机器学习课程
前言
课程代码和数据文件:
一、机器学习概述
1.1.人工智能概述
- 机器学习和人工智能,深度学习的关系
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
- 达特茅斯会议-人工智能的起点
- 1956年8月,在美国汉诺斯小镇宁静的达特茅斯学院中约翰·麦卡锡(John McCarthy)、马文·闵斯基(Marvin Minsky,人工智能与认知学专家)、克劳德·香农(Claude Shannon,信息论的创始人)、艾伦·纽厄尔(Allen Newell,计算机科学家)、赫伯特·西蒙(Herbert Simon,诺贝尔经济学奖得主)等科学家正聚在一起讨论着一个完全不食人间烟火的主题:用机器来模仿人类学习以及其他方面的智能。会议足足开了两个月的时间,虽然大家没有达成普遍的共识,但是却为会议讨论的内容起了一个名字:人工智能。
- 机器学习、深度学习可以做些什么
- 机器学习的应用场景非常多,可以说渗透到了各个行业领域当中。医疗、航空、教育、物流、电商等等领域的各种场景。
- 机器学习领域主要包括三个方面:自然语言处理、图像识别、传统预测。
- 用在挖掘、预测领域,应用场景:店铺销量预测、量化投资、广告推荐、企业客户分类、SQL语。句安全检测分类等等
- 用在图像领域,应用场景:街道交通标志检测、人脸识别等等
- 用在自然语言处理领域,应用场景:文本分类、情感分析、自动聊天、文本检测等等
1.2.什么是机器学习
- 定义:机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测
- 数据集构成
- 结构:特征值+目标值
- 有些数据集可以没有目标值
1.3.机器学习算法分类
- 监督学习:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)
- 分类问题
- 特征值:猫/狗的图片;
- 目标值:猫/狗的类别;
- 分类算法:k-近邻算法、贝叶斯分类、决策树、随机森林、逻辑回归;
- 回归问题
- 特征值:房屋的各个属性信息;
- 目标值:房屋的价格-连续性数据;
- 回归算法:线性回归、岭回归;
- 分类问题
- 无监督学习:输入数据是由输入特征值所组成。
- 特征值:人物的各个属性信息;
- 目标值:无
- 聚类算法:k-means
1.4.机器学习开发流程
1、原始数据
=>
2、数据特征工程(训练数据和测试数据)
=>
3、算法进行学习
=>
4、模型
=>
5、模型评估(测试数据)
=>
6、模型选择
=>
7、判断模型是否合格
=>
8、模型应用
如果模型不合格,重复进行 3 - 7 阶段,知道模型符合要求。
二、特征工程
2.1.数据集
2.1.1.可用数据集
- scikit-learn:Find Open Datasets and Machine Learning Projects | Kaggle
- 数据量较小
- 方便学习
- UCI:UCI Machine Learning Repository
- 收录了300+个数据集
- 覆盖科学、生活、经济等领域
- 数据量几十万
- Kaggle:scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
- 大数据竞赛平台
- 80万科学家
- 真实数据
- 数据量巨大
2.1.2.Scikit-learn工具
1、介绍
- Python语言的机器学习工具;
- Scikit-learn包括许多知名的机器学习算法的实现:分类、回归、聚类、降维、模型选择、特征工程;
- 文档完善,容易上手,丰富的API;
2、安装
pip install scikit-learn3、Scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
4、数据集的使用
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples*n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
from sklearn.datasets import load iris# 获取鸢尾花数据集
iris = load_iris()
print(“鸢尾花数据集的返回值:\n",iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris['data"])
print("鸢尾花的目标值:\n", iris.target)
print(“鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print(“鸢尾花的描述:\n", iris.DESCR)5、数据集的划分
- 机器学习一般的数据集会划分为两个部分
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
- 划分比例
- 训练集:70%80%75%
- 测试集:30%20%25%
- 数据集划分api
- sklearn.model_selecion.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test _size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 训练集特征值,测试集特征值,训练集目标值,测试集目标值
- sklearn.model_selecion.train_test_split(arrays, *options)
from sklearn.model_selection import train_test_split# 训练集的特征值:x_train, 测试集的特征值:x_test, 训练集的目标值:y_train, 测试集的目标值:y_test, test_size:随机数种子
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)2.2.特征工程
1、为什么需要特征工程
业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
2、什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
2.3.特征抽取
2.3.1.什么是特征抽取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(会在深度学习中涉及到)
2.3.2.特征提取API
sklearn.feature_extraction2.3.3.字典特征提取
