CUDA编程面试高频30题
1. 什么是CUDA?它与GPU的关系是什么?
答: CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和应用程序接口模型。它允许开发者利用NVIDIA GPU进行通用计算任务,而不仅仅是图形渲染。CUDA提供了一个编程模型,使得开发者可以通过C、C++或Fortran等语言编写程序,并在支持CUDA的GPU上运行这些程序以获得显著的性能提升。
2. 解释CUDA中的线程层次结构(Thread Hierarchy)。
答: CUDA中的线程层次结构包括网格(Grid)、块(Block)和线程(Thread)三个级别。一个网格由多个块组成,每个块内包含多个线程。这种分层结构有助于实现高效的并行执行。每个块可以独立于其他块执行,但块内的所有线程共享相同的资源,如共享内存。线程ID用于标识每个线程的位置,以便它们可以访问特定的数据元素。
3. 如何计算一个线程的全局ID?
答: 全局ID是通过以下公式计算得出:
int globalId = blockIdx.x * blockDim.x + threadIdx.x;这里blockIdx.x表示当前块在网格中的索引,blockDim.x表示每个块中线程的数量,而threadIdx.x则是当前线程在其所属块中的索引。对于二维或多维的情况,需要相应调整上述公式的维度。
4. 描述全局内存、共享内存和常量内存之间的区别。
答:
- 全局内存: 容量大,所有线程都可以访问,但访问速度较慢,适合存储大量数据。
- 共享内存: 位于每个SM(Streaming Multiprocessor)上,块内线程共享,访问速度快,但容量有限,主要用于减少对全局内存的频繁访问。
- 常量内存: 只读,容量较小,具有高速缓存,适用于在整个核函数执行期间保持不变的数据。
5. 什么是warp?为什么理解warp对CUDA编程很重要?
答: Warp是GPU执行的基本单位,通常包含32个线程。Warp内的线程以单指令多线程(SIMT)方式执行相同的指令流。理解warp的重要性在于优化时需要考虑warp的执行效率,例如避免warp divergence(当warp内的线程遇到不同的分支路径时),因为这会导致某些线程处于空闲状态,降低整体性能。
6. 描述全局内存、共享内存和常量内存之间的区别。(重复)
答: 见第4题的回答。
7. 如何在CUDA中使用共享内存?
答: 使用__shared__关键字声明共享内存变量。例如,在核函数内部定义共享数组:
__global__ void exampleKernel(float* input, float* output) {__shared__ float sharedData[256];// 加载数据到共享内存...__syncthreads(); // 确保所有线程完成加载// 进行计算...
}注意,__syncthreads()用于同步块内的所有线程,确保在此之前的操作已经完成。
8. 解释内存合并的概念,并举例说明其重要性。
答: 内存合并是指当连续的线程访问连续的内存地址时,硬件能够将这些请求合并为更少的内存事务。例如,在向量加法中,如果每个线程按顺序访问连续的输入数组元素,则可以实现内存合并,从而提高内存带宽利用率。这对于最大化全局内存带宽至关重要。
9. 在CUDA编程中,如何减少全局内存访问次数?
答: 减少全局内存访问次数的方法包括:
- 使用共享内存来缓存频繁访问的数据。
- 采用内存合并技术,确保线程按顺序访问连续的内存地址。
- 尽可能地复用数据,比如在矩阵乘法中使用Tile方法。
10. 什么是纹理内存?何时使用纹理内存?
答: 纹理内存是一种只读的缓存机制,专门设计用于处理具有空间局部性的数据,如图像处理。它提供了自动插值和边界检查等功能。当你处理的数据表现出良好的空间局部性,或者你需要快速随机访问大型数据集时,使用纹理内存可以获得更好的性能。例如,在图像滤波操作中,使用纹理内存可以加速像素值的读取过程。示例代码如下:
texture<float, 2> texRef; // 定义纹理对象
// 绑定数据到纹理对象
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
cudaMemcpyToArray(cuArray, 0, 0, h_data, size, cudaMemcpyHostToDevice);
cudaBindTextureToArray(texRef, cuArray, channelDesc);
// 核函数中访问纹理内存
__global__ void textureKernel(...) {float value = tex2D(texRef, x, y); // 纹理拾取...
}11. 提高CUDA程序性能的主要策略有哪些?
答: 提高CUDA程序性能的主要策略包括:
- 优化内存访问:减少全局内存访问次数,利用共享内存和纹理内存。
- 线程配置优化:选择合适的block size(通常为128或256),确保每个SM上有足够的活跃线程以充分利用资源。
- 避免warp divergence:尽量减少条件分支,因为这会导致warp内的线程执行不同的代码路径,降低效率。
