简介
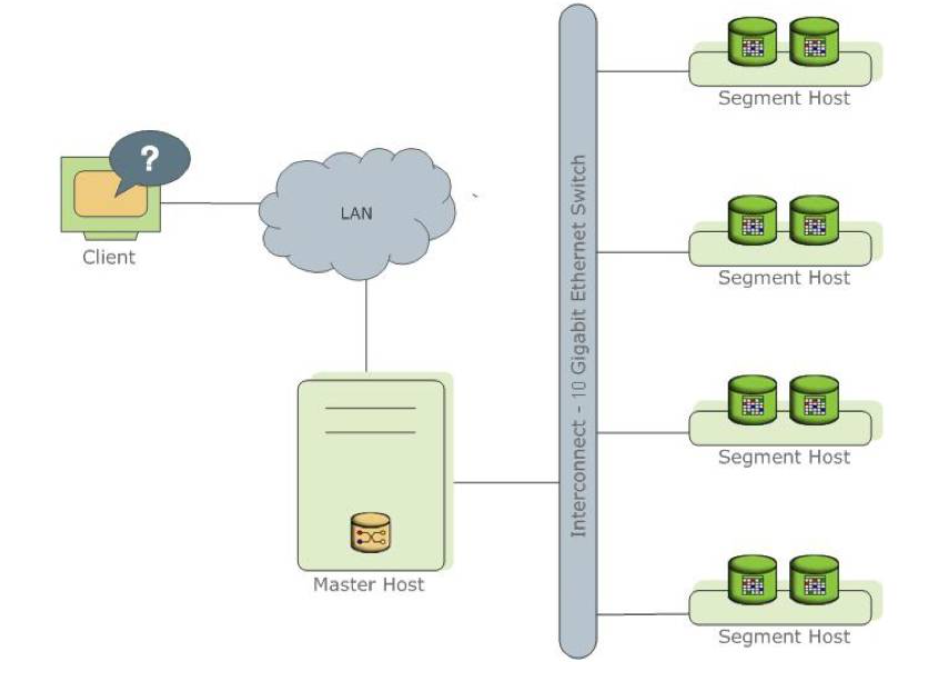
Greenplum是一个面向数据仓库应用的关系型数据库,因为有良好的体系结构,所以在数据存储、高并发、高可用、线性扩展、反应速度、易用性和性价比等方面有非常明显的优势。Greenplum是一种基于PostgreSQL的分布式数据库,其采用sharednothing架构,主机、操作系统、内存、存储都是自我控制的,不存在共享。
GPDB是典型的Mater/Slave架构,在GreenPlum集群中,存在一个Master节点和多个Segment节点,其中每个节点上可以运行多个数据库。 Greenplum采用shared nothing架构(MPP)。典型的Shared Nothing系统会集数据库、内存Cache等存储状态的信息;而不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
Greenplum数据库的Master是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上。Greenplum数据库的最终用户与Greenplum数据库(通过Master)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互。他们使用诸如psql之类的客户端或者JDBC、ODBC、Iibpq(PostgreSQL的C语言API)等应用编程接口(API)连接到数据库。
Master是全局系统目录的所在地,全局系统目录是一组包含了有关GreenPlum数据库系统本身的元数据系统表,Master上不包含任何用户数据,数据只存在于Segment之上。Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。Greenplum数据库使用预写式日志(WAL)来实现主/备镜像。在基于WAL的日志中,所有的修改都会在应用之前被写入日志,以确保对于任何正在处理的操作的数据完整性。注意:Segment镜像还不能使用WAL日志。
GreenPlum数据库的Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。
当一个用户通过Greenplum的Master连接到数据库并且发出一个查询时,在每一个Segment数据库上都会创建一些进程来处理该查询的工作。
用户定义的表及其索引会分布在Greenplum数据库系统中可用的Segment上,每一个Segment都包含数据的不同部分。服务于Segment数据的数据库服务器进程运行在相应的Segment实例之下。用户通过Master与一个Greenplum数据库系统中的Segment交互。
Segment运行在被称作 Segment主机 的服务器上。一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。Segment主机预期都以相同的方式配置。从Greenplum数据库获得最佳性能的关键在于在大量能力相同的Segment之间 平均地 分布数据和工作负载,这样所有的Segment可以同时开始为一个任务工作并且同时完成它们的工作。
Interconect是Greenplum数据库架构中的网络层。
Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络基础设施。Greenplum的Interconnect采用了一种标准的以太交换网络。出于性能原因,推荐使用万兆网或者更快的系统。
默认情况下,Interconnect使用带流控制的用户数据包协议(UDPIFC)在网络上发送消息。Greenplum软件在UDP之上执行包验证。这意味着其可靠性等效于传输控制协议(TCP)且性能和可扩展性要超过TCP。如果Interconnect被改为TCP,Greenplum数据库会有1000个Segment实例的可扩展性限制。对于Interconnect的默认协议UDPIFC则不存在这种限制。
集群搭建
安装准备
1. 准备离线安装包
https://github.com/greenplum-db/gpdb/releases/tag/6.26.0
GreenPlum的安装方式大体分为两类:
这次的搭建过程选用下载编译好的安装包。
2. 集群介绍
搭建的GreenPlum集群,我这里使用五台虚拟机做测试,使用1个master、1个standy、3个segment的集群,如下:
| 主机名称 | 主机IP | 备注 |
| mdw1 | 192.168.1.170 | |
| smdw1 | 192.168.1.171 | |
| sdw1 | 192.168.1.172 | |
| sdw2 | 192.168.1.173 | |
| sdw3 | 192.168.1.174 | |
3. 准备环境
1. 配置ip
此处不过多介绍怎么配置静态IP过程,可以上网进行查询配置过程。
2. 关闭防火墙
# 查看防火墙状态 firewall-cmd --state # 临时停止防火墙 systemctl stop firewalld.service # 禁止防火墙开机启动 systemctl disable firewalld.service
3. 关闭Selinux
