C++STL——容器-vector(含部分模拟实现,即地层实现原理)(含迭代器失效问题)
目录
容器——vector
1.构造
模拟实现
2.迭代器
模拟实现:
编辑
3.容量
模拟实现:
4.元素的访问
模拟实现
5.元素的增删查改
迭代器失效问题:
思考问题
【注】:这里的模拟实现所写的参数以及返回值,都是按照库里的来实现的。
大家都知道,万事开头难,但只要将开头做好,后面的就轻松多了。学习容器也是一样的,只要将第一个容器string学明白,底层实现了然于胸之后,再学习后面的容器之后,你会发现,换汤不换药,也就有一些不一样的地方而已。
那么今天咱们重点要讲迭代器的失效问题。废话少说,让咱们开始吧。
容器——vector

这里涉及到了一个东西——模板,这个东西博主会在后面进行讲解,大家只要记住这是一个泛型编程,即这里面的class T,这个T可以是任何的类型,而后面有个Alloc,这个叫内存管理器,咱们不用去管他,这个东西,编译器会自动进行内存管理的。所以这里只要关注第一个参数即可。vector就类似于顺序表。只不过这个顺序表,是有类似于指向开头的指针 ,指向有效个数下一个位置的指针,有指向容量结尾的指针。比如:咱们将整形int 存入一个vector中,即可这样写:vector<int>。
即可,vector<int>算是一种类吧。
1.构造

