分布式ID服务实现全面解析
分布式ID生成器是分布式系统中的关键基础设施,用于在分布式环境下生成全局唯一的标识符。以下是各种实现方案的深度解析和最佳实践。


一、核心需求与设计考量
1. 核心需求矩阵
| 需求 | 重要性 | 实现难点 |
| 全局唯一 | 必须保证 | 时钟回拨/节点冲突 |
| 高性能 | 高并发场景关键 | 锁竞争/网络开销 |
| 有序性 | 分页查询友好 | 时间戳精度问题 |
| 高可用 | 服务不可中断 | 故障转移/数据恢复 |
| 易用性 | 接入成本低 | 协议兼容性 |
2. 典型业务场景
- 电商订单号生成
- 金融交易流水号
- 物联网设备标识
- 分布式日志追踪
- 数据库分片键
二、主流实现方案对比
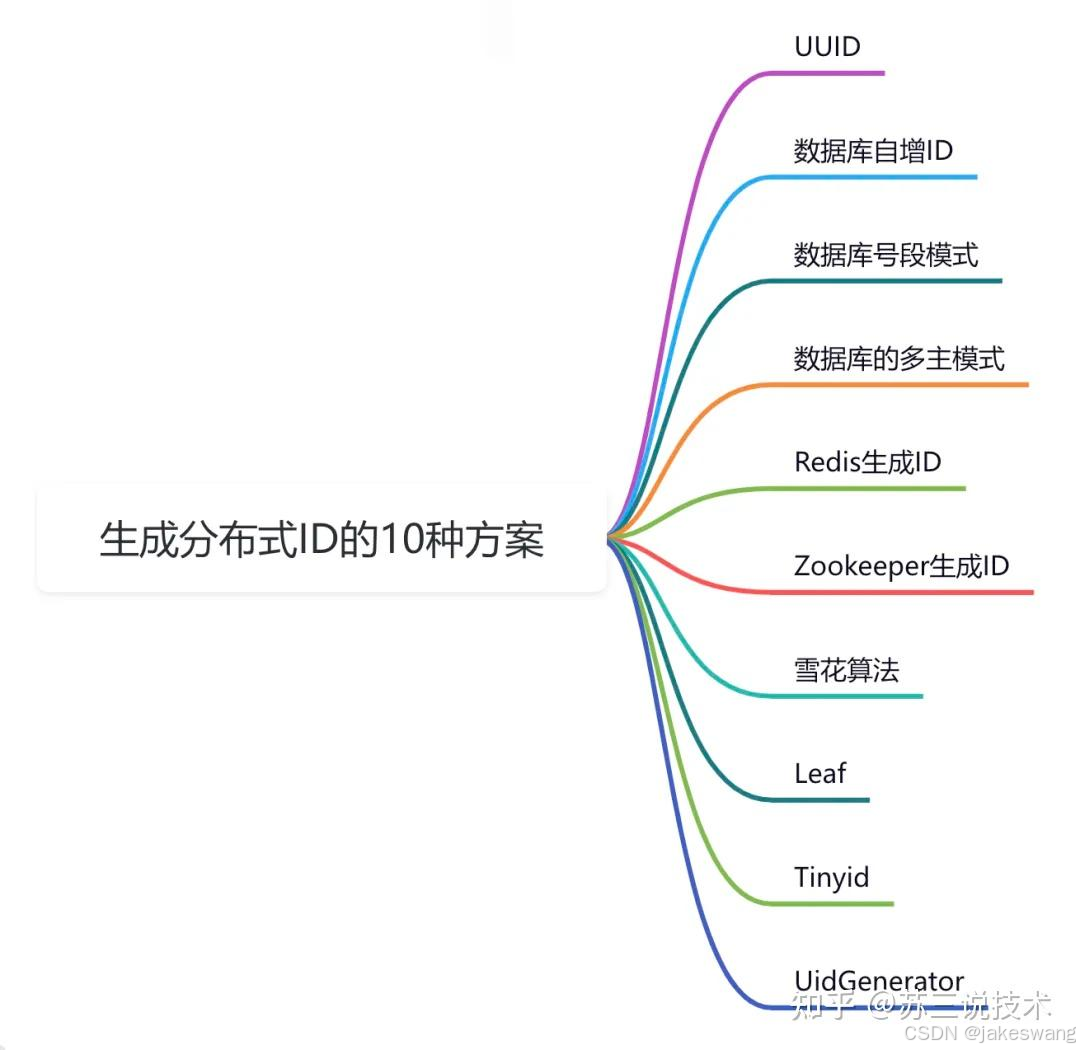
1. 方案全景图
mermaid
graph TDA[分布式ID] --> B[中心化]A --> C[去中心化]B --> D[数据库序列]B --> E[Redis原子操作]B --> F[Zookeeper节点]C --> G[UUID]C --> H[Snowflake]C --> I[Leaf/美团]2. 详细方案对比
| 方案 | 示例ID | 优点 | 缺点 | QPS |
| UUID |
| 无中心节点 | 无序存储效率低 | 100,000+ |
| 数据库自增 |
| 简单可靠 | 单点瓶颈 | 1,000~5,000 |
| Redis INCR |
| 性能较好 | 持久化问题 | 50,000~100,000 |
| Snowflake |
| 有序紧凑 | 时钟敏感 | 100,000+ |
| Leaf-Segment |
| 缓冲优化 | 需DB配合 | 50,000+ |
| Tinyid |
| 批量获取 | 强依赖ZK | 20,000+ |
三、Snowflake 深度实现
1. 标准位分配
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
|____________________________| |________| |_____| |________________________|时间戳(41bit) 数据中心(5bit) 机器ID(5bit) 序列号(12bit)2. Java优化实现
public class SnowflakeIdGenerator {private final long twepoch = 1288834974657L; // 起始时间戳(2010-11-04)private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;private final long sequenceBits = 12L;private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private volatile long lastTimestamp = -1L;private volatile long sequence = 0L;public synchronized long nextId() {long timestamp = timeGen();// 时钟回拨处理if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards");}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & ((1 << sequenceBits) - 1);if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}lastTimestamp = timestamp;return ((timestamp - twepoch) << (workerIdBits + sequenceBits)) | (datacenterId << (workerIdBits + sequenceBits))| (workerId << sequenceBits) | sequence;}protected long tilNextMillis(long lastTimestamp) {// 阻塞到下一毫秒long timestamp;do {timestamp = timeGen();} while (timestamp <= lastTimestamp);return timestamp;}
}3. 时钟回拨解决方案
| 方案 | 实现方式 | 适用场景 |
| 异常抛出 | 直接拒绝请求 | 严格要求时序 |
| 等待时钟 | 自旋直到时钟追回 | 短暂回拨(<100ms) |
| 备用ID池 | 提前生成备用ID | 容忍短暂无序 |
| 扩展位记录 | 增加回拨计数位 | 需要改造ID结构 |
四、Leaf-Segment 方案详解
1. 数据库设计
CREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) NOT NULL,`max_id` bigint NOT NULL DEFAULT '1',`step` int NOT NULL,`update_time` timestamp NOT NULL,PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;2. 双Buffer优化流程
sequenceDiagramparticipant Clientparticipant Serviceparticipant DBClient->>Service: 获取ID(biz_tag=order)Service->>DB: 查询当前max_id和stepDB-->>Service: max_id=1000, step=1000Service->>Service: 分配本地缓存[1001-2000]Service->>Client: 返回1001Service->>DB: 异步更新max_id=2000Note right of Service: Buffer1耗尽前<br>提前加载Buffer23. 异常处理机制
- DB故障:使用本地缓存直到耗尽
- ID耗尽:动态调整step大小
