【AI学习】机器学习算法
1,线性回归模型(Linear Regression):预测连续数值
寻找自变量(解释变量)与因变量(被解释变量)之间的线性关联关系,通过构建线性方程来对数据进行拟合和预测。即两个变量之间是一次函数关系:图像是直线的。
1)一元线性回归

- y:因变量(预测目标)
- x:自变量(输入特征),
- β0:截距项,表示当 x=0时 y的取值(在实际应用中需根据具体情况解释其意义);
- β1:是回归系数,体现了自变量
x每变化一个单位时,因变量 y的平均变化量。 ϵ:随机误差项,用于涵盖模型未考虑到的其他微小影响因素以及测量误差等,通常假设其服从均值为 0、方差为某定值的正态分布。
2)多元线性回归
在存在多个自变量 x1,x2,⋯,xn的情况下,模型表达式拓展为:

βi(i=1,2,⋯,n)分别对应各个自变量的回归系数,反映了相应自变量对因变量 y的影响程度。
3)损失函数(loss function、cost funciton)
如何衡量模型是以最优方式拟合数据的呢?通过loss function来衡量,它衡量了模型预测值与真实值之间的差异程度。loss function越大,模型越差,越不能拟合。
此时,机器学习的过程被化解成对损失函数求最优解的过程。
1>最小二乘法(Least Squares Method)
通过最小化观测值(实际数据中的因变量取值)与模型预测值(由线性方程计算得到)之间的误差平方和,来确定最优的回归系数β0,β1,⋯,βn。
从数学角度来看,就是要最小化目标函数:
 (其中 m 为样本数量)。通过对该目标函数分别关于各个回归系数求偏导数,并令偏导数等于 0,进而求解出使得目标函数达到最小值的回归系数值。
(其中 m 为样本数量)。通过对该目标函数分别关于各个回归系数求偏导数,并令偏导数等于 0,进而求解出使得目标函数达到最小值的回归系数值。
对于一些复杂情况下,使用梯度下降法(Gradient Descent)及其变种(如随机梯度下降、小批量梯度下降等)来逐步更新回归系数,使其朝着使误差平方和减小的方向迭代优化,最终收敛到一个较优的解。
2>均方误差(Mean Squared Error,MSE)
定义:计算预测值与真实值之间误差的平方的平均值,公式为:

特点:MSE 的值越小,说明模型预测的平均误差越小,模型的准确性越高。不过由于对误差进行了平方运算,它对较大误差的惩罚力度更大,在一些对异常值敏感的场景中需要谨慎使用。
3>平均绝对误差(Mean Absolute Error,MAE)
定义:计算预测值与真实值之间误差绝对值的平均值,公式为:

特点:相比于 MSE,MAE 对异常值相对没那么敏感,因为它只是取了误差的绝对值,更直观地反映了预测误差的平均大小,能在一定程度上体现模型预测的精准程度。
5>均方根误差(Root Mean Squared Error,RMSE)
定义:是 MSE 的平方根,即

特点:与 MSE 类似,衡量模型预测误差的大小,其单位和因变量的单位一致,在实际应用中便于和真实值的量级进行直观对比,解释性相对较好。
4)场景
- 经济学领域:
例如预测商品的销售量与价格、收入等因素之间的关系,帮助企业制定定价策略和生产计划。 - 医学领域:
分析患者的某些生理指标(如血压、血糖等)与年龄、生活习惯等自变量之间的关系,辅助疾病诊断和治疗方案制定。 - 市场营销领域:
研究广告投入、市场推广活动等自变量与产品销售额、品牌知名度等因变量之间的关系,以便合理安排营销资源。
5)代码实现
6)实验分析
2,逻辑回归模型(Logistic Regression):解决分类问题
结合了线性回归的思想与非线性的激活函数,将输入特征进行线性组合后,通过特定的函数映射,输出为样本属于各类别的概率,进而依据概率进行分类决策。
1)原理
- 构建输入特征的线性组合
 其中:
其中:
x1,x2,⋯,xnn 个输入特征;
β1,β2,⋯,βn对应的模型参数(回归系数);
β0截距项;
z中间变量。 - 激活函数(Sigmoid 函数、Softmax 回归)
非线性变换。
2)场景
- 分类问题
有效地处理二分类以及多分类任务。
3,聚类算法
无监督学习算法,旨在将数据集中的样本按照相似性或距离等度量方式划分成不同的组(簇),使得同一簇内的样本尽可能相似,而不同簇之间的样本尽可能不同。
1)K-Means 算法
预先指定要划分的簇的数量 k,然后随机初始化 k 个聚类中心(质心),接着通过不断迭代计算每个样本到各个质心的距离(通常采用欧几里得距离),将样本划分到距离最近的质心所在的簇中,之后重新计算每个簇的质心(即簇内样本的均值),重复这个过程直到质心不再发生明显变化或者达到预设的迭代次数为止。
2)K-Medoids 算法
与 K-Means 类似,不过它选取的质心必须是数据集中实际存在的样本点(称为 medoid),而不是像 K-Means 那样可以是虚拟的均值点。相比来说不易受极端值影响。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
基于数据点的密度来进行聚类,它最大的特点是不需要预先指定聚类的簇数,能够发现任意形状的簇,并且可以识别出数据集中的噪声点(即不属于任何簇的孤立点),对于处理非球形、分布不均匀的数据有很好的效果
4,决策树(Decision Tree):分类算法
是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模型,每一条从根结点(对最终分类结果贡献最大的属性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。
1)基本结构

