ray.rllib-入门实践-12-2:在自定义policy中注册使用自定义model(给自定义model新增参数)
建议先看博客 ray.rllib-入门实践-12-1:在自定义policy中注册使用自定义model , 本博客与之区别在于可以给自定义的 model 新增自定义的参数,并通过 config.model["custom_model_config"] 传入自定义的新增参数。
环境配置:
torch==2.5.1
ray==2.10.0
ray[rllib]==2.10.0
ray[tune]==2.10.0
ray[serve]==2.10.0
numpy==1.23.0
python==3.9.18
示例代码:
import numpy as np
import torch.nn as nn
from ray.rllib.models.torch.torch_modelv2 import TorchModelV2
import gymnasium as gym
from gymnasium import spaces
from ray.rllib.utils.typing import Dict, TensorType, List, ModelConfigDict
import ray
from ray.rllib.models import ModelCatalog # ModelCatalog 类: 用于注册 models, 获取env的 preprocessors 和 action distributions。
from ray.rllib.algorithms.ppo import PPOConfig
from ray.tune.logger import pretty_print
from ray.rllib.algorithms.ppo import PPO, PPOConfig, PPOTorchPolicy
from ray.rllib.utils.annotations import override
from ray.rllib.models.modelv2 import ModelV2
import torch
from typing import Dict, List, Type, Union
from ray.rllib.utils.typing import Dict, TensorType, List, ModelConfigDict
from ray.rllib.models.action_dist import ActionDistribution
from ray.rllib.models.modelv2 import ModelV2
from ray.rllib.policy.sample_batch import SampleBatch## 1. 自定义模型 model
class CustomTorchModel(TorchModelV2, nn.Module):def __init__(self, obs_space:gym.spaces.Space, action_space:gym.spaces.Space, num_outputs:int, model_config:ModelConfigDict, ## PPOConfig.training(model = ModelConfigDict), 调用的是config.model中的参数name:str,*,custom_arg1,custom_arg2):TorchModelV2.__init__(self, obs_space, action_space, num_outputs,model_config,name)nn.Module.__init__(self)## 测试 custom_arg1 , custom_arg2 传递进来的是什么数值print(f"=========================== custom_arg1 = {custom_arg1}, custom_arg2 = {custom_arg2}")## 定义网络层obs_dim = int(np.product(obs_space.shape))action_dim = int(np.product(action_space.shape))self.activation = nn.ReLU()## shareNetself.shared_fc = nn.Linear(obs_dim,128)## actorNet# self.actorNet = nn.Linear(128, action_dim)self.actorNet = nn.Linear(128, num_outputs) # 最后一层的输出要设置为 num_outputs,action_dim有时会报错。## criticNetself.criticNet = nn.Linear(128,1)self._feature = None def forward(self, input_dict, state, seq_lens):obs = input_dict["obs"].float()self._feature = self.shared_fc.forward(obs)action_logits = self.actorNet.forward(self._feature)action_logits = self.activation(action_logits)## 测试是否使用了自己的 model print(f"xxxxxxxxxxxxxxxxx 使用了自定义的 model: CustomTorchModel")return action_logits, state def value_function(self):value = self.criticNet.forward(self._feature).squeeze(1)return value ## 2. 自定义策略 policy # 重构 model 和 loss 函数
class MY_PPOTorchPolicy(PPOTorchPolicy):"""PyTorch policy class used with PPO."""def __init__(self, observation_space:gym.spaces.Box, action_space:gym.spaces.Box, config:PPOConfig): PPOTorchPolicy.__init__(self,observation_space,action_space,config)## PPOTorchPolicy 内部对 PPOConfig 格式的config 执行了to_dict()操作,后面可以以 dict 的形式使用 config# 通过修改自定义policy的默认model的方式,使用自定义的model.# 当rllib在使用这个自定义的policy时, 可以默认该 policy 向 ray 注册了这个自定义的 model. def make_model_and_action_dist(self):dist_class,logit_dim = ModelCatalog.get_action_dist(self.action_space,self.config['model'],framework=self.framework)model = CustomTorchModel(obs_space=self.observation_space,action_space=self.action_space,num_outputs=logit_dim,model_config=self.config['model'],name='My_CustomTorchModel',custom_arg1=self.config['model']["custom_model_config"]["custom_arg1"],custom_arg2=self.config['model']["custom_model_config"]["custom_arg2"])return model, dist_class@override(PPOTorchPolicy) def loss(self,model: ModelV2,dist_class: Type[ActionDistribution],train_batch: SampleBatch):## 原始损失original_loss = super().loss(model, dist_class, train_batch) # PPO原来的损失函数, 也可以完全自定义新的loss函数, 但是非常不建议。## 新增自定义损失,这里以正则化损失作为示例addiontial_loss = torch.tensor(0.0) ## 自己定义的lossaddiontial_loss = torch.tensor(0.)for param in model.parameters():addiontial_loss += torch.norm(param)## 得到更新后的损失new_loss = original_loss + 0.01 * addiontial_loss## 测试是否使用了自己的policy print(f"xxxxxxxxxxxxxxxxx 使用了自定义的policy: MY_PPOTorchPolicy")return new_loss## 3. 把自定义的policy封装为算法. 训练和配置的都是算法。
class MY_PPO(PPO):## 重写 PPO.get_default_policy_class 函数, 使其返回自定义的policy def get_default_policy_class(self, config):return MY_PPOTorchPolicyif __name__ == "__main__":## 测试执行自定义的 model and policy ray.init()config = PPOConfig(algo_class = MY_PPO) ## 配置使用自己的算法config = config.environment("CartPole-v1")config = config.rollouts(num_rollout_workers=2)config = config.framework(framework="torch")config.model["custom_model_config"] = {"custom_arg1": 1, "custom_arg2": 2,}algo = config.build()for i in range(3):result = algo.train()print(f"itear_{i}")print("==训练完毕==")以下方式与以上方式等价:
import numpy as np
import torch.nn as nn
from ray.rllib.models.torch.torch_modelv2 import TorchModelV2
import gymnasium as gym
from gymnasium import spaces
from ray.rllib.utils.typing import Dict, TensorType, List, ModelConfigDict
import ray
from ray.rllib.models import ModelCatalog # ModelCatalog 类: 用于注册 models, 获取env的 preprocessors 和 action distributions。
from ray.rllib.algorithms.ppo import PPOConfig
from ray.tune.logger import pretty_print
from ray.rllib.algorithms.ppo import PPO, PPOConfig, PPOTorchPolicy
from ray.rllib.utils.annotations import override
from ray.rllib.models.modelv2 import ModelV2
import torch
from typing import Dict, List, Type, Union
from ray.rllib.utils.typing import Dict, TensorType, List, ModelConfigDict
from ray.rllib.models.action_dist import ActionDistribution
from ray.rllib.models.modelv2 import ModelV2
from ray.rllib.policy.sample_batch import SampleBatch## 1. 自定义模型 model
class CustomTorchModel(TorchModelV2, nn.Module):def __init__(self, obs_space:gym.spaces.Space, action_space:gym.spaces.Space, num_outputs:int, model_config:ModelConfigDict, ## PPOConfig.training(model = ModelConfigDict), 调用的是config.model中的参数name:str,*,custom_arg1,custom_arg2):TorchModelV2.__init__(self, obs_space, action_space, num_outputs,model_config,name)nn.Module.__init__(self)## 测试 custom_arg1 , custom_arg2 传递进来的是什么数值print(f"=========================== custom_arg1 = {custom_arg1}, custom_arg2 = {custom_arg2}")## 定义网络层obs_dim = int(np.product(obs_space.shape))action_dim = int(np.product(action_space.shape))self.activation = nn.ReLU()## shareNetself.shared_fc = nn.Linear(obs_dim,128)## actorNet# self.actorNet = nn.Linear(128, action_dim)self.actorNet = nn.Linear(128, num_outputs) # 最后一层的输出要设置为 num_outputs,action_dim有时会报错。## criticNetself.criticNet = nn.Linear(128,1)self._feature = None def forward(self, input_dict, state, seq_lens):obs = input_dict["obs"].float()self._feature = self.shared_fc.forward(obs)action_logits = self.actorNet.forward(self._feature)action_logits = self.activation(action_logits)## 测试是否使用了自己的 model print(f"xxxxxxxxxxxxxxxxx 使用了自定义的 model: CustomTorchModel")return action_logits, state def value_function(self):value = self.criticNet.forward(self._feature).squeeze(1)return value ## 2. 自定义策略 policy # 重构 model 和 loss 函数
class MY_PPOTorchPolicy(PPOTorchPolicy):"""PyTorch policy class used with PPO."""def __init__(self, observation_space:gym.spaces.Box, action_space:gym.spaces.Box, config:PPOConfig): PPOTorchPolicy.__init__(self,observation_space,action_space,config)## PPOTorchPolicy 内部对 PPOConfig 格式的config 执行了to_dict()操作,后面可以以 dict 的形式使用 config# 通过修改自定义policy的默认model的方式,使用自定义的model.# 当rllib在使用这个自定义的policy时, 可以默认该 policy 向 ray 注册了这个自定义的 model. def make_model_and_action_dist(self):dist_class,logit_dim = ModelCatalog.get_action_dist(self.action_space,self.config['model'],framework=self.framework)model = CustomTorchModel(obs_space=self.observation_space,action_space=self.action_space,num_outputs=logit_dim,model_config=self.config['model'],name='My_CustomTorchModel',custom_arg1=self.config['model']["custom_model_config"]["custom_arg1"],custom_arg2=self.config['model']["custom_model_config"]["custom_arg2"])return model, dist_class@override(PPOTorchPolicy) def loss(self,model: ModelV2,dist_class: Type[ActionDistribution],train_batch: SampleBatch):## 原始损失original_loss = super().loss(model, dist_class, train_batch) # PPO原来的损失函数, 也可以完全自定义新的loss函数, 但是非常不建议。## 新增自定义损失,这里以正则化损失作为示例addiontial_loss = torch.tensor(0.0) ## 自己定义的lossaddiontial_loss = torch.tensor(0.)for param in model.parameters():addiontial_loss += torch.norm(param)## 得到更新后的损失new_loss = original_loss + 0.01 * addiontial_loss## 测试是否使用了自己的policy print(f"xxxxxxxxxxxxxxxxx 使用了自定义的policy: MY_PPOTorchPolicy")return new_loss## 3. 把自定义的policy封装为算法. 训练和配置的都是算法。
class MY_PPO(PPO):## 重写 PPO.get_default_policy_class 函数, 使其返回自定义的policy def get_default_policy_class(self, config):return MY_PPOTorchPolicyif __name__ == "__main__":## 测试执行自定义的 model and policy ray.init()model_config_dict = {}model_config_dict["custom_model_config"] = {"custom_arg1": 1, "custom_arg2": 2,} ## 给 model 传递额外的参数, model 内部通过字符串匹配识别config = PPOConfig(algo_class = MY_PPO) ## 配置使用自己的算法config = config.environment("CartPole-v1")config = config.rollouts(num_rollout_workers=2)config = config.framework(framework="torch")config = config.training(model=model_config_dict) ## wzg notealgo = config.build()for i in range(3):result = algo.train()print(f"itear_{i}")print("==训练完毕==")相关文章:
)
ray.rllib-入门实践-12-2:在自定义policy中注册使用自定义model(给自定义model新增参数)
建议先看博客 ray.rllib-入门实践-12-1:在自定义policy中注册使用自定义model , 本博客与之区别在于可以给自定义的 model 新增自定义的参数,并通过 config.model["custom_model_config"] 传入自定义的新增参数。 环境配置…...