- 双Buffer同时失效:降级到同步获取
五、高性能服务架构
1. 服务化部署架构
+-----------------+| Load Balancer |+--------+--------+|+----------------+----------------+| | |+------+------+ +------+------+ +------+------+| ID Service | | ID Service | | ID Service |+------+------+ +------+------+ +------+------+| | |+------+------+ +------+------+ +------+------+| Redis | | DB | | Zookeeper |+-------------+ +------------+ +-------------+2. 性能优化技巧
| 技术 | 效果 | 实现示例 |
| 本地缓存 | 减少网络IO |
存储Segment |
| 批量获取 | 降低DB压力 |
|
| 异步持久化 | 提高吞吐 | 先响应后写WAL日志 |
| 分层设计 | 故障隔离 | 内存->Redis->DB 三级获取 |
3. 容灾方案对比
| 方案 | 恢复时间 | 数据丢失风险 |
| 主从同步 | 秒级 | 少量异步数据 |
| 多活部署 | 几乎为零 | 无 |
| 定期快照 | 分钟级 | 取决于备份频率 |
六、生产实践案例
案例1:电商订单ID
需求:
- 每日亿级订单
- 需要时间有序
- 包含业务类型信息
实现:
// 格式: 业务类型(2位) + 时间(yyMMddHHmm) + 序列(6位) + 机器(3位)
public String generateOrderId(String bizType) {String timePart = new SimpleDateFormat("yyMMddHHmm").format(new Date());long seq = redis.incr("order:id:" + timePart);return String.format("%s%s%06d%03d", bizType, timePart, seq % 1000000, machineId);
}import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;@Service
public class BufferedOrderIdGenerator {private final Queue<String> idPool = new ConcurrentLinkedQueue<>();private final RedisOrderIdGenerator redisGenerator;private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);private static final int BATCH_SIZE = 100;private static final int REFILL_THRESHOLD = 20;public BufferedOrderIdGenerator(RedisOrderIdGenerator redisGenerator) {this.redisGenerator = redisGenerator;this.scheduler.scheduleAtFixedRate(this::refillPool, 0, 1, TimeUnit.SECONDS);}public String getOrderId() {String id = idPool.poll();if (id == null) {// 缓冲池为空时同步获取return redisGenerator.generateOrderId();}return id;}private void refillPool() {if (idPool.size() < REFILL_THRESHOLD) {// 批量预生成IDString date = LocalDate.now().format(DATE_FORMAT);Long startSeq = redisTemplate.opsForValue().increment(ORDER_ID_PREFIX + date, BATCH_SIZE);for (long i = startSeq - BATCH_SIZE + 1; i <= startSeq; i++) {idPool.add(String.format(ID_FORMAT, date, i));}redisTemplate.expire(ORDER_ID_PREFIX + date, 48, TimeUnit.HOURS);}}
}import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.TimeUnit;@Service
public class RedisOrderIdGenerator {private final StringRedisTemplate redisTemplate;private static final String ORDER_ID_PREFIX = "order:id:";private static final DateTimeFormatter DATE_FORMAT = DateTimeFormatter.BASIC_ISO_DATE;// 订单ID格式:年月日(8位) + 序列号(8位)private static final String ID_FORMAT = "%s%08d"; public RedisOrderIdGenerator(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;}/*** 生成订单ID*/public String generateOrderId() {String date = LocalDate.now().format(DATE_FORMAT);String key = ORDER_ID_PREFIX + date;// 使用Redis原子操作INCRLong sequence = redisTemplate.opsForValue().increment(key);// 设置48小时过期(避免跨日期问题)redisTemplate.expire(key, 48, TimeUnit.HOURS);return String.format(ID_FORMAT, date, sequence);}
