C++多线程的性能优化
高效线程池设计与工作窃取算法实现解析
1. 引言
现代多核处理器环境下,线程池技术是提高程序并发性能的重要手段。本文解析一个采用工作窃取(Work Stealing)算法的高效线程池实现,通过详细代码分析和性能测试展示其优势。
2. 线程池核心设计
2.1 类结构概览
class ThreadPool {
public:using Task = std::function<void()>;
private:struct WorkerData {std::deque<Task> task队列;std::mutex queue_mutex;};// 成员变量std::vector<WorkerData> worker_data; // 每个工作线程独立的数据std::vector<std::thread> workers; // 工作线程集合std::atomic<bool> stop; // 停止标志std::atomic<size_t> next_worker{0}; // 用于任务分发的轮询计数器
};
关键设计特点:
每个工作线程维护独立的任务队列(避免全局竞争)
使用无锁原子操作实现任务分发
双端队列(deque)支持高效的任务窃取
2.2 任务提交机制
void submit(Task task) {size_t index = next_worker.fetch_add(1) % worker_data.size();auto& worker = worker_data[index];std::lock_guard<std::mutex> lock(worker.queue_mutex);worker.task_queue.push_back(std::move(task));
}
提交策略分析:
1使用原子计数器实现轮询分发
2 将任务添加到对应线程的队列尾部
3 细粒度锁(每个线程独立锁)减少竞争
2.3 工作线程主循环
void worker_loop(size_t worker_id) {while (!stop.load()) {Task task = get_local_task(my_data); // 优先处理本地任务if (!task) {task = steal_remote_task(worker_id, gen); // 尝试窃取}if (task) task();else std::this_thread::yield();}
}
工作流程:
1 优先执行本地队列任务(LIFO)
2 本地无任务时随机窃取其他线程任务
3 无任务时主动让出CPU
3. 工作窃取算法实现
3.1 本地任务获取
Task get_local_task(WorkerData& data) {std::lock_guard<std::mutex> lock(data.queue_mutex);if (!data.task_queue.empty()) {Task task = std::move(data.task_queue.front()); // 从头部取data.task_queue.pop_front();return task;}return nullptr;
}
特点:
本地操作使用队列前端(FIFO)
保持任务执行顺序性
3.2 远程任务窃取
Task get_local_task(WorkerData& data) {std::lock_guard<std::mutex> lock(data.queue_mutex);if (!data.task_queue.empty()) {Task task = std::move(data.task_queue.front()); // 从头部取data.task_queue.pop_front();return task;}return nullptr;
}
关键设计:
随机选择窃取目标(避免热点)
尝试获取锁(非阻塞)
从目标队列尾部窃取(减少与本地线程竞争)
使用双端队列实现高效的头/尾操作
4. 性能测试分析
4.1 吞吐量测试
void performance_test() {constexpr int NUM_TASKS = 100000;constexpr int NUM_THREADS = 8;//...
}
典型输出结果:
void performance_test() {constexpr int NUM_TASKS = 100000;constexpr int NUM_THREADS = 8;//...
}
测试结论:
平均每个任务处理时间 ≈ 12.56μs
线程利用率接近线性扩展
4.2 工作窃取效果验证
典型输出:
Task distribution:
Thread 0 processed 2532 tasks
Thread 1 processed 2489 tasks
Thread 2 processed 2496 tasks
Thread 3 processed 2483 tasks
验证结果:
尽管所有任务初始提交到线程0
工作窃取使任务均匀分布到所有线程
负载均衡效果显著
5. 关键优化技术
本地化优先:线程优先处理本地任务,减少同步开销
随机化窃取:避免多个线程争抢同一个目标队列
双端队列:
本地线程从头部取(FIFO)
窃取线程从尾部取(减少锁竞争)
细粒度锁:每个队列独立锁,而非全局锁
6. 适用场景分析
优势场景:
大量短期任务(μs级)
任务负载不均衡
CPU密集型与IO密集型混合
不适用场景:
任务间强依赖性
需要严格顺序执行
超长时任务(可能导致工作窃取失效)
7. 扩展优化方向
动态线程数量调整
任务优先级支持
批量任务提交
窃取失败时的自适应等待策略
8. 结论
本文实现的线程池通过工作窃取算法有效解决了传统线程池的负载不均问题。测试表明,该设计在保持低延迟的同时,能实现良好的负载均衡,特别适合现代多核处理器环境下的高并发场景。
完整代码
#include <vector>
#include <deque>
#include <thread>
#include <mutex>
#include <atomic>
#include <functional>
#include <random>
#include <algorithm>
#include <iostream>
#include <chrono>class ThreadPool {
