Elasticsearch 正排索引
一、正排索引基础概念
在 Elasticsearch 中,正排索引用于存储完整的文档内容,以便通过文档ID 快速定位文档的字段值。正排索引通过 Doc Values 和 Store Fields 两种形式,为聚合、排序、脚本计算等场景提供高效支持。Doc Values 的列式存储设计显著优化了分析性能,而 Store Fields 提供了灵活的直接字段访问能力。
与倒排索引的对比:
- 倒排索引:词项 → 文档列表(用于搜索)。
- 正排索引:文档ID → 字段内容(用于聚合、排序、返回原始数据)。
二、正排索引基本结构
Elasticsearch 中的正排索引(正向索引)主要通过两种机制实现:Doc Values 和 Stored Fields。以下面两个文档为例:
- 文档内容
- 文档id为 1:
{"title": "Elasticsearch Guide","author": "John Doe","year": 2023,"tags": ["search", "database"] } - 文档id为 2:
{"title": "Introduction to Elasticsearch","author": "Jane Smith","year": 2022,"tags": ["tutorial", "search"] }
- 文档id为 1:
-
Doc Values 结构(列式存储)
Doc Values 是 Elasticsearch 默认的正排索引实现方式,采用列式存储结构。-
设计目标:支持高效的列式存储(Column-oriented),用于聚合(Aggregations)、排序(Sorting)、脚本计算等。
-
核心特点:
- 列式存储:按字段垂直存储,而非按文档水平存储。
- 默认启用:所有不支持text类型的字段默认开启。
- 磁盘存储:存储在磁盘,但会被OS缓存到文件系统缓存。
-
适用场景:
- 数值、日期、关键字(Keyword)等非文本字段。
- 默认启用(可通过 mapping 的 doc_values: false 关闭)。
-
存储结构:
- 每个字段单独存储为一列,所有文档的该字段值按DocID顺序排列。
- 列式存储优势:
- 高效聚合:列式存储适合聚合计算。
- 内存友好:可以只加载需要的列。
- 压缩存储:使用多种压缩技术减少空间占用。
- 缓存友好:CPU缓存命中率高。
文档 ID(DocID) 字段名 1 value1 2 value2 以year字段为例,Doc Values 结构如下:
文档 ID(DocID) year 1 2023 2 2022
-
-
Stored Fields 结构(行式存储)
Stored Fields 存储原始文档的完整字段值,用于_source和显式标记为store的字段。-
设计目标:存储字段的原始值(如文本内容),用于直接返回特定字段(而非整个 _source)。
-
核心特点:
- 行式存储:按文档存储完整数据。
- 按需启用:需要通过"store": true显式配置。
- 原始格式:保留字段原始值。
-
适用场景:
- 需要频繁返回少量字段(避免解析整个 _source)。
- 默认不启用(需在 mapping 中显式设置 “store”: true)。
-
存储结构:
- 按字段存储原始值,类似传统数据库的行存储。
- 通过 stored_fields 参数指定需要返回的字段。
文档 ID(DocID) 字段名 字段值 1 title “Elasticsearch Guide” 1 author “John Doe” 1 year 2023 1 tags [“search”, “database”] 2 title “Introduction to Elasticsearch” 2 author “Jane Smith” 2 year 2022 2 tags [“tutorial”, “search”]
-
-
正排索引的 JSON 表示
{"documents": [{"doc_id": 1,"fields": {"title": "Elasticsearch Guide","author": "John Doe","year": 2023,"tags": ["search", "database"]}},{"doc_id": 2,"fields": {"title": "Introduction to Elasticsearch","author": "Jane Smith","year": 2022,"tags": ["tutorial", "search"]}}],"doc_values": {"year": [{"doc_id": 1, "value": 2023},{"doc_id": 2, "value": 2022}],"tags": [{"doc_id": 1, "value": "search"},{"doc_id": 1, "value": "database"},{"doc_id": 2, "value": "tutorial"},{"doc_id": 2, "value": "search"}]} }
三、正排索引的构建过程
Elasticsearch 的正排索引主要通过 Doc Values 和 Stored Fields 两种机制实现,它们的构建过程有所不同。以下是完整的构建流程:
-
Doc Values 构建过程
- 阶段一:内存缓冲
- 文档解析:
- 根据字段映射定义解析文档各字段值。
- 对非text类型字段自动准备构建Doc Values。
- 内存缓冲区:
// 伪数据结构示例 Map<FieldName, List<DocValueEntry>> buffer = {"price": [(doc1, 100), (doc2, 200), ...],"city": [(doc1, "北京"), (doc2, "上海"), ...] }
- 文档解析:
- 阶段二:列式存储转换
- 字典编码:
- 对字符串等离散值创建唯一值字典。
// city字段示例 Dictionary: ["北京", "上海", "广州"]
- 对字符串等离散值创建唯一值字典。
- 值映射:
- 将原始值替换为字典序数。
// 原始值 → 编码值 "北京" → 0 "上海" → 1 "北京" → 0 "广州" → 2
- 将原始值替换为字典序数。
- 列式存储:
- 按字段组织数据,与文档分离。
price列: [100, 200, 150, ...] city列: [0, 1, 0, 2, ...] // 使用字典编码后的值
- 按字段组织数据,与文档分离。
- 字典编码:
- 阶段三:磁盘持久化
- 文件生成:
- 生成.dvd(数据值)和.dvm(元数据)文件。
- 使用紧凑的二进制格式。
- 压缩处理:
- 数值类型:增量编码 + 位压缩
- 字符串类型:前缀压缩
- 索引构建:
- 创建字段值到文档的快速访问索引。
- 对排序字段构建B-tree类结构加速范围查询。
- 文件生成:
- 阶段一:内存缓冲
-
Stored Fields 构建过程
- 阶段一:原始文档处理
- 字段筛选:
- 包含_source字段
- 包含显式设置"store": true的字段
- 内存缓冲:
// 伪数据结构示例 List<StoredDocument> buffer = [{doc1, {"title": "ES指南", "content": "..."}},{doc2, {"title": "大数据", "content": "..."}} ]
- 字段筛选:
- 阶段二:文档块组织
- 分块处理:
- 将多个文档打包为一个块(通常4-32KB)
- 块内文档连续存储
- 压缩处理:
- 使用LZ4算法压缩每个块
- 字段级压缩优化
- 分块处理:
- 阶段三:磁盘存储
- 文件生成:
- 生成.fdt(字段数据)和.fdm(字段元数据)文件
- 存储文档原始JSON结构
- 指针构建:
- 创建文档ID到磁盘位置的映射表
// 伪数据结构 Map<DocID, (fileOffset, compressedSize)> = {1 → (0x1000, 1024),2 → (0x1400, 768) }
- 创建文档ID到磁盘位置的映射表
- 文件生成:
- 阶段一:原始文档处理
-
构建过程关键优化
- 内存控制
- 缓冲限制:
- 默认使用JVM堆外内存
- 通过indices.memory.index_buffer_size配置(默认10%)
- 分段策略:
- 内存缓冲满后生成新的段(segment)
- 每个段包含独立的Doc Values
- 缓冲限制:
- 并行构建
- 多线程处理:
- 不同字段的Doc Values并行构建
- 大型字段使用单独线程
- 异步持久化:
- 内存数据异步刷盘
- 通过refresh_interval控制(默认1秒)
- 多线程处理:
- 内存控制
-
构建过程示例
假设索引以下文档:[{"id":1, "title":"ES基础", "price":100, "city":"北京"},{"id":2, "title":"高级教程", "price":200, "city":"上海"} ]- Doc Values构建结果:
price字段:- 列数据: [100, 200]- 字典: 无(数值类型直接存储)city字段:- 字典: ["北京", "上海"]- 列数据: [0, 1] (字典序数) - Stored Fields构建结果:
Segment文件:- 文档1原始JSON + 文档2原始JSON- 压缩存储为连续数据块
- Doc Values构建结果:
四、正排索引的优势
正排索引作为Elasticsearch的关键组成部分,在特定场景下展现出显著优势,与倒排索引形成互补。以下是其主要优势的详细分析:
- 列式存储带来的性能优势
- 高效聚合计算
- 相同字段的值连续存储,减少磁盘I/O
- 直接对整列数据进行统计运算(如sum/avg/max/min)
- 示例:计算1亿条销售记录的总金额,只需顺序读取price列
- 更好的压缩率
- 同列数据相似度高,压缩率可达60-70%
- 支持多种压缩算法:LZ4、DEFLATE等
- 显著减少磁盘占用和内存压力
- CPU缓存友好
- 现代CPU的缓存预取机制能更好预测列式数据访问模式
- 相比行式存储,缓存命中率提升3-5倍
- 高效聚合计算
- 特定操作性能优势
- 排序(Sorting)效率极高
- 直接访问有序存储的列数据
- 避免倒排索引需要"收集-排序"的两阶段操作
- 测试显示比基于fielddata的排序快2-3倍
- 聚合(Aggregation)加速
- terms聚合直接扫描列值
- 基数聚合(cardinality)使用列式统计
- 比传统数据库的GROUP BY快10-100倍
- 脚本访问优化
- 脚本中访问doc values比_source解析快5-10倍
- 示例:
doc['price'].value * params.tax_rate
- 排序(Sorting)效率极高
- 内存与资源管理优势
- 堆外内存管理
- 默认使用文件系统缓存而非JVM堆内存
- 避免GC压力,稳定性提升
- 可通过indices.queries.cache.size控制内存使用
- 按需加载机制
- 仅加载查询涉及的列
- 支持内存映射(mmap)访问方式
- 对比fielddata的全量加载更节省资源
- 冷数据处理能力
- 数据持久化在磁盘,适合不频繁访问的历史数据
- 仍能保持较好性能(约为内存性能的60-70%)
- 堆外内存管理
- 特殊场景优化
- 高基数字段处理
- 全局序数(Global Ordinals)优化
{"mappings": {"properties": {"user_id": {"type": "keyword","eager_global_ordinals": true}}} }
- 全局序数(Global Ordinals)优化
- 地理空间数据
- 地理距离聚合依赖doc values
- 比传统GIS数据库快3-5倍
- 二进制数据
- 支持binary类型的快速读取
- 适合存储加密数据或序列化对象
- 高基数字段处理
五、正排索引的局限性
尽管正排索引(Doc Values)在Elasticsearch中提供了诸多优势,但在实际应用中仍存在一些重要的局限性。
1. 存储开销限制
- 冗余存储
- Doc Values 的默认启用:ES 默认对所有非文本字段(如 keyword、numeric、date)启用 Doc Values,即使某些字段不参与聚合或排序,仍会占用额外存储空间。
- Store Fields 与 _source 的重复:若字段同时开启 store: true,则同一份数据会存储在 _source 和 Store Fields 中,导致存储冗余。
- 示例:
一个 keyword 字段默认生成以下存储结构:- 倒排索引(用于搜索)
- Doc Values(用于聚合)
- _source(原始值)
- 若再设置 store: true,则额外存储一份原始值。
- 优化建议:
- 禁用不必要的 Doc Values:对无需聚合的字段设置 doc_values: false。
- 避免滥用 store: true:优先通过 _source 获取字段,仅在需要快速访问时启用。
- 高基数字段的存储膨胀
- 字典编码的局限性:对于高基数字段(如唯一 ID、哈希值),字典编码的压缩效率大幅下降,导致存储空间显著增加。
- 示例:
一个存储用户唯一 ID 的字段,若存在 1 亿个唯一值:- 字典编码需要维护 1 亿条映射关系。
- 存储空间可能超过原始值的 2 倍。
- 优化建议:
- 对高基数字段禁用 Doc Values,改用倒排索引或其他存储方式。
- 使用 eager_global_ordinals 优化聚合性能(预加载字典映射)。
2. 内存与性能的局限性
-
内存压力
- 文件系统缓存依赖:Doc Values 依赖操作系统的 Page Cache 加载数据,若物理内存不足,频繁的磁盘 IO 会严重降低聚合性能。
- 全局序号(Global Ordinals)的构建开销:高基数字段在聚合时需构建全局序号映射,首次查询延迟较高。
- 示例:
对包含 1 千万唯一值的 product_id 字段执行 terms 聚合:- 首次查询需构建全局序号,耗时可能达数百毫秒。
- 后续查询复用缓存,但内存占用较高。
- 优化建议:
- 增加物理内存,确保文件系统缓存充足。
- 对高频聚合的高基数字段启用 eager_global_ordinals,在段合并时预构建全局序号。
-
写入性能损耗
- 正排索引的构建成本:写入文档时,ES 需同步构建倒排索引和正排索引(Doc Values/Store Fields),增加 CPU 和 IO 开销。
- 实时性与吞吐量的权衡:高频写入场景下,正排索引的构建可能成为瓶颈,限制写入吞吐量。
- 优化建议:
- 对写入性能敏感的场景(如日志采集),关闭非必要字段的 Doc Values。
- 使用更快的存储介质(如 SSD)提升 IOPS。
3. 功能支持的局限性
- 不支持文本字段的 Doc Values
- 文本类型(text)的限制:text 字段默认不支持 Doc Values,因其内容经过分词处理,无法直接用于聚合或排序。
- 优化建议:
- 对需要聚合的文本字段,使用 keyword 类型子字段(Multi-fields):
PUT my_index {"mappings": {"properties": {"message": {"type": "text","fields": {"keyword": { "type": "keyword" // 支持聚合}}}}} }
- 对需要聚合的文本字段,使用 keyword 类型子字段(Multi-fields):
- 不支持动态更新
- 段不可变性:正排索引(Doc Values)随 Lucene 段(Segment)的生成而固化,更新文档需重新构建整个段,无法原地修改。
- 近实时性限制:新写入的数据需通过 refresh 操作生成新段后,其正排索引才可见,默认延迟 1 秒。
- 优化建议:
- 调低 refresh_interval(如设置为 30s)减少段生成频率,平衡实时性与写入性能。
- 对实时性要求高的场景,使用 GET /_doc/{id} 直接访问文档(依赖 _source 而非正排索引)。
4. 查询场景的局限性
- 无法高效支持全文搜索
- 正排索引的定位:正排索引设计用于按文档访问字段值,而非通过词项定位文档。
- 全文搜索依赖倒排索引:若仅依赖正排索引,全文搜索需遍历所有文档,性能极差。
- 对比示例:
- 倒排索引:搜索 “error” 直接定位倒排列表,复杂度 O(1)。
- 正排索引:需遍历所有文档的 message 字段,复杂度 O(N)。
- 范围查询的局限性
- 非数值字段的低效性:对非数值字段(如 keyword)执行范围查询(如 “a” TO “z”),需遍历字典映射,性能较差。
- 优化建议:
- 对需要范围查询的字符串字段,使用 text 类型分词后结合倒排索引。
- 对数值或日期字段,优先使用 Doc Values 的范围查询优化。
六、正排索引的用途
Elasticsearch 的正排索引(Forward Index)主要用于支持高效的字段值访问和分析操作,与倒排索引(Inverted Index)形成互补,共同满足搜索、聚合、排序等复杂场景的需求。以下是正排索引的核心用途及其实际应用场景的详细说明:
-
聚合(Aggregations)
- 用途说明:正排索引通过 列式存储(Doc Values) 高效支持聚合操作,如统计字段分布、计算平均值/总和等。
- 优势:列式数据连续存储,便于批量遍历,压缩率高,减少磁盘 I/O。
- 示例:
GET sales/_search {"aggs": {"total_sales": { "sum": { "field": "amount" } },"category_distribution": { "terms": { "field": "product_category.keyword" } }} }- amount 字段的 Doc Values 直接遍历所有值求和。
- product_category.keyword 的 Doc Values 统计每个类别的文档数。
-
排序(Sorting)
- 用途说明:通过正排索引快速访问字段值,对搜索结果按指定字段排序。
- 优势:直接读取列式数据,避免解析 _source,性能显著提升。
- 示例:
GET products/_search {"sort": [{ "price": { "order": "desc" } }, // 使用 price 字段的 Doc Values{ "_score": "desc" }] }
-