}import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.transaction.annotation.Transactional;@Service
public class PersistentOrderIdService {private final RedisOrderIdGenerator redisGenerator;private final JdbcTemplate jdbcTemplate;// WAL(Write-Ahead Log)表private static final String WAL_TABLE = "order_id_wal";public PersistentOrderIdService(RedisOrderIdGenerator redisGenerator, JdbcTemplate jdbcTemplate) {this.redisGenerator = redisGenerator;this.jdbcTemplate = jdbcTemplate;}/*** 带持久化保障的ID生成*/@Transactionalpublic String generatePersistentOrderId() {// 1. 先写入预写日志String pendingId = redisGenerator.generateOrderId();jdbcTemplate.update("INSERT INTO " + WAL_TABLE + " (order_id, create_time, status) VALUES (?, NOW(), 'PENDING')",pendingId);// 2. 确认写入Redis// 如果Redis操作失败会抛出异常触发事务回滚// 3. 更新日志状态jdbcTemplate.update("UPDATE " + WAL_TABLE + " SET status = 'CONFIRMED' WHERE order_id = ?",pendingId);return pendingId;}/*** 恢复未确认的ID*/@Scheduled(fixedRate = 60000) // 每分钟执行一次public void recoverPendingIds() {jdbcTemplate.query("SELECT order_id FROM " + WAL_TABLE + " WHERE status = 'PENDING' AND create_time > DATE_SUB(NOW(), INTERVAL 1 HOUR)",(rs, rowNum) -> rs.getString("order_id")).forEach(pendingId -> {if (!redisTemplate.hasKey(buildRedisKey(pendingId))) {redisTemplate.opsForValue().set(buildRedisKey(pendingId), extractSequence(pendingId));}});}private String buildRedisKey(String orderId) {return ORDER_ID_PREFIX + orderId.substring(0, 8); // 提取日期部分}private long extractSequence(String orderId) {return Long.parseLong(orderId.substring(8));}
}案例2:分布式追踪ID
需求:
- 全局唯一
- 高吞吐
- 可解析
实现(借鉴Twitter的Zipkin):
// 128-bit ID = 应用节点(32bit) + 时间(64bit) + 随机数(32bit)
public static String newTraceId() {return String.format("%08x%016x%08x",nodeId,System.currentTimeMillis(),ThreadLocalRandom.current().nextInt());
}七、监控与治理
1. 关键监控指标
| 指标 | 采集方式 | 告警阈值 |
| ID生成延迟 | Micrometer Timer | P99 > 10ms |
| 段缓存命中率 | 缓存统计 | <90% |
| 时钟偏移量 | NTP监控 | >50ms |
| DB连接池使用率 | Druid监控 | >80% |
2. 运维指令集
bash
# 动态调整Leaf步长
curl -X POST "http://id-service/segment/step?bizTag=order&step=5000"# 强制刷新缓存
redis-cli DEL leaf:order:cache# 节点下线
./admin.sh disableNode --nodeId=3八、选型决策树
mermaid
graph TDA[是否需要有序ID?] -->|是| B[考虑Snowflake/Leaf]A -->|否| C[考虑UUID]B --> D[QPS>10万?]D -->|是| E[Leaf-Segment+缓存]D -->|否| F[原生Snowflake]C --> G[需要可读性?]G -->|是| H[时间戳+序列组合]G -->|否| I[标准UUIDv4]通过深入理解这些实现方案和架构设计,可以构建出满足不同业务场景需求的分布式ID服务。建议根据实际业务规模、性能要求和运维能力进行技术选型。
相关文章:
分布式ID服务实现全面解析
分布式ID生成器是分布式系统中的关键基础设施,用于在分布式环境下生成全局唯一的标识符。以下是各种实现方案的深度解析和最佳实践。 一、核心需求与设计考量 1. 核心需求矩阵 需求 重要性 实现难点 全局唯一 必须保证 时钟回拨/节点冲突 高性能 高并发场景…...