1、作用:对字典数据进行特征值化
- sklearn.feature_extraction.DictWectorizer(sparse=True,...)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器
- 返回值:返回sparse矩阵
- DictVectorizer.inverse_transform(X)
- X:array数组或者sparse矩阵
- 返回值:转换之前数据格式
- DictVectorizer.get _feature_names()
- 返回类别名称
- DictVectorizer.fit_transform(X)
2、Demo
这里有一个独热(one-hot)编码的概念:机器学习:数据预处理之独热编码(One-Hot)详解-CSDN博客
from sklearn.feature_extraction import DictVectorizerdef dict_demo():"""字典特征抽取:return:"""data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=True)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray(), type(data_new))print("特征名字:\n", transfer.get_feature_names())return None2.3.4.文本特征提取
1、作用:对文本数据进行特征值化
- sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- stop_words:停用词表,把不需要的词语去掉
- 返回词频矩阵
- CountVectorizer.fit_transform(X)
- X:文本或者包含文本字符串的可迭代对象
- 返回值:返回sparse矩阵
- CountVectorizer.inverse_transform(X)
- X:array数组或者sparse矩阵
- 返回值:转换之前数据格
- CountVectorizer.get_feature_names()
- 返回值:单词列表
- sklearn.feature extraction.text.TfidfVectorizer
- Tf-idf 文本特征提取
- TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度;
- 公式:
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的 idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
- tfidf = tf x idf
- 例子:语料库-1000篇文章,其中100篇文章中有“非常”这个词,现在有一篇文章,她有100个词,“非常”这个词出现了10次,那它的 tf = 10/100 = 0.1, idf = lg 1000/100 = 1,tfidf = 0.1 x 1 = 0.1
- Tf-idf 文本特征提取
2、Demo1:文本特征抽取
from sklearn.feature_extraction.text import CountVectorizerdef count_demo():"""文本特征抽取:CountVecotrizer:return:"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer(stop_words=["is", "too"])# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names())return None3、Demo2:中文文本抽取
from sklearn.feature_extraction.text import CountVectorizerdef count_chinese_demo():"""中文文本特征抽取,自动分词:return:"""# 将中文文本进行分词data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))# print(data_new)# 1、实例化一个转换器类transfer = CountVectorizer(stop_words=["一种", "所以"])# 2、调用fit_transformdata_final = transfer.fit_transform(data_new)print("data_new:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门":param text::return:"""return " ".join(list(jieba.cut(text)))4、Demo3:用TF-IDF的方法进行文本特征抽取
from sklearn.feature_extraction.text import TfidfVectorizerdef tfidf_demo():"""用TF-IDF的方法进行文本特征抽取:return:"""# 将中文文本进行分词data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))# print(data_new)# 1、实例化一个转换器类transfer = TfidfVectorizer(stop_words=["一种", "所以"])# 2、调用fit_transformdata_final = transfer.fit_transform(data_new)print("data_new:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门":param text::return:"""return " ".join(list(jieba.cut(text)))2.4.特征预处理
2.4.1.什么是特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据的过程。
2.4.2.特征预处理的方法
- 归一化
- 标准化
2.4.3.特征预处理的API
sklearn.preprocessing2.4.4.为什么要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征。
2.4.5.归一化
1、定义
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
2、公式

