虫洞数观系列二 | Python+MySQL高效封装:为pandas数据分析铺路
目录
系列文章
1. 引言
2. 常规写法mysql
3. 封装设计接口mysql
3.1dbname.py文件
3.1.1. 导入和基类定义
3.1.2. 具体表定义类
3.1.3. 表定义整合函数
3.1.4. 全局字典和测试代码
3.2mysql_dao文件
3.2.1. 模块导入与配置
3.2.2. 数据库连接池初始化
3.2.3. CommonSQL 类功能
3.3db文件使用
4总结
系列文章
虫洞数观系列总览 | 技术全景:豆瓣电影TOP250数据采集→分析→可视化完整指南
虫洞数观系列一 | 豆瓣电影TOP250数据采集与MySQL存储实战
虫洞数观系列三 | 数据分析全链路实践:Pandas清洗统计 + Navicat可视化呈现
1. 引言
在上一篇文章中,我们完成了豆瓣TOP250电影数据的爬取,存储字段包括:
-
基础信息(中英文片名、详情页链接)
-
制作信息(导演、主演、年份、国家、类型)
-
评分数据(分数、评分人数、经典评语)
这些数据已存入MySQL数据库douban的top250movie表中。
本文核心目标:
-
用Python封装MySQL的CRUD(增删改查)操作类
-
建立高效的数据存取管道
-
为后续的Pandas透视分析(如:
-
按年份/国家的评分分布
-
类型与评分的关联性
-
导演/演员的作品统计等)奠定基础
-
通过标准化数据库操作接口,后续数据分析时只需关注业务逻辑,无需重复编写SQL语句。
2. 常规写法mysql
可以参考之前的文章
知识周汇 | MySQL增删改查与Python连接
对以下的数据表格实现增删改查,

# coding=utf-8import mysql.connector.pooling
import pandas as pd# 本地数据库
__config = {"host": "localhost","port": 3306,"user": "root","password": "faw-vw.1901","database": "douban"
}try:pool = mysql.connector.pooling.MySQLConnectionPool(**__config,pool_size=10)
except Exception as e:print(e)class DoubanDao():# 增def add_infro_from_douban(self):sql = "REPLACE INTO top250movie (feature) VALUES (2);"print(sql)try:con = pool.get_connection()cursor = con.cursor()cursor.execute(sql)con.commit()except Exception as e:if "con" in dir():con.rollback()finally:if "con" in dir():con.close()# 删def del_infro_from_douban(self):sql = "DELETE FROM top250movie WHERE feature ='TOP0001';"print(sql)try:con = pool.get_connection()cursor = con.cursor()cursor.execute(sql)con.commit()except Exception as e:if "con" in dir():con.rollback()finally:if "con" in dir():con.close()# 改def update_infro_from_douban(self):sql = "UPDATE top250movie SET movie_ch = '" + str("你好") + "' WHERE feature = '" + "TOP0002" + "';"# print(sql)try:con = pool.get_connection()cursor = con.cursor()cursor.execute(sql)print(sql)con.commit()except Exception as e:print(e)if "con" in dir():con.rollback()finally:if "con" in dir():con.close()# 查def select_infro_from_douban(self):sql = "SELECT update_date ,movie_ch,movie_en,movie_url FROM top250movie;"print(sql)try:con = pool.get_connection()cursor = con.cursor()cursor.execute(sql)result = cursor.fetchall()return resultexcept Exception as e:if "con" in dir():con.rollback()finally:if "con" in dir():con.close()这种实现方式存在代码冗余问题,当数据库表数量增加时,需要为每个表单独编写定制化逻辑,显著增加了开发维护成本。
3. 封装接口设计mysql
这边设计3个py文件,dbname.py - 表定义模块,mysql_dao.py - 数据访问对象(DAO),main.py - 主程序。

