
【细节讲解】
locator:在Playwright中,locator的作用是用于定位页面上的元素,语法有很多:"text=登录"是通过文本匹配,"#username"是通过ID匹配,"//button[@type='submit']"是通过xpath匹配,"a.s-pagination-next.s-pagination-separator"通过css匹配,"a.s-pagination-next.s-pagination-separator:not([aria-disabled="true"])",这个则是排除具有aria-disabled="true"属性的元素。
type:在playwright中,type的作用时将文字打入输入框中,与之类似的方法是fill,只不过前者是将文字挨个键入,而后者则是将文字一次性输入,在严格监听页面的网页中,type的的功能用的会比较多,因为可以模拟人的操作,而fill则不行。
再执行看看~

芜湖~

同样的,找到搜索按钮并点击就能跳转过去了。
class AmazonBrowser:async def start(self):# ...await search_box.type("键盘", delay=random.uniform(50, 200))await self.page.locator("input#nav-search-submit-button").click()

修改bug
有的人可能会遇到另外一种情况:

这个时候搜索输入框和搜索按钮的id就已经不一样了,这种情况的搜索输入框是id="nav-bb-search",搜索按钮是没有id的只有class="nav-bb-button",所以要修改上面的代码
class AmazonBrowser:async def start(self):#...# 同时检测两种搜索框的存在twotab_exists = await self.page.locator("input#twotabsearchtextbox").count()navbb_exists = await self.page.locator("input#nav-bb-search").count()if twotab_exists:search_box = self.page.locator("input#twotabsearchtextbox")search_btn = self.page.locator("input#nav-search-submit-button")elif navbb_exists:search_box = self.page.locator("input#nav-bb-search")search_btn = self.page.locator("input.nav-bb-button")else:raise Exception("No search box found")await search_box.wait_for(state="visible")await search_box.type("键盘", delay=random.uniform(50, 200))await search_btn.click()
数据获取
我们先来看看要搞哪些数据:

从这个截图上看,有图片,标题,评分,价格。不过有一点是:第二个图片里面有2个价格,到底那个是真实的价格呢?点进去发现,第一个价格是原价,第二个价格好像是二手价格。

那就弄原价吧,不然太麻烦了。可是他的标题有了,要是标题重复了怎么办?从F12里面可以发现data-asin应该是唯一的,那我们就把这个ASIN弄到手,当然后面也有一个uuid,弄那个也行。

# 新增依赖库
from urllib.parse import urljoinclass AmazonBrowser:async def start(self):#...await self.page.wait_for_selector('div[role="listitem"][data-asin]', timeout=15000)items = await self.page.locator('div[role="listitem"][data-asin]').all()batch_data = []for index, item in enumerate(items):asin = await item.get_attribute("data-asin")uuid = await item.get_attribute("data-uuid")img = item.locator('img.s-image').firstawait img.scroll_into_view_if_needed()await self.page.wait_for_timeout(500)src = await img.get_attribute('src')href = await item.locator('a.a-link-normal.s-line-clamp-2').get_attribute('href')product = await item.locator('h2.a-size-medium > span').first.inner_text()price_section = item.locator('span.a-price[data-a-color="base"]')if await price_section.count() > 0:price = await price_section.locator('span.a-offscreen').first.inner_text()else:price_section_secondary = item.locator('div.a-row.a-size-base.a-color-secondary')if await price_section_secondary.count() > 0:price = await price_section_secondary.locator('span.a-color-base').first.inner_text()else:price = '暂无价格'batch_data.append({'Product': product,'UUID': uuid,'ASIN': asin,'ImageURL': src,'URL': urljoin(self.target_url, href) if href else None,'Price': price,})
【细节讲解】
wait_for_selector:是等待页面上符合选择器的元素出现,最长等待15秒。div[role="listitem"][data-asin]:是选择<div>元素,要求这个元素里面有[role="listitem"]以及[data-asin]这两个东西。
await,异步标志,有些情况下需要使用,有些情况下则不需要使用:- 需要使用的情况:
- 涉及网络请求:如
goto()、fetch() - 获取异步返回的内容:如
text_content()、inner_text() - 涉及页面交互的操作:如点击、输入、等待
- 需要时间完成的操作:如
wait_for_selector()
- 涉及网络请求:如
- 不需要使用的情况:
locator()对象- 只定义选择器,不交互
- 直接获取属性,如
browser.name
- 需要使用的情况:
翻页
一页当然是不行的,一页才16条数据,所以肯定要翻页的。同理从F12里面找到翻页标签,那就是