- 重叠计算与通信:通过使用CUDA流实现数据传输和计算的并发执行。
- 指令级并行性:合理安排指令顺序,使得GPU能够更好地利用其SIMT架构。
12. 如何选择合适的block size以优化CUDA程序?
答: 选择合适的block size需要考虑以下几个因素:
- 硬件限制:每个SM上的最大线程数和寄存器数量。
- 内存需求:确保每个block使用的共享内存和寄存器不会超过SM的限制。
- 负载均衡:选择能让所有SM都能被充分利用的block size。通常推荐的block size是128或256,但最佳值需根据具体应用调整。
- 使用
cudaOccupancyMaxPotentialBlockSize函数可以帮助自动确定最优block size。
13. 解释“算术强度”(Arithmetic Intensity)的概念。
答: 算术强度是指一个算法中每字节访存量所对应的浮点运算次数。它是衡量一个算法是否适合在GPU上运行的重要指标之一。高算术强度意味着对于相同的数据量,有更多的计算操作,这有利于掩盖访存延迟,提高GPU利用率。可以通过增加局部性、复用数据等方式来提高算术强度。
14. 列举几种减少bank冲突的方法。
答: 减少bank冲突的方法有:
- 对齐数据结构:确保数据结构按bank边界对齐,避免跨bank访问。
- 循环展开:通过手动展开循环减少同时访问同一bank的可能性。
- 使用移位代替乘法:例如,如果需要访问共享内存中的索引,可以用
(i + offset) % bankCount代替乘法操作。 - 调整数据布局:改变数据存储方式,如转置矩阵,可以改变访问模式从而减少冲突。
15. 在CUDA中,如何利用异步操作提升性能?
答: 异步操作允许CPU和GPU之间进行重叠执行,即一边传输数据一边进行计算。主要方法包括:
- CUDA Streams:将任务分配给不同的流,使它们能够并发执行。例如,可以在一个流中进行数据传输,在另一个流中执行核函数。
cudaStream_t stream;
cudaStreamCreate(&stream);
cudaMemcpyAsync(d_A, h_A, size, cudaMemcpyHostToDevice, stream);
kernel<<<grid, block, 0, stream>>>(d_A, d_B);
cudaStreamSynchronize(stream); // 等待所有操作完成- 异步内存拷贝:使用
cudaMemcpyAsync代替同步的cudaMemcpy,允许在数据传输的同时执行其他操作。
16. 编写一个简单的CUDA核函数实现向量加法。
答: 下面是一个简单的CUDA核函数示例,用于实现两个向量的加法:
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < N) C[i] = A[i] + B[i];
}17. 如何在CUDA中处理复杂的条件逻辑?
答: 处理复杂条件逻辑时应尽量避免导致warp divergence的情况。可以采取以下措施:
- 预计算条件:提前计算出哪些线程满足条件,并将这些信息存储在一个掩码中,然后根据掩码执行相应的操作。
- 简化条件表达式:尝试重构代码,使得条件分支尽可能简单,减少不同路径之间的差异。
- 使用predicated execution:NVIDIA GPU支持基于预测执行的方式,即使某些线程不满足条件也能继续执行后续指令,只是结果会被丢弃。
18. 解释如何避免Warp Divergence。
答: 避免warp divergence的关键在于设计代码时尽量让同一个warp内的线程执行相同的指令序列。具体做法包括:
- 最小化条件语句:尽量减少if-else等控制结构的使用。
- 统一分支路径:当必须使用条件语句时,确保尽可能多的线程走相同的路径。
- 利用mask技术:通过计算mask来决定哪些线程应该执行特定的操作,而不是直接使用条件判断。
19. 在CUDA编程中,如何有效地利用共享内存进行数据交换?
答: 有效利用共享内存进行数据交换的方法包括:
- 加载数据块:首先将需要频繁访问的数据从全局内存加载到共享内存中。
- 同步线程:使用
__syncthreads()确保所有线程都完成了数据加载之后再开始处理。 - 减少重复加载:设计算法使得数据只需从全局内存加载一次即可被多次使用。
- 注意边界检查:确保在共享内存中访问数据时不会超出分配的空间范围。
20. 简述如何通过调整线程配置来优化核函数执行效率。
答: 调整线程配置以优化核函数执行效率涉及以下几个方面:
- 选择适当的block size:通常建议block size为128或256,但需根据具体应用的需求和硬件特性调整。
- 平衡资源使用:确保每个block使用的共享内存和寄存器不超过SM的限制,防止因资源不足而限制驻留的block数量。
- 最大化并发度:通过选择合适的网格大小(grid size),使得所有SM都能被充分利用。
- 考虑数据局部性:根据数据访问模式选择线程配置,比如当数据具有良好的空间局部性时,适当增大block size有助于提高缓存命中率。
