【高并发内存池】第六弹---深入理解内存管理机制:ThreadCache、CentralCache与PageCache的回收奥秘
✨个人主页: 熬夜学编程的小林
💗系列专栏: 【C语言详解】 【数据结构详解】【C++详解】【Linux系统编程】【Linux网络编程】【项目详解】
目录
1、threadcache回收内存
2、centralcache回收内存
3、pagecache回收内存
1、threadcache回收内存
1、当某个线程申请的对象不用了,可以将其释放给thread cache,然后thread cache将该对象插入到对应哈希桶的自由链表当中即可。
2、但是随着线程不断的释放,对应自由链表的长度也会越来越长,这些内存堆积在一个thread cache中就是一种浪费,我们应该将这些内存还给central cache,这样一来,这些内存对其他线程来说也是可申请的,因此当thread cache某个桶当中的自由链表太长时我们可以进行一些处理。
3、如果thread cache某个桶当中自由链表的长度超过它一次批量向central cache申请的对象个数,那么此时我们就要把该自由链表当中的这些对象还给central cache。
// 释放内存对象
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);// 找到对应链表的桶,插入即可size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);// 当链表长度大于一次批量申请的内存时就开始还一段list给central cacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}当自由链表的长度大于一次批量申请的对象时,我们具体的做法就是,从该自由链表中取出一次批量个数的对象,然后将取出的这些对象还给central cache中对应的span即可。
// 释放对象时,链表过长时,回收内存回到中心缓存
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;// 从list取出批量个对象list.PopRange(start, end, list.MaxSize());// 将取出的对象还给central cache对应的spanCentralCache::GetInstance()->ReleaseListToSpans(start, size);
}从上述代码可以看出,FreeList类需要支持用Size函数获取自由链表中对象的个数,还需要支持用PopRange函数从自由链表中取出指定个数的对象。因此我们需要给FreeList类增加一个对应的PopRange函数,然后再增加一个_size成员变量,该成员变量用于记录当前自由链表中对象的个数,当我们向自由链表插入或删除对象时,都应该更新_size的值。
// 管理切分好的小块对象的自由链表
class FreeList
{
public:// 插入,头插void Push(void* obj){assert(obj);//*(void**)obj = _freeList;Next(obj) = _freeList; _freeList = obj;++_size;}// 删除,头删void* Pop(){assert(_freeList);void* obj = _freeList;_freeList = Next(obj);--_size;return obj;}// 头插一段范围的对象到自由链表void PushRange(void* start, void* end, size_t n){assert(start);assert(end);// 链接到自由链表头结点Next(end) = _freeList; _freeList = start; // 更新起点_size += n;}// 从自由链表获取一段范围的对象(头删)void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);// 头删start = _freeList;end = start;for (size_t i = 0; i < n - 1; i++){end = Next(end);}_freeList = Next(end); // 自由链表指向end的下一个对象Next(end) = nullptr; // 取出的一段链表尾结点指向空_size -= n;}// 判断自由链表是否为空bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}
private:void* _freeList = nullptr;size_t _maxSize = 1;size_t _size = 0; // 链表结点个数
};PopRange

对于FreeList类当中的PushRange成员函数,我们最好也像PopRange一样给它增加一个参数,表示插入对象的个数,不然我们这时还需要通过遍历统计插入对象的个数。