这里面的所有的const allocator_type& alloc = allocator_type(),不用去管,这只是一种内存管理器,编译器会自动处理的,并且写参数的时候也不需要去写。那么第一个是无参构造,第二个是构造并初始化n个val,第三个是使用迭代器进行初始化构造(这是一种范围式的构造),第四个是拷贝构造(这是重点,后面会讲它的模拟实现)。来上代码:
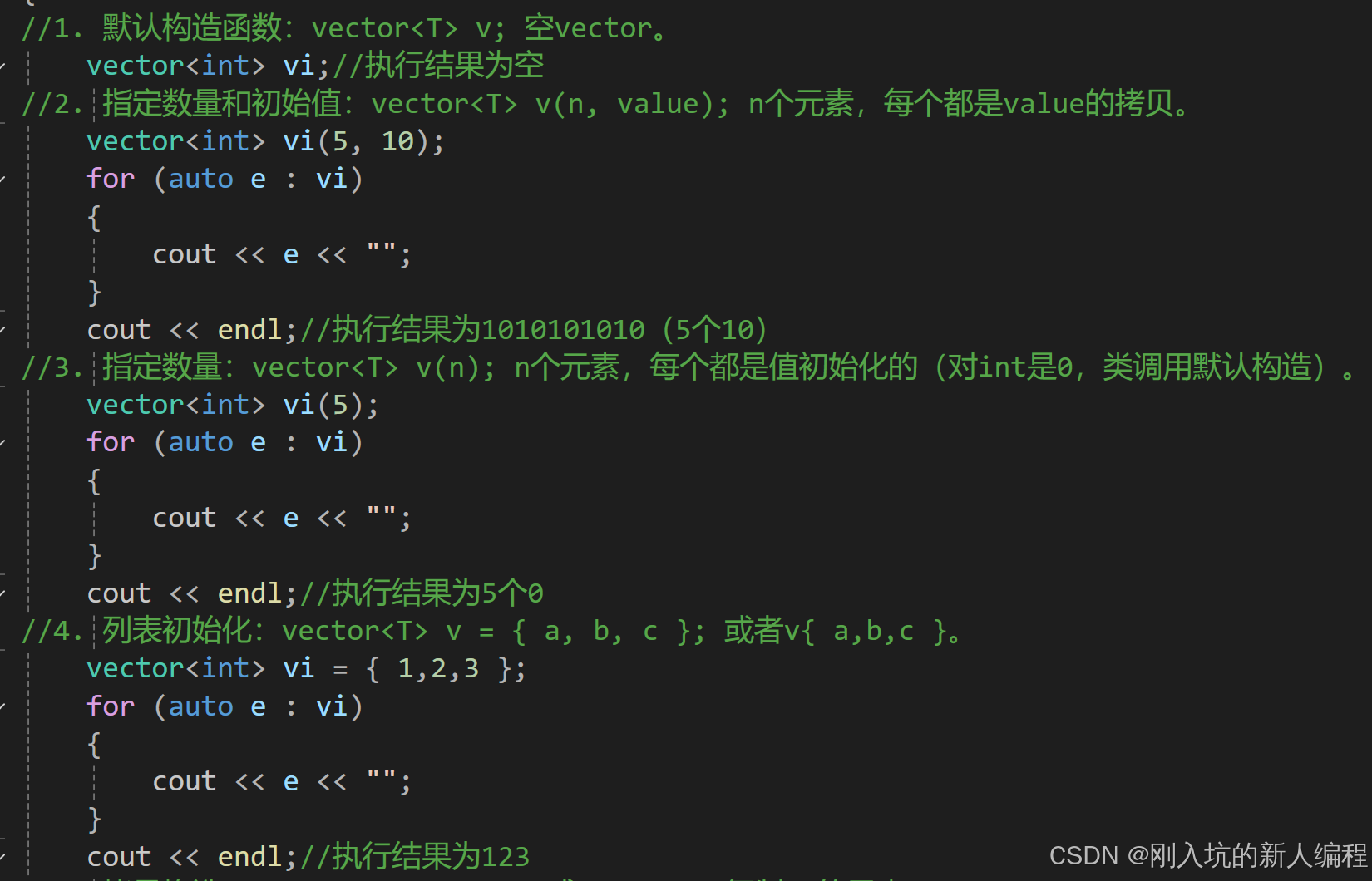
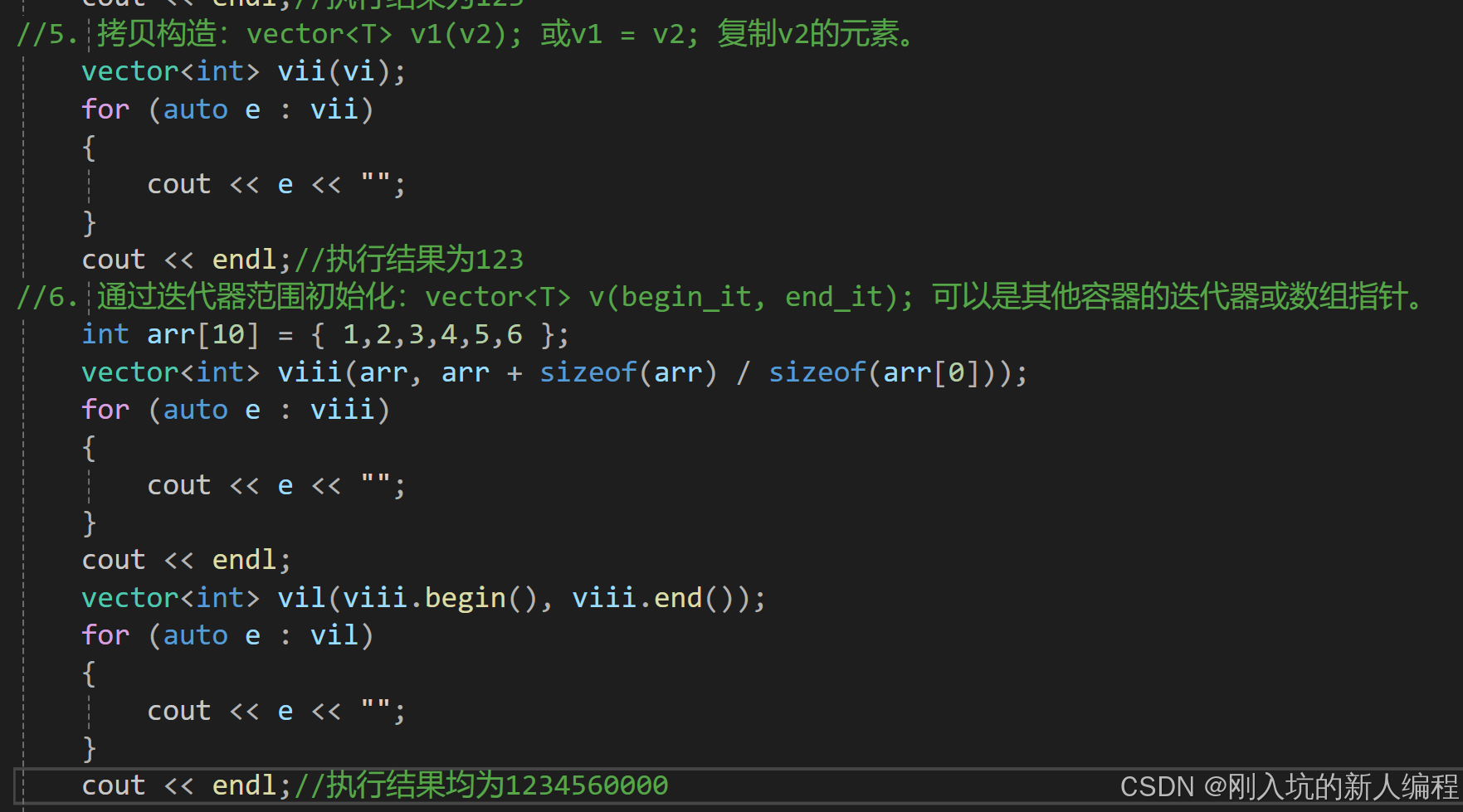
OK,那么通过以上的代码,博友们大概就已经知道它的构造方式了。这里需要强调的一点是:这里的auto后面加不加&,看的是你模板T是什么类型,因为范围for本质(就是不加&)是赋值拷贝,既然是拷贝 ,就有空间的消耗,要是int型还好,要是string型的呢?那你这个空间的消耗可谓是巨大。所以加上了&:传引用,对于一些开空间消耗较大的T来说,可谓是福音啊。所以,建议还是都加上&吧。(当然,你要是根据具体情况来,那也可以)。
模拟实现
第一个没啥,就是为空,就不看他的模拟实现了。
第二个:
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}
这里的T()的意思是T类型的默认构造。这里还需要强调一个问题,也是困扰博主的一个问题,不过还好博主将它解决了:后面的代码中你会看见vector<T>&v或者T&v。那么什么时候用第一个呢?第一个是当你准备用这一整个类型的时候(比如范围for,你是不是得用v去拷贝另一个对象,这个时候v是对象,那么这个时候,v的类型是vector<int>,所以才会用到第一个),参数才会写第一个。而第二个的v是T类型的值,比如int类型的值,并不是对象,所以说第二个主要应用于类似于插入值的时候。没事,慢慢的从后面的代码中体会。
就拿这一个举例,这一个是不是要尾插一个值,所以说,这里是T&val,后面的T(),相当于给val初始化了。
第三个:
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
这里如果说push_back,扩容了,那么这里可能会涉及到迭代器失效的问题(下面将),但这里假定它没有扩容。
第四个:
vector(const vector<T>& v)
{
reserve(v.capacity());
for (auto& e : v)
{
push_back(e);
}
}
这里是拷贝构造,是不是将咱们上面提到的两个问题全都涉及到了,即&问题与参数vector<T>&问题。
再来一个列表初始化的模拟实现:
vector(initializer_list<T> il)
{
reserve(il.size());
for (auto& e : il)
{
push_back(e);
}
}
列表初始化本质就是通过push_back来尾插数据。
2.迭代器

