PostgreSQL pg_repack 重新组织表并释放表空间
pg_repack
pg_repack是 PostgreSQL 的一个扩展,它允许您从表和索引中删除膨胀,并可选择恢复聚集索引的物理顺序。与CLUSTER和VACUUM FULL不同,它可以在线工作,在处理过程中无需对已处理的表保持独占锁定。pg_repack 启动效率高,性能可与直接使用 CLUSTER 相媲美。
要求
PostgreSQL 版本
PostgreSQL 9.5、9.6、10、11、12、13、14、15、16、17。
PostgreSQL 9.4 及之前版本不受支持。
磁盘
执行全表重新打包需要的可用磁盘空间大约是目标表及其索引的两倍。
例如,如果要重组的表和索引的总大小为 1GB,则需要额外的 2GB 磁盘空间。
安装
pg_repack 可以在 UNIX 或 Linux 上使用make构建。在构建之前,您可能需要安装 PostgreSQL 开发包(postgresql-devel等)并将包含pg_config的目录添加到您的$PATH。然后您可以运行:
dnf install -y lz4-develdnf install -y readline-develdnf install -y clang sudo dnf install -y llvm llvm-develwget -c 'https://github.com/reorg/pg_repack/archive/refs/tags/ver_1.5.2.zip'cd /opt unzip pg_repack-ver_1.5.2.zip make PG_CONFIG={your pg_config path}make PG_CONFIG={your pg_config path} install # 安装后,在你要处理的数据库中加载 pg_repack 扩展。pg_repack 被打包为一个扩展,因此你可以执行:$ psql -c "CREATE EXTENSION pg_repack" -d your_databasetest=# select repack.version(), repack.version_sql();version | version_sql
-----------------+-----------------pg_repack 1.5.2 | pg_repack 1.5.2
(1 row)
pgstattuple
pgstattuple 提供了一个非常详细的表和索引空间使用统计信息,尤其是在处理表膨胀和空间碎片时非常有用。通过这些信息,您可以有效地评估表的膨胀率,并决定是否需要执行 VACUUM FULL 或 pg_repack 等操作来回收空间并优化数据库性能。
test=# CREATE EXTENSION IF NOT EXISTS pgstattuple;
CREATE EXTENSIONtest=# select * from pg_extension ;oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+------------------+----------+--------------+----------------+------------+-----------+--------------14528 | plpgsql | 10 | 11 | f | 1.0 | | 16397 | pg_repack | 10 | 2200 | f | 1.5.2 | | 16851 | pgstattuple | 10 | 2200 | t | 1.5 | |
(3 rows)测试
### 关闭 autovacuum -- 仅测试 test=# alter system set autovacuum=off;
ALTER SYSTEMtest=# select pg_reload_conf();pg_reload_conf
----------------t
(1 row)test=# show autovacuum;autovacuum
------------off
(1 row)#### 创建数据库表CREATE TABLE big_table (id SERIAL PRIMARY KEY,name varchar(100),value INT
);CREATE INDEX idx_name on big_table(name);#### 插入测试数据# 插入 300 万行数据
# -- 生成 Name 1, Name 2, Name 3... 的格式
# -- 生成一个在 1 到 100 之间的值INSERT INTO big_table (name, value)
SELECT'Name ' || gs, (gs % 100) + 1
FROM generate_series(1, 3000000) gs;# 查看表的大小和死行数量test=# SELECT * FROM pg_stat_user_tables WHERE relname = 'big_table'\gx
-[ RECORD 1 ]-------+----------
relid | 16929
schemaname | public
relname | big_table
seq_scan | 2
seq_tup_read | 0
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 3000000
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 3000000
n_dead_tup | 0
n_mod_since_analyze | 3000000
n_ins_since_vacuum | 3000000
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0# 查看表的空间大小、索引大小,总大小
test=# SELECT
test-# pg_size_pretty(pg_table_size('big_table')) AS table_size,
test-# pg_size_pretty(pg_indexes_size('big_table')) AS indexes_size,
test-# pg_size_pretty(pg_total_relation_size('big_table')) AS total_size;table_size | indexes_size | total_size
------------+--------------+------------149 MB | 219 MB | 369 MB# 查询默认表空间路径(pg_default)中的物理文件test=# SELECT oid, datname FROM pg_database WHERE datname = 'test';oid | datname
-------+---------16389 | test
(1 row)test=# SELECT pg_relation_filepath('big_table');pg_relation_filepath
----------------------base/16389/16929
(1 row)# 物理文件空间大小ls -lth |grep 16929
-rw-------. 1 postgres postgres 150M Feb 14 16:23 16929
-rw-------. 1 postgres postgres 56K Feb 14 16:22 16929_fsm# 这个查询会返回有关指定表的空间使用统计信息。test=# SELECT * FROM pgstattuple('big_table');table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------156540928 | 3000000 | 139999608 | 89.43 | 0 | 0 | 0 | 6668 | 0
(1 row)#### 执行一些删除和更新操作#为了模拟数据库的实际负载,删除和更新一些行,产生死行和空洞:# 删除一些数据 33%
test=# DELETE FROM big_table WHERE id%3 = 0;
DELETE 1000000test=# select count(*) from big_table;count
---------2000000
(1 row)test=# SELECT * FROM pg_stat_user_tables WHERE relname = 'big_table'\gx
-[ RECORD 1 ]-------+----------
relid | 16929
schemaname | public
relname | big_table
seq_scan | 8
seq_tup_read | 11000000
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 3000000
n_tup_upd | 0
n_tup_del | 1000000 # 被删除的行数
n_tup_hot_upd | 0
n_live_tup | 2000000
n_dead_tup | 1000000 # 产生死行的数量
n_mod_since_analyze | 4000000
n_ins_since_vacuum | 3000000
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0test=# SELECT * FROM pgstattuple('big_table');table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------156540928 | 2000000 | 93333072 | 59.62 | 10 | 480 | 0 | 48005924 | 30.67
(1 row)# 查询 物理文件是否发生变化ls -lth |grep 16929
-rw-------. 1 postgres postgres 150M Feb 14 16:37 16929
-rw-------. 1 postgres postgres 56K Feb 14 16:22 16929_fsm# 更新一些数据test=# UPDATE big_table SET name = name || 'updated' WHERE id%3 = 1;
