《AI大模型应知应会100篇》加餐篇:LlamaIndex 与 LangChain 的无缝集成
加餐篇:LlamaIndex 与 LangChain 的无缝集成
问题背景:在实际应用中,开发者常常需要结合多个框架的优势。例如,使用 LangChain 管理复杂的业务逻辑链,同时利用 LlamaIndex 的高效索引和检索能力构建知识库。本文在基于 第56篇:LangChain快速入门与应用示例和 第57篇:LlamaIndex使用指南:构建高效知识库基础上,通过 cmd方式集成、基于Streamlit UI集成、基于Ollama本地大模型集成 三个步骤以实战案例展示如何将两者无缝集成,构建一个智能客服系统,抛砖引玉、以飨读者。

1. LlamaIndex 与 LangChain CMD界面集成
完整代码案例
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever# Step 1: 使用 LlamaIndex 构建知识库索引
# 数据加载:从本地目录加载文档
documents = SimpleDirectoryReader("./knowledge_base").load_data()# 创建向量索引
index = VectorStoreIndex.from_documents(documents)# 初始化检索器
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)# 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=retriever)# Step 2: 使用 LangChain 构建对话链
# 定义提示模板
prompt = ChatPromptTemplate.from_messages([("system", "你是一个智能客服助手,以下是相关文档内容:\n{context}"),("human", "{query}")
])# 初始化大模型
llm = ChatOpenAI(model="gpt-4o")# 将 LlamaIndex 查询引擎嵌入到 LangChain 链中
def retrieve_context(query):response = query_engine.query(query)return response.response# 构建 LangChain 链路
chain = ({"context": RunnablePassthrough() | retrieve_context, "query": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)# Step 3: 执行查询
query = "公司2023年的主要产品有哪些?"
result = chain.invoke(query)
print(result)
输出结果
"根据知识库内容,公司2023年的主要产品包括智能客服系统、数据分析平台和区块链解决方案。"
说明
Step 1: 使用 LlamaIndex 构建知识库索引
- 数据加载:通过
SimpleDirectoryReader加载本地文档(如 PDF、Word 或文本文件)。 - 索引构建:使用
VectorStoreIndex创建向量索引,支持高效的相似性检索。 - 查询引擎:通过
RetrieverQueryEngine提供对索引的访问接口。
Step 2: 使用 LangChain 构建对话链
- 提示模板:定义对话模板,动态注入检索到的上下文信息。
- 检索函数:通过
RunnablePassthrough将用户输入传递给 LlamaIndex 查询引擎,获取相关上下文。 - 链式调用:将检索结果与用户输入组合后传递给大模型,生成最终答案。
Step 3: 执行查询
- 用户提问“公司2023年的主要产品有哪些?”时:
- LlamaIndex 从知识库中检索相关内容。
- LangChain 将检索到的内容与用户问题结合,生成最终回答。
关键点解析
为什么选择 LlamaIndex 和 LangChain 集成?
- LlamaIndex 的优势:专注于知识库构建,擅长处理大规模文档和复杂检索任务。
- LangChain 的优势:提供灵活的链式调用机制,适合管理复杂的业务逻辑。
- 无缝集成:通过自定义函数(如
retrieve_context),可以轻松将 LlamaIndex 的检索能力嵌入到 LangChain 的工作流中。
代码中的亮点
-
动态上下文注入:
- 使用
RunnablePassthrough动态传递用户输入,并调用 LlamaIndex 的查询引擎。 - 这种方式确保了检索结果始终与用户问题相关。
- 使用
-
模块化设计:
- LlamaIndex 负责知识库的管理和检索。
- LangChain 负责对话管理和最终答案生成。
- 两者的分工明确,便于维护和扩展。
应用场景
- 企业智能客服:结合知识库和对话链,构建多轮对话的客服助手。
- 文档问答系统:快速检索和生成答案,适用于技术支持和内部培训。
- 研究文献分析:通过混合检索和链式调用,生成高质量的研究报告。
2. LlamaIndex 与 LangChain 集成 + 前端 UI
问题背景:为了提升用户体验,我们不仅需要一个强大的后端系统,还需要一个直观、友好的前端界面。以下案例将展示如何结合 LlamaIndex 和 LangChain 构建后端逻辑,同时使用 Streamlit(一个流行的 Python 前端框架)打造一个交互式应用。
完整代码案例
后端逻辑:整合 LlamaIndex 和 LangChain
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever# Step 1: 使用 LlamaIndex 构建知识库索引
def build_knowledge_base():# 数据加载:从本地目录加载文档documents = SimpleDirectoryReader("./knowledge_base").load_data()# 创建向量索引index = VectorStoreIndex.from_documents(documents)# 初始化检索器retriever = VectorIndexRetriever(index=index, similarity_top_k=5)# 创建查询引擎query_engine = RetrieverQueryEngine(retriever=retriever)return query_engine# Step 2: 使用 LangChain 构建对话链
def build_langchain_chain(query_engine):# 定义提示模板prompt = ChatPromptTemplate.from_messages([("system", "你是一个智能客服助手,以下是相关文档内容:\n{context}"),("human", "{query}")])# 初始化大模型llm = ChatOpenAI(model="gpt-4o")# 将 LlamaIndex 查询引擎嵌入到 LangChain 链中def retrieve_context(query):response = query_engine.query(query)return response.response# 构建 LangChain 链路chain = ({"context": RunnablePassthrough() | retrieve_context, "query": RunnablePassthrough()}| prompt| llm)return chain
前端实现:使用 Streamlit 构建用户界面
import streamlit as st# 初始化后端逻辑
query_engine = build_knowledge_base()
chain = build_langchain_chain(query_engine)# Streamlit 应用界面
st.title("智能客服助手")
st.markdown("请输入您的问题,我们将为您快速解答!")# 用户输入框
user_query = st.text_input("您的问题:", "")if user_query:# 显示加载动画with st.spinner("正在为您查找答案..."):# 调用后端逻辑生成回答response = chain.invoke(user_query)# 显示回答st.subheader("回答:")st.write(response)# 显示上下文信息st.subheader("参考内容:")retrieved_context = query_engine.query(user_query).source_nodesfor i, node in enumerate(retrieved_context):st.write(f"**来源 {i+1}:** {node.node.text[:200]}...")
运行方式
-
安装依赖:
pip install llama-index langchain openai streamlit -
启动应用:
- 将上述代码保存为
app.py。 - 在终端运行以下命令:
streamlit run app.py - 打开浏览器访问
http://localhost:8501,即可看到交互式界面。
- 将上述代码保存为
输出结果
界面截图
-
首页布局:
-
输入问题:
- 用户输入问题:“公司2023年的主要产品有哪些?”
-
生成回答:
回答: 根据知识库内容,公司2023年的主要产品包括智能客服系统、数据分析平台和区块链解决方案。参考内容: 来源 1: 公司2023年发布了一系列新产品,其中包括智能客服系统... 来源 2: 数据分析平台采用了最新的机器学习算法...
说明
Step 1: 后端逻辑
- LlamaIndex:
- 负责构建知识库索引,支持高效检索。
- 通过
VectorStoreIndex和RetrieverQueryEngine提供上下文信息。