vim /etc/selinux/config 配置SELINUX=disabled
4. 修改主机名
hostnamectl set-hostname mdw1
5. 配置hosts文件
vim /etc/hosts 192.168.1.170 mdw1 192.168.1.171 smdw1 192.168.1.172 sdw1 192.168.1.173 sdw2 192.168.1.174 sdw3 #重启机器
6. 配置内核配置参数
vim /etc/sysctl.conf kernel.shmall = 4000000000 kernel.shmmax = 500000000 kernel.shmmni = 4096 vm.overcommit_memory = 2 vm.overcommit_ratio = 95 net.ipv4.ip_local_port_range = 10000 65535 kernel.sem = 500 2048000 200 40960 kernel.sysrq = 1 kernel.core_uses_pid = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.msgmni = 2048 net.ipv4.tcp_syncookies = 1 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.conf.all.arp_filter = 1 net.core.netdev_max_backlog = 10000 net.core.rmem_max = 2097152 net.core.wmem_max = 2097152 vm.swappiness = 10 vm.zone_reclaim_mode = 0 vm.dirty_expire_centisecs = 500 vm.dirty_writeback_centisecs = 100 vm.dirty_background_ratio = 0 vm.dirty_ratio = 0 vm.dirty_background_bytes = 1610612736 vm.dirty_bytes = 4294967296 # 执行命令使其生效 sysctl -p
7. 配置资源限制参数
vim /etc/security/limits.conf # 配置如下信息 * soft nofile 524288 * hard nofile 524288 * soft nproc 131072 * hard nproc 131072 # '*' 代表所有用户 # noproc代表最大进程数 # nofile代表最大文件打开数
ulimit -u 命令显示每个用户可以用的最大的进程数 max user processes,验证返回值为131072,需要注意的事,有时候需要重启后才会生效。
8. 创建gpadmin用户
groupadd gpadmin useradd gpadmin -g gpadmin -s /bin/bash passwd gpadmin # 我创建的密码跟用户名一致
4. 安装构建
1. 准备依赖
因按照rpm的方式进行安装,所以需要系统内核能够提供安装环境,可后续执行安装的时候,按照系统缺少的依赖相应进行安装。rpm的镜像网站: centos-7-os-x86_64-Packages安装包下载_开源镜像站-阿里云;
2. 执行安装
- 执行安装脚本,默认安装到/usr/local目录下。
rpm -ivh greenplum-db-6.26.0-rhel7-x86_64.rpm # 安装完毕后,建议手动更改安装路径,放在/home/gpadmin下,执行以下语句
1. 进入安装父目录 cd /usr/local 2. 将安装目录移动到/home/gpadmin mv greenplum-db-6.26.0 /home/gpadmin 3. 删除软链接 /bin/rm -r greenplum-db 4. 在/home/gpadmin下建立软链接 ln -s /home/gpadmin/greenplum-db-6.26.0 /home/gpadmin/greenplum-db 5. 修改greenplum_path.sh,当前版本不需要更改,如果是之前的版本需要更改GPHOME的地址 6. 将文件赋权给gpadmin cd /home chown -R gpadmin:gpadmin /home/gpadmin
3. 集群间互信
生成密钥 GP6.X开始gpssh-exkeys命令已经不带自动生成密钥了,所以需要自己手动生成
cd /home/gpadmin/greenplum-db ssh-keygen -t rsa
将本机的公钥复制给各个节点机器的authorized_keys文件中
ssh-copy-id smdw1 ssh-copy-id sdw1 ssh-copy-id sdw2 ssh-copy-id sdw3
使用gpssh-exkeys工具,打通n-n的免密登录
