【NLP】16. NLP推理方法重点回顾 -- 52道多选题
- Which of the following problems are commonly solved using sequence tagging?
A) Named Entity Recognition (NER)
B) Part-of-Speech (POS) Tagging
C) Word Embedding Training
D) Syntactic Dependency Parsing
序列标注是一种 NLP 任务,常用于 命名实体识别(NER) 和 词性标注(POS Tagging),因为这些任务涉及对输入序列中的每个词进行分类。而 词嵌入训练(Word Embedding Training) 是无监督学习,与序列标注无关。句法依存分析(Dependency Parsing) 通常使用图解析方法,而非序列标注。
- In sequence tagging, why is dynamic programming preferred over a greedy approach?
A) DP ensures global optimization rather than local optimization
B) DP has lower time complexity than greedy methods in all cases
C) Greedy methods may not produce the optimal tag sequence
D) DP can efficiently compute probabilities for all possible sequences
动态规划(DP)可确保找到全局最优解(A),而贪心算法仅基于局部最优选择,可能导致次优解(C)。此外,DP 可以存储计算的概率值,减少冗余计算(D)。但 DP 并不总是比贪心方法的时间复杂度低(B 是错误的)。
- Which of the following are the main steps of dynamic programming in sequence tagging?
A) Compute emission probabilities
B) Compute transition probabilities
C) Use a recursive approach to find optimal labels
D) Always process words independently
在动态规划中,发射概率(emission probabilities)(A)用于表示词对标签的概率,转移概率(transition probabilities)(B)表示前后标签的转换概率。DP 采用递归(C)来求解最优路径,而不会将单词独立处理(D 是错误的)。
- What are the potential drawbacks of brute force approaches in NLP tasks?
A) Exponential time complexity in many cases
B) Always produces optimal solutions
C) Not scalable for real-world applications
D) Can be outperformed by heuristic-based search
穷举搜索(Brute Force)可能导致指数级时间复杂度(A),因此在现实应用中不可扩展(C)。此外,它的计算成本较高,启发式搜索可能在计算资源受限时表现更好(D)。但它确实能找到最优解(B 可能正确,但代价过高)。
- Which algorithm is commonly used in dependency parsing with a dynamic programming approach?
A) CKY algorithm
B) Viterbi algorithm
C) Kruskal’s algorithm
D) Prim’s algorithm
CKY 算法(A) 是一种基于 DP 的句法解析方法,广泛用于 上下文无关文法(CFG) 的解析。而 Viterbi 算法(B) 主要用于 隐马尔可夫模型(HMM) 进行序列预测。Kruskal(C)和 Prim(D) 用于 最小生成树(MST),不是动态规划的依存解析算法。
- In which of the following tasks is the Beam Search algorithm commonly used?
A) Machine Translation
B) Image Recognition
C) Image Segmentation
D) Object Detection
Beam Search算法常用于机器翻译任务中,作为一种搜索策略,用来探索最可能的词序列。它通过在每一步保持一组最优候选来平衡探索和利用。在图像相关任务(如物体检测和分割)中,通常不会使用Beam Search。
- Which of the following is an advantage of Exhaustive Search?
A) It guarantees a globally optimal output
B) It scales well with longer sentences
C) It considers the entire structure
D) It is computationally efficient
Answer: A, C
中文解释:
优势在于穷举搜索能考虑所有可能的结构,从而保证找到全局最优解(A)和保证输出的结构完整性(C),但它计算量巨大,不适合长句,且计算效率低(B和D错误)。
- Which statement best describes the main drawback of Exhaustive Search in NLP?
A) It is not flexible
B) Its search space grows exponentially with sentence length
C) It always finds the optimal solution
D) It is easy to implement
Answer: B
中文解释:
主要问题是穷举搜索的搜索空间随着单词数指数级增长(B),这使得它不可扩展。其他选项要么不正确,要么是优点。
- What is the time complexity of Exhaustive Search in a sequence tagging task?
A) O(|words|)
B) O(|tags| × |words|)
C) O(|tags|^|words|)
D) O(|words|²)
穷举搜索的时间复杂度为所有可能组合的数量,即每个单词有 |tags| 种选择,总体复杂度为 O(|tags|^|words|)。
- In the Greedy method, how is the output generated?
A) By selecting the highest scoring option for each word sequentially
B) By considering all possible combinations simultaneously
C) By randomly selecting words from the probability distribution
D) By using dynamic programming to store intermediate results
贪心方法是逐步选择每一步中概率最高的选项(A),而不是同时考虑所有组合或进行随机采样或使用动态规划。
- Which of the following is a disadvantage of the Greedy Method?
A) Low computational cost
B) It may miss the globally optimal solution
C) It uses only local context
D) It always produces diverse outputs
贪心方法由于只选择局部最优选项,可能导致错失全局最优解(B),并且它只依赖局部信息(C)。低计算量是优点,而“总是产生多样性”是错误的。
- What does the Top-1 variant of the Greedy method do?
A) Chooses the highest probability word at each step
B) Randomly chooses a word from the full distribution
C) Considers a fixed list of top options and samples from it
D) Adjusts scores based on previous outputs
Top-1 方法在每一步选择概率最高的词(A),即使用 argmax 策略,不涉及随机采样或调整分数。
- Which variant of greedy inference increases output diversity by sampling from a probability distribution?
