ChatTTS 开源文本转语音模型本地部署 API 使用和搭建 WebUI 界面
ChatTTS(Chat Text To Speech),专为对话场景设计的文本生成语音(TTS)模型,适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。支持中文和英文,还可以穿插笑声、说话间的停顿、以及语气词等。
1 下载模型
通过git-lfs工具包下载:
sudo apt install git-lfs
下载文件:
git lfs install
git clone https://www.modelscope.cn/pzc163/chatTTS.git ChatTTS-Model
如果因网络不佳下载中断,可以通过以下命令在中断后继续下载:
git lfs pull
2 安装 ChatTTS 依赖包
下载ChatTTS官网GitHub源码:
git clone https://gitcode.com/2noise/ChatTTS.git ChatTTS
安装Python依赖包:
cd ChatTTS
pip install -r requirements.txt
torch需要使用2.2.2
3 ChatTTS 中文文本转音频文件
ChatTTS 官网的样例代码 API 可能会跑不起来。
ChatTTS-01.py
import ChatTTS
import torch
import torchaudio# 下载的ChatTTS模型文件目录,请按照实际情况替换
MODEL_PATH = '/path/to/ChatTTS-Model'# 初始化并加载模型,特别注意加载模型参数,官网样例代码已经过时
chat = ChatTTS.Chat()
chat.load_models(vocos_config_path=f'{MODEL_PATH}/config/vocos.yaml',vocos_ckpt_path=f'{MODEL_PATH}/asset/Vocos.pt',gpt_config_path=f'{MODEL_PATH}/config/gpt.yaml',gpt_ckpt_path=f'{MODEL_PATH}/asset/GPT.pt',decoder_config_path=f'{MODEL_PATH}/config/decoder.yaml',decoder_ckpt_path=f'{MODEL_PATH}/asset/Decoder.pt',tokenizer_path=f'{MODEL_PATH}/asset/tokenizer.pt',
)# 需要转化为音频的文本内容
text = '中文文本'# 文本转为音频
wavs = chat.infer(text, use_decoder=True)# 保存音频文件到本地文件(采样率为24000Hz)
torchaudio.save("./output/output-01.wav", torch.from_numpy(wavs[0]), 24000)
运行Python代码:python ChatTTS-01.py
也可以在文本转换成语音之后,直接播放语音内容:
from IPython.display import Audio# 播放生成的音频(autoplay=True 代表自动播放)
Audio(wavs[0], rate=24000, autoplay=True)
4 搭建 WebUI 界面
4.1 安装 Python 依赖包
pip install omegaconf~=2.3.0 transformers~=4.41.1
pip install tqdm einops vector_quantize_pytorch vocos
pip install modelscope gradio
运行 Python 程序,即可看到可视化界面,可以随意输入文本来生成音频文件了。
ChatTTS-WebUI.py
import randomimport ChatTTS
import gradio as gr
import numpy as np
import torch
from ChatTTS.infer.api import refine_text, infer_codeprint('启动ChatTTS WebUI......')# WebUI设置
WEB_HOST = '127.0.0.1'
WEB_PORT = 8089MODEL_PATH = '/path/to/ChatTTS-Model'chat = ChatTTS.Chat()
chat.load_models(vocos_config_path=f'{MODEL_PATH}/config/vocos.yaml',vocos_ckpt_path=f'{MODEL_PATH}/asset/Vocos.pt',gpt_config_path=f'{MODEL_PATH}/config/gpt.yaml',gpt_ckpt_path=f'{MODEL_PATH}/asset/GPT.pt',decoder_config_path=f'{MODEL_PATH}/config/decoder.yaml',decoder_ckpt_path=f'{MODEL_PATH}/asset/Decoder.pt',tokenizer_path=f'{MODEL_PATH}/asset/tokenizer.pt',
)def generate_seed():new_seed = random.randint(1, 100000000)return {"__type__": "update","value": new_seed}def generate_audio(text, temperature, top_P, top_K, audio_seed_input, text_seed_input, refine_text_flag):torch.manual_seed(audio_seed_input)rand_spk = torch.randn(768)params_infer_code = {'spk_emb': rand_spk,'temperature': temperature,'top_P': top_P,'top_K': top_K,}params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}torch.manual_seed(text_seed_input)text_tokens = refine_text(chat.pretrain_models, text, **params_refine_text)['ids']text_tokens = [i[i < chat.pretrain_models['tokenizer'].convert_tokens_to_ids('[break_0]')] for i in text_tokens]text = chat.pretrain_models['tokenizer'].batch_decode(text_tokens)# result = infer_code(chat.pretrain_models, text, **params_infer_code, return_hidden=True)print(f'ChatTTS微调文本:{text}')wav = chat.infer(text,params_refine_text=params_refine_text,params_infer_code=params_infer_code,use_decoder=True,skip_refine_text=True,)audio_data = np.array(wav[0]).flatten()sample_rate = 24000text_data = text[0] if isinstance(text, list) else textreturn [(sample_rate, audio_data), text_data]def main():with gr.Blocks() as demo:default_text = "文字"text_input = gr.Textbox(label="输入文本", lines=4, placeholder="Please Input Text...", value=default_text)with gr.Row():refine_text_checkbox = gr.Checkbox(label="文本微调开关", value=True)temperature_slider = gr.Slider(minimum=0.00001, maximum=1.0, step=0.00001, value=0.8, label="语音温度参数")top_p_slider = gr.Slider(minimum=0.1, maximum=0.9, step=0.05, value=0.7, label="语音top_P采样参数")top_k_slider = gr.Slider(minimum=1, maximum=20, step=1, value=20, label="语音top_K采样参数")with gr.Row():audio_seed_input = gr.Number(value=42, label="语音随机数")generate_audio_seed = gr.Button("\U0001F3B2")text_seed_input = gr.Number(value=42, label="文本随机数")generate_text_seed = gr.Button("\U0001F3B2")generate_button = gr.Button("文本生成语音")text_output = gr.Textbox(label="微调文本", interactive=False)audio_output = gr.Audio(label="语音")generate_audio_seed.click(generate_seed,inputs=[],outputs=audio_seed_input)generate_text_seed.click(generate_seed,inputs=[],outputs=text_seed_input)generate_button.click(generate_audio,inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],outputs=[audio_output, text_output, ])# 启动WebUIdemo.launch(server_name='127.0.0.1', server_port=8089, share=False, show_api=False, )if __name__ == '__main__':main()
相关文章:

ChatTTS 开源文本转语音模型本地部署 API 使用和搭建 WebUI 界面
ChatTTS(Chat Text To Speech),专为对话场景设计的文本生成语音(TTS)模型,适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。支持中文和英文,还可以穿插笑声、说话间的停顿、以…...

【linux】统信操作系统修改默认编辑模式从nano改为vim
统信操作系统修改默认编辑模式从nano改为vim 适用命令update-alternatives --config editor rootuos-PC:~# update-alternatives --config editor 有 3 个候选项可用于替换 editor (提供 /usr/bin/editor)。选择 路径 优先级 状态 ---------------------…...

单一职责原则开闭原则其他开发原则
一、单一职责原则(Single Responsibility Principle, SRP) 定义 一个类应该有且仅有一个引起它变化的原因(即一个类只负责一个职责)。 核心思想 高内聚:类的功能高度集中 低耦合:减少不同职责之间的相互影…...

数据结构---图的深度优先遍历(DFS)
一、与树的深度优先遍历之间的联系 1.类似于树的先根遍历。 递归访问各个结点: 2.图的深度优先遍历 先设置一个数组,初始值全部设置为false,先访问一个结点,在用一个循环,依次检查和这个结点相邻的其他结点,…...

健康养生:拥抱生活,从呵护身心开始
在这个瞬息万变的时代,人们好似不停旋转的陀螺,在忙碌中迷失了对健康的关注。然而,健康养生绝非可有可无的点缀,它是幸福生活的基石,如同阳光与空气,滋养并支撑着我们的生命。当我们懂得拥抱健康养生&#…...

基线定位系统:长基线与超短基线的原理与应用
基线定位系统:长基线与超短基线的原理与应用 在测量、导航、天文等领域,基线是两个已知位置之间的距离或方向,常用于三角测量、卫星定位等方法来确定其他位置的相对关系。本文将深入探讨长基线(Long Baseline, LBL)与…...

QT网页显示的几种方法及对比
一.直接跳转打开网页 1.使用QDesktopServices::openUrl调用系统浏览器 原理:直接调用操作系统默认浏览器打开指定URL,不在应用程序内嵌入网页。 优点: 实现简单,无需额外模块或依赖。 适用于仅需跳转外部浏览器的场景。 缺点&…...

深入浅出理解LLM PPO:基于verl框架的实现解析之一
1. 写在前面 强化学习(Reinforcement Learning,RL)在大型语言模型(Large Language Model,LLM)的训练中扮演着越来越重要的角色。特别是近端策略优化(Proximal Policy Optimization,PPO)算法,已成为对齐LLM与人类偏好的主流方法之一。本文将基于verl框架(很多复刻De…...

