TiDB 可观测性解读(二)丨算子执行信息性能诊断案例分享
导读
可观测性已经成为分布式系统成功运行的关键组成部分。如何借助多样、全面的数据,让架构师更简单、高效地定位问题、分析问题、解决问题,已经成为业内的一个技术焦点。本系列文章将深入解读 TiDB 的关键参数,帮助大家更好地观测系统的状态,实现性能的优化提升。
本文为 TiDB 可观测性解读系列文章的第二篇,将探讨如何利用算子执行信息更准确地分析和诊断 SQL 性能。
你有没有遇到过这样的情况:同样模式的 SQL 语句,仅仅是日期参数或者函数的变化,最终返回的结果形式也都相同,性能却相差几十甚至上百倍。现实中遇到这样的问题,我们一般会运行 explain 语句,检查执行计划的变化情况。如果执行计划没有改变,如何进行进一步排查?
这种情况下,可以通过 explain analyze 语句来深入查看算子的实际运行情况。本文将结合实际案例和常见问题,探讨如何利用算子执行信息更准确地分析和诊断 SQL 性能。
算子执行信息介绍
通常我们可以用 explain analyze 语句获得算子执行信息。 explain analyze 会实际执行对应的 SQL 语句,同时记录其运行时信息,和执行计划一并返回出来,记录的信息包括: actRows 、 execution info 、 memory 、 disk 。

不同算子的 execution info 可以通过 TiDB 文档 ( https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze )了解。这些信息是研发人员在长期的性能问题定位中,总结提炼出来的指标,值得每一个想对 TiDB SQL 性能诊断有深入研究的同学阅读。
有时候一些 SQL 的性能问题是偶发的,这会增加我们直接使用 explain analyze 来分析的难度。这时候我们还需要借助慢日志功能来获取有效的算子执行信息。通常,我们可以通过 TiDB Dashboard 的慢日志查询 ( https://docs.pingcap.com/zh/tidb/stable/dashboard-overview#最近的慢查询 )页面,快速定位并查询到问题 SQL 的详细执行信息。
案例和问题
接下来,我们将通过一些具体案例来探讨相关问题。请注意,以下案例中的执行计划大多直接来源于生产环境(做了脱敏处理),由于本地难以复现这些场景,版本难以统一。但版本差异并不影响问题诊断和分析的完整性,本文主要探讨诊断问题的思路和方法。
查询延时抖动
查询偶发性延时抖动是较为常见的性能问题之一。如果能够通过慢日志定位到导致性能抖动的具体查询语句,进一步分析这些查询的算子执行信息,往往能够找到问题的根源并获得有效的优化线索。
实际案例
以一个客户遇到过的点查询性能抖动问题为例,点查询的延迟偶尔会超过 2s。我们先通过慢日志查询,定位到某次查询的算子执行信息:
mysql> explain analyze select * from t0 where col0 = 100 and col1 = 'A';
+---------------------+---------+---------+-----------+---------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+---------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+---------------------+---------+---------+-----------+---------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------+---------------+---------+------+
| Point_Get_1 | 1 | 1 | root | table:t0, index:uniq_col0_col1 | time:2.52s, loops:2, ResolveLock:{num_rpc:1, total_time:2.52s}, Get:{num_rpc:3, total_time:2.2ms}, txnNotFound_backoff:{num:12, total_time:2.51s}, tikv_wall_time: 322.8us, scan_detail: {total_process_keys: 2, total_process_keys_size: 825, total_keys: 9, get_snapshot_time: 18us, rocksdb: {delete_skipped_count: 3, key_skipped_count: 14, block: {cache_hit_count: 16}}} | N/A | N/A | N/A |
+---------------------+---------+---------+-----------+---------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------+---------------+---------+------+
诊断分析
首先,我们看到查询中只有一个 Point_Get_1 算子,其 execution info 中记录的执行时间为 2.52s 。这说明执行时间被完整记录了下来。
进一步查看 execution info ,我们注意到其中包含 ResolveLock 项。这一项的细节显示,总的执行时间为 2.52s ,这意味着查询的绝大部分时间都花在了 resolve lock 操作上。与此同时,实际的 Get 统计项显示总时间为 2.2ms ,这表明获取数据本身几乎不耗时。
此外,还有一个 txnNotFound_backoff 项,它记录了因残留事务触发的重试信息。这里显示总共进行了 12 次重试 ,累计耗时 2.51s ,与 ResolveLock 项的 2.52s 基本一致。因此,我们可以初步推测:点查询可能读取到了残留事务的锁,尝试 resolve lock 时发现锁已过期,进而触发了锁清理操作,这一过程导致了较高的查询延迟。
接下来,我们可以通过监控数据进一步验证这一推测:

算子并发度
在 TiDB 中,我们可以通过设置一些系统参数来调节算子的执行并发度,从而最终调节 SQL 的执行性能。算子的执行并发度往往对 SQL 的执行性能有重要的影响,比如同样多的 cop task,我们把并发度从 5 改到 10,性能可能就会有将近 1 倍的提升,当然也会更集中地占用系统的资源。执行信息可以帮助我们了解算子的实际执行并发度,为更进一步的性能诊断做好准备。下面我们来看一个运维同学实际遇到的问题。
实际问题
系统中设置了 tidb_executor_concurrency 为 5 以控制算子的并发度;同时设置了 tidb_distsql_scan_concurrency 为 15,用于限制每个读取算子的最大线程数。那么,在下述执行计划中, cop_task 和 tikv_task 是如何与这两个参数相对应的呢?
mysql> explain analyze select * from t0 where c like '2147%';
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
| IndexLookUp_10 | 3.82 | 99 | root | | time:2.83ms, loops:2, index_task: {total_time: 733.8µs, fetch_handle: 727.9µs, build: 806ns, wait: 5.14µs}, table_task: {total_time: 1.96ms, num: 1, concurrency: 5}, next: {wait_index: 821µs, wait_table_lookup_build: 108.2µs, wait_table_lookup_resp: 1.85ms} | | 41.0 KB | N/A |
| ├─IndexRangeScan_8(Build) | 3.82 | 99 | cop[tikv] | table:t0, index:idx_c(c) | time:719.1µs, loops:3, cop_task: {num: 1, max: 650µs, proc_keys: 99, rpc_num: 1, rpc_time: 625.7µs, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, tikv_task:{time:0s, loops:3}, scan_detail: {total_process_keys: 99, total_process_keys_size: 18810, total_keys: 100, get_snapshot_time: 102µs, rocksdb: {key_skipped_count: 99, block: {cache_hit_count: 3}}} | range:["2147","2148"), keep order:false | N/A | N/A |
| └─TableRowIDScan_9(Probe) | 3.82 | 99 | cop[tikv] | table:t0 | time:1.83ms, loops:2, cop_task: {num: 4, max: 736.9µs, min: 532.6µs, avg: 599µs, p95: 736.9µs, max_proc_keys: 44, p95_proc_keys: 44, rpc_num: 4, rpc_time: 2.32ms, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, tikv_task:{proc max:0s, min:0s, avg: 0s, p80:0s, p95:0s, iters:5, tasks:4}, scan_detail: {total_process_keys: 99, total_process_keys_size: 22176, total_keys: 99, get_snapshot_time: 217.3µs, rocksdb: {block: {cache_hit_count: 201}}} | keep order:false | N/A | N/A |
+-------------------------------+---------+---------+-----------+-------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------+---------+------+
3 rows in set (0.00 sec)
问题分析
我们正好借这个例子解释下执行信息中 cop_task 和 tikv_task 项的关系以及 cop task 的实际执行并发度。
cop_task 和 tikv_task 的关系
首先需要明确, execution info 中的各类 xxx_task 和执行计划中的 “ task ” 列并不是同一个概念。
例如,在执行计划中, task 列的类别分别为“ root ” 、 “ cop[tikv] ”等。它既描述了算子实际在哪个组件执行(如 TiDB、TiKV 或 TiFlash),又进一步说明了其与存储引擎的通信协议类型(如 Coprocessor、Batch Coprocessor 或 MPP)。
相比之下, execution info 中的各类 task 更多是从不同维度对算子执行信息进行拆解,以便用户快速定位潜在性能问题,并通过不同维度的信息进行相互印证。具体来说:
- tikv_task 描述的是某个具体 TiKV 算子的整体执行情况;
- cop_task 描述的是整个 RPC 任务的执行情况,它包含了 tikv_ task 。例如,一个 cop_task 可能包含 tableScan + Selection 两个算子,每个算子都有自己的 tikv_task 信息来描述其执行情况;而 cop_task 则描述了整个 RPC 请求的执行信息,其时间涵盖了这两个算子的执行时间。
类似地,在 MPP 查询中, execution info 中的 tiflash_task 统计项描述了某个具体 TiFlash 算子的整体执行情况:
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+
| HashAgg_22 | 1.00 | 1 | root | | time:17ms, open:1.92ms, close:4.83µs, loops:2, RU:1832.08, partial_worker:{wall_time:15.055084ms, concurrency:5, task_num:1, tot_wait:15.017625ms, tot_exec:12.333µs, tot_time:75.203959ms, max:15.042667ms, p95:15.042667ms}, final_worker:{wall_time:15.079958ms, concurrency:5, task_num:5, tot_wait:1.414µs, tot_exec:41ns, tot_time:75.277708ms, max:15.060375ms, p95:15.060375ms} | funcs:count(Column#19)->Column#17 | 6.23 KB | 0 Bytes |
| └─TableReader_24 | 1.00 | 1 | root | | time:16.9ms, open:1.9ms, close:3.46µs, loops:2, cop_task: {num: 2, max: 0s, min: 0s, avg: 0s, p95: 0s, copr_cache_hit_ratio: 0.00} | MppVersion: 3, data:ExchangeSender_23 | 673 Bytes | N/A |
| └─ExchangeSender_23 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:13.1ms, loops:1, threads:1}, tiflash_network: {inner_zone_send_bytes: 24} | ExchangeType: PassThrough | N/A | N/A |
| └─HashAgg_9 | 1.00 | 1 | mpp[tiflash] | | tiflash_task:{time:13.1ms, loops:1, threads:1} | funcs:count(test.lineitem.L_RETURNFLAG)->Column#19 | N/A | N/A |
| └─TableFullScan_21 | 11997996.00 | 11997996 | mpp[tiflash] | table:lineitem | tiflash_task:{time:12.8ms, loops:193, threads:12}, tiflash_scan:{mvcc_input_rows:0, mvcc_input_bytes:0, mvcc_output_rows:0, local_regions:10, remote_regions:0, tot_learner_read:0ms, region_balance:{instance_num: 1, max/min: 10/10=1.000000}, delta_rows:0, delta_bytes:0, segments:20, stale_read_regions:0, tot_build_snapshot:0ms, tot_build_bitmap:0ms, tot_build_inputstream:15ms, min_local_stream:10ms, max_local_stream:11ms, dtfile:{data_scanned_rows:11997996, data_skipped_rows:0, mvcc_scanned_rows:0, mvcc_skipped_rows:0, lm_filter_scanned_rows:0, lm_filter_skipped_rows:0, tot_rs_index_check:3ms, tot_read:53ms}} | keep order:false | N/A | N/A |
+------------------------------+-------------+----------+--------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------+-----------+---------+