然后仅有这个也不够,我们还要知道终止,也就是不能点击的情况下,是什么情况的,所以翻到20页得到

所以需要设计选择器,来判断下一页按钮能不能按下去,或者是能不能检测到终止的<span>
class AmazonBrowser:async def start(self):#...disabled_selector = 'span.s-pagination-next.s-pagination-disabled'enabled_selector = 'a.s-pagination-next:not([aria-disabled="true"])'# 当检测到disable_selector时就继续while True:if await self.page.locator(disabled_selector).count() > 0:breaknext_btn = self.page.locator(enabled_selector)await next_btn.scroll_into_view_if_needed()# 点击前确保元素可交互await next_btn.wait_for(state="visible")await next_btn.click()await self.page.wait_for_timeout(2000) # 基础等待

优化结构
但是仅有循环,没有获取数据,这也不是我们想要的,所以接下来是优化结构。将数据获取也翻页分开。
class AmazonBrowser:# ...async def data_collection(self):await self.page.wait_for_selector('div[role="listitem"][data-asin]', timeout=15000)items = await self.page.locator('div[role="listitem"][data-asin]').all()for index, item in enumerate(items):asin = await item.get_attribute("data-asin")uuid = await item.get_attribute("data-uuid")img = item.locator('img.s-image').firstawait img.scroll_into_view_if_needed()await self.page.wait_for_timeout(500)src = await img.get_attribute('src')href = await item.locator('a.a-link-normal.s-line-clamp-2').get_attribute('href')product = await item.locator('h2.a-size-medium > span').first.inner_text()price_section = item.locator('span.a-price[data-a-color="base"]')if await price_section.count() > 0:price = await price_section.locator('span.a-offscreen').first.inner_text()else:price_section_secondary = item.locator('div.a-row.a-size-base.a-color-secondary')if await price_section_secondary.count() > 0:price = await price_section_secondary.locator('span.a-color-base').first.inner_text()else:price = '暂无价格'# self.batch_data要提前声明哦self.batch_data.append({'Product': product,'UUID': uuid,'ASIN': asin,'ImageURL': src,'URL': urljoin(self.target_url, href) if href else None,'Price': price,})async def start(self):#...disabled_selector = 'span.s-pagination-next.s-pagination-disabled'enabled_selector = 'a.s-pagination-next:not([aria-disabled="true"])'# 当检测到disable_selector时就继续while True:if await self.page.locator(disabled_selector).count() > 0:break# 在这里添加await self.data_collection()next_btn = self.page.locator(enabled_selector)await next_btn.scroll_into_view_if_needed()# 点击前确保元素可交互await next_btn.wait_for(state="visible")await next_btn.click()await self.page.wait_for_timeout(2000) # 基础等待
这样就搞定啦,但是数据要怎么保存呢?可以有两种方式,一种方式是保存在数据库里面,比如mongodb,mysql等等,还可以保存在csv文件里面。
简单保存
在这里就简单的保存成csv文件的样子吧,也就是直接使用pandas保存就行了,下一篇章就搞一下mongodb
# 导入依赖库
import pandas as pd
class AmazonBrowser:def __init__(self):self.df = pd.DataFrame()#... async def start(self):while True:#...while循环内容new_df = pd.DataFrame(self.batch_data)self.df = pd.concat([self.df, new_df], ignore_index=True)self.df.to_csv(path)
就酱~

相关文章:
爬虫——playwright获取亚马逊数据
目录 playwright简介使用playwright初窥亚马逊安装playwright打开亚马逊页面 搞数据搜索修改bug数据获取翻页优化结构 简单保存 playwright简介 playwright是微软新出的一个测试工具,与selenium类似,不过与selenium比起来还是有其自身的优势的ÿ…...