- 根节点(Root Node)
决策树的起始节点,包含了整个数据集,是决策树开始进行特征判断的地方。 - 内部节点(Internal Nodes)
位于根节点和叶节点之间,每个内部节点都对应一个特征以及该特征的一个划分条件(比如特征值大于某个数值或者等于某个类别等),根据这个条件将数据样本划分到不同的子节点。 - 叶节点(Leaf Nodes)
决策树的末端节点,也称为终端节点,不再有子节点,每个叶节点对应着一个决策结果,在分类问题中就是具体的类别,在回归问题中则是一个预测的数值。
5,集成算法(Ensemble Learning)
结合多个基学习器(可以是决策树、神经网络等基础模型)来提升模型的整体性能。
6,支持向量机(Support Vector Machine,SVM):分类算法
是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。
1)当训练样本线性可分时
- 通过硬间隔最大化,学习一个线性可分支持向量机
即存在一个超平面能将不同类别的样本完全分开。 - 支持向量机的目标就是找到一个最优的超平面,使得不同类别的样本能够被尽可能清晰地分开,并且这个超平面到两类样本的最近距离(间隔)最大。这个最大间隔超平面可以用以下方程表示:
 其中w是超平面的法向量,b是偏置项。距离超平面最近的样本点被称为支持向量,它们决定了超平面的位置和方向。
其中w是超平面的法向量,b是偏置项。距离超平面最近的样本点被称为支持向量,它们决定了超平面的位置和方向。
2)当训练样本近似线性可分时
通过软间隔最大化,学习一个线性支持向量机
3)当训练样本线性不可分时
学习一个非线性支持向量机的方法:
- 核技巧
将原始特征空间映射到一个更高维的特征空间,使得数据在新的空间中变得线性可分,从而简化计算过程。 - 软间隔
允许在一定程度上存在分类错误,通过引入松弛变量ξi来衡量样本点偏离正确分类的程度。
4)场景
- 图像识别
用于图像分类、目标检测等任务,例如识别手写数字、区分不同种类的动物等。 - 文本分类
对新闻文章、电子邮件等文本进行分类,如将新闻分为体育、政治、娱乐等类别。 - 生物信息学
在基因表达数据分析、蛋白质结构预测等方面有广泛应用。
7,神经网络
8,贝叶斯(Bayes)
1)贝叶斯定理
贝叶斯定理是整个贝叶斯理论的核心基础,本质是基于先验知识(先验概率),结合新观察到的证据(似然概率),来更新对某一事件发生概率的判断(得到后验概率)。
其数学表达式为:

P(A∣B) 表示在事件 B 发生的条件下,事件 A 发生的概率,被称为后验概率(Posterior Probability)。
P(B∣A) 是在事件 A 发生的条件下,事件 B 发生的概率,称作似然概率(Likelihood Probability)。
P(A) 为事件 A 发生的先验概率(Prior Probability),即在没有考虑任何其他证据(如事件 B )之前,对事件 A 发生可能性的估计。
P(B) 是事件 B 发生的概率,通常可通过全概率公式等方法来计算,在分母位置起到归一化作用。
2)贝叶斯分类器
- 多项式朴素贝叶斯(Multinomial Naive Bayes)
常用于文本分类任务,它假设特征是服从多项式分布的,比如在文本分类中,把文本中的单词看作特征,单词出现的次数作为特征值,根据文本属于不同类别(如新闻分类中的体育、娱乐等类别)的样本中单词出现的频次来统计条件概率,进而进行分类。 - 高斯朴素贝叶斯(Gaussian Naive Bayes)
适用于特征是连续数值的情况,假设各特征在给定类别下服从高斯分布(正态分布),通过训练数据估计出每个类别下各特征的均值和方差,以此来计算条件概率,常用于处理如医学数据中患者的生理指标(血压、血糖等)分类等场景。 - 伯努利朴素贝叶斯(Bernoulli Naive Bayes)
主要针对特征是二值(0 或 1)的情况,例如判断一封邮件是否为垃圾邮件,把邮件中的单词是否出现看作特征(出现为 1,未出现为 0),依据不同类别(垃圾邮件和正常邮件)中单词出现与否的统计情况来计算概率并分类。
9,关联规则(Association Rules)
是数据挖掘领域中的一种重要分析方法,用于发现数据集中不同项之间的有趣关联关系。
1)基本概念
一般表示为 X⇒Y 的形式,其中 X 和 Y 都是项集,且 X 和 Y 的交集为空集,即 X∩Y=∅。它的含义是如果事务中包含了项集 X,那么很有可能也包含项集 Y。例如,在购物场景下,{面包,牛奶}⇒{鸡蛋}表示购买了面包和牛奶的顾客,很有可能也会购买鸡蛋。
事务(Transaction)
在关联规则分析的语境中,事务通常是指一次数据记录行为,例如一次购物行为(包含购买的商品列表)、一次网页浏览记录(浏览的网页集合)等,它是关联规则挖掘的基本单元,可以看作是一个包含若干项的集合。
项(Item):
是事务中的元素,比如在购物场景中,一件商品就是一个项,像苹果、香蕉、牛奶等都可以是单独的项。
项集(Itemset):
由若干个项组成的集合,例如{苹果,香蕉}就是一个包含两个项的项集。如果一个项集包含的项的数量为 k,则称其为 k- 项集。
2)常用度量指标
- 支持度(Support):规则普遍性;
用于衡量项集在整个数据集中出现的频繁程度。
支持度反映了规则的普遍性,支持度越高,说明该规则在数据集中出现得越频繁。 - 置信度(Confidence):规则可靠性;
用于衡量在包含项集 X 的事务中,同时也包含项集 Y 的概率,也就是规则的可靠性程度。关联规则 X⇒Y 的置信度计算公式为:

它表示当 X 出现时,Y 出现的概率。例如,若 面包牛奶鸡蛋,意味着购买了面包和牛奶的顾客中,有 60% 的人也购买了鸡蛋。 - 提升度(Lift):
用来衡量关联规则中 X 和 Y 的关联性强弱,考虑了项集 X 和 Y 在整个数据集中的独立出现概率以及它们同时出现的概率之间的关系。
10,词向量(Word Embedding)
NLP的应用中,将自然语言中的字词转化为向量形式,使得语义上相似的单词在向量空间中的距离相近,从而通过向量间的计算(比如余弦相似度等)来衡量词与词之间的语义关联程度。
1)word2vec
是Google于2013年开源推出的一个用于获取词向量(word vector)的工具包。
从大量文本预料中以无监督方式学习语义知识的模型。
11,推荐系统
推荐系统通过分析用户的历史行为(如购买记录、浏览记录、评分等)、用户画像(包括年龄、性别、兴趣爱好等属性)以及待推荐内容的特征(比如商品的属性、视频的类型等),运用特定的算法和模型,预测用户可能感兴趣的物品或内容,然后将这些推荐给用户,帮助用户从海量的信息中快速发现对自己有价值的部分。
1)基于用户的协同过滤
先找到与目标用户兴趣爱好相似的其他用户群体(通常通过计算用户之间的相似度,比如余弦相似度,依据用户对物品的评分、浏览等行为来衡量),然后参考这些相似用户喜欢的物品,将目标用户尚未接触过的物品推荐给他。
2)基于物品的协同过滤
重点关注物品之间的相似性,通过分析不同用户对物品的评价、购买等行为,来判断物品之间的关联程度。比如很多购买了手机 A 的用户也同时购买了手机壳 B,那就说明手机 A 和手机壳 B 之间有较高的关联性,当有新用户购买了手机 A 时,就可以向其推荐手机壳 B。
3)缺点
难以挖掘出用户潜在的、跨领域的兴趣,容易陷入推荐内容过于单一、同质化的问题,因为它主要基于物品自身特征进行推荐,忽视了用户行为的多样性。
4)关键技术与算法
- 数据挖掘技术
- 机器学习算法
聚类算法、分类算法、深度学习算法
12,主成分分析(Principal Component Analysis,简称 PCA):降维算法
是一种多元统计分析方法,通过线性变换,将原始数据中可能存在相关性的多个变量,转换为一组相互独立的综合变量,也就是主成分。这些主成分是按照方差从大到小依次排列的,在尽可能保留原始数据信息的同时,实现数据的降维和特征提取。
