C语言之数据结构:双向链表
个人主页:云纳星辰怀自在
座右铭:“所谓坚持,就是觉得还有希望!”
前言
前文阐述了数据结构中单向链表的定义、分类和实际应用。本文将重点阐述带哨兵节点的双向循环链表。
1. 带头双向循环链表
带头双向循环链表 是一种特殊的链表结构,它结合了双向链表和循环链表的特性,并且引入了一个头节点来简化操作。以下是带头双向循环链表的详细说明:
- 双向链表:每个节点有两个指针,prev 指向前一个节点,next 指向后一个节点。
- 循环链表:链表的最后一个节点的 next 指向链表头节点,头节点的 prev 指向最后一个节点,形成一个环。
- 链表中有一个特殊的头节点,它不存储实际数据,只用于简化链表的操作(如插入、删除等)。头节点的 prev 指向链表的最后一个节点,next 指向链表的第一个节点。

1.1 带头双向循环链表优点
简化操作:
🟦插入和删除操作不需要单独处理链表为空的情况。
🟦不需要单独处理链表的第一个节点和最后一个节点。
高效遍历:
🟦可以从任意节点开始遍历链表。
🟦可以方便地从后向前遍历链表。
统一性:
🟦头节点的存在使得链表的操作更加统一,减少了边界条件的判断。
1.2 哨兵节点(Sentinel Node)
哨兵节点是一个特殊的虚拟节点,通常不存储实际数据,主要用于简化链表操作的边界条件处理。哨兵节点的作用类似于一个“占位符”,它始终存在于链表中,无论链表是否为空。
特点:
- 哨兵节点不存储实际数据。
- 在双向循环链表中,哨兵节点的 prev 指向链表的最后一个节点,next 指向链表的第一个节点。
- 哨兵节点的存在使得链表的操作逻辑更加统一,无需额外处理空链表或边界条件。
哨兵节点和头节点的关系: 哨兵节点和头节点可以共存,但它们的作用不同:
- 头节点:用于标识链表的起始位置,通常指向第一个实际存储数据的节点。
- 哨兵节点:用于简化链表操作,通常作为链表的虚拟头节点或尾节点。
在实际实现中,哨兵节点可以取代头节点的功能。例如:
- 在双向循环链表中,哨兵节点可以同时作为链表的“虚拟头节点”和“虚拟尾节点”。
- 链表的第一个实际节点是 sentinel->next,最后一个实际节点是 sentinel->prev。
哨兵节点取代头节点的优势: 使用哨兵节点可以避免处理空链表和边界条件,例如:
🟦普通链表
- 插入第一个节点时,需要更新头节点指针。
- 删除最后一个节点时,如果链表只有一个节点,删除后链表为空,需要将头节点指针置为 nullptr。如果链表有多个节点,删除最后一个节点时,只需更新前驱节点的 next 指针,使其指向 nullptr,而头节点指针保持不变。
🟦带哨兵节点的链表
- 插入和删除操作无需额外判断,因为哨兵节点始终存在。
- 链表的第一个节点是 sentinel->next,最后一个节点是 sentinel->prev。
2. 双向链表的实现
2.1 双向链表数据结构
在实现链表功能之前,首先需要完成数据类型的定义和结构体的声明。
我们选择使用整型作为链表节点的数据类型,这与前文实现的单链表保持一致。
在结构体定义方面,双向链表与单链表存在显著差异。单链表作为单向链表,其节点只需维护一个指向后继节点的指针;而双向链表的每个节点则需要同时维护两个指针:一个指向前驱节点,另一个指向后继节点。这种双向指针的设计使得我们可以从任意节点出发,同时访问其前驱和后继节点,从而实现双向遍历。具体代码如下:
typedef int LinkDataType; // 定义链表数据类型为 inttypedef struct HeadDualListNode {LinkDataType data; // 节点存储的数据struct HeadDualListNode* prev; // 指向前驱节点的指针struct HeadDualListNode* next; // 指向后继节点的指针
} HeadDualListNode;
2.2 循环双向链表数据初始化
初始化链表时,创建一个哨兵节点,并将其 prev 和 next 指针指向自己,表示链表为空。
void initialize(HeadDualListNode** sentinel) {*sentinel = (HeadDualListNode*)malloc(sizeof(HeadDualListNode)); // 为哨兵节点分配内存if (*sentinel == NULL) { // 检查内存分配是否成功perror("malloc error");return;}(*sentinel)->prev = *sentinel; // 哨兵节点的 prev 指向自身(*sentinel)->next = *sentinel; // 哨兵节点的 next 指向自身(*sentinel)->data = -1; // 哨兵节点的数据设置为特殊值(如 -1)
}
2.3 循环双向链表-哨兵节点判定
链表删除操作需要特别注意边界条件的处理。在实现删除功能时,单链表和双向链表存在本质区别:
🟦单链表的删除限制:
- 当链表为空(head == NULL)时,删除操作无法执行
- 必须显式检查空链表情况
🟦双向链表的删除特性:
- 得益于哨兵节点(dummy node)的设计,链表永远不会真正"为空"