由于vector不支持重载流插入流提取,所以不可以像string类一样直接输出,它只能一个元素一个元素的输出,也跟string类一样,三种方法:
1.下标+[]:
for (size_t i = 0; i < v.size(); i++)
{
cout << v[i] << " ";
}
cout << endl;
2.迭代器:
bit::vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
3.范围for:
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
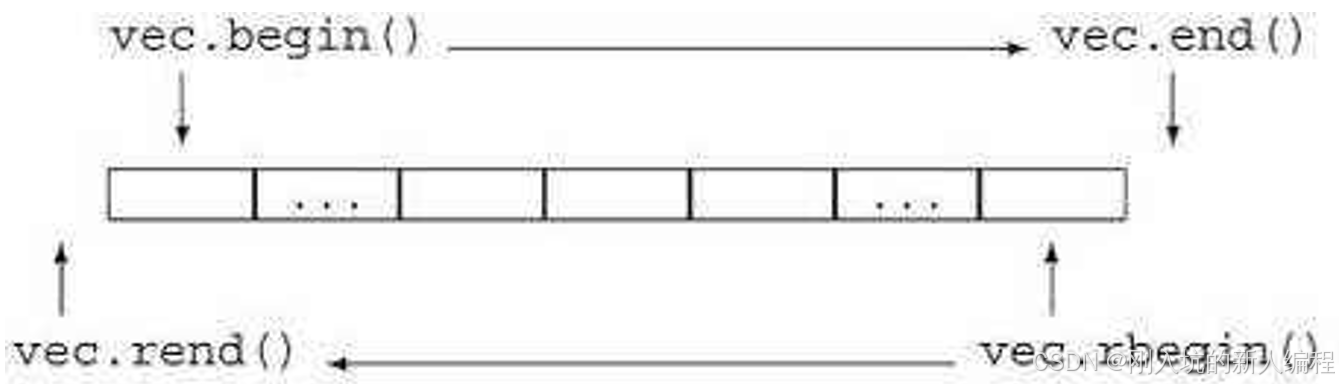
这里vector的迭代器跟string的一样,因为都是迭代器嘛,但这里给上两个图,帮助大家理解:

模拟实现:

给定三个位置,_start,一开始的元素位置,_finish有效数据个数的下一个位置,end_of_storage,容量到头的那个位置。
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
3.容量

这里跟string类差不多,都是一样的,但这里有两个重点的,咱们模拟实现一下:1.size():获取数据个数.2.capacity():获取容量大小3.empty():判断是否为空。4.resize():改变vector的size。5.reserve(): 改变vector的capacity。
我记得string里面并没有说capacity()的增长速度,那么在这咱们来讲一下:
std::vector<int>::size_type sz;std::vector<int> foo;sz = foo.capacity();std::cout << "making foo grow:\n";for (int i=0; i<100; ++i) {foo.push_back(i);if (sz!=foo.capacity()) {sz = foo.capacity();std::cout << "capacity changed: " << sz << '\n';}}std::vector<int> bar;sz = bar.capacity();bar.reserve(100); // this is the only difference with foo abovestd::cout << "making bar grow:\n";for (int i=0; i<100; ++i) {bar.push_back(i);if (sz!=bar.capacity()) {sz = bar.capacity();std::cout << "capacity changed: " << sz << '\n';}}

这是我直接截取的官方库里的代码,咱们来看逻辑分析:先定义一个sz用来存储capacity()的变化情况。 之后写一个for循环用来不断的尾插数据,再来判断容量等不等于之前的,再打印出容量,可以看出容量的变化方式,几乎是成2倍的速度增长的。再来看一下子扩容好100个空间的,那么这个可以看出容量几乎没什么变化,因为空间提前被开好了。虽然容量在g++上是按照2倍增长的,但是在vs上是按照1.5倍增长的,所以说为什么我在string这一篇文章中说,扩容多少是看编译器的,编译器不同,扩容的速率也是不同的。
ok,那么接下来看两个重点的,先来看第一个resize:

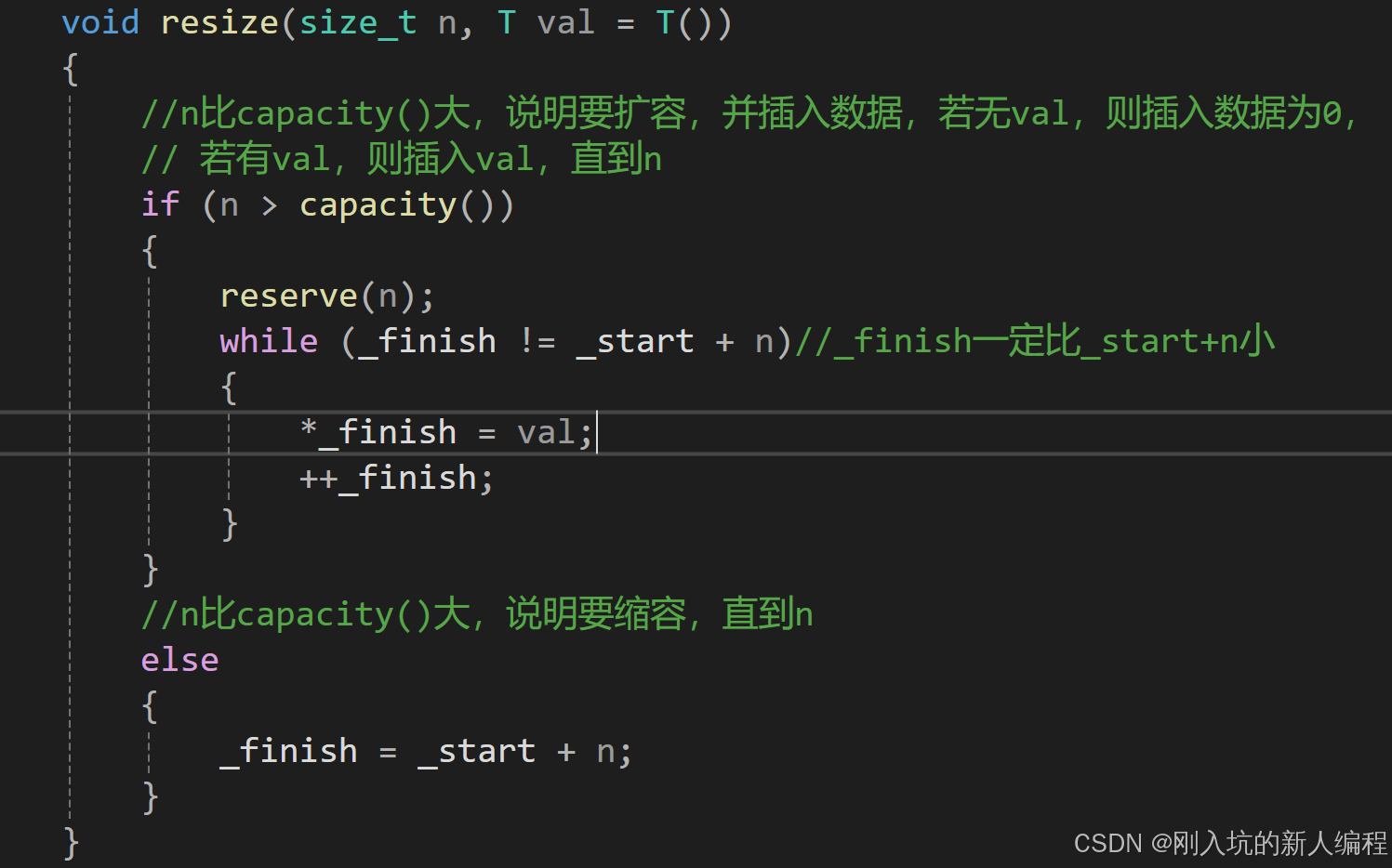
参数也是按照库里来写的。resize起到了对数据的判断是否要插入以及删除。以上就是resize的模拟实现。思路:如果说你要插入的数据个数n大于了这里的capacity,那么就需要扩容了,扩容之后,_start+n就是容量了(capacity),扩容马上讲。那么_finish不可以等于容量,且一定比容量小吧,之后在_finish这插入数据,之后++_finish。更新_finish的位置,直到n。如果说n比capacity小,说明要删除数据了。删除数据就直接 让有效数据的下一个位置更新到你要保存的元素的个数即可(即_start+n)。
第二个:reserve