public:using Task = std::function<void()>;explicit ThreadPool(size_t num_threads) : stop(false), worker_data(num_threads) {for (size_t i = 0; i < num_threads; ++i) {workers.emplace_back([this, i] { worker_loop(i); });}}~ThreadPool() {stop.store(true);for (auto& t : workers) t.join();}void submit(Task task) {// 轮询选择工作线程size_t index = next_worker.fetch_add(1) % worker_data.size();auto& worker = worker_data[index];std::lock_guard<std::mutex> lock(worker.queue_mutex);worker.task_queue.push_back(std::move(task));}private:struct WorkerData {std::deque<Task> task_queue;std::mutex queue_mutex;};std::vector<WorkerData> worker_data;std::vector<std::thread> workers;std::atomic<bool> stop;std::atomic<size_t> next_worker{0};void worker_loop(size_t worker_id) {WorkerData& my_data = worker_data[worker_id];std::random_device rd;std::mt19937 gen(rd());while (!stop.load()) {Task task = get_local_task(my_data);if (!task) {task = steal_remote_task(worker_id, gen);}if (task) {task();} else {std::this_thread::yield();}}}Task get_local_task(WorkerData& data) {std::lock_guard<std::mutex> lock(data.queue_mutex);if (!data.task_queue.empty()) {Task task = std::move(data.task_queue.front());data.task_queue.pop_front();return task;}return nullptr;}Task steal_remote_task(size_t worker_id, std::mt19937& gen) {std::uniform_int_distribution<size_t> dist(0, worker_data.size()-1);size_t start = dist(gen);for (size_t i = 0; i < worker_data.size(); ++i) {size_t idx = (start + i) % worker_data.size();if (idx == worker_id) continue;auto& target = worker_data[idx];std::unique_lock<std::mutex> lock(target.queue_mutex, std::try_to_lock);if (lock.owns_lock() && !target.task_queue.empty()) {Task task = std::move(target.task_queue.back());target.task_queue.pop_back();return task;}}return nullptr;}
};// 测试方案
void performance_test() {constexpr int NUM_TASKS = 100000;constexpr int NUM_THREADS = 8;ThreadPool pool(NUM_THREADS);std::atomic<int> counter{0};auto start = std::chrono::high_resolution_clock::now();// 提交任务for (int i = 0; i < NUM_TASKS; ++i) {pool.submit([&] {// 模拟IO密集型任务std::this_thread::sleep_for(std::chrono::microseconds(10));counter.fetch_add(1);});}// 等待任务完成while (counter.load() < NUM_TASKS) {std::this_thread::sleep_for(std::chrono::milliseconds(1));}auto end = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);std::cout << "Processed " << NUM_TASKS << " tasks in " << duration.count() << " ms using "<< NUM_THREADS << " threads" << std::endl;
}void stealing_effect_test() {constexpr int NUM_TASKS = 10000;constexpr int NUM_THREADS = 4;ThreadPool pool(NUM_THREADS);std::mutex cout_mutex;std::vector<int> task_counts(NUM_THREADS, 0);// 将所有任务提交到第一个工作线程for (int i = 0; i < NUM_TASKS; ++i) {pool.submit([&, i] {std::this_thread::sleep_for(std::chrono::microseconds(100));{std::lock_guard<std::mutex> lock(cout_mutex);// 记录任务被哪个线程执行static thread_local int executed_by = -1;if (executed_by == -1) {executed_by = std::hash<std::thread::id>{}(std::this_thread::get_id()) % NUM_THREADS;}task_counts[executed_by]++;}});}// 等待任务完成std::this_thread::sleep_for(std::chrono::seconds(2));std::cout << "\nTask distribution:\n";for (int i = 0; i < NUM_THREADS; ++i) {std::cout << "Thread " << i << " processed " << task_counts[i] << " tasks\n";}
}int main() {performance_test();stealing_effect_test();return 0;
}相关文章:

C++多线程的性能优化
高效线程池设计与工作窃取算法实现解析 1. 引言 现代多核处理器环境下,线程池技术是提高程序并发性能的重要手段。本文解析一个采用工作窃取(Work Stealing)算法的高效线程池实现,通过详细代码分析和性能测试展示其优势。 2. 线程池核心设计 2.1 类结…...
TS中的类)
【TS学习】(19)TS中的类
在 TypeScript 中,类(Class) 是面向对象编程的核心结构,用于封装数据和行为。TypeScript 的类继承了 JavaScript 的类特性,并增加了类型系统和高级功能的支持(如访问修饰符、存取器和装饰器)。 …...

UI设计系统:如何构建一套高效的设计规范?
UI设计系统:如何构建一套高效的设计规范? 1. 色彩系统的建立与应用 色彩系统是设计系统的基础之一,它不仅影响界面的整体美感,还对用户体验有着深远的影响。首先,设计师需要定义主色调、辅助色和强调色,并…...

深度学习--softmax回归
回归可以用于预测多少的问题,预测房屋出售价格,棒球队可能获胜的的常数或者患者住院的天数。 事实上,我们也对分类问题感兴趣,不是问 多少,而是问哪一个 1 某个电子邮件是否属于垃圾邮件 2 某个用户可能注册还是不注册…...

【计算机网络】记录一次校园网无法上网的解决方法
问题现象 环境:实训室教室内时间:近期突然出现 (推测是学校在施工,部分设备可能出现问题)症状: 连接校园网 SWXY-WIFI 后: 连接速度极慢偶发无 IP 分配(DHCP 失败)即使分…...

Java关于抽象类和抽象方法
引入抽象: 在之前把不同类中的共有成员变量和成员方法提取到父类中叫做继承。然后对于成员方法在不同子类中有不同的内容,对这些方法重新书写叫做重写;不过如果有的子类没有用继承的方法,用别的名字对这个方法命名的话࿰…...
第二十一章:Python-Plotly库实现数据动态可视化
Plotly是一个强大的Python可视化库,支持创建高质量的静态、动态和交互式图表。它特别擅长于绘制三维图形,能够直观地展示复杂的数据关系。本文将介绍如何使用Plotly库实现函数的二维和三维可视化,并提供一些优美的三维函数示例。资源绑定附上…...
(动态规划))
LeetCode 热题 100_打家劫舍(83_198_中等_C++)(动态规划)
LeetCode 热题 100_打家劫舍(83_198) 题目描述:输入输出样例:题解:解题思路:思路一(动态规划(一维dp数组)):思路二(动态规划ÿ…...

C语言复习--assert断言
assert.h 头⽂件定义了宏 assert() ,⽤于在运⾏时确保程序符合指定条件,如果不符合,就报错终止运行。这个宏常常被称为“断⾔”。 assert(p ! NULL); 代码在程序运⾏到这⼀⾏语句时,验证变量 p 是否等于 NULL 。如果确实不等于 NU…...
)
嵌入式软件设计规范框架(MISRA-C 2012增强版)
以下是一份基于MISRA-C的嵌入式软件设计规范(完整技术文档框架),包含编码规范、安全设计原则和工程实践要求: 嵌入式软件设计规范(MISRA-C 2012增强版) 一、编码基础规范 1.1 文件组织 头文件保护 /* 示…...