- 唯一需要处理的情况是:当链表仅包含哨兵节点时禁止删除操作
判断链表是否仅含哨兵节点的方法:可以通过检查哨兵节点的指针指向关系来实现。具体判定条件为:head->next == head 或 head->prev == head(满足任一条件即可)
这种设计优势在于:
- 统一了空链表和非空链表的处理逻辑
- 避免了频繁的空指针检查
- 使代码更加健壮和简洁
注意:在实际实现时,建议将哨兵节点的值域设为特殊值(如INT_MIN)以区别于有效数据节点。
bool hasSentinel(HeadDualListNode* sentinel) {if (sentinel == NULL) { // 如果哨兵节点为空return false; // 返回 false}return (sentinel->prev == sentinel) && (sentinel->next == sentinel); // 判断 prev 和 next 是否指向自身
}
2.4 循环双向链表-申请节点
为了提高代码的模块化和可维护性,我们特别对链表插入操作中的公共功能进行了封装。在实现头插、尾插或指定位置插入等操作时,都需要动态创建新节点,这一过程可以被抽象为独立的功能模块:用内存函数来向内存申请一片空间并返回指向这片空间的指针。
HeadDualListNode* BuyHeadDualListNode(LinkDataType data) {HeadDualListNode* newNode = (HeadDualListNode*)malloc(sizeof(HeadDualListNode)); // 为新节点分配内存if (newNode == NULL) { // 检查内存分配是否成功perror("malloc error");return NULL;}newNode->data = data; // 设置新节点的数据newNode->prev = NULL; // 初始化 prev 为 NULLnewNode->next = NULL; // 初始化 next 为 NULLreturn newNode; // 返回新节点
}
2.5 循环双向链表-打印
链表打印功能是实现链表操作的重要调试手段,它能直观地验证插入、删除等操作的执行效果。在实现打印功能时,双向链表与单链表存在显著差异。
对于单链表而言,打印操作较为简单:从头指针开始顺序遍历,直至遇到NULL指针即可终止。然而,双向链表的环形结构使得传统的遍历方式不再适用。由于双向链表的首尾相连特性,若采用常规遍历方法,程序将陷入无限循环。
为解决这一问题,我们需要调整遍历策略。具体实现方法是:
让遍历指针【cur】从哨兵节点(dummy node)的下一个节点开始
依次访问每个节点并输出数据
当指针再次回到哨兵节点时终止遍历
这种改进后的遍历方式既能完整输出链表数据,又能避免无限循环的问题。需要注意的是,在实现时应当确保哨兵节点的值不被当作有效数据输出,以保持输出结果的准确性。
void printList(HeadDualListNode* sentinel) {HeadDualListNode* current = sentinel; // 从哨兵节点开始do {printf("HeadDualListNode: %d (prev: %d, next: %d)\n",current->data, current->prev->data, current->next->data); // 打印当前节点及其前后节点的数据current = current->next; // 移动到下一个节点} while (current != sentinel); // 如果当前节点不是哨兵节点
}
2.6 循环双向链表-遍历
遍历链表并打印每个节点的数据。
void traverse(HeadDualListNode* sentinel) {HeadDualListNode* current = sentinel->next; // 从哨兵节点的下一个节点开始while (current != sentinel) { // 如果当前节点不是哨兵节点printf("%d ", current->data); // 打印当前节点的数据current = current->next; // 移动到下一个节点}printf("\n"); // 打印换行符}2.7 循环双向链表-查找节点
遍历链表,直至找到数据所对应的结点,并将其地址返回即可。
HeadDualListNode* find(HeadDualListNode* sentinel, LinkDataType data) {HeadDualListNode* current = sentinel->next; // 从哨兵节点的下一个节点开始while (current != sentinel) { // 如果当前节点不是哨兵节点if (current->data == data) { // 如果当前节点的数据等于目标数据return current; // 返回当前节点}current = current->next; // 移动到下一个节点}return NULL; // 未找到,返回 NULL}2.8 循环双向链表-插入节点

