【机器学习】——机器学习思考总结
摘要
这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的需求、评分卡模型的数据量要求,以及个人消费贷场景下的数据量分析等内容,旨在为机器学习实践提供数据方面的思考与经验。
1. 为什么神经网络(DNN)能够有效学习数据特征? 是怎么实现?
神经网络(DNN, Deep Neural Networks)能够有效学习数据特征,主要依赖于多层结构和自动特征提取能力,通过非线性变换逐步从原始数据中抽取有用信息,从而完成复杂任务,如图像识别、语音识别、自然语言处理等。
1.1. 深度神经网络(DNN)的特征学习能力
DNN 之所以能有效学习数据特征,主要依赖以下关键机制:
1.2. 层级特征提取(Hierarchical Feature Extraction)
- 传统机器学习(如 SVM、决策树)依赖人工特征工程,特征设计往往需要领域知识;
- DNN 通过多层神经元,自动学习数据的不同层级特征:
-
- 浅层(前几层):学习低级特征(如边缘、纹理)
- 中层(中间层):学习中级特征(如形状、局部模式)
- 深层(后几层):学习高级特征(如物体、场景)
✅ 示例:图像分类(CNN)
- 第一层:检测边缘
- 第二层:检测简单形状(如角、线)
- 第三层:检测复杂模式(如眼睛、嘴巴)
- 最后层:判断图像类别(如猫、狗、人)
1.3. 通过非线性激活函数实现复杂映射
深度神经网络使用非线性激活函数(如 ReLU、Sigmoid、Tanh)来引入非线性变换,让神经网络能学习复杂的输入-输出关系。
- 线性模型(如线性回归)只能学习线性关系;
- DNN 通过非线性激活函数,使模型能学习非线性关系。

ReLU 的优势
- 计算简单,速度快
- 解决梯度消失问题
- 提高模型的表达能力
1.4. 反向传播(Backpropagation)+ 梯度下降(Gradient Descent)
神经网络通过反向传播算法(Backpropagation)和梯度下降优化不断调整参数,使损失最小化,从而学习有效的特征。

