并发编程之FutureTask.get()阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方案
FutureTask.get方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
- FutureTask.get()方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
- 1、情景复现
- 1.1 线程池工作原理
- 1.2 业务场景模拟
- 1.3 运行结果
- 1.4 发现问题:线程池没有被关闭
- 1.5 引发思考
- 2、结合源码剖析 get 方法阻塞原因
- 2.1 submit()方法提交任务
- 2.2 FutureTask
- 局部变量
- 构造方法
- FutureTask的run方法
- FutureTask的get方法
- FutureTask的get(timeout)方法
- FutureTask的 awaitDone方法(核心)
- FutureTask的report 方法
- 2.3 解决方案
FutureTask.get()方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
FutureTask的get()方法在多线程并发编程中应用场景还是蛮多的,作用是通过get方法阻塞直到获取到结果为止,而FutureTask一般是结合线程池来运行任务的,目的是由线程池统一管理和复用线程的资源。但是如果使用不当则会引发CPU飙升的问题? 接下来我们结合源码底层来剖析下到底会不会引发CPU飙升呢?
1、情景复现
1.1 线程池工作原理

1.2 业务场景模拟
结合上图线程池工作原理进行模拟场景:最大线程数为1,核心线程数为1,队列大小为1,也就是说当前线程池最多可以处理两个任务,如果大于两个任务,那么就会执行拒绝策略(注意此处是自定义拒绝策略,这里设置为打印日志,为FutureTask的get阻塞陷阱埋下伏笔)。
- 自定义线程池配置
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(1, // 核心线程数为11, // 最大线程数为12, // 非核心线程不工作时,存活的时间 2sTimeUnit.SECONDS,// 非核心线程不工作时,存活时间对应的时间单位new ArrayBlockingQueue<>(1), // 阻塞队列 容量大小为1new RejectedExecutionHandler() { // 自定义拒绝策略@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("====任务丢失啦啦啦===="); // 打印一行日志// throw new RejectedExecutionException("任务丢失啦啦啦"); // 或抛出异常提示}});
- 提交任务执行
try {// 模拟任务执行List<Future<Integer>> futureList = Stream.of(2, 4, 6).map(num -> {System.out.println(Thread.currentThread().getName() + "<>>>>>> , 添加数字num(Begin):" + num);Future<Integer> future = poolExecutor.submit(() -> {System.out.println(Thread.currentThread().getName() + ":=====任务开始执行=====Start!");try {// 模拟任务执行逻辑TimeUnit.SECONDS.sleep(num);} catch (InterruptedException e) {System.out.println(Thread.currentThread().getName() + ">>任务被中断了,中断原因:" + e.getMessage());}System.out.println(Thread.currentThread().getName() + "=====任务执行完毕=====End!");return num;});System.out.println(Thread.currentThread().getName() + "<>>>>>> , 添加数字num(End):" + num);return future;}).collect(Collectors.toList());// 获取任务执行结果for (Future<Integer> future : futureList) {try {System.out.println(">>:" + future.get());} catch (InterruptedException | ExecutionException e) {System.out.println("=====获取任务执行结果失败=====,原因:" + e.getMessage());}}} catch (Exception e) {e.printStackTrace();} finally {poolExecutor.shutdown();}1.3 运行结果
根据线程池的配置,最多处理的任务数量=最大线程数+阻塞队列 = 2,所以任务2和任务4会被处理,而任务6会根据拒绝策略输出一行日志。

1.4 发现问题:线程池没有被关闭
根据 1.3 输出的日志和运行结果截图分析可得:都是按照预想结果执行的,但问题是:为什么主线程任务为什么没有停止运行呢?因为业务逻辑使用了try…finally包裹,其中finally会关闭线程池的,按照正常执行逻辑是一定会关闭线程池的(因为我们代码中没有任何地方使用System.exit() 强制终止JVM)