架构设计图
+-------------------+ +-------------------+ +-------------------+
| dbname.py | | mysql_dao.py | | main.py |
| 表结构定义模块 |<--->| 数据访问层 |<--->| 业务逻辑层 |
+-------------------+ +-------------------+ +-------------------+|v+-------------------+| MySQL 数据库 |+-------------------+3.1dbname.py文件
该文件主要是想表达数据表的列名和中文名字对应关系
from typing import Dictclass TableDefinition:"""表定义基类"""@staticmethoddef _create_table_dict(table_name: str, columns: Dict[str, str]) -> Dict[str, Dict[str, str]]:"""创建表字典结构"""return {table_name: columns}class DouBan(TableDefinition):"""分析表定义"""@staticmethoddef top250movie() -> Dict[str, Dict[str, str]]:"""top250电影"""columns = {'update_date': '更新日期','feature': '特征值','movie_ch': '电影中文名','movie_en': '电影英文名','movie_url': '电影详情页链接','director': '导演','star': '主演','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语',}return DouBan._create_table_dict('top250movie', columns)# 其他表定义类...def get_dbname_dict() -> Dict[str, Dict[str, str]]:"""获取所有表定义的字典"""db_dict = {}# 合并所有表定义db_dict.update(DouBan.top250movie())# 添加其他表...return db_dict# 全局表定义字典
dbname_dic = get_dbname_dict()
for dbname in dbname_dic:print('>>>>>>>>>>>>>>>>>')print(dbname)print(dbname_dic[dbname])
打印的结果:

3.1.1. 导入和基类定义
from typing import Dictclass TableDefinition:"""表定义基类"""@staticmethoddef _create_table_dict(table_name: str, columns: Dict[str, str]) -> Dict[str, Dict[str, str]]:"""创建表字典结构"""return {table_name: columns}-
从
typing模块导入Dict,用于类型注解。 -
定义了一个基类
TableDefinition,包含一个静态方法_create_table_dict,用于创建表结构的字典表示。该方法接收表名和列定义字典,返回一个嵌套字典,外层键是表名,内层是列名到列描述的映射。
3.1.2. 具体表定义类
class DouBan(TableDefinition):"""分析表定义"""@staticmethoddef top250movie() -> Dict[str, Dict[str, str]]:"""top250电影"""columns = {'update_date': '更新日期','feature': '特征值','movie_ch': '电影中文名','movie_en': '电影英文名','movie_url': '电影详情页链接','director': '导演','star': '主演','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语',}return DouBan._create_table_dict('top250movie', columns)-
DouBan继承自TableDefinition,表示豆瓣相关的表定义。 -
定义了一个静态方法
top250movie,返回豆瓣Top250电影的表结构:-
包含13个字段,如更新日期、电影中英文名、导演、评分等。
-
每个字段都有英文名和中文描述。
-
使用基类的
_create_table_dict方法生成最终的字典结构。
-
3.1.3. 表定义整合函数
def get_dbname_dict() -> Dict[str, Dict[str, str]]:"""获取所有表定义的字典"""db_dict = {}# 合并所有表定义db_dict.update(DouBan.top250movie())# 添加其他表...return db_dict-
该函数整合所有表定义,返回一个统一的字典。
-
目前只添加了
DouBan.top250movie(),但注释表明可以添加其他表定义。
3.1.4. 全局字典和测试代码
# 全局表定义字典
dbname_dic = get_dbname_dict()
for dbname in dbname_dic:print('>>>>>>>>>>>>>>>>>')print(dbname)print(dbname_dic[dbname])-
生成全局表定义字典
dbname_dic。 -
遍历并打印每个表名及其列定义,用于测试和验证。
3.2mysql_dao文件
# coding=utf-8
import pandas as pd
from tqdm import tqdm
import mysql.connector.pooling
from db.dbname import dbname_dic# Database configuration
__config = {"host": "localhost","port": 3306,"user": "root","password": "faw-vw.1901","database": "douban"
}# Initialize connection pool
try:pool = mysql.connector.pooling.MySQLConnectionPool(**__config,pool_size=10)
except Exception as e:print(f"Error initializing connection pool: {e}")class CommonSQL:def __init__(self):self.pool = pooldef execute_sql_no_return(self, sql):"""Execute SQL without return value."""try:con = self.pool.get_connection()cursor = con.cursor()cursor.execute(sql)con.commit()self._print_success(sql)except Exception as e:if "con" in locals():con.rollback()self._print_failure(sql)print(f"Error: {e}")finally:if "con" in locals():con.close()def executemany_sql_no_return(self, sql, value_list):"""Execute many SQL statements without return value."""try:con = self.pool.get_connection()cursor = con.cursor()cursor.executemany(sql, value_list)con.commit()self._print_success(sql)except Exception as e:if "con" in locals():con.rollback()self._print_failure(sql)print(f"Error: {e}")finally:if "con" in locals():con.close()def execute_sql_return_value(self, dbname):"""Execute SQL and return values as a DataFrame."""try:con = self.pool.get_connection()cursor = con.cursor()sql = f"SELECT * FROM {dbname};"cursor.execute(sql)rows = cursor.fetchall()columns = [desc[0] for desc in cursor.description]df = pd.DataFrame(rows, columns=columns)print(df)# 将df的英文列名更换为中文列名print(dbname)print(dbname_dic)print(dbname_dic[dbname])if dbname in dbname_dic:dbname_columns_dic = dbname_dic[dbname]print(dbname_columns_dic)for each_column in list(df.columns):if each_column in dbname_columns_dic:df.rename(columns={each_column: dbname_columns_dic[each_column]}, inplace=True)return dfexcept Exception as e:if "con" in locals():con.rollback()print(f"Error: {e}")finally:if "con" in locals():con.close()def bulk_update_infor_in_db(self, df, PRIMARY_KEY, update_cols, dbname):"""Bulk update database with DataFrame."""sql = self._create_update_sql(dbname, update_cols, PRIMARY_KEY)self._bulk_operation(df, sql, update_cols, PRIMARY_KEY, dbname, "update")def bulk_insert_infor_in_db(self, df, insert_cols, dbname):"""Bulk insert into database with DataFrame."""sql = self._create_insert_sql(dbname, insert_cols)self._bulk_operation(df, sql, insert_cols, None, dbname, "insert")def bulk_replace_infor_in_db(self, df, insert_cols, dbname):"""Bulk replace into database with DataFrame."""sql = self._create_replace_sql(dbname, insert_cols)self._bulk_operation(df, sql, insert_cols, None, dbname, "replace")def clear_db_table(self, dbname):"""Clear database table."""sql = f"TRUNCATE TABLE {dbname}"self.execute_sql_no_return(sql)def _create_update_sql(self, dbname, update_cols, PRIMARY_KEY):set_parts = ", ".join([f"{col} = %s" for col in update_cols])sql = f"UPDATE {dbname} SET {set_parts} WHERE {PRIMARY_KEY[0]} = %s;"return sqldef _create_insert_sql(self, dbname, insert_cols):columns = ", ".join(insert_cols)placeholders = ", ".join(["%s"] * len(insert_cols))sql = f"INSERT INTO {dbname} ({columns}) VALUES ({placeholders});"return sqldef _create_replace_sql(self, dbname, insert_cols):columns = ", ".join(insert_cols)placeholders = ", ".join(["%s"] * len(insert_cols))sql = f"REPLACE INTO {dbname} ({columns}) VALUES ({placeholders});"return sqldef _bulk_operation(self, df, sql, cols, PRIMARY_KEY, dbname, operation):"""Helper method to perform bulk operations."""df_copy = df.copy()i_max0 = df_copy.shape[0]num = i_max0 // 5000for j in range(num + 1):value_list = []start = j * 5000end = min((j + 1) * 5000, i_max0)for i in tqdm(range(start, end), desc=f"Batch {operation}"):row = df_copy.iloc[i]values = [str(row[cols[col]]) for col in cols]if PRIMARY_KEY:values.append(str(row[PRIMARY_KEY[1]]))value_list.append(tuple(values))self.executemany_sql_no_return(sql, value_list)print(f"Database {dbname} {operation}d {end - start} rows!!!")def _print_success(self, sql):"""Print success message."""operation = "insert" if "INSERT" in sql else "update" if "UPDATE" in sql else "execute"print(f"Successfully {operation} {sql}")def _print_failure(self, sql):"""Print failure message."""operation = "insert" if "INSERT" in sql else "update" if "UPDATE" in sql else "execute"print(f"Failed {operation} {sql}")