dom0运行android_kernel: do_serror of panic----failed to stop secondary CPUs 0
问题描述: 从日志看出,dom0运行android_kernel,刚开始运行就会crash,引发panic 解决及其原因分析: 最终问题得到解决,发现是前期在调试汇编阶段代码时,增加了汇编打印的指令,注释掉这些指令,问题得到解决。…...

HarmonyOS NEXT——【鸿蒙原生应用加载Web页面】
鸿蒙客户端加载Web页面: 在鸿蒙原生应用中,我们需要使用前端页面做混合开发,方法之一是使用Web组件直接加载前端页面,其中WebView提供了一系列相关的方法适配鸿蒙原生与web之间的使用。 效果 web页面展示: Column()…...

HTML输出流
HTML 输出流 JavaScript 中**「直接写入 HTML 输出流」**的核心是通过 document.write() 方法向浏览器渲染过程中的数据流动态插入内容。以下是详细解释: 一、HTML 输出流的概念 1. 动态渲染过程 HTML 文档的加载是自上而下逐行解析的。当浏览器遇到 <script&…...

std::countr_zero
一 基本功能 1 作用 std::countr_zero 是 C++20 标准引入的位操作函数,用于计算无符号整数的二进制表示中末尾零(Trailing Zeros)的数量。 定义:位于 <bit> 头文件中,是标准库的一部分。 2 示例 #include <bit> unsigned int x = 12; // 二进…...