【Java中级】10章、内部类、局部内部类、匿名内部类、成员内部类、静态内部类的基本语法和细节讲解配套例题巩固理解【5】
❤️ 【内部类】干货满满,本章内容有点难理解,需要明白类的实例化,学完本篇文章你会对内部类有个清晰的认知 💕 内容涉及内部类的介绍、局部内部类、匿名内部类(重点)、成员内部类、静态内部类 🌈 跟着B站一位老师学习…...

swift-7-汇编分析闭包本质
一、汇编分析 fn1里面存放的东西 func testClosure2() {class Person {var age: Int 10}typealias Fn (Int) -> Intvar num 0func plus(_ i: Int) -> Int {num ireturn num}return plus} // 返回的plus和num形成了闭包var fn1 getFn()print(fn1(1)) // 1print(fn1(…...

Linux: 进程信号初识
目录 一 前言 二 信号的感性认识 三 信号处理常见方式 四 系统信号列表 五 信号的保存 六 信号的产生 1. 通过终端按键产生信号 2. 通过系统调用向进程发送信号 3. 硬件异常产生信号 4. 软件条件产生信号 一 前言 在Linux操作系统中,进程信号是一个非常重…...

python 项目怎么通过docker打包
python 项目怎么通过docker打包 1. 编写Dockerfile 在Python项目的根目录下创建一个名为 Dockerfile 的文件,其内容示例如下: # 使用Python基础镜像 FROM python:3.9-slim# 设置工作目录 WORKDIR /app# 将当前目录下的所有文件复制到工作目录 COPY . /app# 安装项目依赖 R…...
:数值函数, 字符串函数)
MySQL-- 函数(单行函数):数值函数, 字符串函数
目录 1.数值函数 2. 字符串函数 1.数值函数 ABS:绝对值 ; SIGN:数字正负,正返回1,负返回-1 , 0返回0 ; CEIL,CEILING:取数上面的数 ;FLOOR:取数下面的数 ; MOD:取余 #基本的操作 SELECT ABS(-123),ABS…...

