预测分析(三):基于机器学习的分类预测
文章目录
- 基于机器学习的分类预测
- 分类任务
- 逻辑回归
- 分类树
- 分类树的工作原理
- 随机森林
- 多元分类
- 朴素贝叶斯分类器
- 贝叶斯公式
- 回到分类问题
- **1. 算法原理**
- **2. 主要类型**
- **(1) 高斯朴素贝叶斯**
- **(2) 多项式朴素贝叶斯**
- **(3) 伯努利朴素贝叶斯**
- **3. 优缺点**
- **4. 应用场景**
- **5. 评估指标**
- **6. 示例代码(Python)**
基于机器学习的分类预测
分类任务
分类问题主要是分为三种类型:
- 二元标签类问题:目标中有两个类别的问题。
- 多元分类问题:目标多于两类的问题。
- 多标签分类问题:对观测指派的类别或标签多于一个的问题。
我们在这一章的核心任务就是预测的分类:
- 预测类别
- 预测每种类别可能的概率
在模型输出每种类别的情况下,分类依据是最高概率的类别预测。这是默认的,但是在特定的问题情境中,也会随之改变。
逻辑回归
现在正在使用机器学习执行分类任务。对于二元分类问题,逻辑模型可以生成目标属于正类的条件概率。这个模型是参数化模型的另一个示例,学习算法将尽可能挖掘性能最佳的参数组合 ω \omega ω,参数 ω \omega ω按照以下等式计算估计概率:
P ( y = 1 ∣ X ) = 1 1 + e − ω T X P\left(y=1|X\right)=\frac{1}{1+e^{-\omega^TX}} P(y=1∣X)=1+e−ωTX1
当目标属于正类的时候,得到的值接近 1 1 1;当目标属于负类的时候,得到的值接近 0 0 0。
分类树
分类树生成预测的方法是创建一些规则,连续运用这些规则,最终达到叶节点。
分类树的工作原理
我们深入研讨一下,分类树模型中的一系列规则是如何生成的?从本质上来说,分类树就是将特征空间划分为矩阵区域来生成预测。在分类的情形下,要尽量分割区域均匀。通常使用的方法是递归二元分割。假设有两个特征需要进行分割,我们要搞清楚:
- 应该选择哪个特征进行分割?
- 应该选择哪个点完成分割?
这种递归式的分割数据空间的方法一直持续到抵达某种停止准则。我们给出scikit-learn个简单参数用于控制分类的大小:
max_depthmin_samples_splitmin_samples_leaf
在scikit-learn库中,是基于基尼指数或者熵来确定划分的。
随机森林
随机森林(Random Forest)是一种基于决策树的集成学习模型,通过构建多棵决策树并结合它们的预测结果来提高泛化能力。
核心原理
- 集成学习:
- 自助采样(Bootstrap):从原始数据中随机抽取多个子集(有放回抽样),训练多棵决策树。
- 随机特征子集:每棵树在划分节点时,随机选择部分特征(如
max_features参数),降低树之间的相关性。
- 投票机制:
- 分类任务:通过多数投票确定最终类别;回归任务:取所有树预测值的平均值。
关键优势
- 抗过拟合:多棵树的平均效应减少了单棵树的噪声影响。
- 鲁棒性强:对缺失值、异常值不敏感,无需特征缩放。
- 天然支持多分类:直接通过投票处理多类别问题。
- 可解释性:通过特征重要性分析(
feature_importances_)解释模型决策。
核心参数
| 参数名 | 作用 |
|---|---|
n_estimators | 树的数量,越多模型越稳定,但计算成本越高(建议100+)。 |
max_depth | 单棵树的最大深度,控制复杂度(默认None,可能导致过拟合)。 |
max_features | 划分节点时随机选择的特征数(默认sqrt,适合分类;log2适合回归)。 |
min_samples_split | 节点分裂所需最小样本数,防止过拟合(与决策树参数类似)。 |
class_weight | 处理类别不平衡(如balanced自动调整权重)。 |
与决策树的对比
| 对比项 | 决策树 | 随机森林 |
|---|---|---|
| 模型复杂度 | 单棵树易过拟合 | 多棵树平均,泛化能力强 |
| 特征选择 | 全部特征 | 随机选择部分特征 |
| 预测稳定性 | 方差大 | 方差小 |
| 可解释性 | 直观(树结构) | 需通过特征重要性分析 |
多元分类
多元分类(Multi-class Classification)是指将样本分配到三个或更多互斥类别的任务。
常用策略
(1) One-vs-Rest (OvR)
- 原理:为每个类别训练一个二分类器(区分该类别与其他所有类别),预测时选择概率最高的类别。
- 优缺点:
- 优点:实现简单,适合类别较多的场景。
- 缺点:可能忽略类别间的细微差异,对噪声敏感。
(2) One-vs-One (OvO)
- 原理:为每对类别训练一个二分类器,预测时通过投票决定最终类别。
- 优缺点:
- 优点:训练更精细,避免类别不平衡问题。
- 缺点:计算成本高(需训练( \frac{C(C-1)}{2} )个模型,( C )为类别数)。
(3) 直接多分类算法
- Softmax回归:扩展逻辑回归,使用Softmax函数输出多类别概率。
