【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测
【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测
文章目录
- 【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测
- 前言
- YOLOV3模型运行环境搭建
- YOLOV3模型运行
- 数据集准备
- YOLOV3运行
- 模型训练
- 模型验证
- 模型推理
- 导出onnx模型
- 总结
前言
Ultralytics YOLO 是一系列基于 YOLO(You Only Look Once)算法的检测、分割、分类、跟踪和姿势估计模型,由 Ultralytics 公司开发和维护,YOLO 算法以其快速和准确的目标检测能力而闻名。从最初的YOLOv1到最新的YOLOv11,每一代版本都在特征提取、边界框预测和优化技术等方面引入了重要的创新。这些改进特别是在骨干网络(backbone)、颈部(neck)和头部(head)组件上的进步,使得YOLO成为实时目标检测领域的领先解决方案。
【YOLO的发展历程参考】,本博文将通过人脸检测项目简要介绍Ultralytics–YOLOv3的使用。【官方源码】
YOLOV3模型运行环境搭建
在win11环境下装anaconda环境,方便搭建专用于YOLOV3模型的虚拟环境。
-
查看主机支持的cuda版本(最高)
# 打开cmd,执行下面的指令查看CUDA版本号 nvidia-smi
-
安装GPU版本的torch【官网】
博主的cuda版本是12.2,博主选的11.8也没问题。

其他cuda版本的torch在【以前版本】找对应的安装命令。 -
博主安装环境参考
# 创建虚拟环境 conda create -n yolov3 python=3.10 # 查看新环境是否安装成功 conda env list # 激活环境 activate yolov3 # cd到合适的位置下载yolov3源码 git clone https://github.com/ultralytics/yolov3 cd yolov3 # 切换到一个特定的v9.6.0版本 git checkout tags/v9.6.0 # 安装pytorch和torchvision,否则容易自动安装成CPU版本(不知原因) pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # 安装运行所需的包,修改requirements,删除torch和torchvision部分,增加onnx(博主需要导出onnx) pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 查看所有安装的包 pip list conda list
注意,这里博主的代码是YOLOV3算法的v9.6.0版本,假如git下载经常失败,也可以直接在【官方源码】直接下载。

YOLO系列的每个大版本算法都是有迭代优化的,不是每次迭代都是一个新的大版本,不要理解错了。
YOLOV3模型运行
数据集准备
-
数据集下载:人脸目标检测数据集WIDER_FACE_VOC2007.zip【百度云下载,提取码:u2b9 】,以下是下载的数据集格式:
WIDER_VOC2007└── Annotations 标签 ├── 000001.xml├── 000002.xml├── ...└── ImageSets├── Main| ├── train.txt 训练集| ├── val.txt 验证集└── JPEGImages 图片├── 000001.jpg├── 000002.jpg├── ... -
数据集格式转化:将原始标签的xml格式转化Ultralytics-YOLO的txt格式。
每幅图像对应一个txt文件,如果图像中没有检测对象则不需要txt文件。
每个对象占一行,每一行中包含的内容为:类别(class )、中心X坐标(x_center)、中心Y坐标(y_center)、图像宽度(width)和图像高度(height)。
中心坐标已经宽高都做了归一化处理,从0到 1;类别编号从0开始。


