大模型中的参数规模与显卡匹配
在大模型训练和推理中,显卡(GPU/TPU)的选择与模型参数量紧密相关,需综合考虑显存、计算能力和成本。以下是不同规模模型与硬件的匹配关系及优化策略:
一、参数规模与显卡匹配参考表
| 模型参数量 | 训练阶段推荐显卡 | 推理阶段推荐显卡 | 关键限制因素 |
|---|---|---|---|
| 1B以下 | 1-2×RTX 4090 (24GB) | 1×RTX 3090 (24GB) | 显存容量 |
| 1B-7B | 4-8×A100 40GB | 1×A10G (24GB) | 显存+计算单元 |
| 7B-70B | 16-64×H100 80GB + NVLink | 2-4×A100 80GB | 多卡通信带宽 |
| 70B-1T | 数百张H100 + InfiniBand集群 | 8×H100 + TensorRT-LLM | 分布式训练框架稳定性 |
二、关键硬件指标解析
1. 显存需求计算
模型显存占用 ≈ 参数显存 + 激活值显存 + 优化器状态
- 参数显存:
- FP32参数:每10亿参数 ≈ 4GB
- FP16/BF16:每10亿参数 ≈ 2GB
- 优化器状态(以Adam为例):
- 每参数需存储参数、动量、方差 → 额外12字节/参数
- 70B模型优化器状态 ≈ 70×12 = 840GB
示例:
训练7B模型(FP16)最低显存需求:
7×2GB (参数) + 7×12GB (优化器) + 激活值 ≈ 100GB → 需多卡分布式训练
2. 计算能力需求
- TFLOPS利用率:
- A100 FP16算力:312 TFLOPS
- H100 FP16算力:756 TFLOPS
- 吞吐量估算:
70B模型在8×H100上约生成 50 token/s(使用vLLM优化)
三、训练阶段的硬件策略
1. 单卡小模型(<7B)
- 配置示例:
- 显卡:A6000 (48GB)
- 技术:梯度累积(batch=4时累积8步)
- 框架:PyTorch + FSDP
# FSDP自动分片示例
from torch.distributed.fsdp import FullyShardedDataParallel
model = FullyShardedDataParallel(model)
2. 多卡中大模型(7B-70B)
- 推荐方案:
- 8-32×A100/H100 + NVLink
- 并行策略:
- Tensor并行:拆分权重矩阵(Megatron-LM)
- Pipeline并行:按层分片(GPipe)
- 数据并行:多副本数据分片
# 启动Megatron-LM训练
python -m torch.distributed.launch --nproc_per_node=8 pretrain_gpt.py \--tensor-model-parallel-size 4 \--pipeline-model-parallel-size 2
3. 超大规模(>70B)
- 基础设施:
- 超算集群(如Microsoft的NDv5实例:8×A100 80GB/节点)
- 通信优化:InfiniBand + 3D并行(数据+Tensor+Pipeline)
四、推理阶段的硬件优化
1. 量化技术节省显存
| 量化方法 | 显存压缩比 | 精度损失 | 适用场景 |
|---|---|---|---|
| FP16 | 2x | 可忽略 | 通用推理 |
| INT8 | 4x | <1% | 对话机器人 |
| GPTQ-4bit | 8x | 1-3% | 边缘设备部署 |
示例:
70B模型原始显存需求(FP16):140GB → GPTQ-4bit后仅需17.5GB
2. 推理加速框架
- vLLM:PagedAttention实现高吞吐
python -m vllm.entrypoints.api_server --model meta-llama/Llama-3-70b --quantization awq - TensorRT-LLM:NVIDIA官方优化
from tensorrt_llm import builder builder.build_llm_engine(model_dir="llama-70b", dtype="float16")
五、成本对比分析
| 显卡型号 | 单卡价格 | 适合模型规模 | 每10亿参数训练成本* |
|---|---|---|---|
| RTX 4090 | $1,600 | <3B | $0.8/hr |
| A100 40GB | $10,000 | 3B-20B | $3.2/hr |
| H100 80GB | $30,000 | 20B-1T | $8.5/hr |
*基于AWS p4d.24xlarge实例估算
六、选型建议
-
初创团队:
- 7B以下模型:A10G(推理)/ A100 40GB(训练)
- 使用LoRA微调减少显存需求
-
企业级部署:
- 70B模型:H100集群 + vLLM服务化
- 采用Triton推理服务器实现动态批处理
-
学术研究:
- 租用云GPU(Lambda Labs / RunPod)
- 使用Colab Pro+(有限制)
关键结论
- 7B是分水岭:单卡可推理,多卡才能训练
- H100性价比:对于>20B模型,其NVLink带宽(900GB/s)远优于A100(600GB/s)
- 未来趋势:B100/B200发布后将进一步降低大模型硬件门槛
实际部署前,建议使用NVIDIA DGX Cloud进行性能测试。
相关文章:

大模型中的参数规模与显卡匹配
在大模型训练和推理中,显卡(GPU/TPU)的选择与模型参数量紧密相关,需综合考虑显存、计算能力和成本。以下是不同规模模型与硬件的匹配关系及优化策略: 一、参数规模与显卡匹配参考表 模型参数量训练阶段推荐显卡推理阶…...

数据结构初阶: 顺序表的增删查改
顺序表 概念 顺序表是⽤⼀段物理地址连续的存储单元依次存储数据元素的线性结构,⼀般情况下采⽤数组存储。如图1: 顺序表和数组有什么区别? 顺序表的底层是用数组实现的,是对数组的封装,实现了增删查改等接口。 分…...

Spring Boot项目中策略模式的应用与实现
前言 在Spring Boot项目中,策略模式是一种非常重要的设计模式,它能够让我们定义一系列算法,并使它们可以互相替换。 策略模式通过将算法封装到独立的类中,从而使得代码中的算法可以独立于使用它的客户端变化。 这对于某些需求频…...

【机器学习中的基本术语:特征、样本、训练集、测试集、监督/无监督学习】
机器学习基本术语详解 1. 特征(Feature) 定义:数据的属性或变量,用于描述样本的某个方面。作用:模型通过学习特征与目标之间的关系进行预测。示例: 预测房价时,特征可以是 面积、地段、房龄。…...

