LLM 优化技术(1)——Scaled-Dot-Product-Attention(SDPA)
在 Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由Scaled Dot Product Attention 和Feed Forward Neural Network组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,Attention is All You Need论文中通过搭建编码器(encoder)和解码器(decoder)各 6 层,总共 12 层的Encoder-Decoder,并在机器翻译中取得了 BLEU 值的新高。
作者采用 Attention 机制的原因是考虑到 RNN(或者 LSTM,GRU 等)的计算限制为是顺序的,也就是说 RNN 相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象 LSTM 依旧无能为力。
Transformer 的提出解决了上面两个问题:
- 首先它使用了 Attention 机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
- 其次它不是类似 RNN 的顺序结构,因此具有更好的并行性,符合现有的 GPU 框架。
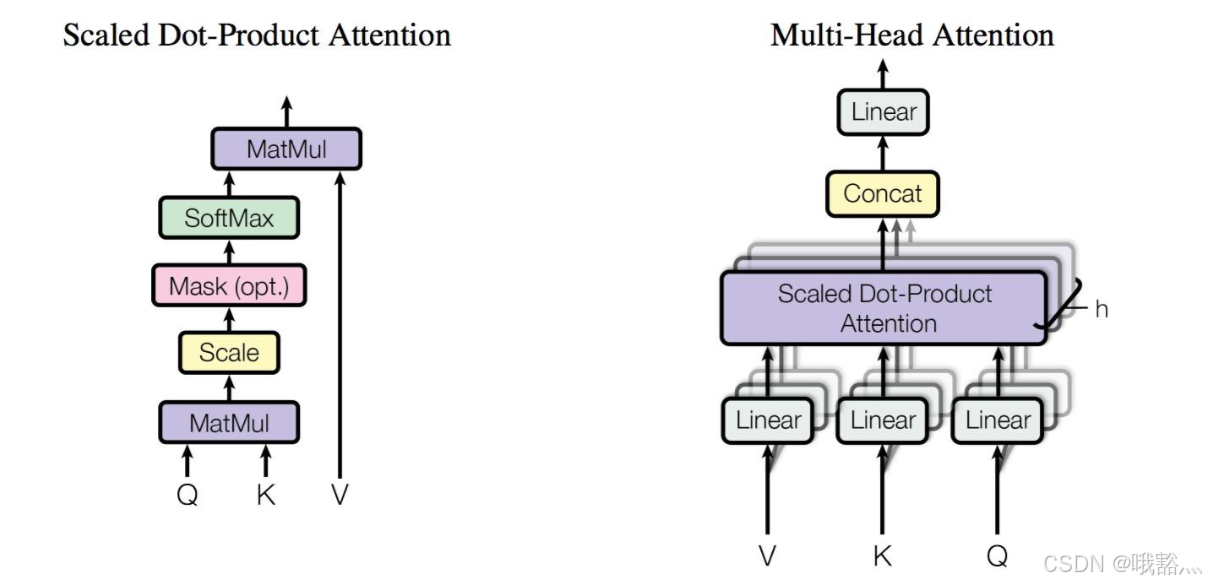
Scaled Dot Product Attention作为 Transformer 模型结构最核心的组件,pytorch 对其做了融合实现支持,并提供了丰富的 python 接口供用户轻松搭建 Transformer:
torch.nn.functional.scaled_dot_product_attention,
torch.nn.MultiheadAttention,
torch.nn.TransformerEncoderLayer,
torch.nn.Transformer,
torch.nn.TransformerDecoderLayer,
torch.ops.aten._scaled_dot_product_flash_attention,
torch.ops.aten._scaled_dot_product_efficient_attention_cuda
这里先之看torch.nn.functional.scaled_dot_product_attention这个接口。
1 Fused implementations
给定 CUDA 张量输入,torch.nn.functional.scaled_dot_product_attention函数将分派到以下实现之一:
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- Memory-Efficient Attention
- C++ 定义的原生 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
device = "cuda" if torch.cuda.is_available() else "cpu"# Example Usage:
query, key, value = torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device)
F.scaled_dot_product_attention(query, key, value)
2 Explicit Dispatcher Control
torch.nn.functional.scaled_dot_product_attention函数将隐式分派到三个实现之一,但用户也可以通过使用上下文管理器显式控制分派。此上下文管理器允许用户明确禁用某些实现。如果用户确定对于特定输入某种实现是最快的实现的话,则可以使用上下文管理器来扫描测量性能。
# Lets define a helpful benchmarking function:
import torch.utils.benchmark as benchmark
def benchmark_torch_function_in_microseconds(f, *args, **kwargs):t0 = benchmark.Timer(stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f})return t0.blocked_autorange().mean * 1e6# Lets define the hyper-parameters of our input
batch_size = 32
max_sequence_len = 1024
num_heads = 32
embed_dimension = 32dtype = torch.float16query = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
key = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
value = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)print(f"The default implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")# Lets explore the speed of each of the 3 implementations
from torch.backends.cuda import sdp_kernel, SDPBackend# Helpful arg mapper