CSS--解决float: right在空间不够时会自动往下移的问题
原文网址:CSS--解决float: right在空间不够时会自动往下移的问题-CSDN博客 简介 众所周知,float: right在空间不够时会自动往下移。那么怎样让它不要往下移呢?本文介绍解决方案。 需求 我想写一个无需列表,每个列表后边跟一个…...

深度学习 Deep Learning 第14章 自编码器
深度学习 Deep Learning 第14章 自编码器 内容概要 本章深入探讨了自编码器(Autoencoders),这是一种用于特征学习和降维的神经网络架构。自编码器通过编码器和解码器两个部分,将输入数据映射到一个内部表示(编码&…...

C++(匿名函数+继承+多态)
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory>using namespace std;// 基类 Weapon class Weapon { protected:int atk; public:Weapon…...

软考中级网络工程师第十一章网络管理
11-1考点分析 11-2网络管理基础(记忆) 网络管理体系结构 网络管理五大功能域:故障管理、配置管理、计费管理、性能管理和安全管理。 助记: “安配能计障” 故障管理:尽快发现故障,找出故障原因&#x…...

创维E900V22C/E900V22D_S905L3(B)_安卓9.0_指示灯正常_线刷固件包
创维E900V22C/E900V22D_S905L3(B)_安卓9.0_指示灯正常_线刷固件包 线刷方法:(新手参考借鉴一下) 1、准备好一根双公头USB线刷刷机线,长度30-50CM长度最佳,同时准备一台电脑; 2、电脑上安装好刷…...

“京数青算“启新篇|北方算网与海东市数据局签署合作协议
近日,青海省海东市2025年“京数青算”推介会在北京召开。海东市委常委、副市长梁荣勃,海东市数据局局长安志忠出席会议,北方算网副总经理(主持工作)喻一鸣等60余家人工智能企业的代表参会。 梁荣勃在致辞中代表海东市…...

QML输入控件: Slider的高级外观定制(音视频控制条)
目录 引言相关阅读示例1:基础样式定制要点效果 示例2:音量控制滑块要点效果 示例3:视频进度条要点效果 解决问题总结工程下载 引言 在现代用户界面设计中,滑块控件(Slider)是一个不可或缺的交互元素。它不仅能让用户直观地进行数…...

密码学基础——古典密码学
目录 一、定义 特点: 二、发展阶段 三、代换密码 1.单表代换密码 1.1恺撒密码 1.2 移位变换 1.3 仿射变换 2.多表代换密码 维吉尼亚密码 四、置换密码 栅栏密码 一、定义 古典密码学是指在现代密码学出现之前,使用较为简单的数学方法和手工…...

KingbaseES物理备份还原之备份还原
此篇续接上一篇<<KingbaseES物理备份还原之物理备份>>,上一篇写物理备份相关操作,此篇写备份还原的具体操作步骤. KingbaseES版本:V009R004C011B003 一.执行最新物理备份还原 --停止数据库服务,并创建物理备份还原测试目录 [V9R4C11B3192-168-198-198 V8]$ sys_ct…...

C++友元与动态内存
一、友元 友元是一种定义在类外部的普通函数或类,但它需要在类体内进行说明,为了与该类的成员函数加以区别,在说明时前面加以关键字friend。友元不是成员函数,但是它可以访问类中的私有成员。 类具有封装和信息隐藏的特性。…...

catch-all路由
介绍 ✅ 什么是 Catch-All 路由? Catch-All 路由 指的是:一个能匹配“任意路径”的通配型路由。 它一般会使用 路径参数 path 类型,比如: app.get("/{full_path:path}") async def fallback_handler(full_path: str):…...
jdk21新特性详解使用总结
jdk21新特性详解总结 1.StringBuilder和StringBuffer新增了一个repeat方法 /*** Java 21的StringBuilder和StringBuffer新增了一个repeat方法*/public static void repeatStr(){var sbnew StringBuilder().repeat("*",10);System.out.println(sb);}运行结果如下&…...

