从一到无穷大 #44:AWS Glue: Data integration + Catalog
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Glue的历史,设计原则与挑战
- Serverless ETL 功能设计
- Glue Studio
- Glue ETL Library with DynamicFrames
- Serverless, Fast Startup, and Auto-scaling
- 存储计算解耦与性能加速
- Catalog 和 Crawler 设计
- 结束语
引言
在如今云产品赛道逐渐细分,如乐高积木一般的时代,时序数据库AP化于我而言带来的疑问是时间线爆炸场景下时序数据库的必要性何在?
一般的AP架构组件基本如下:
- S3 + ETL + RedShift
- S3 + Catalog(Glue or HiveMetaStore) + Athena or Presto
其实依赖现有组件搭建一个可用的,解决时间线爆炸问题的时序数据库非常容易,把数据打包成Parquet直接基于指定前缀格式写入到S3,Glue的爬虫直接识别Schema格式写入到Glue Catalog,上层直接用Presto或Athena这样的AP引擎直接查,如果再给S3做一层缓存加速,类似于ElastiCache[11]和腾讯云GooseFS,基本上性能不会有特别大差别,因为时间线爆炸也没有上倒排索引的必要(不管是Fst还是哈希结构都存在膨胀)。
现在看来,时间线形态的引擎其实有其存在的必要性,其次双引擎也是必要的。

回到论文来,Glue官方的定义是Data integration cloud service,我第一次认识到Glue其实是因为其一统了AWS的元数据管理市场,可以作为Hive,Trio,Spark,Athena的Catalog模块用于查询服务,但在研究了论文后,发现Glue其实是一个巨无霸系统,其至少包括以下重量级功能:
- Glue Studio:允许用户以可视化方式创建ETL脚本
- Glue ETL:Glue Runtime中的Dynamic Frame和Parquet Writer保证了其性能高于Spark,
ChoiceType确保其可以优雅解决单字段类型冲突;独特的资源管理器和WarmPool保证了Serverless的快启动和自动扩展;Decoupling Storage for Cloud Shufle可以降低用户的Worker使用量从而降低成本; - Glue Data Quality[12]:用于检测数据湖中的数据质量, It automatically computes statistics, recommends quality rules, and can monitor and alert you when it detects missing, stale, or bad data.
- Glue Data Catalog:基本兼容HiveMetaStore的Catalog服务
- Glue Crawler:Classifers推断文件的识别文件的类型和Schema,Finalizer负责基于前缀的相似性自动化识别Table与Partition
- Glue DataBrew[13]:Data preparation工具,允许250多种预构建转换中进行选择,不需要写一行代码,看起来是ETL的上层封装
论文中重点放在了三个点:
- Glue的历史,设计原则与挑战
- Serverless ETL 功能设计
- Catalog 和 Crawler 模块设计
这篇文章也从这三个点去做分析
Glue的历史,设计原则与挑战

Glue由2016年推出,随着数据类型和数据种类的激增,用于查询这些数据的系统层出不穷,但是缺乏简单的数据 discover, prepare 和 ETL工具。
开始时的设计约束如下:
- 第一条原则是为客户提供自助服务,让他们在系统出现问题时自行解决。例如,我们让客户可以轻松编写代码来定制他们的 ETL 管道,或直接编辑服务生成的脚本以满足他们的用例。
- 分析环境的异构性越来越强,不可能总是定义单一的数据模型、类型系统或查询语言来支持所有用例。Glue并不要求客户在开始使用之前将数据标准化,而是让他们使用现有的数据,即使这些数据不能在所有地方使用,这样他们就可以逐步采用 Glue 来处理新的应用和用例。
- 尽量减少无差异的工作,虽然我客户都是开发人员,但他们并不想花时间管理基础设施。
基本是以用户的易用性为设计原则。
以前的ETL系统有如下问题:
- Data Discovery and Ingest:相同的数据项在不同的问题之间存在类型不一致;与外部系统集成时需要解决各种网络隔离问题与鉴权问题;不同的源系统扩展性不同,需要客户自己限制ETL的速率防止源系统过载;
- Reliable Data Processing:可靠性十分重要,因为数据规模总会发生变化,因为一般测试使用的数据集远小于现网,会因为ETL机器内存或磁盘耗尽而失败;
- Output and Physical Layout:数据本身在S3这样的系统,为了查询时的分区裁剪,需要工具去管理分区,并在不均衡时重新分区;
Serverless ETL 功能设计
基本分为下面几个方面:
Glue Studio