3.2.1. 模块导入与配置
# coding=utf-8
import pandas as pd
from tqdm import tqdm
import mysql.connector.pooling
from db.dbname import dbname_dic-
pandas:用于将查询结果转换为 DataFrame。 -
tqdm:显示批量操作的进度条。 -
mysql.connector.pooling:MySQL 连接池,提高数据库连接效率。 -
dbname_dic:从自定义模块导入表名和字段名的映射字典(如{'update_date': '更新日期'})。
3.2.2. 数据库连接池初始化
__config = {"host": "localhost","port": 3306,"user": "root","password": "faw-vw.1901","database": "douban"
}pool = mysql.connector.pooling.MySQLConnectionPool(**__config,pool_size=10
)-
使用连接池管理数据库连接,默认大小为 10,避免频繁创建/销毁连接。
3.2.3. CommonSQL 类功能
初始化方法
def __init__(self):self.pool = pool-
直接使用全局连接池
pool。
基础 SQL 操作方法
execute_sql_no_return
def execute_sql_no_return(self, sql):"""执行无返回值的 SQL(如 INSERT/UPDATE/DELETE)"""try:con = self.pool.get_connection()cursor = con.cursor()cursor.execute(sql)con.commit()self._print_success(sql) # 打印成功日志except Exception as e:con.rollback() # 回滚事务self._print_failure(sql) # 打印失败日志finally:con.close() # 释放连接-
用于执行不需要返回结果的 SQL(如 DML 语句)。
executemany_sql_no_return
def executemany_sql_no_return(self, sql, value_list):"""批量执行无返回值的 SQL"""try:con = self.pool.get_connection()cursor = con.cursor()cursor.executemany(sql, value_list) # 批量执行con.commit()except Exception as e:con.rollback()finally:con.close()-
高效批量插入/更新数据(如
INSERT INTO ... VALUES (%s, %s))。
execute_sql_return_value
def execute_sql_return_value(self, dbname):"""执行查询并返回 DataFrame(自动转换列名为中文)"""sql = f"SELECT * FROM {dbname};"cursor.execute(sql)rows = cursor.fetchall()columns = [desc[0] for desc in cursor.description] # 获取列名df = pd.DataFrame(rows, columns=columns)# 将英文列名替换为中文(通过 dbname_dic 映射)if dbname in dbname_dic:df.rename(columns=dbname_dic[dbname], inplace=True)return df-
查询结果转换为 DataFrame,并自动替换列名为中文(如
movie_ch → 电影中文名)。
批量操作方法
bulk_insert_infor_in_db / bulk_update_infor_in_db / bulk_replace_infor_in_db
def bulk_insert_infor_in_db(self, df, insert_cols, dbname):sql = self._create_insert_sql(dbname, insert_cols) # 生成 INSERT SQLself._bulk_operation(df, sql, insert_cols, None, dbname, "insert")def _create_insert_sql(self, dbname, insert_cols):"""生成 INSERT 语句模板,如: INSERT INTO table (col1, col2) VALUES (%s, %s)"""columns = ", ".join(insert_cols)placeholders = ", ".join(["%s"] * len(insert_cols))return f"INSERT INTO {dbname} ({columns}) VALUES ({placeholders});"-
将 DataFrame 数据分批次(每批 5000 行)插入数据库,通过
tqdm显示进度。
_bulk_operation(核心辅助方法)
def _bulk_operation(self, df, sql, cols, PRIMARY_KEY, dbname, operation):"""批量操作(插入/更新/替换)的通用逻辑"""for j in range(num_batches):value_list = []for i in tqdm(range(start, end), desc=f"Batch {operation}"):row = df.iloc[i]values = [str(row[col]) for col in cols] # 提取数据if PRIMARY_KEY: # 如果是更新操作,追加主键值values.append(str(row[PRIMARY_KEY[1]]))value_list.append(tuple(values))self.executemany_sql_no_return(sql, value_list) # 批量执行-
支持分批次处理大数据量,避免内存溢出。
其他工具方法
-
clear_db_table:清空表(TRUNCATE TABLE)。 -
_print_success/_print_failure:格式化打印操作日志。
3.3db文件使用
以下完整演示了"查询→备份→清空→重新插入→更新"的数据处理流程
# 导入必要的库
import pandas as pd # 用于数据处理和分析
from db.mysql_dao import CommonSQL # 自定义的MySQL数据库操作类def main():"""主函数,执行数据库CRUD操作流程"""# ==================== 数据查询模块 ====================# 从'top250movie'表查询数据并返回DataFramedf = CommonSQL().execute_sql_return_value('top250movie')print(df) # 打印原始数据print(df.columns) # 打印列名df.to_excel('原始数据.xlsx') # 导出到Excel备份# ==================== 数据清理模块 ====================# 清空'top250movie'表中的所有数据CommonSQL().clear_db_table('top250movie')# ==================== 数据插入模块 ====================# 从Excel重新加载数据df = pd.read_excel('原始数据.xlsx')# 定义数据库字段与DataFrame列的映射关系insert_cols = {'update_date': '更新日期', # 数据库字段: DataFrame列名'feature': '特征值','movie_ch': '电影中文名','movie_en': '电影英文名','movie_url': '电影详情页链接','director': '导演','star': '主演','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语',}# 执行批量插入操作(两种方式)CommonSQL().bulk_insert_infor_in_db(df, insert_cols=insert_cols, dbname='top250movie')CommonSQL().bulk_replace_infor_in_db(df, insert_cols=insert_cols, dbname='top250movie')# ==================== 数据更新模块 ====================# 定义主键和需要更新的字段映射PRIMARY_KEY = ['feature', '特征值'] # 主键字段update_cols = {'movie_ch': '电影中文名', # 数据库字段: DataFrame列名'movie_en': '电影英文名','movie_url': '电影详情页链接','director': '导演','star': '主演','start_year': '上映年份','country': '国籍','type': '类型','rating': '评分','num_ratings': '评分人数','comment': '评语',}# 执行批量更新操作CommonSQL().bulk_update_infor_in_db(df, PRIMARY_KEY, update_cols, 'top250movie')# 程序入口
if __name__ == '__main__':main()4总结
作为一名长期从事数据处理与分析的专业人士,我在实际工作中总结出了一套成熟的MySQL-DataFrame交互方案。该方案有效解决了数据分析过程中常见的"数据搬运"效率瓶颈问题,显著提升了工作效能。
✅ 智能双向无缝转换
• 实现DataFrame与数据库表的自动化映射
• 免除繁琐的SQL查询编写及结果解析过程
• 全面适配各类数据分析场景的特殊需求
⚡ 高性能批处理机制
• 采用智能分块处理技术(5000行/批)
• 基于executemany预编译实现高效数据操作
• 显著降低I/O开销,提升数据处理效率
应用价值:
• 节省90%以上的数据转换时间
• 专注于核心数据分析逻辑开发
• 充分利用DataFrame的强大分析功能
让数据真正流动起来,释放分析潜能!
相关文章:
虫洞数观系列二 | Python+MySQL高效封装:为pandas数据分析铺路
目录 系列文章 1. 引言 2. 常规写法mysql 3. 封装设计接口mysql 3.1dbname.py文件 3.1.1. 导入和基类定义 3.1.2. 具体表定义类 3.1.3. 表定义整合函数 3.1.4. 全局字典和测试代码 3.2mysql_dao文件 3.2.1. 模块导入与配置 3.2.2. 数据库连接池初始化 3.2.3. Comm…...