vim all_hosts mdw1 smdw1 sdw1 sdw2 sdw3 source /home/gpadmin/greenplum-db/greenplum_path.sh gpssh-exkeys -f all_host vim /home/gpadmin/gpconfigs/seg_hosts sdw1 sdw2 sdw3
4. 设置用户环境
vim ~.bashrc source /home/gpadmin/greenplum-db/greenplum_path.sh
5. 集群节点安装
gp6.x无gpseginstall命令,以下模拟此命令主要过程,完成gpsegment的部署。
su - gpadmin cd /home/gpadmin tar -cf gp6.tar greenplum-db-6.26.0/ vim /home/gpadmin/gpconfigs/gpseginstall_hosts 添加数据节点信息 sdw1 sdw2 sdw3
6. 分发与安装
# 将压缩包分发到其余节点上 gpscp -f gpscp -f /home/gpadmin/gpconfigs/gpseginstall_hosts gp6.tar gpadmin@=:/home/gpadmin # 通过gpssh命令链接到哥哥segment上执行命令 gpssh -f /home/gpadmin/gpconfigs/gpseginstall_hosts >> tar -xf gp6.tar >> ln -s greenplum-db-6.26.0 greenplum-db >> exit
7. 将环境变量文件分发到其他节点上
su - gpadmin cd gpconfigs vi seg_hosts gp-sdw1d gp-sdw2 gp-sdw3-smdw gpscp -f /home/gpadmin/gpconfigs/seg_hosts /home/gpadmin/.bashrc gpadmin@=:/home/gpadmin/.bashrc
8. 创建集群目录
1. 创建master 数据目录 mkdir -p /data/master chown -R gpadmin:gpadmin /data source /home/gpadmin/greenplum-db/greenplum_path.sh 如果有standby节点则需要执行下面2句 gp-sdw3-mdw2 这个hostname灵活变更 gpssh -h gp-sdw3-mdw2 -e 'mkdir -p /data/master' gpssh -h gp-sdw3-mdw2 -e 'chown -R gpadmin:gpadmin /data' 2. 创建segment数据目录 source /home/gpadmin/greenplum-db/greenplum_path.sh gpssh -f /home/gpadmin/gpconfigs/seg_hosts -e 'mkdir -p /data/p1' gpssh -f /home/gpadmin/gpconfigs/seg_hosts -e 'mkdir -p /data/p2' gpssh -f /home/gpadmin/gpconfigs/seg_hosts -e 'mkdir -p /data/m1' gpssh -f /home/gpadmin/gpconfigs/seg_hosts -e 'mkdir -p /data/m2' gpssh -f /home/gpadmin/gpconfigs/seg_hosts -e 'chown -R gpadmin:gpadmin /data'
9. 编辑用户变量
切换到gpadmin用户
export MASTER_DATA_DIRECTORY=/data/master/gpseg-1 除此之外,通常还增加: export PGPORT=5432 # 根据实际情况填写 export PGUSER=gpadmin # 根据实际情况填写 export PGDATABASE=gpdw # 根据实际情况填写 前面已经添加过 source /usr/local/greenplum-db/greenplum_path.sh,此处操作如下: vi .bashrc export MASTER_DATA_DIRECTORY=/data/master/gpseg-1
5. 集群初始化
1. 执行初始化脚本
gpinitsystem -c /home/gpadmin/gpconfigs/gpinitsystem_config --locale=C -h /home/gpadmin/gpconfigs/seg_hosts --mirror-mode=spread
需要注意:spread是指spread分布策略,只允许主机数>每个主机中的段实例数,
如果不指定mirror_mode,则是默认的group策略,这样做的情况在段实例数>1时,down机后不会导致他的镜像全在一台机器中,降低另外一台机器的性能瓶颈。
当出现此行信息,说明数据库初始化成功。
2. 初始化回退