作用于每一列,max为一列的最大值,min为一列的最小值,X''为最终结果,mx,mi分别为指定区间,默认mx为1,mi为0
3、例子
对60进行归一化,X' = (60 - 60) / (90 - 60) = 0;X'' = 0 * (1 - 0) + 0 = 0
对3进行归一化,X' = (3 - 2) / (4 - 2) = 0.5;X'' = 0.5 * (1 - 0) + 0 = 0.5

4、API
- sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)...)
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
- MinMaxScalar.fit_transform(X)
5、Demo
约会对象数据-datingg.txt
如果报错的话,将[2, 3]改为(2, 3)
sklearn.utils._param_validation.InvalidParameterError: The 'feature_range' parameter of MinMaxScaler must be an instance of 'tuple'. Got [2, 3] instead.from sklearn.preprocessing import MinMaxScaler
import pandas as pddef minmax_demo():"""归一化:return:"""# 1、获取数据data = pd.read_csv("datingg.txt")data = data.iloc[:, :3]print("data:\n", data)# 2、实例化一个转换器类transfer = MinMaxScaler(feature_range=[2, 3])# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None6、总结
最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响所以这种方法鲁棒性较差,只适合传统精确小数据场景。
2.4.6.标准化
1、定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
2、公式

作用于每一列,mean为平均值,ó为标准差
3、API
- sklearn.preprocessing.StandardScaler()
- 处理之后,对每列来说,所有数据都聚集在均值为0附近,标准差为1
- StandardScaler.fit_transform(X)
- "X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
5、Demo
from sklearn.preprocessing import StandardScalerdef stand_demo():"""标准化:return:"""# 1、获取数据data = pd.read_csv("dating.txt")data = data.iloc[:, :3]print("data:\n", data)# 2、实例化一个转换器类transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None6、总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
2.5.特征降维
2.5.1.什么是特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大。
2.5.2.降维的两种方式
- 特征选择
- 主成分分析(可以理解为一种特征提取的方式)
2.5.3.特征选择
1、定义
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
2、方法
特征选择方法最全总结!
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数
- Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
3、模块
sklearn.feature_selection2.5.3.1.特征选择 - 过滤式
2.5.3.1.1.低方差特征过滤
1、低方差特征过滤
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
2、API
- sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- 删除所有低方差特征
- Variance.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
3、案例
我们对某些股票的指标特征之间进行一个筛选,数据在“factor_returns.csv”文件当中,除去'index,'date',return'列不考虑(这些类型不匹配,也不是所需要指标)

from sklearn.feature_selection import VarianceThreshold
import pandas as pddef variance_demo():"""过滤低方差特征:return:"""# 1、获取数据data = pd.read_csv("factor_returns.csv")data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=10)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)return None2.5.3.1.2.相关系数
1、相关系数
- 皮尔逊相关系数(Pearson Correlation Coefficient)
- 反应变量之间相关关系密切程度的统计指标
2、公式

3、计算案例
比如说计算广告费和月平均销售额的相关性

那么之间的相关系数怎么计算

最终计算
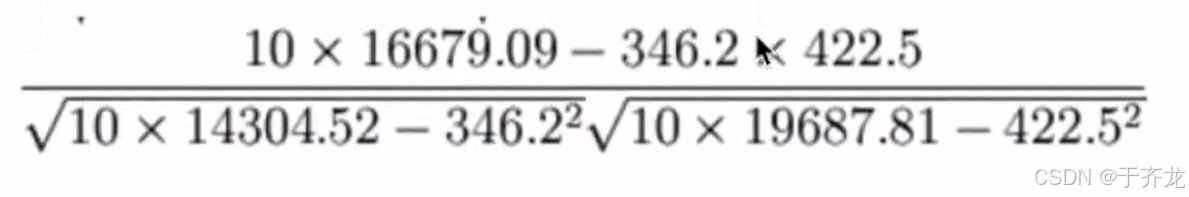 所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系。
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系。
4、特点
相关系数的值介于 -1 与 +1 之间,即 -1 ≤ r ≤ +1。其性质如下:
- 当 r > 0 时,表示两变量正相关,r < 0 时,两变量为负相关
- 当 |r| = 1 时,表示两变量为完全相关,当 r = 0 时,表示两变量间无相关关系
- 当 0 < |r| < 1时,表示两变量存在一定程度的相关。且 |r| 越接近1,两变量间线性关系越密切;|r| 越接近于0,表示两变量的线性相关越弱
- 一般可按三级划分:|r| < 0.4 为低度相关;0.4 ≤ |r| < 0.7 为显著性相关;0.7 ≤ |r| <1为高度线性相关
5、API
- from scipy.stats import pearsonr
- x:(N,) array_like
- y:(N,) array_like Returns:(Pearson's correlation coefficient, pvalue)
6、案例:股票的财务指标相关性计算
from scipy.stats import pearsonrdef pearsonr_demo():"""相关系数:return:"""# 1、获取数据data = pd.read_csv("factor_returns.csv")data = data.iloc[:, 1:-2]print("data:\n", data)# 2、计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data['revenue'], data['total_expense'])print("revenue与total_expense之间的相关性:\n", r2)return None2.5.4.主成分分析
1、什么是主成分分析(PCA)
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
- 作用:使数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析当中
例子:
将下面二维平面上的5个点,降维到一维向量上