 这儿的逻辑跟string的逻辑差不多,唯一的一个坑就是我在代码中注释的,所以为了解决这个问题,你直接用原来的size不就可以了吗,不用新的size,就可以避免_finish为0的问题。以上也是模拟实现。
这儿的逻辑跟string的逻辑差不多,唯一的一个坑就是我在代码中注释的,所以为了解决这个问题,你直接用原来的size不就可以了吗,不用新的size,就可以避免_finish为0的问题。以上也是模拟实现。
模拟实现:
由于resize以及reserve的模拟实现咱们已经写过了,下面咱们写size的那几个:
size_t capacity() const
{
return _end_of_storage - _start;
}
size_t size() const
{
return _finish - _start;
}
4.元素的访问

这里其实跟string差不多,咱们只讲一个,

模拟实现
T& operator[](size_t i)
{
assert(i < size());
return _start[i];
}
5.元素的增删查改

在这也会讲到咱们最重要的部分:迭代器的失效问题。
1.尾插
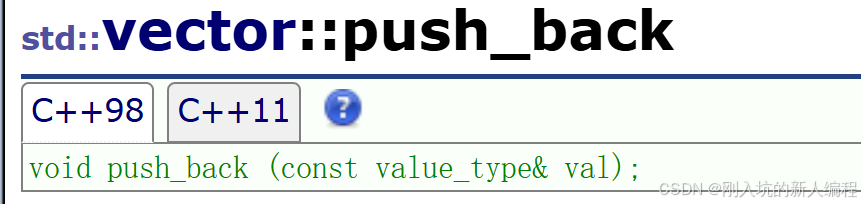 来看它的模拟实现:
来看它的模拟实现:
 这里需要先确定一下是否需要扩容,如果说需要扩容,那么就先扩容,之后往_finish处插入数据,之后更新_finish的位置即可。
这里需要先确定一下是否需要扩容,如果说需要扩容,那么就先扩容,之后往_finish处插入数据,之后更新_finish的位置即可。
2.pop_back:尾删