这里博主提供了转化的python代码,博主个人推荐在yolov3工程下新建datasetsTool目录,用于放置额外需要的辅助代码,将xml2txt.py代码放置到datasetsTool目录下。
# xml2txt.py代码 import os import xml.etree.ElementTree as ETdef parse_xml(xml_file):# 解析XML文件tree = ET.parse(xml_file)root = tree.getroot()# 获取图像尺寸size = root.find('size')width = int(size.find('width').text)height = int(size.find('height').text)# 初始化结果列表objects = []# 遍历所有的object标签for obj in root.findall('object'):name = obj.find('name').textdifficult = int(obj.find('difficult').text)# 只处理name为'face'且difficult为0的对象if name == 'face' and difficult == 0:bndbox = obj.find('bndbox')xmin = int(bndbox.find('xmin').text)ymin = int(bndbox.find('ymin').text)xmax = int(bndbox.find('xmax').text)ymax = int(bndbox.find('ymax').text)# 计算中心点坐标和宽高x_center = (xmin + xmax) / 2.0y_center = (ymin + ymax) / 2.0box_width = xmax - xminbox_height = ymax - ymin# 归一化处理x_center /= widthy_center /= heightbox_width /= widthbox_height /= height# 添加到结果列表objects.append((0, x_center, y_center, box_width, box_height))return objectsdef save_to_txt(objects, txt_file):with open(txt_file, 'w') as f:for obj in objects:line = ' '.join([str(x) for x in obj]) + '\n'f.write(line)def process_directory(input_directory, output_directory):# 确保输出目录存在if not os.path.exists(output_directory):os.makedirs(output_directory)# 遍历输入目录下的所有XML文件for filename in os.listdir(input_directory):if filename.endswith('.xml'):xml_file = os.path.join(input_directory, filename)txt_file = os.path.join(output_directory, filename.replace('.xml', '.txt'))# 解析XML并获取所需信息objects = parse_xml(xml_file)# 将结果保存到TXT文件save_to_txt(objects, txt_file)if __name__ == "__main__":input_directory = r'Annotations' # 替换为你的XML文件所在目录output_directory = r'labels' # 建议与Annotations在同一级'''eg:input_directory = r'E:\BaiduNetdiskDownload\WIDER_FACE_VOC2007\WIDER_VOC2007\Annotations'output_directory = r'E:\BaiduNetdiskDownload\WIDER_FACE_VOC2007\WIDER_VOC2007\labels' ''' process_directory(input_directory, output_directory) -
数据集组织结构:将原始数据划分成训练集和测试集,博主个人推荐在yolov3工程下新建datasets目录,用于放置所需的数据集,并新建人脸检测数据集facedetection,将train和val数据集放到facedetection目录下。
facedetection└── train├── images| ├── 000001.jpg| ├── 000002.jpg| ├── ...├── labels| ├── 000001.txt| ├── 000002.txt| ├── ...└── val├── images| ├── 000007.jpg| ├── 0000010.jpg| ├── ...├── labels| ├── 000007.txt| ├── 0000010.txt| ├── ...这里博主提供了转化的python代码,将split_train_val.py代码放置到datasetsTool目录下。
import os import shutil import randomimage_dir = r'JPEGImages' # 替换为你的图像文件所在目录 label_dir = r'labels' # 刚才生成的txt文件 ''' eg: image_dir = r'E:\BaiduNetdiskDownload\WIDER_FACE_VOC2007\WIDER_VOC2007\JPEGImages' label_dir = r'E:\BaiduNetdiskDownload\WIDER_FACE_VOC2007\WIDER_VOC2007\labels' ''' train_dir = r'datasets/facedetection/train' # 人脸数据集的存放位置 val_dir = r'datasets/facedetection/val' ''' eg: train_dir = r'E:\Ultralytics-YOLO\yolov3\r'datasets\facedetection\train' val_dir = r'E:\Ultralytics-YOLO\yolov3\r'datasets\facedetection\val' '''# 创建新的文件夹 os.makedirs(os.path.join(train_dir, 'images'), exist_ok=True) os.makedirs(os.path.join(train_dir, 'labels'), exist_ok=True) os.makedirs(os.path.join(val_dir, 'images'), exist_ok=True) os.makedirs(os.path.join(val_dir, 'labels'), exist_ok=True)# 获取所有图像文件名 image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]# 设置随机种子以保证结果可复现 random.seed(42)# 打乱文件列表 random.shuffle(image_files)# 计算训练集和验证集的数量 split_index = int(0.8 * len(image_files)) train_files = image_files[:split_index] val_files = image_files[split_index:]# 复制训练集文件 for file_name in train_files:image_path = os.path.join(image_dir, file_name)label_path = os.path.join(label_dir, os.path.splitext(file_name)[0] + '.txt')# 复制图像文件shutil.copy(image_path, os.path.join(train_dir, 'images', file_name))# 复制标签文件shutil.copy(label_path, os.path.join(train_dir, 'labels', os.path.splitext(file_name)[0] + '.txt'))# 复制验证集文件 for file_name in val_files:image_path = os.path.join(image_dir, file_name)label_path = os.path.join(label_dir, os.path.splitext(file_name)[0] + '.txt')# 复制图像文件shutil.copy(image_path, os.path.join(val_dir, 'images', file_name))# 复制标签文件shutil.copy(label_path, os.path.join(val_dir, 'labels', os.path.splitext(file_name)[0] + '.txt'))print("数据集划分完成") -
配置facedetection.yaml:博主根据data/coco128.yaml文件,在data目录下同样配置了人脸目标检测的数据集配置文件facedetection.yaml。
path: datasets/facedetection # 数据集路径 train: train/images # 训练集 val: val/images # 验证集 nc: 1 # 类别数量 names: ['face'] # 类别名:避免用中文 -
配置yolov3-face.yaml:博主根据models/yolov3.yaml文件,在models目录下同样配置了人脸目标检测的网络配置文件yolov3-face.yaml。
# 复制yolov3.yaml只需修改类别数量 nc: 1 # 类别数量
YOLOV3运行
运行yolov3,建议增加虚拟内存!!!!不然内存不足会导致很多错误!!!
模型训练
train.py配置训练参数:在有标注的者训练集进行模型的训练,并在验证集上评估。