2、API
- sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X)
- X:numpy array格式的数据[n_samples,n features]
- 返回值:转换后指定维度的array
3、Demo
def pca_demo():"""PCA降维:return:"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化一个转换器类transfer = PCA(n_components=0.95)# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None4、案例
Instacart市场菜篮子分析
Instacart消费者将购买哪些产品?
参考:day01_instacart_pca.ipynb
三、分类算法
四、回归与聚类算法
相关文章:
机器学习课程
前言 课程代码和数据文件: 一、机器学习概述 1.1.人工智能概述 机器学习和人工智能,深度学习的关系 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来 达特茅斯会议-人工智能的起点 1956年8月,在美国汉诺斯小镇宁静…...

AIGC(生成式AI)试用 28 -- 跟着清华教程学习 - AIGC发展研究 3.0
目标:继续学习 - 信息不对称、不平等、隐私泄露和数据滥用 - 问、改、创、优 - “概率预测(快速反应)”模型和“链式推理(慢速思考)”模型 - 思维滞环现象解决思路:1.调整提问:改变问题方式&…...

问题:md文档转换word,html,图片,excel,csv
文章目录 问题:md文档转换word,html,图片,excel,csv,ppt**主要职责****技能要求****发展方向****学习建议****薪资水平** 方案一:AI Markdown内容转换工具打开网站md文档转换wordmd文档转换pdfm…...

【Java】面向对象之static
用static关键字修饰成员变量 有static修饰成员变量,说明这个成员变量是属于类的,这个成员变量称为类变量或者静态成员变量。 直接用 类名访问即可。因为类只有一个,所以静态成员变量在内存区域中也只存在一份。所有的对象都可以共享这个变量…...
`时,程序会等待你手动关闭图片窗口才能继续往下执行)
解决:在运行 plt.show()`时,程序会等待你手动关闭图片窗口才能继续往下执行
你这个问题本质是: 在运行 plt.show() 时,程序会等待你手动关闭图片窗口才能继续往下执行。 这其实是 matplotlib 的默认行为 —— 它会弹出一个交互式窗口让你“看完图再走”。 ✅ 为什么会这样? 你在程序中使用了: import mat…...

Anaconda安装-Ubuntu-Linux
1、进入Anaconda官网,以下载最新版本,根据自己的操作系统选择适配的版本。 2、跳过注册: 3、选择适配的版本: 4、cd ~/anaconda_download 5、bash Anaconda3-2024.10-1-Linux-x86_64.sh 6、按Enter或PgDn键滚动查看协议&…...

Linux 配置NFS服务器
1. 开放/nfs/shared目录,供所有用户查阅资料 服务端 (1)安装nfs服务,nfs-utils包中包含rpcbind(rpc守护进程) [rootnode1-server ~]# yum install -y nfs-utils # nfs-utils包中包含rpcbind [rootnode…...

css100个问题
一、基础概念 CSS的全称及作用是什么?行内样式、内部样式表、外部样式表的优先级?解释CSS的层叠性(Cascading)CSS选择器优先级计算规则伪类与伪元素的区别?举例说明!important的作用及使用注意事项如何继承父元素字体…...