backend_map = {SDPBackend.MATH: {"enable_math": True, "enable_flash": False, "enable_mem_efficient": False},SDPBackend.FLASH_ATTENTION: {"enable_math": False, "enable_flash": True, "enable_mem_efficient": False},SDPBackend.EFFICIENT_ATTENTION: {"enable_math": False, "enable_flash": False, "enable_mem_efficient": True}
}with sdp_kernel(**backend_map[SDPBackend.MATH]):print(f"The math implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):try:print(f"The flash attention implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")except RuntimeError:print("FlashAttention is not supported. See warnings for reasons.")with sdp_kernel(**backend_map[SDPBackend.EFFICIENT_ATTENTION]):try:print(f"The memory efficient implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")except RuntimeError:print("EfficientAttention is not supported. See warnings for reasons.")
3 Causal Self Attention
下面是受 Andrej Karpathy 的 NanoGPT 仓库启发的 multi-headed causal self attention 的示例实现:
class CausalSelfAttention(nn.Module):def __init__(self, num_heads: int, embed_dimension: int, bias: bool=False, is_causal: bool=False, dropout:float=0.0):super().__init__()assert embed_dimension % num_heads == 0# key, query, value projections for all heads, but in a batchself.c_attn = nn.Linear(embed_dimension, 3 * embed_dimension, bias=bias)# output projectionself.c_proj = nn.Linear(embed_dimension, embed_dimension, bias=bias)# regularizationself.dropout = dropoutself.resid_dropout = nn.Dropout(dropout)self.num_heads = num_headsself.embed_dimension = embed_dimension# Perform causal maskingself.is_causal = is_causaldef forward(self, x):# calculate query, key, values for all heads in batch and move head forward to be the batch dimquery_projected = self.c_attn(x)batch_size = query_projected.size(0)embed_dim = query_projected.size(2)head_dim = embed_dim // (self.num_heads * 3)query, key, value = query_projected.chunk(3, -1)query = query.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)key = key.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)value = value.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)if self.training:dropout = self.dropoutis_causal = self.is_causalelse:dropout = 0.0is_causal = Falsey = F.scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=dropout, is_causal=is_causal)y = y.transpose(1, 2).view(batch_size, -1, self.num_heads * head_dim)y = self.resid_dropout(self.c_proj(y))return ynum_heads = 8
heads_per_dim = 64
embed_dimension = num_heads * heads_per_dim