UPDATE 1000000test=# select count(*) from big_table;count
---------2000000
(1 row)test=# SELECT * FROM pg_stat_user_tables WHERE relname = 'big_table'\gx
-[ RECORD 1 ]-------+----------
relid | 16929
schemaname | public
relname | big_table
seq_scan | 15
seq_tup_read | 21000020
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 3000000
n_tup_upd | 1000000 # 已更新的行
n_tup_del | 1000000
n_tup_hot_upd | 0
n_live_tup | 2000000
n_dead_tup | 2000000 # 产生死行的数量 1000000+1000000=2000000 ( n_tup_del + n_tup_upd)
n_mod_since_analyze | 5000000
n_ins_since_vacuum | 3000000
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0# 检查数据、索引文件大小 test=# SELECT * FROM pgstattuple('big_table');table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------169197568 | 2000000 | 98665204 | 58.31 | 0 | 0 | 0 | 48622184 | 28.74
(1 row)# 查询 物理文件是否发生变化ls -lth |grep 16929
-rw-------. 1 postgres postgres 162M Feb 14 16:44 16929
-rw-------. 1 postgres postgres 64K Feb 14 16:39 16929_fsm#运行 pg_repack 来重建表。这将移除死行并优化表:pg_repack -d test --table public.big_table --echo------------------- 日志如下 ------------------
LOG: (query) SET search_path TO pg_catalog, pg_temp, public
LOG: (query) SET search_path TO pg_catalog, pg_temp, public
LOG: (query) select repack.version(), repack.version_sql()
LOG: (query) SET statement_timeout = 0
LOG: (query) SET search_path = pg_catalog, pg_temp, public
LOG: (query) SET client_min_messages = warning
LOG: (query) SELECT r FROM (VALUES ($1, 'r')) AS given_t(r,kind) WHERE NOT EXISTS( SELECT FROM repack.tables WHERE relid=to_regclass(given_t.r)) AND NOT EXISTS( SELECT FROM pg_catalog.pg_class c WHERE c.oid=to_regclass(given_t.r) AND c.relkind = given_t.kind AND given_t.kind = 'p')
LOG: (param:0) = public.big_table
LOG: (query) SELECT t.*, coalesce(v.tablespace, t.tablespace_orig) as tablespace_dest FROM repack.tables t, (VALUES ($1::text)) as v (tablespace) WHERE (relid = $2::regclass) ORDER BY t.relname, t.schemaname
LOG: (param:0) = (null)
LOG: (param:1) = public.big_table
INFO: repacking table "public.big_table"
LOG: (query) SELECT pg_try_advisory_lock($1, CAST(-2147483648 + $2::bigint AS integer))
LOG: (param:0) = 16185446
LOG: (param:1) = 16929
LOG: (query) BEGIN ISOLATION LEVEL READ COMMITTED
LOG: (query) SET LOCAL lock_timeout = 100
LOG: (query) LOCK TABLE public.big_table IN ACCESS EXCLUSIVE MODE
LOG: (query) RESET lock_timeout
LOG: (query) SELECT pg_get_indexdef(indexrelid) FROM pg_index WHERE indrelid = $1 AND NOT indisvalid
LOG: (param:0) = 16929
LOG: (query) SELECT indexrelid, repack.repack_indexdef(indexrelid, indrelid, $2, FALSE) FROM pg_index WHERE indrelid = $1 AND indisvalid
LOG: (param:0) = 16929
LOG: (param:1) = (null)
LOG: (query) SELECT repack.conflicted_triggers($1)
LOG: (param:0) = 16929
LOG: (query) SELECT repack.create_index_type(16933,16929)
LOG: (query) SELECT repack.create_log_table(16929)
LOG: (query) CREATE TRIGGER repack_trigger AFTER INSERT OR DELETE OR UPDATE ON public.big_table FOR EACH ROW EXECUTE PROCEDURE repack.repack_trigger('id')
LOG: (query) ALTER TABLE public.big_table ENABLE ALWAYS TRIGGER repack_trigger
LOG: (query) SELECT repack.disable_autovacuum('repack.log_16929')
LOG: (query) BEGIN ISOLATION LEVEL READ COMMITTED
LOG: (query) SELECT pg_backend_pid()
LOG: (query) SELECT pid FROM pg_locks WHERE locktype = 'relation' AND granted = false AND relation = 16929 AND mode = 'AccessExclusiveLock' AND pid <> pg_backend_pid()
LOG: (query) COMMIT
LOG: (query) BEGIN ISOLATION LEVEL SERIALIZABLE
LOG: (query) SELECT set_config('work_mem', current_setting('maintenance_work_mem'), true)
LOG: (query) SELECT coalesce(array_agg(l.virtualtransaction), '{}') FROM pg_locks AS l LEFT JOIN pg_stat_activity AS a ON l.pid = a.pid LEFT JOIN pg_database AS d ON a.datid = d.oid WHERE l.locktype = 'virtualxid' AND l.pid NOT IN (pg_backend_pid(), $1) AND (l.virtualxid, l.virtualtransaction) <> ('1/1', '-1/0') AND (a.application_name IS NULL OR a.application_name <> $2) AND a.query !~* E'^\\s*vacuum\\s+' AND a.query !~ E'^autovacuum: ' AND ((d.datname IS NULL OR d.datname = current_database()) OR l.database = 0)
LOG: (param:0) = 12616
LOG: (param:1) = pg_repack
LOG: (query) DELETE FROM repack.log_16929
LOG: (query) SAVEPOINT repack_sp1
LOG: (query) SELECT pid FROM pg_locks WHERE locktype = 'relation' AND granted = false AND relation = 16929 AND mode = 'AccessExclusiveLock' AND pid <> pg_backend_pid()
LOG: (query) SET LOCAL lock_timeout = 100
LOG: (query) LOCK TABLE public.big_table IN ACCESS SHARE MODE
LOG: (query) RESET lock_timeout
LOG: (query) SELECT repack.create_table($1, $2)
LOG: (param:0) = 16929
LOG: (param:1) = pg_default