- 决策树/随机森林:通过树结构直接划分多类别,天然支持多分类。
- 神经网络:使用Softmax激活函数和交叉熵损失函数。
** 评估指标**
- 准确率(Accuracy):正确分类的样本比例。
- 混淆矩阵:可视化各类别预测结果的交叉分布。
- 宏平均(Macro-average):各类别指标的平均值(适用于类别均衡场景)。
- 加权平均(Weighted-average):按类别样本数加权的平均值(适用于类别不平衡场景)。
- F1分数:综合精确率与召回率,衡量模型对少数类的识别能力。
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report# 加载多分类数据集(手写数字识别)
data = load_digits()
X, y = data.data, data.target# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化模型
clf = RandomForestClassifier(n_estimators=200, max_depth=5, random_state=42)# 训练与预测
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)# 评估
print(classification_report(y_test, y_pred))
朴素贝叶斯分类器
贝叶斯公式
P ( d e f a u l t ∣ m a l e ) = P ( m a l e ∣ d e f a u l t ) P ( d e f a u l t ) P ( m a l e ) P\left(default | male\right)=\frac{P\left(male|default \right)P\left(default\right)}{P\left(male\right)} P(default∣male)=P(male)P(male∣default)P(default)
- P ( d e f a u l t ∣ m a l e ) P\left(default | male\right) P(default∣male):后验概率
- P ( d e f a u l t ) P\left(default\right) P(default):先验概率
- P ( m a l e ∣ d e f a u l t ) P\left(male|default \right) P(male∣default) :似然,“逆”条件概率,即目标为真,信息为真的概率
- P ( m a l e ) P\left(male\right) P(male):信息概率
P o s t e r i o r = L i k e l i h o o d × P r i o r E v i d e n c e Posterior=\frac{Likelihood \times Prior}{Evidence} Posterior=EvidenceLikelihood×Prior
回到分类问题
1. 算法原理
朴素贝叶斯是一种基于贝叶斯定理的概率分类模型,其核心思想是通过特征的条件概率来预测类别。
核心公式:
P ( C ∣ X ) = P ( X ∣ C ) ⋅ P ( C ) P ( X ) P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)} P(C∣X)=P(X)P(X∣C)⋅P(C)
其中:
- C C C 是类别, X X X 是特征向量。
- P ( C ∣ X ) P(C|X) P(C∣X) 是后验概率(类别给定特征的概率)。
- P ( X ∣ C ) P(X|C) P(X∣C) 是似然度(特征给类别定的概率)。
- P ( C ) P(C) P(C) 是先验概率(类别本身的概率)。
- P ( X ) P(X) P(X) 是证据因子(特征的全概率)。
关键假设:
特征之间条件独立(即 P ( X 1 , X 2 , … , X n ∣ C ) = ∏ i = 1 n P ( X i ∣ C ) P(X_1,X_2,\dots,X_n|C) = \prod_{i=1}^n P(X_i|C) P(X1,X2,…,Xn∣C)=∏i=1nP(Xi∣C))。
这一假设简化了计算,但可能牺牲部分准确性。
2. 主要类型
根据数据类型的不同,朴素贝叶斯分为以下三类:
(1) 高斯朴素贝叶斯
- 适用数据:连续型特征(如身高、体重)。
- 假设:特征服从高斯分布(正态分布)。
- 公式:
P ( X i ∣ C ) = 1 2 π σ C , i 2 exp ( − ( X i − μ C , i ) 2 2 σ C , i 2 ) P(X_i|C) = \frac{1}{\sqrt{2\pi\sigma_{C,i}^2}} \exp\left(-\frac{(X_i - \mu_{C,i})^2}{2\sigma_{C,i}^2}\right) P(Xi∣C)=2πσC,i21exp(−2σC,i2(Xi−μC,i)2)
其中 μ C , i \mu_{C,i} μC,i 和 σ C , i 2 \sigma_{C,i}^2 σC,i2 是类别 C C C 下第 i i i 个特征的均值和方差。