dtype = torch.float16
model = CausalSelfAttention(num_heads=num_heads, embed_dimension=embed_dimension, bias=False, is_causal=True, dropout=0.1).to("cuda").to(dtype).eval()
print(model)
4 NestedTensor and Dense tensor support
SDPA 支持 NestedTensor 和 Dense 张量输入。NestedTensors 处理输入是一批可变长度序列的情况,而不需要将每个序列填充到批中的最大长度。
import random
def generate_rand_batch(batch_size,max_sequence_len,embed_dimension,pad_percentage=None,dtype=torch.float16,device="cuda",
):if not pad_percentage:return (torch.randn(batch_size,max_sequence_len,embed_dimension,dtype=dtype,device=device,),None,)# Random sequence lengthsseq_len_list = [int(max_sequence_len * (1 - random.gauss(pad_percentage, 0.01)))for _ in range(batch_size)]# Make random entry in the batch have max sequence lengthseq_len_list[random.randint(0, batch_size - 1)] = max_sequence_lenreturn (torch.nested.nested_tensor([torch.randn(seq_len, embed_dimension,dtype=dtype, device=device)for seq_len in seq_len_list]),seq_len_list,)random_nt, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=0.5, dtype=dtype, device=device)
random_dense, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=None, dtype=dtype, device=device)# Currently the fused implementations don't support NestedTensor for training
model.eval()with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):try:print(f"Random NT runs in {benchmark_torch_function_in_microseconds(model, random_nt):.3f} microseconds")print(f"Random Dense runs in {benchmark_torch_function_in_microseconds(model, random_dense):.3f} microseconds")except RuntimeError:print("FlashAttention is not supported. See warnings for reasons.")
5 Scaled Dot Product Attention (SDPA) 在 CPU 上的 性能优化
PyTorch 2.0 的主要 feature 是 compile,一起 release 的还有一个很重要的 feature 是 SDPA: Scaled Dot Product Attention 的优化。一共包含三个算法:
- Math: 把原始实现从 Python 挪到了 C++
- Efficient Attention
- Flash Attention
后两种算法是无损加速,不同于使用 low rank 或者 sparse 的方式,从数学上来说计算没有发生变化,所以不影响精度。
SDPA 主要是为了解决 LLM 中的两方面痛点:
- memory footprint: attn 的尺寸是 {B, H, T, T}。和 T 是 O(n2) 的关系,随着 sequence 变长,memory 开销太大;
- performance speedup: 针对 attn 的 pointwise 操作都是 memory bandwidth bound,速度太慢了
目前的版本中,后两种算法都只支持 CUDA device。
5.1 Previous Work
1.3 版本出现了 nn.MultiheadAttention 的优化,具体应用的 API 是 HuggingFace Optimum 的 BetterTransformer。思路是把 gemm 之间的 pointwise 统统 fuse 起来。
最大的收益来自于对 attn 操作的 fusion,因为 QKV 尺寸是和 T * K 成正比,而 attn 是和 T * T 成正比。这里的 K 是每个 head 上的 feature size,T 是 sequence length,一般来讲 T 会 比 K 大很多。
原始实现对于 masked softmax 的处理一共需要 4 reads + 5 writes:
对于 mask 的处理会非常繁琐:需要 4 次操作: ones, tril, not, masked_fill。共需要 3 reads + 4 writes。softmax 由于需要保障数值稳定性,需要 4 个 steps 完成,不过这 4 步只有 1 read + 1 write,原因在于 transformer 里面是在 lastdim 上做 softmax,正常情况下数据 parallel 的方式保障 L1 cache hit,所以只有 1 read + 1 write。
做了 fuse 之后,masked_softmax 一共需要 1 read + 1 write。attn 是个很大的 tensor,所以主要的性能收益来自这个地方。但即使只有 1次读和1次写,还是不够快,另外这个算法解决不了内存开销太大的问题。为了解决这些问题, SDPA 应运而生了,不管是 efficient attention 还是 flash attention,核心都是如何通过 blocking (或者叫 tiling)避免直接分配一块 {B, H, T, T} 这么大的 attn。通过让数据停留在 cache 上面,达到对 pointwise 操作的加速。
5.2 SDPA 优化
efficient attention 和 flash attention 2 在经过 fully optimized 之后这两种算法本质上没有区别。
5.2.1 naive
整个 scaled dot product attention 的原始计算过程如下图,对于每一个 {B, H} 的 slice:
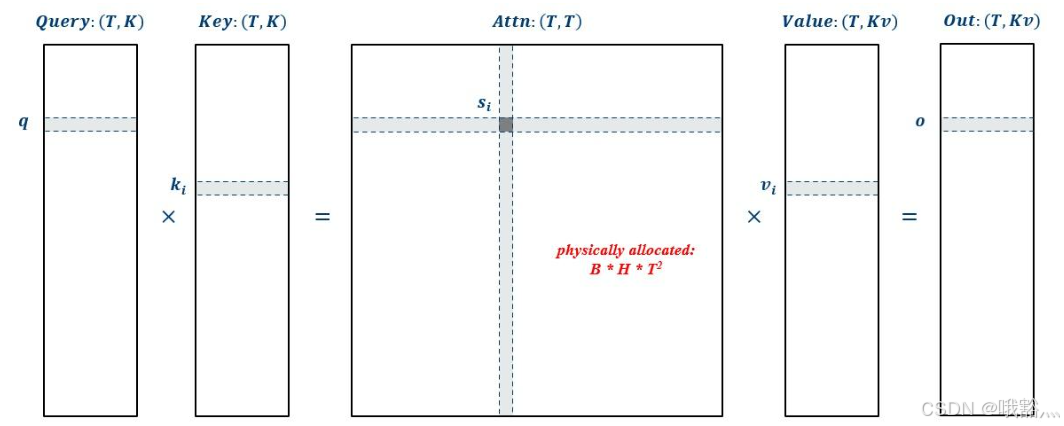
这里,把 V 看作一个 v 0 , v 1 , . . . , {v0, v1, ..., } v0,v1,..., 的向量会比较好理解。另外,我们认为这里 attn 还是做了实际的内存分配。
整个过程可以分解为 3 步:
- 一个 vec-vec 的 Dot Product
- 针对 attn 每一行元素的 pointwise
- 一个 vec-mat 的 GEMV
5.2.2 Lazy Softmax
引入 lazy softmax 可以避免为 attn 实际分配内存,在每个 thread 保留一些 momentum 信息即可:
m*记录当前的 max value;s*记录 sum value;v*记录 out 中每一行的累计值。
那么,可以很容易地算出来每个 thread 需要的额外内存只有:1 + 1 + Kv (Kv 是 V 每个 head 的 feature size)。
从性能角度出发我们更关心计算的性质,与原始形态计算量实际上发生了退化,不过好在不需要分配 {B, H, T, T} 这么大一个 tensor 了:
但是,这种实现依旧很原始,性能并不好,这个 kernel 大概会比原版还慢十几倍。主要原因有两点:
- 对于每一个
q_i,都需要遍历整个 K,才能完成 attn 中一行的计算; s_i需要和v_i相乘并累加到o_i中,这个过程中同样对于 V 有重复访问,并且要多次写入 O;
按模型中实际尺寸来算,KV是不可能被 cache 命中的,所以就是在不停地刷内存带宽,肯定快不了。
5.2.3 在 KV 上做 Blocking
在 KV 上做 blocking,即每一个 iteration 计算 q_i 和 一个 K block 和 V block,这么做是为了减少对 O 的写入次数,KV block 的数量就是减少写入次数的倍数。这个时候计算的性质已经发生了变化,每一步的计算量被放大了 NB 倍。
也需要一个额外的 s_i 来记录 qk 的内积结果,那么每个 thread 的额外内存变为:1 + 1 + NB + Kv
不过这样还是不能解决对 KV 的重复访问。
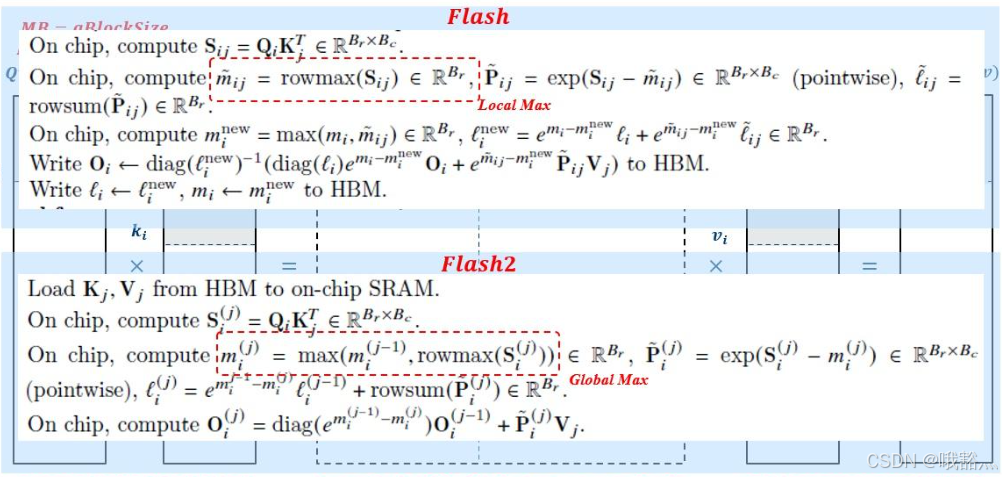
5.2.4 在 Q 上做 Blocking
在 Q 上做 blocking,即每一个 iteration 计算 一个 Q block 和 一个 KV block,这么做是为了减少对 KV 的读取次数,Q block 的数量就是减少读取次数的倍数。
每一步的计算量被再次放大了 MB 倍。
每个 thread 的额外内存变为:MB * (1 + 1 + NB + Kv),扩大了 MB 倍。不过我们还是可以通过计算保障这个 buffer 被 L2 命中(L1 大小是 32KB,L2 是 1MB,这个 buffer 大小可以设置 L2 的 25%)。
至此,我们完成了对 SDPA 基本形态的推导,从 efficient 算法入手,可以得到数学上和 flash2 完全一致的过程:
5.2.5 Float16 和 BFloat16 的实现
基本原则是用 float32 来做 accumulation。当然在 intel xeon 上得益于 AMX 的硬件加速,code 中使用了 MKL 中的 cblas_gemm_bf16bf16f32 函数,即 A(bf16) x B(bf16) = C(fp32)
5.2.6 Causal Mask
SDPA 对于 Causal mask 的处理是在 s_i 这个 buffer 里面加 mask,配合上 blocking,可以额外省掉上三角的 GEMM,所以在 causal mask 的情况下 SDPA 能拿到更大的加速比:
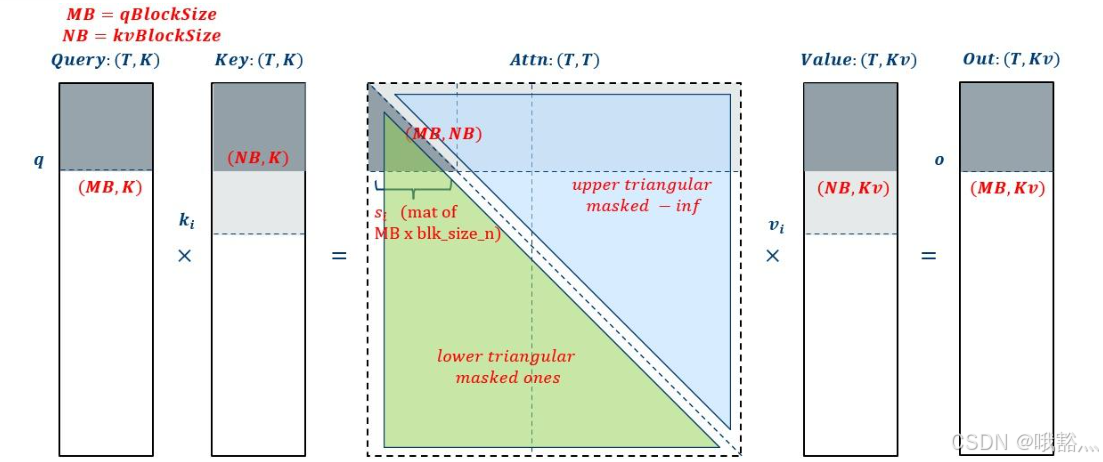
实际中因为配合了 blocking,所以中间的那条线应该是个阶梯状的,阶梯上面的 GEMM 会被省略掉。
5.2.7 一些问题
首先最显著的一个问题就是 load imbalance, 我们依赖在 B-H-MB (batch-head-q_block) 这三个维度上做 parallel,但每一个 q block 对应访问的 kv block 数量是不一样的,可能会导致 load imbalance:

这个问题其实很好解决,因为我们预先就可以算出每个 q block 对应几个 kv block。
还有一个比较难处理的问题是每个 thread memory 访问不均衡的问题。比如我们有 10 个 q block,但每个 thread 只能计算 8 个,那么 T0 只会访问一组 KV (都来自 Head_0);而 T2 会访问两组 KV (来自于 Head_0 和 Head_1)。
另外还有一个让 amx 和 avx512 并行的问题,也就是如何让 GEMM 和 pointwise 并行起来。
相关文章:
LLM 优化技术(1)——Scaled-Dot-Product-Attention(SDPA)
在 Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由Scaled Dot Product Attention 和Feed Forward Neural Network组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,Attention is All You Need论文中通…...
)
AIGC-头条号长文项目创作智能体完整指令(DeepSeek,豆包,千问,Kimi,GPT)
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列AIGC(GPT、DeepSeek、豆包、千问、Kimi)👉关于作者 专注于Android/Unity和各...

基于音频驱动的CATIA动态曲面生成技术解析
一、技术背景与创新价值 在工业设计领域,参数化建模与动态仿真的结合一直是研究热点。本文提出的音频驱动建模技术突破了传统参数调整方式,实现了音乐节奏与三维曲面的实时动态交互。该技术可广泛应用于以下场景: 艺术化产品设计…...