cop task 的执行并发度
首先,我们来看执行计划。 IndexLookUp_10 是一个 root 算子 。我们知道, IndexLookUp 算子主要执行两个步骤:一是通过索引获取目标行的 rowid ;二是根据 rowid 读取所需的列数据。在 IndexLookUp_10 的 execution info 中, index_task 和 table_task 的细节被分别列出。显然, index_task 对应的是 IndexRangeScan_8 算子,而 table_task 对应的是 TableRowIDScan_9 算子。
从并发度的角度来看, index_task 没有显示并发信息,这意味着 IndexRangeScan_8 算子本身的并发度默认为 1 。然而, IndexRangeScan_8 的 cop_task 的 distsql_concurrency 为 15 (由 tidb_distsql_scan_concurrency 参数决定),这意味着理论上它可以并发执行 15 个 cop task 来读取数据。
对于 table_task ,其并发度为 5 (由 tidb_executor_concurrency 参数决定),表示最多可以同时运行 5 个 TableRowIDScan_9 算子 。而 TableRowIDScan_9 的 cop_task 的 distsql_concurrency 同样为 15 (由 tidb_distsql_scan_concurrency 决定)。因此, table_task 的最大并发读取能力为 5 × 15 = 75 个 cop task 。
max 换成 min,慢了好几十倍
实际案例
一条对索引列求 max 值的 SQL 花费 100 毫秒左右,换成求 min 值,却需要花费 8s 多时间,这是他们 explain analyze 的信息:
mysql> explain analyze select max(time_a) from t0 limit 1;
+--------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
| Limit_14 | 1.00. | 1 | root | | time:2.328901ms, loops:2 | offset:0, count:1 | N/A | N/A |
| └─StreamAgg_19 | 1.00 | 1 | root | | time:2.328897ms, loops:1 | funcs:max(t0.time_a)->Column#18 | 128 Bytes | N/A |
| └─Limit_39 | 1.00 | 1 | root | | time:2.324137ms, loops:2 | offset:0, count:1 | N/A | N/A |
| └─IndexReader_45 | 1.00 | 1 | root | | time:2.322215ms, loops:1, cop_task: {num: 1, max:2.231389ms, proc_keys: 32, rpc_num: 1, rpc_time: 2.221023ms, copr_cache_hit_ratio: 0.00} | index:Limit_26 | 461 Bytes | N/A |
| └─Limit_44 | 1.00 | 1 | cop[tikv] | | time:0ns, loops:0, tikv_task:{time:2ms, loops:1} | offset:0, count:1 | N/A | N/A |
| └─IndexFullScan_31 | 1.00 | 32 | cop[tikv] | table:t0, index:time_a(time_a) | time:0ns, loops:0, tikv_task:{time:2ms, loops:1} | keep order:true, desc | N/A | N/A |
+------------------------------+---------+---------+-----------+----------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------+------+
6 rows in set (0.12 sec)mysql> explain analyze select min(time_a) from t0 limit 1;
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
| Limit_14 | 1.00 | 1 | root | | time:8.263857153s, loops:2 | offset:0, count:1 | N/A | N/A |
| └─StreamAgg_19 | 1.00 | 1 | root | | time:8.26385598s, loops:1 | funcs:min(t0.time_a)->Column#18 | 128 Bytes | N/A |
| └─Limit_39 | 1.00 | 1 | root | | time:8.263848289s, loops:2 | offset:0, count:1 | N/A | N/A |
| └─IndexReader_45 | 1.00 | 1 | root | | time:8.26384652s, loops:1, cop_task: {num: 175, max: 1.955114915s, min: 737.989μs, avg: 603.631575ms, p95: 1.161411687s, max_proc_keys: 480000, p95_proc_keys: 480000, tot_proc: 1m44.809s, tot_wait: 361ms, rpc_num: 175, rpc_time: 1m45.632904647s, copr_cache_hit_ratio: 0.00} | index:Limit_44 | 6.6025390625 KB | N/A |
| └─Limit_44 | 1.00 | 1 | cop[tikv] | | time:0ns, loops:0, tikv_task:{proc max:1.955s, min:0s, p80:784ms, p95:1.118s, iters:175, tasks:175} | offset:0, count:1 | N/A | N/A |
| └─IndexFullScan_31 | 1.00 | 32 | cop[tikv] | table:t0, index:time_a(time_a) | time:0ns, loops:0, tikv_task:{proc max:1.955s, min:0s, p80:784ms, p95:1.118s, iters:175, tasks:175} | keep order:true | N/A | N/A |
+--------------------------------+---------+---------+-----------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------+-----------------+------+
6 rows in set (8.38 sec)
诊断分析
使用算子执行信息进行性能诊断时,我们一般先从上到下看每个算子本身(即去除掉等待子算子数据的时间后)的执行时间,再去寻找对整个查询性能影响最大的算子,以下为算子执行时间的计算方法:
单子算子的算子执行时间
以下是不同类型算子的执行时间计算方法:
1. 类型为 “root” 的算子
可以直接用该算子的执行时间减去其子算子的执行时间,得到该算子本身的处理时间。
2. 类型为 “cop[tikv]” 的算子
执行信息中包含 tikv_task 统计项。可以通过以下公式估算包含等待子算子数据的执行时间:
估算执行时间 = avg × tasks / concurrency
然后,再从该时间中减去子算子的执行时间,得到该算子的实际处理时间。
3. 类型为 “mpp[tiflash]”、“cop[tiflash]” 或 “batchcop[tiflash]” 的算子
执行信息中包含 tiflash_task 统计项。通常可以用 proc max 减去子算子的 proc max ,得到该算子的处理时间。这是因为对于 TiFlash 任务,可以简单理解为同一条查询的所有 TiFlash 任务是同时开始执行的。
注意: 对于 ExchangeSender 算子,其执行时间包含了等待数据被上层 ExchangeReceiver 算子接收的时间,因此往往会大于上层 ExchangeReceiver 读取内存数据的时间。
多子算子的算子执行时间
对于包含多个子算子的复合算子,其 execution info 中通常会详细列出各个子算子的执行信息。例如,在 IndexLookUp 算子的执行信息中,会明确包含 index_task 和 table_task 的执行细节。通过分析这些子算子的执行信息,我们可以精准判断哪个子算子对整体性能的影响更大,从而更有针对性地进行优化。
在这个例子中,我们可以看出 IndexReader_45 是对性能影响最大的关键算子。对比其两次执行信息可以发现, cop task 的数量存在显著差异:在“max”场景下,仅有 1 个 cop task ;而在“min”场景下,却有 175 个 cop task 。同时, proc_keys 的数量也从 32 增加到了 480,000 。
从 “operator info” 列的标记来看,“max”场景中读取顺序为降序( keep order, desc ),即从大到小读取;而“min”场景中则是默认的升序( keep order )。由此可以推测:优化器根据聚合函数的类型,对索引的读取顺序进行了优化——在“max”场景中采用降序读取,而在“min”场景中采用升序读取。这种优化策略的初衷是尽快找到第一条满足条件的数据。
在“min”场景中,最小的 keys 附近恰好存在大量已被删除但尚未回收的 keys。因此,系统在读取过程中不得不扫描大量无用数据,直到最终找到第一条有效数据,这导致了显著的性能开销。
换个日期,查询慢了 160 倍还没跑出来
实际案例
