Python网络爬虫:从入门到实践
目录
-
什么是网络爬虫?
-
网络爬虫的工作原理
-
常用Python爬虫库
-
编写爬虫的步骤
-
实战示例
-
注意事项与道德规范
-
未来趋势
1. 什么是网络爬虫?
网络爬虫(Web Crawler)是一种自动化程序,通过模拟人类浏览行为,从互联网上抓取、解析和存储数据。常见的应用包括:
-
搜索引擎索引
-
价格监控
-
舆情分析
-
数据采集与分析
2. 网络爬虫的工作原理
## 2. 网络爬虫的工作原理
1. **初始URL队列**:从种子URL开始
2. **下载器**:发送HTTP请求获取网页内容
3. **解析器**:提取数据和发现新链接- 数据清洗(去除广告/无效信息)- 链接去重(避免重复抓取)
4. **数据管道**:存储结构化数据
5. **调度器**:管理请求优先级与频率
6. **循环机制**:将新链接加入队列,重复流程-
发送请求:通过HTTP协议向目标服务器发送请求(GET/POST)
-
获取响应:接收服务器返回的HTML/JSON/XML数据
-
解析内容:提取所需数据(文本、链接、图片等)
-
存储数据:保存到本地文件或数据库
-
处理后续请求:根据规则跟踪新的链接(广度/深度优先)
3. 常用Python爬虫库
| 库名称 | 用途 | 特点 |
|---|---|---|
| Requests | 发送HTTP请求 | 简单易用,支持多种HTTP方法 |
| Beautiful Soup | HTML/XML解析 | 容错性强,适合简单页面 |
| lxml | 高性能解析库 | XPath支持,速度快 |
| Scrapy | 全功能爬虫框架 | 异步处理,适合大型项目 |
| Selenium | 浏览器自动化 | 处理JavaScript动态加载内容 |
| PyQuery | jQuery式语法解析 | 语法简洁 |
4. 编写爬虫的步骤
4.1 明确目标
-
确定要爬取的网站
-
分析所需数据的结构和位置
4.2 分析网页结构
-
使用浏览器开发者工具(F12)检查元素
-
查看网络请求(Network标签)
4.3 编写代码
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
headers = {"User-Agent": "Mozilla/5.0"} # 模拟浏览器请求response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
titles = soup.select('h1.class_name') # 使用CSS选择器4.4 数据存储
# 保存到CSV
import csv
with open('data.csv', 'w', newline='') as f:writer = csv.writer(f)writer.writerow(['Title', 'URL'])for item in data:writer.writerow([item['title'], item['url']])# 保存到数据库(SQL示例)
import sqlite3
conn = sqlite3.connect('data.db')
c = conn.cursor()
c.execute('CREATE TABLE IF NOT EXISTS articles (title TEXT, url TEXT)')
c.executemany('INSERT INTO articles VALUES (?, ?)', data)4.5 处理反爬措施
-
User-Agent轮换
-
IP代理池
-
请求频率控制(使用
time.sleep()) -
验证码识别(OCR或第三方服务)
-
Cookies处理
5. 实战示例
示例1:静态网页爬取(豆瓣电影Top250)
import requests
from bs4 import BeautifulSoupdef get_movies():url = "https://movie.douban.com/top250"response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')movies = []for item in soup.find_all('div', class_='item'):title = item.find('span', class_='title').textrating = item.find('span', class_='rating_num').textmovies.append({'title': title, 'rating': rating})return movies示例2:动态内容爬取(使用Selenium)
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("https://www.taobao.com")search_box = driver.find_element(By.ID, 'q')
search_box.send_keys('手机')
search_box.submit()# 等待页面加载
driver.implicitly_wait(10)products = driver.find_elements(By.CLASS_NAME, 'item.J_MouserOnverReq')
for product in products:print(product.text)6. 注意事项与道德规范
-
遵守robots.txt:检查
/robots.txt文件 -
控制请求频率:避免造成服务器压力
-
尊重版权:不抓取受保护内容
-
用户隐私:不收集敏感个人信息
-
法律合规:遵守《网络安全法》等法规
7. 未来趋势
-
反爬技术升级:验证码、行为分析、指纹识别
-
AI辅助爬虫:自动识别页面结构
-
分布式爬虫:提高抓取效率
-
法律法规完善:数据采集的合规性要求提高
进一步学习资源
-
官方文档:Requests、Scrapy
-
书籍:《Python网络数据采集》《用Python写网络爬虫》
-
实战项目:GitHub开源爬虫项目
通过这篇博客,读者可以系统掌握Python网络爬虫的核心知识和实践技能。记住:爬虫虽好,但需合法合规使用!
相关文章:

Python网络爬虫:从入门到实践
目录 什么是网络爬虫? 网络爬虫的工作原理 常用Python爬虫库 编写爬虫的步骤 实战示例 注意事项与道德规范 未来趋势 1. 什么是网络爬虫? 网络爬虫(Web Crawler)是一种自动化程序,通过模拟人类浏览行为&#x…...
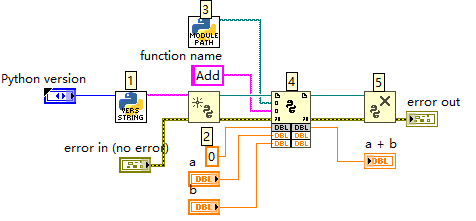
LabVIEW 调用 Python 函数
此程序是 LabVIEW 调用 Python 函数实现双精度数相加的典型示例。通过 LabVIEW 搭建交互框架,借助 “Open Python Session” 创建 Python 代码运行环境,定位 Python 模块路径后调用 “Add” 函数,最终实现数据处理并关闭会话。整个流程展现了…...

视频分析设备平台EasyCVR视频结构化AI智能分析:筑牢校园阳光考场远程监控网
一、背景分析 近年来,学校考试的舞弊现象屡禁不止,严重破坏考试的公平性,不仅损害广大考生的切身利益,也在社会上造成恶劣的影响。为有效制止舞弊行为,收集确凿的舞弊证据,在考场部署一套可靠的视频监控…...
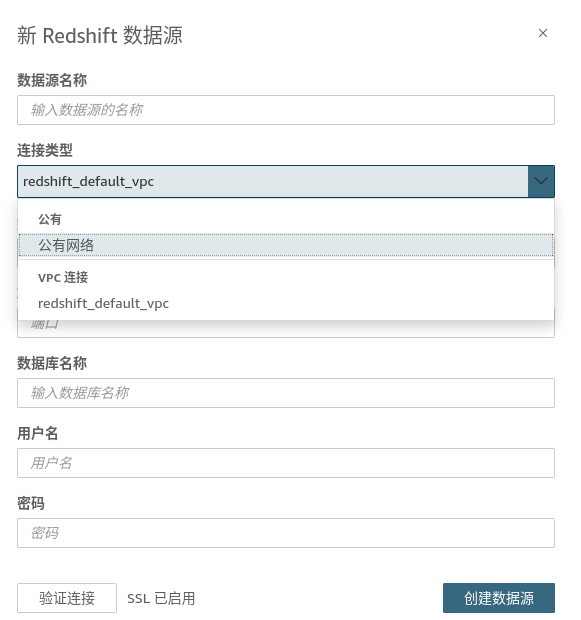
AWS用Glue读取S3文件上传数据到Redshift,再导出到Quicksight完整版,含VPC配置
1. 项目背景 AWS的官方文档,关于Glue和Vpc配置部分已经比较旧了,按照官方文档配置的流程始终跑不通,花了一番时间和波折后,才终于完整的跑通了。 在数据分析和商业智能(BI)领域,我们常需要将存…...

Qt WebSockets使用
Qt WebSockets 是 Qt 官方提供的 WebSocket 协议 实现库,支持全双工通信(客户端/服务端),适用于实时交互应用(如聊天、游戏、实时数据监控)。 1. 核心功能 完整的 WebSocket 协议支持 符合 RFC 6455 标准,支持 ws:// 和 wss://(加密)。 自动处理握手、帧拆分、Ping/…...