大数据学习(77)-Hive详解
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

回调方法传值汇总
<template v-slot"scope"><el-switch v-model"scope.row.open" change"(p1) > changeOpen(p1, scope.row)"></el-switch></template>公域流量 多选 selection-change“val > multipleSelection val”...

汽车一键启动PKE无钥匙系统
移动管家汽车一键启动PKE舒适无钥匙遥控远程系统是一种集成了多项先进功能的汽车电子系统,主要目的是提高驾驶便利性和安全性。 以下是该系统的具体功能: 功能类别 功能描述 无钥匙进入 感应无钥匙进入(自动感应开关门) 一…...

Postman 新手入门指南:从零开始掌握 API 测试
Postman 新手入门指南:从零开始掌握 API 测试 一、Postman 是什么? Postman 是一款功能强大的 API 开发与测试工具,支持 HTTP 请求调试、自动化测试、团队协作等功能。无论是开发人员还是测试工程师,都可以用它快速验证接口的正确…...

猿大师中间件:如何在最新Chrome浏览器Web网页内嵌本地OCX控件?
OCX控件是ActiveX控件的一种,主要用于在网页中嵌入复杂的功能,如图形渲染、多媒体播放等,可是随着谷歌Chrome等主流浏览器升级,目前已经不支持微软调用ActiveX控件了,如果想调用OCX控件用IE浏览器或者国产双擎浏览器&a…...

[数据结构]排序之 归并排序(有详细的递归图解)
一、非递归 基本思想: 归并排序( MERGE-SORT )是建立在归并操作上的一种有效的排序算法 , 该算法是采用分治法( Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列&#x…...

构建第二个Django的应用程序
构建第二个应用程序 文章目录 构建第二个应用程序1.打开Visual Studio code 左上角 点击fike 点击open folder2.打开上次的Django项目 并按图示点击进入终端3.在下方终端输入创建app01项目的命令 接着在左上方会出现一个app01的项目4.接着在Hellodjango的项目里settings.py中定…...

axios 请求拦截器和 响应拦截器总结
请求拦截器 和 响应拦截器 是 axios 提供的强大功能,用于在请求发送前和响应返回后统一处理某些逻辑。它们的作用和具体用法如下: 1. 请求拦截器 作用 在请求发送之前,对请求配置进行统一处理。例如: 添加请求头(如…...