算法刷题-最近公共祖先-LCA
AcWing 1172 祖孙询问 一、题目描述 给定一棵包含 n 个节点的有根无向树,节点编号互不相同,但不一定是 1∼n。 有 m 个询问,每个询问给出了一对节点的编号 x 和 y,询问 x 与 y 的祖孙关系。 输入格式 第一行一个整数 n 表示节…...

MySQl之Binlog
前言 Binlog(Binary Log)是MySQL中至关重要的日志模块,它直接关系到数据恢复、主从复制等高阶架构设计。无论你是刚入门的新手还是有一定经验的开发者,掌握Binlog的原理和应用都是进阶的必经之路。 BinLog是什么? Bin…...

开源项目解读(https://github.com/zjunlp/DeepKE)
1.DeepKE 是一个开源的知识图谱抽取与构建工具,支持cnSchema、低资源、长篇章、多模态的知识抽取工具,可以基于PyTorch实现命名实体识别、关系抽取和属性抽取功能。同时为初学者提供了文档,在线演示, 论文, 演示文稿和海报。 2.下载对应的de…...
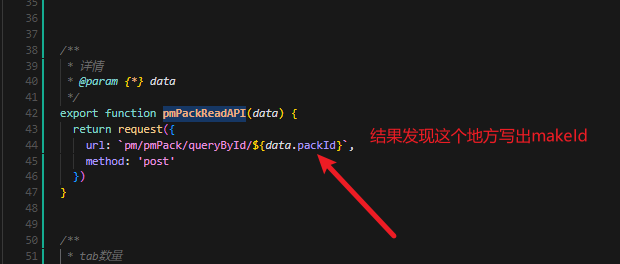
「MethodArgumentTypeMismatchException:前端传递 ‘undefined‘ 导致 Integer 类型转换失败」
遇到的问题: Failed to convert value of type java.lang.String to required type java.lang.Integer; nested exception is java.lang.NumberFormatException: For input string: "undefined" 原因分析: 大致意思就是我传递的参数到后端没…...
LabVIEW故障诊断数据处理方法
在LabVIEW故障诊断系统中,数据处理直接决定诊断的准确性和效率。工业现场常面临噪声干扰、数据量大、实时性要求高等挑战,需针对性地选择处理方法。本文结合电机故障诊断、轴承损伤检测等典型案例,详解数据预处理、特征提取、模式识别三大核心…...