优选算法的慧根之翼:位运算专题
专栏:算法的魔法世界 个人主页:手握风云 一、位运算 基础位运算 共包含6种&(按位与,有0就是0)、|(按位或有1就是1)、^(按位异或,相同为0,相异为1)、~(按位取反,0变成1,1变成0)、<<(左…...

图论问题集合
图论问题集合 寻找特殊有向图(一个节点最多有一个出边)中最大环路问题特殊有向图解析算法解析步骤 1 :举例分析如何在一个连通块中找到环并使用时间戳计算大小步骤 2 :抽象成算法注意 实现 寻找特殊有向图(一个节点最多…...

【数据结构】栈 与【LeetCode】20.有效的括号详解
目录 一、栈1、栈的概念及结构2、栈的实现3、初始化栈和销毁栈4、打印栈的数据5、入栈操作---栈顶6、出栈---栈顶6.1栈是否为空6.2出栈---栈顶 7、取栈顶元素8、获取栈中有效的元素个数 二、栈的相关练习1、练习2、AC代码 个人主页,点这里~ 数据结构专栏,…...

实时目标检测新突破:AnytimeYOLO——随时中断的YOLO优化框架解析
目录 一、论文背景与核心价值 二、创新技术解析 2.1 网络结构革新:Transposed架构 2.2 动态路径优化算法 三、实验结果与性能对比 3.1 主要性能指标 3.2 关键发现 四、应用场景与部署实践 4.1 典型应用场景 4.2 部署注意事项 五、未来展望与挑战 一、论文背景与核心…...

Redis设计与实现-哨兵
哨兵模式 1、启动并初始化sentinel1.1 初始化服务器1.2 使用Sentinel代码1.3 初始化sentinel状态1.4 初始化sentinel状态的master属性1.5 创建连向主服务器的网络连接 2、获取主服务器信息3、获取从服务器的信息4、向主从服务器发送信息5、接受主从服务器的频道信息6、检测主观…...

C++进阶——封装哈希表实现unordered_map/set
与红黑树封装map/set基本相似,只是unordered_map/set是单向迭代器,模板多传一个HashFunc。 目录 1、源码及框架分析 2、模拟实现unordered_map/set 2.1 复用的哈希表框架及Insert 2.2 iterator的实现 2.2.1 iteartor的核心源码 2.2.2 iterator的实…...

第4.1节:使用正则表达式
1 第4.1节:使用正则表达式 将正则表达式用斜杠括起来,就能用作模式。随后,该正则表达式会与每条输入记录的完整文本进行比对。(通常情况下,它只需匹配文本的部分内容就能视作匹配成功。)例如,以…...
【算法day25】 最长有效括号——给你一个只包含 ‘(‘ 和 ‘)‘ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
32. 最长有效括号 给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。 https://leetcode.cn/problems/longest-valid-parentheses/ 2.方法二:栈 class Solution { public:int longestValid…...

Jenkins + CICD流程一键自动部署Vue前端项目(保姆级)
git仓库地址:参考以下代码完成,或者采用自己的代码。 南泽/cicd-test 拉取项目代码到本地 使用云服务器或虚拟机采用docker部署jenkins 安装docker过程省略 采用docker部署jenkins,注意这里的命令,一定要映射docker路径,否则无…...

C 语言的未来:在变革中坚守核心价值
一、从 “古老” 到 “长青”:C 语言的不可替代性 诞生于 20 世纪 70 年代的 C 语言,历经半个世纪的技术浪潮,至今仍是编程世界的 “基石语言”。尽管 Python、Java 等高级语言在应用层开发中占据主流,但 C 语言在系统级编程和资…...

一款超级好用且开源免费的数据可视化工具——Superset
认识Superset 数字经济、数字化转型、大数据等等依旧是如今火热的领域,数据工作有一个重要的环节就是数据可视化。 看得见的数据才更有价值! 现如今依旧有多数企业号称有多少多少数据,然而如果这些数据只是呆在冷冰冰的数据库或文件内则毫无…...

Vue3组合式API与选项式API的核心区别与适用场景
Vue.js作为现代前端开发的主流框架之一,在Vue3中引入了全新的组合式API(Composition API),与传统的选项式API(Options API)形成了两种不同的开发范式。在当前开发中的两个项目中分别用到了组合式和选项式,故记录一下。本文将全面剖析这两种AP…...