1)原理
- 数据标准化:
对原始数据进行标准化处理,消除不同变量在量纲和取值范围等方面的差异,便于后续计算。
常见的标准化方法有零均值标准化等,即让每个变量的均值变为 0,方差变为 1。 - 计算协方差矩阵:
协方差能够反映两个变量之间的线性相关程度,协方差矩阵则综合体现了所有变量两两之间的相关性情况。 - 求解特征值与特征向量:
对协方差矩阵进行特征值分解,得到相应的特征值和特征向量。特征值表示对应主成分所包含的信息量(方差大小),特征向量则确定了主成分的方向。 - 确定主成分个数:
通常根据特征值的大小来选择主成分个数。常见的方法有累计方差贡献率法,即选择使得累计方差贡献率达到一定比例(如 85% 等)的前几个主成分;或者根据特征值大于 1 的原则来选取等。 - 生成主成分得分:
将原始数据投影到选定的主成分对应的特征向量上,得到各样本在主成分上的得分,也就是通过线性变换将原始数据转换为了主成分表示的数据。
13,降维算法
1)主成分分析(PCA)
1>场景:
数据可视化、图像识别、基因数据分析等众多领域,例如将高维的基因表达数据降维,便于找出关键的基因特征组合。
2)线性判别分析(LDA)
与 PCA 不同,LDA 是一种有监督的降维方法,它的目标是寻找能够最大化类间距离、最小化类内距离的投影方向,使得降维后的数据在新的低维空间中不同类别之间区分度更好,基于类别的均值、协方差等统计量来计算投影方向。
1>场景
常用于分类任务中的特征降维,比如在人脸识别中,将人脸图像数据降维,使得不同人的人脸特征在低维空间更易区分,提高分类准确率。
3)局部线性嵌入(LLE)
是一种非线性降维方法,它假设数据在局部是线性的,通过构建每个数据点的局部邻域关系,然后寻找能保持这种局部线性关系的低维嵌入表示,计算过程涉及到求解局部权重矩阵以及全局优化等步骤。
1>场景
适用于处理具有复杂流形结构的数据,像在高维的图像数据、生物医学数据中,当数据分布呈现非线性流形时,LLE 可以有效提取低维特征。
4)等距映射(Isomap)
同样属于非线性降维算法,基于流形学习理论,它利用测地线距离(即流形上两点间的最短距离)来代替欧式距离构建数据点之间的距离关系,进而找到能保持这种距离关系的低维嵌入,通过构建邻域图、计算最短路径等方式来实现。