因此之前在调用PushRange的地方就需要修改一下,而我们实际就在一个地方调用过PushRange函数,并且此时插入对象的个数也是很容易知道的。当时thread cache从central cache获取了actualNum个对象,将其中的一个返回给了申请对象的线程,剩下的actualNum-1个挂到了thread cache对应的桶当中,所以这里插入对象的个数就是actualNum-1。
FetchFromCentralCache()函数修改:
// 从中心缓存获取对象
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1); if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(Next(start),end, actualNum - 1); // 修改部分return start;}
}说明一下:
1、当thread cache的某个自由链表过长时,我们实际就是把这个自由链表当中全部的对象都还给central cache了,但这里在设计PopRange接口时还是设计的是取出指定个数的对象,因为在某些情况下当自由链表过长时,我们可能并不一定想把链表中全部的对象都取出来还给central cache,这样设计就是为了增加代码的可修改性。
2、当我们判断thread cache是否应该还对象给central cache时,还可以综合考虑每个thread cache整体的大小。比如当某个thread cache的总占用大小超过一定阈值时,我们就将该thread cache当中的对象还一些给central cache,这样就尽量避免了某个线程的thread cache占用太多的内存。对于这一点,在tcmalloc当中就是考虑到了的。
2、centralcache回收内存
当thread cache中某个自由链表太长时,会将自由链表当中的这些对象还给central cache中的span。
注意:还给central cache的这些对象不一定都是属于同一个span的。central cache中的每个哈希桶当中可能都不止一个span,因此当我们计算出还回来的对象应该还给central cache的哪一个桶后,还需要知道这些对象到底应该还给这个桶当中的哪一个span。
如何根据对象的地址得到对象所在的页号?
某个页当中的所有地址除以页的大小都等该页的页号。比如我们这里假设一页的大小是100,那么地址0~99都属于第0页,它们除以100都等于0,而地址100~199都属于第1页,它们除以100都等于1。
如何找到一个对象对应的span?
虽然我们现在可以通过对象的地址得到其所在的页号,但是我们还是不能知道这个对象到底属于哪一个span。因为一个span管理的可能是多个页。
为了解决这个问题,我们可以建立页号和span之间的映射。由于这个映射关系在page cache进行span的合并时也需要用到,因此我们直接将其存放到page cache里面。这时我们就需要在PageCache类当中添加一个映射关系了,这里可以用C++当中的unordered_map进行实现,并且添加一个函数接口,用于让central cache获取这里的映射关系。
PageCache类当中新增的成员变量及其成员函数
// 单例模式
class PageCache
{
public:// 获取从对象到span的映射Span* MapObjectToSpan(void* obj);
private:std::unordered_map<PAGE_ID, Span*> _idSpanMap;
};每当page cache分配span给central cache时,都需要记录一下页号和span之间的映射关系。此后当thread cache还对象给central cache时,才知道应该具体还给哪一个span。
因此当central cache在调用NewSpan接口向page cache申请k页的span时,page cache在返回这个k页的span给central cache之前,应该建立这k个页号与该span之间的映射关系。
// 获取一个K页的span(加映射版本)
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES); // 保证在桶的范围内// 1.检查第k个桶里面有没有Span,有则返回if (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();// 建立页号与span的映射,方便central cache回收小块内存查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageID + i] = kSpan;}return kSpan;}// 2.检查一下后面的桶里面有没有span,有则将其切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;// 在nSpan的头部切一个k页下来kSpan->_pageID = nSpan->_pageID;kSpan->_n = k;// 更新nSpan位置nSpan->_pageID += k;nSpan->_n -= k;// 将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);for (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageID + i] = kSpan;}return kSpan;}}// 3.没有大页的span,找堆申请128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1); // 申请128页内存bigSpan->_pageID = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1; // 页数// 将128页span挂接到128号桶上_spanLists[bigSpan->_n].PushFront(bigSpan);// 递归调用自己(避免代码重复)return NewSpan(k);
}此时我们就可以通过对象的地址找到该对象对应的span了,直接将该对象的地址除以页的大小得到页号,然后在unordered_map当中找到其对应的span即可。
// 获取从对象到span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT; // 计算页号auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}
}注意:当我们要通过某个页号查找其对应的span时,该页号与其span之间的映射一定是建立过的,如果此时我们没有在unordered_map当中找到,则说明我们之前的代码逻辑有问题,因此当没有找到对应的span时可以直接用断言结束程序,以表明程序逻辑出错。
central cache回收内存
1、当thread cache还对象给central cache时,就可以依次遍历这些对象,将这些对象插入到其对应span的自由链表当中,并且及时更新该span的_usseCount计数即可。
2、在thread cache还对象给central cache的过程中,如果central cache中某个span的_useCount减到0时,说明这个span分配出去的对象全部都还回来了,那么此时就可以将这个span再进一步还给page cache。
// 将一定数量的对象释放到span
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size); // 计算桶的下标_spanLists[index]._mtx.lock(); // 加桶锁while (start){void* next = Next(start); // 记录下一个结点// 获取从对象到span的映射Span* span = PageCache::GetInstance()->MapObjectToSpan(start);// 将对象头插到span自由链表Next(start) = span->_freeList;span->_freeList = start;span->_useCount--; // 更新被分配给thread cache的计数// 说明这个span分配出去的对象全部都还回来了if (span->_useCount == 0){// 此时这个span就可以再回收给page cache,page cache可以再尝试去做前后页合并_spanLists[index].Erase(span);span->_freeList = nullptr; // 自由链表置空span->_next = nullptr;span->_prev = nullptr;// 释放span给page cache时,使用page cache的锁即可,这是把桶锁解掉_spanLists[index]._mtx.unlock(); // 解除桶锁PageCache::GetInstance()->_pageMtx.lock(); // 加大锁PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock(); // 解除大锁_spanLists[index]._mtx.lock(); // 加桶锁}start = next; // 迭代到下一个结点}_spanLists[index]._mtx.unlock(); // 解除桶锁
}引用计数不为0