1.5. 参数共享与权重共享
某些神经网络(如卷积神经网络 CNN)使用参数共享机制,使模型能更高效地学习数据特征:
- CNN:通过卷积核(Filter)学习局部特征,并在整个输入空间共享参数,减少计算量。
- RNN/LSTM:时间序列数据中,共享权重学习长期依赖关系。
✅ 示例:CNN 识别猫
- 卷积层:检测图像边缘、纹理、形状
- 池化层(Pooling):降维,减少计算量
- 全连接层:将提取的特征用于分类(如猫 or 狗)
1.6. 过拟合 & 泛化能力
深度学习虽然能学习复杂特征,但过拟合是一个常见问题(在训练数据上效果好,但测试数据上表现差)。
✅ 解决方案
| 方法 | 作用 |
| 正则化(L1/L2) | 防止模型过度依赖特定特征 |
| Dropout | 随机丢弃部分神经元,防止过拟合 |
| 数据增强(Data Augmentation) | 扩展训练数据,提高泛化能力 |
| Batch Normalization | 使每一层输入数据分布稳定,加速训练 |
1.7. 深度神经网络如何实现特征学习?
总结来说,深度神经网络能够有效学习数据特征的原因包括:
- 层级特征提取(低级 → 高级特征)。
- 非线性激活函数 让网络能学习复杂映射关系。
- 反向传播 + 梯度下降 让网络不断优化权重,找到最优特征表示。
- 参数共享(如 CNN、RNN)减少计算复杂度,提高效率。
- 正则化、Dropout、BatchNorm 提高泛化能力,避免过拟合。
深度学习的本质: e通过自动特征学习,减少人工特征工程的依赖,在复杂任务上超越传统机器学习!
2. 数据集大小标准? 什么是大数据集、什么中数据集?什么小数据集。
数据集的大小通常没有严格的数值标准,但在机器学习和深度学习领域。
一般按照以下大致标准来区分 小数据集、中等数据集、大数据集:
| 类别 | 数据量(样本数 N) | 存储大小 | 示例 |
| 小数据集(Small Dataset) | N < 1万 | MB 级(<100MB) | Kaggle 小型数据集、UCI 数据集 |
| 中等数据集(Medium Dataset) | 1万 ≤ N < 100万 | GB 级(100MB - 10GB) | 图像分类数据集(CIFAR-10)、金融交易数据 |
| 大数据集(Large Dataset) | N ≥ 100万 | TB 级(10GB - TB 级) | ImageNet(1400万张图片)、电商交易数据、日志数据 |
| 超大规模数据集(Huge Dataset) | N ≥ 10亿 | PB 级(TB - PB) | GPT 训练数据(万亿级 Token)、互联网爬虫数据 |
2.1. 不同数据集大小的影响
- 小数据集
-
- 适合传统机器学习(SVM、决策树),不适合深度学习。
- 容易过拟合,需要使用数据增强、正则化。
- 适合交叉验证(如 10-Fold CV) 来稳定评估。
- 中等数据集
-
- 适合深度学习(CNN、RNN),但需要较强的计算资源(如 GPU)。
- 可用简单的批量处理(Batch Training) 训练模型。
- 大数据集
-
- 需要分布式计算(Hadoop、Spark、Flink)。
- 适合深度学习(如 GPT、BERT)。
- 需要GPU/TPU 加速,并行训练(数据并行、模型并行)。
2.2. 数据集大小示例
- 小数据集
-
- Iris 数据集(150 条数据,<1MB)
- Titanic 生存预测(891 条数据,~5MB)
- 中等数据集
-
- CIFAR-10(6 万张图片,~175MB)
- MNIST(7 万张手写数字,~60MB)
- 大数据集
-
- ImageNet(1400 万张图片,约 150GB)
- Google BERT 训练数据(TB 级文本数据)
- 超大数据集
-
- GPT-4 训练数据(>TB 级,包含整个互联网文本)
2.3. 如何选择算法和计算资源
| 数据集大小 | 适合的算法 | 计算资源 |
| 小数据集 | 传统 ML(决策树、SVM、KNN) | CPU/小型 GPU |
| 中等数据集 | 深度学习(CNN、RNN) | 单机 GPU |
| 大数据集 | 深度学习 + 分布式计算(Transformer, GPT) | 分布式 GPU/TPU |
| 超大数据集 | GPT-4、LLM 训练 | 上万张 GPU/TPU |
2.4. 数据集的大小与模型训练总结
- N < 1万(小数据集) → 传统机器学习。
- 1万 ≤ N < 100万(中数据集) → 深度学习可行,单机 GPU 训练。
- N ≥ 100万(大数据集) → 需要分布式计算、GPU/TPU 并行。
- N ≥ 10亿(超大数据集) → AI 训练(如 GPT-4),需要超级计算集群。
3. 机器学习需要多少训练数据?
机器学习所需的训练数据量取决于多个因素,包括模型的复杂度、数据的质量、问题的难度以及期望的性能水平。以下是一些关键影响因素:
3.1. 模型复杂度
- 简单模型(如线性回归、逻辑回归):通常需要较少的数据,数百到数千条数据可能就能得到不错的效果。
- 复杂模型(如深度神经网络):通常需要大量数据,可能是数十万甚至上百万条数据。
3.2. 数据维度(特征数)
- 维度越高,所需数据越多(维度灾难)。
- 经验法则:至少需要 10 倍于特征数 的数据样本。例如,如果有 100 个特征,建议至少有 1000 条数据。
3.3. 任务类型
- 监督学习(如分类、回归):需要大量带标签的数据。
- 无监督学习(如聚类、降维):通常可以用较少的数据,但效果依赖于数据的结构。
- 强化学习:训练样本通常是通过与环境交互生成的,需要大量尝试和时间。
3.4. 数据质量
- 高质量数据(无噪声、标注准确)可减少所需数据量。
- 低质量数据(含有噪声、错误标签)可能需要更多数据才能弥补误差。
3.5. 经验法则
- 小规模问题(如信用评分):数千到几万条数据可能足够。
- 中等规模问题(如图像分类、推荐系统):通常需要 10万+ 数据。
- 大规模问题(如自动驾驶、语音识别):往往需要 百万级别 甚至 上亿 数据。
3.6. 迁移学习(如果数据不足)
如果数据不足,可以使用预训练模型(如 ResNet、BERT),然后在小数据集上进行微调,减少对大规模数据的需求。
4. 数据集应该怎么划分测试集、训练集、验证集? 他们作用是什么?
4.1. 数据集定义
