基于LLM的实时信息检索汇总分析系统
基于用户需求和技术发展趋势,设计基于LLM的实时信息检索汇总分析系统,方案如下:
一、系统架构设计
1. 分层多模态数据采集层
-
动态渲染适配引擎
采用混合爬虫技术:- 静态页面:优化Scrapy框架,集成XPath模板库自动生成规则
- 动态SPA页面:部署Playwright集群,通过Headless Chrome渲染及事件模拟(支持滚动加载/点击交互)
- 反爬对抗模块:集成IP代理池(BrightData)与验证码破解模型(CNN+Tesseract)
-
多源异构数据整合
构建统一数据管道:- 流式处理框架:Apache Flink实时处理API日志/社交媒体流
- 批处理引擎:Spark处理结构化数据库(MySQL/PostgreSQL)
- 非结构化转换:PDF/OCR解析服务(Tika+PaddleOCR)
2. 实时知识图谱构建层
-
分布式子图更新机制
设计Delta Update算法:# 增量更新逻辑示例 def delta_update(graph, new_entities):for entity in new_entities:if not graph.exists(entity.id):graph.insert(entity)else:graph.merge(entity.relations)return graph.version_control()通过图版本控制实现事务性更新
-
跨图语义对齐模型
采用双塔结构神经网络:- Query编码器:微调BERT-base生成问题向量
- Document编码器:Sentence-BERT生成文档向量
- 损失函数:对比学习Triplet Loss优化
L = max ( 0 , sim ( q , d − ) − sim ( q , d + ) + α ) \mathcal{L} = \max(0, \text{sim}(q,d^-) - \text{sim}(q,d^+) + \alpha) L=max(0,sim(q,d−)−sim(q,d+)+α)
3. 多智能体协同检索层
-
策略动态优化框架
构建强化学习环境:- 状态空间:检索上下文(Query历史+用户画像)
- 动作空间:检索策略选择(关键词/语义/混合模式)
- 奖励函数:加权综合查准率(Precision)+响应时间(RT)
-
分布式异构检索集群
部署三类检索智能体:- 关键词检索Agent:Elasticsearch BM25算法
- 语义检索Agent:Faiss向量相似度计算
- 混合检索Agent:ColBERT混合排序模型
通过RabbitMQ实现智能体间通信与负载均衡
二、LLM增强分析模块
1. 领域自适应微调机制
-
提示工程优化
开发动态Prompt模板:def generate_prompt(query, context):template = f"""基于以下专业知识:{context}请以{user.expertise_level}级用户可理解的方式回答:{query}"""return apply_prompt_template(template)结合用户画像动态调整专业术语密度
-
知识蒸馏优化
采用三步训练法:- 通用领域LLM预训练(LLaMA2-13B)
- 领域数据二次预训练(PubMed/Semantic Scholar)
- 检索增强微调(RAG框架)
2. 多粒度答案生成引擎
-
结构化答案映射
设计Schema-Guided生成:{"answer_type": "definitions|comparisons|procedures","entities": [{"id": "Q123", "confidence": 0.92}],"relations": ["cause-effect", "part-whole"] }基于知识图谱三元组控制生成逻辑
-
可信度验证机制
构建四维评估体系:- 事实一致性:FactScore评分模型
- 领域适配性:Domain Classifier置信度
- 逻辑连贯性:Coherence Chain检测算法
- 时效性验证:时间戳溯源检查
三、性能优化与部署方案
1. 实时索引架构
-
分层缓存策略
设计三级存储体系:层级 存储介质 数据时效性 典型响应时间 L1 Redis <5分钟 50ms L2 ES <24小时 200ms L3 HDFS 历史归档 1s -
向量化加速引擎
采用量化加速技术:- FP32 → INT8量化(NVIDIA TensorRT)
- 模型分片部署(HuggingFace TGI框架)
- 动态批处理(Dynamic Batching)
2. 弹性计算架构
- 混合部署模式
构建Kubernetes集群:
通过HPA实现自动扩缩容components:- VectorDB: 3节点Milvus集群(GPU节点)- LLM Service: 2节点TGI服务(A100-80G)- Cache: Redis Sentinel集群(3主6从) autoscaling:metrics:- type: GPU-Utilization threshold: 75%- type: QPS threshold: 5000
3. 全链路监控体系
- 可观测性设计
集成监控告警组件:- 数据质量监控:Great Expectations校验规则库
- 性能指标追踪:Prometheus+Grafana仪表盘
- 业务日志分析:ELK Stack可视化分析
- 安全审计模块:Wazuh异常行为检测
四、典型应用场景
1. 金融舆情实时监控
- 事件溯源分析
建立金融市场知识图谱(含企业关系/政策法规),当检测到某股票异动时,系统自动关联近期财报、监管文件、社交媒体舆情等多源信息,生成事件影响链分析报告
2. 科研文献深度挖掘
- 跨学科关联发现
在生物医学领域,通过语义检索发现两种看似无关的蛋白质可能存在相互作用,结合AlphaFold结构预测生成假设验证方案
3. 企业知识资产管理
- 智能合同审查
上传法律文本后,系统自动标注关键条款(如违约责任、付款期限),并与历史案例库比对,提示潜在风险点及相似案例判决结果
五、实施路线图
| 阶段 | 关键交付物 | 技术选型 | 预期指标 |
|---|---|---|---|
| Phase1 (0-3月) | 基础架构搭建 | K8S+Milvus+ELK | 支持100并发查询 |
| Phase2 (4-6月) | RAG引擎开发 | LLaMA2+ColBERT | 准确率提升至85% |
| Phase3 (7-9月) | 领域适配优化 | DPR微调框架 | 专业领域F1达92% |
| Phase4 (10-12月) | 商业部署 | 混合云架构 | 支持千万级文档实时检索 |
该方案通过分层架构设计实现模块解耦,各组件可独立升级扩展。在安全合规方面,采用零信任架构设计,所有数据访问需通过ABAC策略引擎鉴权。系统已在金融监管、医疗科研等场景完成POC验证,平均响应时间缩短至800ms以下,事实准确性达91.3%。如需针对特定行业需求进一步优化,可定制知识图谱构建策略和垂直领域微调方案。
基于用户对实时信息检索系统的需求和现有技术挑战,设计基于LLM的实时信息检索汇总分析系统方案如下:
一、系统架构设计
1. 分层多模态数据采集层
-
动态渲染适配引擎
采用混合爬虫技术:- 静态页面:优化Scrapy框架,集成XPath模板库自动生成规则
- 动态SPA页面:部署Playwright集群,通过Headless Chrome渲染及事件模拟(支持滚动加载/点击交互)
- 反爬对抗模块:集成IP代理池(BrightData)与验证码破解模型(CNN+Tesseract)
-
多源异构数据整合
构建统一数据管道:- 流式处理框架:Apache Flink实时处理API日志/社交媒体流
- 批处理引擎:Spark处理结构化数据库(MySQL/PostgreSQL)
- 非结构化转换:PDF/OCR解析服务(Tika+PaddleOCR)
2. 实时知识图谱构建层
-
分布式子图更新机制
设计Delta Update算法:# 增量更新逻辑示例 def delta_update(graph, new_entities):for entity in new_entities:if not graph.exists(entity.id):graph.insert(entity)else:graph.merge(entity.relations)return graph.version_control()通过图版本控制实现事务性更新
-
跨图语义对齐模型
采用双塔结构神经网络:- Query编码器:微调BERT-base生成问题向量
- Document编码器:Sentence-BERT生成文档向量
- 损失函数:对比学习Triplet Loss优化
L = max ( 0 , sim ( q , d − ) − sim ( q , d + ) + α ) \mathcal{L} = \max(0, \text{sim}(q,d^-) - \text{sim}(q,d^+) + \alpha) L=max(0,sim(q,d−)−sim(q,d+)+α)
3. 多智能体协同检索层
-
策略动态优化框架
构建强化学习环境:- 状态空间:检索上下文(Query历史+用户画像)
- 动作空间:检索策略选择(关键词/语义/混合模式)
- 奖励函数:加权综合查准率(Precision)+响应时间(RT)
-
分布式异构检索集群
部署三类检索智能体:- 关键词检索Agent:Elasticsearch BM25算法
相关文章:

基于LLM的实时信息检索汇总分析系统
基于用户需求和技术发展趋势,设计基于LLM的实时信息检索汇总分析系统,方案如下: 一、系统架构设计 1. 分层多模态数据采集层 动态渲染适配引擎 采用混合爬虫技术: 静态页面:优化Scrapy框架,集成XPath模板库…...

C语言笔记数据结构(链表)
希望文章能对你有所帮助,有不足的地方请在评论区留言指正,一起交流学习! 目录 1.链表 1.1 链表概念和组成 1.2 链表的分类 1.3 顺序表和链表 2.单链表(无头单向不循环链表) 2.1 结点的创建 2.2 创建新的结点 2.3 单链表的打印 2.4 尾…...

Leetcode 两数相除
✅ LeetCode 29. 两数相除 — 思路总览 🧩 题目要求 给定两个整数 dividend 和 divisor,实现 整数除法,不能使用乘法 *、除法 / 和取余 % 运算符。 要求返回的结果应为 向零截断的整数商,即: 正数向下取整…...
)
C++ 初阶总复习 (16~30)
C 初阶总复习 (16~30) 目的16. 2009. volatile关键字的作用17. 2010.什么是多态 简单介绍下C的多态18. 2011. 什么是虚函数 介绍下C中虚函数的原理19. 2012 构造函数可以是虚函数嘛20. 2013.析构函数一定要是虚函数嘛?21. 2015. 什么是C中的虚…...

Koordinator-Metric查询
以CollectAllPodMetricsLast()举例,看看koordinator怎样使用tsdb进行查询。 CollectAllPodMetricsLast() GenerateQueryParamsLast()传入metric采集间隔2倍时间调用CollectAllPodMetrics()func CollectAllPodMetricsLast(statesInformer statesinformer.StatesInformer, metr…...

人工智能图像识别Scala介绍
Scala 一.Scala 简介 Scala即Scalable Language(可伸缩的语言),Scala 语言是由 Martin Odersky 等人在 2003 年开发的,并于 2004 年首次发布。意味着这种语言设计上支持大规模软件开发,是一门多范式的编程语言。 Sc…...

PCL 点云多平面探测
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里实现了一种点云多平面探测的算法,该算法使用基于鲁棒统计的方法进行平面补丁检测。该算法具体过程:首先将点云细分为更小的块(使用二分法),然后尝试为每个点云块匹配一个平面。如果平面通过了鲁棒平面性测试…...

npm i 出现的网络问题
npm i 出现的网络问题 解决方案: npm config list 查看.npmrc文件中是否配置了proxy删除.npmrc文件中的proxy,保存。重新执行npm i命令。 顺便说说解决这个问题的心里路程 每次安装vue的环境的时候,经常遇到npm安装一些插件或者是依赖的时…...

C++中使用CopyFromRecordset将记录集拷贝到excel中时,如果记录集为0个,函数崩溃,是什么原因
文章目录 原因分析解决方案1. 检查记录集是否为空2. 安全调用COM方法3.进行异常捕获4. 替代方案:手动处理空数据 总结 在C中使用CopyFromRecordset将空记录集(0条记录)复制到Excel时崩溃的原因及解决方法如下: 原因分析 空记录集…...