注意:
如果要把某个span还给page cache,我们需要先将这个span从central cache对应的双链表中移除,然后再将该span的自由链表置空,因为page cache中的span是不需要切分成一个个的小对象的,以及该span的前后指针也都应该置空,因为之后要将其插入到page cache对应的双链表中。但span当中记录的起始页号以及它管理的页数是不能清除的,否则对应内存块就找不到了。
在central cache还span给page cache时也存在锁的问题,此时需要先将central cache中对应的桶锁解掉,然后再加上page cache的大锁之后才能进入page cache进行相关操作,当处理完毕回到central cache时,除了将page cache的大锁解掉,还需要立刻加上central cache对应的桶锁,然后将还未还完对象继续还给central cache中对应的span。
3、pagecache回收内存
1、如果central cache中有某个span的_useCount减到0了,那么central cache就需要将这个span还给page cache了。
2、这个过程看似是非常简单的,page cache只需将还回来的span挂到对应的哈希桶上就行了。但实际为了缓解内存碎片的问题,page cache还需要尝试将还回来的span与其他空闲的span进行合并。
page cache进行前后页的合并分析
合并的过程可以分为向前合并和向后合并。如果还回来的span的起始页号是num,该span所管理的页数是n。那么在向前合并时,就需要判断第num-1页对应span是否空闲,如果空闲则可以将其进行合并,并且合并后还需要继续向前尝试进行合并,直到不能进行合并为止。而在向后合并时,就需要判断第num+n页对应的span是否空闲,如果空闲则可以将其进行合并,并且合并后还需要继续向后尝试进行合并,直到不能进行合并为止。
因此page cache在合并span时,是需要通过页号获取到对应的span的,这就是我们要把页号与span之间的映射关系存储到page cache的原因。
注意:
当我们通过页号找到其对应的span时,这个span此时可能挂在page cache,也可能挂在central cache。而在合并时我们只能合并挂在page cache的span,因为挂在central cache的span当中的对象正在被其他线程使用。
可是我们不能通过span结构当中的_useCount成员,来判断某个span到底是在central cache还是在page cache。因为当central cache刚向page cache申请到一个span时,这个span的_useCount就是等于0的,这时可能当我们正在对该span进行切分的时候,page cache就把这个span拿去进行合并了,这显然是不合理的。
基于上面的分析,我们可以在span结构中再增加一个_isUse成员,用于标记这个span是否正在被使用,而当一个span结构被创建时我们默认该span是没有被使用的。
// 管理多个连续页大块内存跨度结构
struct Span
{PAGE_ID _pageID = 0; // 大块内存起始页的页号size_t _n = 0; // 页的数量Span* _next = nullptr; // 双向链表结构Span* _prev = nullptr;size_t _useCount = 0; // 切好的小内存块,被分配给thread cache的计数void* _freeList = nullptr; // 切好的小块内存的自由链表bool _isUse = false; // 是否在被使用
};当central cache向page cache申请到一个span时(CentralCache::GetOneSpan函数),需要立即将该span的_isUse改为true。
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{//...Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));span->_isUse = true; // 设置为truePageCache::GetInstance()->_pageMtx.unlock();//...