常用参数含义
weights:指定预训练模型的权重文件;
cfg:存储模型结构的配置文件;
data:存储训练、测试数据的配置文件;
batch-size:一次训练的图片数量;
img:输入图片宽高,根据需求和硬件条件修改;
device:模型运行的设备,cuda 0,1,2,3或者cpu.
其他参数在后续讲解具体代码的过程中再去解释。
训练运行以下命令:
python train.py --img 640 --epochs 300 --data data/facedetection.yaml --batch-size 4 --weights yolov3.pt --cfg yolov3-face.yaml --device 0
weights 参数和 cfg 参数对应的模型有冲突,以 cfg 指定的模型为基准。

可能出现的问题:
1.问题:“_pickle.UnpicklingError: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.”

解决方式:

# 修改前
ckpt = torch.load(weights, map_location=device) # load checkpoint
# 修改后
ckpt = torch.load(weights, map_location=device,weights_only=False) # load checkpoint
2.问题“AttributeError: module ‘numpy’ has no attribute ‘int’.”

解决方式:将np.int替换成np.int64或者np.int32(推荐)
3.问题:“RuntimeError: result type Float can’t be cast to the desired output type __int64.”

解决方式:

# 修改前
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
# 修改后
gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
4.问题:“AttributeError: ‘FreeTypeFont’ object has no attribute ‘getsize.’”
解决方式:

# 修改前
w, h = self.font.getsize(label) # text width, height
w, h = self.font.getsize(text) # text width, height
# 修改后
w, h = self.font.getbbox(label)[2:4] # text width, height
w, h = self.font.getbbox(text)[2:4] # text width, height
模型验证
val.py参数验证配置:在有标注的者验证集上进行模型效果的评估模型好坏,目标检测中最常使用的评估指标为mAP。

常用参数含义
data:存储训练、测试数据的配置文件;
weights:指定训练好的模型权重文件;
batch-size:一次验证的图片数量;
img:输入图片宽高,根据需求和硬件条件修改;
device:模型运行的设备,cuda 0,1,2,3或者cpu;
augment:额外的数据增强.
其他参数在后续讲解具体代码的过程中再去解释。
验证运行以下命令:
python val.py --img 640 --data data/facedetection.yaml --batch-size 4 --weights runs/train/exp/weights/best.pt --device 0 --augment