脚本计算(Scripting)
- 用途说明:在查询脚本中动态访问字段值,支持复杂计算逻辑。
- 优势:通过 doc[‘field’].value 直接读取 Doc Values,延迟低。
- 示例:
GET products/_search {"script_fields": {"discounted_price": {"script": "doc['price'].value * 0.9" // 使用 price 字段的 Doc Values}} }
-
高亮显示(Highlighting)
- 用途说明:快速返回字段原始内容,用于搜索结果的高亮展示。
- 优势:若字段设置为 store: true,可直接从 Store Fields 读取数据,跳过解析 _source 的开销。
- 示例:
GET articles/_search {"query": { "match": { "content": "Elasticsearch" } },"highlight": {"fields": { "content": {} } // 从 Store Fields 或 _source 获取原始内容} }
-
部分字段返回(Stored Fields)
- 用途说明:直接返回指定字段的原始值,无需解析完整 _source。
- 优势:减少网络传输和 JSON 解析开销,提升响应速度。
- 示例:
GET logs/_search {"stored_fields": ["timestamp", "status_code"], // 从 Store Fields 获取"query": { "match_all": {} } }
-
范围查询(Range Queries)
- 用途说明:对数值、日期等字段执行范围查询时,正排索引优化数据访问。
- 优势:列式存储天然有序,支持快速范围过滤。
- 示例:
GET logs/_search {"query": {"range": {"timestamp": {"gte": "2023-01-01","lte": "2023-12-31"}}} }
-
字段值存在性检查(Exists Query)
- 用途说明:快速判断某字段是否存在非空值。
- 优势:直接遍历 Doc Values 检查字段值的非空性。
- 示例:
GET users/_search {"query": {"exists": { "field": "email" } // 检查 email 字段是否有值} }
-
地理空间分析(Geospatial Analytics)
- 用途说明:对地理坐标字段(如 geo_point)进行聚合或距离计算。
- 优势:Doc Values 支持高效的地理数据遍历。
- 示例:
GET locations/_search {"aggs": {"heatmap": {"geohash_grid": { "field": "coordinates", "precision": 5 }}} }
-
多字段组合分析
- 用途说明:在复杂分析场景中,联合使用多个字段的 Doc Values。
- 示例:
GET sales/_search {"aggs": {"sales_by_region": {"terms": { "field": "region.keyword" }, // 使用 region 的 Doc Values"aggs": {"avg_amount": { "avg": { "field": "amount" } } // 使用 amount 的 Doc Values}}} }
-
时序数据分析(Time Series)
- 用途说明:针对时间序列数据(如日志、指标),利用 Doc Values 高效处理时间范围聚合。
- 示例:
GET metrics/_search {"aggs": {"hourly_stats": {"date_histogram": {"field": "timestamp","calendar_interval": "1h"},"aggs": { "avg_value": { "avg": { "field": "value" } } }}} }
七、正排索引的优化策略
Elasticsearch 的正排索引(Forward Index)优化策略需结合存储效率、查询性能、写入速度等多方面因素。以下是系统化的优化方案,涵盖配置调整、数据结构设计及硬件调优:
-
存储优化
- 按需启用 Doc Values
- 禁用非必要字段:对不参与聚合、排序的字段关闭 Doc Values。
PUT my_index/_mapping {"properties": {"log_message": {"type": "text","doc_values": false // 关闭聚合能力,减少存储}} } - 高基数字段特殊处理:唯一ID等字段建议禁用 Doc Values,改用倒排索引。
- 禁用非必要字段:对不参与聚合、排序的字段关闭 Doc Values。
- 避免冗余存储
- 慎用 store: true:仅对高频访问字段(如标题、摘要)启用存储字段。
PUT my_index/_mapping {"properties": {"title": {"type": "text","store": true // 显式存储,用于快速返回}} } - 依赖 _source 作为主存储:默认通过 _source 返回数据,减少冗余。
- 慎用 store: true:仅对高频访问字段(如标题、摘要)启用存储字段。
- 压缩优化
- 数值类型优化:
- 使用最小化数据类型(如 byte 替代 integer)。
- 启用 index_options: docs 减少倒排索引开销(仅记录文档ID)。
- 字符串类型优化:
- 使用 keyword 类型代替 text 进行聚合。
- 对长文本禁用 norms 和 index_options。
- 数值类型优化:
- 按需启用 Doc Values
-
查询性能优化
- 全局序号(Global Ordinals)预热
- 启用 eager_global_ordinals:对高基数字段预加载字典映射,减少首次聚合延迟。
PUT my_index/_mapping {"properties": {"user_id": {"type": "keyword","eager_global_ordinals": true // 预加载字典}} }
- 启用 eager_global_ordinals:对高基数字段预加载字典映射,减少首次聚合延迟。
- 缓存策略
- 聚合结果缓存:对重复查询使用 cache: true。
GET sales/_search {"aggs": {"total_sales": {"sum": { "field": "amount", "missing": 0 }}},"size": 0,"request_cache": true // 启用查询缓存 }
- 聚合结果缓存:对重复查询使用 cache: true。
- 分页优化
- 避免深度分页:使用 search_after 替代 from/size,减少内存占用。
- 聚合分页:对海量数据聚合使用 composite 分桶。
- 全局序号(Global Ordinals)预热
-
写入性能优化
- 降低 Refresh 频率
- 增大 refresh_interval,减少段生成频率:
PUT my_index/_settings {"index.refresh_interval": "30s" // 默认1s,调整为30秒 }
- 增大 refresh_interval,减少段生成频率:
- 批量写入
- 使用 bulk API 批量提交数据,减少 IOPS 压力。
- 控制单批次文档数(建议 5-15MB/批次)。
- 关闭副本写入
- 写入高峰期临时关闭副本,写入完成后再恢复:
PUT my_index/_settings {"index.number_of_replicas": 0 }
- 写入高峰期临时关闭副本,写入完成后再恢复:
- 降低 Refresh 频率
-
数据结构与映射优化
- 字段类型选择
- 数值类型:优先使用 integer、short、byte 等最小化类型。
- 时间类型:使用 date 而非 text 或 keyword。
- 高维数据:地理位置使用 geo_point,IP地址使用 ip 类型。
- 多字段(Multi-fields)设计
- 对文本字段同时支持搜索和聚合:
PUT my_index/_mapping {"properties": {"message": {"type": "text", // 支持全文搜索"fields": {"keyword": { "type": "keyword" // 支持聚合}}}} }
- 对文本字段同时支持搜索和聚合:
- 避免嵌套对象
- 扁平化数据结构,减少 nested 类型使用(因其 Doc Values 效率较低)。
- 字段类型选择
-
硬件与架构优化
- 分片策略
- 控制分片大小:单个分片建议 10-50GB(过小导致段过多,过大影响并行性)。
- 预创建索引:对时序数据按时间滚动(如每日索引),避免分片膨胀。
- 存储介质
- 使用 SSD 提升 IOPS,尤其对高写入场景。
- 确保足够内存,保障文件系统缓存(Page Cache)容量。
- 冷热架构
- 对历史数据迁移至冷节点(使用高压缩率存储),热节点专注实时查询。
- 分片策略
相关文章:

Elasticsearch 正排索引
一、正排索引基础概念 在 Elasticsearch 中,正排索引用于存储完整的文档内容,以便通过文档ID 快速定位文档的字段值。正排索引通过 Doc Values 和 Store Fields 两种形式,为聚合、排序、脚本计算等场景提供高效支持。Doc Values 的列式存储设…...
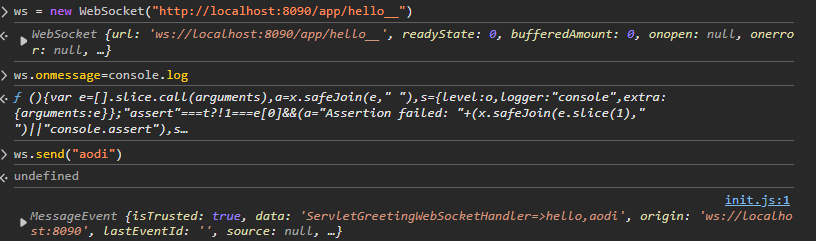
Spring实现WebScoket
SpringWeb编程方式分为Servlet模式和响应式。Servlet模式参考官方文档:Web on Servlet Stack :: Spring Framework,响应式(Reacive)参考官方文档:Web on Reactive Stack :: Spring Framework。 WebSocket也有两种编程方…...