这是另一个客户的实际案例:查询 12 月 20 日 数据的 SQL 语句仅耗时 25 分钟便完成,而查询 12 月 21 日 数据的 SQL 语句却运行了超过 40 小时仍未完成,最终只能手动终止。以下是这两条 SQL 语句及其对应的执行信息:
【12.20日】
explain analyze INSERT INTO t1 (col0, col1)
SELECTstr_to_date('20241219', '%Y%m%d') AS col0,count(1)
FROM t0 WHEREcol0 = str_to_date('20241219', '%Y%m%d')AND col2 = '1';
+-------------------------------------+-----------+-------------+-----------+-------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+
| id | task | estRows | actRows | operator info | execution info | memory | disk |
+-------------------------------------+-----------+-------------+-----------+-------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+
| Insert_1 | root | 0 | 0 | N/A | time:25m21.1s, loops:1, prepare: 25m21.1s, insert:62.2µs, lock_keys: {time:3.28ms, region:1, keys:1, slowest_rpc: {total: 0.003s, region_id: 615664606, store: 214.194.4.93:20160, tikv_wall_time: 230.1µs}, lock_rpc:2.811716ms, rpc_count:1} | 29.2 KB | N/A |
| └─Projection_7 | root | 1 | 1 | col0 -> Column#209, Column#208 | time:25m21.1s, loops:2, Concurrency:OFF | 380 Bytes| N/A |
| └─HashAgg_16 | root | 1 | 1 | funcs:count(Column#215) -> Column#208 | time:25m21.1s, loops:2, partial_worker:{wall_time:25m21.069799539s, concurrency:5, task_num:82364, tot_wait:2h6m36.573780845s, tot_exec:8.745753026s, tot_time:2h6m45.348679761s, max:25m21.069763913s, p95:25m21.069763913s}, final_worker:{wall_time:25m21.069835493s, concurrency:5, task_num:5, tot_wait:2h6m45.348923309s, tot_exec:18.591µs, tot_time:2h6m45.348944905s, max:25m21.069801614s, p95:25m21.069801614s} | 260.2 KB | N/A |
| └─IndexLookUp_17 | root | 1 | 84339969 | N/A | time:25m19.4s, loops:82365, index_task: {total_time: 25m20.7s, fetch_handle: 7m18.7s, build: 23.5ms, wait: 18m2s}, table_task: {total_time: 2h6m24.2s, num: 5813, concurrency: 5}, next: {wait_index: 7.63ms, wait_table_lookup_build: 5.74s, wait_table_lookup_resp: 25m10.7s} | 52.6 MB | N/A |
| ├─IndexRangeScan_13(Build) | cop[tikv] | 59335552.00 | 118921714 | table:t0, index:idx_index0(col0, col3, col4), range:[2024-12-19,2024-12-19], keep order:false, stats:pseudo | time:1m0.5s, loops:116574, cop_task: {num: 3457, max: 359.8ms, min: 1.13ms, avg: 51.7ms, p95: 121.5ms, max_proc_keys: 50144, p95_proc_keys: 50144, tot_proc: 1m54s, tot_wait: 373ms, rpc_num: 3458, rpc_time: 2m58.7s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, backoff{regionMiss: 2ms}, scan_detail: {total_process_keys: 118921714, total_process_keys_size: 14309548264, total_keys: 119003503, get_snapshot_time: 635.1ms, rocksdb: {key_skipped_count: 120441534, block: {cache_hit_count: 212755, read_count: 23658, read_byte: 538.1 MB, read_time: 179.2ms}}} | N/A | N/A |
| └─HashAgg_9(Probe) | cop[tikv] | 1 | 84339969 | funcs:count(1) -> Column#215 | time:1h47m18.5s, loops:90847, cop_task: {num: 91439604, max: 4.05s, min: 450µs, avg: 2.5ms, p95: 9.62ms, max_proc_keys: 9094, p95_proc_keys: 2, tot_proc: 3m46.3s, tot_wait: 1h36m3.1s, rpc_num: 91439649, rpc_time: 61h20m32.2s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, backoff{regionMiss: 86ms}, scan_detail: {total_process_keys: 118921714, total_process_keys_size: 272099421438, total_keys: 353720316, get_snapshot_time: 3h23m51s, rocksdb: {delete_skipped_count: 4, key_skipped_count: 234799057, block: {cache_hit_count: 2970751374, read_count: 15457191, read_byte: 268.8 GB, read_time: 4m11.8s}}} | N/A | N/A |
| └─Selection_15 | cop[tikv] | 59335.55 | 110035144 | eq(t0.col2, "1") | tikv_task:{proc max:321ms, min:0s, avg: 193.5µs, p80:0s, p95:0s, iters:91440577, tasks:91439604} | N/A | N/A |
| └─TableRowIDScan_14 | cop[tikv] | 59335552.00 | 118921714 | table:t0, keep order:false, stats:pseudo | tikv_task:{proc max:321ms, min:0s, avg: 183.3µs, p80:0s, p95:0s, iters:91440577, tasks:91439604} | N/A | N/A |
+------------------------+-----------+------------+--------------------------------------------------+------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+【12.21日】
explain analyze INSERT INTO t1 (col0, col1)
SELECTstr_to_date('20241220', '%Y%m%d') AS col0,count(1)
FROM t0 WHEREcol0 = str_to_date('20241220', '%Y%m%d')AND col2 = '1';+-------------------------------------+-----------+-------------+-----------+-------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+
| id | task | estRows | actRows | operator info | execution info | memory | disk |
+-------------------------------------+-----------+-------------+-----------+-------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+
| Insert_1 | root | 0 | 0 | N/A | time:40h30m50.9s, loops:1 | 0 Bytes | N/A |
| └─Projection_7 | root | 1 | 0 | col0 -> Column#209, Column#208 | time:40h30m50.9s, loops:1, Concurrency:OFF | 8.24 KB | N/A |