MySQL全链路指南
目录 前言 第一章 MySQL基础入门 1.1 MySQL简介与安装 1.2 数据库基本操作 1.3 表结构与数据类型 第二章 SQL语言深度解析 2.1 DDL(数据定义语言) 2.2 DML(数据操作语言) 2.3 DQL(数据查询语言) 2…...
)
System.arraycopy()
在 Java 编程中,数组是一种常用的数据结构,用于存储相同类型的元素集合。在处理数组时,经常需要进行数组复制操作,例如将一个数组的部分或全部元素复制到另一个数组中。System.arraycopy() 方法是 Java 提供的一个高效的数组复制工…...
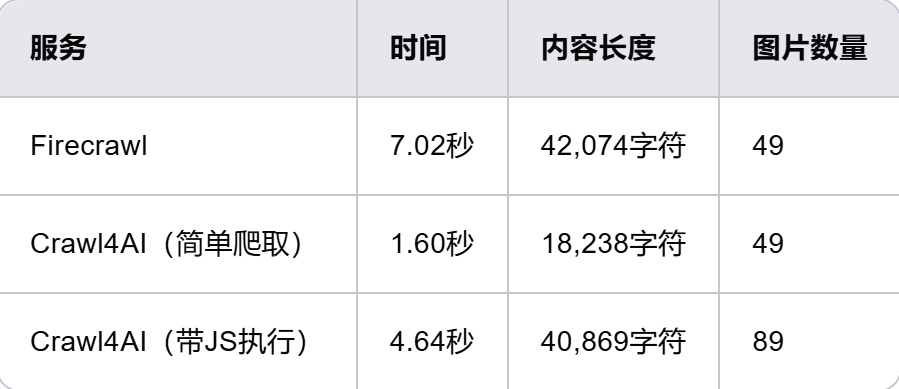
详解AI采集框架Crawl4AI,打造智能网络爬虫
大家好,Crawl4AI作为开源Python库,专门用来简化网页爬取和数据提取的工作。它不仅功能强大、灵活,而且全异步的设计让处理速度更快,稳定性更好。无论是构建AI项目还是提升语言模型的性能,Crawl4AI都能帮您简化工作流程…...
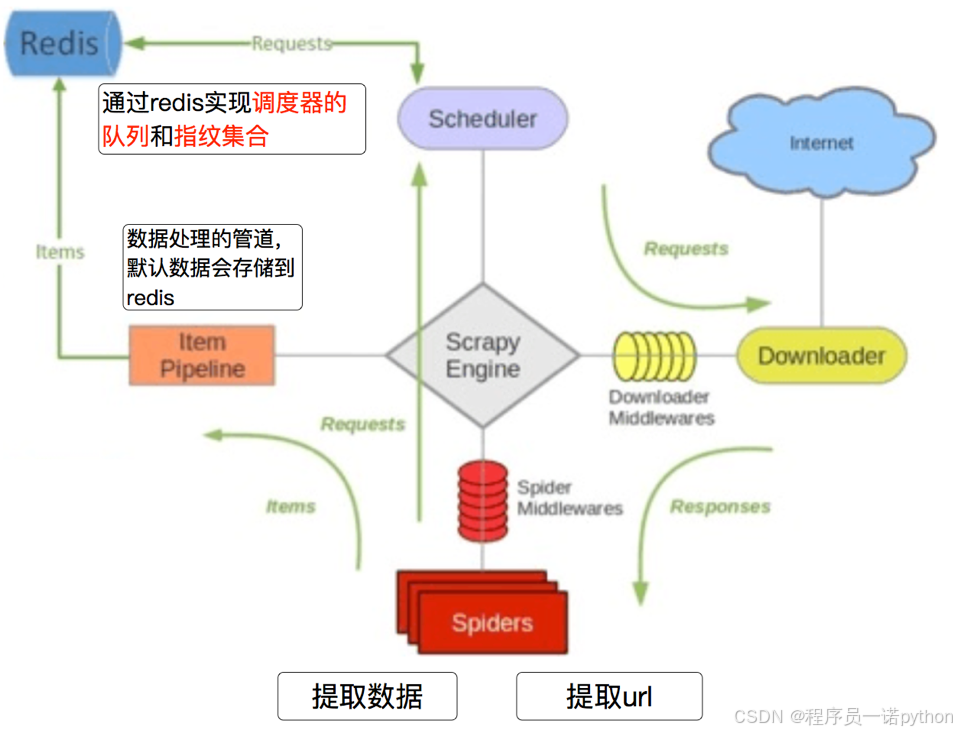
【爬虫开发】爬虫开发从0到1全知识教程第14篇:scrapy爬虫框架,介绍【附代码文档】
本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:…...

