零基础入门网络爬虫第5天:Scrapy框架
4周
Srapy爬虫框架
不是一个简单的函数功能库,而是一个爬虫框架
安装:pip install scrapy
检测:scrapy -h
Scrapy爬虫框架结构
爬虫框架
- 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合
- 爬虫框架是一个半成品,能够帮助用户实现网络爬虫
5+2结构

spiders:入口,用来像整个模块提供要访问的url链接,解析从网络中获得页面的内容
item pipelines:出口。负责对提取的信息进行后处理
engine,downloader,scheduler都是已有的功能实现
用户编写(配置):spiders item pipelines
Engine:不需要用户修改
- 控制所有模块之间的数据流
- 根据条件触发事件
Downloader:不需要用户修改
- 根据请求下载网页
Schedule:不需要用户修改
- 对所有的爬取请求进行调度管理
Downloader Middleware:用户可以编写配置代码
目的:实施Engine,Scheduler和Downloader之间进行用户可配置的控制
功能:修改,丢弃,新增请求或响应
如果用户不需要对request或response进行修改的时候,用户可以不更改这个中间件
Spider:需要用户编写配置代码
- 解析Downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的爬取请求(request)
Item Pipelines:需要用户编写配置代码
- 以流水线方式处理Spiders产生的爬取项
- 由一组操作顺序组成,类似流水线,每个操作是一个 Item Pipeline类型
- 可能操作包括:清理,检验和查重爬取项的HTML数据,将数据存储到数据库
Spider Middleware:用户可以编写配置代码
目的:对请求和爬取项的再处理
功能:修改,丢弃,新增请求或爬取项
requests库和Scrapy库的比较
相同点:
- 两者都可以进行网页 请求和爬取,python爬虫的两个重要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js,提交表单,应对验证码等功能(可扩展)
| requests | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高(基于异步结构设计) |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
非常小的需求:requests库
不太小的需求:Scrapy框架
定制程度很高的需求(不考虑规模),自搭框架,requests>Scrapy
Scrapy常用命令
Scrapy命令行:
Scrapy是为持续运行设计的专业爬虫框架,提供命令行
命令格式:


一个工程是一个最大的单元,一个工程相当于大的Scrapy框架内
演示
演示地址:http://python123.io/ws/demo.html
文件名称:demo.html
步骤1:建立一个Scrapy爬虫工程
scrapy startproject python123demo
生成的工程目录
python123demo/————>外层目录
scrapy.cfg—————>部署Scrapy爬虫的配置文件,将这样的爬虫放在特定的服务器上,并且在服务器配置好相关的操作接口。本机来讲,不需要改变部署的配置文件
python123demo/————>Scrapy框架的用户自定义python代码
init.py————>初始化脚本
items.py———>Items代码模板(继承类)
middlewares.py——>Middewares代码模板(继承类)
pipelines.py———>Pipelines代码模板 (继承类)
settings,py———>Scrapy爬虫的配置文件
spiders/————>Spiders代码模板目录(继承类)
__init__.py——>初始文件,无需修改
__pycache__/———>缓存目录,无需修改
步骤2:在工程中产生一个Scrapy爬虫
cd python123demo
scrapy genspider demo python123.io
生成了一个demo.py 和要爬取的网页信息
import scrapyclass DemoSpider(scrapy.Spider):name = "demo"allowed_domains = ["python123.io"]start_urls = ["https://python123.io"]def parse(self, response):pass
#pass()用于处理响应,解析内容形成字典,发现新的URL爬取请求
步骤3:配置产生的spider爬虫
步骤4:运行命令
scrapy crawl demo
import scrapyclass DemoSpider(scrapy.Spider):# 爬虫唯一标识符(运行爬虫时使用)name = "demo"# 允许爬取的域名(当前被注释)# allowed_domains = ["python123.io"]# 起始URL列表(自动生成请求)start_urls = ["https://python123.io/ws/demo.html"]def parse(self, response):""" 响应处理核心方法 """# 从URL提取文件名(取最后一段作为文件名)fname = response.url.split('/')[-1]# 二进制写入模式保存网页内容with open(fname, 'wb') as f:f.write(response.body) # response.body是原始字节数据self.log('Saved file %s.' % fname)# 应移除pass,可在此添加数据解析逻辑# 例如:生成后续请求或解析数据

yield关键字的使用
yield<——>生成器
- 生成器是一个不断产生值的函数
- 包含yield语句的函数是一个生成器
- 生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值。唤醒时它所使用的局部变量的值跟之前执行所使用的值是一致的