| └─HashAgg_16 | root | 1 | 0 | funcs:count(Column#215) -> Column#208 | time:40h30m50.9s, loops:1, partial_worker:{wall_time:40h30m50.867278633s, concurrency:5, task_num:141733, tot_wait:202h33m46.814913611s, tot_exec:27.470849055s, tot_time:202h34m14.336192096s, max:40h30m50.867251785s, p95:40h30m50.867251785s}, final_worker:{wall_time:40h30m50.867835193s, concurrency:5, task_num:5, tot_wait:202h34m14.336323864s, tot_exec:587.154µs, tot_time:202h34m14.336916359s, max:40h30m50.867823183s, p95:40h30m50.867823183s} | 253.9 KB | N/A |
| └─IndexLookUp_17 | root | 1 | 145134747 | N/A | time:40h30m44.5s, loops:141734, index_task: {total_time: 40h30m50.8s, fetch_handle: 1h26m6.1s, build: 53.4ms, wait: 39h4m44.7s}, table_task: {total_time: 202h30m18s, num: 10576, concurrency: 5}, next: {wait_index: 38.7ms, wait_table_lookup_build: 16m5.5s, wait_table_lookup_resp: 35h58m38.1s} | 54.1 MB | N/A |
| ├─IndexRangeScan_13(Build) | cop[tikv] | 59418221.51 | 216452387 | table:t0, index:idx_index0(col0, col3, col4), range:[2024-12-20,2024-12-20], keep order:false, stats:pseudo | time:1h10m20.7s, loops:212130, cop_task: {num: 6031, max: 4.3s, min: 1.25ms, avg: 68.2ms, p95: 157.5ms, max_proc_keys: 50144, p95_proc_keys: 50144, tot_proc: 4m2.6s, tot_wait: 1.72s, rpc_num: 6032, rpc_time: 6m51.3s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, backoff{regionMiss: 4.01s}, tikv_task:{proc max:240ms, min:0s, avg: 35ms, p80:52ms, p95:60ms, iters:235427, tasks:6031}, scan_detail: {total_process_keys: 216452387, total_process_keys_size: 26106920846, total_keys: 216513446, get_snapshot_time: 1.82s, rocksdb: {key_skipped_count: 217250001, block: {cache_hit_count: 85194, read_count: 336650, read_byte: 5.71 GB, read_time: 2.59s}}} | N/A | N/A |
| └─HashAgg_9(Probe) | cop[tikv] | 1 | 145183684 | funcs:count(1) -> Column#215 | time:200h6m9.4s, loops:157469, cop_task: {num: 152652462, max: 5.48s, min: 428.9µs, avg: 3.46ms, p95: 9.78ms, max_proc_keys: 9041, p95_proc_keys: 3, tot_proc: 3h59m54.1s, tot_wait: 9h5m23.6s, rpc_num: 152657420, rpc_time: 138h15m0.2s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 15}, backoff{regionMiss: 5.94s}, tikv_task:{proc max:468ms, min:0s, avg: 494.8µs, p80:0s, p95:4ms, iters:152653501, tasks:152652462}, scan_detail: {total_process_keys: 216364520, total_process_keys_size: 340485612010, total_keys: 490792535, get_snapshot_time: 12h12m26.1s, rocksdb: {delete_skipped_count: 1944, key_skipped_count: 274430096, block: {cache_hit_count: 5855418083, read_count: 285117868, read_byte: 4977.3 GB, read_time: 4h18m23.9s}}} | N/A | N/A |
| └─Selection_15 | cop[tikv] | 59418.22 | 207051411 | eq(t0.col2, "1") | tikv_task:{proc max:1.3s, min:0s, avg: 489.8µs, p80:0s, p95:4ms, iters:152653501, tasks:152652462} | N/A | N/A |
| └─TableRowIDScan_14 | cop[tikv] | 59418221.51 | 232766720 | table:t0, keep order:false, stats:pseudo | tikv_task:{proc max:1.3s, min:0s, avg: 478.8µs, p80:0s, p95:4ms, iters:152653501, tasks:152652462} | N/A | N/A |
+------------------------+-----------+------------+--------------------------------------------------+------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------+------+
诊断分析
首先对比两次查询的执行计划,确认执行计划未发生跳变。接着,我们从上至下逐一分析,找出两次查询中主要执行时间差异的来源。可以看到, Insert_1 、 Projection_7 和 HashAgg_16 的执行时间均在秒级,因此可以排除这些算子的嫌疑。
重点聚焦于 IndexLookUp 算子。在 12 月 21 日的查询中, index_task 的总耗时为 40 小时,但实际获取 rowid 的时间仅为 1 个多小时,其余时间主要消耗在等待 table_task 读取表数据上,具体为 wait :39h4m44.7s。
进一步查看 table_task 的执行细节,以下两个信息值得关注: total_time :202h30m18s 和 concurrency :5。计算可得,平均每个并发任务的耗时为 202h / 5 = 40.4h ,与 IndexLookUp 的 总耗时基本一致。因此,基本可以确定问题出在 table_task 上,即对应的 HashAgg_9 算子。
在 HashAgg_9 算子的 execution info 中,主要包含以下关键信息:
- time: 200h6m9.4s, loops: 157469
:该算子的任务类型为“cop[tikv]”,表明其实际在TiKV上执行。这里的执行时间反映了 TiDB 等待和读取 Coprocessor 任务返回数据的总耗时。需要注意的是,这个时间并不是实际的walltime,而是多个并发任务的执行时间累加而成。由于 table_task 的并发度为5,因此实际算子的walltime大约为200h / 5 = 40h,与总耗时一致。从 TiDB 9.0 版本开始,我们将这种并发执行时间的统计项名称改为to tal_t ime,以便与真正的walltime区分开来。 - cop_task
: 此部分信息描述了向 TiKV 发送cop task的执行情况。其中,rpc_time和distsql_concurrency是两个关键指标:- rpc_time
是 TiDB 端记录的从发送cop task到接收结果的总耗时。 - distsql_concurrency
是单个table_task发送cop_task的并发度。由于table_task的并发度为5,因此整体的cop task并发度为5 × 15 = 75。
- rpc_time
根据这两个指标,我们可以推算出 cop task 的实际 walltime 大约为 138h / 75 ≈ 1.8h,与整体的 40h 相比,占比并不高。
- backoff
:这部分描述了 cop task 发送失败时重试的时间。 - tikv_task
:这部分是描述的 HashAgg_9 这个算子在 TiKV 上的执行信息,实际时间并不多。 - sc an_detail
:描述了 TiKV 从 RocksDB 读取数据的信息统计,由于 tikv_task 推算出算子总执行时间并不长,所以这部分信息不影响总体性能。
综合上述信息可以发现, HashAgg_9 的总执行时间并非主要消耗在 cop task 的执行上,而更可能是花费在从 cop task response 中读取数据的过程中。结合 CPU profiling 的结果,可以看到 Go runtime 的 GC(垃圾回收)占用了大约 80% 的 CPU 时间。