LOG: (query) INSERT INTO repack.table_16929 SELECT id,name,value FROM ONLY public.big_table
LOG: (query) SELECT repack.disable_autovacuum('repack.table_16929')
LOG: (query) COMMIT
LOG: (query) SELECT 'repack.table_16929'::regclass::oid
LOG: (query) CREATE UNIQUE INDEX index_16933 ON repack.table_16929 USING btree (id)
LOG: (query) CREATE INDEX index_16935 ON repack.table_16929 USING btree (name)
LOG: (query) SELECT repack.repack_apply($1, $2, $3, $4, $5, $6)
LOG: (param:0) = SELECT * FROM repack.log_16929 ORDER BY id LIMIT $1
LOG: (param:1) = INSERT INTO repack.table_16929 VALUES ($1.*)
LOG: (param:2) = DELETE FROM repack.table_16929 WHERE (id) = ($1.id)
LOG: (param:3) = UPDATE repack.table_16929 SET (id, name, value) = ($2.id, $2.name, $2.value) WHERE (id) = ($1.id)
LOG: (param:4) = DELETE FROM repack.log_16929 WHERE id IN (
LOG: (param:5) = 1000
LOG: (query) SELECT pid FROM pg_locks WHERE locktype = 'virtualxid' AND pid <> pg_backend_pid() AND virtualtransaction = ANY($1)
LOG: (param:0) = {}
LOG: (query) SAVEPOINT repack_sp1
LOG: (query) SET LOCAL lock_timeout = 100
LOG: (query) LOCK TABLE public.big_table IN ACCESS EXCLUSIVE MODE
LOG: (query) RESET lock_timeout
LOG: (query) SAVEPOINT repack_sp1
LOG: (query) SET LOCAL lock_timeout = 100
LOG: (query) LOCK TABLE repack.table_16929 IN ACCESS EXCLUSIVE MODE
LOG: (query) RESET lock_timeout
LOG: (query) SELECT repack.repack_apply($1, $2, $3, $4, $5, $6)
LOG: (param:0) = SELECT * FROM repack.log_16929 ORDER BY id LIMIT $1
LOG: (param:1) = INSERT INTO repack.table_16929 VALUES ($1.*)
LOG: (param:2) = DELETE FROM repack.table_16929 WHERE (id) = ($1.id)
LOG: (param:3) = UPDATE repack.table_16929 SET (id, name, value) = ($2.id, $2.name, $2.value) WHERE (id) = ($1.id)
LOG: (param:4) = DELETE FROM repack.log_16929 WHERE id IN (
LOG: (param:5) = 0
LOG: (query) SELECT repack.repack_swap($1)
LOG: (param:0) = 16929
LOG: (query) COMMIT
LOG: (query) BEGIN ISOLATION LEVEL READ COMMITTED
LOG: (query) SAVEPOINT repack_sp1
LOG: (query) SET LOCAL lock_timeout = 100
LOG: (query) LOCK TABLE public.big_table IN ACCESS EXCLUSIVE MODE
LOG: (query) RESET lock_timeout
LOG: (query) SELECT repack.repack_drop($1, $2)
LOG: (param:0) = 16929
LOG: (param:1) = 4
LOG: (query) COMMIT
LOG: (query) BEGIN ISOLATION LEVEL READ COMMITTED
LOG: (query) ANALYZE public.big_table
LOG: (query) COMMIT
LOG: (query) SELECT pg_advisory_unlock($1, CAST(-2147483648 + $2::bigint AS integer))
LOG: (param:0) = 16185446
LOG: (param:1) = 16929# 创建触发器跟踪新表--旧表test=# \d big_tableTable "public.big_table"Column | Type | Collation | Nullable | Default
--------+------------------------+-----------+----------+---------------------------------------id | integer | | not null | nextval('big_table_id_seq'::regclass)name | character varying(100) | | | value | integer | | |
Indexes:"big_table_pkey" PRIMARY KEY, btree (id)"idx_name" btree (name)
Triggers firing always:repack_trigger AFTER INSERT OR DELETE OR UPDATE ON big_table FOR EACH ROW EXECUTE FUNCTION repack.repack_trigger('id')# 创建新表
test=# set search_path=public,repack;
SETtest=# \dList of relationsSchema | Name | Type | Owner
--------+-------------------+----------+--------------public | big_table | table | postgrespublic | big_table_id_seq | sequence | postgrespublic | student | table | postgrespublic | test_table | table | postgrespublic | test_table_id_seq | sequence | postgresrepack | log_16929 | table | postgres # 创建日志表: log_[relid], 新数据记录到这张表 repack | log_16929_id_seq | sequence | postgresrepack | primary_keys | view | postgresrepack | table_16929 | table | postgres # 创建临时表: 表名_[relid]repack | tables | view | postgres
(10 rows)# 产生新的数据test=# select * from log_16929;id | pk | row
----+-----------+----------------------------------1 | | (3000004,"name inserted",99)2 | (367871) | (367871,"Name 367871updated",72)3 | (3000004) | 4 | | (3000005,"name inserted",99)5 | (3000005) |
(5 rows)test=# SELECT pg_relation_filepath('big_table');pg_relation_filepath
----------------------base/16389/16949
(1 row)# 查询 物理文件是否发生变化ls -lth |grep 16949
-rw-------. 1 postgres postgres 108M Feb 14 16:52 16949
-rw-------. 1 postgres postgres 48K Feb 14 16:52 16949_fsm# 检查膨胀率 test=# SELECT * FROM pgstattuple('big_table');table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------112607232 | 2000000 | 98665260 | 87.62 | 8 | 384 | 0 | 229804 | 0.2
(1 row)
重建表总结:
原理介绍
pg_repack插件支持对全表和索引进行repack操作。
对全表进行repack的实现原理如下:
1.创建日志表,记录repack期间对原表的变更。
2.在原表上创建触发器,将原表的INSERT、UPDATE和DELETE操作记录到日志表中。
3.创建原表结构相同的新表并将原表数据导入其中。
4.在新表中创建与原表相同的索引。
5.将日志表里的变更(即repack期间表上产生的增量数据)应用到新表。
6.在系统catalog交换新旧表。
7.删除旧表。
相关文章:

PostgreSQL pg_repack 重新组织表并释放表空间
pg_repack pg_repack是 PostgreSQL 的一个扩展,它允许您从表和索引中删除膨胀,并可选择恢复聚集索引的物理顺序。与CLUSTER和VACUUM FULL不同,它可以在线工作,在处理过程中无需对已处理的表保持独占锁定。pg_repack 启动效率高&a…...

通过 Markdown 改进 RAG 文档处理
通过 Markdown 改进 RAG 文档处理 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/29139791931 通过 Markdown 改进 RAG 文档处理https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw 如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果 Mar…...
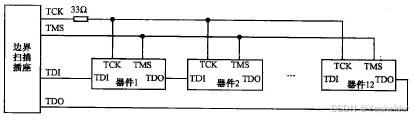
高速电路 PCB 设计要点一
3 高速电路 PCB 设计要点 3.1 PCB设计与信号完整性 随着电子技术的发展,电路的规模越来越大,单个器件集成的功能越来越多,速率越来越高,而器件的尺寸越来越小。由于器件尺寸的减小,器件引脚信号变化沿的速率变得越来…...

【Centos】centos7内核升级-亲测有效
相关资源 通过网盘分享的文件:脚本升级 链接: https://pan.baidu.com/s/1yrCnflT-xWhAPVQRx8_YUg?pwd52xy 提取码: 52xy –来自百度网盘超级会员v5的分享 使用教程 将脚本文件上传到服务器的一个目录 执行更新命令 yum install -y linux-firmware执行脚本即可 …...
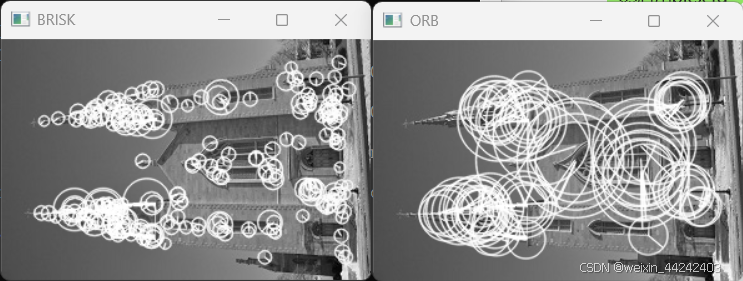
Opencv计算机视觉编程攻略-第八节 检测兴趣点
目录 1.检测图像中的角点 2.快速检测特征 3.尺度不变特征的检测 4.多尺度FAST 特征的检测 在计算机视觉领域,兴趣点(也称关键点或特征点)应用包括目标识别、图像配准、视觉跟踪、三维重建等。这个概念的原理是,从图像中选取某…...