系统思考反馈
最近交付的都是一些持续性的项目,越来越感觉到,系统思考和第五项修炼不只是简单的一门课程,它们能真正融入到我们的日常工作和业务中,帮助我们用更清晰的思维方式解决复杂问题,推动团队协作,激发创新。 特…...

【C++】vector常用方法总结
📝前言: 在C中string常用方法总结中我们讲述了string的常见用法,vector中许多接口与string类似,作者水平有限,所以这篇文章我们主要通过读vector官方文档的方式来学习vector中一些较为常见的重要用法。 🎬个…...

Burpsuite 伪造 IP
可以用于绕过 IP 封禁检测,用来暴力、绕过配额限制。 也可以用来做 ff98sha 出的校赛题,要求用 129 个 /8 网段的 IP 地址访问同一个 domain 插件 - IPRotate 原理:利用云服务商的反向代理服务。把反向代理的域名指向到目标 ip 即可。 http…...

12.小节
1.认识 QLabel 类,能够在界面上显示字符串. 通过 setText 来设置的.参数 QString (Qt 中把 C 里的很多容器类, 进行了重新封装.历史原因) c叫法容器类,java叫法集合类 2.内存泄露,文件资源泄露 3.对象树。Qt 中通过对象树,来统一的释放界面的…...

大模型专题10 —LangGraph高级教程:构建支持网页搜索+人工干预的可追溯对话系统
在本教程中,我们将使用 LangGraph 构建一个支持聊天机器人,该机器人能够: ✅ 通过搜索网络回答常见问题 ✅ 在多次调用之间保持对话状态 ✅ 将复杂查询路由给人工进行审核 ✅ 使用自定义状态来控制其行为 ✅ 进行回溯并探索替代的对话路径 我们将从一个基础的聊天机器人开…...

2025年数智化电商产业带发展研究报告260+份汇总解读|附PDF下载
原文链接:https://tecdat.cn/?p41286 在数字技术与实体经济深度融合的当下,数智化产业带正成为经济发展的关键引擎。 从云南鲜花产业带的直播热销到深圳3C数码的智能转型,数智化正重塑产业格局。2023年数字经济规模突破53.9万亿元ÿ…...
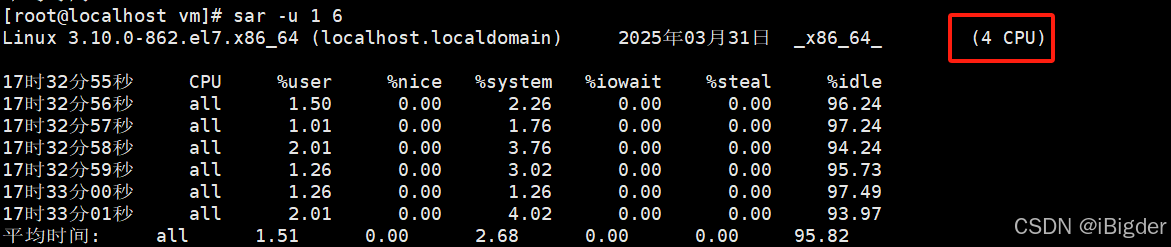
Linux中常用服务器监测命令(性能测试监控服务器实用指令)
1.查看进程 ps -ef|grep 进程名以下指令需要先安装:sysstat,安装指令: yum install sysstat2.查看CPU使用情况(间隔1s打印一个,打印6次) sar -u 1 63.#查看内存使用(间隔1s打印一个,打印6次) sar -r 1 6...