结合以上运行截图可以发现,是由于拒绝策略中仅仅是打印了一行日志,导致FutureTask一直以为任务6还存活着,所以在调用futureTask的get方法时一直处于阻塞中,这是导致线程池没有关闭的直接原因。
1.5 引发思考
试想下,如果是在多线程环境下出现这种情况,那么线程池的CPU岂不是会持续飚高运行,从而直接影响服务器的处理性能(此时让我想到工作中有个万能公式:没有什么问题是重启解决不了的呢)。
既然我们已经清楚是因为 futureTask的get方法导致线程阻塞,下面我们继续结合源码来进行验证为什么会被阻塞?
2、结合源码剖析 get 方法阻塞原因
2.1 submit()方法提交任务
public <T> Future<T> submit(Callable<T> task) {// 若任务为空时,抛出空指针异常if (task == null) throw new NullPointerException();// 创建一个FutureTask对象RunnableFuture<T> ftask = newTaskFor(task);// 将该任务添加线程池中execute(ftask);// 返回FutureTask对象return ftask;
}
- submit执行原理图

2.2 FutureTask

局部变量
/*** Possible state transitions(可能的状态转换):NEW -> COMPLETING -> NORMAL(业务逻辑执行正常时)NEW -> COMPLETING -> EXCEPTIONAL(业务逻辑执行异常时)NEW -> CANCELLEDNEW -> INTERRUPTING -> INTERRUPTED*/
private volatile int state; // 被volatile关键字修饰,确保线程可见
private static final int NEW = 0; // 首次submit方法提交任务时,初始化值为NEW
private static final int COMPLETING = 1; //
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
构造方法
public FutureTask(Callable<V> callable) {if (callable == null)throw new NullPointerException();this.callable = callable;this.state = NEW; // ensure visibility of callable
}
FutureTask的run方法
如果业务逻辑call执行分为两种:1、执行异常(NEW -> COMPLETING -> EXCEPTIONAL);2、正常执行(NEW -> COMPLETING -> NORMAL)
public void run() {// 若state不等于NEW 或 CAS 将期望值null设置为当前线程失败时,直接returnif (state != NEW ||!UNSAFE.compareAndSwapObject(this, runnerOffset,null, Thread.currentThread()))return;try {// 当前state等于NEW 或 CAS占用为当前线程成功Callable<V> c = callable;if (c != null && state == NEW) {// c代表当前Task,不等于空且state等于NEWV result;boolean ran;try {// 执行Task的业务逻辑result = c.call();// task执行成功,则将ran变量设置为trueran = true;} catch (Throwable ex) {// 如果Task执行异常,则将结果result置为空,ran变量设置为falseresult = null;ran = false;// 状态变更: NEW -> COMPLETING -> EXCEPTIONALsetException(ex);}// ran变量为true时, 状态变更为:NEW -> COMPLETING -> NORMALif (ran)set(result);}} finally {runner = null;int s = state;// INTERRUPTING值等于5// 若state 大于或等于 5 ,此时state状态为 INTERRUPTING 或 INTERRUPTEDif (s >= INTERRUPTING)// 如果 state等于INTERRUPTING(5)时,调用 Thread.yield() 方法,让出CPU的使用权// 当前线程状态由 运行状态(Running) 转化为 就绪状态(Runnable)。handlePossibleCancellationInterrupt(s);}}
FutureTask的get方法
public V get() throws InterruptedException, ExecutionException {int s = state; // 获取当前任务的 state 变量// 如果 state 变量的值 小于或等于 COMPLETING(1) 则进入 awaitDone (翻译为:等待完成)if (s <= COMPLETING)s = awaitDone(false, 0L);// 此处表示s 大于COMPLETING(1)return report(s);
}
FutureTask的get(timeout)方法
public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {if (unit == null)throw new NullPointerException();int s = state;if (s <= COMPLETING &&(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)throw new TimeoutException();// 超时会抛出异常TimeoutExceptionreturn report(s);
}
FutureTask的 awaitDone方法(核心)
/*** <p>等待完成</p>* 根据 timed 参数分为两种情况:* 1、如果timed为true时,调用LockSupport.parkNanos(this, nanos);// 表示仅等待nanos时间* 2、如果timed为false时,则调用LockSupport.park(this); // 表示一直等待*/
private int awaitDone(boolean timed, long nanos) throws InterruptedException {final long deadline = timed ? System.nanoTime() + nanos : 0L;WaitNode q = null;boolean queued = false;// 默认为false// 进入死循环for (;;) {// 当前线程被中断if (Thread.interrupted()) {// q不为空时移除waiterremoveWaiter(q);// 抛出中断异常InterruptedExceptionthrow new InterruptedException();}// 表示当前线程未被中断int s = state;// 如果 state 大于 COMPLETING(1) 时,// 则代表此时的state值为NORMAL、EXCEPTIONAL、CANCELLED、INTERRUPTING、INTERRUPTEDif (s > COMPLETING) {// waitNode不为空时,将thread置为nullif (q != null)q.thread = null;// 返回当前的state值return s;}// 如果 state 值为COMPLETING时,则让出CPU的使用权else if (s == COMPLETING)Thread.yield();// 让出CPU的使用权else if (q == null)q = new WaitNode(); // 如果q等于空时,创建一个WaitNode节点else if (!queued)// 通过CAS(Compare-And-Swap)操作将当前线程的等待节点q插入到waiters链表中queued = UNSAFE.compareAndSwapObject(this, waitersOffset,q.next = waiters, q);else if (timed) {// timed 为 true 时,调用LockSupport.parkNanos(this, nanos);nanos = deadline - System.nanoTime();if (nanos <= 0L) {// 如果小于或等于0,则表示等待时间到了removeWaiter(q);// 此时返回 statereturn state;}LockSupport.parkNanos(this, nanos);}else// 表示当前线程一直等待完成, 一直阻塞LockSupport.park(this);}
}
- 引发阻塞的核心原因(LockSupport.park(this))
如果使用的get(timeout)方法,则使用 LockSupport.parkNanos(this, nanos); 会阻塞 nanos 时间后会释放锁;反之使用 get()方法,则使用LockSupport.park(this); 会一直阻塞
FutureTask的report 方法
private V report(int s) throws ExecutionException {Object x = outcome;// 如果 state 变量 等于 NORMAL,则返回结果值 Valueif (s == NORMAL)return (V)x;// state 大于或等于 CANCELLED,则state可能的值为:CANCELLED、INTERRUPTING、INTERRUPTEDif (s >= CANCELLED) throw new CancellationException();// 抛出异常// 抛出异常ExecutionExceptionthrow new ExecutionException((Throwable)x);
}
2.3 解决方案