跟push_back的差不多。

3.insert:在position之前插入val

来看它的模拟实现:
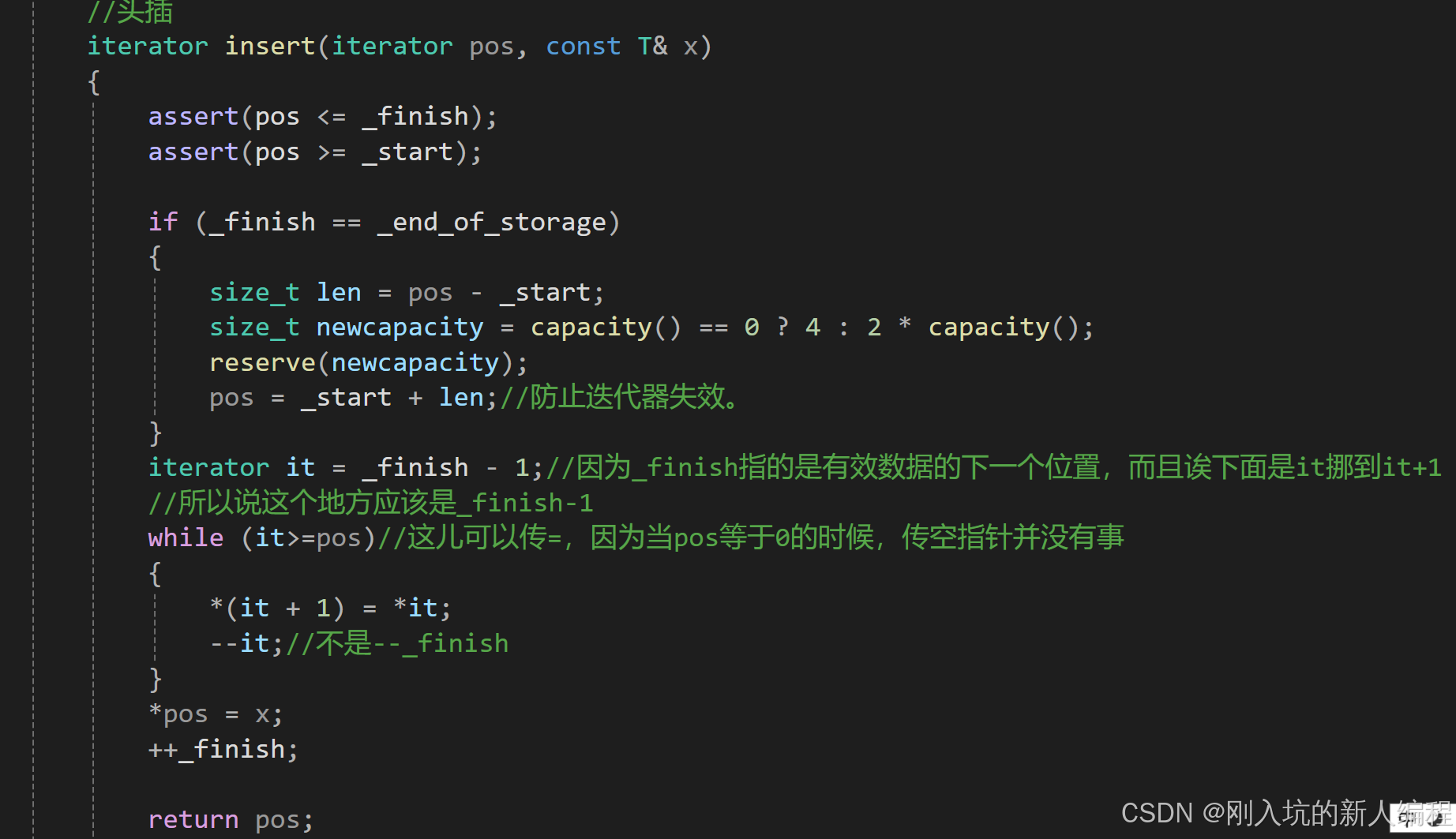 这儿有一个迭代器失效问题,待会讲完erase一块讲。这个代码的逻辑:先判断pos必须在_start与_finish之间。需要扩容的时候记得扩容。之后定义一个迭代器,让_finish赋给它,之后一直到pos的位置,往后挪一位,之后在pos这个地方插入数据,更新_finish。不知道大家发没发现一个规律:就是比如说我在pos插入元素,那么我一开始定义的地方一定是尾部,然后往后挪动数据,直到pos位置空出一个位置即可。而对于删除pos位置的元素,一般都是从pos位置开始定义,然后往前挪数据,直到有效数据的最后位置。
这儿有一个迭代器失效问题,待会讲完erase一块讲。这个代码的逻辑:先判断pos必须在_start与_finish之间。需要扩容的时候记得扩容。之后定义一个迭代器,让_finish赋给它,之后一直到pos的位置,往后挪一位,之后在pos这个地方插入数据,更新_finish。不知道大家发没发现一个规律:就是比如说我在pos插入元素,那么我一开始定义的地方一定是尾部,然后往后挪动数据,直到pos位置空出一个位置即可。而对于删除pos位置的元素,一般都是从pos位置开始定义,然后往前挪数据,直到有效数据的最后位置。
4.erase:删除position位置的数据
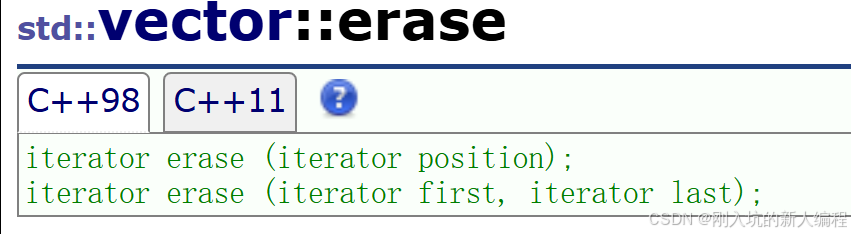
来看模拟实现:

这个代码逻辑也很简单,从pos位置开始定义,一直往前挪动一个数据,直到尾部为止,别忘了更新_finish。
迭代器失效问题:
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对 指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器 底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即
如果继续使用已经失效的迭代器,程序可能会崩溃)。类似于野指针,指向了一块不存在空间。
1.扩容导致的迭代器失效:

看图,再看咱们模拟实现的 insert,假设空间不够了,但还要插入数据,是不是得扩容啊?扩容一般都是异地扩容,但是异地扩容,你的_start,_finish,enf_of_storge都更新过去了,但是迭代器it呢?它没有更新啊同志们,它还指向了一块已经被释放的空间,你说这迭代器能不失效吗?解决办法也很简单,记住原来it的位置,将它映射到新开的空间上即可。insert的模拟实现已经给出了答案。但你也可以,提前先reserve好足够的空间(在定义迭代器之前先开好空间),这样就完美的避开了这个问题。
2.由于删除元素导致的迭代器失效

