多模态大模型训练范式演进与前瞻
本文从多模态大模型相关概念出发,并以Flamingo 模型为例,探讨了基于多模态大模型训练的演进与前瞻。新一代训练范式包括统一架构、数据工程革新和动态适应机制,以提升跨模态推理能力和长视频理解。
多模态大模型
定义
什么是多模态大模型?
模态(Modality):指数据的一种类型或形式,如文本、图像、音频等。例如,图像是视觉模态,文本是语言模态。
多模态(Multimodal):涉及两种或更多不同信号类型的模态。例如,多模态研究可能探讨文本和图像的结合使用。
多模态模型(Multimodal Model):能处理和整合多种模态数据的AI模型。例如,模型能同时理解和生成文本描述的图像。
多模态系统(Multimodal System):能处理多种模态输入和输出的系统。例如,智能助手既能解析语音指令(音频输入)也能以文字回复(文本输出);ChatGPT增加了视觉问答;微信既可以纯文字聊天,又可以语音转文字,文字转语音,还集成了识别图像中文字的功能。
多模态大模型(Multimodal Large Language Models, MLLMs):将额外的模态融入大语言模型(LLMs),也就是将大语言模型扩展到多种数据类型,例如,OpenAI的GPT-4、微软的Kosmos-1和谷歌的PaLM-E都是近年来由科技巨头公司构建的多模态大模型示例。
多模态大模型 vs 多模态模型?