SQL:CASE WHEN使用详解
文章目录 1. 数据转换与映射2. 动态条件筛选3. 多条件分组统计4. 数据排名与分级5. 处理空值与默认值6. 动态排序 CASE WHEN 语句在 SQL 中是一个非常强大且灵活的工具,除了常规的条件判断外,还有很多巧妙的用法,以下为你详细总结:…...

linux内核`fixmap`和`memblock`有什么不同?
Linux内核中的fixmap和memblock是两个不同层次的内存管理机制,分别用于不同的场景和阶段。以下是它们的核心区别和联系: 功能与作用 memblock 物理内存管理: memblock是内核启动早期的物理内存分配器,在伙伴系统(Budd…...

基于 GEE 的区域降水数据可视化:从数据处理到等值线绘制
目录 1 引言 2 代码功能概述 3 代码详细解析 3.1 几何对象处理与地图显示 3.2 加载 CHIRPS 降水数据 3.3 筛选不同时间段的降水数据 3.4 绘制降水时间序列图 3.5 计算并可视化短期和长期降水总量 3.6 绘制降水等值线图 4 总结 5 完整代码 6 运行结果 1 引言 在气象…...
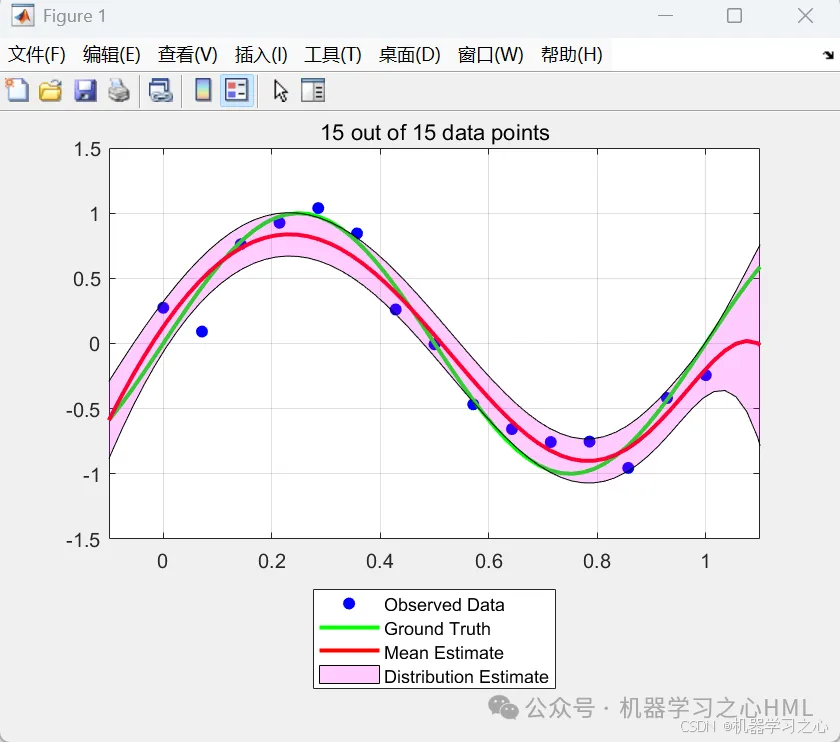
曲线拟合 | Matlab基于贝叶斯多项式的曲线拟合
效果一览 代码功能 代码功能简述 目标:实现贝叶斯多项式曲线拟合,动态展示随着数据点逐步增加,模型后验分布的更新过程。 核心步骤: 数据生成:在区间[0,1]生成带噪声的正弦曲线作为训练数据。 参数设置:…...
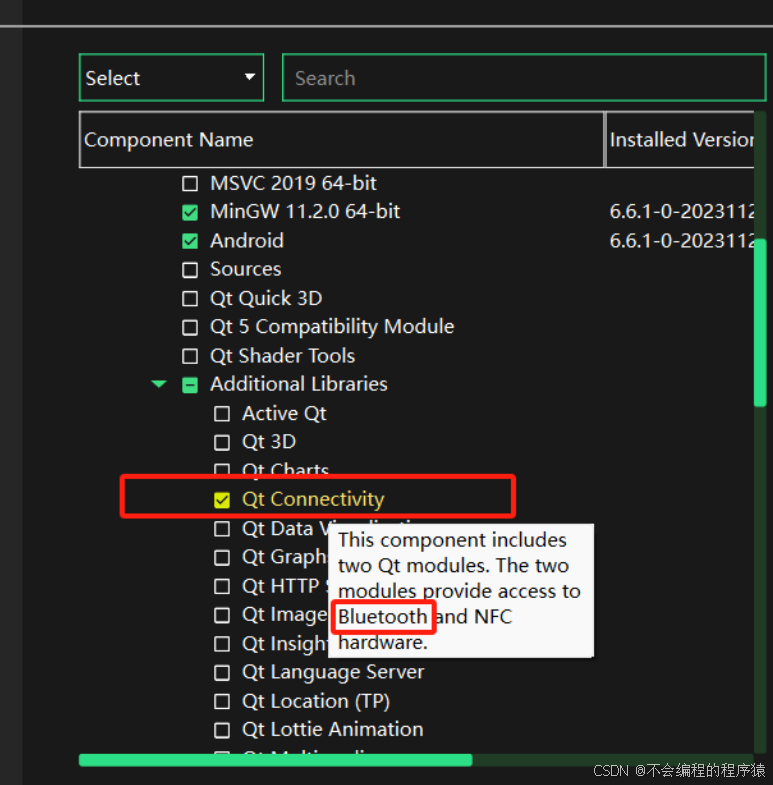
Qt6调试项目找不到Bluetooth Component蓝牙组件
错误如图所示 Failed to find required Qt component "Bluetooth" 解决方法:搜索打开Qt maintenance tool 工具 打开后,找到这个Qt Connectivity,勾选上就能解决该错误...