塔能科技:用精准节能撬动社会效益的行业杠杆
在全球积极践行可持续发展理念的当下,能源高效利用与节能减排,已然成为各行各业实现高质量发展绕不开的关键命题。对企业来说,节能早已不是一道可做可不做的选择题,而是关乎生存与发展、社会责任与竞争力的必答题。塔能科技推出的…...

Java 大视界 -- Java 大数据在自动驾驶高精度地图数据更新与优化中的技术应用(157)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Conda配置Python环境
1. 安装 Conda 选择发行版: Anaconda:适合需要预装大量科学计算包的用户(体积较大)。 Miniconda:轻量版,仅包含 Conda 和 Python(推荐自行安装所需包)。 验证安装: co…...

nginx https配置
一.https配置 HTTPS 协议是由HTTP 加上TLS/SSL 协议构建的可进行加密传输、身份认证的网络协议,主要通过数字证书、加密算法、非对称密钥等技术完成互联网数据传输加密,实现互联网传输安全保护。 1.生成证书 openssl genrsa -des3 -out server.key 20…...

每日一题洛谷P10901 [蓝桥杯 2024 省 C] 封闭图形个数c++
排序思想,只不过这时的排序与之前的略有不同,com函数中要先比较封闭图形再比较真实的大小,多了一步,但是原理还是一样的 #include<iostream> #include<algorithm> #include<vector> using namespace std; //统…...

拓展知识六:MetInfo6.0.0目录遍历漏洞原理分析
所需进行代码审计的文件路径: C:\phpStudy\WWW\MetInfo6.0.0\include\thumb.php C:\phpStudy\WWW\MetInfo6.0.0\app\system\entrance.php C:\phpStudy\WWW\MetInfo6.0.0\app\system\include\class\load.class.php C:\phpStudy\WWW\MetInfo6.0.0\app\system\include…...

tar包部署rabbitMQ
部署erlang: 有网使用: sudo apt-get update sudo apt-get install libncurses5-dev libncursesw5-dev sudo yum install ncurses-devel 无网使用 tar zxvf ncurses.tar.gz mkdir ncurses cd ncurses-6.3/ ./configure --with-shared --without-debu…...

天锐蓝盾终端安全防护——企业终端设备安全管控
从办公室的台式电脑到员工手中的移动终端,这些设备不仅是工作的得力助手,更是企业数据的重要载体。然而,随着终端设备的广泛使用,安全风险也如影随形。硬件设备使用不当、数据随意传输等问题频发,使得企业数据面临着泄…...

MySQL高级特性与大数据应用
事务与锁机制 1.1 事务控制 START TRANSACTION; UPDATE account SET balance balance - 500 WHERE user_id 1001; UPDATE account SET balance balance 500 WHERE user_id 2002; COMMIT; -- 显式提交事务 ROLLBACK; -- 异常时回滚 1.2 锁机制 锁类型:共…...
处理音频数据的输出的函数)
小智机器人关键函数解析,Application::OutputAudio()处理音频数据的输出的函数
以下是对 Application::OutputAudio() 函数的详细解释: 源码: void Application::OutputAudio() { // 扬声器的输出auto now std::chrono::steady_clock::now();auto codec Board::GetInstance().GetAudioCodec();const int max_silence_seconds 10;…...
)
玛卡巴卡的k8s知识点问答题(五)
17. Init 类型容器有什么特点,主要用途? 特点: 启动顺序:Init 容器在普通容器启动之前运行,必须先完成所有 Init 容器后,Pod 的主容器才会启动。 顺序执行:如果定义了多个 Init 容器ÿ…...