在机器学习或深度学习任务中,通常将数据集划分为 训练集(Train Set)、验证集(Validation Set) 和 测试集(Test Set),每个部分的作用如下:
4.1.1. 训练集(Training Set)
- 作用:用于训练模型,让模型学习数据的特征和模式,调整内部参数(如神经网络的权重)。
- 占比:通常占 60%~80%,如果数据量大,可以适当减少。
4.1.2. 验证集(Validation Set)
- 作用:用于 调优模型超参数(如学习率、正则化参数)和 防止过拟合,帮助选择最优模型。
- 占比:通常占 10%~20%,用于在训练过程中评估模型性能,调整模型结构或超参数。
4.1.3. 测试集(Test Set)
- 作用:用于 最终评估模型的泛化能力,测试集的数据模型在训练和调优过程中完全不可见。
- 占比:通常占 10%~20%,确保模型在未见过的数据上仍能保持较好的预测能力。
4.2. 数据划分的方法
4.2.1. 随机划分(自留法)
- 直接按比例随机拆分数据,例如 70% 训练集,15% 验证集,15% 测试集。
4.2.2. K折交叉验证(K-Fold Cross Validation)
- 适用于数据量较少的情况,通常划分成 K 份,每次选择 K-1 份训练,剩下 1 份验证,循环 K 次,最终取平均结果。
4.2.3. 时间序列数据划分
- 如果数据有时序特性(如金融、风控、交易数据),不能随机划分,而是按照时间顺序划分,如前 80% 作为训练集,后 10% 验证集,最后 10% 测试集。
4.3. 风控、金融数据划分的特点
由于风控涉及时间敏感性数据,数据通常按时间划分而非随机划分。例如:
- 过去 2 年的数据用于训练
- 最近 6 个月的数据用于验证
- 最近 1 个月的数据用于测试
这样可以更真实地模拟模型在生产环境中的表现。
5. 训练样本越多,学习获得具有强泛化能力的模型?
在机器学习中,数据集 DDD 通常被假设为独立同分布 (i.i.d.) 的,即数据样本是相互独立的,并且来自相同的分布。这一假设对于理论分析和模型泛化能力至关重要。
5.1. 训练样本越多,模型的泛化能力越强的原因:
减少过拟合
- 训练样本较少时,模型可能会记住训练数据中的噪声和特殊模式,而不是学习到数据的真实分布,导致泛化能力较差。
- 增加样本量后,模型能够更好地捕捉数据的整体特征,而不是仅仅记住个别样本,提高了模型的泛化能力。
更准确地逼近真实数据分布
- 训练数据的目的是估计真实的数据分布 P(X,Y)P(X, Y)P(X,Y)。样本量越大,数据的统计特性(如均值、方差等)就越接近真实分布,避免了由于小样本引起的偏差(sampling bias)。
- 例如,假设某个任务的数据分布是 P(X,Y)P(X, Y)P(X,Y),如果我们只采样了很少的数据,那么采样到的样本可能不能全面代表整个分布。随着样本量增加,数据的覆盖面更广,能够更好地反映 P(X,Y)P(X, Y)P(X,Y) 的真实情况。
符合大数定律
- 根据大数定律,当样本数趋近无穷时,样本的经验分布会逐渐收敛于真实分布。换句话说,随着数据增多,模型训练时所依赖的经验分布会更接近数据的真实分布,从而提高泛化能力。
降低方差,提高模型稳定性
- 在小数据集上训练的模型,其参数可能会对每个样本的细节高度敏感,导致模型的方差较大,即不同训练集上的训练结果可能差异较大。
- 但如果训练样本充足,模型在不同数据集上的表现会更加稳定,即使更换训练集,模型也能保持较好的泛化性能。
结论: 当训练样本数量增加时,我们对真实数据分布 P(X,Y)的估计就会更加准确,避免过拟合,并且符合大数定律的收敛特性,从而提高模型的泛化能力。这也是为什么深度学习通常需要大规模数据集才能训练出高性能的模型。
6. 深度神经网络实现应用是不是依赖于现代计算机计算速度?
是的,深度神经网络(DNN) 的应用和发展高度依赖现代计算机的计算速度。DNN 需要大量的计算资源来训练和推理,特别是对于大规模数据和复杂模型(如 GPT、ResNet、Transformer),计算能力直接决定了其可行性和效率。
7. 评分卡模型(如信用评分卡、欺诈检测模型)数据量要求
金融风控公司建立评分卡模型(如信用评分卡、欺诈检测模型)时,数据量的需求取决于多个因素,包括业务场景、评分卡类型、数据质量以及建模方法。以下是详细的分析:
7.1. 评分卡建模的数据需求分析
7.1.1. 评分卡类型
- 应用评分卡(Application Scorecard):用于评估新客户的信用风险,通常需要 10万+ 的历史申请数据。
- 行为评分卡(Behavior Scorecard):用于评估已有客户的信用行为,需要 数十万甚至百万级 交易数据。
- 催收评分卡(Collection Scorecard):用于预测违约客户的还款可能性,通常需要 至少几万条 违约客户数据。
- 欺诈检测评分卡:涉及少数欺诈案例,可能需要 百万级数据 来确保足够的欺诈样本。
7.1.2. 数据维度(特征数)
- 评分卡模型(如 Logistic 回归)一般使用 20~50 个变量,每个变量可能有多个衍生特征。
- 经验法则:样本数至少是 特征数的 10 倍。如果有 30 个特征,至少需要 几万条数据。
7.1.3. 违约率及少数类样本
- 对于不平衡数据(如违约率 <5%),需要更大的数据集来保证违约客户样本充足。
- 通常需要至少 5,000~10,000 条违约样本 才能建立稳健的模型。
- 如果违约样本较少,可使用上采样、下采样或 SMOTE 方法增加数据量。
7.2. 经验数据量参考
| 评分卡类型 | 适用场景 | 推荐样本量(保守估计) |
| 应用评分卡 | 贷款审批、信用卡申请 | 10万+ |
| 行为评分卡 | 现有用户还款预测 | 10万~50万 |
| 催收评分卡 | 违约催收 | 5万+ |
| 欺诈评分卡 | 交易反欺诈 | 50万~100万+ |
7.3. 如何减少对大数据的依赖?
- WOE 分箱 + 变量筛选:降低变量维度,减少所需样本量。
- 迁移学习:如果数据有限,可使用其他相似金融业务的数据进行迁移学习。
- 集成学习:组合多个小样本模型,提高泛化能力。
- 合成数据:对少数类样本(如欺诈)进行数据增强。
7.4. 评分卡模型总结
📌 评分卡建模至少需要几万条数据,但更复杂的场景可能需要 10 万甚至百万级数据。
📌 如果你能提供更具体的业务场景(如个人消费贷、企业贷款、信用卡、反欺诈等),我可以帮你更精准估算数据需求!
7.5. 计算能力对深度神经网络的影响