1>场景
在处理图像识别、机器人运动轨迹分析等领域中,当需要考虑数据的内在几何结构时,Isomap 能挖掘出更符合实际的低维特征。
5)多维缩放(MDS)
保持原始数据点之间的距离关系,在低维空间中找到对应的点,使得低维空间中点的距离与原始高维空间中点的距离尽可能相似,通过对距离矩阵进行特征值分解等操作来确定低维坐标。
1>场景
在心理学、社会学等领域的数据分析中,例如分析不同个体对多种事物的态度相似性,通过 MDS 降维可视化不同个体间的关系。
14,隐马尔科夫模型(Hidden Markov Model,简称 HMM):统计模型
由马尔科夫链扩展而来,它包含了两个随机过程:
- 隐藏的状态序列,其状态转移满足马尔科夫性质,即下一时刻的状态只依赖于当前时刻的状态,与更早的状态无关;
- 与隐藏状态相关联的可观测序列,通过隐藏状态按照一定的概率关系产生可观测值。
相关文章:
【AI学习】机器学习算法
1,线性回归模型(Linear Regression):预测连续数值 寻找自变量(解释变量)与因变量(被解释变量)之间的线性关联关系,通过构建线性方程来对数据进行拟合和预测。即两个变量之间是一次函…...
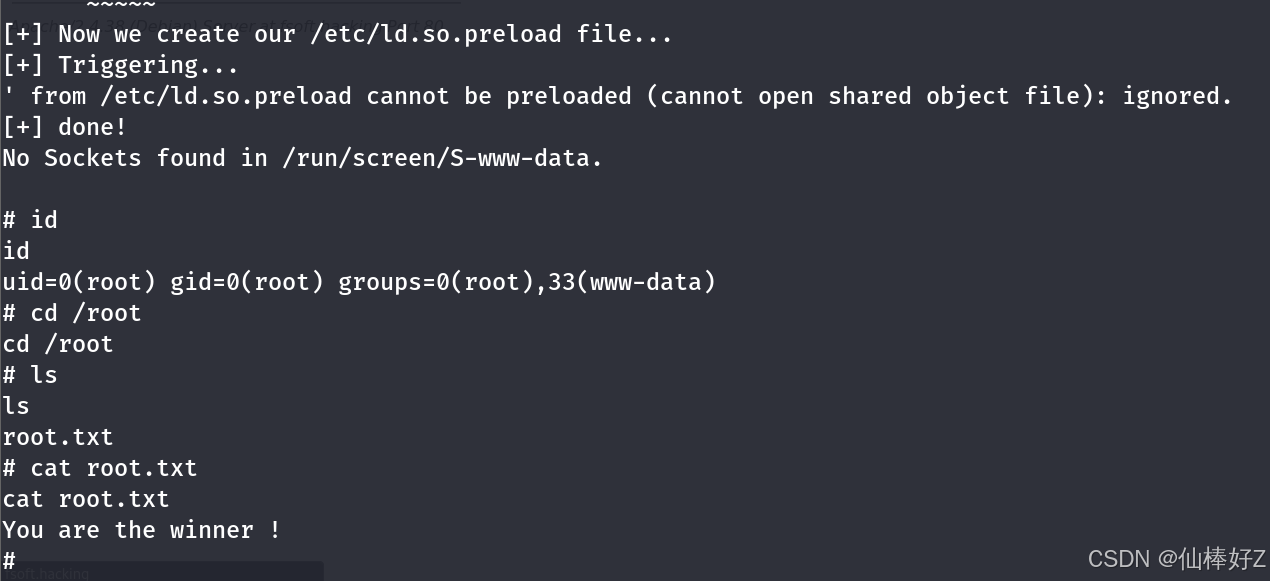
【渗透测试】Vulnhub靶机-FSoft Challenges VM: 1-详细通关教程
下载地址:https://www.vulnhub.com/entry/fsoft-challenges-vm-1,402/ 目录 前言 信息收集 目录扫描 wpscan扫描 修改密码 反弹shell 提权 思路总结 前言 开始前注意靶机简介,当第一次开机时会报apache错误,所以要等一分钟后重启才…...
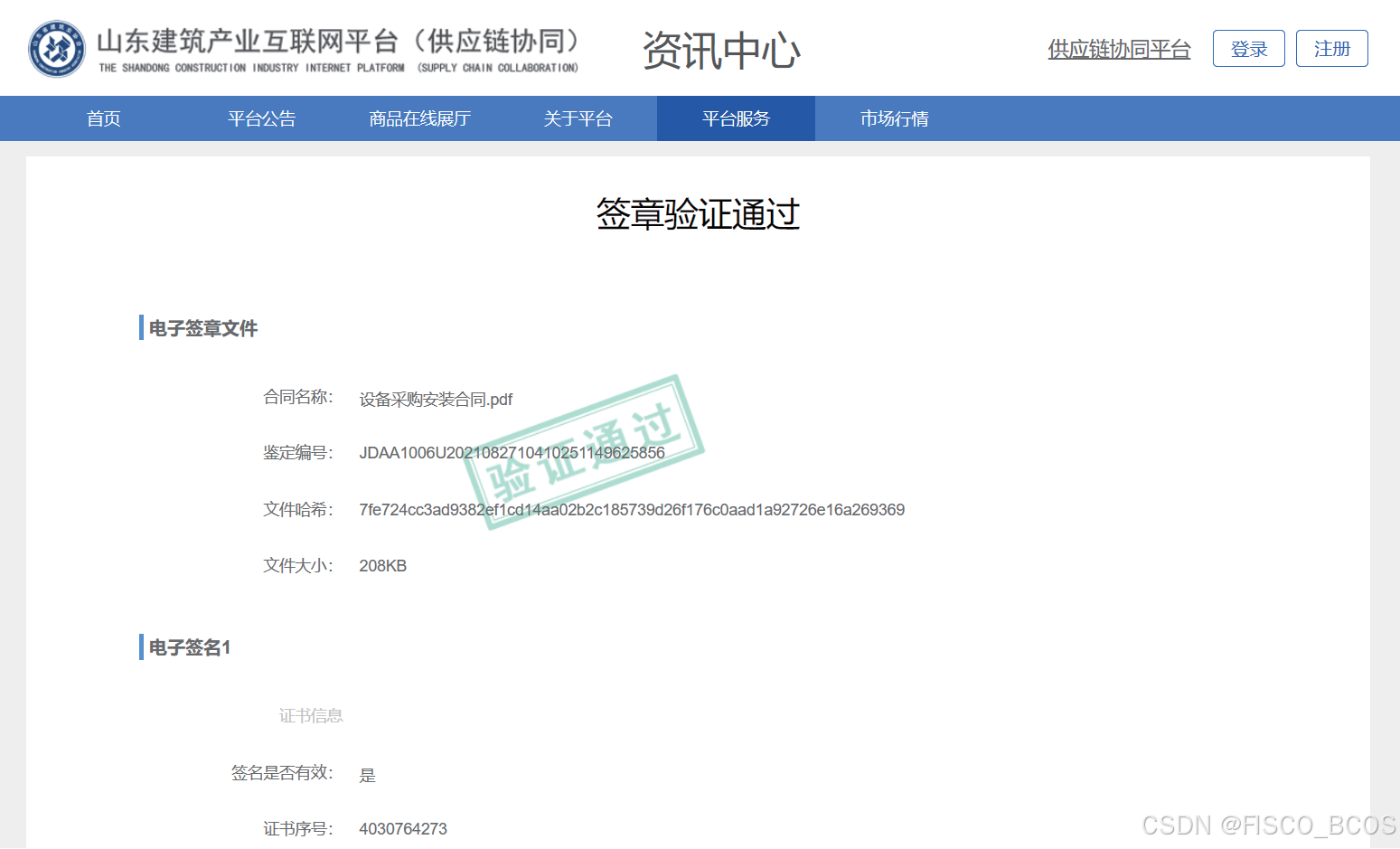
【区块链+ 房产建筑】山东省建筑产业互联网平台 | FISCO BCOS 应用案例
山东省建筑产业互联网平台(山东省弘商易盟平台)是基于区块链技术构建的分布式产业互联网平台, 旨在把各企业内部的供应链协同管理系统(包括采购或者SRM 系统, 以及销售或CRM 系统)利用区块链技术链接起来&a…...