- LangChain:
- 负责管理对话链,动态注入检索到的上下文。
- 通过
RunnablePassthrough和ChatPromptTemplate生成最终回答。
Step 2: 前端实现
- Streamlit:
- 提供了一个简单易用的前端框架,适合快速构建交互式应用。
- 使用
st.text_input获取用户输入,st.spinner显示加载动画,st.write展示结果。
- 用户体验:
- 界面简洁直观,用户只需输入问题即可获得答案。
- 显示参考内容,增强透明度和可信度。
关键点解析
为什么选择 Streamlit?
- 简单易用:无需复杂的前端开发经验,仅需几行代码即可构建交互式界面。
- 实时更新:支持动态刷新,用户输入后立即显示结果。
- 跨平台支持:可在本地或云端部署,方便扩展。
代码中的亮点
- 前后端分离:
- 后端逻辑专注于数据处理和业务逻辑。
- 前端负责用户交互和结果展示。
- 动态加载:
- 使用
st.spinner提供加载动画,提升用户体验。
- 使用
- 参考内容展示:
- 显示检索到的上下文信息,帮助用户理解答案来源。
3. LlamaIndex 与 LangChain 集成 + 前端 UI+ Ollama
在案例中,如果需要将大模型调用从云端(如 OpenAI 的 ChatOpenAI)改为本地运行的 Ollama,我们需要调整代码以适配 Ollama 提供的接口。以下是详细的调整步骤和完整代码示例。
模型接口说明
-
Ollama 简介:
- Ollama 是一个用于本地运行大语言模型(LLM)的工具,支持多种开源模型(如 Llama、Mistral、GPT-NeoX 等)。
- 它提供了 RESTful API 接口,可以通过 HTTP 请求与本地模型交互。
-
调整点:
- 替换
langchain_openai.ChatOpenAI为适配 Ollama 的自定义实现。 - 使用
ollama的 Python SDK 或直接通过 HTTP 请求调用本地模型。 - 修改 LangChain 的链式调用逻辑,确保与 Ollama 的输出格式兼容。
- 替换
本地Ollama大模型调用代码实现
后端逻辑:整合 LlamaIndex 和 LangChain + Ollama
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
import requests# Step 1: 使用 LlamaIndex 构建知识库索引
def build_knowledge_base():# 数据加载:从本地目录加载文档documents = SimpleDirectoryReader("./knowledge_base").load_data()# 创建向量索引index = VectorStoreIndex.from_documents(documents)# 初始化检索器retriever = VectorIndexRetriever(index=index, similarity_top_k=5)# 创建查询引擎query_engine = RetrieverQueryEngine(retriever=retriever)return query_engine# Step 2: 配置 Ollama 模型调用
class OllamaLLM:def __init__(self, model_name="llama2", base_url="http://localhost:11434"):self.model_name = model_nameself.base_url = base_urldef invoke(self, prompt):# 发送请求到 Ollamaresponse = requests.post(f"{self.base_url}/api/generate",json={"model": self.model_name,"prompt": prompt,"stream": False})if response.status_code == 200:result = response.json()return result.get("response", "")else:raise Exception(f"Error calling Ollama: {response.text}")# Step 3: 使用 LangChain 构建对话链
def build_langchain_chain(query_engine, ollama_llm):# 定义提示模板prompt = ChatPromptTemplate.from_messages([("system", "你是一个智能客服助手,以下是相关文档内容:\n{context}"),("human", "{query}")])# 将 LlamaIndex 查询引擎嵌入到 LangChain 链中def retrieve_context(query):response = query_engine.query(query)return response.response# 构建 LangChain 链路chain = ({"context": RunnablePassthrough() | retrieve_context, "query": RunnablePassthrough()}| prompt| ollama_llm.invoke)return chain
前端实现:使用 Streamlit 构建用户界面
import streamlit as st# 初始化后端逻辑
query_engine = build_knowledge_base()
ollama_llm = OllamaLLM(model_name="llama2") # 使用本地 Ollama 模型
chain = build_langchain_chain(query_engine, ollama_llm)# Streamlit 应用界面
st.title("智能客服助手")
st.markdown("请输入您的问题,我们将为您快速解答!")# 用户输入框
user_query = st.text_input("您的问题:", "")if user_query:# 显示加载动画with st.spinner("正在为您查找答案..."):# 调用后端逻辑生成回答response = chain.invoke(user_query)# 显示回答st.subheader("回答:")st.write(response)# 显示上下文信息st.subheader("参考内容:")retrieved_context = query_engine.query(user_query).source_nodesfor i, node in enumerate(retrieved_context):st.write(f"**来源 {i+1}:** {node.node.text[:200]}...")
运行方式
-
安装依赖:
pip install llama-index langchain requests streamlit -
启动 Ollama:
- 确保 Ollama 已安装并运行在本地(默认地址为
http://localhost:11434)。 - 下载并加载目标模型(如
llama2):ollama pull llama2
- 确保 Ollama 已安装并运行在本地(默认地址为
-
启动应用:
- 将上述代码保存为
app.py。 - 在终端运行以下命令:
streamlit run app.py - 打开浏览器访问
http://localhost:8501。
- 将上述代码保存为
输出结果
界面截图
-
首页布局:
-
输入问题:
- 用户输入问题:“公司2023年的主要产品有哪些?”
-
生成回答:
回答: 根据知识库内容,公司2023年的主要产品包括智能客服系统、数据分析平台和区块链解决方案。参考内容: 来源 1: 公司2023年发布了一系列新产品,其中包括智能客服系统... 来源 2: 数据分析平台采用了最新的机器学习算法...
关键调整点解析
-
Ollama 模型调用:
- 使用
requests.post向 Ollama 的/api/generate接口发送请求。 - 参数包括
model(模型名称)和prompt(输入提示)。 - 返回值为 JSON 格式,提取
response字段作为模型输出。
- 使用
-
LangChain 集成:
- 自定义
OllamaLLM类,提供与 LangChain 兼容的invoke方法。 - 将
OllamaLLM.invoke嵌入到链式调用中,替代原有的云端模型。
- 自定义
-
性能优化:
- 本地运行模型减少了网络延迟,提升了响应速度。
- 可根据硬件性能选择合适的模型(如
llama2、mistral等)。
应用场景
- 离线环境:适用于无法访问云端服务的场景,如内网部署。
- 隐私保护:数据完全在本地处理,避免敏感信息泄露。
- 低成本运行:无需支付云端服务费用,适合预算有限的项目。
通过将大模型调用从云端切换为本地 Ollama,我们实现了更高的灵活性和隐私保护。结合 LlamaIndex 和 LangChain 的强大功能,以及 Streamlit 的友好界面,最终构建了一个高效、易用的智能客服应用。
如果你有任何疑问或想法,欢迎在评论区交流讨论!
总结
通过本案例,我们展示了如何将 LlamaIndex 和 LangChain 的强大功能与 Streamlit 的友好界面以及本地Ollama大模型API相结合,构建一个完整的智能客服应用。这种组合不仅提升了系统的功能性,还极大地改善了用户体验。
如果你有任何疑问或想法,欢迎在评论区交流讨论!
相关文章:
《AI大模型应知应会100篇》加餐篇:LlamaIndex 与 LangChain 的无缝集成
加餐篇:LlamaIndex 与 LangChain 的无缝集成 问题背景:在实际应用中,开发者常常需要结合多个框架的优势。例如,使用 LangChain 管理复杂的业务逻辑链,同时利用 LlamaIndex 的高效索引和检索能力构建知识库。本文在基于…...