为什么要有生成器
- 生成器相比一次列出所有内容的优势
- 更节省存储空间
- 响应更迅速
- 使用更灵活

生成器所使用的元素空间仍然是一个

Scrapy爬虫的基本使用
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipline
步骤4:优化配置策略
Scrapy爬虫的数据类型
Request类
Response类
item类
Requests类
class scrapy.http.Request()
- request对象表示一个HTTP请求
- 由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,‘GET’“POST”等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求主体内容,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用(实际爬取内容没用) |
| .copy() | 复制该请求 |
Respone类
class scrapy.http.Response()
- Response对象表示一个HTTP响应
- 由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
|---|---|
| .url | response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline处理
- Item类似字典类型,可以按照字典类型操作
Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法,主要应用在spider模块内
- Beautiful Soup
- Ixml
- re
- XpathSelector
- CSS Selector
CSS Selector的基本使用

股票数据爬虫
步骤1:建立工程和Spider模板
步骤2:编写Spider
步骤3:编写ITEM Pipelines(对后期提取的数据进行处理)




# -*- coding: utf-8 -*-
import scrapy
import reclass StocksSpider(scrapy.Spider):name = "stocks" # <mcsymbol name="StocksSpider" filename="stocks_spider.py" path="d:\javaexperiment\experiment0\test\stocks_spider.py" startline="5" type="class">爬虫唯一标识符</mcsymbol>start_urls = ['http://quote.eastmoney.com/stocklist.html'] # 起始页面(股票列表页)def parse(self, response):""" 解析股票列表页 """for href in response.css('a::attr(href)').extract(): # 提取所有链接try:stock = re.findall(r"[s][hz]\d{6}", href)[0] # 正则匹配股票代码url = f'https://gupiao.baidu.com/stock/{stock}.html' # 构造详情页URLyield scrapy.Request(url, callback=self.parse_stock) # 生成新请求except:continue # 跳过无效链接def parse_stock(self, response):""" 解析个股详情页 """infoDict = {}stockInfo = response.css('.stock-bets') # 定位信息容器# 提取股票名称(含复杂处理)name = stockInfo.css('.bets-name').extract()[0]company = re.findall(r'\s.*\(', name)[0].split()[0]code = re.findall(r'\>.*\<', name)[0][1:-1]# 提取键值对信息keys = [re.sub(r'<.*?>', '', k) for k in stockInfo.css('dt').extract()]values = [re.sub(r'<.*?>', '', v) for v in stockInfo.css('dd').extract()]# 构建数据字典for k, v in zip(keys, values):infoDict[k] = v if re.search(r'\d', v) else '--'infoDict['股票名称'] = f"{company}{code}"yield infoDict
graph TD
A[启动爬虫] --> B(访问股票列表页)
B --> C{遍历所有链接}
C -->|匹配股票代码| D[构造详情页URL]
C -->|不匹配| E[跳过]
D --> F(请求详情页)
F --> G[解析股票数据]
G --> H[生成结构化数据]
# -*- coding: utf-8 -*-class BaidustocksPipeline(object):def process_item(self, item, spider):# 基础管道(未实现具体功能)return item # 必须返回item对象以传递到后续管道class BaidustocksInfoPipeline(object):def open_spider(self, spider):"""爬虫启动时执行"""self.f = open('BaiduStockInfo.txt', 'w') # 创建/覆盖写入文件def close_spider(self, spider):"""爬虫关闭时执行"""self.f.close() # 必须关闭文件def process_item(self, item, spider):"""处理每个item的回调"""try:line = str(dict(item)) + '\n' # 将item转为字典格式字符串self.f.write(line) # 写入文本文件except Exception as e: # 应指定具体异常类型spider.logger.error(f"写入失败: {str(e)}") # 建议添加日志return item # 保持item传递链
graph LR
A[爬虫产生Item] --> B[Item经过BaidustocksPipeline]
B --> C[Item经过BaidustocksInfoPipeline]
C --> D[数据写入BaiduStockInfo.txt]
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
相关文章:
零基础入门网络爬虫第5天:Scrapy框架
4周 Srapy爬虫框架 不是一个简单的函数功能库,而是一个爬虫框架 安装:pip install scrapy 检测:scrapy -h Scrapy爬虫框架结构 爬虫框架 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合爬虫框架是一个半成品,能够帮助…...
)
ARCGIS PRO DSK 栅格数据(Raster)
ArcGIS Pro 中与栅格相关的功能可以在两个单独程序集中的两个命名空间中找到。 1、ArcGIS.Core.dll 中的 ArcGIS.Core.Data.Raster 命名空间提供了栅格类和成员,用于处理栅格数据集、内存栅格、像素块和光标。 2、ArcGIS.Desktop.Mapping.dll 中的 ArcGIS.Desktop.M…...