主要在于它们的规模和能力。多模态大模型利用大语言模型作为基础,具有处理和理解多种模态(如文本、图像等)数据的能力,可以实现先进的、跨模态的任务处理能力。而多模态模型可能指的是更广泛的概念,包括任何能够处理多种类型模态数据的模型,无论其规模大小。比如有些文生图模型,也是属于多模态模型,但并没有集成语言模型的组件,不能称之为多模态大模型。
多模态大模型的训练方式
传统方法
传统的训练方法主要是通过Seq2Seq,例如Image Caption,主要采用End-to-End训练方式。
具体实现逻辑可以概括为:
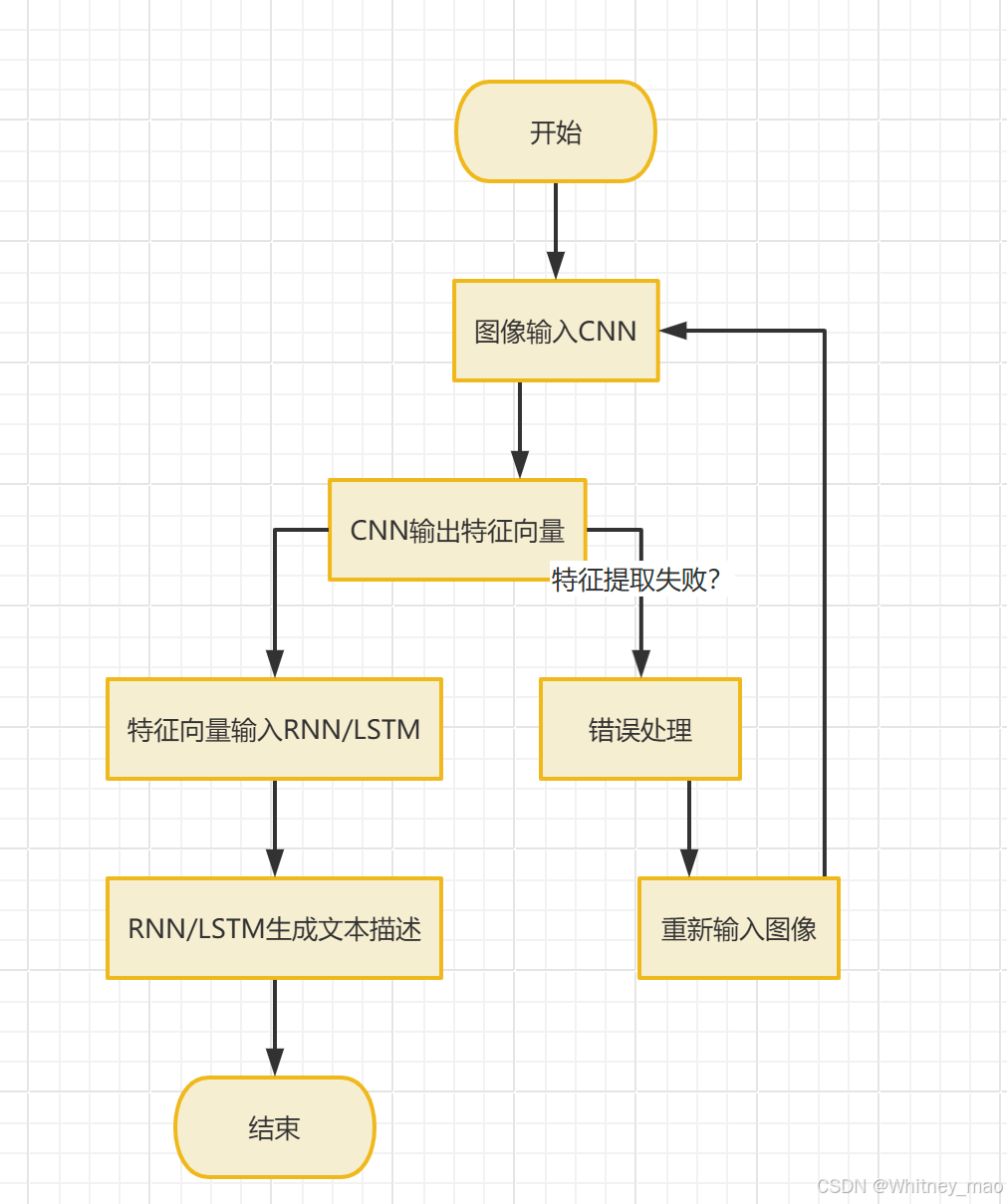
训练数据<Image1, Des1>,<Image2, Des2>,…,<Image n, Des n>
早期的训练项目示例:flamingo
Flamingo 模型是视觉语言模型(VLM)的一个代表性模型,核心目标是通过融合视觉和文本信息实现更接近人类认知的跨模态推理能力,其核心创新与应用价值延续至今。
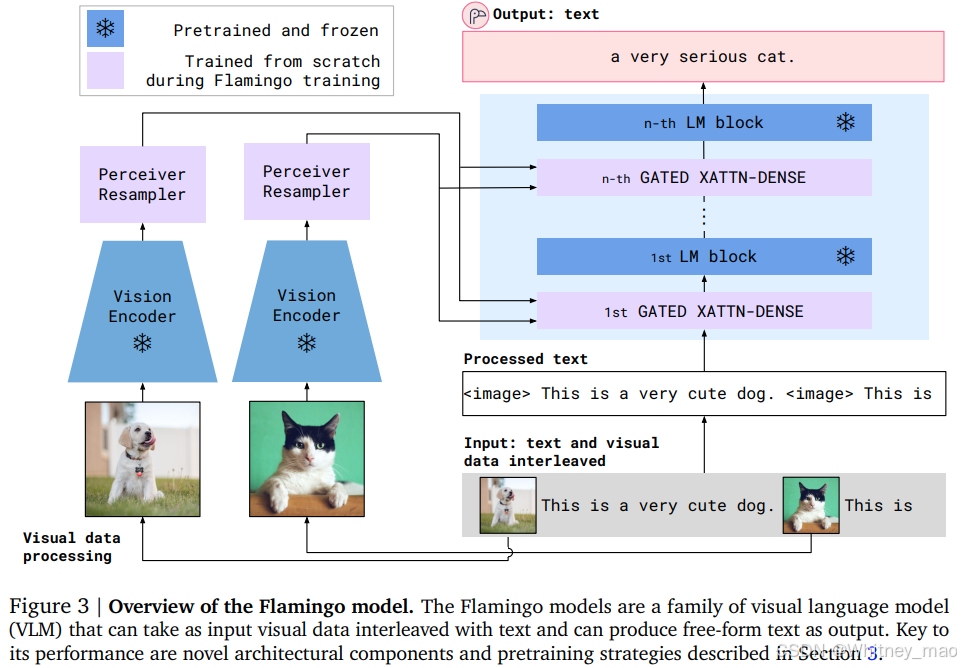
1. 架构设计的范式突破
- 双流异构编码器
视觉分支采用改进的 NFNet(Normalizer-Free ResNet)作为骨干网络,通过消除批量归一化层降低训练内存消耗;文本分支则基于稀疏激活的 Chinchilla 模型(700 亿参数),通过参数复用提升计算效率。两模态的异构设计体现了硬件约束下的工程优化智慧。 - Perceiver 重采样机制