7.6. 推理(Inference)仍然依赖计算
虽然推理计算量比训练小,但对于大模型(如 ChatGPT、DALL·E)仍然非常重要:
- 实时性要求高(如自动驾驶、智能语音助手)
- 并发量大(如搜索引擎、推荐系统)
✅ 计算优化方案
- 低延迟部署:使用专用 AI 加速芯片(如 TPU、NPU)
- 模型量化(Quantization):减少计算量,提高速度
8. 未来研究大模型是不是可以从的模型优化与计算两个方向?
是的,未来的深度学习模型研究可以从模型优化和计算优化两个主要方向进行突破,这两者相辅相成,共同推动人工智能的发展。
8.1. 模型优化方向
8.1.1. 更高效的模型架构
目标:在不增加计算成本的情况下,提高模型性能。
- 轻量化神经网络(EfficientNet, MobileNet):减少参数,提高推理速度,适用于移动端/边缘计算。
- 稀疏神经网络(Sparse Networks):通过剪枝(Pruning)和量化(Quantization)减少计算量。
- 自监督学习(Self-Supervised Learning, SSL):减少对大规模标注数据的依赖,提高数据利用率。
- 混合专家模型(Mixture of Experts, MoE):像 GPT-4 等大模型,使用部分激活的专家网络,减少计算消耗。
8.1.2. 训练方法优化
目标:减少训练时间,提高泛化能力。
- 蒸馏学习(Knowledge Distillation):用大模型训练小模型,提高效率。
- 对比学习(Contrastive Learning):提高无监督学习效果,减少数据需求。
- 梯度压缩(Gradient Compression):减少分布式训练中的通信开销,加速大规模模型训练。
- 自适应优化算法(Adaptive Optimization):如 LAMB、Lion,比 Adam 更适合大模型训练。
8.1.3. 模型的泛化与鲁棒性
目标:让模型更稳定,适应不同环境。
- 抗对抗攻击(Adversarial Robustness):提升 AI 在现实环境下的可靠性。
- 多模态学习(Multimodal Learning):结合图像、文本、语音,提高 AI 认知能力。
- 小样本学习(Few-shot / Zero-shot Learning):让模型能从少量样本中学习,提高应用范围。
8.2. 计算优化方向
8.2.1. 硬件加速
目标:使用更高效的硬件减少计算开销。
- GPU 并行计算优化(如 NVIDIA CUDA):加速矩阵计算,提高训练效率。
- 专用 AI 芯片(TPU、NPU):Google TPU 专门用于 AI 计算,比 GPU 更高效。
- 存储与计算融合(Processing-in-Memory, PIM):减少数据移动,提高 AI 计算速度。
- 光子计算(Photonic Computing):未来 AI 计算可能摆脱电子器件的限制,实现更快速度。
8.2.2. 分布式计算
目标:利用多台服务器加速训练。
- 数据并行(Data Parallelism):每个 GPU 处理一部分数据,加快训练。
- 模型并行(Model Parallelism):每个 GPU 处理模型的不同部分,适合超大模型(如 GPT-4)。
- 联邦学习(Federated Learning):多个设备协作训练 AI,保护隐私(如手机 AI)。
8.2.3. 计算方法优化
目标:减少计算量,提升计算效率。
- 低比特计算(Low-bit Computation):使用 8-bit 甚至 4-bit 计算代替 32-bit,提高速度。
- 动态计算(Dynamic Computation):只计算必要部分,减少冗余计算,如 Transformer 的稀疏注意力(Sparse Attention)。
- 能效优化(Energy-efficient AI):降低 AI 计算的能耗,使 AI 更环保。
8.3. 未来AI研究趋势
| 方向 | 研究目标 | 代表技术 |
| 模型优化 | 提高准确率、减少计算需求 | EfficientNet, MoE, 知识蒸馏 |
| 计算优化 | 降低计算成本、加快推理速度 | TPU, NPU, 分布式计算 |
| 训练优化 | 提高训练效率、减少数据需求 | 联邦学习, 对比学习 |
| 推理优化 | 让 AI 更快、更轻量 | 量化, 稀疏计算, 低比特计算 |
🚀 未来 AI 的发展,既要“更聪明”,也要“更高效”!
博文参考
相关文章:
【机器学习】——机器学习思考总结
摘要 这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的…...