21. 什么是CUDA Streams?它们如何用于提升并发度?
答: CUDA流(Stream)是一种机制,允许开发者在同一个GPU上并行执行多个任务。每个流代表一系列命令(如内核启动、内存拷贝等)的序列,这些命令在该流中按顺序执行。通过将不同的任务分配给不同的流,可以实现计算与数据传输的重叠执行,从而提高GPU利用率和整体应用性能。例如,在一个流中执行数据传输的同时,在另一个流中执行计算任务。
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);// 在stream1中异步拷贝数据
cudaMemcpyAsync(d_A, h_A, size, cudaMemcpyHostToDevice, stream1);
kernel<<<grid, block, 0, stream1>>>(d_A, d_B);// 在stream2中异步拷贝数据
cudaMemcpyAsync(d_C, h_C, size, cudaMemcpyHostToDevice, stream2);
kernel<<<grid, block, 0, stream2>>>(d_C, d_D);22. 简述CUDA Graphs的功能及其应用场景。
答: CUDA Graphs提供了一种优化方式来表示和执行一系列相关操作,比如一系列的内核调用和内存拷贝。它允许用户创建图形式的任务描述,并以更高效的方式执行这些任务,减少了CPU-GPU之间的交互开销。CUDA Graphs特别适用于具有重复模式的工作负载,如深度学习训练中的批量处理或科学计算中的迭代算法。
23. 解释多GPU环境下的编程挑战及解决方案。
答: 多GPU编程的主要挑战包括负载均衡、通信效率和复杂性管理。解决这些问题的方法有:
- 负载均衡:确保各GPU之间的工作量均匀分布。
- 高效通信:利用NVIDIA NCCL库提供的高性能集合通信原语(如all-reduce)来加速跨GPU的数据交换。
- 简化复杂性:使用高层次框架或库(如Horovod、PyTorch Distributed)抽象化底层细节,使得开发人员能够专注于算法本身而非分布式系统的管理。
24. 如何利用NVIDIA Nsight工具进行性能分析?
答: NVIDIA Nsight是一组工具集,帮助开发者分析CUDA应用程序的性能瓶颈。主要步骤如下:
- 使用Nsight Compute分析单个内核的性能指标,如寄存器使用情况、共享内存占用、指令吞吐量等。
- 使用Nsight Systems查看整个应用程序的时间线视图,了解不同阶段的执行时间和资源消耗情况。
- 根据分析结果调整代码结构或参数设置,以优化性能。
25. 讨论CUDA中的错误处理机制,以及如何调试CUDA程序。
答: CUDA提供了cudaError_t类型的返回值来指示函数调用的成功与否。对于每个API调用,应检查其返回状态。此外,还可以使用cudaGetLastError()获取最近一次发生的错误信息。为了调试CUDA程序,可以利用以下工具和技术:
- Nsight Debugger:支持断点设置、变量监控等功能。
- printf():在内核中使用
printf()输出调试信息。 - cuda-memcheck:检测非法内存访问等问题。
26. 描述一个实际项目中使用CUDA加速计算的例子。
答: 例如,在图像处理领域,CUDA可用于加速卷积神经网络(CNN)的推理过程。通过将CNN的前向传播部分移植到CUDA上运行,可以显著加快模型的预测速度。这不仅提高了实时性,也降低了能耗,非常适合移动设备上的部署。
27. 在图像处理领域,CUDA可以如何被用来加速算法?
答: CUDA非常适合图像处理,因为它能高效地处理大规模并行运算。具体应用包括但不限于:
- 滤波操作:如高斯模糊、边缘检测等。
- 色彩空间转换:快速转换图像的颜色表示形式。
- 图像变换:如缩放、旋转等几何变换。
28. 简述CUDA在深度学习训练中的应用。
答: CUDA极大地推动了深度学习的发展,几乎所有主流的深度学习框架(如TensorFlow、PyTorch)都支持CUDA加速。通过CUDA,可以大幅减少神经网络训练时间,尤其是在涉及大量矩阵乘法和卷积操作的情况下。此外,NVIDIA还推出了cuDNN库,进一步优化了深度学习模型的性能。
29. 如何在CUDA中高效地实现矩阵乘法?
答: 高效实现矩阵乘法的关键在于充分利用共享内存和减少全局内存访问次数。一种常见的方法是采用分块技术(tiling),即把大矩阵分割成小块,然后在共享内存中加载这些小块进行局部计算。这种方法不仅可以减少全局内存带宽的需求,还能增加数据重用率,提高计算效率。
30. 讨论CUDA编程中可能遇到的安全性和稳定性问题及应对措施。
答: 安全性和稳定性问题是CUDA编程不可忽视的部分,主要包括:
- 内存泄漏和非法访问:正确管理内存分配与释放,使用工具如
cuda-memcheck检测潜在问题。 - 死锁:特别是在使用多个CUDA流时,需小心设计同步机制避免死锁发生。
- 硬件故障:定期更新驱动程序和固件,保证系统稳定运行;同时设计容错机制,如数据备份与恢复策略。
相关文章:

CUDA编程面试高频30题
1. 什么是CUDA?它与GPU的关系是什么? 答: CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和应用程序接口模型。它允许开发者利用NVIDIA GPU进行通用计算任务,而不仅仅是图形渲染。CUDA提…...

PageHelper插件依赖引入不报错,但用不了
情况: 父模块pom. Xml 引入1. 4. 0以上版本的pagehelper-spring-boot-starter。 要用到插件的子模块,去掉版本号,引入和父模块一样的依赖。 引入成功,没有报错,但是打开右边的maven里面没有找到PageHelper插件。 终端清空并重…...

背包问题——动态规划的经典问题包括01背包问题和完全背包问题
01背包问题:给你多个物品每个物品只能选一次,要你在不超过背包容积(或者恰好等于)的情况下选择装价值最大的组合。如果没有动态规划的基础其实是很难理解这个问题的,所以看这篇文章之前先去学习一下动态规划的基本思想…...

MyBatis 面试专题
MyBatis 面试专题 基础概念MyBatis中的工作原理MyBatis 与 Hibernate 的区别?#{} 和 ${} 的区别?MyBatis 的核心组件有哪些? 映射与配置如何传递多个参数?ResultMap 的作用是什么?动态 SQL 常用标签有哪些?…...

Animation - AI Controller控制SKM_Manny的一些问题
一些学习笔记归档; 在UE5中,使用新的小白人骨骼:SKM_Manny,会跟UE4中的小白人有一些差别; 比如在用AI Controller控制使用该骨骼(配置默认的ABP_Manny Animation BP)角色的时候,需要…...

安科瑞新能源防逆流解决方案:守护电网安全,赋能绿色能源利用
随着光伏、储能等新能源在用户侧的快速普及,如何避免电力逆流对电网造成冲击,成为行业关注的焦点。安科瑞凭借技术实力与丰富的产品矩阵,推出多场景新能源防逆流解决方案,以智能化手段助力用户实现安全、经济的能源管理࿰…...

filebeat和logstash区别
Filebeat 角色: 轻量级日志收集器。 功能: 从指定的日志文件中读取日志数据。 可以从多个源(如文件、系统日志、容器日志等)收集日志。 将收集到的日志数据传输到 Logstash、Elasticsearch 或其他支持的输出端点。 性能: 由于是轻量级的,File…...

【一起学Rust | Tauri2.0框架】基于 Rust 与 Tauri 2.0 框架实现全局状态管理
前言 在现代应用程序开发中,状态管理是构建复杂且可维护应用的关键。随着应用程序规模的增长,组件之间共享和同步状态变得越来越具有挑战性。如果处理不当,状态管理可能会导致代码混乱、难以调试,并最终影响应用程序的性能和可扩…...

扩散模型算法实战——三维重建的应用
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 引言 三维重建是计算机视觉和图形学中的一个重要研究方向,旨在从二维图像或其他传感器数据中恢复…...