针对视觉特征与语言模型维度不匹配问题,引入 Perceiver Resampler 模块:- 使用可学习的 latent query 对图像块特征进行交叉注意力聚合
- 输出固定长度的视觉 token 序列(如 64 tokens)
- 该机制使模型可处理任意分辨率的输入图像,显著提升泛化能力
- 门控交叉注意力(Gated XATTN-DENSE)
在语言模型每层插入可学习的门控单元,动态调节视觉信号对文本生成的贡献度。数学表达为:
h’ = h + σ(α) * Attn(h, V)
其中, α 为可学习门控参数,σ 为 sigmoid 函数,实现了模态融合的软切换。
2. 训练范式的创新
-
交错序列建模
输入序列形式如 [图像_1, 文本_1, 图像_2, 文本_2, …],模型需要建立跨模态的因果依赖关系。通过掩码矩阵控制注意力范围,确保每个位置的预测仅依赖历史信息。 -
混合训练策略
- 预训练阶段:使用 43M 图文对(ALT-400M 数据集)进行跨模态对齐
- 微调阶段:在 1.5M 交错多模态序列(网页抓取数据)上优化上下文学习能力
- 采用梯度累积和模型并行解决显存瓶颈
-
稀疏激活技术
语言模型部分采用条件计算(Conditional Computation),仅激活约 20%的神经元处理视觉信号,在保持模型容量的同时显著降低计算开销。
3. 小结