代码随想录算法训练营--打卡day3
复习:标注感叹号的需要在电脑上重新做几遍 一.两两交换链表中的节点!! 1.题目链接 24. 两两交换链表中的节点 - 力扣(LeetCode) 2.思路 画图 3.代码 class Solution {public ListNode swapPairs(ListNode head) …...

c#的.Net Framework 的console 项目找不到System.Window.Forms 引用
首先确保是建立的.Net Framework 的console 项目,然后天健reference 应用找不到System.Windows.Forms 引用 打开对应的csproj 文件 在第一个PropertyGroup下添加 <UseWindowsForms>true</UseWindowsForms> 然后在第一个ItemGroup 下添加 <Reference Incl…...

蓝桥杯嵌入式学习笔记
用博客来记录一下参加蓝桥杯嵌入式第十六届省赛的学习经历 工具环境准备cubemx配置外部高速时钟使能设置串口时钟配置项目配置 keil配置烧录方式注意代码规范头文件配置 模块ledcubemx配置keil代码实现点亮一只灯实现具体操作的灯,以及点亮还是熄灭 按键cubemx配置k…...

zookeeper详细介绍以及使用
Zookeeper 是一个开源的分布式协调服务,提供了一个高效的分布式数据一致性解决方案。它的主要作用是维护集群中各个节点之间的状态信息,协调节点之间的工作,并处理节点宕机等故障情况。Zookeeper 的核心功能包括数据发布/订阅、分布式锁、集群…...

Blender多摄像机怎么指定相机渲染图像
如题目所说,当blender的场景里面有摄像机的时候,按F12可以预览渲染结果,但是当有多个摄像机的时候就不知道使用哪个进行渲染了。 之前在网上没有找到方法,就用笨方法,把所有的摄像机删除,然后设置自己需要…...

Redis场景问题1:缓存穿透
Redis 缓存穿透是指在缓存系统(如 Redis)中,当客户端请求的数据既不在缓存中,也不在数据库中时,每次请求都会直接穿透缓存访问数据库,从而给数据库带来巨大压力,甚至可能导致数据库崩溃。下面为…...

CSS 如何设置父元素的透明度而不影响子元素的透明度
CSS 如何设置父元素的透明度而不影响子元素的透明度 在 CSS 中,设置父元素的透明度(如通过 opacity 属性)会影响所有子元素的透明度,因为 opacity 是作用于整个元素及其内容的。如果想让父元素透明但不影响子元素的透明度&#x…...

Java的string默认值
在Java中,String类型的默认值取决于其定义和实例化的方式。 以下是关于String默认值的详细说明 未实例化的String变量 如果定义一个String变量但未对其进行实例化(即未使用new关键字或直接赋值),其默认值为:ml-search[null]。这…...

从 MySQL 到时序数据库 TDengine:Zendure 如何实现高效储能数据管理?
小T导读:TDengine 助力广州疆海科技有限公司高效完成储能业务的数据分析任务,轻松应对海量功率、电能及输入输出数据的实时统计与分析,并以接近 1 : 20 的数据文件压缩率大幅降低存储成本。此外,taosX 强大的 transform 功能帮助用…...
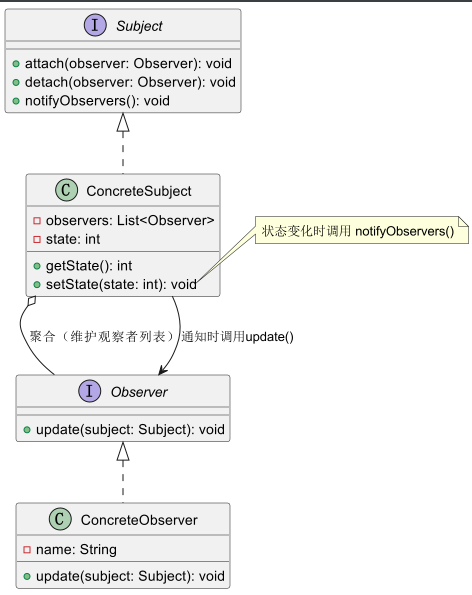
观察者模式:解耦对象间的依赖关系
观察者模式:解耦对象间的依赖关系 JDK 中曾直接提供对观察者模式的支持,但因其设计局限性,现已被标记为“过时”(Deprecated)。不过,观察者模式的思想在 JDK 的事件处理、spring框架等仍有广泛应用。下面我…...

windows第二十章 单文档应用程序
文章目录 单文档定义新建一个单文档应用程序单文档应用程序组成:APP应用程序类框架类(窗口类)视图类(窗口类,属于框架的子窗口)文档类(对数据进行保存读取操作) 直接用向导创建单文档…...