5-管理员-维护权限
在“后台”-“人员管理”-“权限”下,通过不同的操作按钮,按照权限分组对权限进行设置。操作部分的按钮依次为 视野维护:设置该分组可以查看、访问的视图。权限维护:设置分组成员可以操作的具体动作等所有在禅道中涉及的权限。成…...

全新升级 | Built For You Spring ‘25 发布,Fin 智能客服实现新突破!
图像识别、语音交互、任务自动化,立即体验智能客服蜕变! 上周,Intercom 举办了 Built For You Spring 25 发布会,正式揭晓了 AI Agent Fin 的一系列令人振奋的更新。Fin 正在以前所未有的速度革新客户支持模式——它已经成功解决了…...

turtle的九个使用
一 import turtle as t color [red,green,blue,orange,pink] for i in range(len(color)):t.penup()t.goto(-20070*i,0)t.pendown()t.pencolor(color[i])t.circle(50, steps 5) t.done()二 #在____________上补充代码 #不要修改其他代码import random as r import turtle a…...

营销库存系统设计方案
文章目录 一、营销库存系统设计方案1. 核心模块设计实时库存管理促销库存预占机制库存分层调度动态库存分配2. 技术架构示例二、技术难点与解决方案高并发下的数据一致性防超卖与恶意请求拦截多级库存同步延迟异常场景处理三、关键注意事项1.系统弹性…...

R002-云计算
1 概念 英文名:Cloud Computing 核心:云计算的核心概念就是以互联网为中心,在网站上提供快速且安全的云计算服务与数据存储,让每一个使用互联网的人都可以使用网络上的庞大计算资源与数据中心 2.分类 基础设施即服务(IaaS)它向…...