Linux python 安装 conda(内部自带的有python的版本了)
位置网站 https://repo.anaconda.com/miniconda/也可以在https://www.anaconda.com/download/success 官方下载之后方linux中 切换路径之后 执行 bash Miniconda3-py310_25.1.1-2-Linux-x86_64.sh [rootVM-4-5-centos ~]# [rootVM-4-5-centos ~]# uname -a Linux VM-4-5-cen…...

git原理与常用命令及其使用
认识工作区、暂存区、版本库 ⼯作区:是在电脑上你要写代码或⽂件的⽬录。 暂存区:英⽂叫 stage 或 index。⼀般存放在 .git ⽬录下的 index ⽂件(.git/index)中,我们 把暂存区有时也叫作索引(index…...

19681 01背包
19681 01背包 ⭐️难度:中等 🌟考点:动态规划、01背包 📖 📚 import java.util.Arrays; import java.util.LinkedList; import java.util.Queue; import java.util.Scanner;public class Main {static int N 10001…...

Guava:Google开源的Java工具库,太强大了
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

多阶段构建实现 Docker 加速与体积减小:含文件查看、上传及拷贝功能的 FastAPI 应用镜像构建
本文围绕使用 Docker 构建 FastAPI 应用镜像展开,着重介绍了多阶段构建的 Dockerfile 编写及相关操作。借助多阶段构建,不仅实现了 Docker 构建的加速,还有效减小了镜像体积。 1. Dockerfile 内容 以下是我们要使用的 Dockerfile 内容&…...

蓝桥杯每日一题----海底高铁
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 题目链接 P3406 海底高铁 - 洛谷https://www.luogu.com.cn/problem/P3406 解题思路 在这道题来说,主要使用的想法就是使用一维的差分数组,这道题中有两个买…...

触动精灵对某东cookie读取并解密--记lua调用C语言
在Mac上构建Lua扩展模块:AES解密与Base64解码实战 今天我要分享一个实用技术:如何在Mac系统上为Lua编写和编译C扩展模块,特别是实现一个某东iOS PIN码解密功能的扩展。这对于需要在Lua环境中执行高性能计算或使用底层系统功能的开发者非常有…...

分布式中间件:基于 Redis 实现分布式锁
分布式中间件:基于 Redis 实现分布式锁 一、背景引入 在当今的互联网应用中,分布式系统变得越来越常见。在分布式环境下,多个服务实例可能会同时对共享资源进行读写操作,这就很容易引发数据不一致等问题。比如电商系统中的库存扣…...

鸿蒙开发工程师简历项目撰写全攻略
一、项目结构的黄金法则 建议采用「41」结构: 项目背景(业务价值)技术架构(鸿蒙特性)核心实现(技术难点)个人贡献(量化成果)附加价值(延伸影响) …...

MSE分类时梯度消失的问题详解和交叉熵损失的梯度推导
下面是MSE不适合分类任务的解释,包含梯度推导。以及交叉熵的梯度推导。 前文请移步笔者的另一篇博客:大模型训练为什么选择交叉熵损失(Cross-Entropy Loss):均方误差(MSE)和交叉熵损失的深入对比…...

【设计模式】三十二、策略模式
系列文章|源码 https://github.com/tyronczt/design-mode-learn 文章目录 系列文章|源码一、模式定义与核心思想二、模式结构与Java实现1. 核心角色2. Java代码示例 三、策略模式的五大核心优势四、适用场景五、与其他模式的对比六、最佳实践建议总结 🚀进阶版【更…...

Cyberchef实用功能之-json line格式文件美化和查询
本文将介绍一下如何使用cyberchef对json line格式数据进行美化方便阅读,以及json line格式数据的批量查询操作。 之前的文章介绍了json格式数据的美化和查询,即Cyberchef实用功能之-json解析美化和转换,Cyberchef实用功能之-批量提取json数据…...

Java求101-200之间有多少素数
Java学习笔记 今天看教程看到了这个题,对于一名打过算法竞赛的选手还是很简单的,但由于之前是c组的,所以用java写一下,练一下手。 代码: package com.itheima.hello;public class Test1 {public static void main(S…...
计算机基础:编码03,根据十进制数,求其原码
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:计算机基础:编码02,有符号数编码…...