如果在安装中途失败,提示使用bash /home/gpadmin/gpAdminLogs/backout_gpinitsystem_gpadmin_* 回退,执行该脚本即可。
如果在执行完此行脚本后仍然并未清理干净,可执行一下语句后,再重新安装
pg_ctl -D /data/master/gpseg-1 stop # 如果出现命令卡死,则加上 -m fast代表立即执行 rm -f /tmp/.s.PGSQL.5432 /tmp/.s.PGSQL.5432.lock 主节点 rm -rf /data/master/gpseg* 所有数据节点 rm -rf /data/p1/gpseg* rm -rf /data/p2/gpseg*
3. 配置认证文件
客户端认证由一个配置文件,通常是pg_hba.conf控制的,它存放再数据库集群的数据目录中。也就是基于主机的认证。在init初始化数据目录的时候,它会安装一个缺省的pg_hba.conf文件
vim /home/master/gpseg-1/pg_hba.conf 新增一行host all all 0.0.0.0/0 md5
4. 初始化standby节点
gpinitstandy -s smdw1
5. 初始化异常
1. 连接template1连接超时
2. 报错信号量不够
需要调整下liunx的内核参数:
kernel.sem = 1000 5120000 2500 9000
6. 重启数据库
# 启动数据库 gpstart # 重启数据库 gpstop -r # 重新载入配置文件更改 gpstop -u # gpstop -M fast
7. 登录数据库
1. 控制台登录数据库
#使用psql命令可进行登录,用法与postgresql一致 psql -d postgres > alter user gpadmin encrypted password 'gpadmin'; 退出 \q 显示数据库列表 \l
2. 客户端登录
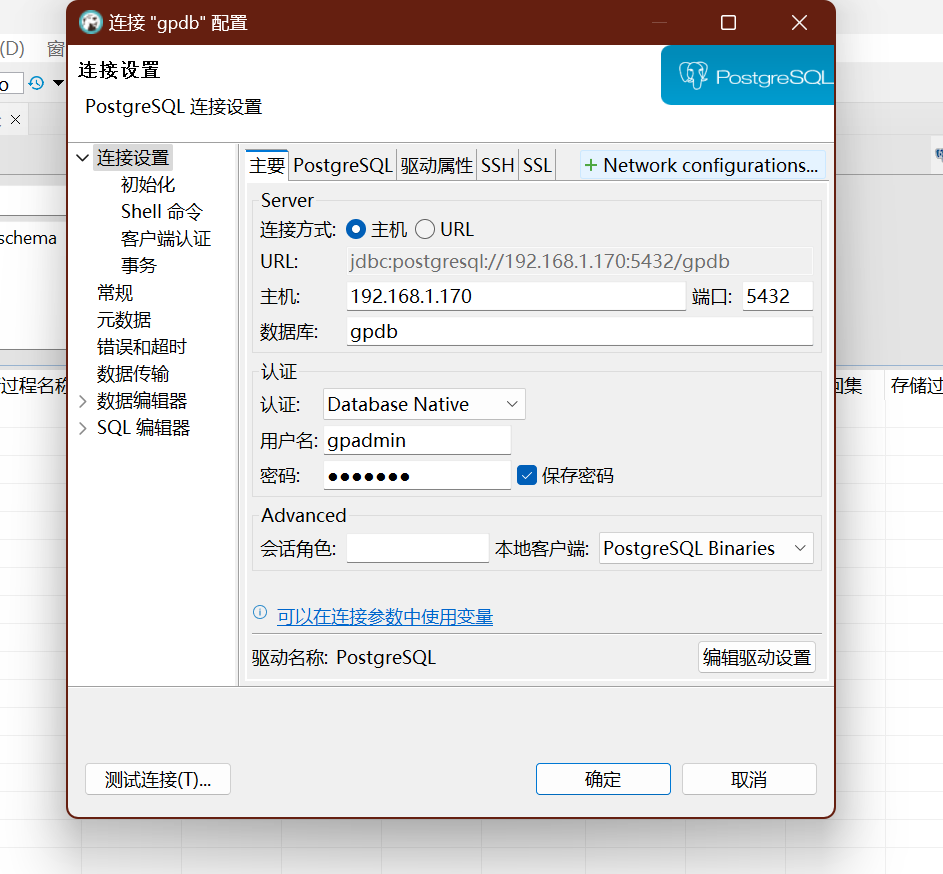
这边选择使用连接工具为dbeaver工具,也可以选用naivate连接工具,任意。
如何使用
数据库管理
用户创建的每一个新数据库都是基于一个模板的。GreenPlum提供了一个默认数据库tempalate1,第一次可以使用postgres连接到GreenPlum数据库。除非指定另一个模板, Greenplum会使用 template1 来创建数据库。
# 创建一个数据库 CREATE DATABASE new_dbname; # 克隆数据库 CREATE DATABASE new_dbname TEMPLATE old_dbname; # 查看数据库列表 SELECT datname from pg_database; # 修改一个数据库,可以修改数据库属性,例如拥有者、名称或者默认配置属性。 ALTER DATABASE mydatabase SET search_path TO myschema, public, pg_catalog; # 删除一个数据库,会移除该数据库的系统目录项并且删除该数据库在磁盘上的目录以及其中包含的数据 => \c postgres => DROP DATABASE mydatabase;
表空间管理
表空间允许数据库管理员在每台机器上拥有多个文件系统决定如何最好的使用物理存储来存放数据库对象, 表空间允许用户为频繁使用和不频繁使用的数据库对象分配不同的存储,或者在特定的数据库对象上控制I/O性能。例如,把频繁使用的表放在使用高性能固态驱动器(SSD)的文件系统上,而把其他表放在标准的磁盘驱动器上。
有一种比较方便的工具gpfilespace工具来创建文件空间,但是发现并没有这个工具,查询资料显示在gp6.x版本之后取消了此概念。
现如果创建表空间,可以按照pg数据库的创建表空间的逻辑进行创建。需要注意的是创建的表空间的名称不能以pg_或者gp_开头,因为此类名称为系统表空间专用。
具体步骤如下:
第一步:创建本地目录文件
# 需要所有机器都执行 mkdir -p /datax/tbs_tmp mkdir -p /datax/tbs_tmp2 chown -R gpadmin:gpadmin /datax
第二步:创建表空间
create tablespace tbs_temp location '/datax/tbs_tmp'; create tablespace tbs_temp2 location '/datax/tbs_tmp2'; #########其余参数解释########## CREATE TABLESPACE tablespace_name [ OWNER user_name ] LOCATION 'directory' [ WITH ( tablespace_option = value [, ... ] ) ] tablespace_name:创建的表空间名称 owner user_name: 拥有表空间的用户名 location '/datax/xx':目录的路径,它将是表空间的根目录,注册表空间时,该目录应该为空 contentID_i = '/datax/xx_i': 是段实例用作表空间的根目录的主机系统文件位置的路径。不能指定主实例的内容ID(-1)。只能为多个实例段指定相同的目录。