LeeCode 434. 字符串中的单词数
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意,你可以假定字符串里不包括任何不可打印的字符。 示例: 输入: "Hello, my name is John" 输出: 5 解释: 这里的单词是指连续的不是空格的字符,所以 "…...

DriveDreamer动力学模块和博弈论优化器
DriveDreamer的动力学模块与博弈论优化器是其实现复杂场景下高保真重建与多智能体协同优化的核心技术组件。 一、动力学模块(NTGM) 功能定位:作为新轨迹生成模块(Novel Trajectory Generation Module, NTGM)…...

【AI编程学习之Python】第一天:Python的介绍
Python介绍 简介 Python是一种解释型、面向对象的语言。由吉多范罗苏姆(Guido van Rossum)于1989年发明,1991年正式公布。官网:www.python.org Python单词是"大蟒蛇”的意思。但是龟叔不是喜欢蟒蛇才起这个名字,而是正在追剧:英国电视喜剧片《蒙提派森的飞行马戏团》(Mo…...

西域平台商品详情接口设计与实现
接口描述: 该接口用于获取西域平台中指定商品的详细信息,包括商品名称、价格、库存、描述、图片等。 点击获取key和secret 接口地址: GET /api/product/detail 请求参数: 参数名 类型 是否必填 描述 productId st…...

如何让 history 记录命令执行时间?Linux/macOS 终端时间戳设置指南
引言:你真的会用 history 吗? 有没有遇到过这样的情况:你想回顾某个重要命令的执行记录,却发现 history 只列出了命令序号和内容,根本没有时间戳?这在运维排查、故障分析、甚至审计时都会带来极大的不便。 想象一下,你在服务器上误删了某个文件,但不知道具体是几点执…...

云原生四重涅槃·破镜篇:混沌工程证道心,九阳真火锻金身
【乾坤惊变混沌劫起】 "轰——!" 龙渊山巅突然雷云翻滚,九重天外传来梵音轰鸣。监察使手中玄光镜剧烈震颤,镜中映出骇人景象:原本井然有序的Service Mesh星轨竟自行扭曲,数十万Envoy边车化身血色修罗&#…...

04-SpringBoot3入门-配置文件(多环境配置)
1、简介 在 SpringBoot 中,不同的环境(如开发、测试、生产)可以编写对应的配置文件,例如数据库连接信息、日志级别、缓存配置等。在不同的环境中使用对应的配置文件。 2、配置环境 # 开发环境 zbj:user:username: root # 测试环…...

CodeSouler v1.15.0 版本更新
经过深度研发与全面优化,CodeSouler迎来了又一次重要升级。本次更新不仅提升了插件的智能化水平,更将“自主开发”从愿景变为现实! 无论你是在构建插件、部署工具链,还是希望提升开发效率,v1.15.0版本都将为你带来更流…...

windows第十八章 菜单、工具栏、状态栏
文章目录 创建框架窗口菜单菜单的风格通过资源创建菜单菜单的各种使用通过代码创建菜单在鼠标位置右键弹出菜单 CMenu常用函数介绍工具栏方式一,从资源创建工具栏方式二,代码创建 状态栏状态栏基础创建状态栏 创建框架窗口 手动创建一个空项目ÿ…...

EMC电源端传导干扰预测试
本实验需要在微波暗室里面进行,隔离外界干扰。 1.EMI接收机和人工电源网络的电源线都插在隔离变压器上面,隔离变压器的电源插在AC220上面 2.被测设备EUT的电源线接在人工电源网络上: 人工电源网络的信号输出端连接EMI接收机。 EMI接收机前面…...