这里博主随便找了一次训练过程中的中间训练权重进行演示,所以精度不是很高。
模型推理
detect.py配置推理参数:在没有标注的数据集上进行推理。
常用参数含义
weights:指定训练好的模型权重文件;
source:测试图片的保存路径;
device:模型运行的设备,cuda 0,1,2,3或者cpu;
–conf-thres:指定置信度阈值;
–iou-thres:非极大值抑制IoU 阈值;
其他参数在后续讲解具体代码的过程中再去解释。
推理运行以下命令:
python detect.py --weights runs/train/exp/weights/best.pt --source data/images --device 0 --conf-thres 0.7 --iou-thres 0.3

在runs/detect/exp获得输出:

导出onnx模型
export.py配置推理参数:

常用参数含义
weights:指定训练好的模型权重文件;
include:导出的模型类型;
其他参数在后续讲解具体代码的过程中再去解释。
导出运行以下命令:
python export.py --weights runs/train/exp/weights/best.pt --include onnx

总结
尽可能简单、详细的介绍了YOLOV3的安装流程以及YOLOV3的使用方法。后续会根据自己学到的知识结合个人理解讲解YOLOV3的原理和代码。
相关文章:
【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测
【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】Windows11下YOLOV3人脸检测前言YOLOV3模型运行环境搭建YOLOV3模型运行数据集准备YOLOV3运行模型训练模型验证模型推理导出onnx模型 总结…...
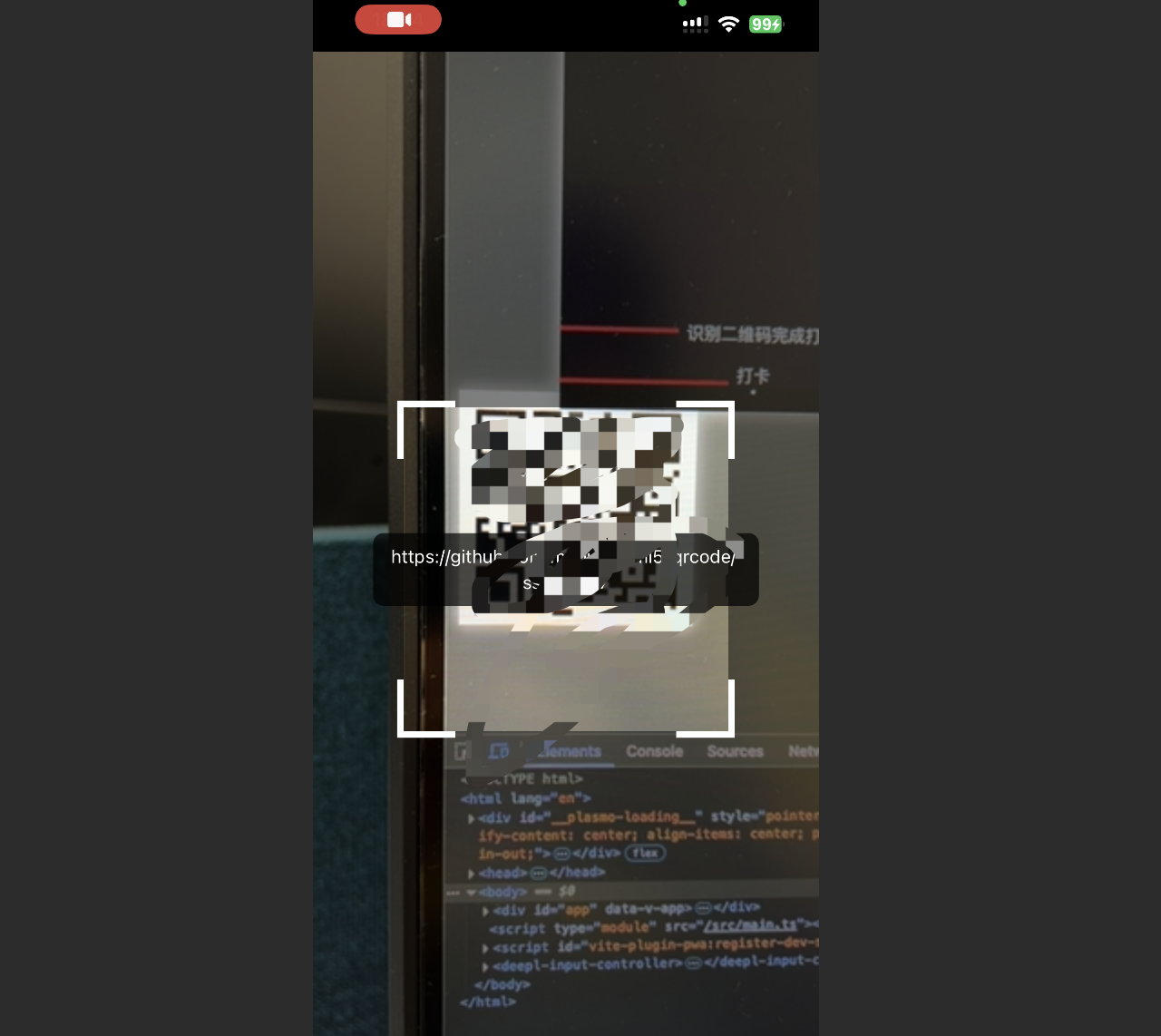
html5-qrcode前端打开摄像头扫描二维码功能
实现的效果如图所示,全屏打开并且扫描到二维码后弹窗提醒,主要就是使用html5-qrcode这个依赖库,html5-qrcode开源地址:GitHub - mebjas/html5-qrcode: A cross platform HTML5 QR code reader. See end to end implementation at:…...