图像分割的mask有空洞怎么修补
分享一个对实例分割mask修补的方法,希望对大家有所帮助。 1. 这是我准备分割的图片 2 分割结果 可以看到衣服部分有一些没分割出来,二值化图片能清晰看到衣服部分有些黑色未分出的地方。 3 补全mask区域 import cv2 import numpy as npdef fill_mask_h…...
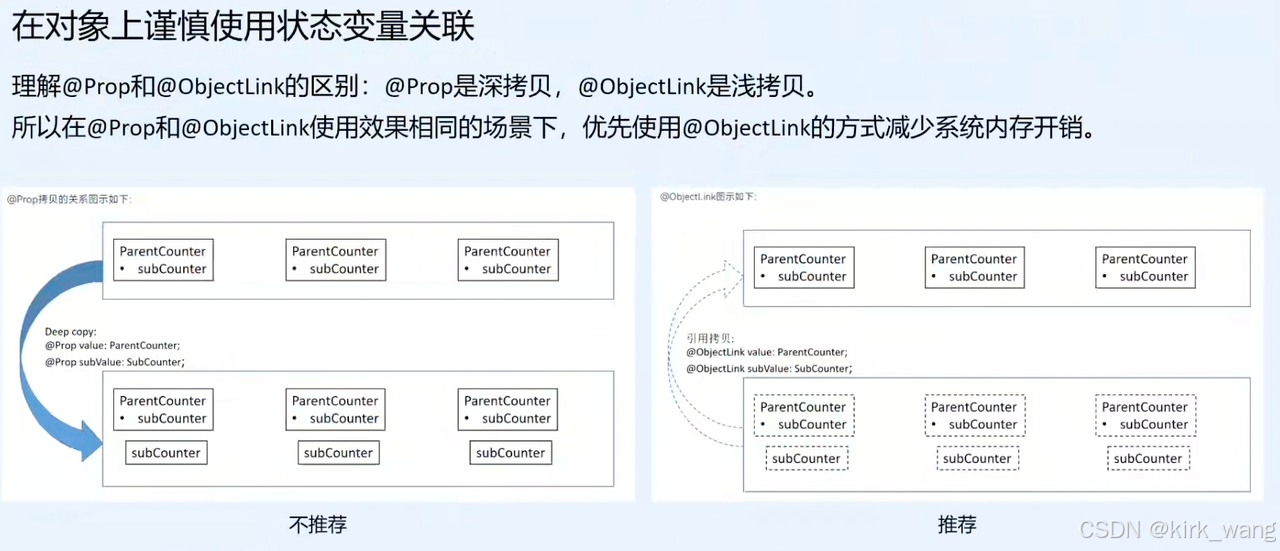
HarmonyOS NEXT 组件状态管理的对比
在HarmonyOS NEXT开发中,组件状态管理是构建动态用户界面的核心。本文将深入探讨State、Prop、Link和ObjectLink这四种常见的状态管理装饰器,并通过示例代码进行对比分析,以帮助同学们更好地理解和选择合适的状态管理方式。 一、装饰器概述 …...

C#通过API接口返回流式响应内容---SignalR方式
1、背景 在上两篇《C#通过API接口返回流式响应内容—分块编码方式》和《C#通过API接口返回流式响应内容—SSE方式》实现了流式响应的内容。 上面的这两个主要是通过HTTP的一些功能,除了这些之外,还有WebSocket的方式。C#中的WebSocket的有比较多的方案&…...

vulhub靶机----基于docker的初探索,环境搭建
环境搭建 首先就是搭建docker环境,这里暂且写一下 #在kali apt update apt install docker.io配置docker源,位置在/etc/docker/daemon.json {"registry-mirrors": ["https://5tqw56kt.mirror.aliyuncs.com","https://docker…...
)
P1659 [国家集训队] 拉拉队排练 (manacher 算法)
P1659 [国家集训队] 拉拉队排练 - 洛谷 这题需要求前k大的回文子串的长度的乘积。因为n的大小为1e6 ,所以我们只能使用manacher 线性的来找到所有的回文子串。 其中长度大的回文子串可以包含小的回文子串,所以其实我们只需要知道以每一个位置为回文中心…...

Redis命令详解--集合
Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令: SADD key member1 [member2...] 向集合添加一个或多个成员 SREM key member1 [member2...] 移除集合中一个或多个成员 SMEMBERS key 获…...

AI对话框实现
请注意,功能正在开发中,代码和注释不全 场景:AI对话框实现,后端调用AI大模型。前端发送请求后端返回流式数据,进行一问一答的对话功能(场景和现在市面上多个AI模型差不多,但是没人家功能健全&a…...
可视化图解算法:删除链表中倒数第n个节点
1. 题目 描述 给定一个链表,删除链表的倒数第 n 个节点并返回链表的头指针 例如, 给出的链表为: 1→2→3→4→5, n 2. 删除了链表的倒数第 n 个节点之后,链表变为1→2→3→5. 数据范围: 链表长度 0≤n≤1000,链表中任意节点的…...

智能汽车图像及视频处理方案,支持视频智能拍摄能力
美摄科技,作为智能汽车图像及视频处理领域的先行者,凭借其卓越的技术实力和前瞻性的设计理念,为全球智能汽车制造商带来了一场视觉盛宴的革新。我们自豪地推出——美摄科技智能汽车图像及视频处理方案,一个集高效性、智能化、画质…...
)
如何根据 CUDA 配置安装 PyTorch 和 torchvision(大模型 环境经验)
目录 前言1. CUDA2. 环境配置前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 写过ubuntu的配置安装:Ubuntu安装配置Cuda和Pytorch gpu 以下针对Window,如何通过Cuda配置对应版本,安装大模型环境! 代码有配置包,直接执行:pip install -r requi…...