重要事情讲三遍,注意、注意、注意:在使用get方法时首先需要结合线程池的拒绝策略,避免直接 使用get方法(导致线程一直阻塞中,进而引发服务器CPU飚高)。
综上所述是对FutureTask的get方法阻塞陷阱问题结合源码底层进行深度剖析,是我自己在工作中遇到的坑,如果你有用到这块知识,希望可以帮你避坑,当然如果有理解不到的地方望指正哟。

相关文章:
并发编程之FutureTask.get()阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方案
FutureTask.get方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法 FutureTask.get()方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法1、情景复现1.1 线程池工作原理1.2 业务场景模拟1.3 运行结果1.4 发现问题:线程池没有被关闭1.…...

DGNN-YOLO:面向遮挡小目标的动态图神经网络检测与追踪方法解析
一、算法结构与核心贡献 1.1 文章结构 采用经典五段式结构: 引言:分析智能交通系统(ITS)中小目标检测与追踪的挑战,提出研究动机。相关工作:综述小目标检测(YOLO系列、Faster R-CNN)、目标追踪(SORT、Transformer)和图神经网络(GNN)的进展。方法论:提出DG…...

在Ubuntu中固定USB设备的串口号
获取设备信息 lsusb # 记录设备的Vendor ID和Product ID(例如:ID 0403:6001)# 获取详细属性(替换X和Y为实际设备号) udevadm info -a /dev/ttyUSBX 结果一般如下 创建udev规则文件 sudo gedit /etc/udev/rules.d/us…...

javaSE————文件IO(2)、
文件内容的读写——数据流 我们对于文件操作使用流对象Stream来操作,什么是流对象呢,水流是什么样的,想象一下,水流的流量是多种的,可以流100ml,也可以流1ml,流对象就和水流很像,我…...