部署大模型实战:如何巧妙权衡效果、成本与延迟?
目录 部署大模型实战:如何巧妙权衡效果、成本与延迟? 一、为什么要进行权衡? 二、权衡的三个关键维度 三、如何进行有效权衡?(实操策略) (一)明确需求场景与优先级 (…...
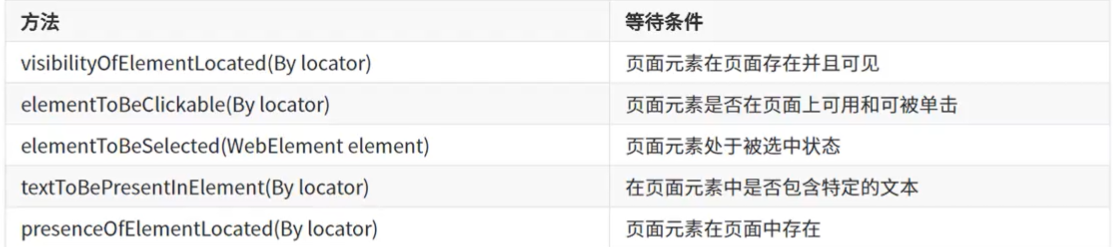
元素三大等待
硬性等待(强制等待) 线程休眠,强制等待 Thread.sleep(long millis);这是最简单的等待方式,使用time.sleep()方法来实现。在代码中强制等待一定的时间,不论元素是否已经加载完成,都会等待指定的时间后才继…...