FaryGui文字shader修改,弧线排列
因项目要求,希望将文字进行标题那样的弧线排列,如下图: 对FaryGUI的文字Shader进行了一些修改,基本达到要求,shader设置如下: shader代码如下: // Upgrade NOTE: replaced _Object2World with unity_ObjectToWorld // Upgrade NOTE: replaced mul(UNITY_MATRIX_MVP,*) with Un…...

QT笔记---JSON
QT笔记---JSON JSON1、JSON基本概念1.1、判断.json文件工具 2、生成.json数据3、解析.json数据 JSON 在现代软件开发中,数据的交换和存储格式至关重要。JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,以其简洁易…...
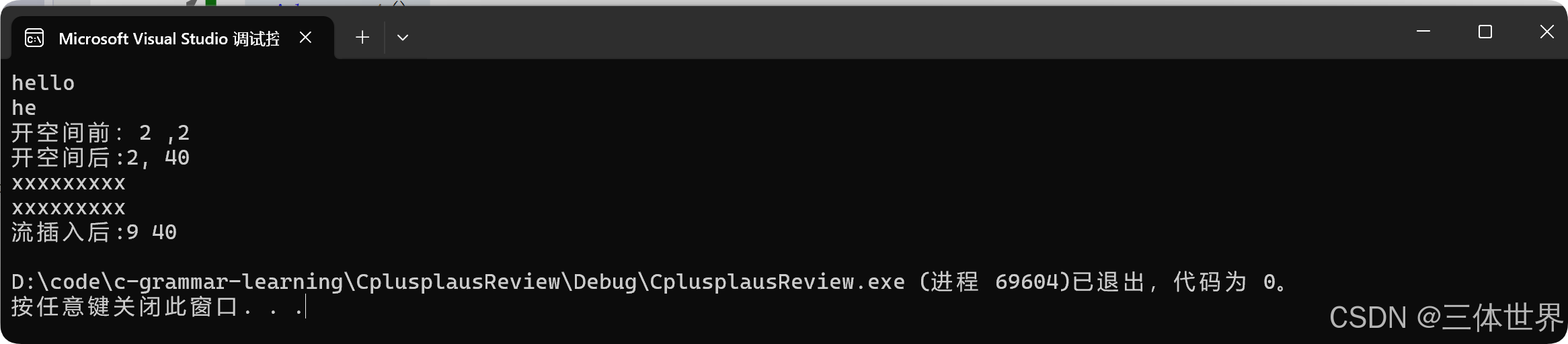
C++ string的模拟实现
Hello!!大家早上中午晚上好,昨天复习了string的使用,今天来模拟实现一下string!!! 一、string的框架搭建 1.1首先我们需要一个string的头文件用来做变量、函数、类等声明;再需要一个test文件来做测试,还需…...

使用LangChain实现基于LLM和RAG的PDF问答系统
目录 前言一.大语言模型(LLM)1. 什么是LLM?2. LLM 的能力与特点 二、增强检索生成(RAG)三. 什么是 LangChain?1. LangChain 的核心功能2. LangChain 的优势3. LangChain 的应用场景4. 总结 四.使用 LangChain 实现基于 PDF 的问答系统 前言 本文将介绍 …...

图像滤波中常用滤波器的相位响应——不是只有零相位滤波器
实偶函数滤波器 当滤波器是实偶函数时,其滤波结果的相位在通带内为 0 或 π \pi π,正频率和负频率成分的相位相同。这种相位特性使得实偶函数滤波器在低通滤波、平滑处理等需要保持信号相位不失真的应用中非常有用。 实偶函数特性: 滤波器…...
`)
学习CSS滤镜属性 `filter: invert()`
一、核心机制 数学原理 invert(1) 对每个像素的RGB通道执行 颜色反相计算: 新通道值 255 - 原通道值 例如 rgb(255,0,0)(纯红)会转换为 rgb(0,255,255)(青色)。 透明度处理 该滤镜会保留元素的Alpha通道(…...

C++实现rabbitmq生产者消费者
RabbitMQ是一个开源的消息队列系统,它实现了高级消息队列协议(AMQP), 特点 可靠性:通过持久化、镜像队列等机制保证消息不丢失,确保消息可靠传递。灵活的路由:提供多种路由方式,如…...

在VMware上部署【Ubuntu】
镜像下载 国内各镜像站点均可下载Ubuntu镜像,下面例举清华网站 清华镜像站点:清华大学开源软件镜像站 | Tsinghua Open Source Mirror 具体下载步骤如下: 创建虚拟机 准备:在其他空间大的盘中创建存储虚拟机的目录,…...