Docker学习--容器生命周期管理相关命令--start/stop/restart命令
docker start 命令作用: 启动一个或多个已经创建的容器。 语法: docker start [参数] CONTAINER [CONTAINER…](要操作的容器的名称,可以同时操作多个) 参数解释: -a:附加到容器的标准输入输出…...

dom操作笔记、xml和document等
文章目录 mybatis dom部分 dom(Document Object Model文档对象模型)。 xml和html都属于dom,每天都会用到,一直以为很简单,直到有一天,操作mybatis的xml时候惨不忍睹,被上了一课,做个笔记整理下吧。 xml和ht…...
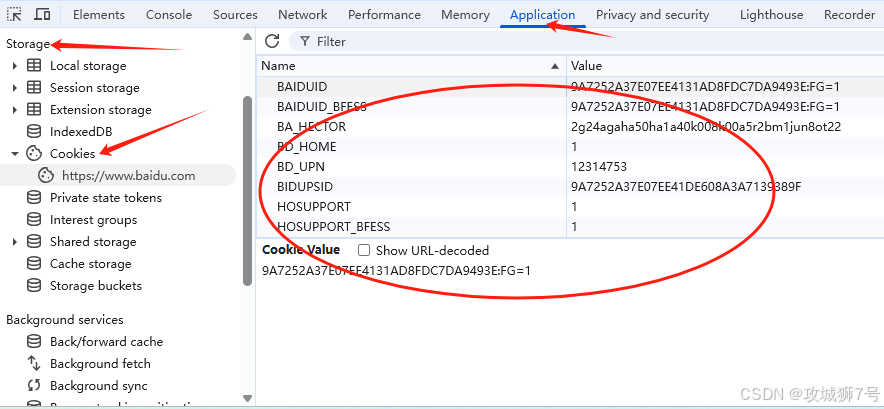
Python爬虫第3节-会话、Cookies及代理的基本原理
目录 一、会话和Cookies 1.1 静态网页和动态网页 1.2 无状态HTTP 1.3 常见误区 二、代理的基本原理 2.1 基本原理 2.2 代理的作用 2.3 爬虫代理 2.4 代理分类 2.5 常见代理设置 一、会话和Cookies 大家在浏览网站过程中,肯定经常遇到需要登录的场景。有些…...
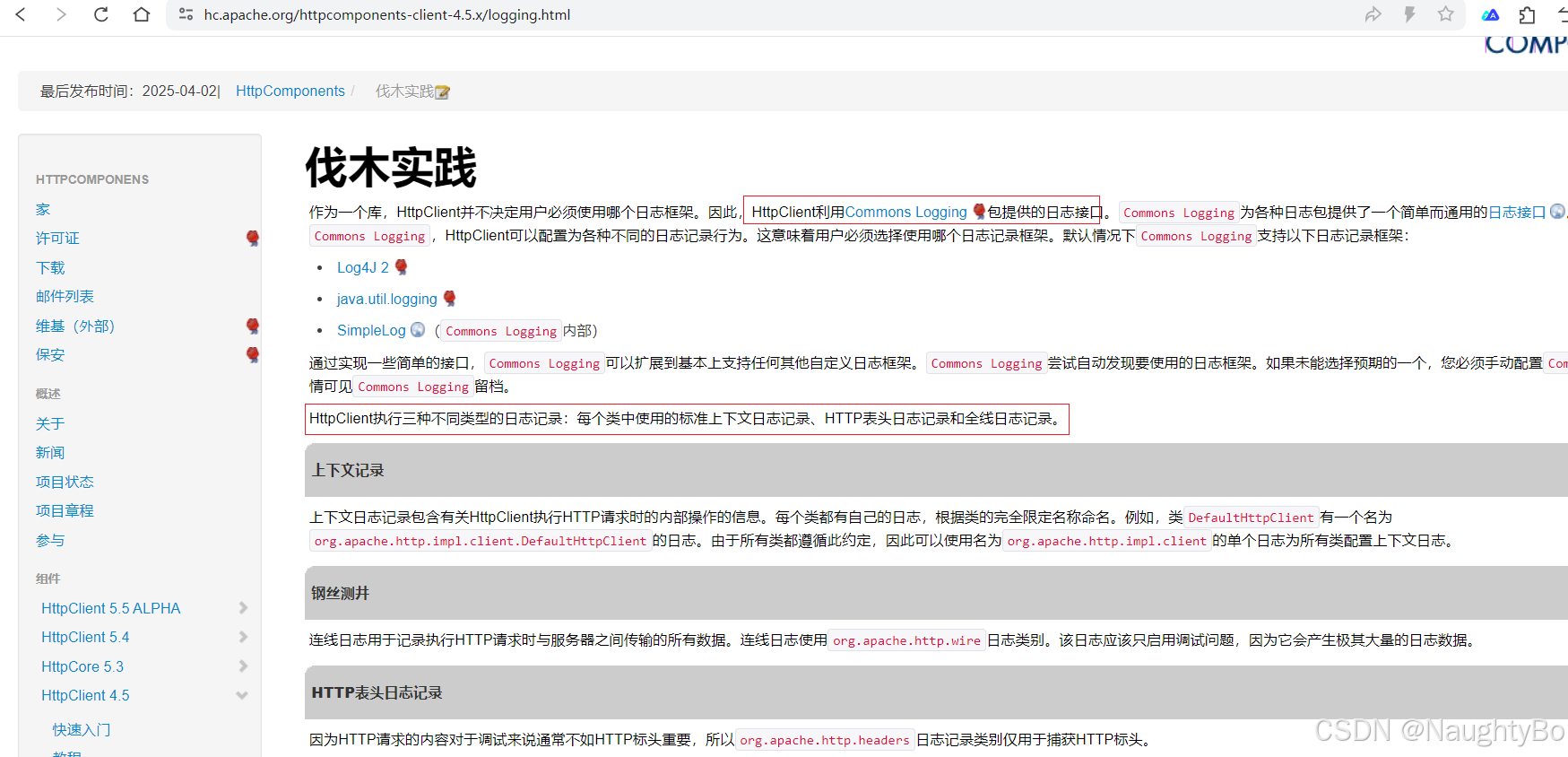
OkHttpHttpClient
学习链接 okhttp github okhttp官方使用文档 SpringBoot 整合okHttp okhttp3用法 Java中常用的HTTP客户端库:OkHttp和HttpClient(包含请求示例代码) 深入浅出 OkHttp 源码解析及应用实践 httpcomponents-client github apache httpclie…...