A) Top-1
B) Random Sampling
C) Top-K Sampling
D) Contrastive Sampling
随机采样(Random Sampling)在每一步按照概率分布随机选取词,从而增加输出多样性。
- In Top-K sampling, what is the main idea?
A) Always select the highest probability option
B) Randomly sample from the entire vocabulary
C) Filter to the top K options and randomly sample from them
D) Adjust scores based on similarity with previous outputs
Top-K 采样在每一步仅考虑概率最高的 K 个选项,然后从中随机选择(C)。这既保留了多样性,也避免了选择低概率词。
- How does Top-P (Nucleus) Sampling differ from Top-K Sampling?
A) It selects a fixed number of top options
B) It selects options until a cumulative probability threshold is reached
C) It always chooses the highest scoring word
D) It uses a variable number of options based on the probability mass
Top-P 采样(Nucleus Sampling)不是固定数量,而是选取直到累积概率超过设定阈值的所有选项(B和D),从而自适应候选词数量。
- What is the purpose of Contrastive Sampling in text generation?
A) To adjust scores based on recent outputs and reduce repetition
B) To guarantee the highest probability choice
C) To combine benefits of random sampling with deterministic selection
D) To only sample from the top-K list
对比采样通过调整得分来减少重复,使得生成的文本更连贯(A);它结合了随机采样的多样性和确定性选择(C)。
- Which of the following is a primary advantage of the Greedy method compared to Exhaustive Search?
A) Lower computational complexity
B) Global optimality
C) Faster decision making
D) It always finds the best structure
贪心方法计算量低(A)且决策速度快(C),但它无法保证全局最优(B、D错误)。
- Which method has the lowest computational cost in inference?
A) Exhaustive Search
B) Greedy (Top-1)
C) Beam Search
D) Random Sampling
- In Beam Search, what is meant by “Beam Width”?
A) The maximum number of candidate sequences kept at each step
B) The fixed length of the output sequence
C) The total number of words considered in the vocabulary
D) The number of candidates pruned at the final step
“Beam Width”指的是在每一步中保留的候选序列数量(A),即最多追踪多少个可能路径。
- How does Beam Search improve upon the Greedy method?
A) It considers multiple candidate sequences simultaneously
B) It uses dynamic programming to store all intermediate results
C) It guarantees a globally optimal solution
D) It provides a trade-off between quality and computational cost
Beam Search在每一步保留多个候选序列(A),从而可以找到比单一贪心选择更优的结果,同时在计算量和质量上提供平衡(D)。
- What is a common modification applied to Beam Search to prevent bias towards shorter sequences?
A) Increasing Beam Width
B) Length Penalty
C) Random Sampling
D) Contrastive Sampling
长度惩罚(Length Penalty)用于调整序列得分,避免Beam Search因累乘概率而偏向生成较短句子(B)。
- Which of the following is a potential drawback of Beam Search?
A) It might still be locally optimal
B) It can be computationally intensive if Beam Width is too large
C) It always finds the global optimum
D) It may lack diversity in output
Beam Search只保留K个候选,可能错过全局最优(A);当Beam Width较大时计算复杂度会增加(B);如果K太小则输出多样性不足(D)。选项C错误。
- What is the primary goal of Graph Search in text generation?
A) To find the shortest path
B) To estimate a final score and guide generation towards the highest scoring sequence
C) To perform exhaustive search
D) To rely solely on local context
图搜索在文本生成中的目标是估算最终得分,指导生成过程以获得得分最高的文本序列(B),而不是寻找最短路径或仅依赖局部信息。
- How does Graph Search differ from A Search in the context of text generation?
A) Graph Search seeks the highest score rather than the shortest path
B) A Search uses a heuristic for path length estimation*
C) Graph Search combines probability and additional factors like fluency
D) They are essentially the same in every aspect
在文本生成中,图搜索目标是最大化得分(A),而A*搜索通常用于最短路径且依赖启发式函数估计距离(B)。此外,图搜索还考虑语言流畅性、语法正确性等因素(C)。选项D不正确。
- In Graph Search for text generation, what role does “heuristic score estimation” play?
A) It predicts the future score of the remaining sequence
B) It helps in pruning low-scoring branches
C) It guarantees an optimal solution
D) It adjusts the current word probability
启发式得分估计用于预测后续生成序列可能获得的分数(A),从而帮助剪枝低分支(B)。它并不保证最优(C),也不直接调整当前词概率(D)。
-
Which of the following sampling methods can dynamically adjust the candidate list size based on cumulative probability?
A) Top-1 Sampling
B) Top-K Sampling
C) Top-P (Nucleus) Sampling