2.8.1 在指定节点后插入
将新节点插入到某个节点之后。
void insertBefore(HeadDualListNode* node, LinkDataType data) {HeadDualListNode* newNode = new HeadDualListNode();newNode->data = data;newNode->next = node; // 新节点的 next 指向 nodenewNode->prev = node->prev; // 新节点的 prev 指向 node 的前驱节点node->prev->next = newNode; // node 的前驱节点的 next 指向新节点node->prev = newNode; // node 的 prev 指向新节点}2.8.2 在指定节点前插入
将新节点插入到某个节点之前。
void insertAfter(HeadDualListNode* node, LinkDataType data) {HeadDualListNode* newNode = new HeadDualListNode();newNode->data = data;newNode->prev = node; // 新节点的 prev 指向 nodenewNode->next = node->next; // 新节点的 next 指向 node 的后继节点node->next->prev = newNode; // node 的后继节点的 prev 指向新节点node->next = newNode; // node 的 next 指向新节点}2.9 循环双向链表-删除节点
删除指定节点,并释放其内存。要删除的结点置空,并将其前后两个结点进行链接即可。不过要注意的依旧是链表是否只含有哨兵卫,若只含有哨兵卫,就无需进行链表的删除。
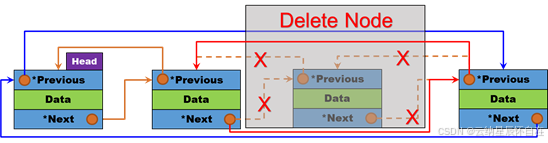
void removeNode(HeadDualListNode* node) {node->prev->next = node->next; // 前驱节点的 next 指向后继节点node->next->prev = node->prev; // 后继节点的 prev 指向前驱节点free(node); // 释放当前节点的内存}2.10 循环双向链表-尾插
在链表的尾部插入一个新节点。首先就是链表的尾插。我们先来看看单链表是如何进行尾插的,对于单链表,我们需要对单链表进行遍历找到最后一个结点,再对这个结点和新结点进行链接的操作。而对于双向链表,就没有这么复杂了,因为哨兵卫的上一个结点就已经指向了链表的最后一个结点,在找到这个尾结点之后,剩下的就是链接的问题了。相比于单链表要复杂一点,要将哨兵卫、尾结点、新结点这三个结点进行链接。
void insertTail(HeadDualListNode* sentinel, LinkDataType data) {insertBefore(sentinel, data); // 在哨兵节点前插入新节点}2.11 循环双向链表-尾删
删除链表的尾部节点。不需要对链表进行遍历来找到尾结点,只需要通过哨兵卫来找到最后一个结点,并将其置空,再将倒数第二个结点和哨兵卫进行链接。
void removeTail(HeadDualListNode* sentinel) {if (sentinel->prev != sentinel) { // 如果链表不为空removeNode(sentinel->prev); // 删除哨兵节点的前一个节点(尾节点)}}2.12 循环双向链表-头插
在链表的头部插入一个新节点。先是申请一个新的结点,进而将该结点与哨兵卫与链表的头结点进行链接。需要注意的一点就是判断链表是否只有哨兵卫,若是只有哨兵卫就无须删除。
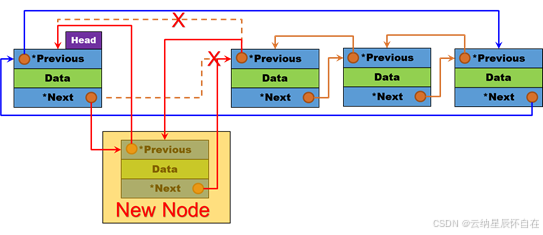
void insertHead(HeadDualListNode* sentinel, LinkDataType data) {insertAfter(sentinel, data); // 在哨兵节点后插入新节点}2.13 循环双向链表-头删
删除链表的头部节点。将哨兵卫与头结点的下一个结点链接,并将头结点的内存释放。唯一需要注意的一点就是判断链表是否只有哨兵卫,若是只有哨兵卫就无须删除。
void removeHead(HeadDualListNode* sentinel) {if (sentinel->next != sentinel) { // 如果链表不为空removeNode(sentinel->next); // 删除哨兵节点的下一个节点(头节点)}}2.14 循环双向链表-链表销毁
销毁链表,释放所有节点的内存,包括哨兵节点。从哨兵卫的下一个结点开始遍历链表,边遍历边销毁,直至遍历到哨兵卫为止,最后将哨兵卫的内存销毁并将指针置空。
void destroyList(HeadDualListNode* sentinel) {if (sentinel == NULL) { // 如果哨兵节点为空return; // 直接返回}HeadDualListNode* current = sentinel->next; // 从哨兵节点的下一个节点开始while (current != sentinel) { // 如果当前节点不是哨兵节点HeadDualListNode* nextNode = current->next; // 保存下一个节点free(current); // 释放当前节点的内存current = nextNode; // 移动到下一个节点}free(sentinel); // 释放哨兵节点的内存
}2.15 完整代码
1. LinkedList.h