假定咱们删除了一个元素2对吧,那么2后面的元素的3会往前1移动,代替2的位置,但是呢,你可以认为这个迭代器比较傻,它只认它一开始指向的那个元素,如果那个元素没有了,那么它会认为那个元素所在的空间被销毁了,那么这个迭代器也就失效了。比如上图中的it迭代器,就是这个原理。那么以此类推,it后面的元素是不是都要往前移动啊,那么如果说it后面还有迭代器,那么自然it后面的迭代器全部失效。解决办法也很简单,就是再重新将被删元素的下一个空间重新赋值给it,那么被删元素的下一个空间其实就是it所指向的空间,因为被删元素的下一个元素往前挪动了一格嘛,所以说,这个空间就是it所指向的空间,就是原被删元素的空间。
那么失效后的迭代器,都不可再对他们进行++,--等操作,当然,在vs上会强制检查,但在其他编译器上,可能还可以正常运行,这也是看编译器的。
那么insert的返回值是插入那个元素的空间位置。而erase的返回值是被删元素的下一个元素的空间,其实都是it这个位置。
思考问题
vector v{ 1, 2, 3, 4 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
v.erase(it);
++it;
}
}
那么看上面这个代码,对吗?为什么不对?
肯定不对啊,1.首先是迭代器失效的问题,你erase后是不可以对迭代器进行加减操作的。
2.erase删除的迭代器如果是最后一个元素,删除之后it已经超过end,此时迭代器是无效的,++it导致程序崩溃。是因为进去循环的条件是it不等于_finish(这个循环式erase中的循环),而删除尾部元素的时候,it被定义为指向尾部的下一个元素,那么就可以进入循环,之后it会一直++,那这肯定不行,一直访问的是没有的空间。
3.就算你给erase重新赋值,但是又有一个问题:比如vector<int> v={1,2,2,3,4},有两个连续的偶数,你删除了第一个偶数之后,第二个偶数挪到了第一个偶数的位置,然后it++,会直接跳过第二个偶数,那这样第二个偶数就删不了了,不可以,所以,完美的解决办法就是,当它是偶数的时候,直接删,当它是奇数的时候,再++.即:
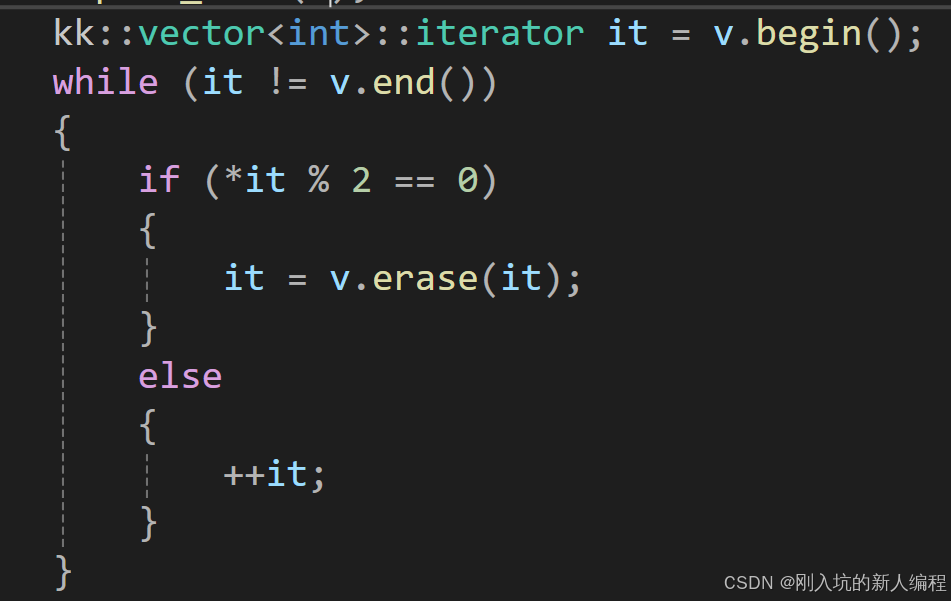
现在迭代器失效的问题,我已经全部讲清楚了,也讲的很透了。
5.swap

void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
那么现在咱们再来看一下现代写法的赋值有多精妙。
// v1 = v3
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
首先,先对v3进行传值传参,需要调用拷贝构造,那么拷贝构造就是再次构造出一个与v3一样大的空间,完了之后,交换v1与v(v3),那么咱们v3是想要的,而v1是不想要的,通过交换正好拿到了v3,那么v1也给了v,而v是一个局部变量啊,出了作用域就销毁了。所以说,v出了函数就销毁了,反正也不要了,是不是很nice呀,哈哈哈哈哈,确实,我也这么想的,当年创造这个写法的人肯定也是这么想的。
OK,vector的内容就这些,由于咱们有了string的基础,所以学起来vector就是很简单了,除了一些特殊的坑外,其他的也没什么了。
以上内容均我个人理解,若有不对,还请各位大佬指出,谢谢啦!
本篇完...................
相关文章:
C++STL——容器-vector(含部分模拟实现,即地层实现原理)(含迭代器失效问题)
目录 容器——vector 1.构造 模拟实现 2.迭代器 模拟实现: 编辑 3.容量 模拟实现: 4.元素的访问 模拟实现 5.元素的增删查改 迭代器失效问题: 思考问题 【注】:这里的模拟实现所写的参数以及返回值,都是…...

严重BUG修复及部分体验问题优化
随着Deepseek APIPython 测试用例一键生成与导出 V1.0.6的试用不断深入,会出现程序异常崩溃的问题。经群友定位,紧急修复了bug,并适当优化部分体验性问题。针对生成的测试用例xlsx文档,可以再次选中该xlsx给大模型进行推理生成新的…...

黑马 C++ 学习笔记
课程链接:黑马 C 文章目录 C 基础语法指针空指针和野指针 const 修饰指针 C 核心编程程序的内存分区模型程序运行前程序运行后new 操作符 引用引用的基本使用引用的注意事项引用作函数参数引用作函数返回值引用的本质常量引用 函数的提高函数默认参数函数默认参数函…...
Elasticsearch 证书问题解决
报错信息 javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested targetat org.elasticsearch.client.RestClient. extractAndWrapCause(R…...

I²C总线高级特性与故障处理分析
IC总线高级特性与故障处理深度分析 目录 1. IC基础回顾 1.1 IC通信基本原理1.2 IC总线时序与协议1.3 寻址方式与读写操作 2. IC高级特性 2.1 多主机模式2.2 时钟同步与伸展2.3 高速模式与Fast-mode Plus2.4 10位寻址扩展 3. IC总线故障与锁死 3.1 断电锁死原理3.2 总线挂起与…...

山东大学《多核平台下的并行计算》实验笔记
每年的题目都不一样,学弟学妹参考参考就行。 一、搭建linux环境 主播用的ssh+虚拟机,目前用着最顺手的 二、安装并行编程软件 MPI(Message Passing Interface),由其字面意思也可些许看出,是一个信息传递接口。可以理解为是一种独立于语言的信息传递标准。而OpenMPI和MP…...
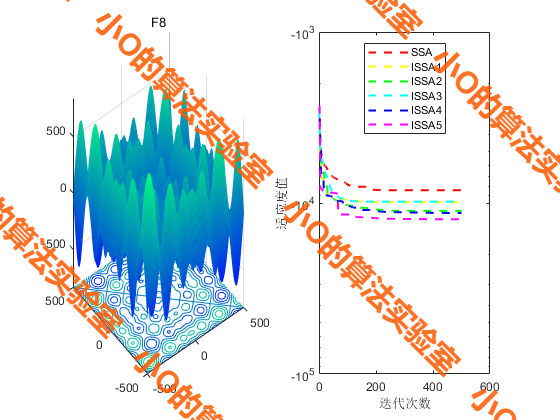
2023年CIE SCI1区TOP:序列融合麻雀搜索算法ISSA,深度解析+性能实测
目录 1.摘要2.麻雀搜索算法SSA原理3.改进策略3.结果展示4.参考文献5.代码获取 1.摘要 麻雀搜索算法(SSA)是一种基于麻雀觅食和防捕行为的群体智能算法。然而,基本SSA在迭代过程中,种群多样性逐渐降低,容易陷入局部最优…...

elasticsearch 如果按照日期进行筛选
如果你需要按照日期进行筛选,你可以使用 Elasticsearch 的范围查询来实现。以下是一个示例代码,演示如何在 Java 中进行日期范围查询: import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticse…...