D) Random Sampling -
Which method is most likely to produce repetitive outputs in long text generation if not adjusted?
A) Greedy (Top-1)
B) Random Sampling
C) Contrastive Sampling
D) Beam Search -
What is the main benefit of using Random Sampling in inference?
A) It always chooses the best candidate
B) It increases output diversity
C) It is computationally more intensive than exhaustive search
D) It ensures deterministic outputs
随机采样通过按概率随机选择,增加了生成文本的多样性(B)。但它不总是选择最佳候选,也不保证确定性(A和D错误),且计算量比贪心低(C错误)。 -
Which of the following best summarizes the trade-off between Greedy Search and Beam Search?
A) Greedy is faster but may miss better sequences
B) Beam Search is slower but explores multiple paths
C) Beam Search always finds the global optimum
D) Greedy Search uses exhaustive computation
贪心搜索速度快但可能错过全局最优(A);Beam Search虽然计算量较高,但能同时探索多个候选路径(B)。选项C和D均不正确。
- What is one reason to combine Beam Search with methods like Top-K or Top-P Sampling?
A) To reduce computational cost
B) To enhance output diversity while maintaining quality
C) To completely eliminate randomness
D) To guarantee global optimality
将Beam Search与Top-K或Top-P采样结合,可在保留候选序列的同时增加多样性,提升生成文本的整体质量(B)。其他选项不符合实际情况。
- Which of the following correctly lists the order of computational complexity from lowest to highest for the methods discussed?
A) Greedy (Top-1) → Random Sampling → Beam Search → Exhaustive Search
B) Exhaustive Search → Beam Search → Greedy (Top-1) → Random Sampling
C) Greedy (Top-1) → Beam Search → Exhaustive Search
D) Beam Search → Exhaustive Search → Random Sampling → Greedy (Top-1)
贪心(Top-1)的计算复杂度最低,其次随机采样,Beam Search在中等水平,穷举搜索的复杂度最高(A)。
- Which method explicitly requires rescaling of probabilities among selected candidates?
A) Top-1
B) Top-K Sampling
C) Random Sampling
D) Contrastive Sampling
在Top-K采样中,需要对选中的K个候选词的概率重新归一化(B);在对比采样中,调整得分时也可能涉及对概率进行重新缩放(D)。
- In the context of text generation, what does “coverage penalty” aim to address?
A) Bias toward shorter sequences
B) Missing key information such as subject or object
C) Overly repetitive outputs
D) Low computational complexity
覆盖惩罚旨在鼓励模型翻译或生成时覆盖输入中的所有关键信息,避免遗漏主语、宾语等(B),而不是处理序列长度、重复或计算复杂度问题。
- Which sampling method is best suited when you want a fixed-length candidate list regardless of the distribution shape?
A) Top-1
B) Random Sampling
C) Top-K Sampling
D) Top-P Sampling
Top-K采样固定保留K个候选词,不受概率分布形状影响(C),而Top-P的候选数量会根据累计概率变化。
- Which statement best compares Greedy and Beam Search methods in the context of NLP inference?
A) Greedy Search is deterministic and fast but may produce suboptimal results
B) Beam Search explores multiple paths, improving the chance to reach a higher scoring sequence
C) Both methods have identical computational complexity
D) Greedy Search always produces more diverse outputs than Beam Search
贪心搜索是确定性的且速度快,但可能会错过更优序列(A);Beam Search通过保留多个候选路径提高了整体输出质量(B)。选项C和D均不正确。
- Which of the following statements about exhaustive search in sequence tagging tasks is correct? (Select all that apply)
A) It guarantees finding the global optimal solution.
B) It scales well with increasing sentence length.
C) Its time complexity is exponential, O(|tags|^|words|).
D) It is computationally efficient for long sentences.
A) 正确,因为穷举搜索遍历所有可能性,能够保证找到全局最优解。
B) 错误,随着句子长度增加,穷举搜索的搜索空间呈指数级增长,不具备扩展性。
C) 正确,穷举搜索的时间复杂度为每个单词都有 |tags| 种选择,总体为 O(|tags|^|words|)(指数级)。
D) 错误,由于计算量巨大,长句子时计算效率极低。
- What is Dynamic Programming (DP)?
A. A method to solve problems by breaking them into overlapping subproblems
B. A technique to guess the answer based on prior probability
C. A strategy to randomly explore solution space
D. A method to simulate neural network behavior
动态规划是一种通过将问题分解成重复的子问题并保存它们的解来避免重复计算的方法,通常用于优化最优解问题。
- In sequence tagging, what does the emission model represent?
A. The probability of transitioning between labels
B. The likelihood of a word being generated by a label
C. The overall score of the sequence
D. The loss function of the model
发射模型用于计算当前单词属于某个标签的概率,即单词与标签之间的关联。
- In sequence tagging, the transition model calculates the probability of:
A. Emitting a word