C#设计模式快速回顾
知识点来源:人间自有韬哥在,豆包 目录 一、七大原则1. 单一职责原则 (Single Responsibility Principle)2. 开放封闭原则 (Open-Closed Principle)3. 里氏替换原则 (Liskov Substitution Principle)4. 接口隔离原则 (Interface Segregation Principle)5…...

分页查询互动问题(用户端)
文章目录 概要整体架构流程技术细节小结 概要 需求分析以及接口设计 技术细节 1.Controller层 GetMapping("/page")ApiOperation("分页查询问题")public PageDTO<QuestionVO> queryQuestionPage(QuestionPageQuery query){return questionService…...

【全队项目】智能学术海报生成系统PosterGenius(项目介绍)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏:🏀大模型实战训练营_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前…...

P5356 [Ynoi Easy Round 2017] 由乃打扑克 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 个操作分两种: add ( l , r , x ) \operatorname{add}(l,r,x) add(l,r,x):对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r] 执行 …...

【线程安全问题的原因和方法】【java形式】【图片详解】
在本章节中采用实例图片的方式,以一个学习者的姿态进行描述问题解决问题,更加清晰明了,以及过程中会发问的问题都会一一进行呈现 目录 线程安全演示线程不安全情况图片解释: 将上述代码进行修改【从并行转化成穿行的方式】不会出…...

MySQL-----视图与索引
目录 视图 1.视图 2.操作 11.索引 1.定义 2.优缺点: 3.分类 4.索引的设计原则 5.索引的使用 作业 视图 1.视图 ❓如果需要在原表中隐藏部分字段时,怎么办? 视图 📖视图: 是一个没有存储任何数据的表,可以对其CRUD视图…...

【差分隐私相关概念】约束下的列联表边缘分布计算方法
列联表及其边缘分布的详细解释 一、列联表的定义 列联表(Contingency Table) 是一种用于表示 多个分类变量联合分布 的表格。其核心是通过多维数组记录不同属性组合的频次。以下是关键点: 分类属性: 设有 k k k 个分类属性 A …...

解决IDEA中maven找不到依赖项的问题
直接去官网找到对应的依赖项jar包,并且下载到本地,然后安装到本地厂库中。 Maven官网:https://mvnrepository.com/ 一、使用mvn install:install-file命令 Maven提供了install:install-file插件,用于手动将jar包安装到本地仓库…...

pyside6的QGraphicsView体系,当鼠标位于不同的物体,显示不同的右键菜单
代码: # 设置样本图片的QGraphicsView模型 from PySide6.QtCore import Qt, QRectF, QObject from PySide6.QtGui import QPainter, QPen, QColor, QAction, QMouseEvent from PySide6.QtWidgets import QGraphicsView, QGraphicsScene, QGraphicsPixmapItem, QGra…...

Python自动化测试 之 DrissionPage 的下载、安装、基本使用详解
Python自动化测试 之 DrissionPage 使用详解 🏡前言:一、☀️DrissionPage的基本概述二、 🗺️环境安装2.1 ✅️️运行环境2.2 ✅️️一键安装 三、🗺️快速入门3.1 页面类🛰️ChromiumPage🛫 SessionPage&…...