html处理Base文件流
处理步骤 从服务返回的字符串中提取文件流数据,可能是Base64或二进制。将数据转换为Blob对象。创建对象URL。创建<a>元素,设置href和download属性。触发点击事件以下载文件。删除缓存数据 代码 // 假设这是从服务返回的Base64字符串(…...

力扣每日一题:2712——使所有字符相等的最小成本
使所有字符相等的最小成本 题目示例示例1示例2 题解这些话乍一看可能看不懂,但是多读两遍就明白了。很神奇的解法,像魔术一样。 题目 给你一个下标从 0 开始、长度为 n 的二进制字符串 s ,你可以对其执行两种操作: 选中一个下标…...
:深入了解QMfcApp)
在MFC中使用Qt(六):深入了解QMfcApp
前言 此前系列文章回顾: 在MFC中使用Qt(一):玩腻了MFC,试试在MFC中使用Qt!(手动配置编译Qt) 在MFC中使用Qt(二):实现Qt文件的自动编译流程 在M…...

JMeter进行分布式压测
从机: 1、确认防火墙是否关闭; 2、打开网络设置,关闭多余端口;(避免远程访问不到) 3、打开JMeter/bin 目录底下的jmeter.properties; remove_hosts设置当前访问地址,192.XXXXX&…...

Python实现音频数字水印方法
数字水印技术可以将隐藏信息嵌入到音频文件中而不明显影响音频质量。下面我将介绍几种在Python中实现音频数字水印的方法。 方法一:LSB (最低有效位) 水印 import numpy as np from scipy.io import wavfile def embed_watermark_lsb(audio_path, watermark, ou…...
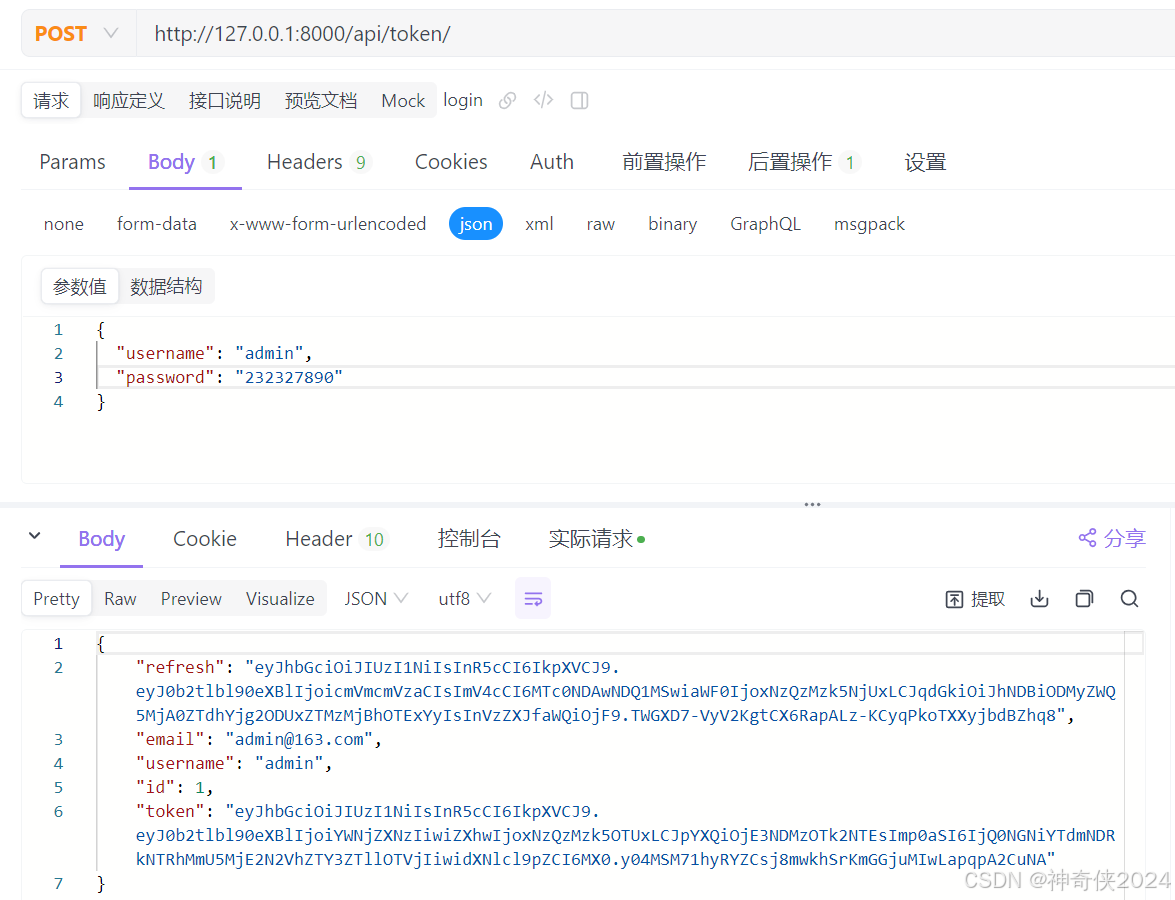
快速入手-基于Django-rest-framework的第三方认证插件(SimpleJWT)权限认证扩展返回用户等其他信息(十一)
1、修改serializer.py,增加自定义类 # 自定义用户登录token等返回信息 class MyTokenObtainPair(TokenObtainPairView): def post(self, request, *args, **kwargs): serializer self.get_serializer(datarequest.data) try: serializer.is_valid(raise_exceptio…...

关于IP免实名的那些事
IP技术已成为个人与企业保护隐私、提升网络效率的重要工具。其核心原理是通过中介服务器转发用户请求,隐藏真实IP地址,从而实现匿名访问、突破地域限制等目标。而“免实名”代理IP的出现,进一步简化了使用流程,用户无需提交身份信…...

【SQL性能优化】预编译SQL:从注入防御到性能飞跃
🔥 开篇:直面SQL的"阿喀琉斯之踵" 假设你正在开发电商系统🛒,当用户搜索商品时: -- 普通SQL拼接(危险!) String sql "SELECT * FROM products WHERE name "…...