MySQL索引原理:从B+树手绘到EXPLAIN
最近在学后端,学到了这里做个记录 一、为什么索引像书的目录? 类比:500页的技术书籍 vs 10页的目录缺点:全表扫描就像逐页翻找内容优点:索引将查询速度从O(n)提升到O(log n) 二、B树手绘课堂 1. 结构解剖࿰…...
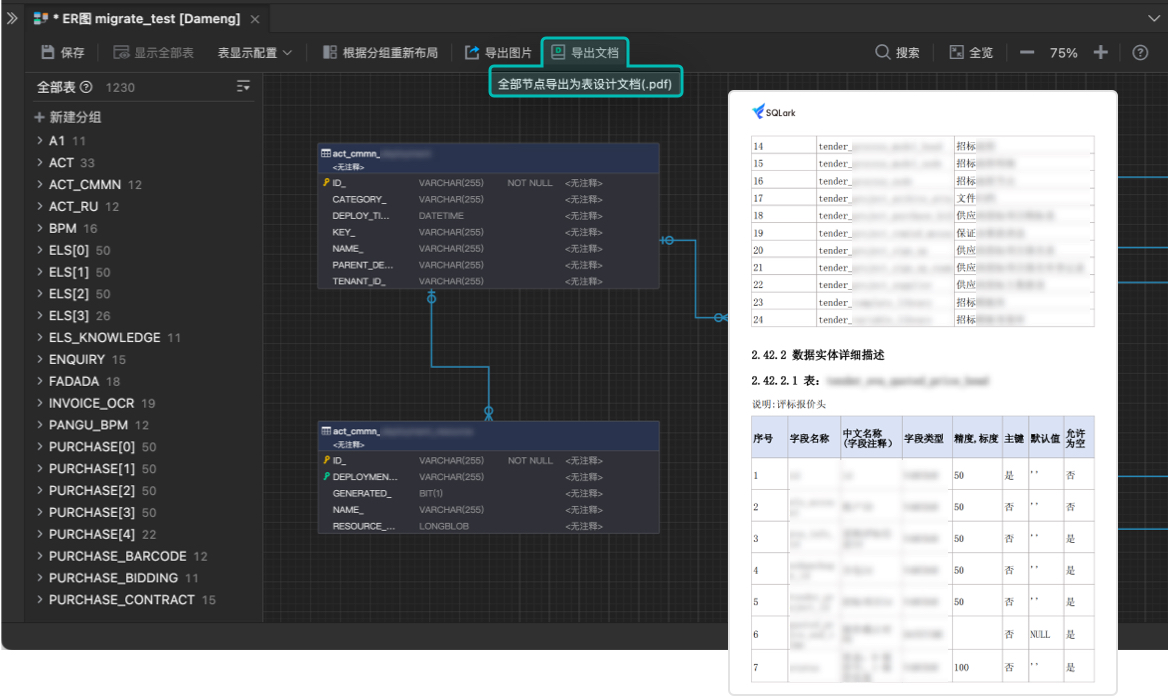
SQLark:一款国产免费数据库开发和管理工具
SQLark(百灵连接)是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统,目前可以支持达梦数据库、Oracle 以及 MySQL。 对象管理 SQLark 支持丰富的数据库对象管理功能,包括…...

防爆对讲机VS非防爆对讲机,如何选择?
在通信设备的广阔市场中,对讲机以其高效、便捷的特点,成为众多行业不可或缺的沟通工具。而面对防爆对讲机与非防爆对讲机,许多用户常常陷入选择困境。究竟该如何抉择,且听我为您细细道来。 防爆对讲机,专为危险作业场…...

微信小程序开发:开发实践
微信小程序开发实践研究 摘要 随着移动互联网的迅猛发展,微信小程序作为一种轻量化、无需安装的应用形式,逐渐成为开发者和用户的首选。本文以“个人名片”小程序为例,详细阐述了微信小程序的开发流程,包括需求分析、项目规划、…...

操作 Office Excel 文档类库Excelize
Excelize 是 Go 语言编写的一个用来操作 Office Excel 文档类库,基于 ECMA-376 OOXML 技术标准。可以使用它来读取、写入 XLSX 文件,相比较其他的开源类库,Excelize 支持操作带有数据透视表、切片器、图表与图片的 Excel 并支持向 Excel 中插…...

青铜与信隼的史诗——TCP与UDP的千年博弈
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 第一章 契约之匣与自由之羽 熔岩尚未冷却的铸造台上,初代信使长欧诺弥亚将液态秘银倒入双生模具。左侧模具刻着交握的青铜手掌,右侧则是展开的隼翼纹章。当星辰…...
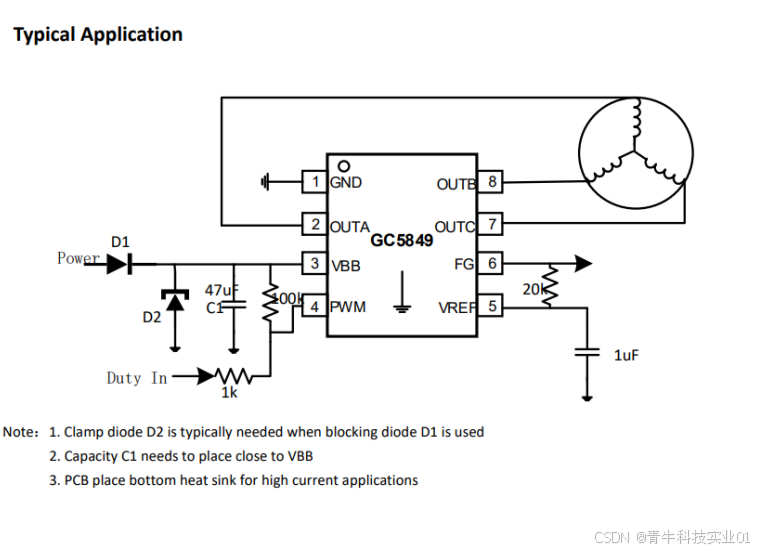
「青牛科技」GC5849 12V三相无感正弦波电机驱动芯片
芯片描述: • 4 ~ 20V 工作电压, 30V 最大耐压 • 驱动峰值电流 2.0A ,连续电流 800mA 以内 • 芯片内阻: 900mΩ (上桥 下桥) • eSOP-8 封装,底部 ePAD 散热,引…...