ui_auto_study(持续更新)
通过where python来找到python解释器的安装目录 如果不适配,谷歌浏览器插件可以在这个地址下载对应的驱动 谷歌浏览器驱动下载地址 下载对应的驱动版本,替换原驱动 替换后,可以执行成功 div代表标签 .开头的代表类# 使用class定位元素 …...

从Oracle到腾讯TDSQL数据库升级技术分享
目录 一、腾讯TDSQL简介 1.强大的分布式能力 2.高度兼容性 3.高可用性与容错性 4.云原生特性 二、Java类应用主要出现的问题及解决方案 1.驱动问题 2.事务处理差异 3.存储过程与函数的适配 三、性能调优问题及方案 1.索引优化 2.查询缓存利用 3.参数调优 四、生产…...

【nodejs】爬虫路漫漫,关于nodejs的基操
一.下载安装nodejs 官网地址:Node.js — 在任何地方运行 JavaScript 二.下载安装vscode代码编辑器 官网地址:Download Visual Studio Code - Mac, Linux, Windows 三.修改本地脚本策略 1,windowsi 打开电脑设置 2,输入powersh…...

蓝桥杯C++基础算法-0-1背包
这段代码实现了一个经典的0-1 背包问题的动态规划解法。0-1 背包问题是指给定一组物品,每个物品有其体积和价值,要求在不超过背包容量的情况下,选择物品使得总价值最大。以下是代码的详细思路解析: 1. 问题背景 给定 n 个物品&am…...

常见中间件漏洞攻略-Jboss篇
一、CVE-2015-7501-Jboss JMXInvokerServlet 反序列化漏洞 第一步:开启靶场 第二步:访问该接口,发现直接下载,说明接⼝开放,此接⼝存在反序列化漏洞 http://47.103.81.25:8080/invoker/JMXInvokerServlet 第三步&…...

quartz.net条件执行
quartz.net条件执行 在使用Quartz.NET时,你可能需要基于某些条件来决定是否执行一个任务。Quartz.NET本身并不直接支持基于条件执行任务的功能,但你可以通过一些策略来实现这一需求。下面是一些方法来实现基于条件的任务执行: 1. 使用触发器…...