RedHatLinux(2025.3.22)
1、创建/www目录,在/www目录下新建name和https目录,在name和https目录下分别创建一个index.htm1文件,name下面的index.html 文件中包含当前主机的主机名,https目录下的index.htm1文件中包含当前主机的ip地址。 (1&…...

【C++篇】类与对象(上篇):从面向过程到面向对象的跨越
💬 欢迎讨论:在阅读过程中有任何疑问,欢迎在评论区留言,我们一起交流学习! 👍 点赞、收藏与分享:如果你觉得这篇文章对你有帮助,记得点赞、收藏,并分享给更多对C感兴趣的…...

深搜专题13:分割回文串
描述 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案数。 例如: 输入:“aab” 输出:2 2种方案数是[“a”,“a”,“b”]和[“aa”,“b”] 输入描述 一个字符串 s&#…...
 specified for column)
OGG故障指南:OGG-01163 Bad column length (xxx) specified for column
报错 OGG-01163 Bad column length (xxx) specified for column AAA in table OWNER.TABLE, maximum allowable length is yyy原因 源端修改了字段长度。 虽然源端和目标端的长度已经通过DDL语句修改到一致,在extract进程未重启的情况下,生成的trail文…...

智慧运维平台:赋能未来,开启高效运维新时代
在当今数字化浪潮下,企业IT基础设施、工业设备及智慧城市系统的复杂度与日俱增,传统人工运维方式已难以满足高效、精准、智能的管理需求。停机故障、低效响应、数据孤岛等问题直接影响企业运营效率和成本控制。大型智慧运维平台(AIOps, Smart…...

基于大语言模型的智能音乐创作系统——从推荐到生成
一、引言:当AI成为音乐创作伙伴 2023年,一款由大语言模型(LLM)生成的钢琴曲《量子交响曲》在Spotify冲上热搜,引发音乐界震动。传统音乐创作需要数年专业训练,而现代AI技术正在打破这一壁垒。本文提出一种…...

Reactive编程:什么是Reactive编程?Reactive编程思想
文章目录 **1. Reactive编程概述****1.1 什么是Reactive编程?****1.1.1 Reactive编程的定义****1.1.2 Reactive编程的历史****1.1.3 Reactive编程的应用场景****1.1.4 Reactive编程的优势** **1.2 Reactive编程的核心思想****1.2.1 响应式(Reactive&…...

深度剖析:U盘突然无法访问的数据拯救之道
一、引言 在数字化办公与数据存储日益普及的当下,U盘凭借其小巧便携、即插即用的特性,成为了人们工作、学习和生活中不可或缺的数据存储工具。然而,U盘突然无法访问这一棘手问题却时常困扰着广大用户,它不仅可能导致重要数据的丢失…...

23种设计模式中的备忘录模式
在不破坏封装的前提下,捕获一个对象的内部状态,并允许在对象之外保存和恢复这些状态。 备忘录模式,主要用于捕获并保存一个对象的内部状态,以便将来可以恢复到该状态。 备忘录的模式主要由三个角色来实现:备忘录、发起…...

蓝桥杯-特殊的三角形(dfs/枚举/前缀和)
思路分析 深度优先搜索(DFS)思路 定义与参数说明 dfs 函数中,last 记录上一条边的长度,用于保证新选边长度大于上一条边,实现三边互不相等 。cnt 记录已选边的数量,当 cnt 达到 3 时,就构成了…...

我的编程之旅:从零到无限可能
一、自我介绍 大家好,我是望云山,一名智能科学与技术专业的大一学生 痴迷于用代码解决现实问题,尤其是自动化工具开发与智能硬件交互方向 2024年偶然用Python写了一个自动整理文件的脚本,第一次感受到“代码即魔法”的震撼 二、…...

一文详解k8s体系架构知识
0.云原生 1.k8s概念 1. k8s集群的两种管理角色 Master:集群控制节点,负责具体命令的执行过程。master节点通常会占用一股独立的服务器(高可用部署建议用3台服务器),是整个集群的首脑。 Master节点一组关键进程…...

wx162基于springboot+vue+uniapp的在线办公小程序
开发语言:Java框架:springbootuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包&#…...