Flamingo 的技术路线揭示了多模态智能的演进方向:通过架构创新实现模态深度融合,利用大规模预训练捕获跨模态关联,最终在少样本场景下展现类人的推理能力。Flamingo 模型通过多模态预训练和架构创新,已显著缓解了传统单任务训练模式下的数据依赖和计算效率问题,但仍会面临几个核心问题:
- 传统单任务训练需为每个 Image Caption 任务独立建模,本质上是未建立跨任务的共享表征空间。Flamingo 的解决方案已部分突破该限制,但仍需通过微调适配下游任务。
- 传统监督学习需为每个任务收集大规模标注数据(如 COCO Caption 需 12 万人工标注图文对),成本高昂且不可持续。
更有“潜力”的训练方法
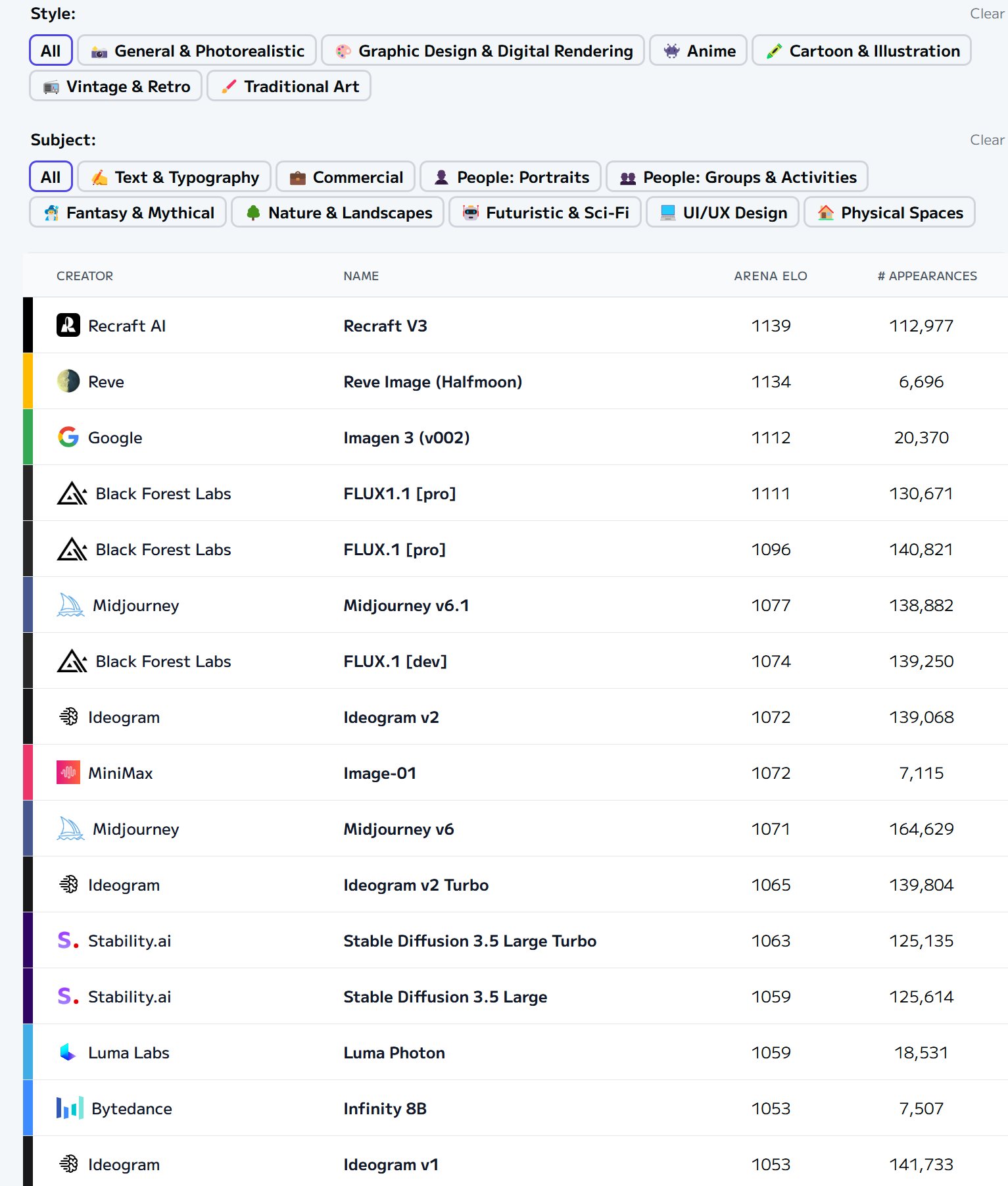
多模态大模型的训练方式正在经历从传统架构向新型范式的演进,不同专业领域构建基础模型(Foundation Model)的核心价值在于将通用智能的泛化能力与领域知识的深度理解相结合,从而在特定场景下实现超越通用模型的性能与效率。首先,先了解一下当前人工智能产品竞技评测结果:
- Image领域:
- Video Arena:
Text to Video:
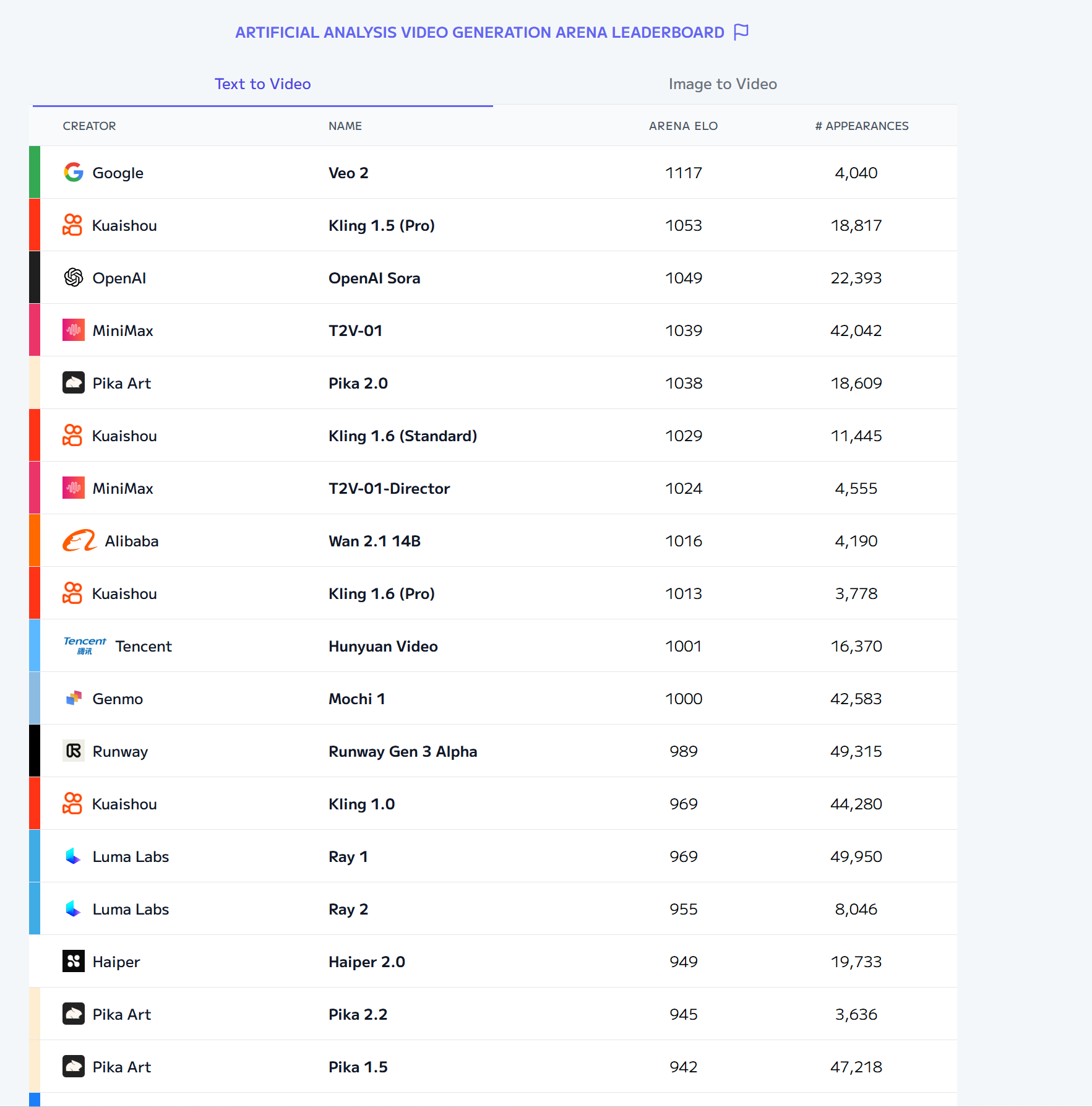
Image to Video:
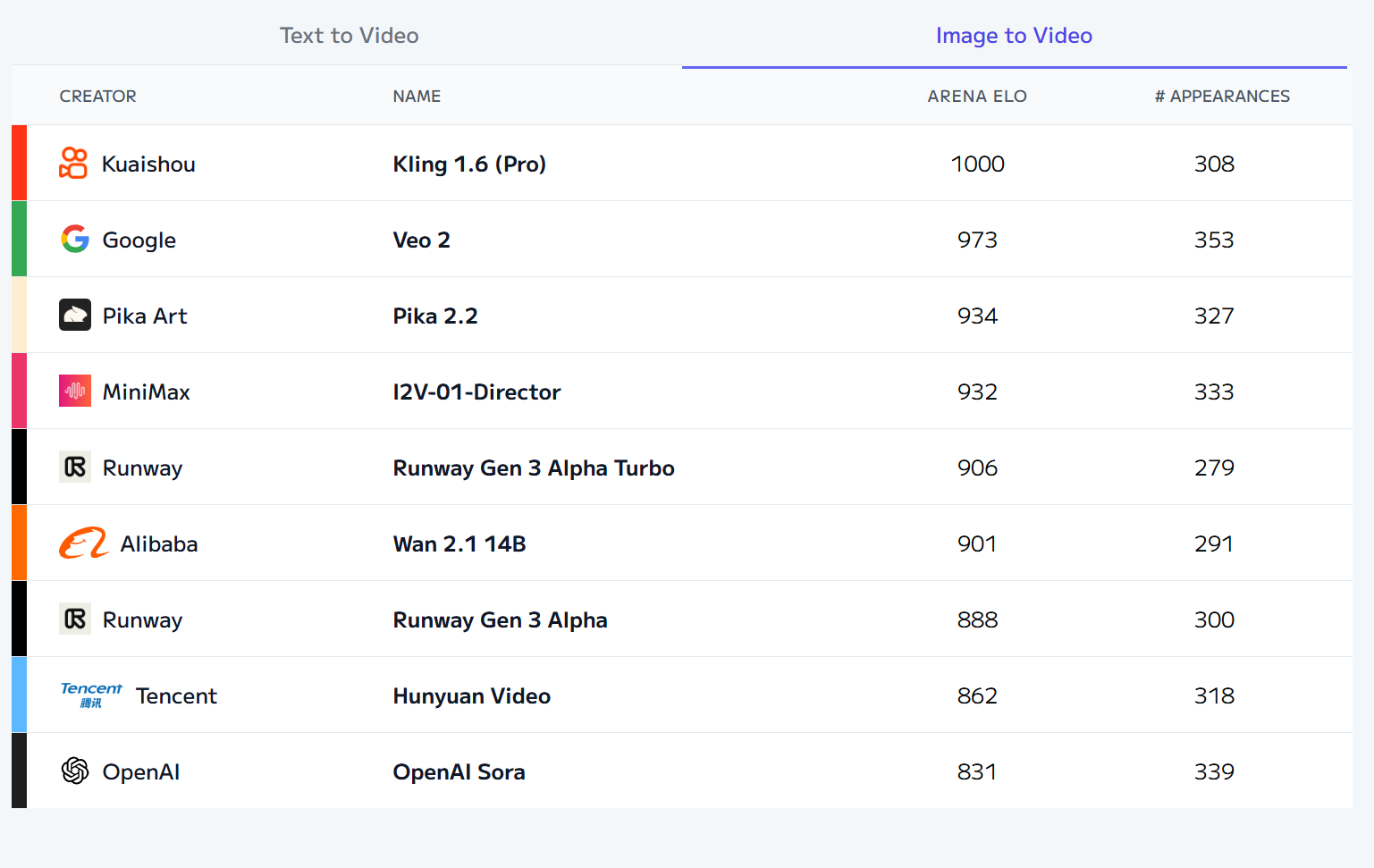
- Speech