为了让用户更容易开始使用 AWS Glue,Glue为 ETL 脚本构建了一个可视化 ETL 界面和代码生成机制。核心依赖于将 ETL 脚本作为 DAG。
上图显示了一个使用 Glue Studio UI 的示例,允许客户以可视化方式创建 ETL 脚本:
- 从S3 获取一个数据源
- 执行 ApplyMapping(用于restructure 或者 fatten nested objects)
- 将结果与Catalog中的一个表Join
- 将输出写入亚马逊 S3
Glue ETL Library with DynamicFrames

与传统Spark需要两次遍历(Schema推断+数据处理)不同,DynamicFrames通过延迟Schema计算实现了单次遍历处理。如上图所示,在处理GitHub时间线数据(包含751个动态属性)时,Glue的过滤+Parquet写入任务耗时仅为Spark DataFrame的66%(136GB数据集)。

其次传统Spark DataFrames要求预先定义静态Schema,而Glue的DynamicFrame采用了完全不同的设计哲学。其核心数据结构DynamicRecord采用树状存储结构,每个记录内嵌自描述元数据,支持灵活的模式演进。在Schema推断过程中,Glue引入了ChoiceType机制,能够自动识别字段的类型冲突(如某字段同时存在string和int类型值),并将其记录为联合类型。这种设计避免了传统Schema推断中的强制类型转换导致的数据丢失。
Serverless, Fast Startup, and Auto-scaling

Glue 1.0的集群冷启动需要等待完整集群(含Driver+Executors)的EC2实例分配,导致平均启动延迟超过8分钟(上图a),Glue 2.0引入分层资源池架构:
- Warm Pool预测模型:基于时间序列分析预测各区域/可用区的实例需求,预分配Spark执行环境
- 动态分阶段启动:Driver优先启动后立即开始任务调度,Executor按需动态加入
- Shuffle状态感知:通过扩展Spark的Shuffle Tracking机制,确保含中间状态的Executor不被提前终止
通过上述优化,Glue 4.0的作业启动P99延迟降至10秒内(上图b),支持秒级响应的交互式ETL开发。
存储计算解耦与性能加速

传统Spark Shuffle依赖本地磁盘存储中间数据,存在单点故障和扩展性限制。Glue的Cloud Shuffle Storage Plugin将中间结果写入S3,减少了用户的成本。

针对CSV/JSON解析的CPU瓶颈,Glue开发了C++原生向量化读取器
下面三点可以看论文:
- Glue Workfows & Incremental Processing
- Monitoring Pipelines and Data Quality
- Connectivity for Data Integration
Catalog 和 Crawler 设计
随着客户越来越多地在亚马逊 S3 等数据存储中构建和管理持久性数据湖,他们需要发现和管理数据集元数据的机制。查询引擎需要模式和数据位置等元数据来规划和执行查询,而客户也依赖元数据在大型企业中进行数据发现和管理。传统数据库将这些元数据存储在内部目录中,但在数据湖环境中,许多引擎都可用于查询相同的数据集,因此元数据必须与查询引擎分离。
开源社区率先在这一领域推出了 Hive metastore[15],它已成为 Hadoop 生态系统中元数据管理的事实标准。它为访问数据库、表和分区的元数据提供了一个通用接口,并得到 Apache Hive、Trino 和 Apache Spark 等开源查询引擎的广泛支持。虽然 Hive 元存储已被广泛部署并经过实践检验,但它也有一些局限性,使其不足以管理大型数据湖。首先,它成为数据湖管理员必须管理的另一个系统。Hive 元存储的标准实现使用关系数据库,客户需要负责元存储的配置、扩展和打补丁。此外,性能也是一个挑战,用户通常需要对大型 Hive 元存储进行分片,这又增加了一层复杂性。
论文中主要提到Catalog是Serverless且支持分区索引(允许用户把分区谓词下刷至Catalog)
Crawler逻辑上也好理解,Classifier做类型识别,Finalizer做Table与分区自动识别,为了实现自动化的核心假设是表中的分区可能具有相同或相似的模式,而两个不同表的模式可能有很大差异,以此分析不同路径的相似程度。
结束语
这篇文章的意义除了在于了解了一个新的云产品的设计理念和功能外,比较重要的一点是笃定了Catalog模块需要去适配开源协议[14][15][16],否则就让对象存储上的数据无法被用户的其他查询引擎和ETL工具使用了
参考:
- Data lake系列:Glue 功能简介-快速构建 Serverless ETL
- 使用 AWS Glue 和 Amazon S3 构建数据湖基础
- Data lake系列:快速构建基于 AWS Glue 的抽取跨区域 MySQL 8 的数据管道
- AWS Glue再研究
- AWS Glue OverReview
- AWS Glue 在数据湖仓中的应用
- AWS Glue 介绍
- AWS Glue 文档
- AWS Glue DynamicFrame class
- Apache Avro
- Turbocharge Amazon S3 with Amazon ElastiCache for Redis
- https://aws.amazon.com/glue/features/data-quality/
- https://aws.amazon.com/cn/glue/features/databrew/?nc1=h_ls
- AWS Glue Catalog API
- DataBricks MetaStore API
- Hive 文档
- https://cwiki.apache.org/confuence/display/hive/design#Design-Motivation
相关文章:
从一到无穷大 #44:AWS Glue: Data integration + Catalog
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言Glue的历史,设计原则与挑战Serverless ETL 功能设计Glue StudioGlue …...