On Superresolution Effects in Maximum Likelihood Adaptive Antenna Arrays论文阅读
On Superresolution Effects in Maximum Likelihood Adaptive Antenna Arrays 1. 论文的研究目标与实际问题意义1.1 研究目标1.2 解决的实际问题1.3 实际意义2. 论文提出的新方法、模型与公式2.1 核心创新:标量化近似表达式关键推导步骤:公式优势:2.2 与经典方法的对比传统方…...
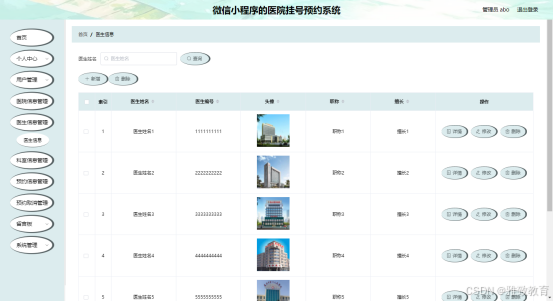
基于微信小程序的医院挂号预约系统设计与实现
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本微信小程序医院挂号预约系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大…...
如何保障话费api接口的稳定性?
保障话费接口的稳定性是确保服务高效运行的关键。以下是基于最新信息的建议: 1. 选择可靠的API服务提供商 信誉和稳定性:选择有良好声誉和稳定服务记录的提供商,查看其服务水平协议(SLA)以确保高可用性。技术支持&…...
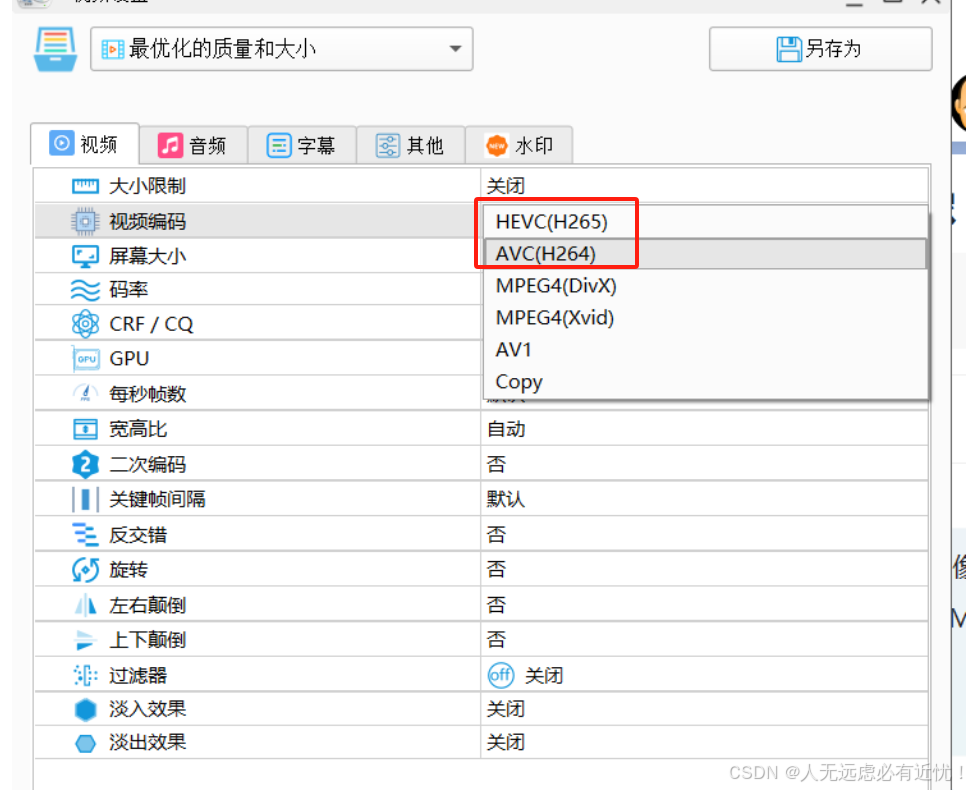
video标签播放mp4格式视频只有声音没有图像的问题
video标签播放mp4格式视频只有声音没有图像的问题 这是由于视频格式是hevc(H265)编码的,这种编码格式视频video播放有问题主要是由于以下两种原因导致的: 1、浏览器没有开启硬加速模式: 开启方法(以谷歌浏览器为例)&a…...