通过逆向工程分析产品功能,解析底层模型架构,初步假设更具潜力的方法侧重于统一架构、数据效率和动态适应三个维度。
统一架构(模态建模):打破模态壁垒
(1)全模态 Transformer
核心思想:将图像、视频、音频、文本统一映射为离散 token(如 ViT 处理图像为 16x16 的 patch token,音频转为频谱图 token),共享同一 Transformer 架构进行编码和解码。
- 优势:
- 模态无关性:新增模态仅需扩展 tokenizer,无需修改模型结构
- 跨模态注意力:通过自注意力机制自动捕获模态间关联
- 框架:
- 采用共享自注意力机制的通用编码器(如CoCa)
- 模态无关的位置编码设计
- 动态路由机制实现跨模态特征选择
- 参数高效化设计
- 混合专家系统(MoE)实现模态专属处理
- 可插拔适配器模块(Adapter)实现零样本迁移
- 参数冻结下的提示学习(Prompt Tuning)
(2)符号-神经混合架构
- 神经网络提取原始特征
- 符号引擎
数据效率:从「标注依赖」到「自进化」
- 生成式预训练
(1)技术路径:
跨模态扩散:如 Stability AI 的 Stable Diffusion XL,联合优化图像生成与文本理解
自回归生成:如 OpenAI DALL·E 3,通过文本→图像→文本循环生成,自动扩充训练数据
(2)数据合成公式:
\mathcal{D}{syn} = { (x_i, y_i) | x_i = G{\text{text→image}}(z_i), y_i = G_{\text{image→text}}(x_i) }
其中生成器 G 与判别器 D 交替优化,形成数据自增强闭环。
- 世界模型驱动训练
原理:构建虚拟环境(如 Unity 模拟器),让模型在合成场景中主动探索:- 视觉:渲染多视角图像流
- 语言:自动生成场景描述问答对
- 物理:通过刚体动力学引擎生成因果事件链
动态适应(动态计算网络):让模型「按需思考」
-
条件计算
- MoE(Mixture of Experts):如 Google V-MoE,每个图像 patch 动态路由至不同专家网络
- 早退机制(Early Exit):对简单样本在浅层输出结果,复杂样本深入计算。
-
动态提示引擎
- Prompt 工厂:根据输入内容自动生成适配的 prompt 模板;
- 可微分提示:将离散 prompt 替换为连续向量(如 P-tuning v2)
-
动态知识检索增强
基于领域知识图谱的深度融合,模型推理时实时检索领域知识库。
未来多模态训练的核心范式将转向生成即训练、推理即优化、交互即标注的自我进化模式,最终实现人类水平的跨模态情境理解与因果推理能力。后续将基于具体产品以及应用剖析多模态大模型的技术实现。
相关文章:
多模态大模型训练范式演进与前瞻
本文从多模态大模型相关概念出发,并以Flamingo 模型为例,探讨了基于多模态大模型训练的演进与前瞻。新一代训练范式包括统一架构、数据工程革新和动态适应机制,以提升跨模态推理能力和长视频理解。 多模态大模型 定义 什么是多模态大模型&…...