【Redis】如何处理缓存穿透、击穿、雪崩
Redis 缓存穿透、击穿和雪崩是高并发场景下的典型问题,以下是详细解决方案和最佳实践: 一、缓存穿透(Cache Penetration) 问题:恶意请求不存在的数据(如不存在的ID),绕过缓存直接访…...

区块链技术如何重塑金融衍生品市场?
区块链技术如何重塑金融衍生品市场? 金融衍生品市场一直是全球金融体系的重要组成部分,其复杂性和风险性让许多投资者望而却步。然而,随着区块链技术的兴起,这一领域正在经历一场深刻的变革。区块链以其去中心化、透明和不可篡改…...
实战打靶集锦-35-GitRoot
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查5. 系统提权6. 写在最后 靶机地址:https://download.vulnhub.com/gitroot/GitRoot.ova 1. 主机发现 目前只知道目标靶机在192.168.56.xx网段,通过如下的命令,看看这个网段上在线的主机…...

Vue3 + Element Plus + AntV X6 实现拖拽树组件
Vue3 Element Plus AntV X6 实现拖拽树组件 介绍 在本篇文章中,我们将介绍如何使用 Vue 3 和 Element Plus 结合 antv/x6 实现树形结构的拖拽功能。用户可以将树节点拖拽到图形区域,自动创建相应的节点。我们将会通过简单的示例来一步步讲解实现过程…...

从零开始跑通3DGS教程:介绍
写在前面 本文内容 本文所属《从零开始跑通3DGS教程》系列文章,将实现从原始图像(有序、无序)数据开始,经过处理(视频抽帧成有序),SFM,3DGS训练、编辑、渲染等步骤,完整地呈现从原始图像到新视角合成的全部流程&#x…...

聊聊Spring AI的Chat Model
序 本文主要研究一下Spring AI的Chat Model Model spring-ai-core/src/main/java/org/springframework/ai/model/Model.java public interface Model<TReq extends ModelRequest<?>, TRes extends ModelResponse<?>> {/*** Executes a method call to …...

将mysql配置成服务的方法
第一步:配置环境变量 1)新建MYSQL_HOME变量,并配置:C:\Program Files\MySQL\MySQL Server 5.6 MYSQL_HOME:C:\Program Files\MySQL\MySQL Server 5.6 2)编辑path系统变量,将%MYSQL_HOME%\bin添加到path变量后。配置path环境变量…...
 存储引擎:ASTORE 与 USTORE 详细对比)
GaussDB(for PostgreSQL) 存储引擎:ASTORE 与 USTORE 详细对比
GaussDB(for PostgreSQL) 存储引擎:ASTORE 与 USTORE 详细对比 1. 背景说明 GaussDB(for PostgreSQL) 是华为基于 PostgreSQL 开发的企业级分布式数据库,其存储引擎分为 ASTORE 和 USTORE 两种类型,分别针对不同场景优化。 2. 核心对比 (1)…...

英语口语 -- 常用 1368 词汇
英语口语 -- 常用 1368 词汇 介绍常用单词List1 (96 个)时间类气候类自然类植物类动物类昆虫类其他生物地点类 List2 (95 个)机构类声音类食品类餐饮类蔬菜类水果类食材类饮料类营养类疾病类房屋类家具类服装类首饰类化妆品类 Lis…...