}当central cache将某个span还给page cache时(PageCache::ReleaseSpanToPageCache函数),也就需要将该span的_isUse改成false。
// 释放空闲的span回到PageCache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{//...span->_isUse = false;
}由于在合并page cache当中的span时,需要通过页号找到其对应的span,而一个span是在被分配给central cache时,才建立的各个页号与span之间的映射关系,因此page cache当中的span也需要建立页号与span之间的映射关系。
与central cache中的span不同的是,在page cache中,只需建立一个span的首尾页号与该span之间的映射关系。因为当一个span在尝试进行合并时,如果是往前合并,那么只需要通过一个span的尾页找到这个span,如果是向后合并,那么只需要通过一个span的首页找到这个span。也就是说,在进行合并时我们只需要用到span与其首尾页之间的映射关系就够了。
因此当我们申请k页的span时,如果是将n页的span切成了一个k页的span和一个n-k页的span,我们除了需要建立k页span中每个页与该span之间的映射关系之外,还需要建立剩下的n-k页的span与其首尾页之间的映射关系。
// 获取一个K页的span(加映射版本)
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES); // 保证在桶的范围内// 1.检查第k个桶里面有没有Span,有则返回if (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();// 建立页号与span的映射,方便central cache回收小块内存查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageID + i] = kSpan;}return kSpan;}// 2.检查一下后面的桶里面有没有span,有则将其切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;// 在nSpan的头部切一个k页下来kSpan->_pageID = nSpan->_pageID;kSpan->_n = k;// 更新nSpan位置nSpan->_pageID += k;nSpan->_n -= k;// 将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);for (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageID + i] = kSpan;}return kSpan;}}// 3.没有大页的span,找堆申请128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1); // 申请128页内存bigSpan->_pageID = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1; // 页数// 将128页span挂接到128号桶上_spanLists[bigSpan->_n].PushFront(bigSpan);// 递归调用自己(避免代码重复)return NewSpan(k);
}相关文章:
【高并发内存池】第六弹---深入理解内存管理机制:ThreadCache、CentralCache与PageCache的回收奥秘
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】【Linux系统编程】【Linux网络编程】【项目详解】 目录 1、threadcache回收内存 2、centralcache回收内存 3、pagecache回收内存 1、threadcache回收内…...
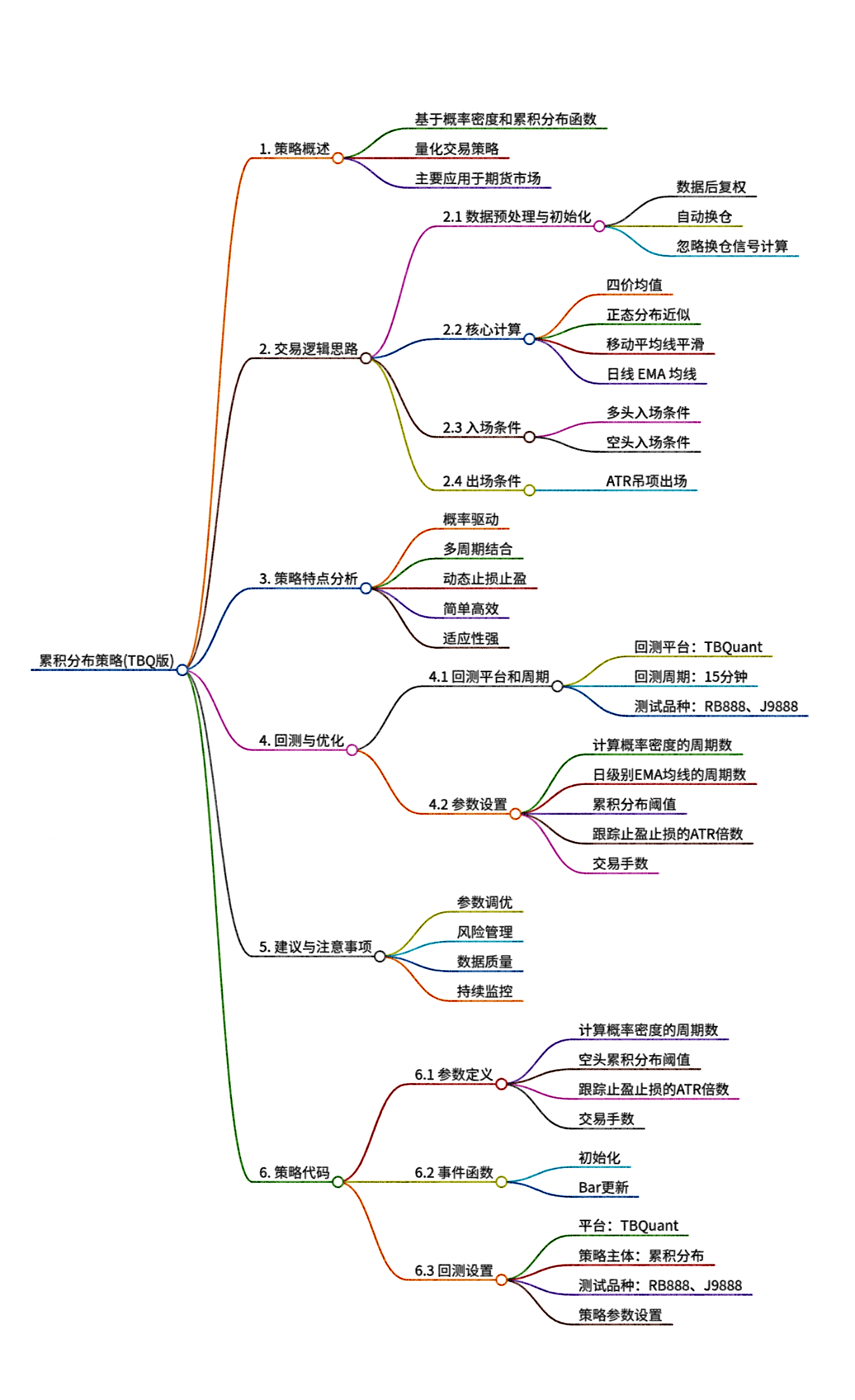
累积分布策略思路
一种基于概率密度和累积分布函数的量化交易策略,主要应用于期货市场。该策略通过计算价格数据的概率密度和累积分布函数(CDF),结合移动平均线和ATR(平均真实范围)等技术指标,实现多空交易的自动…...