社群经济4.0时代:开源链动模式与AI技术驱动的电商生态重构
摘要:在Web3.0技术浪潮与私域流量红利的双重驱动下,电商行业正经历从"流量收割"到"用户深耕"的范式转变。本文基于社群经济理论框架,结合"开源链动21模式"、AI智能名片、S2B2C商城小程序源码等创新工具&#x…...

【Linux系统】进程等待:告别僵尸进程深入理解Linux进程同步的核心密码
Linux系列 文章目录 Linux系列前言一、进程等待的核心目的二、进程等待的实现方式2.1 wait()函数2.2 waitpid()函数 总结 前言 在Linux系统中,进程等待(Process Waiting)是多进程编程中的核心机制,指父进程…...

根据文件名称查询文件所在位置
在 Linux 中,根据文件名称查询文件所在位置主要通过命令行工具实现,以下是几种常用方法: --- ### **1. 使用 find 命令(最灵活)** find 命令可以递归搜索指定目录下的文件,支持按名称、类型、时间等条件过…...

六十天前端强化训练之第二十五天之组件生命周期大师级详解(Vue3 Composition API 版)
欢迎来到编程星辰海的博客讲解 看完可以给一个免费的三连吗,谢谢大佬! 目录 一、生命周期核心知识 1.1 生命周期全景图 1.2 生命周期钩子详解 1.2.1 初始化阶段 1.2.2 挂载阶段 1.2.3 更新阶段 1.2.4 卸载阶段 1.3 生命周期执行顺序 1.4 父子组…...
—自定义运算符)
Pytorch使用手册(专题五十)—自定义运算符
1. PyTorch 自定义运算符 PyTorch 提供了一个庞大的运算符库,这些运算符可以对张量进行操作(例如 torch.add、torch.sum 等)。然而,您可能希望向 PyTorch 引入一个新的自定义操作,并使其能够与诸如 torch.compile、autograd 和 torch.vmap 等子系统协同工作。为此,您必须…...

springboot整合mybatis-plus(保姆教学) 及搭建项目
一、Spring整合MyBatis (1)将MyBatis的DataSource交给Spring IoC容器创建并管理,使用第三方数据库连接池(Druid,C3P0等)代替MyBatis内置的数据库连接池 (2)将MyBatis的SqlSessionFactory交给Spring IoC容器创建并管理,使用spring-mybatis整…...
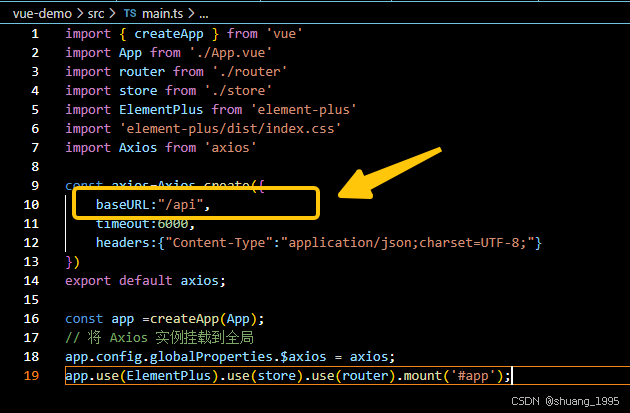
VSCode创建VUE项目(三)使用axios调用后台服务
1. 安装axios,执行命令 npm install axios 2. 在 main.ts 中引入并全局挂载 Axios 实例 修改后的 代码(也可以单独建一个页面处理Axios相关信息等,然后全局进行挂载) import { createApp } from vue import App from ./App.vue import rou…...

JVM常用垃圾回收器
Serial 和Serial Old收集器 Serial 系列的垃圾收集器采用了简单高效、资源消耗最少、单线程收集的设计思路。 简单高效:由于硬件资源有限,垃圾回收器需要设计得简单高效,以减少系统资源的占用。Serial 系列的垃圾收集器实现简单,…...

车辆模型——运动学模型
文章目录 约束及系统移动机器人运动学模型(Kinematic Model)自行车模型含有加速度 a a a 的自行车模型系统偏差模型 在机器人的研究领域中,移动机器人的系统建模与分析是极为关键的基础环节,本文以非完整约束的轮式移动机器人为研…...

EJS缓存解决多页面相同闪动问题
基于 EJS 的模板引擎特性及其缓存机制,以下是关于缓存相同模块的详细解答: 一、EJS 缓存机制的核心能力 模板编译缓存 EJS 默认会将编译后的模板函数缓存在内存中,当相同模板文件被多次渲染时,会直接复用已编译的模板函数&#x…...