前端常问的宏观“大”问题详解(二)
JS与TS选型 一、为什么选择 TypeScript 而不是 JavaScript? 1. 静态类型系统:核心优势 TypeScript 的静态类型检查能在 编译阶段 捕获类型错误(如变量类型不匹配、未定义属性等),显著减少运行时错误风险。例如&…...

[创业之路-343]:创业:一场认知重构与组织进化的双向奔赴
目录 前言:关键词: 一、重构企业认知框架: 1、认知框架的顶层设计——六大维度生态模型 2、认知重构的精密设计——五层结构化模型 第一层:战略层(脑) 第二层:运营层(躯干&…...

智慧电力:点亮未来能源世界的钥匙
在科技日新月异的今天,电力行业正经历着前所未有的变革。智慧电力,作为这一变革的核心驱动力,正逐步改变着我们对电力的认知和使用方式。它不仅是电力行业的一次技术革新,更是推动社会可持续发展、实现能源高效利用的重要途径。 智…...
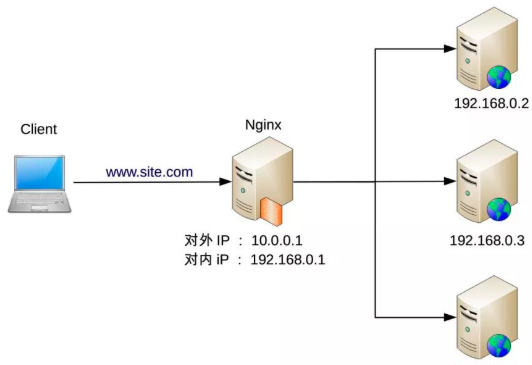
架构师面试(二十三):负载均衡
问题 今天我们聊微服务相关的话题。 大中型微服务系统中,【负载均衡】是一个非常核心的组件;在微服务系统的不同位置对【负载均衡】进行了实现,下面说法正确的有哪几项? A. LVS 的负载均衡一般通过前置 F5 或是通过 VIP keepa…...
)
CSS3学习教程,从入门到精通, CSS3 列表控制详解语法知识点及案例代码(24)
CSS3 列表控制详解 CSS 列表控制的语法知识点及案例代码的详细说明,包括 list-style-type、list-style-image、list-style-position 和 list-style 的用法。 1. list-style-type 属性 list-style-type 属性用于设置列表项标记的类型。 语法 list-style-type: v…...

NSSCTF(MISC)—[justCTF 2020]pdf
相应的做题地址:https://www.nssctf.cn/problem/920 binwalk分离 解压文件2AE59A.zip mutool 得到一张图片 B5F31内容 B5FFD内容 转换成图片 justCTF{BytesAreNotRealWakeUpSheeple}...

坚持“大客户战略”,昂瑞微深耕全球射频市场
北京昂瑞微电子技术股份有限公司(简称“昂瑞微”)是一家聚焦射频与模拟芯片设计的高新技术企业。随着5G时代的全面到来,智能手机、智能汽车等终端设备对射频前端器件在通信频率、多频段支持、信道带宽及载波聚合等方面提出了更高需求…...

LiteDB 数据库优缺点分析与C#代码示例
LiteDB 是一个轻量级的 .NET NoSQL 嵌入式数据库,完全用 C# 开发,支持跨平台(Windows、Linux、MacOS),并提供类似于 MongoDB 的简单 API。它以单文件形式存储数据,类似于 SQLite,支持事务和 ACID 特性,确保数据的一致性和可靠性。 优缺点分析 优点: 轻量级与嵌入式:…...

上海SMT贴片技术解析与行业趋势
内容概要 随着长三角地区电子制造产业集群的快速发展,上海作为核心城市正引领着SMT贴片技术的革新浪潮。本文聚焦表面组装技术在高密度互连、微间距贴装等领域的突破性进展,通过解析焊膏印刷精度控制、元件定位算法优化等核心工艺,展现上海企…...