android设备出厂前 按键测试 快速实现-屏蔽Home,Power等键
android整机测试,需要测试按键。 一般的键好按,好测试。如:音量加 ,音量- 。 但是,有些按键就不好测了。譬如:电源键(Power),Home键,Menu键,Bac…...

Spring Boot3使用Spring AI通过Ollama集成deepseek
文章目录 项目地址版本信息集成步骤 项目地址 DeepSeekSpringAI实战AI家庭医生应用 版本信息 版本Spring Boot3.4.4JDK21spring-ai1.0.0-M6ollama0.6.3LLMdeepseek:14b 集成步骤 引入依赖 <dependency><groupId>org.springframework.ai</groupId><a…...

c++柔性数组、友元、类模版
目录 1、柔性数组: 2、友元函数: 3、静态成员 注意事项 面试题:c/c static的作用? C语言: C: 为什么可以创建出 objx 4、对象与对象之间的关系 5、类模版 1、柔性数组: #define _CRT_SECURE_NO_WARNINGS #…...

win10 快速搭建 lnmp+swoole 环境 ,部署laravel6 与 swoole框架laravel-s项目1
参考文献 1.dnmp环境 https://github.com/yeszao/dnmp 2.laravel6.0文档 https://learnku.com/docs/laravel/6.x 3.laravels 文档 https://github.com/hhxsv5/laravel-s/blob/master/README-CN.md 安装前准备 1.确认已经安装且配置好docker,能在cmd 中运行 docker …...

【Kafka基础】基础概念解析与消息队列对比
1 Kafka 是什么? Kafka是一个 分布式流处理平台,主要用于 高吞吐量、低延迟的实时数据流处理,最初由LinkedIn开发。 核心特点: 高吞吐量:支持每秒百万级消息处理持久化存储:消息可持久化到磁盘,…...

vue将组件中template转为js
在 Vue 中,组件的 template 需要被转换为 JavaScript 渲染函数(Render Function)才能在浏览器中运行。Vue 2 和 Vue 3 的转换机制有所不同,主要体现在编译时机、编译工具和输出结果上。 1. Vue 2 的 Template 转换 转换方式 Vue…...
Centos 8 安装教程(新手版)
1.需要在阿里开源镜像站下载对应的镜像,如下:https://mirrors.aliyun.com/centos/8.5.2111/isos/x86_64/ 2.打开VM虚拟机,创建新的虚拟机,选择自定义 如图所示点击进行: 选择下载好的镜像 选择“Linux”,版…...