【DY】信息化集成化信号采集与处理系统;生物信号采集处理系统一体机
MD3000-C信息化一体机生物信号采集处理系统 实验平台技术指标 01、整机外形尺寸:1680mm(L)*750mm(w)*2260mm(H); 02、实验台操作面积:750(w)*1340(L)(长*宽); 03、实验台面离地高度…...
康谋分享 | 仿真驱动、数据自造:巧用合成数据重构智能座舱
随着汽车向智能化、场景化加速演进,智能座舱已成为人车交互的核心承载。从驾驶员注意力监测到儿童遗留检测,从乘员识别到安全带状态判断,座舱内的每一次行为都蕴含着巨大的安全与体验价值。 然而,这些感知系统要在多样驾驶行为、…...
)
YOLO学习笔记 | 基于YOLOv5的车辆行人重识别算法研究(附matlab代码)
基于YOLOv5的车辆行人重识别算法研究 🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥 摘要 本文提出了一种基于YOLOv5的车辆行人重识别(ReID)算法,结合目标检测与特征匹配技术,实现高效的多目标跟踪与识别。通过引入注意力机制、优化损失函数和轻量化网络结构…...

Vue 数据传递流程图指南
今天,我们探讨一下 Vue 中的组件传值问题。这不仅是我们在日常开发中经常遇到的核心问题,也是面试过程中经常被问到的重要知识点。无论你是初学者还是有一定经验的开发者,掌握这些传值方式都将帮助你更高效地构建和维护 Vue 应用 目录 1. 父…...

Node.js 与 MySQL:深入理解与高效实践
Node.js 与 MySQL:深入理解与高效实践 引言 随着互联网技术的飞速发展,Node.js 作为一种高性能的服务端JavaScript运行环境,因其轻量级、单线程和事件驱动等特点,受到了广大开发者的青睐。MySQL 作为一款开源的关系型数据库管理系统,以其稳定性和可靠性著称。本文将深入…...
)
鸿蒙NEXT开发缓存工具类(ArkTs)
import { ObjectUtil } from ./ObjectUtil;/*** 缓存工具类** 该类提供了一组静态方法,用于操作缓存数据。* 主要功能包括:获取缓存数据、存储缓存数据、删除缓存数据、检查键是否存在、判断缓存是否为空以及清空缓存。** author CSDN-鸿蒙布道师* since…...
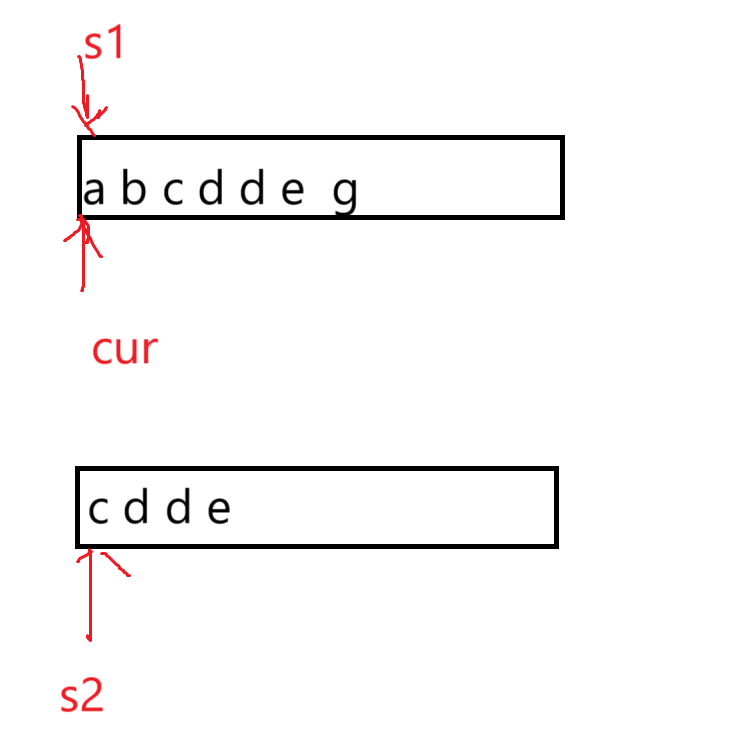
【C语言】strstr查找字符串函数
一、函数介绍 strstr 是 C 语言标准库 <string.h> 中的字符串查找函数,用于在主字符串中查找子字符串的首次出现位置。若找到子串,返回其首次出现的地址;否则返回 NULL。它是处理字符串匹配问题的核心工具之一。 二、函数原型 char …...

使用pkexec 和其策略文件安全提权执行外部程序
一、pkexec 基本机制 pkexec 是 Linux 桌面环境下基于 PolicyKit 的安全提权工具,可通过交互式图形界面获取用户授权后,以 root 权限执行指定程序。其核心特点包括: 图形化密码输入:调用时自动弹出系统认证对话框&a…...