子网划分超AI教程:5分钟教会划分子网
友情提示:本文内容由银河易创AI(https://ai.eaigx.com)创作平台deepseek-v3模型生成,仅供参考 前言 子网划分(Subnetting)是网络工程师和IT运维人员必须掌握的基础技能,但对于初学者来说&#…...

制造业数字化转型:流程改造先行还是系统固化数据?基于以MTO和MTS的投资回报分析
1. 执行摘要 制造业正经历一场深刻的数字化转型,企业面临着先进行流程改造以优化运营,还是直接上线系统以固化数据的战略选择。本文深入分析了以销定产(MTO)和以产定销(MTS)两种主要生产模式下,…...

【实用技巧】电脑重装后的Office下载和设置
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言下载设置总结互动致谢参考目录导航 前言 在数字化办公时代,Windows和…...

使用Android 原生LocationManager获取经纬度
一、常用方案 1、使用LocationManager GPS和网络定位 缺点:个别设备,室内或者地下停车场获取不到gps定位,故需要和网络定位相结合使用 2、使用Google Play服务 这种方案需要Android手机中有安装谷歌服务,然后导入谷歌的第三方库: 例如:i…...

STM32开发板上生成PWM正弦波
在STM32开发板上生成正弦波通常需要结合定时器(TIM)、数模转换器(DAC)或脉宽调制(PWM)以及时钟系统的配置。以下是分步指南: 方法1:使用DAC 定时器(推荐) 步…...

量子计算与人工智能融合的未来趋势
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。 在当今科技飞速发展…...

关于登录鉴权session、cookie和token
一、cookie是用来解决什么问题的? 假如现有业务需求:当浏览器发起一个url请求之后,在一个会话周期内,服务端需要判断这个用户是否第一次发起请求,第一次请求展示的页面跟第N次请求需要响应的页面不同的。现在我们大部分…...
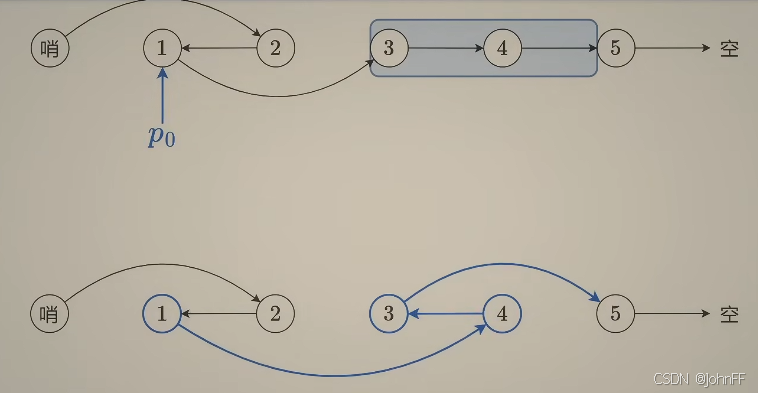
206. 反转链表 92. 反转链表 II 25. K 个一组翻转链表
leetcode Hot 100系列 文章目录 一、翻转链表二、反转链表 II三、K 个一组翻转链表总结 一、翻转链表 建立pre为空,建立cur为head,开始循环:先保存cur的next的值,再将cur的next置为pre,将pre前进到cur的位置…...

实时内核稳定性 - scheduling while atomic
scheduling while atomic问题 根因:未成对使用获取cpu_id的函数[ 291.881071][ 0] [XW]: type=0x00000003 cpuid=4 time=1725877230 subj...

离线语音识别 ( 小语种国家都支持)可定制词组
1产品介绍 离线语音模组采用神经网络算法,支持语音识别、自学习等功能。运用此模组将 AI 技 术赋能产品,升级改造出语音操控的智能硬件 ( 例如风扇、台灯、空调、马桶、按摩椅、运 动相机、行车记录仪等 ) 。支持全球多种语言识别,如中文…...

网络华为HCIA+HCIP 策略路由,双点双向
目录 路由策略,策略路由 策略路由优势 策略路由分类 接口策略路由 双点双向 双点双向路由引入特点: 联系 路由回灌和环路问题 路由策略,策略路由 路由策略:是对路由条目进行控制,通过控制路由条目影响报文的转发路径,即路…...

【面试篇】JVM
文章目录 一、JVM 内存结构1. 请详细描述 JVM 的内存结构,各个区域的作用是什么?2. 堆内存是如何划分的?新生代和老年代的比例是多少?3. Eden 区和 Survivor 区的作用是什么?它们之间是如何协作的?4. 方法区…...