#ifndef LINKEDLIST_H
#define LINKEDLIST_H#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef int LinkDataType; // 定义链表数据类型为 inttypedef struct HeadDualListNode {LinkDataType data; // 节点存储的数据struct HeadDualListNode* prev; // 指向前驱节点的指针struct HeadDualListNode* next; // 指向后继节点的指针
} HeadDualListNode;// 函数声明
void initialize(HeadDualListNode** sentinel); // 初始化链表
bool hasSentinel(HeadDualListNode* sentinel); // 判断链表是否有哨兵节点
HeadDualListNode* BuyHeadDualListNode(LinkDataType data); // 申请新节点
void insertAfter(HeadDualListNode* node, LinkDataType data); // 在指定节点后插入
void insertBefore(HeadDualListNode* node, LinkDataType data); // 在指定节点前插入
void insertHead(HeadDualListNode* sentinel, LinkDataType data); // 头插
void insertTail(HeadDualListNode* sentinel, LinkDataType data); // 尾插
void removeNode(HeadDualListNode* node); // 删除指定节点
void removeHead(HeadDualListNode* sentinel); // 头删
void removeTail(HeadDualListNode* sentinel); // 尾删
void traverse(HeadDualListNode* sentinel); // 遍历链表
void printList(HeadDualListNode* sentinel); // 打印链表详细信息
void destroyList(HeadDualListNode* sentinel); // 销毁链表#endif2. LinkedList.c
#include "LinkedList.h"// 初始化链表
void initialize(HeadDualListNode** sentinel) {*sentinel = (HeadDualListNode*)malloc(sizeof(HeadDualListNode)); // 为哨兵节点分配内存if (*sentinel == NULL) { // 检查内存分配是否成功perror("malloc error");return;}(*sentinel)->prev = *sentinel; // 哨兵节点的 prev 指向自身(*sentinel)->next = *sentinel; // 哨兵节点的 next 指向自身(*sentinel)->data = -1; // 哨兵节点的数据设置为特殊值(如 -1)
}// 判断链表是否有哨兵节点
bool hasSentinel(HeadDualListNode* sentinel) {if (sentinel == NULL) { // 如果哨兵节点为空return false; // 返回 false}return (sentinel->prev == sentinel) && (sentinel->next == sentinel); // 判断 prev 和 next 是否指向自身
}// 申请新节点
HeadDualListNode* BuyHeadDualListNode(LinkDataType data) {HeadDualListNode* newNode = (HeadDualListNode*)malloc(sizeof(HeadDualListNode)); // 为新节点分配内存if (newNode == NULL) { // 检查内存分配是否成功perror("malloc error"); // 打印错误信息return NULL; // 返回 NULL}newNode->data = data; // 设置新节点的数据newNode->prev = NULL; // 初始化 prev 为 NULLnewNode->next = NULL; // 初始化 next 为 NULLreturn newNode; // 返回新节点
}// 在指定节点后插入新节点
void insertAfter(HeadDualListNode* node, LinkDataType data) {HeadDualListNode* newNode = BuyHeadDualListNode(data); // 申请新节点if (newNode == NULL) return; // 如果申请失败,直接返回newNode->prev = node; // 新节点的 prev 指向指定节点newNode->next = node->next; // 新节点的 next 指向指定节点的下一个节点node->next->prev = newNode; // 指定节点的下一个节点的 prev 指向新节点node->next = newNode; // 指定节点的 next 指向新节点
}// 在指定节点前插入新节点