SpringBoot+Vue 中 WebSocket 的使用
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它使得客户端和服务器之间可以进行实时数据传输,打破了传统 HTTP 协议请求 - 响应模式的限制。 下面我会展示在 SpringBoot Vue 中,使用WebSocket进行前后端通信。 后端 1、引入 j…...
关于依赖注入框架VContainer DIIOC 的学习记录
文章目录 前言一、VContainer核心概念1.DI(Dependency Injection(依赖注入))2.scope(域,作用域) 二、练习例子1.Hello,World!步骤一,编写一个底类。HelloWorldService步骤二,编写使用低类的类。GamePresenter步骤三&am…...

LRU缓存是什么
LRU缓存是什么 LRU(Least Recently Used)即最近最少使用,是一种缓存淘汰策略。在缓存空间有限的情况下,当新的数据需要存入缓存,而缓存已满时,LRU 策略会优先淘汰最近最少使用的数据,以此保证缓存中存储的是最近最常使用的数据。 LRU缓存的工作原理 LRU 缓存的核心思…...
Qt常用控件第一部分
1.控件概述 Widget 是 Qt 中的核⼼概念. 英⽂原义是 "⼩部件", 我们此处也把它翻译为 "控件" . 控件是构成⼀个图形化界⾯的基本要素. 像上述⽰例中的, 按钮, 列表视图, 树形视图, 单⾏输⼊框, 多⾏输⼊框, 滚动条, 下拉框等, 都可以称为 "控件"…...

docker存储卷及dockers容器源码部署httpd
1. COW机制 Docker镜像由多个只读层叠加而成,启动容器时,Docker会加载只读镜像层并在镜像栈顶部添加一个读写层。 如果运行中的容器修改了现有的一个已经存在的文件,那么该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本依然存在,只是已经被读写层中该文件…...

JMeter接口自动化发包与示例
前言 JMeter接口自动化发包与示例 近期需要完成对于接口的测试,于是了解并简单做了个测试示例,看了看这款江湖上声名远播的强大的软件-Jmeter靠不靠谱。 官网:Apache JMeter - Apache JMeter™ 1简介 Apache-Jmeter是一个使用java语言编写且开源&…...

INFINI Console 极限控制台密码忘记了,如何重置?
在使用 INFINI Console(极限控制台)时,可能会遇到忘记密码的情况,这对于管理员来说是一个常见但棘手的问题。 本文将详细介绍如何处理 INFINI Console 密码忘记的情况,并提供两种可能的解决方案,帮助您快速…...

Python运算符的理解及简单运用
免责声明 如有异议请在评论区友好交流,或者私信 内容纯属个人见解,仅供学习参考 如若从事非法行业请勿食用 如有雷同纯属巧合 版权问题请直接联系本人进行删改 前言 提示:这里可以添加本文要记录的大概内容: 提示:以…...
汇编学习之《jcc指令》
JCC(Jump on Condition Code)指的是条件跳转指令,c中的就是if-else, while, for 等分支循环条件判断的逻辑。它包括很多指令集,各自都不太一样,接下来我尽量将每一个指令的c 源码和汇编代码结合起来看,加深…...

k8s的容器操作指令
几个命令目录 1、kubectl exec -n ithmp-prod -it <pod-name> /bin/bash命令组成部分使用场景注意事项 2、docker ps基本用法输出格式常用选项1. 列出所有容器(包括已停止的)2. 显示最近创建的容器3. 显示最近创建的几个容器4. 显示容器的详细信息…...
从零构建大语言模型全栈开发指南:第四部分:工程实践与部署-4.3.3低代码开发:快速构建行业应用(电商推荐与金融风控案例)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 从零构建大语言模型全栈开发指南-第四部分:工程实践与部署4.3.3 低代码开发:快速构建行业应用(电商推荐与金融风控案例)1. 低代码与AI结合的核心价值2. 电商推荐系统案例2.1 技术架构与实现2.2 性能…...