Node.js全局生效的中间件
目录 1. 目录结构 2. 代码实现 2.1 安装Express 2.2 app.js - 主文件 2.3 globalMiddleware.js - 全局中间件 3. 程序运行结果 4. 总结 在Node.js的Express框架中,全局生效的中间件是指应用程序启动后,对所有请求都有效的中间件。它通常用于日志记…...

国家天文台携手阿里云,发布国际首个太阳大模型“金乌”
2025年4月1日,中国科学院国家天文台与阿里云共同宣布推出全球首个太阳物理大模型“金乌”,在太阳活动预测领域实现颠覆性突破——其针对破坏性最强的M5级太阳耀斑预报准确率高达91%,远超传统数值模型,标志着人类对太阳的认知迈入“…...

数据结构(5)——栈
目录 前言 一、栈的概念及其结构 二、栈的实现 2.1说明 2.2动态栈结构体定义 2.3初始化 2.4销毁 2.5进(压)栈 2.6检验栈是否为空 2.7弹(出)栈 2.8栈的元素个数 2.9访问栈顶元素 三、运行 总结 前言 栈是一种常见的…...
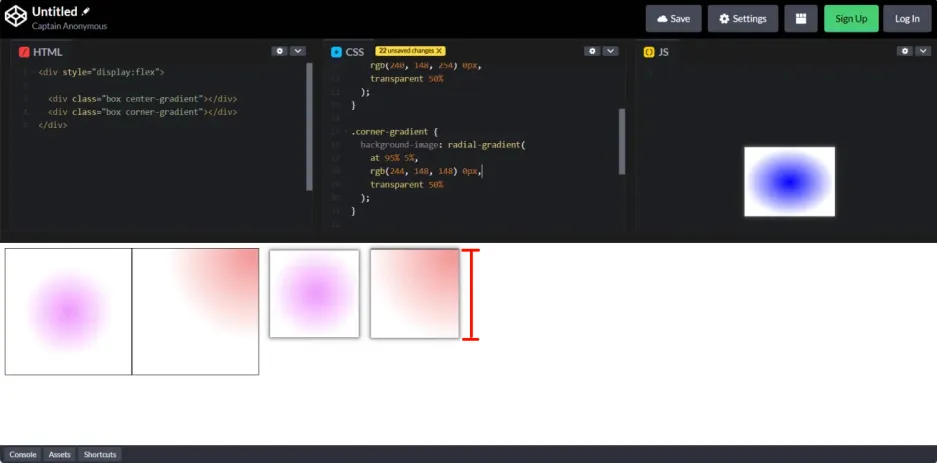
Css径向渐变 - radial-gradient
由background-image: radial-gradient(at 75% 7%, blue 0px, transparent 50%);引出: 一、径向渐变是什么 径向渐变是颜色从一个中心点向外扩散的变化过程。 二、radial-gradient 函数是什么 1、使用语法: background-image: radial-gradient(shape si…...

理解激活函数,多个网络层之间如何连接
1. 激活函数如何在两个层之间作用 如果不在两个层之间添加激活函数,模型将无法学习非线性关系,表现出像线性模型一样的局限性。 LeakyReLU(0.2) 是一个激活函数,它的作用是对每一层的输出进行非线性转换。激活函数通常在神经网络中用于增加网…...

HTML5 Canvas绘画板项目实战:打造一个功能丰富的在线画板
HTML5 Canvas绘画板项目实战:打造一个功能丰富的在线画板 这里写目录标题 HTML5 Canvas绘画板项目实战:打造一个功能丰富的在线画板项目介绍技术栈核心功能实现1. 画板初始化与工具管理2. 多样化绘画工具3. 事件处理机制 技术要点分析1. Canvas上下文优化…...

2025亲测有用 yolov8 pt转onnx转ncnn 部署安卓
参考文章:pt转onnx转ncnn模型(yolov8部署安卓)_best.pt 转ncnn模型-CSDN博客 Yolov8-Ncnn模型部署Android,实现单一图片识别_yolov8转ncnn-CSDN博客 onnx转化为ncnn这条路径现在已经落后了,更多的是通过pnnx转化为nc…...

cursor的.cursorrules详解
文章目录 1. 文件位置与作用2. 基本语法规则3. 常用规则类型与示例3.1 忽略文件/目录3.2 限制代码生成范围3.3 自定义补全建议3.4 安全规则 4. 高级用法4.1 条件规则4.2 正则表达式匹配4.3 继承规则 5. 示例文件6. 注意事项 Cursor 是一款基于 AI 的智能代码编辑器,…...

MySQL 入门大全:运算符
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
>)
Oracle数据库数据编程SQL<3.6 PL/SQL 包(Package)>
包是Oracle数据库中一种重要的PL/SQL程序结构,它将逻辑相关的变量、常量、游标、异常、过程和函数组织在一起,提供了更好的封装性和模块化。在大型项目中,可能有很多模块,而每一个模块又有自己的存过、函数等。而这些存过、函数默认是放在一起的,如果所有的存过函数都是放…...