NVIDIA显卡
NVIDIA显卡作为全球GPU技术的标杆,其产品线覆盖消费级、专业级、数据中心、移动计算等多个领域,技术迭代贯穿架构创新、AI加速、光线追踪等核心方向。以下从技术演进、产品矩阵、核心技术、生态布局四个维度展开深度解析: 一、技术演进&…...
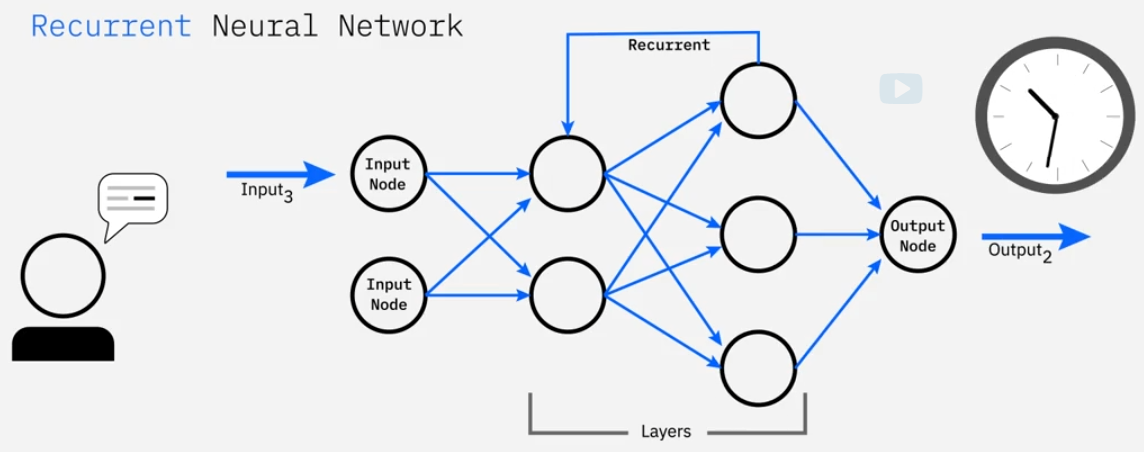
机器学习、深度学习和神经网络
机器学习、深度学习和神经网络 术语及相关概念 在深入了解人工智能(AI)的工作原理以及它的各种应用之前,让我们先区分一下与AI密切相关的一些术语和概念:人工智能、机器学习、深度学习和神经网络。这些术语有时会被交替使用&#…...

数字孪生在智慧城市中的前端呈现与 UI 设计思路
一、数字孪生技术在智慧城市中的应用与前端呈现 数字孪生技术通过创建城市的虚拟副本,实现了对城市运行状态的实时监控、分析与预测。在智慧城市中,数字孪生技术的应用包括交通流量监测、环境质量分析、基础设施管理等。其前端呈现主要依赖于Web3D技术、…...

黑莓手机有望回归:搭载 Android 15、支持 AI
据 3 月 31 日快科技消息,有博主称一家英国的初创公司正悄悄努力复活 BlackBerry Classic 及 OnwardMobility 未完成的产品。 从爆料的信息看,黑莓新手机将具备 5G、AMOLED 显示屏、12GB RAM 和 256GB 或 512GB 存储空间等高端配置,同时运行 …...

Android OpenGLES 360全景图片渲染(球体内部)
概述 360度全景图是一种虚拟现实技术,它通过对现实场景进行多角度拍摄后,利用计算机软件将这些照片拼接成一个完整的全景图像。这种技术能够让观看者在虚拟环境中以交互的方式查看整个周围环境,就好像他们真的站在那个位置一样。在Android设备…...

LETTERS(DFS)
【题目描述】 给出一个rowcolrowcol的大写字母矩阵,一开始的位置为左上角,你可以向上下左右四个方向移动,并且不能移向曾经经过的字母。问最多可以经过几个字母。 【输入】 第一行,输入字母矩阵行数RR和列数SS,1≤R,S≤…...