基于vue框架的智能服务旅游管理系统54kd3(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,景点信息,门票预订,酒店客房,客房预订,旅游意向,推荐景点,景点分类 开题报告内容 基于Vue框架的智能服务旅游管理系统开题报告 一、研究背景与意义 1.1 行业现状与挑战 传统系统局限性:当前旅游管理系统普遍存在信息…...
用Python实现TCP代理
依旧是Python黑帽子这本书 先附上代码,我在原书代码上加了注释,更好理解 import sys import socket import threading#生成可打印字符映射 HEX_FILTER.join([(len(repr(chr(i)))3) and chr(i) or . for i in range(256)])#接收bytes或string类型的输入…...
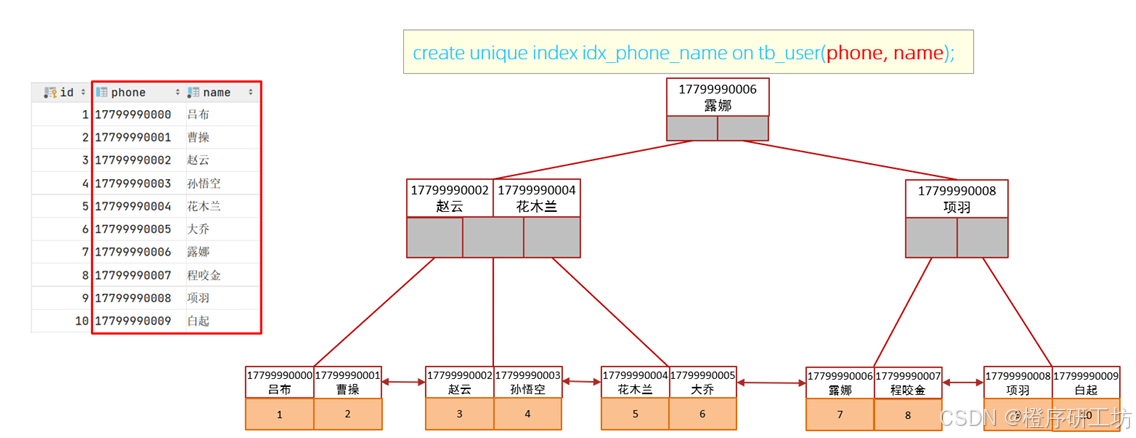
MySQL的进阶语法7(索引-B+Tree 、Hash、聚集索引 、二级索引(回表查询)、索引的使用及设计原则
目录 一、索引概述 1.1 基本介绍 1.2 基本演示 1.3 特点及优势 二、索引结构 2.1 概述 2.2 二叉树 2.3 B-Tree 2.4 BTree 2.5 Hash 2.5.1 结构 2.5.2 特点 2.5.3 存储引擎支持 三、索引的分类 3.1 索引分类 3.2 聚集索引和二级索引 3.2.1 聚集索引和二级…...

【CSS3】04-标准流 + 浮动 + flex布局
本文介绍浮动与flex布局。 目录 1. 标准流 2. 浮动 2.1 基本使用 特点 脱标 2.2 清除浮动 2.2.1 额外标签法 2.2.2 单伪元素法 2.2.3 双伪元素法(推荐) 2.2.4 overflow(最简单) 3. flex布局 3.1 组成 3.2 主轴与侧轴对齐方式 3.2.1 主轴 3.2.2 侧轴 3.3 修改主…...

内网环境将nginx的http改完https访问
原文参考链接:https://www.cnblogs.com/leilcoding/p/16138778.html 编写生成证书的脚本 vim gen-ssl.sh #!/bin/sh # create self-signed server certificate: read -p "Enter your domain [www.example.com]: " DOMAIN echo "Create server key…...
)
使用 libevent 处理 TCP 粘包问题(基于 Content-Length 或双 \r\n)
在基于 libevent 的 TCP 服务器开发中,处理消息边界是常见需求。以下是两种主流分包方案的完整实现: 一、基于 Content-Length 的分包方案 1.1 数据结构设计 typedef struct {struct bufferevent *bev;int content_length; // 当前消息的预期长度int received_bytes; //…...

论坛系统的测试
项目背景 论坛系统采用前后端分离的方式来实现,同时使用数据库 来处理相关的数据,同时将其部署到服务器上。前端主要有7个页面组成:登录页,列表页,论坛详情页,编辑页,个人信息页,我…...
宠物店小程序怎么做?助力实体店实现营销突破
宠物店小程序怎么做?助力实体店实现营销突破 ——一个宠物店老板的“真香”实战分享 一、行业现状:线下宠物店的“流量焦虑” 作为开了3年宠物店的“铲屎官供应商”,这两年明显感觉生意难做了:某宝9.9包邮的狗粮、某团“满…...
《Mycat核心技术》第21章:高可用负载均衡集群的实现(HAProxy + Keepalived + Mycat)
作者:冰河 星球:http://m6z.cn/6aeFbs 博客:https://binghe.gitcode.host 文章汇总:https://binghe.gitcode.host/md/all/all.html 星球项目地址:https://binghe.gitcode.host/md/zsxq/introduce.html 沉淀,…...