第三步:查询表空间的信息
select oid,* from pg_tablespace;
select * from gp_tablespace_location(16398);
WITH spc AS (SELECT * FROM gp_tablespace_location(16398)) SELECT seg.role, spc.gp_segment_id as seg_id, seg.hostname, seg.datadir, tblspc_loc FROM spc, gp_segment_configuration AS seg WHERE spc.gp_segment_id = seg.content ORDER BY seg_id;
第四步:使用表空间
ALTER DATABASE zhzkdb SET TABLESPACE tbs_temp;
模式管理
-- 创建模式 create schema snjs_mode; -- 授权模式给指定用户 grant all on schema snjs_mode to zhzk;
用户管理/授权
create user zhzk password 'zhzk'; grant all on database zhzkdb to zhzk; -- 授权其余用户可执行其余模式或者表的操作权限 grant USAGE on schema odm_mode to fdmuser; grant select on table odm_mode.employees to fdmuser; revoke all on tablespace tbs_intf from intfuser; -- 修改角色属性 ALTER ROLE zhzk NOSUPERUSER NOCREATEDB CREATEROLE INHERIT LOGIN NOREPLICATION; -- 删除角色 drop role test; -- 创建角色 CREATE ROLE test WITH NOSUPERUSER NOCREATEDB NOCREATEROLE NOINHERIT LOGIN NOREPLICATION CONNECTION LIMIT -1; ## 此处建议,可以优先创建出角色组后,然后创建用户,随后将该组继承到某用户上,方便管理。
分区策略
表分区让我们通过把表划分为较小的、易于管理的小块来支持非常大的表, 通过让Greenplum数据库查询优化器只扫描满足给定查询所需的数据而避免扫描大表的全部内容,分区表能够提升查询性能。
分区并不会改变表数据在Segment之间的物理分布。表分布是物理的:Greenplum数据库会在物理上把分区表和未分区表划分到多个Segment上来启用并行查询处理。表 分区 是逻辑的:Greenplum数据库在逻辑上划分大表来提升查询性能并且有利于数据仓库维护任务,例如把旧数据滚出数据仓库。
GreenPlum支持:
决定一个表的分区策略:
- 表是否足够大
- 用户是否体验到不满意的性能
- 用户查询谓词有没有可识别的访问模式
- 用户的数据仓库是否维护了一个历史数据的窗口
- 数据能否基于某种定义的原则被划分成差不多相等的部分
不要创建超过所需数量的分区,创建过多的分区可能会拖慢管理和维护工作,例如清理、恢复Segment、扩展集群、检查磁盘用量等等。
定义日期范围的分区
一个按日期范围分区的表使用单个date或者timestamp列作为分区键列。
1. 用户可以通过给出一个START值、一个END值以及一个定义分区增量值的子句让Greenplum数据库自动产生分区。默认情况下,START值总是被包括在内而END值总是被排除在外。
CREATE TABLE sales (id int, date date, amt decimal(10,2)) DISTRIBUTED BY (id) PARTITION BY RANGE (date) ( START (date '2016-01-01') INCLUSIVE END (date '2017-01-01') EXCLUSIVE EVERY (INTERVAL '1 day') );
2. 用户也可以逐个声明并且命名每一个分区。例如:
CREATE TABLE sales (id int, date date, amt decimal(10,2)) DISTRIBUTED BY (id) PARTITION BY RANGE (date) ( PARTITION Jan16 START (date '2016-01-01') INCLUSIVE , PARTITION Feb16 START (date '2016-02-01') INCLUSIVE , PARTITION Mar16 START (date '2016-03-01') INCLUSIVE , PARTITION Apr16 START (date '2016-04-01') INCLUSIVE , PARTITION May16 START (date '2016-05-01') INCLUSIVE , PARTITION Jun16 START (date '2016-06-01') INCLUSIVE , PARTITION Jul16 START (date '2016-07-01') INCLUSIVE , PARTITION Aug16 START (date '2016-08-01') INCLUSIVE , PARTITION Sep16 START (date '2016-09-01') INCLUSIVE , PARTITION Oct16 START (date '2016-10-01') INCLUSIVE , PARTITION Nov16 START (date '2016-11-01') INCLUSIVE , PARTITION Dec16 START (date '2016-12-01') INCLUSIVE END (date '2017-01-01') EXCLUSIVE );
定义数据范围表分区
一个数字范围分区的表使用单个数字数据类型列作为分区分区键列
CREATE TABLE rank (id int, rank int, year int, gender char(1), count int) DISTRIBUTED BY (id) PARTITION BY RANGE (year) ( START (2006) END (2016) EVERY (1), DEFAULT PARTITION extra );
定义列表表分区
一个按列表分区的表可以使用任意允许等值比较的数据类型列作为它的分区键列。一个列表分区也可以用一个多列(组合)分区键,反之一个范围分区只允许单一列作为分区键。对于列表分区,用户必须为每一个用户想要创建的分区(列表值)声明一个分区说明。
CREATE TABLE rank (id int, rank int, year int, gender char(1), count int ) DISTRIBUTED BY (id) PARTITION BY LIST (gender) ( PARTITION girls VALUES ('F'), PARTITION boys VALUES ('M'), DEFAULT PARTITION other );
序列管理
创建序列
CREATE SEQUENCE 命令用给定的序列名称创建并且初始化一个特殊的单行序列生成器表。序列名称必须和同一个方案中任何其他序列、表、索引或者视图的名称不同。
CREATE SEQUENCE myserial START 101;
使用序列
在使用CREATE SEQUENCE创建了一个序列生成器表之后,用户可以使用nextval函数来操作该序列。例如,要向表中插入一个得到序列中下个值的行。
-- 插入时使用序列 INSERT INTO vendors VALUES (nextval('myserial'), 'acme'); -- 重置序列 SELECT setval('myserial', 201); -- 查询序列 SELECT * FROM myserial; -- 修改序列 ALTER SEQUENCE myserial RESTART WITH 105; -- 删除序列 DROP SEQUENCE myserial; -- 设为默认值 CREATE TABLE ... ( id INT4 DEFAULT nextval('id_seq') );
存储模型
Greenplum数据库支持多种存储模型和一种混合存储模型。当用户创建一个表时,用户会选择如何存储它的数据。这个主题解释了表存储的选项以及如何为用户的负载选择最好的存储模型。
注意:为了简化数据库表的创建,可以使用GreenPlum数据库的服务器配置参数gp_default_storage_options为一些表存储选项指定默认值。
堆存储
默认情况下, Greenplum数据库使用和PostgreSQL相同的堆存储模型。堆表存储在OLTP类型负载下表现最好,这种环境中数据会在初始载入后被频繁地修改。UPDATE和DELETE操作要求存储行级版本信息来确保可靠的数据库事务处理。堆表最适合于较小的表,例如维度表,它们在初始载入数据后会经常被更新。
追加优化存储
追加优化表存储在数据仓库环境中的规范化事实表表现最好。规范化事实表通常是系统中最大的表。事实表通常成批地被载入并且被只读查询访问。将大型的事实表改为追加优化存储模型可以消除每行中的更新可见性信息负担,这可以为每一行节约大概20字节。这可以得到一种更加简洁并且更容易优化的页面结构。 追加优化表的存储模型是为批量数据装载优化的,因此不推荐单行的INSERT语句
创建一个堆表
面向行的堆表是默认的存储类型
CREATE TABLE foo (a int, b text) DISTRIBUTED BY (a); -- 可以通过声明with子句声明表的存储选项, 默认是将表创建为面向行的堆存储表。例如,要创建一个不压缩的追加优化表: CREATE TABLE bar (a int, b text) WITH (appendonly=true) DISTRIBUTED BY (a); -- 在一个可序列化事务中的追加优化表上不允许UPDATE和DELETE,它们将导致该事务中止。 追加优化表上不支持CLUSTER、DECLARE…FOR UPDATE和触发器。
