linux-5.10.110内核源码分析 - 写磁盘(从VFS系统调用到I/O调度及AHCI写磁盘)
1、VFS写文件到page缓存(vfs_write)
1.1、写裸盘(dd)
使用如下命令写裸盘:
dd if=/dev/zero of=/dev/sda bs=4096 count=1 seek=11.2、系统调用(vfs_write)
系统调用栈如下:

对于调用栈的new_sync_write函数,buf为写磁盘的内容的内存地址,也就是从/dev/zero读取上来的数据(全0),len为数据长度,也就是4096(块大小为4096,共一个块,也就是4096 bytes),*ppos为偏移,也就是跳过1个bs(4096)。
wirte系统调用的数据地址及长度保存到了iovec里面,偏移保存到了kiocb:

1.3、写文件缓存(mapping)
块设备也是一个文件,以4k page为单位对块设备内容进行缓存,页缓存保存在mapping里面,写块设备的时候,如果有对应的缓存则写该page缓存,如果没有则创建page缓存。
1.4、写块设备位置(__generic_file_write_iter)
前面wirte系统调用介绍了,写偏移保存到了kiocb里面,最终在__generic_file_write_iter读取并传递给下一级函数,代码如下:

这个pos的单位是byte,当前dd命令写的4096偏移。
1.5、查找page缓存(find_get_entry)
前面介绍了文件系统以4k page为单位缓存文件内容,将一个物理硬盘划分为n个page,wirte系统调用传递了写偏移,偏移pos除以page大小也就是page索引(内核用移位代替除法),代码如下:

根据page的索引index获取page,代码如下:

函数调用栈如下:

(之前没有读该page也没有写该page,当前返回空指针)
1.6、创建page缓存(add_to_page_cache_lru)
pagecache_get_page获取page缓存失败的情况,会创建一个page,并添加到cache的lru里面,也就是前面的mapping->i_pages,代码如下:

函数调用栈如下:

__add_to_page_cache_locked会将page的index设置为offset,这里的offset是写偏移offset对应的page索引(*ppos对应的page索引,后面不再用pos,写磁盘以页为单位,pos不一定以page对齐,如果pos不以page对齐,并且没有缓存,那么写操作会先从磁盘读取一页上来,与当前写的数据合并),后面内核代码都以page索引来写磁盘。
1.7、写缓存(iov_iter_copy_from_user_atomic)
拷贝比较简单,主要就是将前面传递过来的iov_iter里面的数据拷贝到查找或者创建的page缓存里面,代码如下:

函数调用栈:

2、写page缓存到bio(blkdev_writepage)
写page过程,主要通过PageDirty判断文件的page缓存是否为脏(是否被修改,前面写page的时候会标记对应的page为dirty)
2.1、判断page缓存是否dirty(PageDirty)
write_cache_pages函数主要就是遍历文件缓存,找到dirty的page,然后写磁盘,判断dirty代码如下:

2.2、创建初始化bio(submit_bh_wbc)
(前面写数据的时候,会调用attach_page_private给page设置一个buffer_head,在__block_write_begin_int里面会根据page->index计算page对应的扇区,扇区、块设备相关信息会保存到buffer_head里面,前面忽略了,这里简要解释一下,因为submit_bh_wbc会用到这些信息)
submit_bh_wbc将块设备及扇区信息保存到bio的代码如下:

submit_bh_wbc函数调用栈:
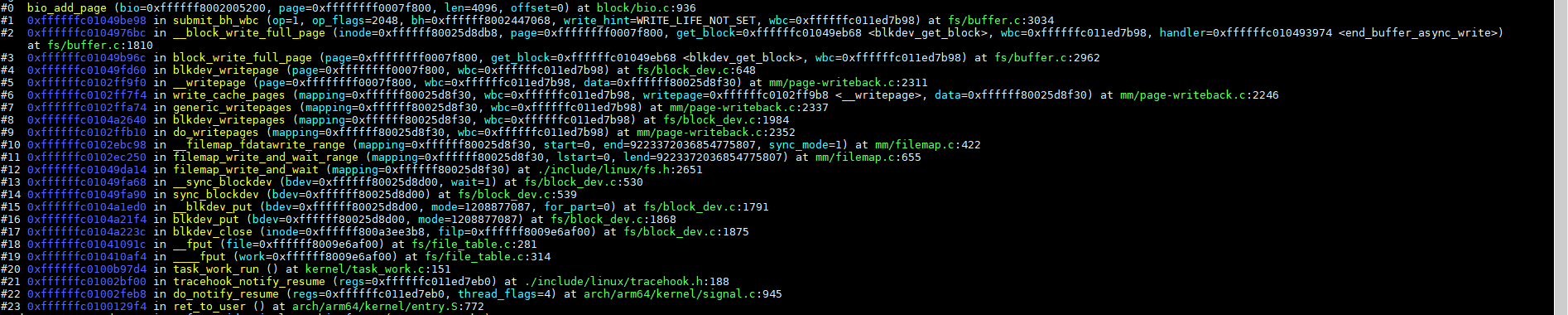
2.3、添加page到bio(__bio_add_page)
添加page过程比较简单,主要就是添加page到bio->bi_io_vec,bio->bi_io_vec是一个数组,一个个page追加到数组末尾,当前只写一个page,不涉及合并操作,__bio_add_page代码如下:

__bio_add_page调用栈如下:
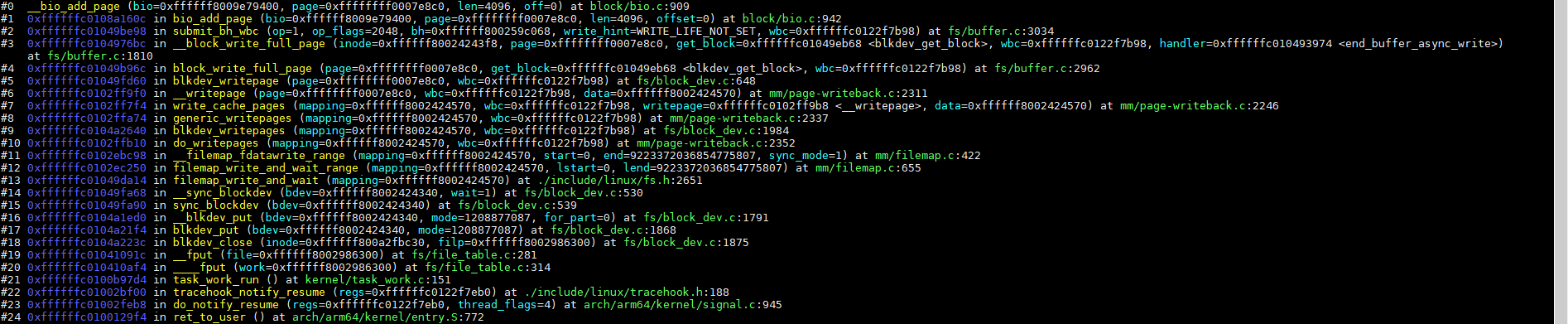
3、提交bio(blk_mq_submit_bio)
3.1、获取request请求(__blk_mq_alloc_request)
__blk_mq_alloc_request调用blk_mq_get_ctx获取当前线程上下文,调用blk_mq_map_queue映射请求到硬件队列,调用blk_mq_get_tag尝试从硬件队列中获取一个可用的标签,用于标识请求,这个tag标签不是硬件相关的,而是一个软件上唯一的tag标签。(这个标签跟/sys/class/block/sda/queue/nr_requests I/O 请求队列中最大并发请求数的值有关,允许最多nr_requests个tag,就是允许最多同时下发nr_requests请求,具体可以查看blk_mq_update_nr_requests、blk_mq_get_tag,__blk_mq_alloc_request函数也可以看到,获取不到tag的时候,__blk_mq_alloc_request重复尝试获取tag)
__blk_mq_alloc_request相关代码如下:

获取到tag之后, __blk_mq_alloc_request调用blk_mq_rq_ctx_init分配并初始化一个request。
3.2、bio转request(blk_mq_bio_to_request)
blk_mq_bio_to_request主要就是将bio的扇区地址以及bio等保存到request里面,代码如下:
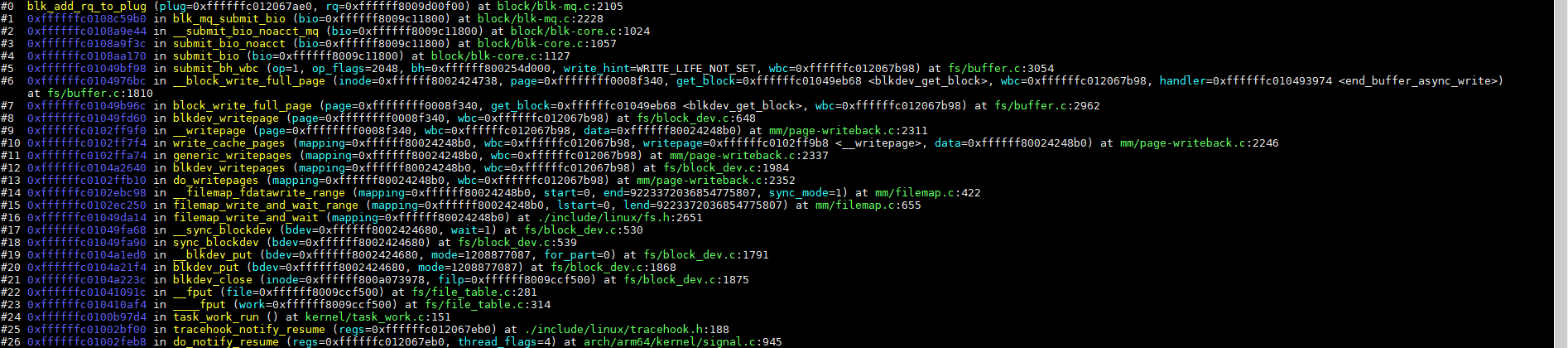
3.3、将request添加到plug的mq_list(blk_add_rq_to_plug)
(blk_mq_submit_bio有很多路径,不同场景走的分支不一样,本文仅针对当前实际场景)
blk_mq_submit_bio调用blk_add_rq_to_plug将请求先添加到当前进程的plug队列里面,代码如下:

函数调用栈如下:
3.4、刷request(blk_finish_plug)
在将所有page经过一系列操作转request保存到plug之后,调用blk_finish_plug,刷当前进程的plug:

blk_finish_plug最终调用blk_mq_flush_plug_list将plug里面的request发送到不同的队列,代码如下:
void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{// 创建一个临时链表头用于存储任务队列LIST_HEAD(list);// 如果当前插件的多队列链表为空,则直接返回if (list_empty(&plug->mq_list))return;// 将插件中的任务队列移动到临时链表中,并清空原链表list_splice_init(&plug->mq_list, &list);// 如果任务数量大于2且支持多个队列,则对任务进行排序if (plug->rq_count > 2 && plug->multiple_queues)list_sort(NULL, &list, plug_rq_cmp);// 初始化任务计数器plug->rq_count = 0;// 循环处理临时链表中的任务do {// 创建一个局部链表头,用于存储当前批次的任务struct list_head rq_list;// 获取当前链表的第一个任务,并将其从链表中移除struct request *rq, *head_rq = list_entry_rq(list.next);struct list_head *pos = &head_rq->queuelist; /* 跳过第一个任务 */struct blk_mq_hw_ctx *this_hctx = head_rq->mq_hctx;struct blk_mq_ctx *this_ctx = head_rq->mq_ctx;unsigned int depth = 1;// 遍历剩余的任务,将属于同一硬件上下文和上下文的任务归为一批list_for_each_continue(pos, &list) {rq = list_entry_rq(pos);BUG_ON(!rq->q); // 确保任务队列不为空if (rq->mq_hctx != this_hctx || rq->mq_ctx != this_ctx)break;depth++;}// 将当前批次的任务从链表中切分出来list_cut_before(&rq_list, &list, pos);// 跟踪任务未插队事件,记录队列、深度以及是否来自调度程序trace_block_unplug(head_rq->q, depth, !from_schedule);// 将当前批次的任务插入调度队列blk_mq_sched_insert_requests(this_hctx, this_ctx, &rq_list,from_schedule);} while (!list_empty(&list)); // 如果链表不为空,则继续处理
}
(说明:代码注释由chartGPT自动生成)
4、request插入到调度队列(blk_mq_sched_insert_requests)
(SATA调度的请求没有经过blk_mq_ctx队列,请求直接存入了blk_mq_hw_ctx->queue->elevator->elevator_data里面。)
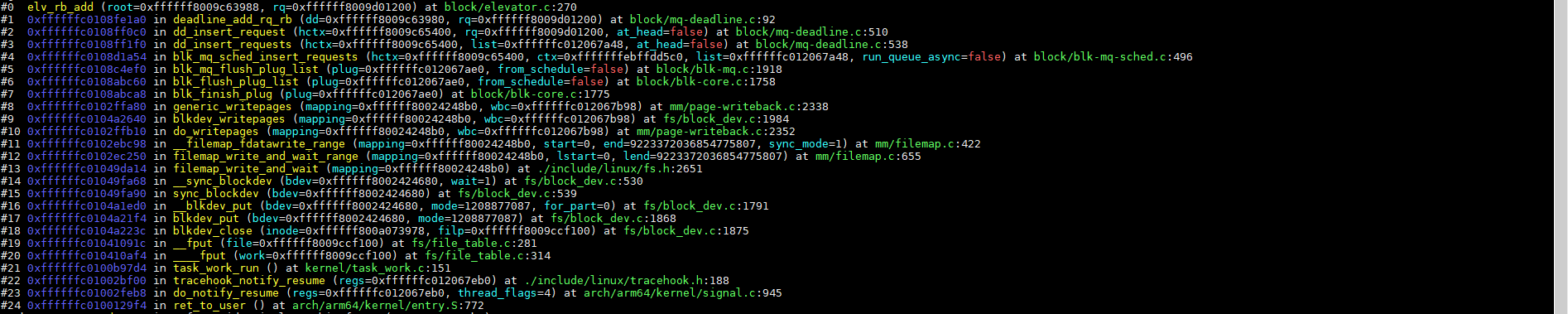
4.1、将request插入到Deadline调度器(deadline_add_rq_rb)
当前dd写的sata硬盘,使用deadline调度算法;deadline_add_rq_rb将前面blk_mq_flush_plug_list获取的request插入到Deadline调度器,elv_rb_add函数代码如下:
/*** elv_rb_add - 将请求插入到红黑树中,并保持排序顺序。* @root: 红黑树的根节点指针。* @rq: 要插入的请求节点。** 该函数实现了一个典型的红黑树插入操作,同时根据请求的位置进行排序。*/
void elv_rb_add(struct rb_root *root, struct request *rq)
{// 定义一个指向红黑树根节点的指针变量 p,初始值为 root 的子节点指针。struct rb_node **p = &root->rb_node;// 定义一个指向当前父节点的指针变量 parent,用于记录插入位置的上一级节点。struct rb_node *parent = NULL;// 定义一个临时变量 __rq,用于存储当前遍历到的红黑树节点对应的请求。struct request *__rq;// 开始遍历红黑树,找到合适的插入位置。while (*p) { // 将当前节点赋值给 parent,以便后续插入时作为新节点的父节点。parent = *p; // 将当前节点转换为请求结构体,方便比较请求的顺序。__rq = rb_entry(parent, struct request, rb_node); // 如果当前请求的扇区号小于待插入请求的扇区号,则向左子树继续查找。if (blk_rq_pos(rq) < blk_rq_pos(__rq)) p = &(*p)->rb_left; else if (blk_rq_pos(rq) >= blk_rq_pos(__rq)) // 否则,向右子树继续查找。p = &(*p)->rb_right; }/*** 插入新节点:* - rb_link_node() 用于将新节点插入到红黑树中,但不调整颜色。* - rb_insert_color() 用于调整红黑树的颜色属性,确保其仍然是有效的红黑树。*/rb_link_node(&rq->rb_node, parent, p); rb_insert_color(&rq->rb_node, root);
}
(说明:代码注释由chartGPT自动生成;函数里面的blk_rq_pos是获取扇区地址,本质就是按扇区地址对request排序,对于机械硬盘,按扇区顺序写对性能比较友好,避免太频繁来回移动磁头;当前场景下只有一个请求,需要调试排队的情况,可以用fio下发多个随机写请求)
函数调用栈如下:
4.2、将request插入到fifo队列末尾(dd_insert_request)
dd_insert_request插入request的代码如下,会给请求加上一个expire time,jiffies可以理解为当前时间,dd->fifo_expire[data_dir]可以理解为超时时间,也就是从request入队列开始之后的多少时间内应该得到调度,前面的Deadline调度器队列是按扇区排序,一味按扇区顺序下发请求,会导致request长时间得不到调度,所以有一个fifo队列,在不超时的情况下,尽可能按扇区顺序调度request请求,后面可以看到具体的请求过程,这里仅介绍:

函数调用栈如下:

5、调度request(dd_dispatch_request)
5.1、下一个request请求(deadline_latter_request)
下一个request请求为在下发一个请求之后,调度器会选择下一个需要调度的请求放到next_rq里面,对于机械硬盘,应该就是下一个最近的扇区的请求,这样可以避免磁头来回跳转,相关函数如下:
static void
deadline_move_request(struct deadline_data *dd, struct request *rq)
{const int data_dir = rq_data_dir(rq);dd->next_rq[READ] = NULL;dd->next_rq[WRITE] = NULL;dd->next_rq[data_dir] = deadline_latter_request(rq);/** take it off the sort and fifo list*/deadline_remove_request(rq->q, rq);
}
每次下发都需要先清除下一个读写请求,再选择当前请求的下一个请求,并将已经调度的请求从相关队列里面删除。
5.2、批量调度request(__dd_dispatch_request)
__dd_dispatch_request有两种调度,一种是批量调度,另一种是fifo调度。批量调度就是,如果之前是调度的是写请求,那么接下来还是继续调度写请求,如果之前调度的是读请求,那么接下来还是继续调度读请求,除非fifo有请求超时或者批量请求超过上限等其他情况;fifo调度就是请求超过了应该调度的时间,这个时候优先处理超时的fifo请求。
__dd_dispatch_request步骤为获取deadline_latter_request选取的下一个请求(只能是读写请求里面的一个或者空,虽然先查询的是WRITE,不表示优先下发写请求,而是如果READ不为空的情况下,WRITE必然为空,先查询哪个都一样,都是由前一个调度的请求决定),代码如下:
/** 批处理当前只允许读或写,不能同时处理*/rq = deadline_next_request(dd, WRITE); // 尝试获取下一个写请求if (!rq) // 如果没有写请求,则尝试获取读请求rq = deadline_next_request(dd, READ);如果批量调度的请求数量少于批量下发的请求数量,继续调度前面选出的下一个请求,这里是继续前面按扇区排序选择的下一个扇区的请求:
// 如果有请求并且尚未达到批处理限制,则继续批处理if (rq && dd->batching < dd->fifo_batch)goto dispatch_request;批量调度次数加1,选择下个需要调度的请求,返回当前调度的请求:
dispatch_request: // 标签:调度请求/** rq 是选定的合适请求*/dd->batching++; // 增加批处理计数器deadline_move_request(dd, rq); // 移动请求到调度队列done: // 标签:处理完成/** 如果请求需要锁定目标区域,则执行锁定操作*/blk_req_zone_write_lock(rq); // 锁定目标区域rq->rq_flags |= RQF_STARTED; // 设置请求已启动标志return rq; // 返回选定的请求批量调度超过上限的情况或者没有下一个请求等情况(磁盘没发送过请求,当前为第一个请求),如果读fifo队列不为空,检查写是否被饿死(写操作前面有多个fifo读操作),如果没有被饿死则调度读操作,否则调度写操作:
// 如果有读请求且写请求未被饿死,则选择读请求if (reads) {BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ])); // 确保读排序列表不为空// 如果写请求未被饿死且已经连续等待超过阈值,则跳转到写请求处理if (deadline_fifo_request(dd, WRITE) &&(dd->starved++ >= dd->writes_starved))goto dispatch_writes;data_dir = READ; // 设置数据方向为读goto dispatch_find_request; // 跳转到查找请求的标签}5.3、查找下一个request请求(dispatch_find_request)
批量调度的情况,下发一个请求的时候已经根据磁盘扇区选择好了下一个需要调度的请求,不需要查找,非批量调度的情况下需要选择下一个要调度的请求,前面代码会根据条件选择好是调度读还是调度写,然后从相应队列获取下一个请求。
选择下一个请求,deadline_next_request获取下一个请求(不考虑zone等情况,这里主要是上一次下发请求是选择的下一个请求,按扇区排序的请求),deadline_check_fifo检查fifo最前面的请求是否超时,如果有超时应该从fifo里面调度超时请求,如果没有超时并且deadline_next_request也没有获取到下一个请求,那么也按fifo调度:
/** 不在批处理模式下,找到选定数据方向的最佳请求*/next_rq = deadline_next_request(dd, data_dir); // 获取下一个请求if (deadline_check_fifo(dd, data_dir) || !next_rq) { // 检查是否有超时请求或无更多请求/** 如果有超时请求、上次请求方向不同或已无更高扇区的请求,* 则重新从最早到期时间的请求开始。*/rq = deadline_fifo_request(dd, data_dir); // 获取最早的到期请求} else {没有请求超时,并且按扇区顺序已经选择好了请求的话,调度下一个选择好的请求:
} else {/** 上次请求方向相同且有下一个请求,则继续从这里开始。*/rq = next_rq; // 设置当前请求为下一个请求}从整个代码看Deadline调度,不保证优先处理超时请求,优先批处理,批处理方向一致,性能较好,批量处理一定程度之后才考虑fifo超时,总体就是尽量保证磁头向一个方向转,避免来回转。至于什么时候触发调度,这里暂时忽略。
__dd_dispatch_request函数调用栈:
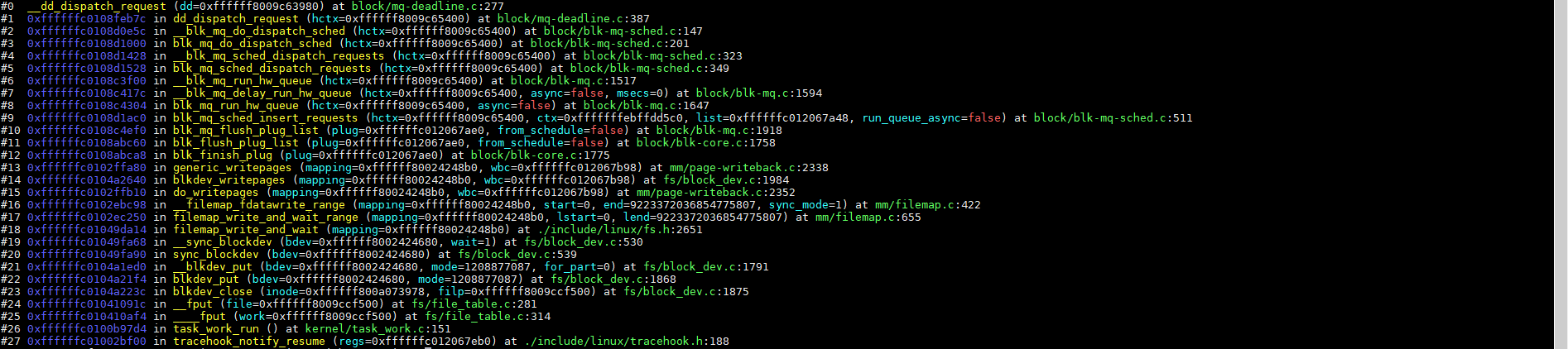
5.4、分发request(__blk_mq_do_dispatch_sched)
前面的代码选择一个个request,这些request先保存到一个请求链表里面,直到没有请求或者超过最大请求数量:
__blk_mq_do_dispatch_sched从调度队列获取reqest请求代码如下:

将调度的request添加到队列:

至此,系统调用的数据从写缓存到入调度队列再到调度出调度队列已经完成了。request调度之后接下来发送到更下一层。
6、下发request(blk_mq_dispatch_rq_list)
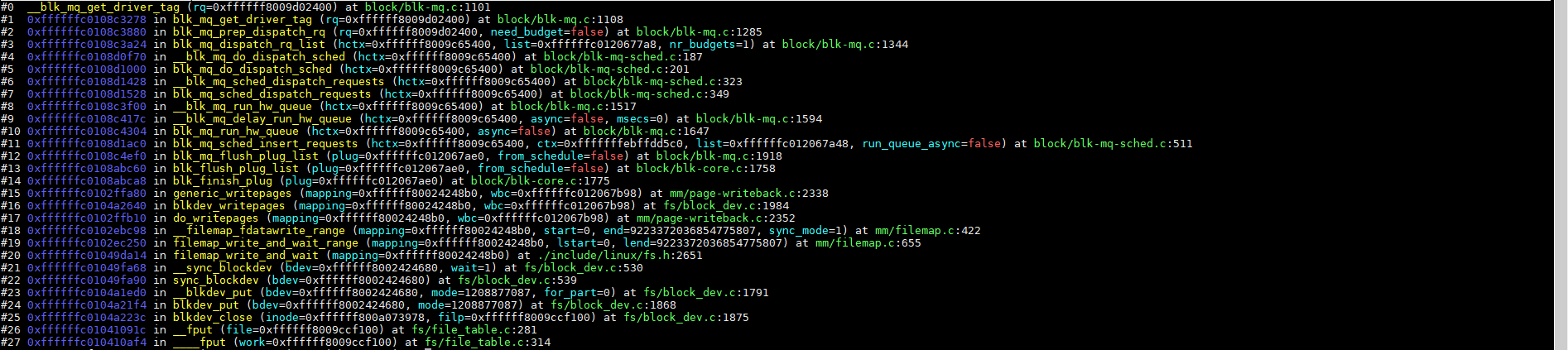
6.1、获取tag(__blk_mq_get_driver_tag)
在前面《linux-5.10.110内核源码分析 - bcm2711 SATA驱动(AHCI)》里面介绍了,AHCI的一定意义上对应一个slot,也就是一个命令通道,下发request需要给request获取一个slot,这个是硬件相关的,与前面的tag不同,前面的tag可以理解为队列里的一个标签。
__blk_mq_get_driver_tag获取tag的代码如下:

函数调用栈:
6.2、request转scsi_cmnd(scsi_prepare_cmd)
将request转换成scsi_cmnd:
6.3、下发scsi命令(scsi_dispatch_cmd)
调度队列的请求request保存到了scsi_cmnd,然后调用scsi_dispatch_cmd下发scsi命令,主要就是根据scsi协议,填充各种字段信息,然后scsi再转换成ahci相关命令,最终下发到ahci控制。
调用栈如下:

相关文章:
linux-5.10.110内核源码分析 - 写磁盘(从VFS系统调用到I/O调度及AHCI写磁盘)
1、VFS写文件到page缓存(vfs_write) 1.1、写裸盘(dd) 使用如下命令写裸盘: dd if/dev/zero of/dev/sda bs4096 count1 seek1 1.2、系统调用(vfs_write) 系统调用栈如下: 对于调用栈的new_sync_write函数,buf为写磁盘的内容的内存地址&…...

arinc818 fpga单色图像传输ip
arinc818协议支持的常用线速率如下图 随着图像分辨率的提高,单lane的速率无法满足特定需求,一种方式是通过多个LANE交叉的去传输图像,另外一种是通过降低图像的带宽,即通过只传单色图像达到对应的效果 程序架构如下图所示&#x…...