解决docker部署的容器第二天访问报错139的问题
前阵子我部署项目,把数据库放宿主机上,结果电脑一重启,Docker 直接把数据库删了个精光!我当时的表情 be like 😱:"我的数据呢???" 连备份都没来得及做…...

如何对接银行卡二要素核验接口?
银行卡二要素核验接口是一种通过API(应用程序编程接口)实现对用户提供的银行卡信息进行基本身份验证的技术服务,主要用于核验银行卡号与持卡人姓名是否一致,从而确认用户身份的真实性和操作合法性。 银行卡二要素核验接口通过调用…...

高效深度学习lecture01
lecture01 零样本学习(Zero-Shot Learning, ZSL): 模型可以在没有见过某种特定任务或类别的训练样本的情况下,直接完成对应的任务 利用知识迁移 模型在一个任务上训练时学到的知识,能够迁移到其他任务上比如,模型知道“狗”和“…...

用ChatGPT-5自然语言描述生成完整ERP模块
一、技术实现原理 1.1 语义理解能力 理解维度技术指标典型应用业务术语识别准确率98.7%物料需求计划流程逻辑上下文关联度0.92生产排程设计数据关系实体识别F1值0.95财务科目设置约束条件规则匹配率89%库存警戒规则 1.2 模块生成流程 五阶段生成机制: 需求澄清…...

深度学习——深入解读各种卷积的应用场景优劣势与实现细节
前言 卷积操作在深度学习领域中占据着核心地位,其在多种神经网络架构中发挥着关键作用。然而,卷积的种类繁多,每种卷积都有其独特的定义、应用场景和优势。 对于那些对深度学习中不同卷积类型(例如 2D 卷积、3D 卷积、11 卷积、转…...

python大数据相关职位,还需要学习java哪些知识
一、核心需要掌握的 Java 知识 1. Java 基础语法 语法基础:变量、数据类型、流程控制、异常处理(对比 Python 的差异)。面向对象编程(OOP):类、继承、多态、接口(Java 的 OOP 比 Pyth…...

easyPan技术回顾day4
1.主页删除接口(移动到回收站) 流程: 1.先查询要删除的文件是否存在。 2.递归获取选中的内容,以及(状态为USING)的所有子目录将其放到(delFilePidList) 3.将delFilePidList的所有子…...
Pyinstaller 打包flask_socketio为exe程序后出现:ValueError: Invalid async_mode specified
Pyinstaller 打包flask_socketio为exe程序后出现:ValueError: Invalid async_mode specified 一、详细描述问题描述 Traceback (most recent call last): File "app_3.py", line 22, in <module> File "flask_socketio\__init__.py"…...
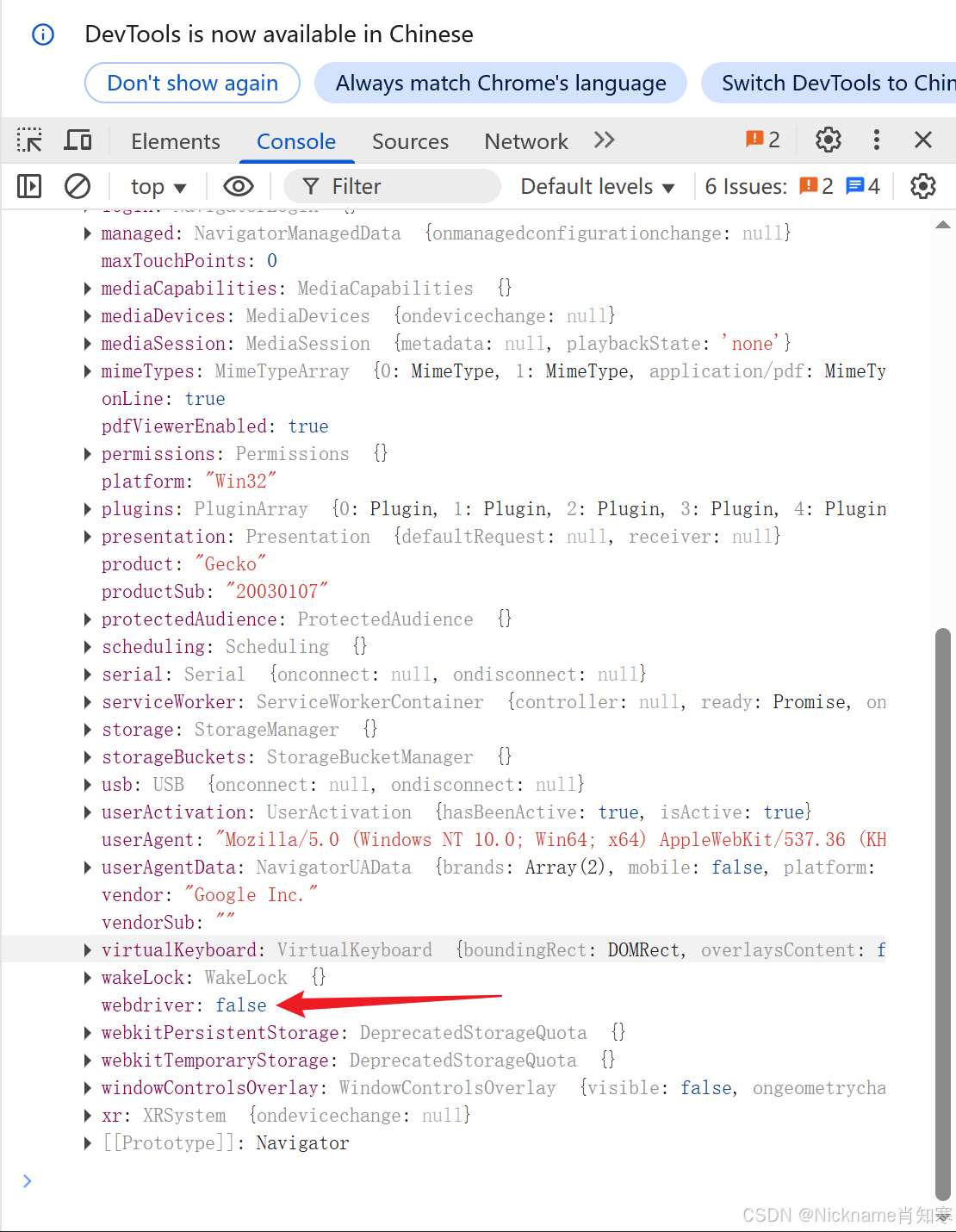
chromium魔改——navigator.webdriver 检测
chromium源码官网 https://source.chromium.org/chromium/chromium/src 说下修改的chromium源码思路: 首先在修改源码过检测之前,我们要知道它是怎么检测的,找到他通过哪个JS的API来做的检测,只有知道了如何检测,我们…...