基于 SpringBoot 的火车订票管理系统
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...

Python的概论
免责声明 如有异议请在评论区友好交流,或者私信 内容纯属个人见解,仅供学习参考 如若从事非法行业请勿食用 如有雷同纯属巧合 版权问题请直接联系本人进行删改 前言 提示:: 提示:以下是本篇文章正文内容,…...

构建大语言模型应用:句子转换器(Sentence Transformers)(第三部分)
本系列文章目录 简介数据准备句子转换器(本文)向量数据库搜索与检索大语言模型开源检索增强生成评估大语言模型服务高级检索增强生成 RAG 在之前的博客中,我们学习了为RAG(检索增强生成,Retrieval Augmented Generati…...

怎样提升大语言模型(LLM)回答准确率
怎样提升大语言模型(LLM)回答准确率 目录 怎样提升大语言模型(LLM)回答准确率激励与规范类知识关联类情感与语境类逆向思维类:为什么不,反面案例群体智慧类明确指令类示例引导类思维引导类约束限制类反馈交互类:对话激励与规范类 给予奖励暗示:在提示词中暗示模型如果回…...

【进阶】vscode 中使用 cmake 编译调试 C++ 工程
基于 MSYS2 的 MinGW-w64 GCC 工具链与 CMake 构建系统,结合VSCode及其扩展插件( ms-vscode.cmake-tools),可实现高效的全流程C开发调试。既可通过 VSCode 可视化界面(命令面板、状态栏按钮)便捷完成配置、…...

流影---开源网络流量分析平台(三)(管理引擎部署)
目录 前沿 功能介绍 部署过程 前沿 在上一篇文章中,最后因为虚拟机的资源而没看到最后的效果,而是查看了日志,虽然效果是有了,但后来我等了很久,还是那个转圈的画面,所以我猜测可能是少了什么东西&#…...

QT Quick(C++)跨平台应用程序项目实战教程 5 — 界面设计
目录 1.版面设计 2. 自定义按钮 2.1 自定义工具栏按钮 2.2 自定义图标按钮 3. 顶部工具栏 4. 主体 5. 底部工具栏 6. 主文件 7. 最终效果 上一章内容讲解了QML基本使用方法。本章内容继续延续“音乐播放器”项目主线,完成程序的界面设计任务。 1.版面设计…...
【微服务架构】SpringCloud Alibaba(三):负载均衡 LoadBalance
文章目录 SpringCloud Alibaba1、核心组件2、优势3、应用场景 一、Loadbalance介绍二、Ribbon和Loadbalance 对比三、整合LoadBlance1、升级版本2、移除ribbon依赖,增加loadBalance依赖 四、自定定义负载均衡器五、重试机制六、源码分析1、猜测源码的实现2、初始化过…...

关于音频采样率,比特,时间轴的理解
是的,你的理解完全正确!-ar、-af aresampleasync1000 和 -b:a 64k 分别用于控制音频的采样率、时间戳调整和比特率。它们各自有不同的作用,但共同确保音频的质量和同步性。下面我将详细解释每个参数的作用和它们之间的关系。 1. -ar 参数 作用…...

06-02-自考数据结构(20331)- 查找技术-动态查找知识点
自考数据结构动态查找算法主要讲二叉树和平衡二叉树,但是感觉到了,就又续接了一部分,所以这篇备考的小伙伴着重看前两种就可以了。 知识拓扑 知识点介绍 二叉排序树(BST) 定义 二叉排序树(Binary Search Tree)又称二叉查找树,它或者是一棵空树,或者是具有下列性质的二…...

【Vue2插槽】
Vue2插槽 Vue2插槽默认插槽子组件代码(Child.vue)父组件代码(Parent.vue) 命名插槽子组件代码(ChildNamed.vue)父组件代码(ParentNamed.vue) 代码解释 Vue2插槽 Vue2插槽 下面为你详…...