业务流程先导及流程图回顾
一、测试流程回顾  1. 备测内容回顾  备测内容: 本次测试涵盖买家和卖家的多个业务流程,包括下单流程、发货流程、搜索退货退款、支付抢购、换货流程、个人中心优惠券等。 2. 先测业务强调  1)测试业务流程 …...

HCIP(RSTP+MSTP)
一、STP的重新收敛: 复习STP接口状态 STP初次收敛至少需要50秒的时间。STP的重新收敛情况: 检测到拓扑变化:当网络中的链路故障或新链路加入时,交换机会检测到拓扑变化。 选举新的根桥:如果原来的根桥故障或与根桥直…...

《无线江湖五绝:BLE/WiFi/ZigBee的频谱大战》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 文章目录 **第一回武林大会,群雄并起****第二回WiFi的“降龙十八掌”****第三回BLE的“峨眉轻功”****第四回ZigBee的“暗器百解”****第五回LoRa的“千里传音”****第六回NB…...

QT第六课------QT界面优化------QSS
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

本地化智能运维助手:基于 LangChain 数据增强 和 DeepSeek-R1 的K8s运维文档检索与问答系统 Demo
写在前面 博文内容为基于 LangChain 数据增强 和 Ollams 本地部署 DeepSeek-R1实现 K8s运维文档检索与问答系统 Demo通过 Demo 对 LEDVR 工作流, 语义检索有基本认知理解不足小伙伴帮忙指正 😃,生活加油 我看远山,远山悲悯 持续分享技术干货…...

C++ STL常用算法之常用算术生成算法
常用算术生成算法 学习目标: 掌握常用的算术生成算法 注意: 算术生成算法属于小型算法,使用时包含的头文件为 #include <numeric> 算法简介: accumulate // 计算容器元素累计总和 fill // 向容器中添加元素 accumulate 功能描述: 计算区间内容器元素…...

Tof 深度相机原理
深度相机(TOF)的工作原理_tof相机原理-CSDN博客 深度剖析 ToF 技术:原理、优劣、数据纠错与工业应用全解析_tof技术-CSDN博客 飞行时间技术TOF_tof计算公式-CSDN博客 深度相机(二)——飞行时间(TOF)_飞行时间技术-C…...

【Linux篇】进程入门指南:操作系统中的第一步
步入进程世界:初学者必懂的操作系统概念 一. 冯诺依曼体系结构1.1 背景与历史1.2 组成部分1.3 意义 二. 进程2.1 进程概念2.1.1 PCB(进程控制块) 2.2 查看进程2.2.1 使用系统文件查看2.2.2 使⽤top和ps这些⽤⼾级⼯具来获取2.2.3 通过系统调用…...

JavaScript 中的原型链与继承
JavaScript 是一种基于原型的编程语言,这意味着它的对象继承是通过原型链而非类的机制来实现的。原型链是 JavaScript 中对象与对象之间继承属性和方法的基础。本文将深入探讨 JavaScript 中的原型链和继承机制,帮助你理解这一重要概念。 一、原型&…...
:ITU、3GPP及传统波段对无线频谱的划分)
无线通信技术(二):ITU、3GPP及传统波段对无线频谱的划分
目录 一.ITU波段划分 二.3GPP频带划分(仅介绍5G NR) 2.1 频带分类 2.2 频带划分表 2.2.1 FR1 2.2.2 FR2 2.3 全球部署趋势 三.传统波段划分 3.1 射频工程中的微波 3.2 军用雷达波段命名 本文介绍国际标准组织ITU、3GPP和传统波段对无线频谱的划…...

Android 系统ContentProvider流程
一、ContentProvider初始化注册流程 源码查看路径:http://xrefandroid.com/android-11.0.0_r48/ 涉及到源码文件: /frameworks/base/core/java/android/content/ContentProvider.java 自定义ContentProvider需要继承该类,内部类Transport继承关系如下,实…...

SpringBean模块(一)定义如何创建生命周期
一、介绍 1、简介 在 Spring 框架中,Bean 是指由 Spring 容器 管理的 Java 对象。Spring 负责创建、配置和管理这些对象,并在应用程序运行时对它们进行依赖注入(Dependency Injection,DI)。 通俗地讲,Sp…...
StorangeClass)
k8s存储介绍(六)StorangeClass
一、Kubernetes 存储类(StorageClass)详解 1. 什么是 StorageClass? 在 Kubernetes 中,StorageClass(存储类)是一种用于动态创建 PersistentVolume(PV)的资源对象。它允许管理员根…...