Spring容器从启动到关闭的注解使用顺序及说明
Spring容器从启动到关闭的注解使用顺序及说明 1. 容器启动阶段 注解:Configuration、ComponentScan 作用: Configuration:标记配置类,声明Spring应用上下文的配置源。ComponentScan:扫描指定包下的组件(B…...

UVM概念面试题100问
1-10:UVM概述 Q1: 什么是UVM? A1: UVM是Universal Verification Methodology的缩写,它是由Accellera标准化的一种用于IC验证的方法学。它提供了一个基类库(BCL),包含通用工具如组件层次结构、事务级模型(TLM)和配置数据库等,使用户能够创建结构化、可重用的验证环境。 Q2:…...

SQL Server从安装到入门一文掌握应用能力。
本篇文章主要讲解,SQL Server的安装教程及入门使用的基础知识,通过本篇文章你可以快速掌握SQL Server的建库、建表、增加、查询、删除、修改等基本数据库操作能力。 作者:任聪聪 日期:2025年3月31日 一、SQL Server 介绍: SQL Server 是微软旗下的一款主流且优质的数据库…...

力扣HOT100之矩阵:54. 螺旋矩阵
这道题之前在代码随想录里刷过类似的,还有印象,我就按照当初代码随想录的思路做了一下,结果怎么都做不对,因为按照代码随想录的边界条件设置,当行数和列数都为奇数时,最后一个元素无法被添加到数组中&#…...

5.1 WPF路由事件以及文本样式
一、路由事件 WPF中存在一种路由事件(routed event),该事件将发送到包含该控件所在层次的所有控件,如果不希望继续向更高的方向传递,只要设置e.Handled true即可。 这种从本控件-->父控件->父的父控件的事件&am…...

Python数据可视化-第1章-数据可视化与matplotlib
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第1章 数据可视化与matplotlib 本文主要介绍了什么是数据集可视化,数据可视化的目的,常见的数据可视化方式…...

Flutter敏感词过滤实战:基于AC自动机的高效解决方案
Flutter敏感词过滤实战:基于AC自动机的高效解决方案 在社交、直播、论坛等UGC场景中,敏感词过滤是保障平台安全的关键防线。本文将深入解析基于AC自动机的Flutter敏感词过滤实现方案,通过原理剖析实战代码性能对比,带你打造毫秒级…...

20250331-vue-组件事件1触发与监听事件
触发与监听事件 1 在组件的模板表达式中,可以直接使用 $emit 方法触发自定义事件(例如:在 v-on 的处理函数中): 子组件代码 <template><button click"$emit(someEvent)">点击</button> </template><…...

Odoo/OpenERP 和 psql 命令行的快速参考总结
Odoo/OpenERP 和 psql 命令行的快速参考总结 psql 命令行选项 选项意义-a从脚本中响应所有输入-A取消表数据输出的对齐模式-c <查询>仅运行一个简单的查询,然后退出-d <数据库名>指定连接的数据库名(默认为当前登录用户名)-e回显…...
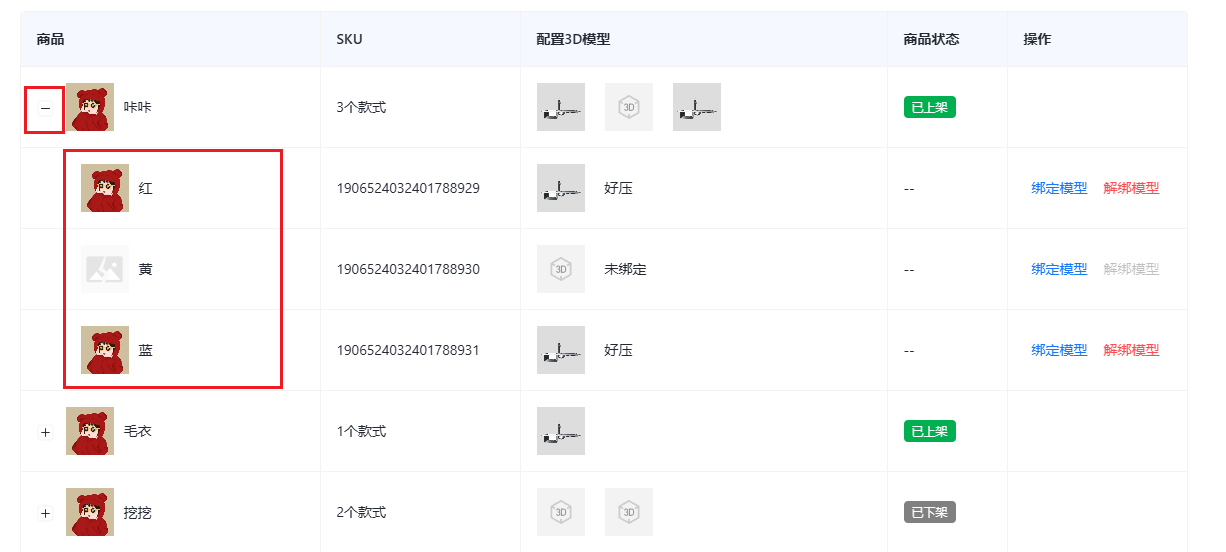
Vue中使用antd-table组件时,树形表格展开配置不生效-defaultExpandedRowKeys-默认展开配置不生效
defaultExpandedRowKeys属性 defaultExpandAllRows这个属性仅仅是用来设置默认值的,只在第一次渲染的时候起作用,后续再去改变,无法实现响应式 解决方案一 a-table表格添加key属性,当每次获取值时,动态改变key,以达到重新渲染的效果 <a-table:key="tableKey"…...