Java替换jar包中class文件
在更新java应用版本的运维工作中,由于一些原因,开发没办法给到完整的jar包,这个时候,就可以只将修改后的某个Java类的class文件替换掉原来iar包中的class文件,重新启动服务即可: 1、将jar包和将要替换的cl…...

unix网络编程
unix网络编程 AI出来以后,软件不可能找到工作的,就算找到了也在走下坡路。再过几年,机器人发展起来,连流水线都找不到。人为什么整体不值钱,每个部位却很值钱。你说我初中辍学就去开直播结局会不会比现在好。 更新in…...
)
常考计算机操作系统面试习题(一下)
目录 操作系统基本类型 操作系统的功能 操作系统的主要任务 进程与线程 进程状态转变 内存管理 文件系统与文件管理 虚拟存储器 设备管理 磁盘调度 死锁 信号量机制 文件打开与管理 进程与线程的互斥与同步 进程同步 进程调度 文件分配磁盘块的方法 程序执行…...

2025_0321_生活记录
刚刚写完待会儿早上要汇报的文档,看了一眼时间,现在已经是凌晨2点多了。一直说要早睡,但是一直都没做到。。。算了,不苛求自己了。 昨天是春分,春分秋分,昼夜平分。不知不觉就到春天了,但房间里…...
)
三层网络 (服务器1 和 服务器2 在不同网段)
服务器1 和 服务器2 在不同网段,并且通过三层交换机实现通信 1. 网络拓扑 假设网络拓扑如下: 服务器1: mac0:IP 地址 192.168.1.10/24,网关 192.168.1.1 mac1:IP 地址 10.0.1.10/24,网关 10.0…...

AI Tokenization
AI Tokenization 人工智能分词初步了解 类似现在这个,一格子 一格子,拼接出来的,一行或者一句,像不像,我们人类思考的时候组装出来的话,并用嘴说出来了呢。...

关于大数据的基础知识(四)——大数据的意义与趋势
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于大数据的基础知识(四&a…...

某视频的解密下载
下面讲一下怎么爬取视频,这个还是比小白的稍微有一点绕的 首先打开网址:aHR0cDovL3d3dy5wZWFydmlkZW8uY29tL3BvcHVsYXJfNA 首页 看一下: 有一个标题和一个href,href只是一个片段,待会肯定要拼接, 先找一…...
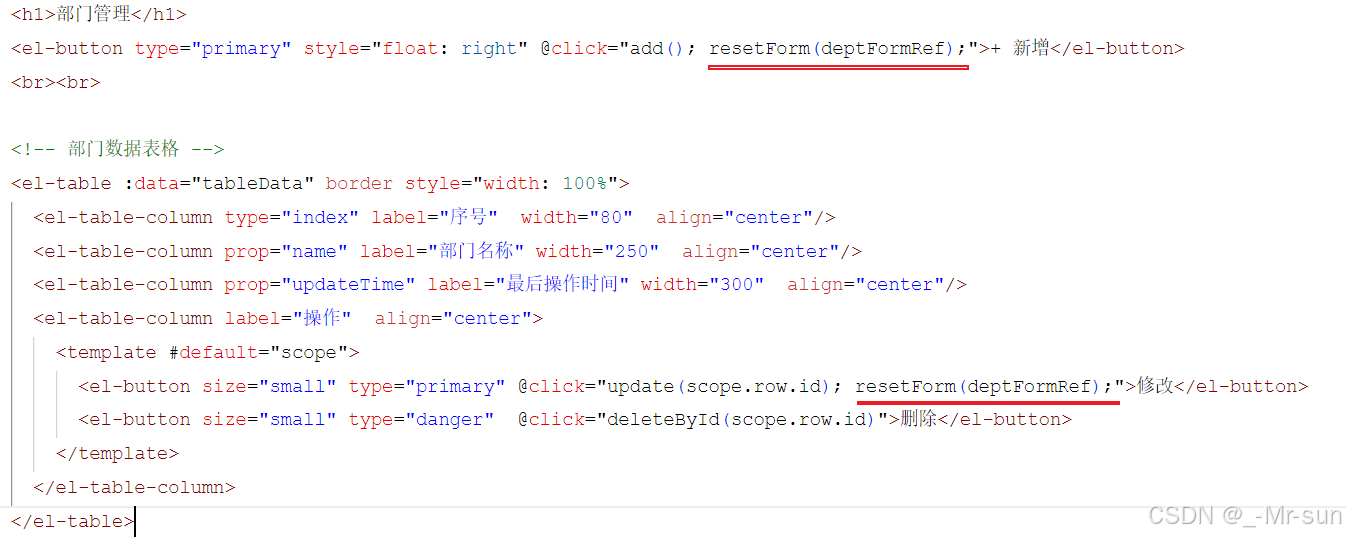
Day20-前端Web案例——部门管理
目录 部门管理1. 前后端分离开发2. 准备工作2.1 创建Vue项目2.2 安装依赖2.3 精简项目 3. 页面布局3.1 介绍3.2 整体布局3.3 左侧菜单 4. Vue Router4.1 介绍4.2 入门4.3 案例4.4 首页制作 5. 部门管理5.1部门列表5.1.1. 基本布局5.1.2 加载数据5.1.3 程序优化 5.2 新增部门5.3…...