Java基础之反射的基本使用
简介 在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意属性和方法;这种动态获取信息以及动态调用对象方法的功能称为Java语言的反射机制。反射让Java成为了一门动…...
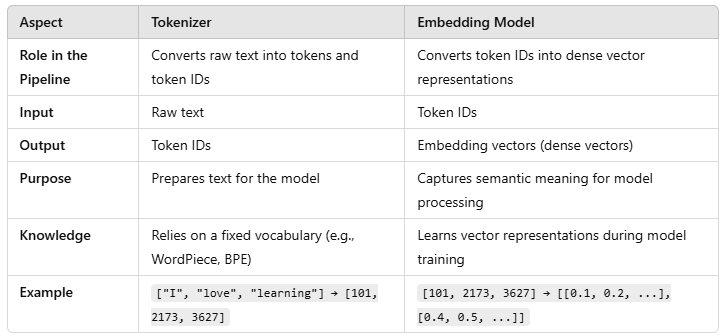
大语言模型中的嵌入模型
本教程将拆解什么是嵌入模型、为什么它们在NLP中如此重要,并提供一个简单的Python实战示例。 分词器将原始文本转换为token和ID,而嵌入模型则将这些ID映射为密集向量表示。二者合力为LLMs的语义理解提供动力。图片来源:[https://tzamtzis.gr/2024/coding/tokenization-by-an…...