VRRP交换机三层架构综合实验
题目要求: 1,内网Ip地址使用172.16.0.0/16分配 说明可以划分多个子网,图中有2个VLAN,可以根据VLAN划分 2,sw1和SW2之间互为备份 互为备份通常通过VRRP(虚拟路由冗余协议)来实现。VRRP会在两个…...
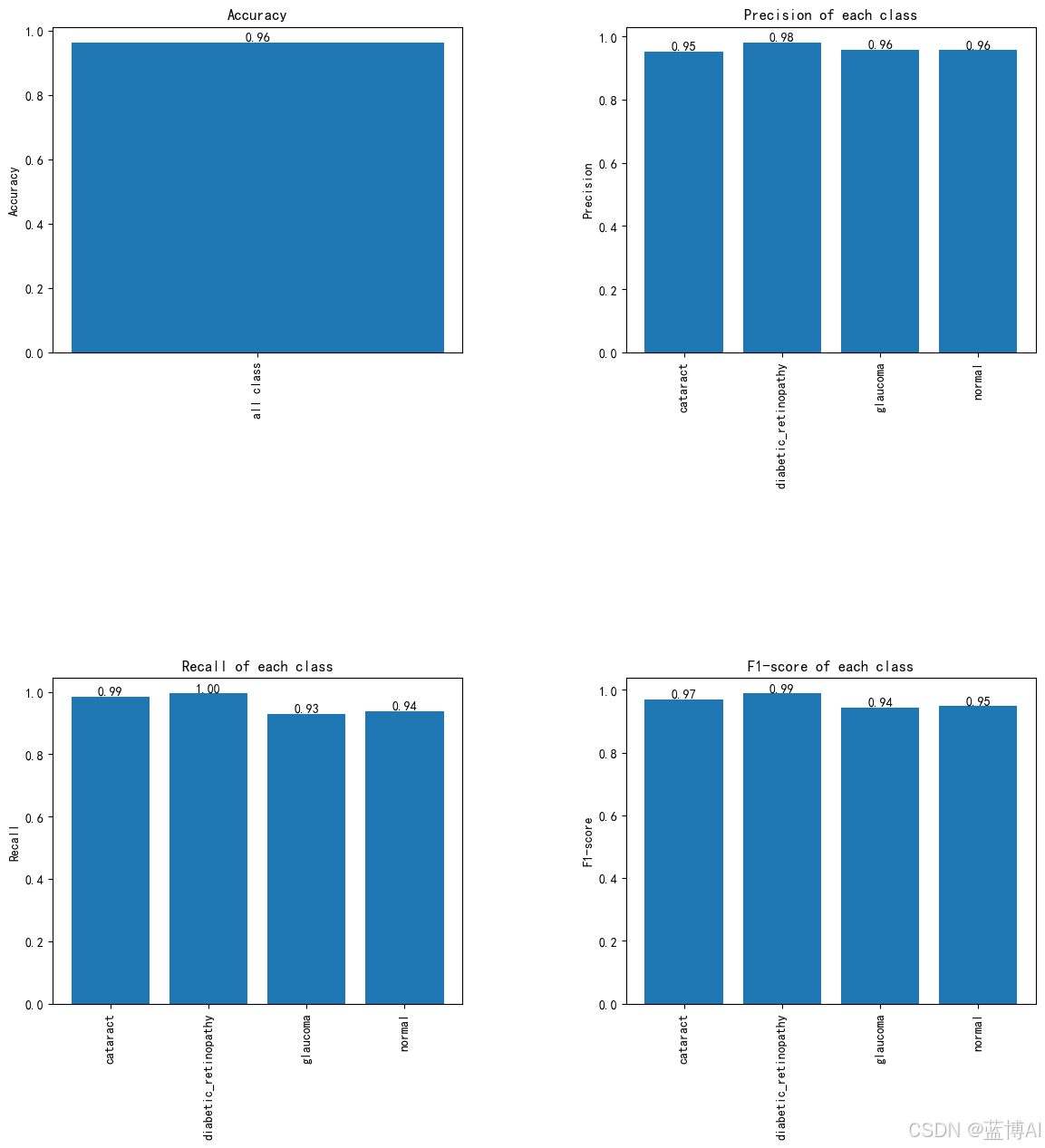
基于卷积神经网络的眼疾识别系统,resnet50,efficentnet(pytorch框架,python代码)
更多图像分类、图像识别、目标检测、图像分割等项目可从主页查看 功能演示: 眼疾识别系统resnet50,efficentnet,卷积神经网络(pytorch框架,python代码)_哔哩哔哩_bilibili (一)简介…...