【力扣hot100题】(048)二叉树的最近公共祖先
依旧只会用递归栈。 栈记录当前遍历的节点,如果有一个节点已经被找到,则不往栈中添加新节点,并且每次回溯删除栈顶节点,每次回溯判断另一个节点有没有在栈顶节点的右边。 /*** Definition for a binary tree node.* struct Tree…...

C 语言中的递归:概念、应用与实例解析
一、引言 在 C 语言编程领域中,递归是一个既强大又有趣的概念。它指的是在函数的定义中使用函数自身的方法。递归的思想在解决许多复杂问题时能够提供简洁而优雅的解决方案。就如同那个经典的故事:“从前有座山,山里有座庙,庙里有…...

FFmpeg录制屏幕和音频
一、FFmpeg命令行实现录制屏幕和音频 1、Windows 示例 #include <cstdlib> #include <string> #include <iostream>int main() {// FFmpeg 命令行(录制屏幕 麦克风音频)std::string command "ffmpeg -f gdigrab -framerate 3…...

爬虫:请求头,requests库基本使用
请求方式:get(向服务器要资源)和post(提交资源) user-agent:模拟正常用户的一种方式 cookie:登陆保持 referer:表示当前这一次请求是由哪个请求过来的 抓取数据包得到的内容才是判断依据elements中的源码是渲染之后的不能作为…...

[物联网iot]对比WIFI、MQTT、TCP、UDP通信协议
第一步:先理解最基础的关系(类比快递) 假设你要给朋友寄快递: Wi-Fi:相当于“公路和卡车”,负责把包裹从你家运到快递站。 TCP/UDP:相当于“快递公司的运输规则”。 TCP:顺丰快递&…...
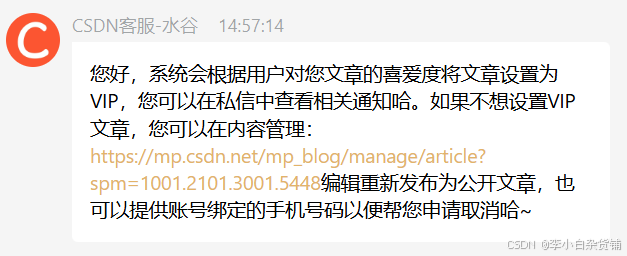
CSDN自动设置vip文章的解除办法
文章目录 CSDN真的会将“全部可见”文章偷偷自动设置为“VIP可读”最省事的途径:联系客服,预计1-2个工作日可以取消新版“内容管理”内手工操作 CSDN真的会将“全部可见”文章偷偷自动设置为“VIP可读” 今天无意中发现之前一些公开的文章变为仅VIP可读…...

P4305 [JLOI2011] 不重复数字
使用stl中的动态数组和unordered_map #include<iostream> #include<iostream> #include<vector> #include<unordered_map> using namespace std; int t; int main(){cin>>t;while(t--){//每次处理一组数据.int n;cin>>n;vector<int&…...