void insertBefore(HeadDualListNode* node, LinkDataType data) {HeadDualListNode* newNode = BuyHeadDualListNode(data); // 申请新节点if (newNode == NULL) return; // 如果申请失败,直接返回newNode->next = node; // 新节点的 next 指向指定节点newNode->prev = node->prev; // 新节点的 prev 指向指定节点的前一个节点node->prev->next = newNode; // 指定节点的前一个节点的 next 指向新节点node->prev = newNode; // 指定节点的 prev 指向新节点
}// 头插
void insertHead(HeadDualListNode* sentinel, LinkDataType data) {insertAfter(sentinel, data); // 在哨兵节点后插入新节点
}// 尾插
void insertTail(HeadDualListNode* sentinel, LinkDataType data) {insertBefore(sentinel, data); // 在哨兵节点前插入新节点
}// 删除指定节点
void removeNode(HeadDualListNode* node) {node->prev->next = node->next; // 前驱节点的 next 指向后继节点node->next->prev = node->prev; // 后继节点的 prev 指向前驱节点free(node); // 释放当前节点的内存
}// 头删
void removeHead(HeadDualListNode* sentinel) {if (sentinel->next != sentinel) { // 如果链表不为空removeNode(sentinel->next); // 删除哨兵节点的下一个节点(头节点)}
}// 尾删
void removeTail(HeadDualListNode* sentinel) {if (sentinel->prev != sentinel) { // 如果链表不为空removeNode(sentinel->prev); // 删除哨兵节点的前一个节点(尾节点)}
}// 遍历链表
void traverse(HeadDualListNode* sentinel) {HeadDualListNode* current = sentinel->next; // 从哨兵节点的下一个节点开始while (current != sentinel) { // 如果当前节点不是哨兵节点printf("%d ", current->data); // 打印当前节点的数据current = current->next; // 移动到下一个节点}printf("\n"); // 打印换行符
}// 打印链表详细信息
void printList(HeadDualListNode* sentinel) {HeadDualListNode* current = sentinel; // 从哨兵节点开始do {printf("HeadDualListNode: %d (prev: %d, next: %d)\n",current->data, current->prev->data, current->next->data); // 打印当前节点及其前后节点的数据current = current->next; // 移动到下一个节点} while (current != sentinel); // 如果当前节点不是哨兵节点
}// 销毁链表
void destroyList(HeadDualListNode* sentinel) {if (sentinel == NULL) { // 如果哨兵节点为空return; // 直接返回}HeadDualListNode* current = sentinel->next; // 从哨兵节点的下一个节点开始while (current != sentinel) { // 如果当前节点不是哨兵节点HeadDualListNode* nextNode = current->next; // 保存下一个节点free(current); // 释放当前节点的内存current = nextNode; // 移动到下一个节点}free(sentinel); // 释放哨兵节点的内存
}3. main.c
#include "LinkedList.h"int main() {HeadDualListNode* sentinel;initialize(&sentinel); // 初始化链表insertHead(sentinel, 10); // 头插 10insertHead(sentinel, 20); // 头插 20insertTail(sentinel, 30); // 尾插 30insertTail(sentinel, 40); // 尾插 40printf("遍历链表: ");traverse(sentinel); // 遍历链表printf("打印链表详细信息:\n");printList(sentinel); // 打印链表详细信息removeHead(sentinel); // 头删removeTail(sentinel); // 尾删printf("删除头尾节点后遍历链表: ");traverse(sentinel); // 遍历链表destroyList(sentinel); // 销毁链表return 0;
}参考文章
C语言之数据结构:链表(一)