Upload-labs 靶场搭建 及一句话木马的原理与运用
1、phpstudy及upload-labs下载 (1)下载phpstudy小皮面板 首先需要软件phpstudy 下载地址 phpStudy下载-phpStudy最新版下载V8.1.1.3 -阔思亮 (2)然后到github网址下载源码压缩包 网址 https://github.com/c0ny1/upload-labs 再…...

爬虫的第三天——爬动态网页
一、基本概念 动态网页是指网页内容可以根据用户的操作或者预设条件而实时发生变化的网页。 特点: 用户交互:动态网页能够根据用户的请求而生成不同的内容。内容动态生成:数据来自数据库、API或用户输入。客户端动态渲染:浏览器…...

vue状态管理器pinia、pinia-plugin-persist持久化储存
vue状态管理器pinia、pinia-plugin-persist持久化储存 一、简介二、配置状态管理器,需安装pinia、pinia-plugin-persist三、定义store:defineStore五、pinia中的Getter六、pinia中的Action七、pinia-plugin-persist持久化储存配置 一、简介 Pinia 是一个…...

为什么需要 Node.js 的 URL 处理工具?
关键问题:ES 模块与传统模块的路径差异 1. 传统 CommonJS 模块的做法 在传统的 Node.js 模块(使用 require)中,我们会这样获取当前文件所在目录的路径: javascript 复制 const path require(path); const dirPat…...

力扣HOT100之矩阵:48. 旋转图像
这道题本来想用剥洋葱的办法的,一直写不对,放弃了。。。直接去看题解,用剥洋葱其实也可以做,就是要从外层处理到内层,每一个边界上的元素为matrix[0].size() - 1个,这样一来,四条边界上的元素个…...
uniapp微信小程序获取用户手机号uniCloud云开发版
开发微信小程序,很多时候需要获取用户的手机号,这样方便平台更好的为用户服务,但是微信小程序不允许开发者直接获取用户的手机号,需要用户手动授权才能获取手机号,且需要配合后端进行解密才能获得完整的手机号…...