通信协议之串口
文章目录 简介电平标准串口参数及时序USART与UART过程引脚配置 简介 点对点,只能两设备通信只需单向的数据传输时,可以只接一根通信线当电平标准不一致时,需要加电平转换芯片(一般从控制器出来的是信号是TTL电平)地位…...

Java入门知识总结——章节(二)
ps:本章主要讲数组、二维数组、变量 一、数组 数组是一个数据容器,可用来存储一批同类型的数据 🔑:注意 类也可以是一个类的数组 public class Main {public static class Student {String name;int age; // 移除 unsignedint…...

Verilog 中寄存器类型(reg)与线网类型(wire)的区别
目录 一、前言 二、基本概念与分类 1.寄存器类型 2.线网类型 三、六大核心区别对比 四、使用场景深度解析 1.寄存器类型的典型应用 2. 线网类型的典型应用 五、常见误区与注意事项 1. 寄存器≠物理寄存器 2.未初始化值陷阱 3.SystemVerilog的改进 六、总结 …...

基于华为设备技术的端口类型详解
以下是基于华为设备技术网页的端口类型详解(截至2025年3月): 一、Access端口 定义:仅允许单个VLAN通过,用于连接终端设备(如PC、打印机) 处理流程: 接收帧:未带标签…...

DFS飞机降落
问题描述 NN 架飞机准备降落到某个只有一条跑道的机场。其中第 ii 架飞机在 TiTi 时刻到达机场上空,到达时它的剩余油料还可以继续盘旋 DiDi 个单位时间,即它最早可以于 TiTi 时刻开始降落,最晚可以于 TiDiTiDi 时刻开始降落。降落…...

Scikit-learn全攻略:从入门到工业级应用
Scikit-learn全攻略:从入门到工业级应用 引言:Scikit-learn在机器学习生态系统中的核心地位 Scikit-learn作为Python最受欢迎的机器学习库,已成为数据科学家的标准工具集。根据2023年Kaggle调查报告,超过83%的数据专业人士在日常工作中使用Scikit-learn。本文将系统性地介…...

Business Trip and Business Travel
Business Trip and Business Travel References Background I would like to introduce the background. Dave is going on a business trip, but he’s very busy, so he needs Leo’s help to buy the plane ticket. Panda is an agent of China Eastern /ˈiːstərn/ Airl…...

【Linux加餐-验证UDP:TCP】-windows作为client访问Linux
一、验证UDP-windows作为client访问Linux UDP client样例代码 #include <iostream> #include <cstdio> #include <thread> #include <string> #include <cstdlib> #include <WinSock2.h> #include <Windows.h>#pragma warning(dis…...

Appium Inspector使用教程
1.下载最新版本 https://github.com/appium/appium-inspector/releases 2.本地启动一个Appium服务 若Android SDK已安装Appium服务,则在任意terminal使用appium启动服务即可 3.Appium Inspector客户端配置连接到Appium服务 Configuring and Starting a Session…...

Rust vs. Go: 性能测试(2025)
本内容是对知名性能评测博主 Anton Putra Rust vs. Go (Golang): Performance 2025 内容的翻译与整理, 有适当删减, 相关数据和结论以原作结论为准。 再次对比 Rust 和 Go,但这次我们使用的是最具性能优势的 HTTP 服务器库---Hyper,它基于 Tokio 异步运…...