微信小程序的业务域名配置(通过ingress网关的注解)
一、背景 微信小程序的业务域名配置(通过kong网关的pre-function配置)是依靠kong实现,本文将通过ingress网关实现。 而我们的服务是部署于阿里云K8S容器,当然内核与ingress无异。 找到k8s–>网络–>路由 二、ingress注解 …...

自学Python创建强大AI:从入门到实现DeepSeek级别的AI
人工智能(AI)是当今科技领域最热门的方向之一,而Python是AI开发的首选语言。无论是机器学习、深度学习还是自然语言处理,Python都提供了丰富的库和工具。如果你梦想创建一个像DeepSeek这样强大的AI系统,本文将为你提供…...

Matlab 舰载机自动着舰控制系统研究
1、内容简介 Matlab 188-舰载机自动着舰控制系统研究 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...
】)
【华为OD-E卷 -123 判断一组不等式是否满足约束并输出最大差 100分(python、java、c++、js、c)】
【华为OD-E卷 - 判断一组不等式是否满足约束并输出最大差 100分(python、java、c++、js、c)】 题目 给定一组不等式,判断是否成立并输出不等式的最大差(输出浮点数的整数部分) 要求: 不等式系数为 double类型,是一个二维数组 不等式的变量为 int类型,是一维数组; 不等式…...

剑指 Offer II 113. 课程顺序
comments: true edit_url: https://github.com/doocs/leetcode/edit/main/lcof2/%E5%89%91%E6%8C%87%20Offer%20II%20113.%20%E8%AF%BE%E7%A8%8B%E9%A1%BA%E5%BA%8F/README.md 剑指 Offer II 113. 课程顺序 题目描述 现在总共有 numCourses 门课需要选,记为 0 到 n…...

小科普《DNS服务器》
DNS服务器详解 1. 定义与核心作用 DNS(域名系统)服务器是互联网的核心基础设施,负责将人类可读的域名(如www.example.com)转换为机器可识别的IP地址(如192.0.2.1),从而实现设备间的…...

嵌入式硬件篇---WIFI模块
文章目录 前言一、核心工作原理1. 物理层(PHY)工作频段2.4GHz5GHz 调制技术直接序列扩频正交频分复用高效数据编码 2. 协议栈架构MAC层Beacon帧4次握手 3. 核心工作模式 二、典型应用场景1. 智能家居系统远程控制环境监测视频监测 2. 工业物联网设备远程…...

WindowsAD域服务权限提升漏洞
WindowsAD 域服务权限提升漏洞(CVE-2021-42287, CVE-2021-42278) 1.漏洞描述 Windows域服务权限提升漏洞(CVE-2021-42287, CVE-2021-42278)是由于Active Directory 域服务没有进行适当的安全限制,导致可绕过安…...

Oracle常见系统函数
一、字符类函数 1,ASCII(c)和CHR(i)字符串和ascii码互转换 SQL> select ascii(Z) ,ascii(H),ascii( A) from dual;ASCII(Z) ASCII(H) ASCII(A) ---------- ---------- ----------90 72 32SQL> select chr(90),chr(72),chr(65) from dual;C…...

甘特图dhtmlx-gantt 一行多任务
继上篇进行修改 dhtmlxGantt 甘特图 一行展示多条任务类型_dhtmlxgantt多个任务显示在一行-CSDN博客 主要修改 getProductData 数据部分: 数据中添加: render: "split", //允许任务在同一行中拆分显示, parent: "1",…...

docker配置国内镜像站链接
修改这个文件 sudo vi /etc/docker/daemon.json将镜像站的链接放在里面,如果大于等于两个用逗号分隔 { "registry-mirrors": ["https://docker.1panel.live"] }使配置生效 sudo systemctl daemon-reload sudo systemctl restart docker条件允…...