基于神经网络的文本分类的设计与实现
标题:基于神经网络的文本分类的设计与实现 内容:1.摘要 在信息爆炸的时代,大量文本数据的分类处理变得至关重要。本文旨在设计并实现一种基于神经网络的文本分类系统。通过构建合适的神经网络模型,采用公开的文本数据集进行训练和测试。在实验中&#x…...
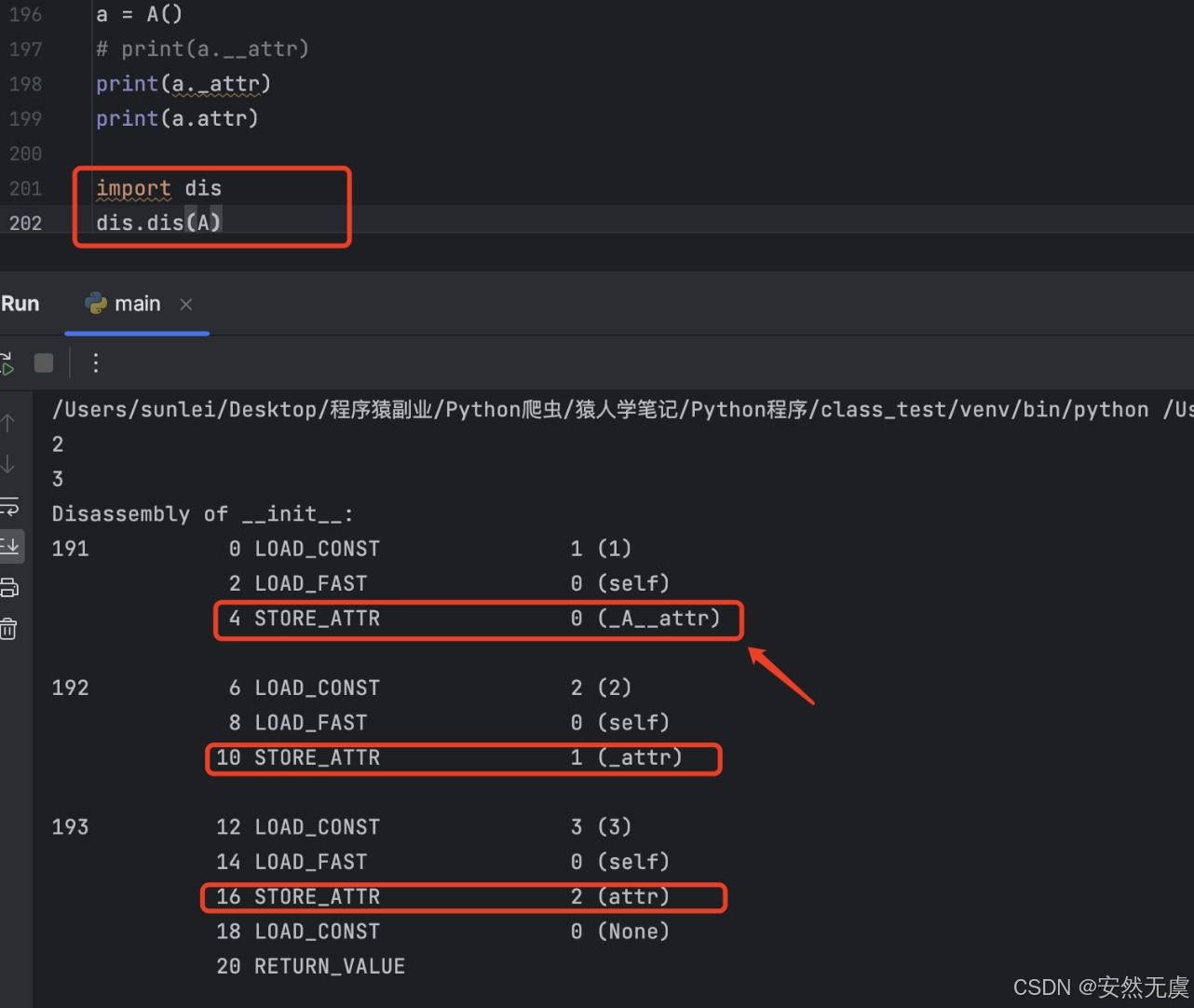
31天Python入门——第18天:面向对象三大特性·封装继承多态
你好,我是安然无虞。 文章目录 面向对象三大特性1. 封装2. 继承3. 多态4. 抽象基类5. 补充练习 面向对象三大特性 面向对象编程(Object-Oriented Programming, 简称OOP)有三大特性, 分别是封装、继承和多态.这些特性是面向对象编程的基础, …...

第十六届蓝桥杯模拟二(串口通信)
由硬件框图可以知道我们要配置LED 和按键 一.LED 先配置LED的八个引脚为GPIO_OutPut,锁存器PD2也是,然后都设置为起始高电平,生成代码时还要去解决引脚冲突问题 二.按键 按键配置,由原理图按键所对引脚要GPIO_Input 生成代码,在文件夹中添加code文件夹,code中添加fun.…...

22--交换安全与端口隔离完全指南:MAC地址的奇幻漂流
🌐 交换安全与端口隔离完全指南:MAC地址的奇幻漂流 🎩 引言:当数据包参加假面舞会 想象一下,网络世界正在举办盛大的假面舞会。每个设备都戴着MAC地址面具入场,交换机就是严格的安检员。本文将带你揭秘&…...

Redis和三大消息队列
一、中间件核心概念解析 1. Redis Redis是一种高性能的内存数据库,支持多种数据结构和持久化机制,常用于缓存、队列等场景。 (1)核心数据结构 数据结构特性与典型应用场景String存储文本、数值(如计数器࿰…...

1.2-WAF\CDN\OSS\反向代理\负载均衡
WAF:就是网站应用防火墙,有硬件类、软件类、云WAF; 还有网站内置的WAF,内置的WAF就是直接嵌在代码中的安全防护代码 硬件类:Imperva、天清WAG 软件:安全狗、D盾、云锁 云:阿里云盾、腾讯云WA…...

UE5学习笔记 FPS游戏制作32 主菜单,暂停游戏,显示鼠标指针
文章目录 一主菜单搭建UI显示主菜单时,暂停游戏,显示鼠标绑定按钮 二 打开主菜单 一主菜单 搭建UI 添加一个MainUi的控件 添加一个返回游戏的按钮和一个退出游戏的按钮 修改一下样式,放中间 显示主菜单时,暂停游戏࿰…...