B. Moving from one label to another
C. Generating a new sequence
D. Predicting the next word in a sentence
转移模型表示从前一个标签到当前标签的转移概率,用于考虑标签之间的依赖关系。
- What is the time complexity of standard sequence tagging using dynamic programming with a fixed label set?
A. O(|words|)
B. O(|words| × |labels|)
C. O(|words| × |labels|²)
D. O(|words| × |labels|³)
当标签集固定时,每个单词需要考虑所有标签之间的转移,其时间复杂度为 O(单词数×标签数²)。
- How does a greedy prediction approach differ from a dynamic programming approach in sequence tagging?
A. Greedy prediction always finds the global optimum
B. Greedy prediction makes local optimal choices that might lead to global errors
C. Dynamic programming ignores emission probabilities
D. Greedy prediction considers all possible paths simultaneously
贪心算法每次只选择局部最优,可能忽略整体最优解,从而导致错误,而动态规划考虑了全局信息。
- Which problem is associated with independent predictions in sequence tagging?
A. They always result in the best global sequence
B. They may yield inconsistent overall predictions
C. They reduce computational complexity to O(1)
D. They guarantee consistent label transitions
独立预测忽略了标签之间的依赖性,可能导致整体标签序列不一致的问题。
- The sentence “the old man the boat” is used to illustrate:
A. The effectiveness of greedy algorithms
B. The complexity of language ambiguity in sequence tagging
C. The clarity of independent predictions
D. A typical example of correct tagging
该例句展示了语言歧义和贪心预测的局限性,即错误预测可能导致全局错误。
-
In dynamic programming for sequence tagging, what does “prob pre” refer to?
A. The initial probability for the first word
B. The probability of the previous label’s state
C. The overall probability of the sequence
D. The emission probability of the current word -
Which two main components are used to calculate the score in sequence tagging models?
A. Input embedding and output layer
B. Emission model and transition model
C. Loss function and activation function
D. Neural network and support vector machine -
What is the primary purpose of using dynamic programming in graph parsing?
A. To randomly sample parse trees
B. To store and reuse intermediate results for building the best parse
C. To eliminate the need for transition models
D. To increase the randomness in predictions
动态规划在图解析中主要通过存储中间结果来避免重复计算,从而高效地构造得分最高的解析树。
- What is the time complexity of the CKY algorithm as described in the text?
A. O(|words|)
B. O(|words|²)
C. O(|rules_comb| × |words|³ + |rules_arc| × |words|²)
D. O(|words| × |labels|)
CKY算法的时间复杂度为 O(组合规则数×单词数³ + 弧规则数×单词数²)。
- What is the primary goal of coreference resolution in NLP?
A. To generate summaries of texts
B. To identify when different expressions refer to the same entity
C. To tag parts of speech in a sentence
D. To compute the probability of word sequences
共同指代的主要目的是识别文本中不同表达是否指向相同的实体。
- How does entity linking (wikification) differ from coreference resolution?
A. It assigns part-of-speech tags to words
B. It links each entity mention to an external knowledge base
C. It groups words based on their syntactic structure
D. It predicts the next word in a sequence
实体链接不仅判断文本中实体是否指同一事物,还将这些实体链接到外部知识库,如维基百科。
- Which is a suggested simplification strategy for coreference resolution mentioned in the text?
A. Using a deep neural network to process the entire document simultaneously
B. First perform mention detection and filtering
C. Ignoring the transitive property of references
D. Applying independent tagging without pairwise comparisons
一种简化方法是首先检测和过滤所有可能的提及,然后再进行候选提及对的链接处理。
- In graph parsing, what does an “arc” represent?
A. A connection between two unrelated sentences
B. A dependency relation from a head word to a dependent
C. A punctuation mark in the sentence
D. A random edge in a neural network
在图解析中,“arc”表示词语之间的依存关系,即从核心词(head)到依赖词(dependent)的连接。
- What role do “rules” play in the dynamic programming approach to parsing?
A. They define the way items can be combined to form larger structures
B. They randomly generate parse trees
C. They act as regularizers in the training process
D. They provide the word embeddings for each node
规则定义了如何将已有的中间结构(items)组合成更大的部分,从而逐步构造完整的解析树。
相关文章:

【NLP】16. NLP推理方法重点回顾 -- 52道多选题
Which of the following problems are commonly solved using sequence tagging? A) Named Entity Recognition (NER) B) Part-of-Speech (POS) Tagging C) Word Embedding Training D) Syntactic Dependency Parsing 序列标注是一种 NLP 任务,常用于 命名实体…...

Redisson分布式锁深度解析:原理与实现机制
Redisson作为Redis Java客户端中的分布式解决方案佼佼者,其分布式锁实现被广泛应用于生产环境。以下从底层设计到源码实现进行全面剖析。 一、核心架构设计 1. 整体架构图 graph LRA[客户端] --> B[RLock接口]B --> C[RedissonLock]C --> D[Redis命令执…...

Linux 系统调用实现机制详解
Linux 系统调用实现机制详解 —— fork()、execve()、waitpid() 内核层面的秘密 在 Linux 内核中,fork()、execve() 和 waitpid() 是构建多任务操作系统的三大基石,它们涉及进程控制、内存管理、文件系统等多个子系统。本文将带你一探它们在 内核层面的…...

责任链模式_行为型_GOF23
责任链模式 责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,核心思想是将多个处理请求的对象连成一条链,请求沿链传递直到被处理。它像现实中的“多级审批流程”——请假或报销时,申请会逐级提交给…...

03-SpringBoot3入门-配置文件(自定义配置及读取)
1、自定义配置 # 自定义配置 zbj:user:username: rootpassword: 123456# 自定义集合gfs:- a- b- c2、读取 1)User类 package com.sgu.pojo;import lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.spring…...

学习记录-软件测试基础
一、软件测试分类 1.按阶段:单元测试(一般开发自测)、集成测试、系统测试、验收测试 2.按代码可见度测试:黑盒测试、灰盒测试、白盒测试 3.其他:冒烟测试(冒烟测试主要是在开发提测后进行,主要是测试主流…...

【蓝桥杯每日一题】3.28
🏝️专栏: 【蓝桥杯备篇】 🌅主页: f狐o狸x "今天熬的夜,会变成明天奖状的闪光点!" 目录 一、唯一的雪花 题目链接 题目描述 解题思路 解题代码 二、逛画展 题目链接 题目描述 解题思路 解题代…...

优秀的 React 入门开源项目推荐
以下是一些优秀的 React 入门开源项目推荐,涵盖不同应用场景和功能模块,适合学习和实践: 1. Jira Clone 仓库地址:GitHub - oldboyxx/jira_clone 亮点: 基于 React Hooks 实现,模仿 Jira 的任务管理功能。…...

万字长文详解Text-to-SQL
什么是Text-to-SQL 在各个企业数据量暴涨的现在,Text-to-SQL越来越重要了,所以今天就来聊聊Text-to-SQL。 Text-to-SQL是一种将自然语言查询转换为数据库查询的技术。它可以让用户通过自然语言来查询数据库,而不需要编写复杂的SQL语句。 T…...