Vue2函数式组件实战:手写可调用的动态组件,适用于toast轻提示、tip提示、dialog弹窗等
Vue2函数式组件实战:手写可调用的动态组件 一、需求场景分析 在开发中常遇到需要动态调用的组件场景: 全局弹窗提示即时消息通知动态表单验证需要脱离当前DOM树的悬浮组件 传统组件调用方式的痛点:必须预先写入模板,可能还要用…...

ESLint语法报错
ESLint语法报错 运行报错 You may use special comments to disable some warnings. Use // eslint-disable-next-line to ignore the next line. Use /* eslint-disable */ to ignore all warnings in a file.解决方案 关闭eslint的语法检测,在eslintrc.js文件中…...

大象如何学会太空漫步?美的:科技领先、To B和全球化
中国企业正处在转型的十字路口。一边是全新的技术、全新的市场机遇;一边是转型要面临的沉重负累和巨大投入,无数中国制造、中国品牌仍在寻路,而有的人已经走至半途。 近日,美的集团交出了一份十分亮眼的2024年财报。数据显示&…...

Leetcode 3500. Minimum Cost to Divide Array Into Subarrays
Leetcode 3500. Minimum Cost to Divide Array Into Subarrays 1. 解题思路2. 代码实现 题目链接:3500. Minimum Cost to Divide Array Into Subarrays 1. 解题思路 这一题非常惭愧,没有自己搞定,基本是抄的大佬们的代码,甚至抄…...
已经使用中的clickhouse更改数据目录
在更换的目录操作,这里更换的目录为home目录,原先安装的目录在/soft/clickhouse/ ,在该目录下有data目录和log目录 更改前目录 更改后目录 1、停止clickhouse服务 sudo systemctl stop clickhouse-server 2、在home目录创建clickhouse目录,在clickho…...

PHP的相关配置和优化
进入etc下面 去掉注释 pid run/php-fpm.pid #指定pid文件存放位置 生成一下子配置文件 这些都是生成的fastcgi的配置文件 进入php中,然后复制模版,生成配置文件 然后编辑文件更改时区 改完之后可以生成启动脚本 这时候刷新之后,再启动会报…...

体重秤PCBA电路方案组成结构
体重秤PCBA电路主要由以下几个部分组成: 主控芯片电路 芯片选择:通常采用低功耗、高性能的单片机作为主控芯片,如前面提到的SIC8833等。这类芯片具备丰富的外设接口,可方便地与其他模块进行通信和控制。 电路连接:主控…...

android 加载本地.svg资源的几种引入方式
在 Android 中,可以在 XML 布局文件中引入本地 .svg 资源,但需要先转换为 Android 可识别的格式。主要有以下几种方式: 方式 1:使用 Vector Asset(官方推荐) Android 不支持直接加载 .svg,但可…...

fio磁盘测试工具使用笔记
本文介绍磁盘性能测试工具fio在某国产操作系统(内核4.19,gcc为7.3.0)上的编译和使用。 背景 某项目使用物理机安装某数据库,相关人员提到磁盘性能方面的要求,用fio测试32k的随机读写,性能要达到1万 IOPS。…...

JavaScrip——BOM编程
一、BOM核心对象与导航控制 1. location对象:页面跳转与刷新 // 跳转到指定URL location.href "https://example.com"; // 刷新当前页面 location.reload(); // 示例:点击按钮跳转 document.querySelector("#btn").onclick () &…...

机器学习 分类算法
【实验名称】 实验:分类算法 【实验目的】 1.了解分类算法理论基础 2.平台实现算法 3. 编程实现分类算法 【实验原理】 分类(Categorization or Classification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类。 【实验环境】 OS:Ubuntu16.0…...

【leetcode100】每日温度
1、题目描述 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输…...

<贪心算法>
前言:在主包还没有接触算法的时候,就常听人提起“贪心”,当时是layman,根本不知道说的是什么,以为很难呢,但去了解一下,发现也不过如此嘛(bushi),还以为是什么高级东西呢…...
基于银河麒麟桌面服务器操作系统的 DeepSeek本地化部署方法【详细自用版】
一、3种方式使用DeepSeek 1.本地部署 服务器操作系统环境进行,具体流程如下(桌面环境步骤相同): 本例所使用银河麒麟高级服务器操作系统版本信息: (1)安装ollama 方式一:按照ollama官网的下载指南,执行如下命令: curl -fsSL https://ollama.com/install.sh | sh方…...