相关文章:
C语言之数据结构:双向链表
个人主页:云纳星辰怀自在 座右铭:“所谓坚持,就是觉得还有希望!” 前言 前文阐述了数据结构中单向链表的定义、分类和实际应用。本文将重点阐述带哨兵节点的双向循环链表。 1. 带头双向循环链表 带头双向循环链表 是一种特殊的链…...

剑指Offer62 -- 约瑟夫环
1. 题目描述 圆圈中最后剩下的数字 2. 约瑟夫环 人们站在一个等待被处决的圈子里。 计数从圆圈中的指定点开始,并沿指定方向围绕圆圈进行。 在跳过指定数量的人之后,处刑下一个人。 对剩下的人重复该过程,从下一个人开始,朝同一方…...

RAG生成中的多文档动态融合及去重加权策略探讨
目录 RAG生成中的多文档动态融合及去重加权策略探讨 一、RAG生成概述 二、多文档动态融合策略 1. 拼接与分段编码 2. 独立编码与后续融合 3. 基于查询的动态加权 三、检索结果的去重与加权策略 1. 去重策略 2. 加权策略 四、实践中的挑战与思考 五、结语 RAG生成中的…...

jdk21使用Vosk实现语音文字转换,免费的语音识别
1.下载vosk的model vosk官网:https://alphacephei.com/vosk/models 我这里使用较小的vosk-model-small-cn-0.22 2.添加相关pom文件 <!-- 获取音频信息 --><dependency><groupId>org</groupId><artifactId>jaudiotagger</artifac…...

I.MX6ULL 开发板上挂载NTFS格式 U 盘
I.MX6ULL 开发板上挂载NTFS格式 U 盘 挂载失败安装NTFS-3G安装失败成功安装 移植挂载成功卸载U盘 挂载失败 我使用的U盘的格式是NTFS格式的 插入U盘时会有信息 我使用的是闪迪的U盘,大小标称是 32G ,实际能用的只有 28G 左右 可以使用lsblk命令查看磁盘…...

性能测试~
1.什么是性能测试 1.什么是性能 就像这两个车一样,虽然都是代步工具,构造都是一样的,但是路虎的发动机要比捷达好.路虎的百米加速却是比捷达快的,我们就知道路虎的性能要比捷达好 . 那么什么是软件的性能呢?我们分析一下 2.常见的性能测试指标 2.1并发数 并发数是指在同一…...

排查使用RestTemplate远程调用,@RequestBody注解接收不到实体类
做项目学习,使用RestTemplate远程调用,从order订单系统调用pay支付系统,出现使用Request做远程接收。 代码的逻辑很简单,但就是没有接收到实体类 1. 猜想是不是没有序列化和初始化方法? 这个好排查,看Pay和…...