【Linux】动静态库的制作与使用
一.对软硬链接的补充 1、无法对目录进行硬链接 为什么呢? 首先,我们在访问文件时,每一个文件都会有自己的dentry结构,这些结构会在内存中维护一棵路径树,来快速进行路径查找。但是如果某个节点直接使用硬链接到了根节…...
ubuntu22.04 如何安装 ch341 驱动
前言 本篇是介绍ubuntu22.04如何安装 ch341 驱动,并对其中遇到的问题进行整理。 一、流程 1.1 查看CH340驱动 首先是查看ubuntu22.04系统自带的驱动,用以下命令即可 ls /lib/modules/$(uname -r)/kernel/drivers/usb/serial 然后会跳出以下界面&…...
个人博客网站从搭建到上线教程
步骤1:设计个人网站 设计个人博客网站的风格样式,可以在各个模板网站上多浏览浏览,以便有更多设计网站风格样式的经验。 设计个人博客网站的内容,你希望你的网站包含哪些内容如你的个人基本信息介绍、你想分享的项目、你想分享的技术文档等等。 步骤2:选择开发技术栈 因…...

android 一步完成 aab 安装到手机
家人们谁懂!在 Android 系统安装 aab 应用超麻烦。满心期待快速体验,却发现 aab 无法直装,得先转为 apks 格式,这过程复杂易错。好不容易转好,还得安装 apks,一番折腾,时间与耐心全耗尽。别愁&a…...

c#使用forms实现屏幕截图
说明: c#使用forms实现屏幕截图 step1: 点击按钮,拖拽,截图,保存本地 C:\Users\wangrusheng\RiderProjects\WinFormsApp1\WinFormsApp1\Form1.cs using System; using System.Drawing; using System.Drawing.Imaging; using Syst…...

mac m4 Homebrew安装MySQL 8.0
1.使用Homebrew安装MySQL8 在终端中输入以下命令来安装MySQL8: brew install mysql8.0 安装完成后,您可以通过以下命令来验证MySQL是否已成功安装: 2.配置mysql环境变量 find / -name mysql 2>/dev/null #找到mysql的安装位置 cd /op…...

UE5学习笔记 FPS游戏制作26 UE中的UI
文章目录 几个概念创建一个UI蓝图添加UI获取UI的引用 切换设计器和UI蓝图将UI添加到游戏场景锚点轴点slotSizeToContent三种UI数据更新方式(Text、Image)函数绑定属性绑定事件绑定 九宫格分割图片按钮设置图片绑定按下事件 下拉框创建添加数据修改样式常用函数 滚动框创建添加数…...
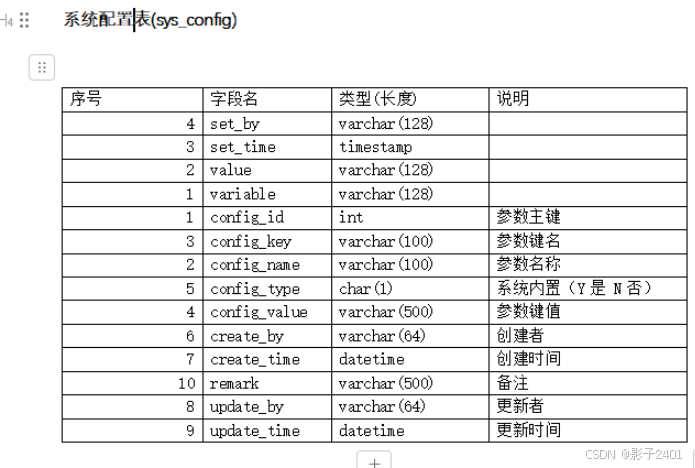
Navicat导出mysql数据库表结构说明到excel、word,单表导出方式记录
目前只找到一张一张表导出的方式 使用information_schema传入表名查询 字段名根据需要自行删减,一般保留序号、字段名、类型、说明就行 SELECT COLUMNS.ORDINAL_POSITION AS 序号, COLUMNS.COLUMN_NAME AS 字段名, COLUMNS.COLUMN_TYPE AS 类型(长度), COLUMNS.N…...

目标检测 AP 计算 实例 python
以下是使用 Python 实现目标检测中 Average Precision (AP) 计算的完整实例,包含代码和注释。这里以 Pascal VOC 标准 为例(IoU阈值0.5)。 步骤1:准备数据 假设: gt_boxes: 真实标注框列表,格式为 …...