Rust 语言语法糖深度解析:优雅背后的编译器魔法
之前介绍了语法糖的基本概念和在C/Python/JavaScript中的使用,今天和大家讨论语法糖在Rust中的表现形式。 程序语言中的语法糖:让代码更优雅的甜味剂 引言:语法糖的本质与价值 语法糖(Syntactic Sugar) 是编程语言中那些并不引入新功能&…...

React-Markdown详解
React-Markdown 详解(2025年最新实践指南) 一、核心特性与架构解析 React-Markdown 是一个基于 React 的 Markdown 渲染组件库,其核心设计理念是通过 Unified 生态系统实现安全、可扩展的 Markdown 解析。关键特性包括: 安全渲染…...

uniapp 微信小程序 使用ucharts
文章目录 前言一、组件功能概述二、代码结构分析2.1 模板结构 总结 前言 本文介绍一个基于 Vue 框架的小程序图表组件开发方案。该组件通过 uCharts 库实现折线图的绘制,并支持滚动、缩放、触摸提示等交互功能。文章将从代码结构、核心方法、交互实现和样式设计等方…...

mysql中将外部文本导入表中过程出现的错误及解决方法
问题一: MySQL Loading local data is disabled; this must be enabled on both the client and server sides (MySQL加载本地数据被禁用;这必须在客户端和服务器端同时启用) 解决方法: 1,依次输入以下命令…...

C#实现HiveQL建表语句中特殊数据类型的包裹
用C#实现搜索字符串中用’(‘和’)‘包裹的最外层的里面里面的字符串,将里面的记录按一个或多个空格、换行或tab,或者是它的在一起的组合作为分隔,分隔出多个字符串组,如果组中有字符串中同时包含’<‘和’>’,则…...

【idea】实用插件
SonarLint SonarLint:代码质量扫描工具 使用 SonarLint 可以帮助我们发现代码的问题,并且还提供了相应的解决方案. 对于每一个问题,SonarLint 都给出了示例,还有相应的解决方案,教我们怎么修改,极大的方便了我们的开发…...

关于mysql 数据库中的 慢SQL 的详细分析,包括定义、原因、解决方法及表格总结
以下是关于 慢SQL 的详细分析,包括定义、原因、解决方法及表格总结: 1. 什么是慢SQL? 定义: 慢SQL 是指执行时间超过预设阈值(如 2 秒)的 SQL 语句,通常会导致数据库响应延迟、资源占用过高&am…...

uniapp选择文件使用formData格式提交数据
1. Vue实现 在vue项目中,我们有个文件,和一些其他字段数据需要提交的时候,我们都是使用axios 设置请求头中的Content-Type: multipart/form-data,然后new FormData的方式来进行提交。方式如下: const sendRequest = () => {const formData = new FormData()formData…...

蓝牙数字音频和模拟音频优劣势对比?
蓝牙模块中我们常说的模拟音频和数字音频,是指两种不同的信号处理技术,它们都可以实现声音的录制、存储、编辑、压缩或播放,但也有一些区别和特点。本文将为您深入解析蓝牙数字音频和模拟音频的一些常见区别。 数字音频: 蓝牙数…...

WiFi(无线局域网)技术的多种工作模式
WiFi(无线局域网)技术支持多种工作模式,以满足不同的网络需求和应用场景。以下是主要的WiFi工作模式及其详细说明: 1. 基础设施模式(Infrastructure Mode) [无线接入点 (AP)]/ | \ [客户端…...

基于OpenCV的指纹验证:从原理到实战的深度解析
指纹识别的技术革命与OpenCV的轻量级方案 在生物特征识别领域,指纹识别始终以独特性和稳定性占据核心地位。随着OpenCV等开源视觉库的普及,这项看似"高大上"的技术正逐步走向民用化开发。本文将突破传统算法框架,提出一套基于OpenC…...

VMware+Ubuntu+VScode+ROS一站式教学+常见问题解决
目录 一.VMware的安装 二.Ubuntu下载 1.前言 2.Ubuntu版本选择 三.VMware中Ubuntu的安装 四.Ubuntu系统基本设置 1.中文更改 2.中文输入法更改 3. 辅助工具 vmware tools 五.VScode的安装ros基本插件 1.安装 2.ros辅助插件下载 六.ROS安装 1.安装ros 2.配置ROS…...