HTML5和CSS3的一些特性
HTML5 和 CSS3 是现代网页设计的基础技术,它们引入了许多新特性和功能,极大地丰富了网页的表现力和交互能力。 HTML5 的一些重要特性包括: 新的语义化标签: HTML5 引入了一些重要的语义化标签如 <header>, <footer>, <articl…...

Linux系统中快速安装docker
1 查看是否安装docker 要检查Ubuntu是否安装了Docker,可以使用以下几种方法: 方法1:使用 docker --version 命令 docker --version如果Docker已安装,输出会显示Docker的版本信息,例如: Docker version …...
)
每日c/c++题 备战蓝桥杯(最长上升子序列)
点击题目链接 题目描述 给出一个由 n(n≤5000) 个不超过 1e6 的正整数组成的序列。请输出这个序列的最长上升子序列的长度。 最长上升子序列是指,从原序列中按顺序取出一些数字排在一起,这些数字是逐渐增大的。 输入格式 第一行,一个整数…...

蓝桥杯—质数
质数 质数是一个只有1和它本身2个因数 代码实现 //求质数 #include<bits/stdc.h> using namespace std; bool zhishu(int n) {if(n1){cout<<"1不是质数";return false;}else if(n>1){for(int i2;i<sqrt(n);i){if(n%i0){cout<<n<<&q…...

CP15 协处理器
ARMv7-A 一共支持 16 个协处理器,编号从 CP0~CP15。这里仅对CP15进行描述。 1、ARMv7-A 协处理器 ARMv7-A 处理器除了标准的 R0~R15,CPSR,SPSR 以外,由于引入了 MMU、TLB、Cache 等内容,ARMv7-A 使用协处理器来对这些…...

网络运维学习笔记(DeepSeek优化版)026 OSPF vlink(Virtual Link,虚链路)配置详解
文章目录 OSPF vlink(Virtual Link,虚链路)配置详解1. 虚链路核心特性2. 基础配置命令3. 状态验证命令3.1 查看虚链路状态3.2 验证LSDB更新 4. 关键技术要点4.1 路径选择机制4.2 虚链路的链路优化 5. 环路风险案例 OSPF vlink(Virtual Link&a…...

简单介绍一下Unity中的material和sharedMaterial
在Unity中,材质(Material)是定义物体外观的关键组件,它决定了物体的颜色、纹理、光照效果等属性。Renderer组件(如MeshRenderer或SpriteRenderer)通过材质来渲染游戏对象的外观。Unity提供了两种访问材质的…...
 用于持续监听事件组中的事件,并根据不同的事件触发相应的操作)
小智机器人关键函数解析,Application::MainLoop() 用于持续监听事件组中的事件,并根据不同的事件触发相应的操作
以下是对 Application::MainLoop() 函数的详细解释: 源码: // The Main Loop controls the chat state and websocket connection // If other tasks need to access the websocket or chat state, // they should use Schedule to call this function …...
:STL适配器)
设计模式之适配器模式(二):STL适配器
目录 1.背景 2.什么是 STL 适配器? 3.函数对象适配器 3.1.std::bind 3.2.std::not1 和 std::not2 3.3.std::mem_fn 4.容器适配器 4.1.std::stack(栈) 4.2.std::queue(队列) 4.3.std::priority_queue(优先队列࿰…...

【区块链安全 | 第十六篇】类型之值类型(三)
文章目录 函数类型声明语法转换成员合约更新时的值稳定性示例 函数类型 函数类型是函数的类型。函数类型的变量可以通过函数进行赋值,函数类型的参数可以用来传递函数并返回函数。 函数类型有两种类型:内部函数和外部函数。 内部函数只能在当前合约内调…...