HarmonyOS NEXT图形渲染体系:重新定义移动端视觉体验
一、革命性架构设计 1.1 多线程并行渲染引擎 HarmonyOS NEXT通过四级流水线并行架构实现渲染效率质的飞跃,其核心包含: 优先级任务调度器:动态分配紧急渲染任务(如手势反馈)与常规任务智能线程池管理:根…...

使用 Docker 18 安装 Eureka:解决新版本 Docker 不支持的问题
使用 Docker 18 安装 Eureka:解决新版本 Docker 不支持的问题 在微服务架构中,Eureka 是一个常用的注册中心,用于服务发现和管理。然而,随着 Docker 版本的更新,一些新版本的 Docker 对 Eureka 的支持并不友好。如果你…...

Linux驱动开发 中断处理
目录 序言 1.中断的概念 2.如何使用中断 中断处理流程 中断上下文限制 屏蔽中断/使能 关键区别与选择 上半部中断 下半部中断 软中断(SoftIRQ) 小任务(Tasklet) 工作队列(Workqueue) 线程 IRQ(Threaded IRQ…...
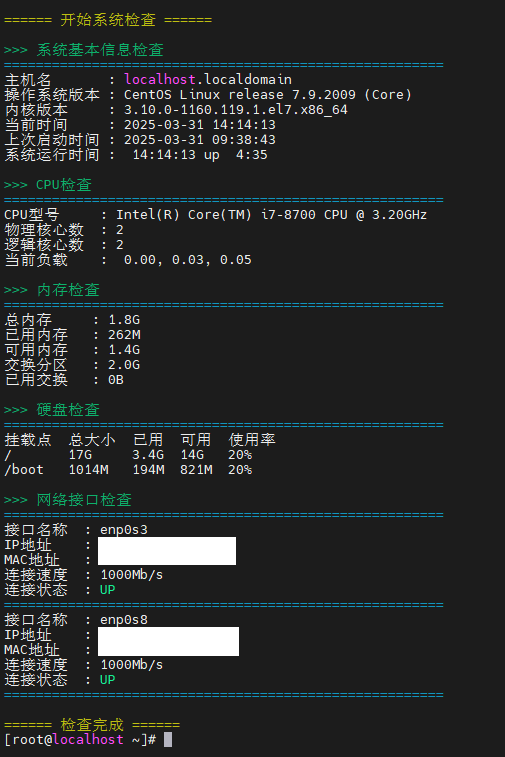
Centos主机检查脚本
使用方法: 将脚本保存为 CentOS_syscheck.sh 添加执行权限: chmod x CentOS_syscheck.sh 执行脚本: ./CentOS_syscheck.sh #!/bin/bash# 设置颜色变量 RED\033[0;31m GREEN\033[0;32m YELLOW\033[0;33m BLUE\033[0;34m NC\033[0m # 重置…...
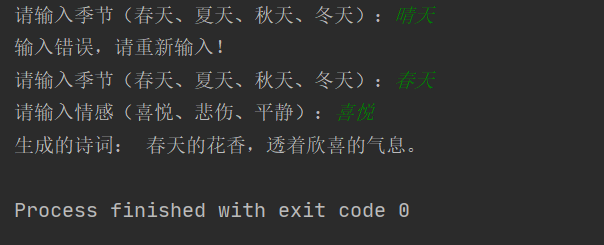
python系统之综合案例:用python打造智能诗词生成助手
不为失败找理由,只为成功找方法。所有的不甘,因为还心存梦想,所以在你放弃之前,好好拼一把,只怕心老,不怕路长。 python系列之综合案例 前言一、项目描述二、项目需求三、 项目实现1、开发准备2、代码实现 …...

【微服务】SpringBoot整合LangChain4j 操作AI大模型实战详解
目录 一、前言 二、Langchain4j概述 2.1 Langchain4j 介绍 2.1.1 Langchain4j 是什么 2.1.2 主要特点 2.2 Langchain4j 核心组件介绍 2.3 Langchain4j 核心优势 2.4 Langchain4j 核心应用场景 三、SpringBoot 整合 LangChain4j 组件使用 3.1 前置准备 3.1.1 获取apik…...

DeepSeek:巧用前沿AI技术,开启智能未来新篇章
引言 近年来,人工智能(AI)技术迅猛发展,大模型成为全球科技竞争的核心赛道。在这场AI革命中,DeepSeek作为中国领先的大模型研发团队,凭借其创新的技术架构、高效的训练方法和广泛的应用场景,迅…...