Joomla教程—Joomla 模块管理与Joomla 模块类型介绍
Joomla 模块管理 原文:Joomla 模块管理_w3cschool 模块管理,从文字意面上理解,可想而知,就是管理网站中所有的模块,模块的增、删、改、查都会在模块管理进行。这一节将简单介绍joomla后台的模块管理 1、模块管理的界…...

安装gvm后普通用户模式下无法使用cd切换目录
安装gvm后普通用户模式下无法使用cd切换目录 今天装完gvm后发现无法使用cd来切换目录了。。。 1.使用type cd命令发现cd命令被定义为了函数 usrusr-pc:~$ type cd cd 是函数 cd () { if __gvm_is_function __gvm_oldcd; then__gvm_oldcd $*;fi;local dot_go_version dot_go_…...

Pyspark学习二:快速入门基本数据结构
写在前面:实际工作中其实不需要自己安装和配置,更重要的是会用。所以就不研究怎么安装配置了。 前面介绍过:简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海…...
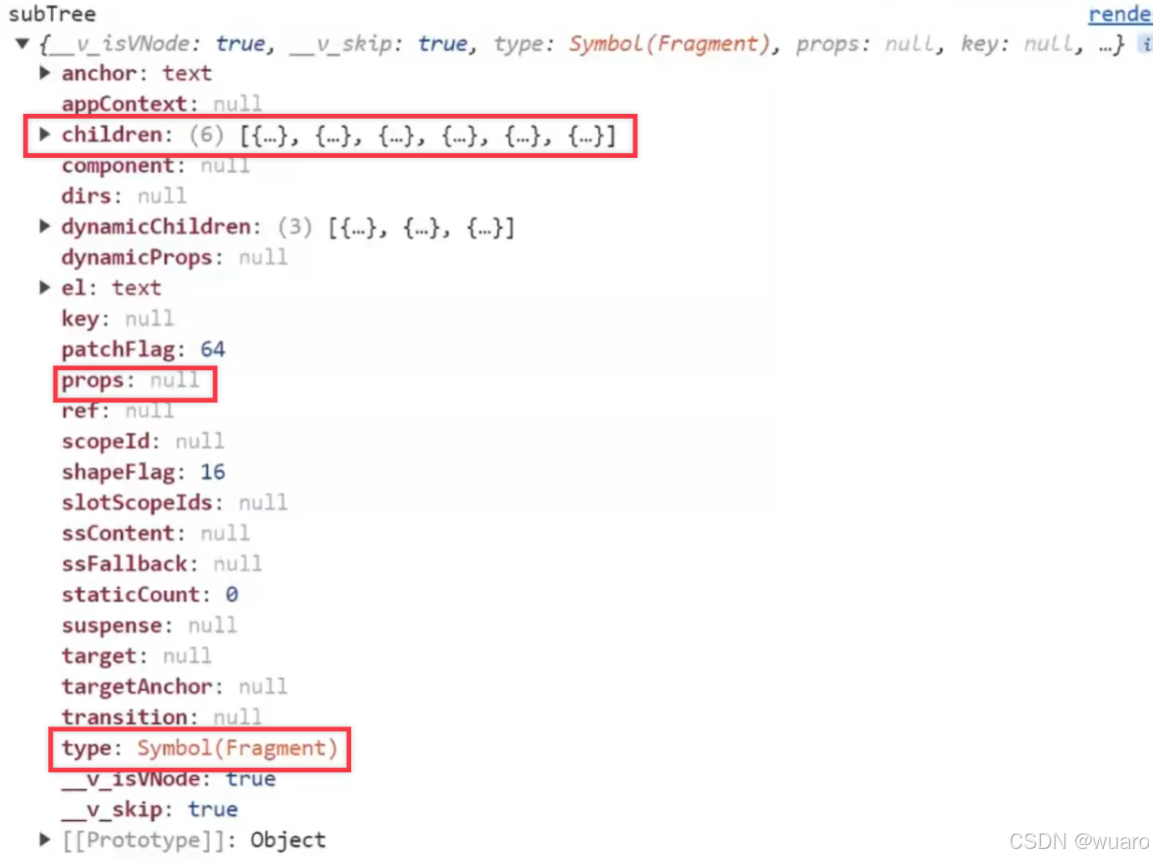
Vue中虚拟DOM创建到挂载的过程
Vue中虚拟DOM创建到挂载的过程 流程概括下来基本上就是:模板 → AST → render函数 → 虚拟节点 → 挂载 AST:抽象语法树,它用于记录原始代码中所有的关键信息,根据AST可以将代码从一种语言转化为另一种语言。 虚拟DOM创建到挂载…...

选择网上购物系统要看几方面?
随着电子商务的迅猛发展,选择一个合适的网上购物系统已成为许多企业成功的关键。无论是初创企业还是已经成熟的公司,选择合适的购物系统都能显著提升用户体验、提高销售额和优化运营效率。本文将从几个重要方面探讨选择网上购物系统时需要考虑的关键因素…...