进一步观察 heap profiling 的结果,可以最终确认问题根源是 issue44047 ( https://github.com/pingcap/tidb/issues/44047 ):此前,TiDB 为了精确统计 cop task 的 p90 等指标,会缓存所有 cop task 的执行信息。当 cop task 数量极为庞大时,这会导致 TiDB 内存紧张,进而频繁触发 Go 的 GC(垃圾回收),最终引发性能异常。该问题已经在 TiDB 6.5 版本中修复。

未来展望
在 TiDB 9.0 版本中,我们将进一步丰富算子执行信息,提升系统的可观测性,具体改进包括:
1. 算子执行时间的细化
在 9.0 版本中,TiDB 算子的执行信息新增了 open 和 close 时间。此前,执行信息中的 time 并未涵盖算子初始化和结束执行的时间,这可能导致执行时间显著低于实际耗时(如 issue50377 ( https://github.com/pingcap/tidb/issues/50377 ) 和 issue55957 ( https://github.com/pingcap/tidb/issues/55957 ))。在 9.0 版本中, ti me 被修正为从进入算子到离开算子的完整 wall time ,包括所有子算子的执行时间。其中:
- open :表示算子初始化所需的时间。
- close :表示从算子处理完所有数据到完全结束的时间。
- time 包含了 open 和 close 的时间。
2. 并发执行时间的区分
当算子存在多并发执行时,此前的 execution info 中显示的是并发任务的 wall time 累加值,这可能导致子算子的执行时间大于父算子的执行时间(如 issue56746 ( https://github.com/pingcap/tidb/issues/56746 )),容易引起混淆。在 9.0 版本中,这些累加的时间信息(如 time 、 open 和 close )将被替换为 total_time 、 total_open 和 total_close ,以更清晰地反映并发执行的真实耗时。
3. TiFlash 执行中的等待时间信息补充
在 TiFlash 的执行信息中,新增了以下等待时间的统计:
- minTSO_wait :记录 MPP Task 等待 TiFlash MinTSO 调度器调度的时间。
- pipeline_breaker_wait :在 TiFlash 的 Pipeline 执行模型中,记录包含 pipeline breaker 算子的 pipeline 等待上游 pipeline 数据的时间。目前主要用于展示包含 Join 算子的 pipeline 等待哈希表构建完成的时间。
- pipeline_queue_wait :在 TiFlash 的 Pipeline 执行模型中,记录 pipeline 在 CPU Task Thread Pool 和 IO Task Thread Pool 中的等待时间。
通过这些改进,TiDB 9.0 版本将为用户提供更全面、更准确的执行信息,帮助更好地诊断和优化查询性能。
相关文章:
TiDB 可观测性解读(二)丨算子执行信息性能诊断案例分享
导读 可观测性已经成为分布式系统成功运行的关键组成部分。如何借助多样、全面的数据,让架构师更简单、高效地定位问题、分析问题、解决问题,已经成为业内的一个技术焦点。本系列文章将深入解读 TiDB 的关键参数,帮助大家更好地观测系统的状…...