【JavaScript】九、JS基础练习
文章目录 1、练习:对象数组的遍历2、练习:猜数字3、练习:生成随机颜色 1、练习:对象数组的遍历 需求:定义多个对象,存数组,遍历数据渲染生成表格 let students [{ name: 小明, age: 18, gend…...

RAG、大模型与智能体的关系
一句话总结: RAG(中文为检索增强生成) 检索技术 LLM 提示。 RAG、大模型与智能体的关系解析 1. 核心概念定义 RAG(检索增强生成) 是一种结合信息检索与生成式模型的框架,通过从外部知识库(如…...

使用firewall-cmd配置SIP端口转发,实现双网卡互通,内外网方式
使用firewall-cmd配置SIP端口转发,实现双网卡,内外网方式 脚本内容 这里以内网IP: 192.168.2.88 这里以外网IP: 10.3.3.3 以下是一个用于启用和停用端口转发的Shell脚本: #!/bin/bash# 配置变量 ZONE"public" TARGET_IP"192.168.2.88" POR…...

Oracle数据库数据编程SQL<3.2 PL/SQL 匿名块中的DML操作、动态SQL、实际应用场景、使用技巧>
匿名块是学习和测试PL/SQL代码的强大工具,特别适合执行一次性任务或快速验证业务逻辑。 目录 一、匿名块中的DML操作 1. INSERT 示例 2. UPDATE 示例 3. DELETE 示例 二、匿名块中的动态SQL 1. EXECUTE IMMEDIATE 2. 动态游标--下篇文章会具体展开详细分享该…...

Spring AI Alibaba 实战:集成 OpenManus 实现智能体应用开发
引言 2024 年 9 月,阿里云正式开源 Spring AI Alibaba,为 Java 开发者提供了一套完整的 AI 应用开发框架,支持与通义系列大模型深度集成,并覆盖了从模型调用到云原生部署的全链路能力。而近期,中国团队发布的通用型 A…...

Linux中《进程状态--进程调度--进程切换》详细介绍
目录 进程状态Linux内核源代码怎么说运行&&阻塞&&挂起内核链表 进程状态查看Z(zombie)-僵尸进程僵尸进程危害孤儿进程 进程优先级进程切换Linux2.6内核进程O(1)调度队列 进程状态 Linux内核源代码怎么说 为了弄明白正在运⾏的进程是什么意思,我们…...