Redis-04.Redis常用命令-字符串常用命令
一.字符串操作命令 set name jack 点击左侧name,显示出值。 get name get abc:null setex key seconds value:设置过期时间,过期后该键值对将会被删除。 然后再get,在过期时间内可以get到,过期get不到。…...

golang接口-interface
interface接口 概述 接口(interface)是 Go 语言中的一种类型,用于定义行为的集合,它通过描述类型必须实现的方法,规定了类型的行为契约。 它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这…...
Epub转PDF软件Calibre电子书管理软件
Epub转PDF软件:Calibre电子书管理软件 https://download.csdn.net/download/hu5566798/90549599 一款好用的电子书管理软件,可快速导入电脑里的电子书并进行管理,支持多种格式,阅读起来非常方便。同时也有电子书格式转换功能。 …...

【自学笔记】PHP语言基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1. PHP 简介2. PHP 环境搭建3. 基本语法变量与常量数据类型运算符 4. 控制结构条件语句循环语句 5. 函数函数定义与调用作用域 6. 数组7. 字符串8. 表单处理9. 会话…...

FAST-LIVO2 Fast, Direct LiDAR-Inertial-Visual Odometry论文阅读
FAST-LIVO2 Fast, Direct LiDAR-Inertial-Visual Odometry论文阅读 论文下载论文翻译FAST-LIVO2: 快速、直接的LiDAR-惯性-视觉里程计摘要I 引言II 相关工作_直接方法__LiDAR-视觉(-惯性)SLAM_ III 系统概述IV 具有顺序状态更新的误差状态迭代卡尔曼滤波…...

【Git】--- Git远程操作 标签管理
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: Git 前面我们学习的操作都是在本地仓库进行了,如果团队内多人协作都在本地仓库操作是不行的,此时需要新的解决方案 --- 远程仓库。…...
)
Docker学习之服务编排(day9)
文章目录 前言一、问题描述二、解决方案1.安装Docker Compose1.1 [github下载相应版本](https://github.com/docker/compose/releases)1.2 将下载的文件移动到 /usr/local/bin 目录,确保它能够被系统识别为可执行文件1.3 赋予执行权限1.4 验证安装1.5 创建软链 2. 使…...

前后端常见模型以及相关环境配置介绍
一、前端常见框架 Vue.js 特点:采用数据驱动的响应式编程,组件化的开发模式使得代码结构清晰,易于维护,且学习成本相对较低,适合初学者和快速迭代的项目。应用场景:广泛应用于各类 Web 应用开发ÿ…...

职能型组织、项目型组织、矩阵型组织的介绍及优缺点比较
PMP考试中,经常会涉及到职能型组织、项目型组织、矩阵型组织的比较,下面简单介绍下职能型组织、项目型组织、矩阵型组织及其优缺点: 一、职能型组织 定义:以专业职能划分部门(如财务、技术、市场等)&…...

Java基本类型深度解析:从内存模型到高效编程实践
Java基本类型深度解析:从内存模型到高效编程实践 一、Java基本类型概述 Java作为强类型语言,定义了8种基本数据类型(Primitive Types),这些类型直接存储数据值而非对象引用,是构建Java程序的基础。它们的…...

论文阅读笔记——ST-4DGS,WideRange4D
ST-4DGS ST-4DGS 论文 在 4DGS 中,变形场 F \mathcal{F} F 与运动参数 X 和形状参数 ( S , R ) (S,R) (S,R) 高度耦合,导致训练时高斯表示紧凑型退化,影响动态渲染质量。由此,本文提出两种方法解耦运动与形状参数,保…...

[python]基于yolov8实现热力图可视化支持图像视频和摄像头检测
YOLOv8 Grad-CAM 可视化工具 本工具基于YOLOv8模型,结合Grad-CAM技术实现目标检测的可视化分析,支持图像、视频和实时摄像头处理。 功能特性 支持多种Grad-CAM方法实时摄像头处理视频文件处理图像文件处理调用简单 环境要求 Python 3.8需要电脑带有…...

五.ubuntu20.04 - ffmpeg推拉流以及Nginx、SRS本地部署
一.本地部署nginx 1.编译ffmpeg,参考这位博主的,编译选项有的enable找不到的不需要的可以直接删除,但是像sdl(包含ffplay)、h264、h265这些需要提前下载好,里面都有下载指令。 Ubuntu20.04 编译安装 FFmp…...

深度神经网络全解析:原理、结构与方法对比
深度神经网络全解析:原理、结构与方法对比 1. 引言 随着人工智能的发展,深度神经网络(Deep Neural Network,DNN)已经成为图像识别、自然语言处理、语音识别、自动驾驶等领域的核心技术。相比传统机器学习方法&#x…...

豪越科技消防一体化平台:打通消防管理“任督二脉”
在城市的车水马龙间,火灾隐患如潜藏的暗礁,威胁着人们的生命财产安全。传统消防管理模式在现代社会的复杂环境下,逐渐显露出诸多弊端。内部管理分散混乱,人员、装备、物资管理缺乏统一标准和高效流程;外部监管困难重重…...