嵌入式海思Hi3861连接华为物联网平台操作方法
1.1 实验目的 快速演示 1、认识轻量级HarmonyOS——LiteOS-M 2、初步掌握华为云物联网平台的使用 3、快速驱动海思Hi3861 WIFI芯片,连接互联网并登录物联网平台...
:3D机房大屏全景解析)
CMDB平台(进阶篇):3D机房大屏全景解析
在数字化转型的浪潮中,数据中心作为企业信息架构的核心,其高效、智能的管理成为企业竞争力的关键因素之一,其运维管理方式也正经历着革命性的变革。传统基于二维平面图表的机房监控方式已难以满足现代企业对运维可视化、智能化的需求。乐维CM…...
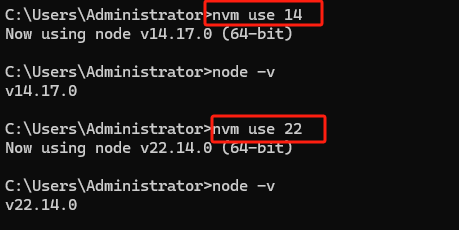
NVM 多版本Node.js 管理全指南(Windows系统)
🧑 博主简介:CSDN博客专家、全栈领域优质创作者、高级开发工程师、高级信息系统项目管理师、系统架构师,数学与应用数学专业,10年以上多种混合语言开发经验,从事DICOM医学影像开发领域多年,熟悉DICOM协议及…...
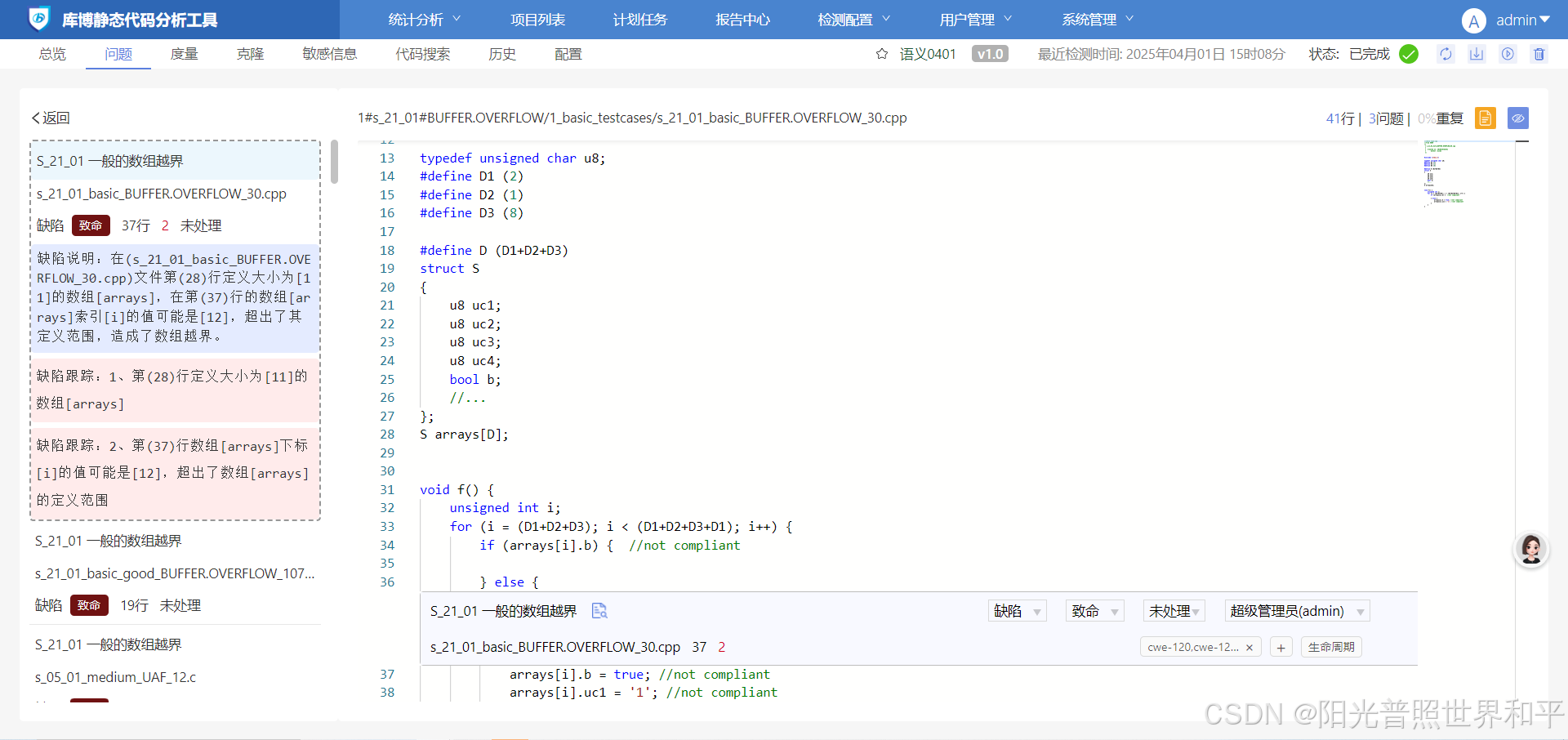
C,C++语言缓冲区溢出的产生和预防
缓冲区溢出的定义 缓冲区是内存中用于存储数据的一块连续区域,在 C 和 C 里,常使用数组、指针等方式来操作缓冲区。而缓冲区溢出指的是当程序向缓冲区写入的数据量超出了该缓冲区本身能够容纳的最大数据量时,额外的数据就会覆盖相邻的内存区…...

《Linux内存管理:实验驱动的深度探索》【附录】【实验环境搭建 2】【vscode搭建调试内核环境】
1. 如何调试我们的内核 1. GDB调试 安装gdb sudo apt-get install gdb-multiarchgdb-multiarch是多架构版本,可以通过set architecture aarch64指定架构 QEMU参数修改添加-s -S #!/usr/bin/shqemu-7.2.0-rc1/build/aarch64-softmmu/qemu-system-aarch64 \-nogr…...
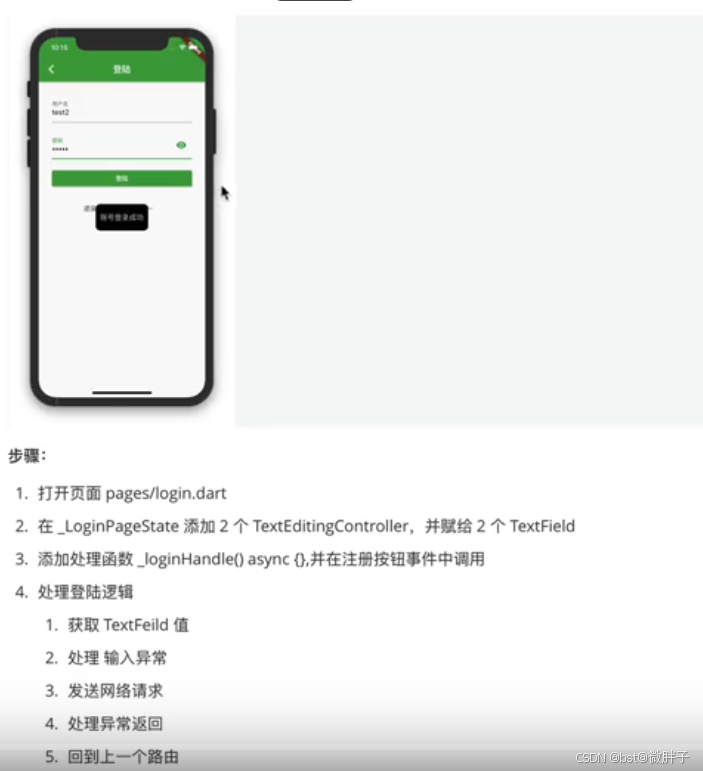
Flutter项目之登录注册功能实现
目录: 1、页面效果2、登录两种状态界面3、中间按钮部分4、广告区域5、最新资讯6、登录注册页联调6.1、网络请求工具类6.2、注册页联调6.3、登录问题分析6.4、本地缓存6.5、共享token6.6、登录页联调6.7、退出登录 1、页面效果 import package:flutter/material.dart…...