数据库同步中间件PanguSync:如何跳过初始数据直接进行增量同步
某些用户在使用数据库同步中间件PanguSync时说,我不想进行初次的全量同步,我已经源备份还原到目标库了,两边初始数据一样,想跳过初始数据,直接进行增量同步,该怎么设置。 直接上干货,按如下步骤…...

javaWeb Router
一、路由简介 1、什么是路由? - 定义:路由就是根据不同的 URL 地址展示不同的内容或页面。 - 通俗理解:路由就像是一个地图,我们要去不同的地方,需要通过不同的路线进行导航。 2、路由的作用 - 单页应用程序…...

qwen2.5vl技术报告解读
一. 首先qwen2.5vl模型特点 全能文档解析能力 升级文本识别至全场景文档解析,擅长处理多场景、多语种及复杂版式文档(含手写体、表格、图表、化学方程式、乐谱等),实现跨类型文档的精准解析。 跨格式精准目标定位 突破格式限制,大幅提升对象检测、坐标定位与数量统计精度,…...

【Linux】进程的详讲(上)
目录 📖1、冯诺依曼体系结构 📖2、硬件介绍 📖3、内存的重要性 📖4、程序运行的步骤 📖5、QQ聊天时的数据流动 📖6、操作系统 📖7、操作系统的目的 📖8、操作系统是如何…...

高精度除法
除数与被除数都是大整数 代码 #include<bits/stdc.h> using namespace std; typedef long long ll; string a,b; vector<int>dend,sor; bool aisbigger(vector<int>&a,vector<int>&b){if(a.size()!b.size())return a.size()>b.size();for…...

Android面试总结之Glide源码级理解
当你的图片列表在低端机上白屏3秒、高端机因内存浪费导致FPS腰斩时,根源往往藏在Glide的内存分配僵化、磁盘混存、网络加载无优先级三大致命缺陷中。 本文从阿里P8级缓存改造方案出发,结合Glide源码实现动态内存扩容、磁盘冷热分区、智能预加载等黑科技&…...

Pyside6 开发 使用Qt Designer
使用Qt Designer 在Scripts目录下打开pyside6-designer.exe 分别将姓名、年龄、爱好对应的输入框的ObjectName 设置为 uname、uage、ulike 提交按钮Object设置为 btnSubmit 点击保存文件 ,命名为student.ui 将.ui文件编程成.py文件 pyside6-uic student.ui -o st…...

PyQt6实例_批量下载pdf工具_使用pyinstaller与installForge打包成exe文件
目录 前置: 步骤: step one 准备好已开发完毕的项目代码 step two 安装pyinstaller step three 执行pyinstaller pdfdownload.py,获取初始.spec文件 step four 修改.spec文件,将data文件夹加入到打包程序中 step five 增加…...

局域网共享失败?打印机/文件夹共享工具
很多时候,在办公或家庭环境中,我们需要进行打印机和文件夹的共享,以便更高效地协作和处理文件。然而,寻找对应版本的共享设置或是不想花费太多时间去进行复杂的电脑设置,总是让人感到头疼。今天,我要向大家…...

DeepSeek-V3-250324: AI模型新突破,性能超越GPT-4.5
DeepSeek 于 3 月 25 日宣布完成 V3 模型的小版本升级,推出 DeepSeek-V3-250324 版本。新版本在推理能力、代码生成、中文写作及多模态任务上实现显著优化,尤其在数学和代码类评测中得分超越 GPT-4.5,引发行业高度关注。 DeepSeek-V3-250324…...

第R9周:阿尔兹海默症诊断(优化特征选择版)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 文章目录 1、导入数据2、数据处理2.1 患病占比2.2 相关性分析2.3 年龄与患病探究 3、特征选择4、构建数据集4.1 数据集划分与标准化4.2 构建加载 5、构建模型6…...

19726 星际旅行
19726 星际旅行 ⭐️难度:困难 🌟考点:Dijkstra、省赛、最短路问题、期望、2024 📖 📚 import java.util.*;public class Main {static int N 1005;static ArrayList<Integer>[] g new ArrayList[N]; // …...