SpringBoot条件装配注解
SpringBoot条件装配注解 Spring Boot 提供了一系列条件装配注解,用于控制 Bean 的创建和装配过程。以下是一些常用的条件装配注解及其详细介绍: ConditionalOnClass 作用:当类路径中存在指定的类时,才会创建该 Bean。 示例&#…...
配置晟腾910b的PyTorch torch_npu环境
1.【新教程】华为昇腾NPU的pytorch环境搭建 - Lukea - 博客园 1、新建conda环境。 conda create -n pytorch python3.102、在新建好的conda环境中,安装基础的依赖。 pip install attrs cython numpy1.24.0 decorator sympy cffi pyyaml pathlib2 psutil protobuf…...
 [第291~300题](持续更新))
算法刷题记录——LeetCode篇(3.10) [第291~300题](持续更新)
更新时间:2025-04-02 算法题解目录汇总:算法刷题记录——题解目录汇总技术博客总目录:计算机技术系列博客——目录页 优先整理热门100及面试150,不定期持续更新,欢迎关注! 295. 数据流的中位数 中位数是…...

conda 激活环境vscode的Bash窗口
多份conda环境注意事项,当时安装了两个conda环境,miniconda和conda,导致环境总是冲突矛盾。初始化时需要更加注意。 $ C:/Users/a_hal/miniconda3/Scripts/conda.exe init bash能够显示用哪里的conda环境命令执行。 然后直接conda activate…...

网线和跳线
文章目录 一、网线二、跳线三、区别对比一句话总结 一、网线 网线(网路线): 它是一种用来连接网络设备的线,比如: 把 电脑连到交换机把 路由器连到光猫把 交换机和交换机连接起来 它的本质是:传输网络信…...
火山 RTC 引擎 2 ----APPKEY
前篇文章:火山RTC引擎 --一次失望的体验 那个DEMO可以编译运行了,但是功能不能用, 一用就崩溃。 主要原因还是没有APPKEY 一、火山引擎 APPKEY 管理 1、登录后台 账号登录-火山引擎欢迎登录火山引擎,火山引擎是字节跳动旗下的云…...

Linux中进程与计划任务
目录 一.进程 1.进程相关概念 2.进程的特征 3.进程相关的命令 3.1 ps命令 3.2 top命令 3.3 pgrep命令 3.4 pstree命令进程树 3.5 kill命令 二.计划任务 1.一次性任务 2.周期性任务crontab 三.本章涉及面试题 1.运维需要关注服务器的系统性能及如何查看 一.进程 1…...

Springboot学习笔记3.28
目录 实战第六课:文章分类开发 新增文章分类: 具体实现: 查询文章分类: 具体实现: 获取文章分类的详情 更新文章分类: 注意点: 编辑 对校验规则进行分组: 学习时的疑惑…...

【CSS3】05-定位 + 修饰属性
本文介绍定位和CSS中的修饰属性。 目录 1. 定位 1.1 相对定位 1.2 绝对定位 1.3 定位居中 1.4 固定定位 1.5 z-index堆叠层级 2. 修饰属性 2.1 垂直对齐方式 vertical-align 2.2 过渡属性 2.3 透明度 opacity 2.4 光标类型 cursor 1. 定位 灵活改变盒子在网页中的位…...

C 语言测验
C 语言测验 引言 C 语言作为一种历史悠久且广泛使用的编程语言,自1972年由Dennis Ritchie在贝尔实验室发明以来,一直是计算机科学领域的基石。C 语言以其高效、灵活、可移植的特点,在操作系统、嵌入式系统、游戏开发等多个领域占据着重要地位。为了帮助读者深入了解C语言,…...

如何屏蔽mac电脑更新提醒,禁止系统更新
最烦mac的系统更新提醒了,过几天就是更新弹窗提醒,现在可以直接禁掉了,眼不见心不乱,不然一升级,开发环境全都不能用了,那才是最可怕的,屏蔽的方法也很简单,就是屏蔽mac系统更新的请…...

tcp的粘包拆包问题,如何解决?
TCP的粘包和拆包问题是由于TCP协议面向流的特性导致数据边界不明确,解决方案需在应用层明确数据包边界。以下是具体解决方法: 1. 固定长度消息(Fixed-Length Protocol) 实现方式:每个数据包长度固定,不足…...
Rclone同步Linux数据到google云盘
文章目录 Rclone管理云存储Rclone安装和使用说明安装rclone配置rclone连接到云盘基本备份命令高级备份选项自动化备份加密备份(可选)恢复数据常见云存储服务名称注意事项 googleCloud 平台中操作OAuth权限请求页面(OAuth同意屏幕)…...

AI人工智能-Jupyter NotbookPycharm:Py开发
安装 命令: pip install jupyter 启动 命令: jupyter notebook 启动成功后,下面网址会默认自动打开当前用户的根目录。 其实这个页面显示的内容,是我们电脑目录C:\Users\当前用户\下的文件夹 我们平常做实验,希望在…...

DDR简介
一、什么是DDR? DDR SDRAM(Double Data Rate Synchronous DYNAMIC RAM)中文名是:双倍数据速率同步动态随机存储器。 传统的SDRAM只在时钟信号的上升沿传输数据,而DDR可以同时在时钟的上升沿和下降沿传输数据…...