存储策略选择
- 面向行的存储:对于OLTP类型的工作负载很好,因为它需要许多迭代事务和单行的许多列,所以检索是高效的。
- 面向列的存储:适量与少量列上计算数据聚集的数据仓库负载,或者是用于对单列定期更新但是不修改其他列的情况。
对于大部分常用目的或者混合负载,面向行的存储提供了灵活性和性能的最佳组合。不过,也有场景中面向列的存储模型提供了更高效的I/O和存储。在为一个表决定存储方向模型时,请考虑下列需求:
- 表数据的更新:如果用户会频繁地装载和更新表数据,请选择一个面向行的堆表。面向列的表存储只能用于追加优化表。
- 频繁的Insert:如果频繁地向表中插入行,请考虑面向行的模型。列存表并未对写操作优化,因为一行的列值必须被写到磁盘上的不同位置。
- 查询要求的列数: 如果在查询的SELECT列表或者WHERE子句中常常要求所有或者大部分列,请考虑面向行的模型。面向列的表最适合的情况是,查询会聚集一个单一列中的很多值且WHERE或者HAVING谓词也在该聚集列上。例如:SELECT SUM(salary)…SELECT AVG(salary)… WHERE salary > 10000。另一种适合面向列的情况是WHERE谓词在一个单一列上并且返回相对较少的行。例如:SELECT salary, dept … WHERE state=’CA’
- 表中的列数:在同时要求很多列或者表的行尺寸相对较小时,面向行的存储会更有效。对于具有很多列的表且查询中访问这些列的一个小子集时,面向列的表能够提供更好的查询性能。
- 压缩:列数据具有相同的数据类型,因此在列存数据上支持存储尺寸优化,但在行存数据上则不支持。
创建一个面向列的表
CREATE TABLE命令的WITH子句指定表的存储选项。默认是面向行的堆表。使用面向列的存储的表必须是追加优化表。
CREATE TABLE bar (a int, b text) WITH (appendonly=true, orientation=column) DISTRIBUTED BY (a);
使用压缩(只能适用于追加优化表)
对于追加优化表,在Greenplum数据库中有两种类型的库内压缩可用:
-- 创建一个压缩表 -- 要创建一个使用zlib压缩且压缩级别为5的追加优化表: CREATE TABLE foo (a int, b text) WITH (appendonly=true, compresstype=zlib, compresslevel=5);
运维操作
基础操作
select * from pg_partitions;
alter table class_one drop partition class_b;
扩容机制
随着数据库数据的不断增长,有时候有必要增加数据库能力来联合不同数据仓库到一个数据库中,针对greenplum数据库类型能够在维护期间进行扩容操作。
在线扩容
Grennplum使用gpexpand工具进行扩容。
gpexpand介绍
gpexpand是在阵列中的新主机上扩展现有的Greenplum数据库的一个工具,具体使用如下:
gpexpand [{-f|--hosts-file} hosts_file] | {-i|--input} input_file [-B batch_size] | [{-d | --duration} hh:mm:ss | {-e|--end} 'YYYY-MM-DD hh:mm:ss'] [-a|-analyze] [-n parallel_processes] | {-r|--rollback} | {-c|--clean} [-v|--verbose] [-s|--silent] [{-t|--tardir} directory ] [-S|--simple-progress ] gpexpand -? | -h | --help gpexpand --version ------------------------------------------------- 具体介绍: -a | --analyze:在扩展后运行ANALYZE更新表的统计信息,默认是不运行ANALYZE。 -B batch_size:在暂停一秒钟之前发送给给定主机的远程命令的批量大小。默认值是16, 有效值是1-128 -c | --clean:删除扩展模式 -d | --duration hh:mm:ss:扩展会话的持续时间。 -e | --end 'YYYY-MM-DD hh:mm:ss':扩展会话的结束日期及时间。 -f | --hosts-file filename:指定包含用于系统扩展的新主机列表的文件的名称。文件的每一行都必须包含一个主机名。 -i | --input input_file:指定扩展配置文件的名称,其中为每个要添加的Segment包含一行,格式为: hostname:address:port:datadir:dbid:content:preferred_role -n parallel_processes:要同时重新分布的表的数量。有效值是1 - 96。 -r | --rollback:回滚失败的扩展设置操作。 -s | --silent:以静默模式运行。在警告时,不提示确认就可继续。 -S | --simple-progress:果指定,gpexpand工具仅在Greenplum数据库表 gpexpand.expansion_progress中记录最少的进度信息。该工具不在表 gpexpand.status_detail中记录关系大小信息和状态信息。 [-t | --tardir] directory:Segment主机上一个目录的完全限定directory,gpexpand 工具会在其中拷贝一个临时的tar文件。该文件包含用于创建Segment实例的Greenplum数据库文件。 默认目录是用户主目录。 -v | --verbose:详细调试输出。使用此选项,该工具将输出用于扩展数据库的所有DDL和DML。 --version:显示工具的版本号并退出。
gpexpand工具分为两个阶段执行系统扩展:segment初始化和表重新分布。
- 在初始化阶段,gpexpand用一个输入文件运行,该文件指定新Segment的数据目录、 dbid值和其他特征。用户可以手动创建输入文件,也可以在交互式对话中 按照提示进行操作。
- 在表数据重分布阶段,gpexpand会重分布表的数据,使数据在新旧segment 实例之间平衡
要开始重分布阶段,可以通过运行gpexpand并指定-d(运行时间周期) 或-e(结束时间)选项,或者不指定任何选项。如果客户指定了结束时间或运行周期,工具会在扩展模式下重分布表,直到达到设定的结束时间或执行周期。如果没指定任何选项,工具会继续处理直到扩展模式的表 全部完成重分布。每张表都会通过ALTER TABLE命令来在所有的节点包括新增加的segment实例 上进行重分布,并设置表的分布策略为其原始策略。如果gpexpand完成所有表的重分布,它会 显示成功信息并退出。
纵向扩容
1. 查看数据库状态
运行命令:gstate查看当前数据库状态
因为我在其余机器上无法进行截图,信息概述为:一个master节点,一个standby节点,三个数据节点,每个数据节点存放一个主节点与镜像节点。
需要先创建出新的目录,可以使用gpssh命令或者手动创建对应目录。
primary:/apps/data2/primary mirror:/apps/data2/mirror
目录权限均为gpadmin的用户权限。
2. 初始化
- 执行命令gpexpand -f seg_hosts,根据提示输入对应的命令。
执行完毕后,会在当前目录下生成一个gpexpand_inputfileXXXXX的文件。
运行 gpexpand -i gpexpand_inputfile_20240201_141705,等待便可,如果出现错误,系统会有相应提示错误信息,且后面执行gpexpand -r进行回滚即可。
如果错误信息不明显,可以到对应seg节点下查看启动日志,会有详细信息。
再次使用gpstate节点,发现segment增长了两个。
3. 重分布
执行命令:gpexpand -d 1:00:00 #不动命令回去看gpexpand命令说明,这里没有业务表,所以很快就重分布完成了,如果数据量很大,可以增加线程。
4. 移除扩容schema
扩容成功,数据重分布成功后记得使用analyze或者analyzedb进行分析。
横向扩容
当前场景下更多的数据节点来分布分布,提交数据计算速率,现重新申请出两台机器做数据节点。
| 主机名称 | 主机IP | 备注 |
| sdw4 | 192.168.57.175 | 数据节点 |
| sdw5 | 192.168.57.176 | 数据节点 |
环境准备
现增加的数据节点,需要按照之前前三个数据节点进行同样的服务器配置。
安装构建
#拷贝master主机的安装目录 cd /usr/local && tar -cf /usr/local/gp6.tar greenplum-db-6.26.0 #master主机操作 scp gp6.tar gpadmin@mdw1:/home/gpadmin/ #master主机操作 scp gp6.tar gpadmin@mdw1:/home/gpadmin/ #master主机操作 cd /home/gpadmin/ tar -xf gp6.tar ln -s greenplum-db-6.26.0 greenplum-db chown -R gpadmin:gpadmin greenplum-db* --创建数据目录 mkdir /data/p1 mkdir /data/p2 mkdir /data/m1 mkdir /data/m2 chown -R gpamdin:gpamdin /data #master操作,增设免密操作 ssh-copy-id sdw4 ssh-copy-id sdw5
修改seg_hosts,all_hosts文件
追加: sdw4 sdw5 #执行命令 gpssh-exkeys -f all_hosts
创建初始化文件
gpexpand -f seg_hosts
初始化操作
# 初始化 gpexpand -i 生成的inputfile文件 # 重新分布 gpexpand -d 1:00:00 # 移除扩容schema gpexpand -c gpstate # 检测节点是否正常运行