游戏引擎学习第187天
看起来观众解决了上次的bug 昨天遇到了一个相对困难的bug,可以说它相当棘手。刚开始的时候,没有立刻想到什么合适的解决办法,所以今天得从头开始,逐步验证之前的假设,收集足够的信息,逐一排查可能的原因&a…...

HarmonyOS NEXT 关于鸿蒙的一多开发(一次开发,多端部署) 1+8+N
官方定义 定义:一套代码工程,一次开发上架,多端按需部署。 目标:支撑开发者快速高效的开发支持多种终端设备形态的应用,实现对不同设备兼容的同时,提供跨设备的流转、迁移和协同的分布式体验。 什么是18…...

SAP-ABAP:OData 协议深度解析:架构、实践与最佳应用
OData 协议深度解析:架构、实践与最佳应用 一、协议基础与核心特性 协议定义与目标 定位:基于REST的开放数据协议,标准化数据访问接口,由OASIS组织维护,最新版本为OData v4.01。设计哲学:通过统一资源标识符(URI)和HTTP方法抽象数据操作,降低异构系统集成复杂度。核心…...

当Kafka化身抽水马桶:论组件并发提升与系统可用性的量子纠缠关系
《当Kafka化身抽水马桶:论组件并发提升与系统可用性的量子纠缠关系》 引言:一场OOM引发的血案 某个月黑风高的夜晚,监控系统突然发出刺耳的警报——我们的数据发现流水线集体扑街。事后复盘发现:Kafka集群、Gateway、Discovery服…...

Dify+ollama+vanna 实现text2sql 智能数据分析 -01
新鲜出炉-今天安装vanna踩过的坑 今天的任务是安装vanna这个工具,因为dify中自己写的查询向量数据库和执行sql这两步太慢了大概要20S,所以想用下这个工具,看是否会快一点。后面会把这个vanna封装成一个工具让dify调用。 环境说明 我是在本…...