mybatis 自带的几个插入接口的区别
研究这个的原由是应为需求对一张表新增了一个有默认值的字段,然后调用插入接口的时候发现这个字段没有传默认值但是还是以null值入库了,数据库中设置的默认值没有生效。 通过排查之后发现是使用了insertUseGeneratedKeys 方法进行插入,此方法…...
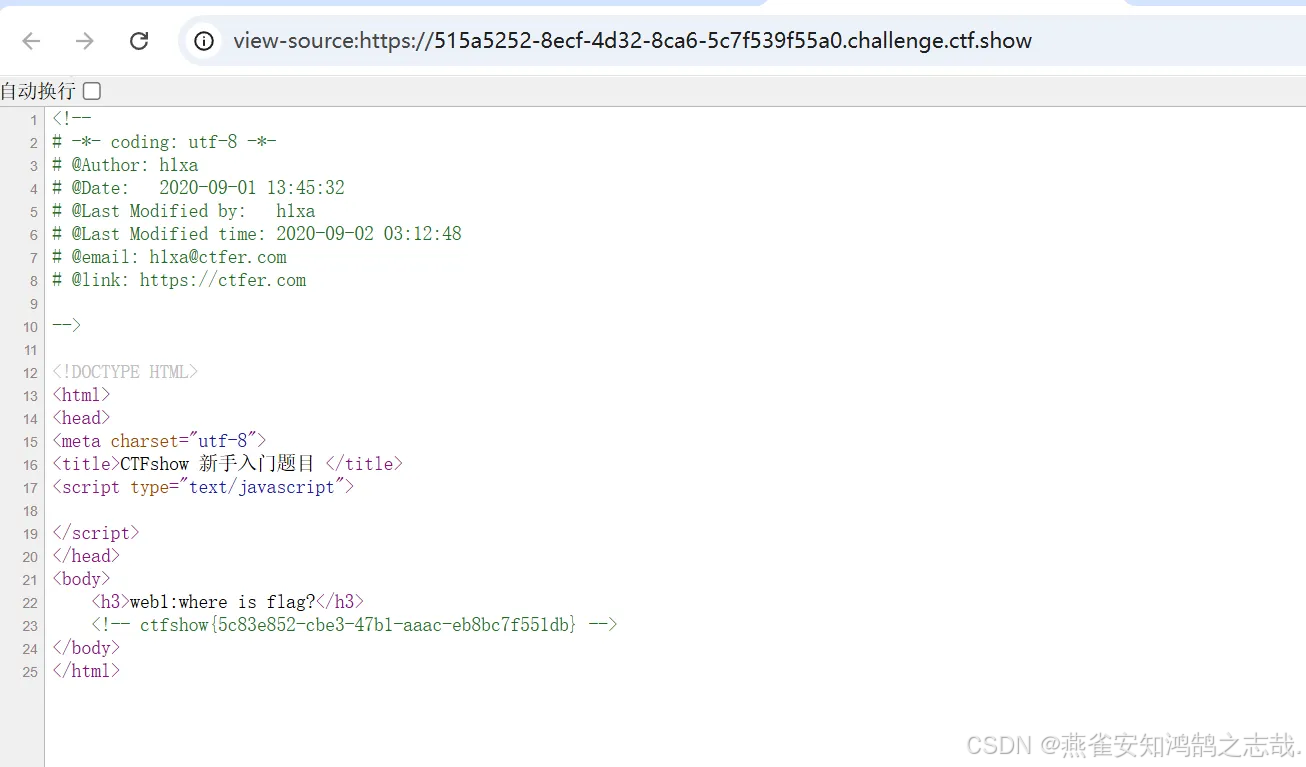
ctfshow VIP题目限免 源码泄露
根据题目提示是源代码泄露,右键查看页面源代码发现了 flag...