【从零实现Json-Rpc框架】- 项目实现 - 服务端主题实现及整体封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
的作用)
位置编码(Positional Encoding, PE)的作用
在神经网络(尤其是Transformer、RNN等序列模型)中,位置编码(Positional Encoding, PE)的作用是为模型提供序列中元素的位置信息,以弥补模型本身对顺序感知的不足。 为什么Transformer需要位置编码…...
开源的 LLM 应用开发平台Dify的安装和使用
文章目录 前提环境应用安装deocker desktop镜像源配置Dify简介Dify本地docker安装Dify安装ollama插件Dify安装硅基流动插件简单应用练习进阶应用练习数据库图像检索与展示助手echart助手可视化 前提环境 Windows环境 docker desktop魔法环境:访问Dify项目ollama电脑…...
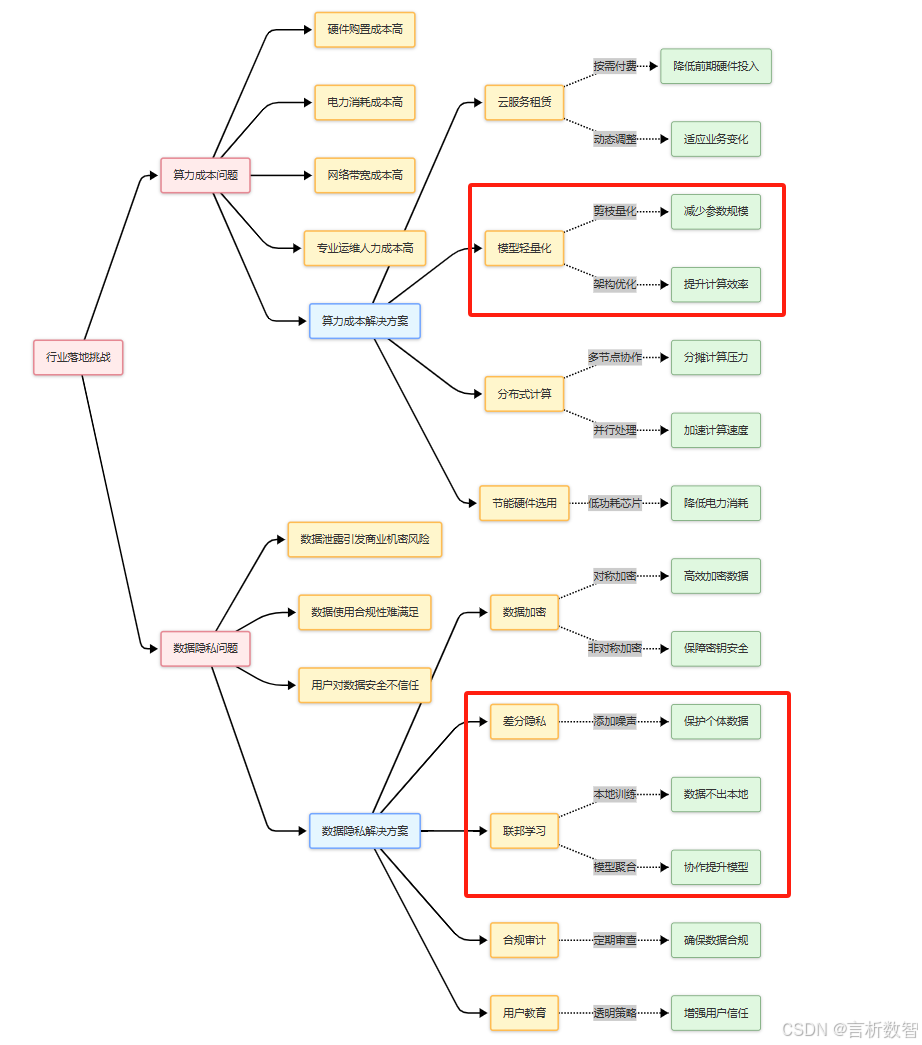
从零构建大语言模型全栈开发指南:第五部分:行业应用与前沿探索-5.1.2行业落地挑战:算力成本与数据隐私解决方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 从零构建大语言模型全栈开发指南-第五部分:行业应用与前沿探索5.1.2 行业落地挑战:算力成本与数据隐私解决方案1. 算力成本挑战与优化策略1.1 算力成本的核心问题1.2 算力优化技术方案2. 数据隐私挑战…...
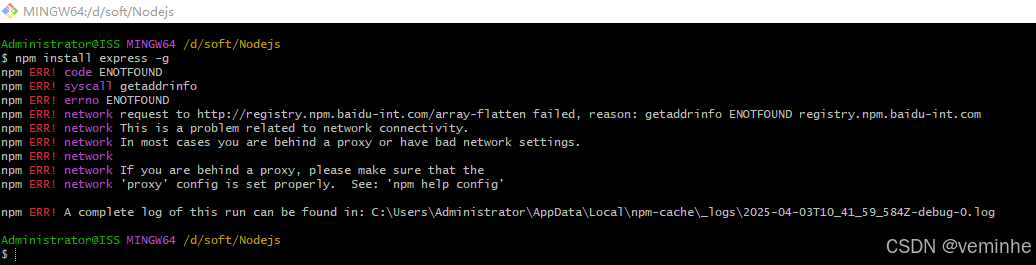
NodeJS--NPM介绍使用
1、使用npm install命令安装模块 1.1、本地安装 npm install express 1.2、全局安装 npm install express -g 1.3、本地安装和全局安装的区别...