docker利用ollama +Open WebGUI在本地搭建部署一套Deepseek-r1模型
系统:没有限制,可以运行docker就行 磁盘空间:至少预留50GB; 内存:8GB docker版本:4.38.0 桌面版 下载ollama镜像 由于docker镜像地址,网络不太稳定,建议科学上网的一台服务器拉取ollama镜像&am…...

java TCP UDP 客户端访问例子和对比差异
Java TCP客户端示例 import java.io.*; import java.net.*;public class TCPClient {public static void main(String[] args) {try (Socket socket new Socket("localhost", 12345); // 连接服务端PrintWriter out new PrintWriter(socket.getOutputStream(), t…...

两个还算好用的ppt转word和PDF转word的python脚本
PPT转word: import re from pptx import Presentation from docx import Document from docx.shared import Inches from io import BytesIO from PIL import Imagedef clean_text(text):# 使用正则表达式删除控制字符和NULL字节return re.sub(r[\x00-\x1F\x7F], ,…...

opencascade 源码学习 XmlDrivers-XmlDrivers
OpenCASCADE 中的 XmlDrivers 是用于处理 XML 格式的 CAD 数据持久化模块,属于 OCAF(Open CASCADE Application Framework) 的一部分。它允许将 OCAF 文档(包含 CAD 数据、属性、关系等)序列化为 XML 文件,…...

Java-模块二-1
print和println print 和 println 是两种常用的输出方法,主要用于在控制台上打印信息。它们的行为因编程语言而异,但通常具有以下特点: Java中的print和println System.out.print():此方法用于打印输出内容到控制台,…...

k8s--集群内的pod调用集群外的服务
关于如何让同一个局域网内的Kubernetes服务的Pod访问同一局域网中的电脑上的服务。 可能的解决方案包括使用ClusterIP、NodePort、Headless Service、HostNetwork、ExternalIPs,或者直接使用Pod网络。每种方法都有不同的适用场景,需要逐一分析。 例如&…...

AI比人脑更强,因为被植入思维模型【20】卡尼曼双系统理论
定义 卡尼曼双系统理论思维模型是由诺贝尔经济学奖得主丹尼尔卡尼曼提出的,该理论认为人类的思维系统可以分为两个相互关联但又具有不同特点的子系统,即系统1(快思考)和系统2(慢思考)。系统1是基于直觉、经…...

ccfcsp3302相似度计算
//相似度计算 #include<iostream> #include<set>//不重复 #include<string> using namespace std; int main() {int n, m;cin >> n >> m;set<string>str1;set<string>str2;for(int i0;i<n;i){string s;cin>>s;for(int j0;…...

jEasyUI 创建 RSS 阅读器
jEasyUI 创建 RSS 阅读器 引言 随着互联网的快速发展,信息量呈爆炸式增长。为了方便用户快速获取所需信息,RSS 阅读器应运而生。jEasyUI 是一款流行的前端框架,具有丰富的组件和便捷的开发体验。本文将介绍如何使用 jEasyUI 创建一个功能齐…...

DeepSeek和Kimi在Neo4j中的表现
以下是2个最近爆火的人工智能工具, DeepSeek:DeepSeek Kimi: Kimi - 会推理解析,能深度思考的AI助手 1、提示词: 你能帮我生成一个知识图谱吗,等一下我会给你一篇文章,帮我从内容中提取关键要素,然后以N…...

【Java】TCP网络编程:从可靠传输到Socket实战
活动发起人小虚竹 想对你说: 这是一个以写作博客为目的的创作活动,旨在鼓励大学生博主们挖掘自己的创作潜能,展现自己的写作才华。如果你是一位热爱写作的、想要展现自己创作才华的小伙伴,那么,快来参加吧!…...

windows 平台编译openssl
文章目录 准备环境安装perl安装NASM获取源码 源码编译配置编译 准备环境 安装perl 下载Perl 5.40.0.1 Portable zip strawberryperl 解压后设置系统环境变量 测试安装是否成功 perl --versionThis is perl 5, version 40, subversion 0 (v5.40.0) built for MSWin32-x64-m…...