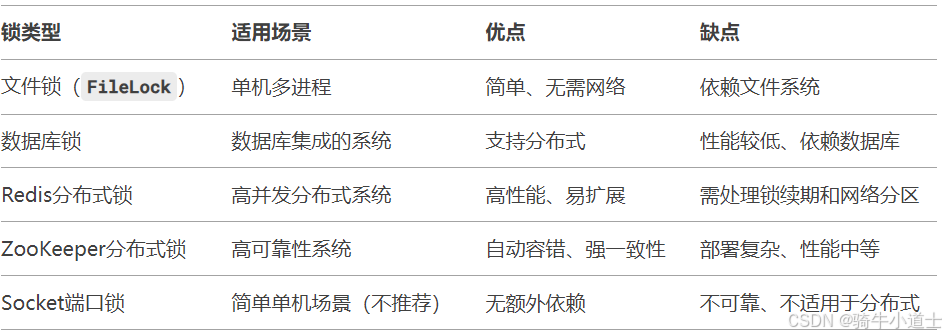
JAVA- 锁机制介绍 进程锁
进程锁 基于文件的锁基于Socket的锁数据库锁分布式锁基于Redis的分布式锁基于ZooKeeper的分布式锁 实际工作中都是集群部署,通过负载均衡多台服务器工作,所以存在多个进程并发执行情况,而在每台服务器中又存在多个线程并发的情况,…...
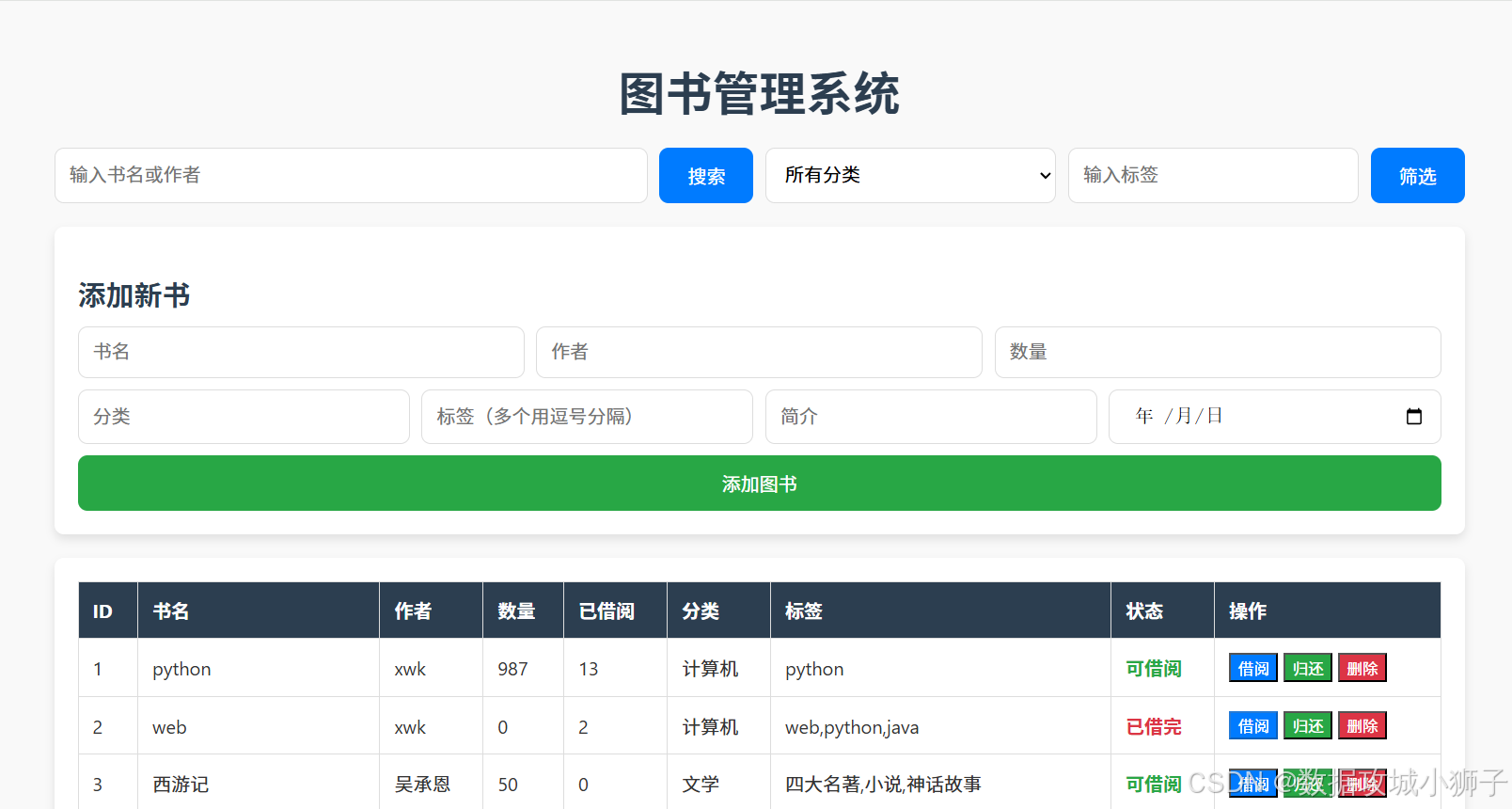
Java Spring Boot 与前端结合打造图书管理系统:技术剖析与实现
目录 运行展示引言系统整体架构后端技术实现后端代码文件前端代码文件1. 项目启动与配置2. 实体类设计3. 控制器设计4. 异常处理 前端技术实现1. 页面布局与样式2. 交互逻辑 系统功能亮点1. 分页功能2. 搜索与筛选功能3. 图书操作功能 总结 运行展示 引言 本文将详细剖析一个基…...