音视频(一)ZLMediaKit搭建部署
前言 一个基于C11的高性能运营级流媒体服务框架 全协议支持H264/H265/AAC/G711/OPUS/MP3,部分支持VP8/VP9/AV1/JPEG/MP3/H266/ADPCM/SVAC/G722/G723/G729 1:环境 ubuntu22.* ZLMediaKit downlaod:https://github.com/ZLMediaKit/ZLMediaKit or https://g…...

leetcode25.k个一组翻转链表
思路源自 【力扣hot100】【LeetCode 25】k个一组翻转链表|虚拟节点的应用 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val val; }* ListNode(in…...
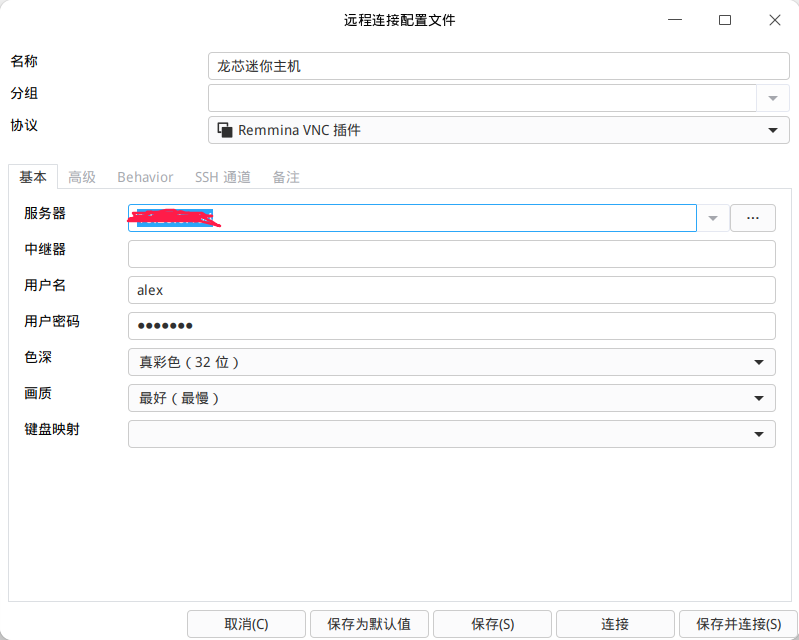
配置 UOS/deepin 系统远程桌面,实现多台电脑协同办公
由于开发工作的需要,我的办公桌上目前有多台电脑。一台是 i7 配置的电脑,运行 UOS V20 系统,作为主力办公电脑,负责处理企业微信、OA 等任务,并偶尔进行代码编译和验证软件在 UOS V20 系统下的兼容性;另一台…...

配置Next.js环境 使用vscode
配置 Next.js 的开发环境其实非常简单,下面是一个从零开始的完整步骤,适用于 Windows、macOS 和 Linux: ✅ 一、准备工作 确保你已经安装了以下软件: 1. Node.js(推荐 LTS 版本) 官网:https:/…...
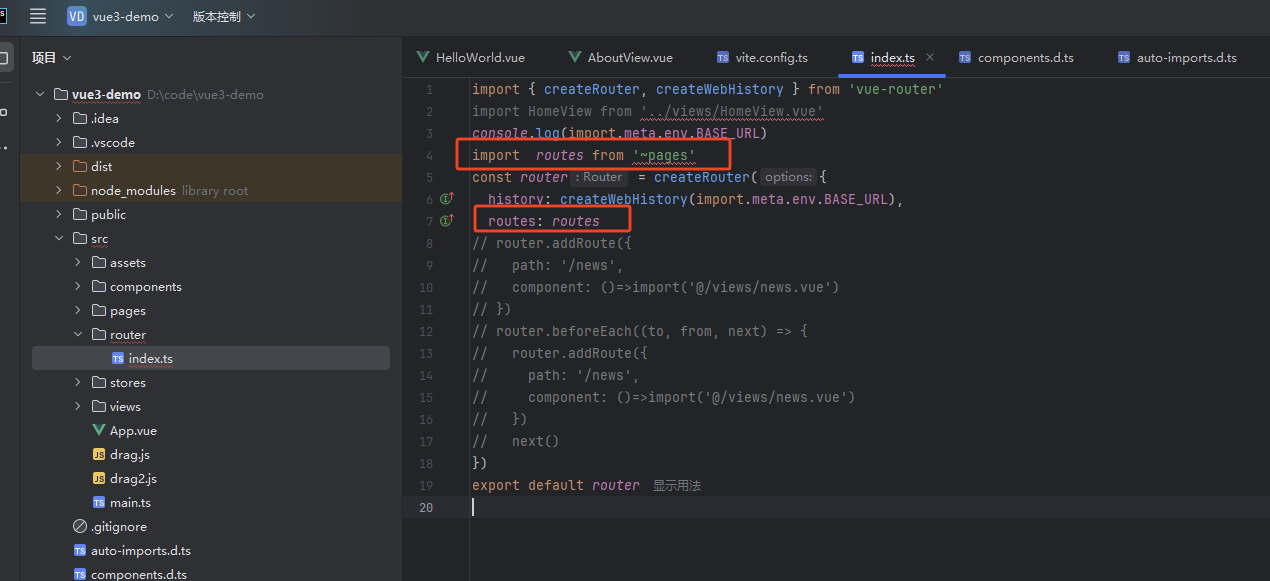
Vite相关知识点
一、自动导入vue vue-router pinia 1、安装unplugin-auto-import npm install unplugin-auto-import -D 2、引入 import AutoImport from unplugin-auto-import/vite; 3、配置vite.config.ts plugins: [ vue(), vueDevTools(), AutoImport({ include: [ /…...