DeepSeek大模型应用开发新模式
DeepSeek大模型应用全景技术架构 DeepSeek大模型 VS 主流大模型 DeepSeek大模型系统提示词 VS 主流大模型 DeepSeek大模型迭代版本 DeepSeek专业化模型分类 DeepSeek大模型部署所需显存资源 DeepSeek不同参数模型及应用场景 DeepSeek大模型安装部署技术选型...

代码随想录动态规划05
74.一和零 视频讲解:动态规划之背包问题,装满这个背包最多用多少个物品?| LeetCode:474.一和零_哔哩哔哩_bilibili 代码随想录 给你一个二进制字符串数组 strs 和两个整数 m 和 n 。 请你找出并返回 strs 的最大子集的大小&#…...

Next.js 深度解析:全栈React框架的架构哲学与实践精髓
Next.js 作为 React 生态中最流行的全栈框架,已经超越了简单的SSR工具,发展成为完整的Web开发解决方案。以下从八个维度进行深度剖析: 一、核心架构设计 双引擎驱动模型 页面路由系统:基于文件系统的约定式路由渲染引擎ÿ…...

Node.js Express 处理静态资源
目录 1. 什么是静态资源? 2. 安装 Express 3. 目录结构 4. 创建 server.js 5. 创建 public/index.html 6. 创建 public/style.css 7. 创建 public/script.js 8. 运行服务器 9. 结语 1. 什么是静态资源? 静态资源指的是 HTML、CSS、JavaScript、…...

2025企业级项目设计三叉戟:权限控制+错误监控+工程化提效实战指南
一、权限系统设计:动态路由与按钮级控制的终极方案 1. 权限系统架构设计痛点 路由权限滞后:传统方案需页面加载后动态计算路由表,导致首屏白屏时间增加30%按钮颗粒度不足:基于角色的权限控制(RBAC)无法满…...

DeepSeek-V3新版本DeepSeek-V3-0324
中国人工智能初创公司深度求索(DeepSeek)2025年3月24日深夜低调上线了DeepSeek-V3的新版本DeepSeek-V3-0324,参数量为6850亿,在代码、数学、推理等多个方面的能力再次显著提升,甚至代码能力追平美国Anthropic公司大模型…...

108回回目设计
由于108回完整目录篇幅极长,我将以分卷缩略核心回目详解形式呈现,既保证完整性,又避免信息过载。以下是凝练后的完整框架与部分代表性回目: 第一卷:京口草鞋摊的野望(1-36回) 核心矛盾…...

探索:如何构建一个自我的AI辅助的开发环境?
构建支持AI的开发辅助环境并实现全流程自动化,需要整合开发工具链、AI模型服务和自动化流水线。以下是分步实施指南,包含关键技术栈和架构设计: 一、开发环境基础架构 1. 工具链集成平台 #mermaid-svg-RFSaibQJwVEcW9fT {font-family:"…...

国产RISC-V车规芯片当前现状分析——从市场与技术角度出发
摘要 随着汽车产业的智能化、电动化转型加速,车规级芯片的战略地位日益凸显。RISC-V指令集凭借其开源、灵活、低功耗等优势,成为国产车规芯片的重要发展方向。本文从市场与技术两个维度出发,深入分析国产RISC-V车规芯片的现状。通过梳理国内…...

华为eNSP-配置静态路由与静态路由备份
一、静态路由介绍 静态路由是指用户或网络管理员手工配置的路由信息。当网络拓扑结构或者链路状态发生改变时,需要网络管理人员手工修改静态路由信息。相比于动态路由协议,静态路由无需频繁地交换各自的路由表,配置简单,比较适合…...
)
数据分析中,文件解析库解析内容样式调整(openpyxl 、tabulate)
CSV文件:使用Python标准库中的csv模块,通过简单的文本解析来读取数据。 Excel文件:使用专门的库(如openpyxl、xlrd)来解析复杂的文件格式,或者使用pandas库来简化读取过程。 openpyxl openpyxl 是一个 Pyt…...