基于srpingboot智慧校园管理服务平台的设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论…...
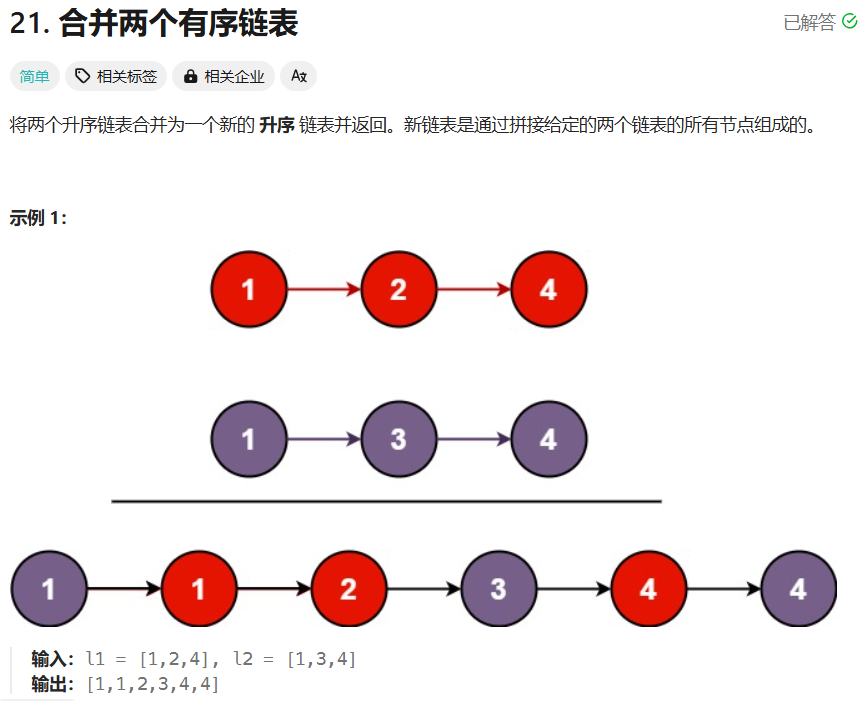
【力扣hot100题】(026)合并两个有序链表
可以创建一个新链表记录答案: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *…...

TCP网络编程与多进程并发实践
一、引言 在网络编程中,TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。而多进程并发则是一种提高服务器处理能力的有效手段,允许服务器同时处理多个客户端的请求。本文将详细介绍如何使用 TCP 协议进…...
)
【前端】一文掌握 Vue 3 指令用法(vue3 备忘清单)
文章目录 入门介绍创建应用应用实例通过 CDN 使用 Vue使用 ES 模块构建版本模板语法文本插值原始 HTMLAttribute 绑定布尔型 Attribute动态绑定多个值使用 JavaScript 表达式仅支持表达式(例子都是无效)调用函数指令 Directives参数 Arguments绑定事件动态参数动态的事件名称修…...
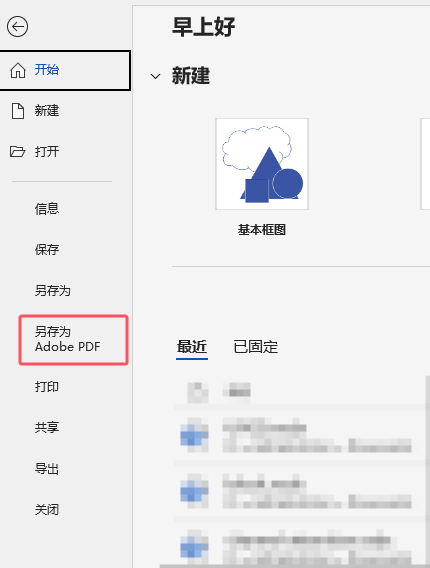
visio导出pdf公式变形
情况描述导出为pdf后,mathtype写的公式就变形了 但是导出为png和jpg就是正常 解决方法就是 需要下载一个Adobe Acrobat...

【学习笔记】计算机网络(六)
第6章应用层 文章目录 第6章应用层6.1 域名系统DNS6.1.1 域名系统概述6.1.2 互联网的域名结构6.1.3 域名服务器域名服务器的分区管理DNS 域名服务器的层次结构域名服务器的可靠性域名解析过程-两种查询方式DNS 高速缓存机制 6.2 文件传送协议6.2.1 FTP 概述6.2.2 FTP 的基本工作…...

做一个多级动态表单,可以保存数据和回显数据
<template> <div class"two"> <button class"save" click"saveBtn">保存数据</button> <button class"sd" click"showBtn">回显数据</button> <div class"all" click&quo…...

量子退火与机器学习(2):少量实验即可找到新材料,黑盒优化➕量子退火
使用量子退火和因子分解机设计新材料 这篇文章是东京大学的一位博士生的毕业论文中的主要贡献。 结合了黑盒优化和量子退火,是融合的非常好的一篇文章,在此分享给大家。 https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.2.0133…...

WPF中的Adorner基础用法详解与实例
WPF中的Adorner基础用法详解与实例 Adorner(装饰器)是WPF中一个强大的功能,它允许开发者在现有UI元素之上叠加额外的视觉效果或交互功能,而不会影响原有布局系统。本文将详细介绍Adorner的基础概念、核心用法以及实际应用示例。 …...