15:00开始面试,15:08就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到8月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...

蓝桥杯准备(前缀和差分)
import java.util.Scanner; public class qianzhuihe {public static void main(String[] args) {int N,M;Scanner scnew Scanner(System.in);Nsc.nextInt();Msc.nextInt();int []treesnew int[N1];//设为N1的意义,防止越界int []prefixSumnew int[N1];for(int i1;i…...
)
试用thymeleaf引入vue-element-admin(一)
作为后端程序员,一直使用springbootbootstarp做管理系统,对前端不是太了解,现在感觉bootstarp的admin ui一直不得劲,想切换成前端使用较多的ui,费了老鼻子劲。 我的目的不是前后端分离,而是一个人全栈&…...

Minimind 训练一个自己专属语言模型
发现了一个宝藏项目, 宣传是完全从0开始,仅用3块钱成本 2小时!即可训练出仅为25.8M的超小语言模型MiniMind,最小版本体积是 GPT-3 的 17000,做到最普通的个人GPU也可快速训练 https://github.com/jingyaogong/minimi…...
)
C++11QT复习 (七)
智能指针雏形 **Day7-1 智能指针雏形:独占语义与共享语义****1. 独占语义与共享语义****1.1 Circle 类:示例类** **2. 拷贝构造:独占语义(Unique Ownership)****2.1 代码解析** **3. 拷贝构造:共享语义&…...
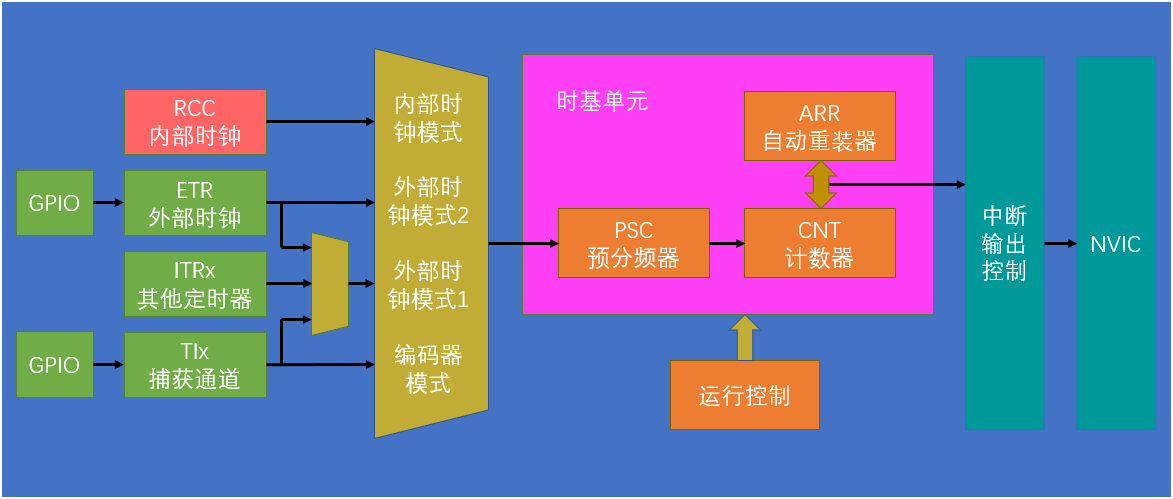
STM32八股【5】----- TIM定时器
1. TIM定时器分类 STM32 的定时器主要分为以下几类: 高级定时器(Advanced TIM,TIM1/TIM8) 具备 PWM 生成、死区控制、互补输出等高级功能,适用于电机控制和功率转换应用。通用定时器(General-purpose TIM…...
)
单元测试之Arrange-Act-Assert(简称AAA)
Arrange-Act-Assert(简称AAA)是一种编写单元测试的标准模式,具有清晰的结构和明确的步骤,有助于提高测试的可读性、可维护性和可扩展性。以下是对每个步骤的详细说明: 1. Arrange(准备阶段) 在…...

厘米级定位赋能智造升级:品铂科技UWB技术驱动工厂全流程自动化与效能跃升”
在智能制造中的核心价值体现在高精度定位、流程优化、安全管理等多个维度,具体应用如下: 一、核心技术与定位能力 厘米级高精度定位 UWB技术通过纳秒级窄脉冲信号(带宽超500MHz)实现高时间分辨率,结合…...
C++刷题(四):vector
📝前言说明: 本专栏主要记录本人的基础算法学习以及刷题记录,使用语言为C。 每道题我会给出LeetCode上的题号(如果有题号),题目,以及最后通过的代码。没有题号的题目大多来自牛客网。对于题目的…...

学习记录706@微信小程序+springboot项目 真机测试 WebSocket错误: {errMsg: Invalid HTTP status.}连接不上
我微信小程序springboot项目 真机测试 websocket 总是报错 WebSocket错误: {errMsg: Invalid HTTP status.},总是连接不上,但是开发者工具测试就没有问题。 最后解决方案是编码token,之前是没有编码直接拼接的,原因不详。 consol…...

【虚拟仪器技术】Labview虚拟仪器技术应用教程习题参考答案[13页]
目录 第1章 第2章 第3章 第4章 第5章 第6章 第7章 第8章 第1章 1. 简述虚拟仪器概念。 参考答案:虚拟仪器是借助于强大的计算机软件和硬件环境的支持,建立虚拟的测试仪器面板,完成仪器的控制、数…...

【工作梳理】怎么把f12里面的东西导入到postman
postman左上角导入 结果:...

UE5学习笔记 FPS游戏制作34 触发器切换关卡
文章目录 搭建关卡制作触发器传送门显示加载界面 搭建关卡 首先搭建两个关卡,每个关卡里至少要有一个角色 制作触发器传送门 1 新建一个蓝图,父类为actor,命名为portal(传送门) 2 为portal添加一个staticMesh&#…...

智谱大模型(ChatGLM3)PyCharm的调试指南
前言 最近在看一本《ChatGLM3大模型本地化部署、应用开发和微调》,本文就是讨论ChatGLM3在本地的初步布设。(模型文件来自魔塔社区) 1、建立Pycharm工程 采用的Python版本为3.11 2、安装对应的包 2.1、安装modelscope包 pip install model…...