3.27学习总结 爬虫+二维数组+Object类常用方法
高精度: 一个很大的整数,以字符串的形式进行接收,并将每一位数存储在数组内,例如100,即存储为[1][0][0]。 p2437蜜蜂路线 每一个的路线数前两个数的路线数相加。 #include <stdio.h> int a[1005][1005]; int …...

kafka零拷贝技术的底层实现
什么是 Sendfile? sendfile 是一种操作系统提供的系统调用(system call),用于在两个文件描述符(file descriptor)之间高效传输数据。它最初由 Linux 内核引入(从 2.1 版本开始)&…...

MFC中CMap类的用法和原理
1、CMap 的原理 CMap 是一个基于哈希表的映射类,它将唯一键映射到对应的值。其内部实现依赖于哈希算法,通过哈希函数将键转换为哈希值,然后将哈希值映射到哈希表中的某个位置。如果多个键的哈希值相同(即哈希冲突)&am…...

elementplus的el-tabs路由式
在使用 Element Plus 的 el-tabs 组件,实现路由式的切换(即点击标签页来切换不同的路由页面)。下面是一个基于 Vue 3 和 Element Plus 实现路由式 el-tabs 的基本步骤和示例。 步骤 1: 安装必要的库 在vue3项目安装 Vue Router 和 Element …...

数据结构初阶:单链表
序言: 本篇博客主要介绍单链表的基本概念,包括如何定义和初始化单链表,以及如何进行数据的插入,删除和销毁等操作。 1.单链表 1.1 概念与结构 概念:链表是一种非顺序的存储结构,数据元素的逻辑顺序是通过…...

北斗导航 | 改进伪距残差矢量的接收机自主完好性监测算法原理,公式,应用,RAIM算法研究综述,matlab代码
改进伪距残差矢量的接收机自主完好性监测算法研究 摘要 接收机自主完好性监测(RAIM)是保障全球卫星导航系统(GNSS)可靠性的核心技术。本文针对传统伪距残差矢量法在微小故障检测和多故障隔离中的不足,提出一种融合加权奇偶空间与动态阈值调整的改进算法。通过理论推导验证…...

RabbitMQ高级特性--TTL和死信队列
目录 1.TTL 1.1设置消息的TTL 1.1.1配置交换机&队列 1.1.2发送消息 1.1.3运行程序观察结果 1.2设置队列的TTL 1.2.1配置队列和交换机的绑定关系 1.2.2发送消息 1.2.3运行程序观察结果 1.3两者区别 2.死信队列 2.1 声名队列和交换机 2.2正常队列绑定死信交换机 …...

Java后端开发: 如何安装搭建Java开发环境《安装JDK》和 检测JDK版本
文章目录 一、JDK的安装1、 打开 Oracle 官方网址2、点击产品 二、检测JDK是否安装成功以及JDK版本的查看1. 打开命令行窗口检测是否安装成功查看 JDK 版本 一、JDK的安装 1、 打开 Oracle 官方网址 Oracle官网地址:https://www.oracle.com/cn/ 2、点击产品 打开下载的JDK文件…...
LabVIEW液压控制系统开发要点
液压控制系统开发需兼顾高实时性、强抗干扰性和安全性,尤其在重工业场景中,毫秒级响应延迟或数据异常都可能导致设备损坏。本文以某钢厂液压升降平台项目为例,从硬件选型、控制算法、安全机制三方面,详解LabVIEW开发中的关键问题与…...

鸿蒙Flutter实战:18-组合而非替换,现有插件快速鸿蒙化
引言 在对插件鸿蒙化时,除了往期文章现有Flutter项目支持鸿蒙II中讲到的使用 dependency_overrides 来配置鸿蒙适配库的两种方式以外,如果三方插件本身使用了联合插件的形式,也可以通过下面这种方式来添加鸿蒙平台的实现: depen…...

Qt之Service开发
一、概述 基于Qt的用于开发系统服务(守护进程)和后台服务,有以下几个优秀的开源 QtService 框架和库。 1. QtService (官方解决方案) GitHub: https://github.com/qtproject/qt-solutions/tree/master/qtservice 特点: 官方提供的服务框架 支持 Windows 服务和 Linux 守护…...