Token是什么?
李升伟 整理 “Token” 是一个多义词,具体含义取决于上下文。以下是几种常见的解释: 1. 计算机科学中的 Token 定义:在编程和计算机科学中,Token 是源代码经过词法分析后生成的最小单位,通常用于编译器和解释器。 …...

odoo-045 ModuleNotFoundError: No module named ‘_sqlite3‘
文章目录 一、问题二、解决思路 一、问题 就是项目启动,本来好好地,忽然有一天报错,不知道什么原因。 背景: 我是在虚拟环境中使用的python3.7。 二、解决思路 虚拟环境和公共环境直接安装 sqlite3 都会报找不到这个库的问题…...

cesium加载CTB生成的地形数据
由于CTB生成的地形数据是压缩的(gzip)格式,需要在nginx加上特殊配置才可以正常加载,NGINX全部配置如下 worker_processes 1; events {worker_connections 1024; } http {include mime.types;default_type application/o…...

前端JS高阶技法:序列化、反序列化与多态融合实战
✨ 摘要 序列化与反序列化作为数据转换的核心能力,与多态这一灵活代码设计的核心理念,在现代前端开发中协同运作,提供了高效的数据通信与扩展性支持。 本文从理论到实践,系统解析: 序列化与反序列化的实现方式、使用…...