Kubernetes 入门篇之 Node 安装与部署
上篇记录了Master节点的安装与部署,本篇记录一下node的安装与部署。 1. 基础环境配置 关闭防火墙与交换分区(swap),关闭selinux,配置yum源参考上篇;启用 IPv4 数据包转发 和 iptables 网络过滤参考上篇&a…...

企业数据治理实践:“七剑” 合璧,释放数据价值
在数字化转型的浪潮中,数据已成为企业的核心资产,其治理水平直接关乎企业的竞争力和可持续发展能力。数据模型治理、元数据治理、数据质量治理、数据标准治理、主数据治理、数据安全治理以及数据服务平台治理,共同构成了企业数据治理的关键体…...
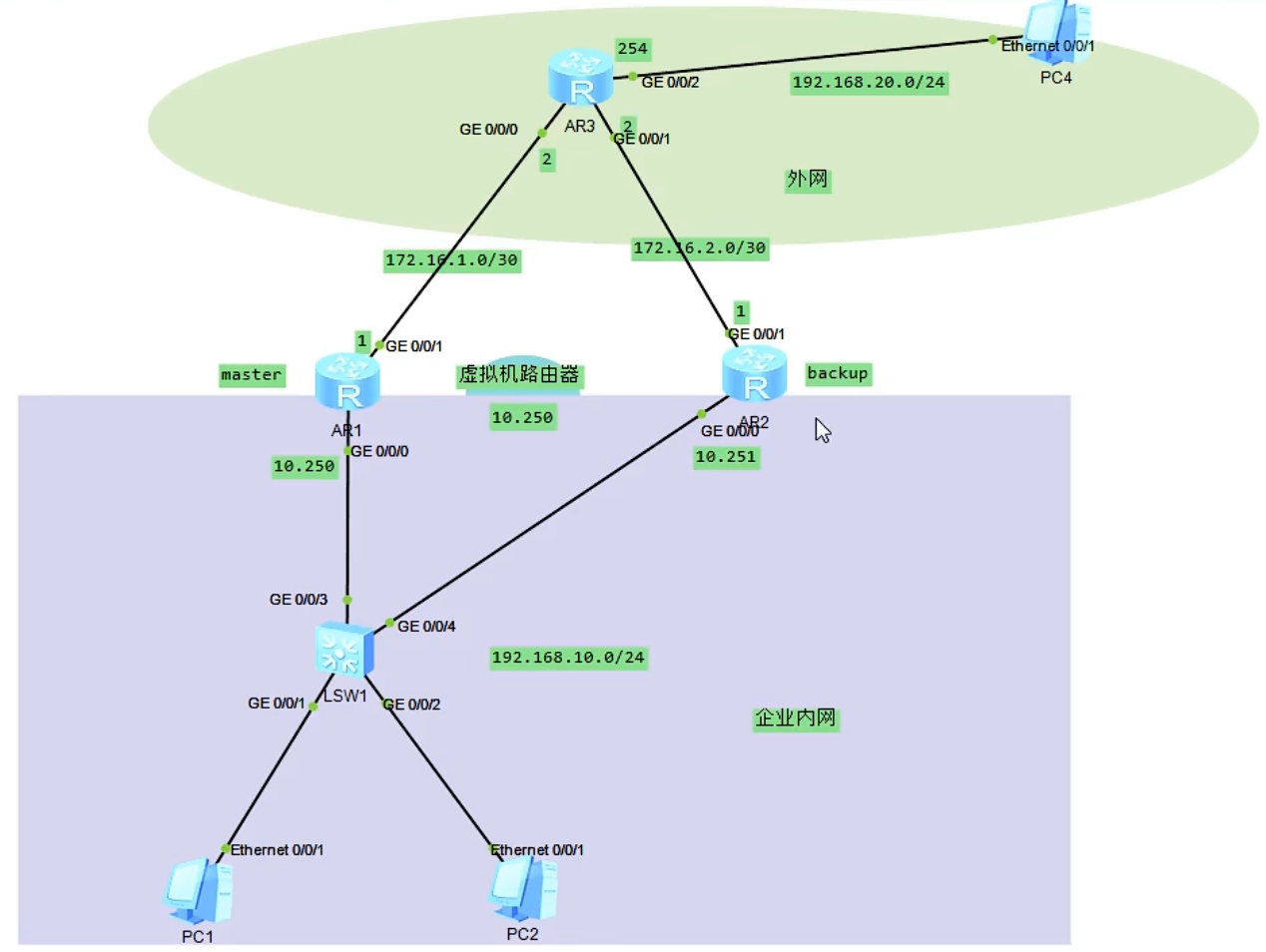
VRRP(虚拟路由器冗余协议)、虚拟路由器、master路由器、backup路由器
VRRP(虚拟路由器冗余协议) 1、介绍 虚拟路由冗余协议 VRRP (Virtual Router Redundancy Protocol)通过把几台路由设备联合组成一台虚拟的路由设备,将虚拟路由设备的IP地址作为用户的默认网关实现与外部网络通信。当网关设备发生故障时,VRRP机制能够选举…...
)
基本元素定位(findElement方法)
通过ID定位:使用元素的ID属性进行定位,是最简单和最常用的方法,因为ID在页面上是唯一的。 //定位百度的搜索框元素,并且输入数据(ID定位)-唯一 chromeDriver.findElement(By.id("kw")).sendKeys("腾讯课堂")…...

多模态RAG实践:如何高效对齐不同模态的Embedding空间?
目录 多模态RAG实践:如何高效对齐不同模态的Embedding空间? 一、为什么需要对齐Embedding空间? 二、常见的对齐方法与关键技术点 (一)对比学习(Contrastive Learning) (二&#…...

Cesium 核心思想及基础概念应用
文章目录 Cesium 基础理解(一)1. 场景(Scene)2. 查看器(Viewer)3. 相机(Camera)4. 实体(Entity)5. 图元(Primitive)6. 数据加载与解析…...

vue中的 拖拽
拖拽总结 实现方式特点适用场景HTML5 原生拖拽 API✅ 直接使用 dataTransfer 进行数据传输 ✅ 兼容性好(大部分浏览器支持) ✅ 适合简单的拖拽场景低代码平台、表单生成器、组件拖拽Vue/React 组件库(如 Vue Draggable、SortableJSÿ…...