设计模式——设计模式理念
文章目录 参考:[设计模式——设计模式理念](https://mp.weixin.qq.com/s/IEduZFF6SaeAthWFFV6zKQ)参考:[设计模式——工厂方法模式](https://mp.weixin.qq.com/s/7tKIPtjvDxDJm4uFnqGsgQ)参考:[设计模式——抽象工厂模式](https://mp.weixin.…...
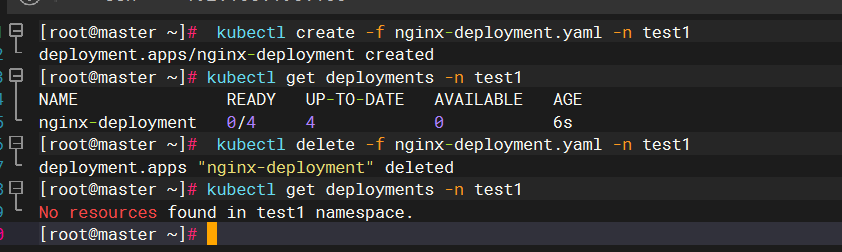
Kubernetes对象基础操作
基础操作 文章目录 基础操作一、创建Kubernetes对象1.使用指令式命令创建Deployment2.使用指令式对象配置创建Deployment3.使用声明式对象配置创建Deployment 二、操作对象的标签1.为对象添加标签2.修改对象的标签3.删除对象标签4.操作具有指定标签的对象 三、操作名称空间四、…...

Java与代码审计-Java基础语法
Java基础语法 package com.woniuxy.basic;public class HelloWorld {//入口函数public static void main(String[] args){System.out.println("Hello World");for(int i0;i< args.length;i){System.out.println(args[i]);}} }运行结果如下: 但是下面那个没有参数…...
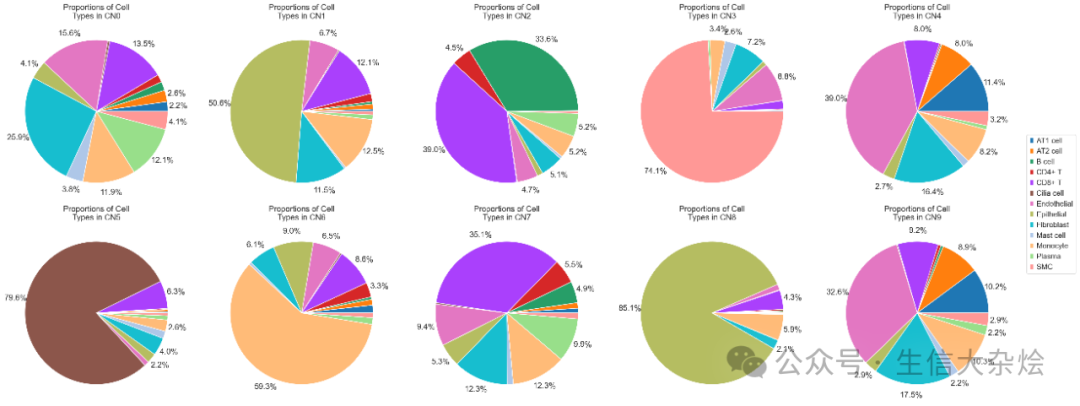
Xenium | 细胞邻域(Cellular Neighborhood)分析(fixed radius)
上节我们介绍了空间转录组数据分析中常见的细胞邻域分析,CN计算过程中定义是否为细胞邻居的方法有两种,一种是上节我们使用固定K最近邻方法(fixed k-nearest neighbors)定义细胞Neighborhood,今天我们介绍另外一种固定半径范围内(fixed radiu…...

Python:爬虫概念与分类
网络请求: https://www.baidu.com url——统一资源定位符 请求过程: 客户端,指web浏览器向服务器发送请求 请求:请求网址(request url);请求方法(request methods);请求头(request header)&…...

[Linux实战] Linux设备树原理与应用详解
Linux设备树原理与应用详解 一、设备树概述 1.1 什么是设备树 设备树(Device Tree,简称DT)是一种描述硬件资源的数据结构,它通过一种树状结构来描述系统硬件配置,包括CPU、内存、总线、外设等硬件信息。设备树最初在…...
)
用Nginx实现负载均衡与高可用架构(整合Keepalived)
前言 在分布式架构中,负载均衡和高可用是保障系统稳定性的两大核心能力。本文将深入讲解如何通过Nginx实现七层负载均衡,并结合Keepalived构建无单点故障的高可用架构。文末附完整配置模板! 一、Nginx负载均衡实现方案 1. 核心原理 Nginx通…...