深入剖析JavaScript多态:从原理到高性能实践
摘要 JavaScript多态作为面向对象编程的核心特性,在动态类型系统的支持下展现了独特的实现范式。本文深入解析多态的三大实现路径:参数多态、子类型多态与鸭子类型,详细揭示它们在动态类型系统中的理论基础与实践意义。结合V8引擎的优化机制…...

GalTransl开源程序支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案
一、软件介绍 文末提供程序和源码下载 GalTransl是一套将数个基础功能上的微小创新与对GPT提示工程(Prompt Engineering)的深度利用相结合的Galgame自动化翻译工具,用于制作内嵌式翻译补丁。支持GPT-4/Claude/Deepseek/Sakura等大语言模型的…...
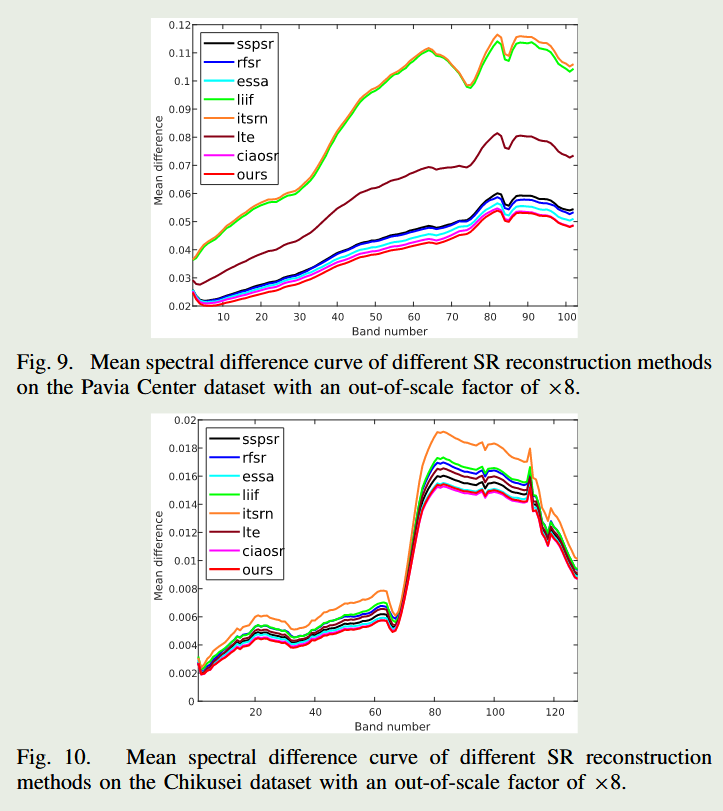
TGES 2024 | 基于空间先验融合的任意尺度高光谱图像超分辨率
Arbitrary-Scale Hyperspectral Image Super-Resolution From a Fusion Perspective With Spatial Priors TGES 2024 10.1109/TGRS.2024.3481041 摘要:高分辨率高光谱图像(HR-HSI)在遥感应用中起着至关重要的作用。单HSI超分辨率ÿ…...

算法基础_基础算法【高精度 + 前缀和 + 差分 + 双指针】
算法基础_基础算法【高精度 前缀和 差分 双指针】 ---------------高精度---------------791.高精度加法题目介绍方法一:代码片段解释片段一: 解题思路分析 792. 高精度减法题目介绍方法一:代码片段解释片段一: 解题思路分析 7…...

多线程猜数问题
题目:线程 A 生成随机数,另外两个线程来猜数,线程 A 可以告诉猜的结果是大还是小,两个线程都猜对后,游戏结束,编写代码完成。 一、Semaphore 多个线程可以同时操作同一信号量,由此实现线程同步…...

Ubuntu环境安装
1. 安装gcc、g和make sudo apt update sudo apt install build-essential 2. 安装cmake ubuntu安装cmake的三种方法(超方便!)-CSDN博客 3. 安装ssh sudo apt-get install libssl-dev...