23种设计模式-结构型模式-桥接器
文章目录 简介问题解决方案示例总结 简介 桥接器是一种结构型设计模式,可将一个大类或一系列紧密相关的类拆分为抽象和实现两个独立的层次结构,从而能在开发时分别使用。 问题 假如你有一个几何形状Shape类,它有两个子类:圆形C…...

K8S学习之基础五十八:部署nexus服务
部署nexus服务 Nexus服务器是一个代码包管理的服务器,可以理解 Nexus 服务器是一个巨大的 Library 仓库。Nexus 可以支持管理的工具包括 Maven , npm 等,对于 JAVA 开发来说,只要用到 Maven 管理就可以了。Nexus服务器作用&#x…...

Docker Desktop 界面功能介绍
Docker Desktop 界面功能介绍 左侧导航栏 Containers(容器): 用于管理容器,包括查看运行中或已停止的容器,检查容器状态、日志,执行容器内命令,启动、停止、删除容器等操作。Images(镜像): 管理本地 Docker 镜像,可查看镜像列表、从 Docker Hub 拉取新镜像、删除镜…...

C++ set map
1.set和map是什么 set和map是 C STL 提供的容器,用于高效的查找数据,底层采用红黑树实现,其中set是Key模型,map是Key-Value模型 set和map的基本使用较为简单,这里不再叙述,直接进入实现环节 2.set和map的…...
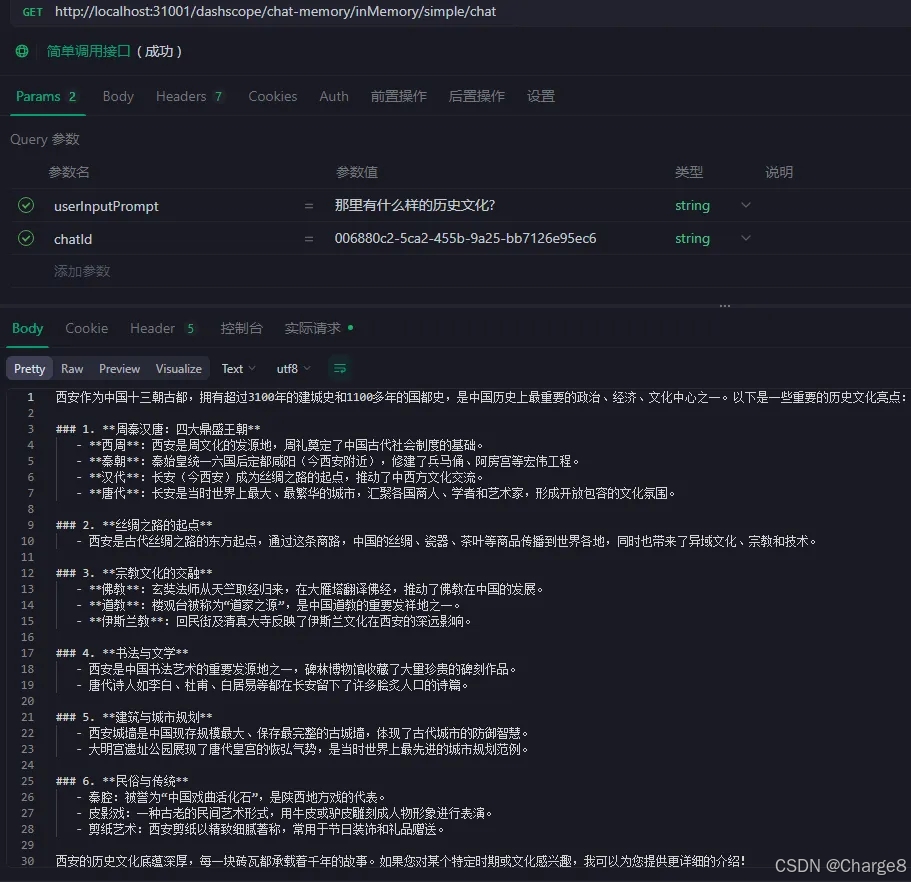
Spring AI Alibaba 对话记忆使用
一、对话记忆 (ChatMemory)简介 1、对话记忆介绍 ”大模型的对话记忆”这一概念,根植于人工智能与自然语言处理领域,特别是针对具有深度学习能力的大型语言模型而言,它指的是模型在与用户进行交互式对话过程中,能够追踪、理解并利…...