TS中的Class
基本用法 implements implements 关键字用于传递对类产生约束的数据类型 interface AnimalInfo{name:stringrace:stringage:number }interface AnimalCls{info:AnimalInfosayName():void} class Animal implements AnimalCls{info:AnimalInfoconstructor(info:AnimalInfo) {t…...
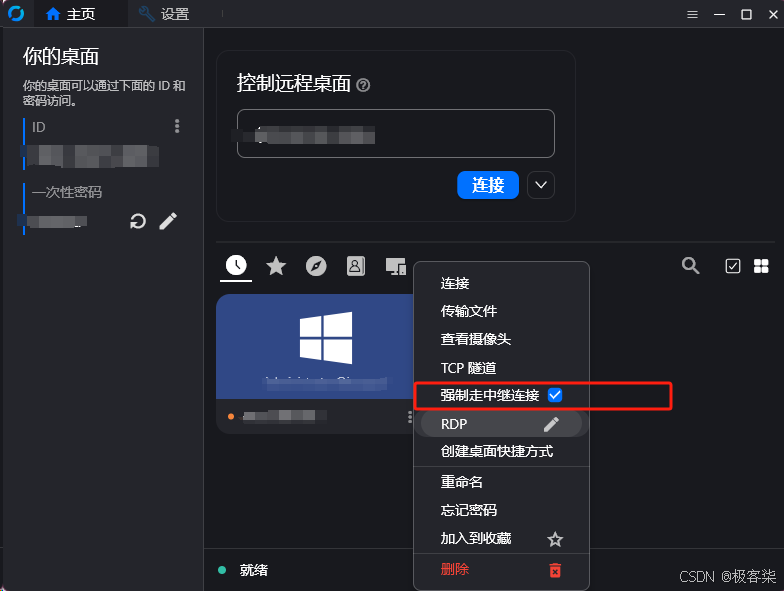
RustDesk 开源远程桌面软件 (支持多端) + 中继服务器伺服器搭建 ( docker版本 ) 安装教程
在需要控制和被控制的电脑上安装软件 github开源仓库地址 https://github.com/rustdesk/rustdesk/releases 蓝奏云盘备份 ( exe ) https://geek7.lanzouw.com/iPf592sadqrc 密码:4esi 中继服务器设置 使用docker安装 sudo docker image pull rustdesk/rustdesk-server sudo…...
)
【计网速通】计算机网络核心知识点与高频考点——数据链路层(二)
数据链路层核心知识点(二) 涵盖局域网、广域网、介质访问控制(MAC层)及数据链路层设备 上文链接:https://blog.csdn.net/weixin_73492487/article/details/146571476 一、局域网(LAN,Loacl Area Network&am…...
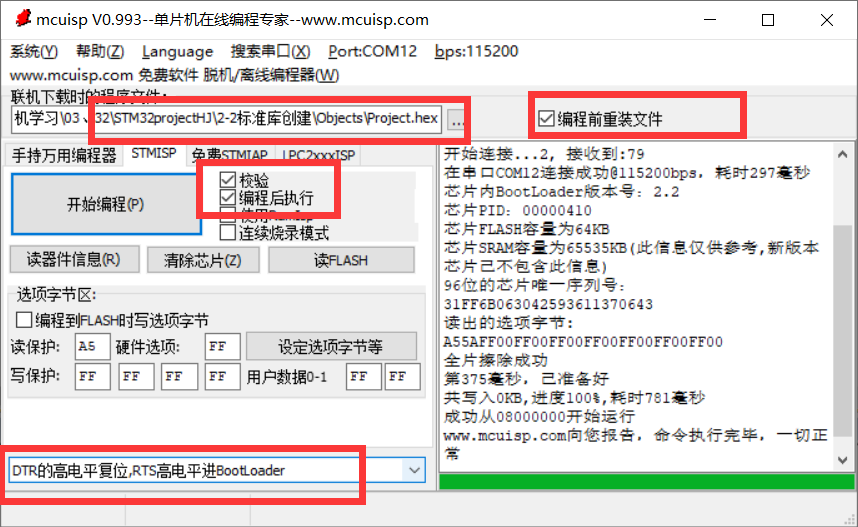
STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.01 STM32开发板学习——第一节: [1-1]课程简介 前言开发板说明引用解答和…...

W3C XML Schema 活动
W3C XML Schema 活动 概述 W3C XML Schema(XML Schema)是万维网联盟(W3C)定义的一种数据描述语言,用于定义XML文档的结构和约束。XML Schema为XML文档提供了一种结构化的方式,确保数据的一致性和有效性。本文将详细介绍W3C XML Schema的活动,包括其发展历程、主要特点…...

爬虫【Scrapy-redis分布式爬虫】
Scrapy-redis分布式爬虫 1.Scrapy-redis实现增量爬虫 增量爬虫的含义 就是前面所说的的暂停、恢复爬取 安装 # 使用scrapy-redis之前最好将scrapy版本保持在2.8.0版本, 因为2.11.0版本有兼容性问题 pip install scrapy==2.8.0 pip install scrapy-redis -i https://pypi.tun…...
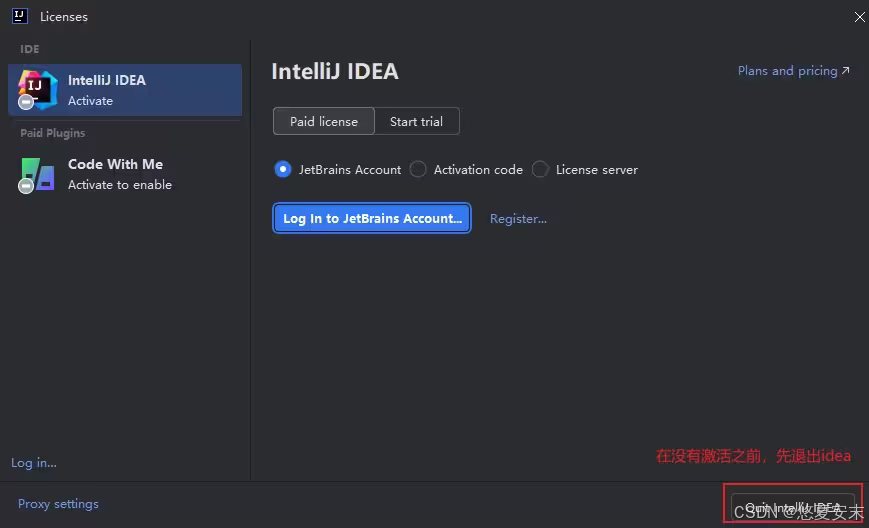
intellij Idea 和 dataGrip下载和安装教程
亲测有效 第一步:卸载老版本idea/Datagrip (没有安装过的可跳过此步骤) 第二步:下载idea/dataGrip安装包 建议选择2022以后的版本 官网: https://www.jetbrains.com/datagrip/download/other.html 选择dataGrip 的…...

轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践
Hi,你好! 轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践 接口特性与适用场景 本接口适用于需要快速集成搜索能力的开发场景,支持通过关键词获取结构化搜索结果。典型应用场景包括: 垂直领域信息检索…...
架构设计基础系列:事件溯源模式浅析
图片来源网络,侵权删 1. 引言 1.1 研究背景 传统CRUD模型的局限性:状态覆盖导致审计困难、无法追溯历史。分布式系统复杂性的提升:微服务架构下数据一致性、回滚与调试的需求激增。监管合规性要求:金融、医疗等领域对数…...

ResNet系列和ViT系列预训练模型权重文件下载
一、简单介绍 OpenAI CLIP项目提供的预训练模型权重文件列表,主要包含两种架构系列和不同规模配置: ResNet系列 (RN) 基础版本:RN50(ResNet-50)扩展版本:RN50x4、RN50x16、RN50x64(宽度扩展&am…...

【力扣hot100题】(035)二叉树的中序遍历
正常方法递归很简单,于是又学了一种栈的方法。 原理如下:每次循环先尽量将目前节点入栈并左移,没有左节点时回到栈首节点将目前节点放入结果容器中并移出栈外,目前节点变为该节点的右节点,循环结束条件是目前节点为nu…...

《数字图像处理》教材寻找合作者
Rafael Gonzalez和Richard Woods所著的《数字图像处理》关于滤波器的部分几乎全错,完全从零开始写,困难重重。关于他的问题已经描述在《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》。 现寻找能够共同讨论、切磋、…...
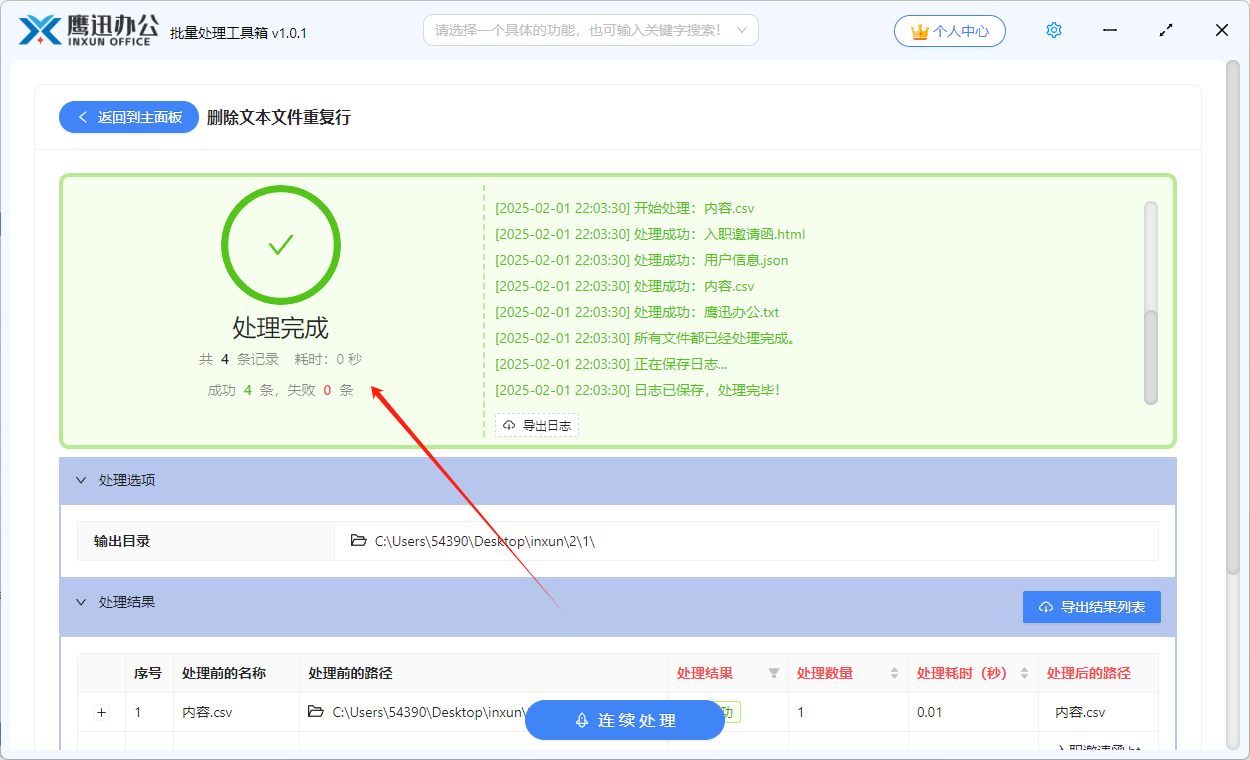
批量删除 txt/html/json/xml/csv 等文本文件中的重复行
在文本文件中,可能会存在一些重复的数据行,这可能不是我们期望的,因此我们会碰到需要删除文本文件中重复行的情况。如果是人工删除,当文件较大或者数量较多的时候,处理的难度会较大。今天就给大家介绍一下批量删除文本…...