94二叉树中序遍历解题记录
怎么说呢,以为这道题不用记录了,菜得吓到了自己。起因是这个遍历的递归一般是写两个函数完成,如下: func inorder(root *TreeNode, res *[]int) {if root nil {return}inorder(root.Left, res)*res append(*res, root.Val) // …...

java项目之基于ssm的亚盛汽车配件销售业绩管理系统(源码+文档)
项目简介 亚盛汽车配件销售业绩管理系统实现了以下功能: 亚盛汽车配件销售业绩管理系统根据调研,确定管理员管理客户,供应商,员工,管理配件和配件的进货以及出售信息。员工只能管理配件和配件的出售以及进货信息&…...

ebay跨境电商账号安全防护:IP污染风险深度解析及应对方案
一、IP污染的技术定义与风控逻辑 在跨境电商运营中,IP污染特指因网络地址关联导致的账号风控问题。eBay平台通过多维数据监测体系(包括IP归属地、设备指纹、网络行为模式等)识别账号关联性。当系统检测到多个账号存在网络层特征重叠时&#x…...

云资源开发学习应用场景指南,场景 1 云上编程实践平台
云资源开发学习应用场景指南 云资源开发学习应用场景指南,场景 2:云桌面实验室 云资源开发学习应用场景指南,场景 3:云资源支持的项目实践 场景 1:云上编程实践平台 《如何在云平台上搭建你的第一个编程实践环境》…...

前端开发3D-基于three.js
基于 three.js 渲染任何画面,都要基于这 3 个要素来实现 1场景scene:放置物体的容器 2摄像机:类似人眼,可调整位置,角度等信息,展示不同画面 3渲染器:接收场景和摄像机对象,计算在浏…...

Mysql的单表查询和多表查询
创建数据库db_ck mysql> create database db_ck; Query OK, 1 row affected (0.03 sec) 查看以 db 开头的的数据库 show database like "db_%"; 二、创建表 新建表t_hero mysql> use db_ck Database changed mysql> create table t_hero(-> id int…...

Spring Initializr搭建spring boot项目
介绍 Spring Initializr 是一个用于快速生成 Spring Boot 项目结构的工具。它为开发者提供了一种便捷的方式,可以从预先定义的模板中创建一个新的 Spring Boot 应用程序,从而节省了从头开始设置项目的大量时间。 使用 Spring Initializr,你…...

第十二章:补充介绍pip与配置及Python结构层次
一、pip介绍pip介绍与配置及Python结构层次 1. pip是什么 pip 是 Python 的一个包管理工具,它允许你安装和管理 Python 库和依赖项。简单来说,pip 就是一个工具,它可以帮助你轻松地安装、更新、卸载 Python 的各种库。 2. pip属于什么层次的…...
】安全审计与日志管理:为电商平台筑牢安全防线)
【商城实战(91)】安全审计与日志管理:为电商平台筑牢安全防线
【商城实战】专栏重磅来袭!这是一份专为开发者与电商从业者打造的超详细指南。从项目基础搭建,运用 uniapp、Element Plus、SpringBoot 搭建商城框架,到用户、商品、订单等核心模块开发,再到性能优化、安全加固、多端适配…...

Hyperlane:Rust Web开发的未来,释放极致性能与简洁之美
Hyperlane:Rust Web开发的未来,释放极致性能与简洁之美 你是否厌倦了复杂的Web框架,想要一个既高效又易用的工具来构建现代Web应用?Hyperlane正是你需要的答案!作为专为Rust打造的轻量级、高性能HTTP服务器库…...

deepseek 技术的前生今世:从开源先锋到AGI探索者
一、引言:中国AI领域的“超越追赶”样本 DeepSeek(深度求索)作为中国人工智能领域的代表性企业,自2023年创立以来,凭借开源生态、低成本技术路径与多模态创新,迅速从行业新秀成长为全球AI竞赛中的关键力量…...

django orm的优缺点
Django ORM(对象关系映射)是 Django 框架的核心组件之一,它通过将数据库表映射为 Python 类,简化了数据库操作。以下是其优缺点总结: 优点 开发效率高 用 Python 类定义数据模型,无需手写 SQL,…...