移动神器RAX3000M路由器变身家庭云之七:增加打印服务,电脑手机无线打印
系列文章目录: 移动神器RAX3000M路由器变身家庭云之一:开通SSH,安装新软件包 移动神器RAX3000M路由器变身家庭云之二:安装vsftpd 移动神器RAX3000M路由器变身家庭云之三:外网访问家庭云 移动神器RAX3000M路由器不刷固…...
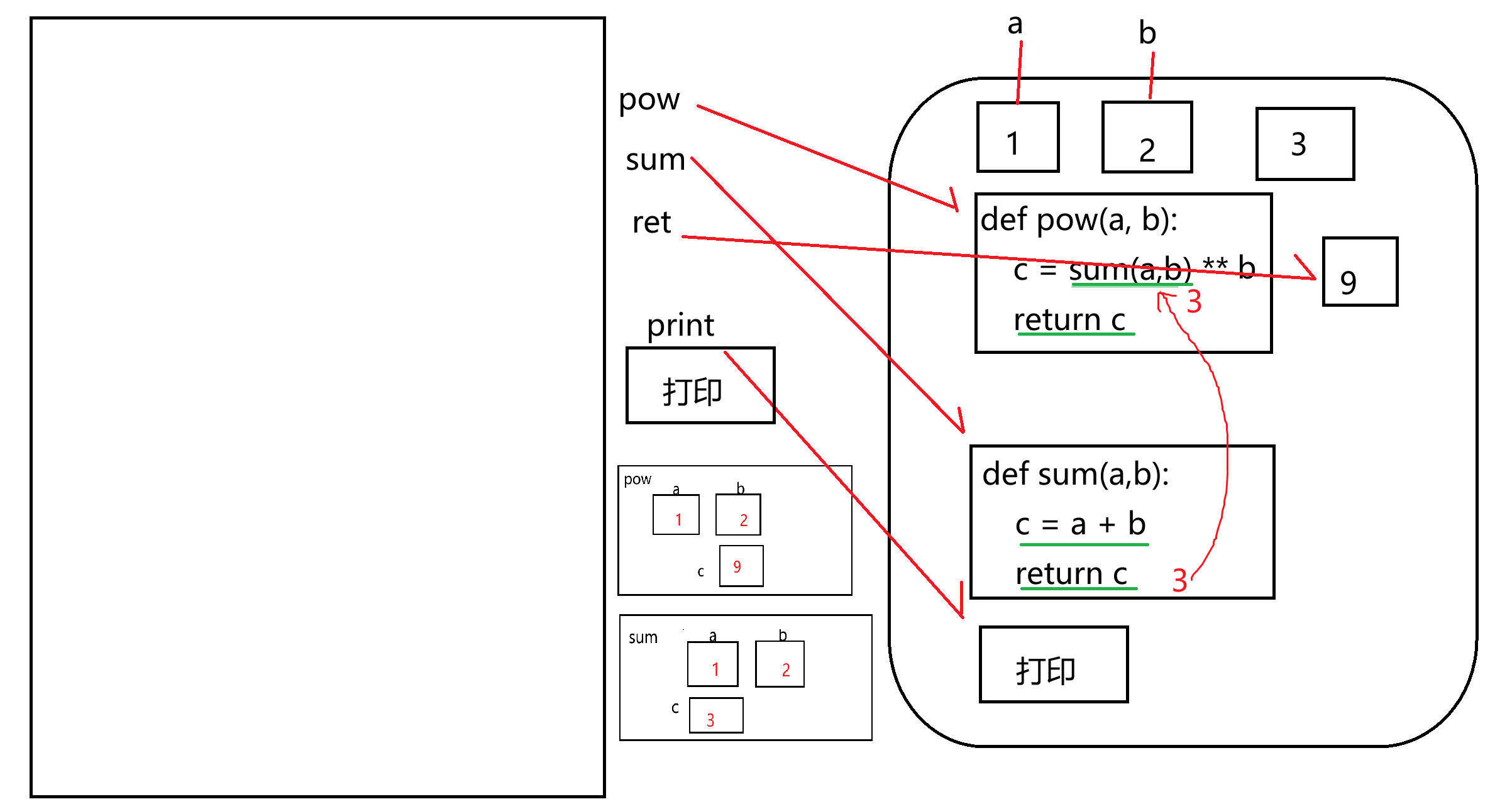
《函数基础与内存机制深度剖析:从 return 语句到各类经典编程题详解》
一、问答题 (1)使用函数的好处是什么? 1.提升代码的复用性 2.提升代码的可维护性 3.增强代码的可读性 4.提高代码的灵活性 5.方便进行单元测试 (2)如何定义一个函数?如何调用一个函数? 在Pytho…...
Python | 使用Matplotlib绘制Swarm Plot(蜂群图)
Swarm Plot(蜂群图)是一种数据可视化图表,它用于展示分类数据的分布情况。这种图表通过将数据点沿着一个或多个分类变量轻微地分散,以避免它们之间的重叠,从而更好地显示数据的分布密度和分布趋势。Swarm Plot特别适用…...

风云可测:华为AI天气大模型将暴雨预测误差缩至3公里内
华为云正式发布全球首个气象专用人工智能大模型"盘古气象",实现台风路径24小时预测误差<30公里、暴雨落区72小时精度91%,较传统数值预报效率提升10000倍。本文基于对西北太平洋10个台风回溯测试、全国2360个气象站验证数据,解析…...

JavaScript基础-window.sessionStorage
在Web开发中,数据存储是一个非常重要的环节。它不仅关系到用户体验的提升,还影响着应用的状态管理与性能优化。window.sessionStorage 是一种轻量级的数据存储机制,允许网页在同一会话期间内保存数据。本文将详细介绍 sessionStorage 的基本概…...