从切图仔到鸿蒙开发01-文本样式
从切图仔到鸿蒙开发01-文本样式 本系列教程适合 HarmonyOS 初学者,为那些熟悉用 HTML 与 CSS 语法的 Web 前端开发者准备的。 本系列教程会将 HTML/CSS 代码片段替换为等价的 HarmonyOS/ArkUI 代码。 页面结构 HTML 与 ArkUI 在 Web 开发中,HTML 文档结…...

菱形虚拟继承的原理
一 :菱形继承的问题 普通的菱形继承存在数据冗余和二义性的问题 ,如下代码: class Person { public:string _name; //姓名 };class Student : public Person { protected:int _num; //学号 };class Teacher : public Person { protected:int…...

【数据结构】C语言实现树和森林的遍历
C语言实现树和森林的遍历 导读一、树的遍历二、森林的遍历2.1 为什么森林没有后序遍历?2.2 森林中存不存在层序遍历?三、C语言实现3.1 准备工作3.2 数据结构的选择3.3 树与森林的创建3.4 树与森林的遍历3.4.1 先根遍历3.4.2 后根遍历3.4.3 森林的遍历3.5 树与森林的销毁3.6 算…...

第四天 开始Unity Shader的学习之旅之Unity中的基础光照
Unity Shader的学习笔记 第四天 开始Unity Shader的学习之旅之Unity中的基础光照 文章目录 Unity Shader的学习笔记前言一、我们是如何看到这个世界的1. 光源2.吸收和散射3.着色 二、标准光照模型1. 自发光2. 高光反射① Phong模型② Blinn-Phong模型 3.漫反射4.环境光 总结 前…...

基于SpringBoot的“社区居民诊疗健康管理系统”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“社区居民诊疗健康管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统模块功能结构图 局部E-R图 系统首…...

React Native集成到现有原生Android应用
使用React Native(以下简称RN)从头开始制作一个新的应用会是一个非常好的选择。但如果只想给现有的原生应用中添加一两个视图或是业务流程,RN也同样不在话下。只需简单几步,就可以给原有应用加上新的基于RN的特性、画面和视图等。 一、核心概念 把 React Native 组件集成…...

Java-空链基础入门
经过调研和细致观察,我们发现空链对于初次接触或是对Stream和Optional不太熟悉的人来说,确实存在一定的上手难度,宛如开启了“地狱模式”。为了降低这一门槛,我们决定通过一系列由简入深的案例演示,来逐步引导大家掌握…...

【江协科技STM32】Unix时间戳BKP备份寄存器RTC实时时钟(学习笔记)
Unix时间戳 Unix 时间戳(Unix Timestamp)定义为从UTC/GMT的1970年1月1日0时0分0秒开始所经过的秒数,不考虑闰秒时间戳存储在一个秒计数器中,秒计数器为32位/64位的整型变量世界上所有时区的秒计数器相同,不同时区通过…...

PCDN网络设备
PCDN(Peer-to-Peer Content Delivery Network,点对点内容分发网络)是一种基于P2P技术的内容分发网络。它利用用户终端设备之间的直接数据传输来减少中心服务器的压力,并提高内容交付的速度和效率。 PCDN的工作原理 节点共享&…...