DeepSeek与ChatGPT的优势对比:选择合适的工具来提升工作效率
选DeepSeek还是ChatGPT?这就像问火锅和披萨哪个香! "到底该用DeepSeek还是ChatGPT?” 这个问题最近在互联网圈吵翻天!其实这就跟选手机系统-样,安卓党iOS党都能说出一万条理由,但真正重要的是你拿它来干啥!&am…...

lib-zo,C语言另一个协程库,sleep协程化,睡眠
lib-zo,C语言另一个协程库,sleep协程化,睡眠 另一个 C 协程库 https://blog.csdn.net/eli960/article/details/146802313 重载了 sleep 函数, 使其支持协程化 另外毫秒单位睡眠函数 void zcoroutine_sleep_millisecond(int milliseconds);例子 #include "coroutine.h…...
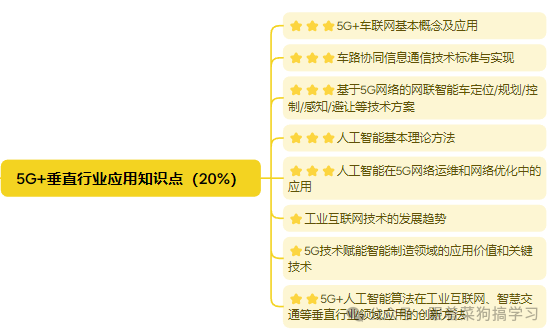
25大唐杯赛道一本科B组知识点大纲(下)
5G/6G网络技术知识点(10%) 工程概论及通信工程项目实践(20%) 5G垂直行业应用知识点(20%) ⭐⭐⭐为重点知识,尽量要过一遍哦 大唐杯赛道一国一备赛思路 大唐杯国一省赛回忆录--有付出就会有收…...

Python+Playwright自动化测试-1-环境准备与搭建
1、Playwright 是什么? 微软在 2020 年初开源的新一代自动化测试工具,它的功能类似于 Selenium、Pyppeteer 等,都可以驱动浏览器进行各种自动化操作。它的功能也非常强大,对市面上的主流浏览器都提供了支持,API 功能简…...

生产管理系统如何破解汽车零部件行业追溯难痛点
在汽车零部件制造行业中,生产追溯一直是企业面临的核心挑战之一。随着市场竞争的加剧和客户需求的日益复杂,如何确保产品质量、快速定位问题源头、减少批次性返工,成为了每个企业亟待解决的问题。而生产管理系统,作为智能制造的重…...
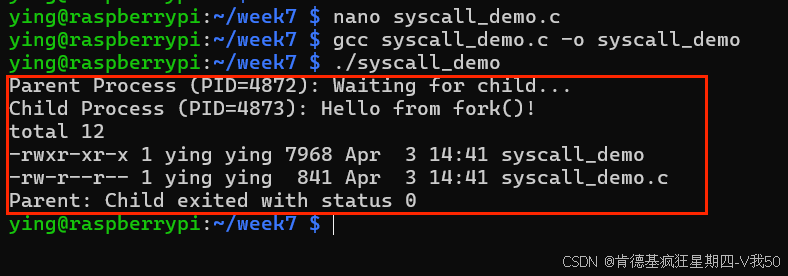
【XTerminal】【树莓派】Linux系统下的函数调用编程
目录 一、XTerminal下的Linux系统调用编程 1.1理解进程和线程的概念并在Linux系统下完成相应操作 (1) 进程 (2)线程 (3) 进程 vs 线程 (4)Linux 下的实践操作 1.2Linux的“虚拟内存管理”和stm32正式物理内存(内存映射)的区别 (1)Linux虚拟内存管…...

umi框架开发移动端h5
1、官网:https://umijs.org/ 2、创建出来的项目 yarn create umi yarn start3、推荐目录结构 . ├── config │ └── config.ts ├── public//静态资源 ├── dist ├── mock │ └── app.ts|tsx ├── src │ ├── .umi │ ├── .um…...

TDengine 重磅功能虚拟表
简介 虚拟表功能是 TDengine 最近刚发现的 3.3.6.0 版本中一项重磅级新功能,虚拟表可理解为在原来查询基础上做了一层逻辑表,在数据查询建模时即可不依赖底层物理存储表,直接通过虚拟表进行数据查询建模,这样逻辑上会更加清晰&am…...