LangChain 使用向量数据库介绍与使用
LangChain 是一个用于构建大语言模型(LLM)应用的框架,而向量数据库在 LangChain 中主要用于实现检索增强生成(RAG, Retrieval-Augmented Generation),即通过向量搜索从外部知识库中快速检索相关信息,辅助大模型生成更准确的回答。以下是具体的使用方法: 1. 核心流程 L…...
基于微信小程序的智慧乡村旅游服务平台【附源码】
基于微信小程序的智慧乡村旅游服务平台(源码L文说明文档) 目录 4系统设计 4.1系统功能设计 4.2系统结构 4.3.数据库设计 4.3.1数据库实体 4.3.2数据库设计表 5系统详细实现 5.1 管理员模块的实现 5.1.1旅游景点管理…...

d202542
一、142.环形链表I 142. 环形链表 II - 力扣(LeetCode) 用set统计一下 如果再次出现那么就环的第一个return返回就行 public ListNode detectCycle(ListNode head) {Set<ListNode> set new HashSet<>();ListNode cur head;while(cur ! …...

NodeTextFileCollectorScrapeError 报警原因及解决方法
现象 prometheus 经常有告警 NodeTextFileCollectorScrapeError 查看 node-exporter 日志出现如下报错 time2025-04-01T06:43:18.266Z levelERROR sourcetextfile.go:248 msg"failed to collect textfile data" collectortextfile fileipmitool.prom err"fail…...
(四))
RapidJSON 处理 JSON(高性能 C++ 库)(四)
第四部分:RapidJSON 处理 JSON(高性能 C++ 库) 📢 快速掌握 JSON!文章 + 视频双管齐下 🚀 如果你觉得阅读文章太慢,或者更喜欢 边看边学 的方式,不妨直接观看我录制的 RapidJSON 课程视频!🎬 视频里会用更直观的方式讲解 RapidJSON 的核心概念、实战技巧,并配有…...
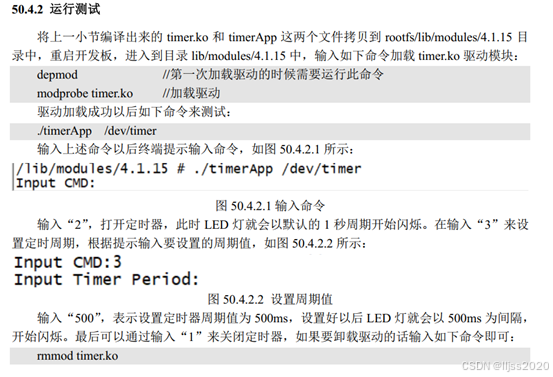
80. Linux内核定时器实验
一、Linux内核定时器原理 1.1、内核时间管理 1、Cortex-M内核使用systick作为系统定时器。 2、硬件定时器、软件定时器,原理是依靠系统定时器来驱动。 3、linux内核频率可以配置,图形化界面配置。 4、重点,HZ表示系统节拍率, 1.…...

Java 可变参数全解析:动态参数传递的实践指南
Java 可变参数全解析:动态参数传递的实践指南 一、可变参数:Java 方法的灵活扩展 在狂神说 Java 第 49 集课程中,我们系统学习了 Java 可变参数的核心原理。作为 Java SE 5 引入的重要特性,可变参数允许方法接受动态数量的输入&…...

C++类与对象(上):从入门到实践
目录 一、引言 二、面向过程和面向对象初步认识 2.1 面向过程编程 2.2 面向对象编程 三、类的引入 四、类的定义 4.1 定义格式 4.2 定义方式 4.3 成员变量命名规则建议 五、类的访问限定符及封装 5.1 访问限定符 5.2 封装 六、类的作用域 七、类的实例化 7.1 概念…...

Lumerical ------ Edge coupler design
Lumerical ------ Edge coupler design 引言正文无 Si Substrate 的仿真步骤有 Si Substrate 的仿真步骤引言 本文,我们将使用官方提供的 Edge coupler 设计教程,但是中间会带有作者本人的设计的感悟。 正文 无 Si Substrate 的仿真步骤 打开 Edge_Coupler_No_Substrate.l…...

大语言模型本质上还是自动化,而不是智能化
大语言模型本质上仍然是自动化或高级自动化,而非真正的智能化,原因可以从以下几个方面进行分析:1、自动化与智能化的本质区别自动化:大语言模型通过预训练和微调,基于大量数据和规则生成输出。它的行为是基于输入数据的…...

cmake 中的命令
命令描述示例capabilities报告 CMake 内置的功能,以 JSON 格式输出cmake -E capabilitiescat连接文件并将其内容打印到标准输出cmake -E cat file1.txt file2.txtchdir在指定目录中运行命令cmake -E chdir /path/to/dir commandcompare_files比较两个文件是否相同cm…...