剑指小米特斯拉:秦L EV上市11.98万起
3月23日,比亚迪王朝网推出全新中级纯电轿车秦L EV,价格区间为11.98万-13.98万元,瞬间火爆市场。 依托e平台3.0 Evo技术赋能,秦L EV以“国潮设计、智能座舱、越级空间、高效安全、高阶智驾”五大核心优势,直击年轻用户痛…...
 函数的错误❌使用!!!)
避雷 :C语言中 scanf() 函数的错误❌使用!!!
1. 返回值说明 scanf函数会返回成功匹配并赋值的输入项个数,而不是返回输入的数据。 可以通过检查返回值数量来确认输入是否成功。若返回值与预期不符,就表明输入存在问题。 #include <stdio.h>int main() {int num;if (scanf("%d", …...

Godot读取json配置文件
概述 在Godot 4.3中读取JSON配置文件,可以通过以下步骤实现: 步骤说明 读取文件内容:使用FileAccess类打开并读取JSON文件。 解析JSON数据:使用JSON类解析读取到的文本内容。 错误处理:处理文件不存在或JSON格式错…...

Hadoop 3.x中的zookeeper和JournalNode的作用
在Hadoop 3.x版本中,ZooKeeper 和 JournalNode 的作用有所变化和增强,尤其是在HDFS高可用性(HA)架构和其他Hadoop组件的协作方面。下面是它们在Hadoop 3.x中的具体作用: ZooKeeper 继续在Hadoop 3.x中为集群提供协调服务,尤其是在HDFS的高可用性和YARN资源管理器的管理中…...

蓝桥杯高频考点——并查集(心血之作)
并查集 TA Can Do What & why learningwhatwhy 原理和结构路径压缩例题讲解题解solution 1(50分)solution 2(100分) 按秩(树高)合并按大小合并 TA Can Do What & why learning 从字面意思上来理解就是,合并&a…...

基于概率图模型的蛋白质功能预测
标题:基于概率图模型的蛋白质功能预测 内容:1.摘要 蛋白质功能预测在生物学研究中具有重要意义,能够帮助理解生命过程和疾病机制。本研究的目的是利用概率图模型进行蛋白质功能预测。方法上,收集了大量已知功能的蛋白质数据构建数据集,运用贝…...

Flutter 学习之旅 之 flutter 使用 connectivity_plus 进行网路状态监听(断网/网络恢复事件监听)
Flutter 学习之旅 之 flutter 使用 connectivity_plus 进行网路状态监听(断网/网络恢复事件监听) 目录 Flutter 学习之旅 之 flutter 使用 connectivity_plus 进行网路状态监听(断网/网络恢复事件监听) 一、简单介绍 二、conne…...

Redisson 分布式锁原理
加锁原理 # 如果锁不存在 if (redis.call(exists, KEYS[1]) 0) then# hash结构,锁名称为key,线程唯一标识为itemKey,itemValue为一个计数器。支持相同客户端线程可重入,每次加锁计数器1.redis.call(hincrby, KEYS[1], ARGV[2], 1);# 设置过期时间redis.call(pexpi…...

高频SQL50题 第四天 | 1251. 平均售价、620. 有趣的电影、1075. 项目员工 I、1633. 各赛事的用户注册率
知识点导览:日期大小比较;ifnull(字段,默认值)函数;取余操作;字符串比较like;逆序desc 1251. 平均售价 题目链接:https://leetcode.cn/problems/average-selling-price/description/?envTypest…...

【STM32】SPI通信外设硬件SPI读写W25Q64
SPI通信协议和W25Q64存储器芯片解读笔记: 【STM32】SPI通信协议&W25Q64Flash存储器芯片(学习笔记)-CSDN博客 SPI通信外设 SPI外设简介 STM32内部集成了硬件SPI收发电路,可以由硬件自动执行时钟生成、数据收发等功能&…...