【Python实用技巧】OS模块详解:文件与目录操作的瑞士军刀
大家好,我是唐叔!今天咱们来聊聊Python中那个被低估的"老黄牛"——os模块。这个模块看似简单,但却是每个Python开发者都绕不开的利器。就像我常说的:“不会用os模块的Python程序员,就像不会用筷子的美食家”…...

动态内存分配与内存对齐
在C语言及其他低级编程语言中,内存管理是一个至关重要的主题。动态内存分配和内存对齐是确保程序高效和稳定运行的关键因素。本文将深入探讨动态内存分配的原理,内存对齐的概念,并解释它们如何共同影响程序的性能和资源利用。 一、动态内存分配简介 1.1 动态内存分配的概念…...

C 标准库 – 头文件
1️⃣ <fenv.h> 简介 <fenv.h> 提供了用于控制和检查浮点运算行为的宏和函数。它为浮点环境提供了精细的控制,允许设置舍入模式、捕获浮点异常等。通过 <fenv.h>,程序员可以: 控制浮点舍入模式,指定不同的舍入…...

Redis的基础,经典,高级问题解答篇
目录 一,基础 二,经典 缓存雪崩: 1. Redis事务的原子性 2. 与MySQL事务的区别 1. 主从复制原理 2. 哨兵模式故障转移流程 3. 客户端感知故障转移 三,高级 一,基础 Redis的5种基础数据类型及使用场景…...

uniapp uni-swipe-action滑动内容排版改造
在uniapp开发中 默认的uni-swipe-action滑动组件 按钮里的文字都是横排的 不能换行的 如果是在一些小屏设备 比如PDA这种,同时按钮文字又都是4个字 多按钮的情况 就会发现滑动一下都直接满屏了 观看体验都不好 但默认的官方组件又没有样式的设置,下面就告…...

电脑卡怎么办?提升电脑流畅的方法
电脑已经成为我们工作、学习和娱乐不可或缺的伙伴。然而,随着使用时间的增长,许多用户会遇到电脑运行变慢、卡顿的情况,这不仅影响了工作效率,也大大降低了使用体验。本文将为大家分析电脑卡顿的常见原因,并提供一套实…...

SpringBoot报错解决方案
org.apache.tomcat.util.http.fileupload.impl.SizeLimitExceededException: the request was rejected because its size (31297934) exceeds the configured maximum (10485760) 文件上传大小超过限制...
)
知识表示方法之二:产生式表示法(Production System)
有关知识表示方法之一:一阶谓词逻辑的内容可以看我的文章:https://blog.csdn.net/lzm12278828/article/details/146541478 一、定义 “产生式”这一术语是有美国数学家博斯特(E.Post)在1943年首先提出来的,他根据串替代规则提出了一种称为波斯特机的计算模型,模型中的每…...

SQL Server中账号权限
目录标题 查看现有权限授予权限拒绝权限撤销权限角色管理 在SQL Server中管理账号权限主要通过以下几个关键步骤: 查看现有权限 可以使用系统视图来查看账号的权限,比如 sys.database_permissions 视图,示例查询如下: SELECT d…...

软件需求未明确非功能性指标(如并发量)的后果
软件需求未明确非功能性指标(如并发量)可能带来的严重后果包括:系统性能下降、用户体验恶化、稳定性降低、安全风险增加、后期维护成本高企。其中,系统性能下降尤为显著。当软件系统在设计和开发阶段未明确并发量需求时࿰…...

VScode-i18n-ally-Vue
参考这篇文章,做Vue项目的国际化配置,本篇文章主要解释,下载了i18n之后,该如何对Vscode进行配置 https://juejin.cn/post/7271964525998309428 i18n Ally全局配置项 Vscode中安装i18n Ally插件,并设置其配置项&#…...
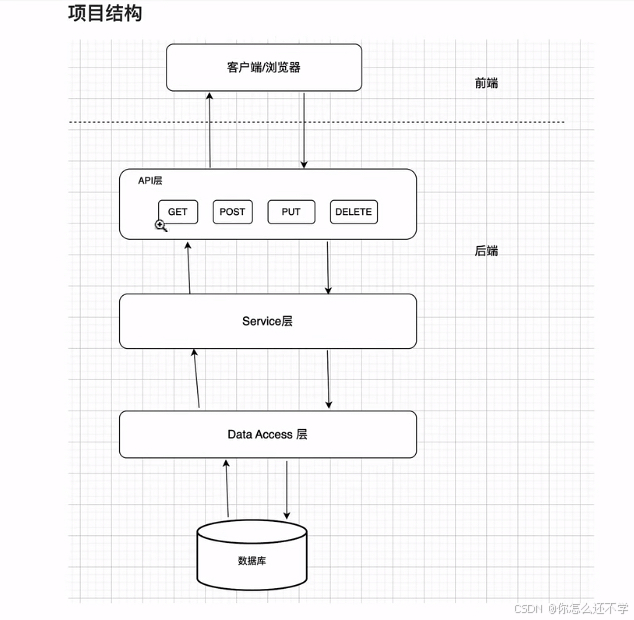
Spring Boot项目快速创建-开发流程(笔记)
主要流程: 前端发送网络请求->controller->调用service->操纵mapper->操作数据库->对entity数据对象赋值->返回前端 前期准备: maven、mysql下载好 跟学视频,感谢老师: https://www.bilibili.com/video/BV1gm4…...