<details>和<summary>标签的用途,如何使用它们实现可折叠内容
大白话和标签的用途,如何使用它们实现可折叠内容 <details> 和 <summary> 标签用途 <details> 和 <summary> 标签是 HTML 里的实用标签,二者配合能创建出可折叠内容。 <details> 标签就像是一个容器,能把那…...

HUGO介绍、安装、以及使用
HUGO官方网站,文章内容的简介大部分来自官网的翻译,官网是纯英文描述,英语好的可以前往官方网站,博主在这里简介中简单翻译处理包括一些链接的引用,主要是讲解一下如何安装和使用。 这里再粘贴一个三方网站opendocs.i…...

【STM32实物】基于STM32的太阳能充电宝设计
基于STM32的太阳能充电宝设计 演示视频: 基于STM32的太阳能充电宝设计 硬件组成: 系统硬件包括主控 STM32F103C8T6、0.96 OLED 显示屏、蜂鸣器、电源自锁开关、温度传感器 DS18B20、继电器、5 V DC 升压模块 、TB4056、18650锂电池、9 V太阳能板、稳压降压 5 V三极管。 功能…...

【Netty】长连接与短连接的不同实现
长连接与短连接的不同实现 配置层面 // 长连接配置 bootstrap.option(ChannelOption.SO_KEEPALIVE, true) // 启用 TCP keepalive.option(ChannelOption.TCP_NODELAY, true); // 禁用 Nagle 算法// 短连接不需要这些配置心跳机制 // 长连接需要心跳 pipeline.addLast(new Idl…...

安装 OpenSSL 1.1.1 的完整脚本适用于 Ubuntu 22.04 系统
#!/bin/bash # 更新系统包 sudo apt-get update # 安装编译工具和依赖库 sudo apt-get install -y build-essential checkinstall zlib1g-dev # 下载 OpenSSL 1.1.1 源码 wget https://www.openssl.org/source/openssl-1.1.1.tar.gz # 检查下载是否成功 if [ $? -ne 0 ]; …...

24-智慧旅游系统(协同过滤算法)
介绍 技术: 基于 B/S 架构 SpringBootMySQLLayuivue 环境: Idea mysql maven jdk1.8 管理端功能 管理端主要用于对系统内的各类旅游资源进行管理,包括用户信息、旅游路线、车票、景点、酒店、美食、论坛等内容。具体功能如下: …...

Vue 中的日期格式化实践:从原生 Date 到可视化展示!!!
📅 Vue 中的日期格式化实践:从原生 Date 到可视化展示 🚀 在数据可视化场景中,日期时间的格式化显示是一个高频需求。本文将以一个邀请码关系树组件为例,深入解析 Vue 中日期格式化的 核心方法、性能优化 和 最佳实践…...

2025年使用Scrapy和Playwright解决网页抓取挑战的方案
0. 引言 随着互联网技术的发展,网页内容呈现方式越来越复杂,大量网站使用JavaScript动态渲染内容,这给传统的网络爬虫带来了巨大挑战。在2025年的网络爬虫领域,Scrapy和Playwright的结合为我们提供了一个强大的解决方案ÿ…...

可靠消息投递demo
以下是一个基于 Spring Boot RocketMQ 的完整分布式事务实战 Demo,包含事务消息、本地事务、自动重试、死信队列(DLQ) 等核心机制。代码已充分注释,可直接运行。 一、项目结构 src/main/java ├── com.example.rocketmq │ …...

阻止 Mac 在运行任务时进入休眠状态
掌握Caffeinate命令:让您的 Mac 保持清醒以完成关键任务 开发人员经常发现自己在 Mac 上运行持续时间较长的进程。无论是大量文件上传、广泛的数据分析脚本,还是复杂的构建过程,我们最不希望的就是我们的机器在任务中途进入睡眠状态。输入 c…...

Copilot提示词库用法:调整自己想要的,记住常用的,分享该共用的
不论你是 Microsoft 365 Copilot 的新用户还是熟练运用的老鸟,不论你是使用copilot chat,还是在office365中使用copilot,copilot提示词库都将帮助你充分使用copilot这一划时代的产品。它不仅可以帮助你记住日常工作中常用的prompt提示词&…...