新专栏预告 《AI大模型应知应会短平快系列100篇》 - 整体规划设计
做个预告,为系统化梳理AI大模型的发展脉络,并为普及AI素养做一点贡献,特给自己制定了一个小目标,3个月内完成交稿。 AI大模型应知应会短平快系列100篇 - 整体规划设计 一、基础知识模块(20篇) 1.1 大模型…...
SwanLab Slack通知插件:让AI训练状态同步更及时
在AI模型训练的过程中,开发者常常面临一个难题:如何及时跟踪训练状态?无论是实验超参数的调整、关键指标的变化,还是意外中断的告警,传统的监控方式往往依赖手动刷新日志或反复检查终端,这不仅效率低下&…...

收集 的 JavaScript 数组方法表格
这个表格可以作为数组方法的快速参考指南 方法名对应版本功能原数组是否改变返回值类型concat()ES5-合并数组,并返回合并之后的新数组nArrayjoin()ES5-使用分隔符,将数组转为字符串并返回nStringpop()ES5-删除最后一位,并返回删除的数据yAny…...
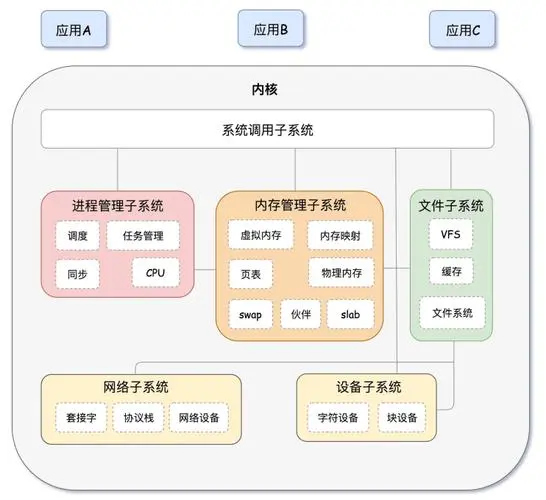
操作系统高频(六)linux内核
操作系统高频(六)linux内核 1.内核态,用户态的区别⭐⭐⭐ 内核态和用户态的区别主要在于权限和安全性。 权限:内核态拥有最高的权限,可以访问和执行所有的系统指令和资源,而用户态的权限相对较低&#x…...

位置编码汇总 # 持续更新
看了那么多还没有讲特别好的,GPT老师讲的不错关于三角函数编码。 一、 手撕transformer常用三角位置编码 GPT说:“低维度的编码(例如,第一个维度)可以捕捉到大的位置差异,而高维度的编码则可以捕捉到小的细…...
详解)
电阻(Resistor)详解
一、电阻的定义与核心作用 电阻是电子电路中用于 限制电流、分压、调节信号电平、消耗功率 的基础被动元件,其阻值(Resistance)单位为欧姆(Ω)。其核心作用可归纳为: 限流保护:防止元器件过电流…...
DaVinci Resolve19.1下载:达芬奇调色中文版+安装步骤
如大家所了解的,DaVinci Resolve中文名为达芬奇,是一款专业视频编辑与调色软件。它最初以调色功能闻名,但经过多年发展,已扩展为一套完整的后期制作解决方案,涵盖了剪辑、视觉特效、动态图形和音频后期制作等多个模块。…...

文件IO 2
补充一些用到前面没提到的方法 isDirectory()方法,检查一个对象是否是文件夹,是true不是false isFile()方法,检测一个对象是否为文件,是true不是false 文件的读写操作实践 上一篇大致讲了文件读写操作的基本操作,下面是实践时…...

【Word】批注一键导出:VBA 宏
📌 VBA 宏代码实现 下面是完整的 VBA 代码,支持: 自动创建新文档,并将当前 Word 文档的所有批注导出。批注格式清晰,包括编号、作者、日期和批注内容。智能检测,如果当前文档没有批注,则提示用…...

《深度洞察:MySQL与Oracle中游标的性能分野》
在数据库管理的复杂领域中,游标作为一种强大的工具,用于对数据进行逐行处理,为许多复杂的数据操作提供了解决方案。然而,当涉及到MySQL和Oracle这两大主流数据库时,游标在性能表现上存在着显著的差异。深入理解这些差异…...
LINUX 1
快照 克隆:关机状态下:长时间备份 uname 操作系统 -a 获取所有信息 绝对路径 相对路径 -a -l 列表形式查看 -h 查看版本 相对路径这个还没太搞懂 LS -L LL 简写 显示当前路径 pwd cd 切换到目录 clear 清屏 reboot 重启操作系统...

高效定位 Go 应用问题:Go 可观测性功能深度解析
作者:古琦 背景 自 2024 年 6 月 26 日,阿里云 ARMS 团队正式推出面向 Go 应用的可观测性监控功能以来,我们与程序语言及编译器团队携手并进,持续深耕技术优化与功能拓展。这一创新性的解决方案旨在为开发者提供更为全面、深入且…...

【Windows】win10系统安装.NET Framework 3.5(包括.NET 2.0和3.0)失败 错误代码:0×80240438
一、.NET3.5(包括.NET 2.0和3.0)安装方式 1.1 联网安装(需要联网,能访问微软,简单,很可能会失败) 1.2 离线安装-救急用(需要操作系统iso镜像文件,复杂,成功几率大) 二、联网安装 通过【控制面板】→【程序】→【程序和功能】→【启用或关闭Windows功能】 下载过程…...

蓝桥杯训练士兵
思路:其实每次就是要比较士兵单独训练的价格之和SUM与S的大小,如果 SUM大,那么就减去所有士兵都要训练的次数的最小值,SUM再更新一下,继续比较。 先对士兵的次数按从小到大的次序排序(很重要)&…...

Java基础-27-多态-多态好处和存在的问题
在面向对象编程(OOP)中,多态是一个非常重要的概念。它能够让我们用统一的方式处理不同类型的对象,提升代码的灵活性和可扩展性。Java 作为一种面向对象的编程语言,充分支持多态,并在实际开发中提供了巨大的…...