Element PlusAnt-design常问问题详解
Element UI Plus 高频面试问题解析(2025 版) 一、核心组件使用与原理 动态表头实现方案 • 场景:如何根据接口数据动态生成表头? • 技术方案: ◦ 使用 v-for 遍历表头数组生成 el-table-column ◦ 结合 render-header 属性实现复杂表头(如带提示的标题) ◦ 示例代码:通…...
】打造商城监控利器Prometheus与Grafana)
【商城实战(96)】打造商城监控利器Prometheus与Grafana
【商城实战】专栏重磅来袭!这是一份专为开发者与电商从业者打造的超详细指南。从项目基础搭建,运用 uniapp、Element Plus、SpringBoot 搭建商城框架,到用户、商品、订单等核心模块开发,再到性能优化、安全加固、多端适配…...

Megatron-LM中的deepseek-v3实现
Megatron-LM:https://github.com/NVIDIA/Megatron-LM/tree/main 使用此仓库构建的著名的库也有很多,如: Colossal-AI, HuggingFace Accelerate, and NVIDIA NeMo Framework.Pai-Megatron-Patch工具是阿里人工智能平台PAI算法团队研发,ai-Megatron-Patch…...

SpringCloud如何整合DeepSeek
SpringCloud 整合 DeepSeek 的核心目标是通过微服务架构调用其分布式文件系统(如 3FS)或 API 服务。以下从技术选型、整合步骤和关键配置三个方面展开说明: 一、技术选型与架构分析 DeepSeek 服务类型 3FS 分布式文件系统:基于 RD…...

蓝桥杯备考:多米诺骨牌
这道题要求上下方格子和之差要最小,其实就是算每个上下格子的差求和的最小值 这道题其实是动态规划01背包问题 我们直接按步骤做吧 step1:定义状态表示f[i][j]表示从1到i个编号的差值里选出刚好j个数的最小操作次数 step2:推导状态转移方程 如图这就是我们的状态…...

wireshark开启对https密文抓包
HTTPS抓包解密指南 通常情况下,Wireshark只能抓取HTTP的明文包,对于HTTPS的报文需要特殊设置才能抓取。如果不进行设置,抓取到的都是TLS加密报文,这对调试工作造成了很大困难。 前言 提到HTTPS抓包,基本都绕不开SSL…...

AudioFlinger与AudioPoliceManager初始化流程
AF/APF启动流程 在启动AudioSeriver服务的过程中会对启动AF/APF。main_audioserver.cpp有如下代码: AudioFlinger::instantiate();AudioPolicyService::instantiate();AF初始化流程 1.AudioFlinger::instantiate() 1.1 AudioFlinger构造函数 void AudioFlinger:…...

网路传输层UDP/TCP
一、端口号 1.端口号 1.1 五元组 端口号(port)标识了一个主机上进行通信的不同的应用程序. 如图所示, 在一个机器上运行着许多进程, 每个进程使用的应用层协议都不一样, 比如FTP, SSH, SMTP, HTTP等. 当主机接收到一个报文中, 网络层一定封装了一个目的ip标识我这台主机, …...

Python大数据处理 基本的编程方法
目录 一、实验目的 二、实验要求 三、实验代码 四、实验结果 五、实验体会 一、实验目的 体会基本的python编程方法;学习python中的各类函数;了解python读取与写入文件的方法。 二、实验要求 输入2000年后的某年某月某日,判断这一天是…...

STM32F103_LL库+寄存器学习笔记06 - 梳理串口与串行发送“Hello,World“
导言 USART是嵌入式非常重要的通讯方式,它的功能强大、灵活性高且用途广泛。只停留在HAL库层面上用USART只能算是入门,要加深对USART的理解,必须从寄存器层面入手。接下来,先从最简单的USART串行发送开始。 另外,在接…...

硬件基础--14_电功率
电功率 电功率:指电流在单位时间内做的功(表示用电器消耗电能快慢的一个物理量)。 单位:瓦特(W),简称瓦。 公式:PUI(U为电压,单位为V,i为电流,单位为A,P为电功率,单位为W)。 单位换算:进位为1000ÿ…...