车架号查询车牌号接口如何用Java对接
一、什么是车架号查询车牌号接口? 车架号查询车牌号接口,即传入车架号,返回车牌号、车型编码、初次登记日期信息。车架号又称车辆VIN码,车辆识别码。 二、如何用Java对接该接口? 下面我们以阿里云接口为例࿰…...

npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本的处理方法
1、安装了node.js后,windows powershell中直接输入npm,然后就报错 2、出现原因:权限不够 系统禁用了脚本的执行,所以我们在windows powershell输入npm -v的时候,就会报上面的错误。 3、解决 Set-ExecutionPolicy Un…...

【java笔记】泛型、包装类、自动装箱拆箱与缓存机制
一、泛型:类型安全的基石 1. 泛型的本质与原理 Java 泛型(Generics)是 JDK 5 引入的特性,通过类型参数化实现代码的通用性。泛型类、接口和方法允许在定义时声明类型参数(如 T、E、K、V),这些…...

数仓开发那些事(11)
某神州优秀员工:一闪,领导说要给我涨米。 一闪:。。。。(着急的团团转) 老运维:Oi,两个吊毛,看看你们的hadoop集群,健康度30分,怎么还在抽思谋克?…...

自动化测试【Python3.7+Selenium3】
1、自动化测试环境搭建之selenium3安装 方法1:cmd环境下,用pip install selenium (速度很慢,不推荐) 方法2:下载selenium安装包手动安装 下载地址:https://pypi.org/project/selenium/ 在解压…...

从零开始完成冒泡排序(0基础)——C语言版
文章目录 前言一、冒泡排序的基本思想二、冒泡排序的执行过程(一)第一轮排序(二)第二轮排序(三)第三轮排序(四)第四轮排序 三、冒泡排序的代码实现(C语言)&am…...

工业级POE交换机:助力智能化与自动化发展
随着工业互联网、物联网(IoT)和自动化技术的快速发展,网络设备在工业领域的应用日益广泛。然而,在严苛环境下,传统网络设备往往难以应对复杂的温湿度变化、电磁干扰和供电不稳定等挑战。为同时满足数据传输与供电一体化…...

使用ZYNQ芯片和LVGL框架实现用户高刷新UI设计系列教程(第五讲)
在上一讲我们讲解了按键回调函数的自定义函数的用法,这一讲继续讲解回调函数的另一种用法。 首先我们将上一讲做好的按键名称以及自定义回调事件中的按键名称修改,改为默认模式为“open”当点击按键时进入回调函数将按键名称改为“close”,具…...

Burp Suite Professional 2024版本安装激活指南
文章目录 burpsuite简介Burp Suite的主要组件:Burp Suite的版本使用场景 下载地址使用教程 burpsuite简介 Burp Suite 是一个广泛使用的网络安全测试工具,特别是在Web应用程序安全领域。它主要用于发现和修复Web应用中的安全漏洞,特别适用于渗…...

【c++深入系列】:类与对象详解(上)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 你仰望的星辰并非遥不可及,而是跋涉者脚印的倒影;你向往的远方未必需要翅膀,只要脚下始终有路&#x…...

6、进程理论和简单进程创建
一、了解进程推荐看这个视频,很详细 1、概念 进程(Process)程序的运行过程,是系统进行资源分配和调度的独立单元程序的运行过程:多个不同程序 并发,同一个程序同时执行多个任务。 就需要很多资源来实现这个过程。 每个进程都有一…...

java八股文之JVM
1.什么是程序计数器 程序计数器是 JVM 管理线程执行的“定位器”,记录每个线程当前执行的指令位置,确保程序流程的连续性和线程切换的准确性。线程私有的,每个线程一份,内部保存的字节码的行号。用于记录正在执行的字节码指令的地…...