【C#语言】C#文件操作实战:动态路径处理与安全写入
文章目录 ⭐前言⭐一、场景痛点⭐二、完整实现代码⭐三、关键技术解析🌟1、动态路径处理🌟2、智能目录创建🌟3、安全的文件写入 ⭐四、进阶扩展方案🌟1、用户自定义路径选择🌟2、异常处理增强🌟3、异步写入…...
Vue.js 完全指南:从入门到精通
1. Vue.js 简介 1.1 什么是 Vue.js? Vue.js(通常简称为 Vue)是一个用于构建用户界面的渐进式 JavaScript 框架。所谓"渐进式",意味着 Vue 的设计是由浅入深的,你可以根据自己的需求选择使用它的一部分或全部功能。 Vue 最初由尤雨溪(Evan You)在 2014 年创…...

在Git仓库的Readme上增加目录页
一般在编写Readme时想要增加像文章那样的目录,方便快速跳转,但是Markdown语法并没有提供这样的方法,但是可以通过超链接结合锚点的方式来实现,如下图是我之前一个项目里写的Readme: 例如有下面几个Readme内容ÿ…...

C# SolidWorks 二次开发 -各种菜单命令增加方式
今天给大家讲一讲solidworks中各种菜单界面,如下图,大概有13处,也许还不完整哈。 1.CommandManager选项卡2.下拉选项卡3.菜单栏4.下级菜单5.浮动工具栏6.快捷方式工具栏7.FeatureManager工具栏区域8.MontionManager区域 ModelView?9.任务窗…...

分布式架构-Spring技术如何能实现分布式事务
在Spring技术栈中实现分布式事务,可通过多种成熟方案实现跨服务或跨数据库的事务一致性管理。以下是主要实现方式及技术要点: 一、基于Seata框架的AT模式 核心组件 TC (Transaction Coordinator):全局事务协调器(独立部署…...

【RocketMQRocketMQ Dashbord】Springboot整合RocketMQ
【RocketMQ&&RocketMQ Dashbord】Springboot整合RocketMQ 【一】Mac安装RocketMQ和RocketMQ Dashbord【1】安装RocketMQ(1)下载(2)修改 JVM 参数(3)启动测试(4)关闭测试&…...

vue 3 深度指南:从基础到全栈开发实践
目录 一、环境搭建与项目初始化 1. 前置依赖安装 2. 项目初始化与结构解析 二、核心概念与语法深度解析 1. MVVM 模式与响应式原理 2. 模板语法与指令进阶 3. 组件化开发 三、进阶开发与全栈集成 1. 路由管理(Vue Router) 2. 状态管理…...

《白帽子讲 Web 安全》之跨站请求伪造
引言 在数字化时代,网络已深度融入人们生活的方方面面,Web 应用如雨后春笋般蓬勃发展,为人们提供着便捷高效的服务。然而,繁荣的背后却潜藏着诸多安全隐患,跨站请求伪造(CSRF)便是其中极为隐蔽…...

K8S学习之基础五十:k8s中pod时区问题并通过kibana查看日志
k8s中pod默认时区不是中国的,挂载一个时区可以解决 vi pod.yaml apiVersion: v1 kind: Pod metadata:name: counter spec:containers:- name: countimage: 172.16.80.140/busybox/busybox:latestimagePullPolicy: IfNotPresentargs: [/bin/sh,-c,i0;while true;do …...

nginx代理前端请求
一,项目配置 我在 ip 为 192.168.31.177 的机器上使用 vue3 开发前端项目,项目中使用 axios 调用后端接口。 这是 axios 的配置: import axios from axios;const request axios.create({baseURL: http://192.168.31.177:8001,// 设置请求…...

LibVLC —— 《基于Qt的LibVLC专业开发技术》视频教程
🔔 LibVLC/VLC 相关技术、疑难杂症文章合集(掌握后可自封大侠 ⓿_⓿)(记得收藏,持续更新中…) 《基于Qt的LibVLC专业开发技术》课程视频,(CSDN课程主页、51CTO课程主页) 适合具有一些C++/Qt编程基础,想要进一步提高或涉足音视频行业的。本课程分7章节,共计35小节。…...