(2) 多项式朴素贝叶斯
- 适用数据:离散型特征(如文本分类中的词频)。
- 假设:特征服从多项式分布。
- 公式:
P ( X i ∣ C ) = N C , i + α N C + α ⋅ n P(X_i|C) = \frac{N_{C,i} + \alpha}{N_C + \alpha \cdot n} P(Xi∣C)=NC+α⋅nNC,i+α
其中 N C , i N_{C,i} NC,i 是类别 C C C 中特征 i i i 出现的次数, N C N_C NC 是类别 C C C 的总特征数, α \alpha α 是平滑参数(防止零概率)。
(3) 伯努利朴素贝叶斯
- 适用数据:二值特征(如文本中的单词是否出现)。
- 假设:特征服从伯努利分布(二项分布)。
- 公式:
P ( X i ∣ C ) = p C , i ⋅ X i + ( 1 − p C , i ) ⋅ ( 1 − X i ) P(X_i|C) = p_{C,i} \cdot X_i + (1 - p_{C,i}) \cdot (1 - X_i) P(Xi∣C)=pC,i⋅Xi+(1−pC,i)⋅(1−Xi)
其中 p C , i p_{C,i} pC,i 是类别 C C C 中特征 i i i 为 1 1 1的概率。
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 计算效率高,适合大规模数据。 | 对特征条件独立假设敏感,若假设不成立则性能下降。 |
| 无需复杂调参。 | 对缺失值敏感。 |
| 能有效处理高维数据(如文本)。 | 无法捕捉特征间的交互关系。 |
4. 应用场景
- 文本分类(如垃圾邮件过滤、情感分析)。
- 实时预测(因计算速度快)。
- 推荐系统(基于用户行为的概率预测)。
- 医学诊断(基于症状的概率推断)。
5. 评估指标
与其他分类模型类似,常用:
- 准确率(Accuracy)
- 混淆矩阵
- 精确率(Precision)、召回率(Recall)、F1分数
- ROC曲线与AUC值(针对二分类问题)。
6. 示例代码(Python)
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report# 加载文本分类数据集
data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
X, y = data.data, data.target# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 文本向量化(TF-IDF)
vectorizer = TfidfVectorizer(max_features=5000)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)# 初始化模型
clf = MultinomialNB(alpha=0.1) # alpha为平滑参数# 训练与预测
clf.fit(X_train_vec, y_train)
y_pred = clf.predict(X_test_vec)# 评估
print(classification_report(y_test, y_pred))
相关文章:
:基于机器学习的分类预测)
预测分析(三):基于机器学习的分类预测
文章目录 基于机器学习的分类预测分类任务逻辑回归分类树分类树的工作原理 随机森林多元分类朴素贝叶斯分类器贝叶斯公式回到分类问题**1. 算法原理****2. 主要类型****(1) 高斯朴素贝叶斯****(2) 多项式朴素贝叶斯****(3) 伯努利朴素贝叶斯** **3. 优缺点****4. 应用场景****5…...

基于大模型预测升主动脉瘤的多维度诊疗研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的与意义 二、升主动脉瘤概述 2.1 定义与分类 2.2 发病原因与机制 2.3 流行病学现状 三、大模型技术原理及应用现状 3.1 大模型基本原理 3.2 在医疗领域的应用进展 3.3 针对升主动脉瘤预测的独特价值 四、术前大模型预测方案…...

解决Spring参数解析异常:Name for argument of type XXX not specified
前言 在开发 Spring Boot 应用时,我们常遇到类似 java.lang.IllegalArgumentException: Name for argument not specified 的报错。这类问题通常与方法参数名称的解析机制相关,尤其在使用 RequestParam、PathVariable 等注解时更为常见。 一、问题现象与…...

基数排序算法解析与TypeScript实现
基数排序(Radix Sort)是一种高效的非比较型整数排序算法,通过逐位分配与收集的方式实现排序。本文将深入解析其工作原理,并给出完整的TypeScript实现。 一、算法原理 1. 核心思想 多关键字排序:将整数按位数切割成不同…...
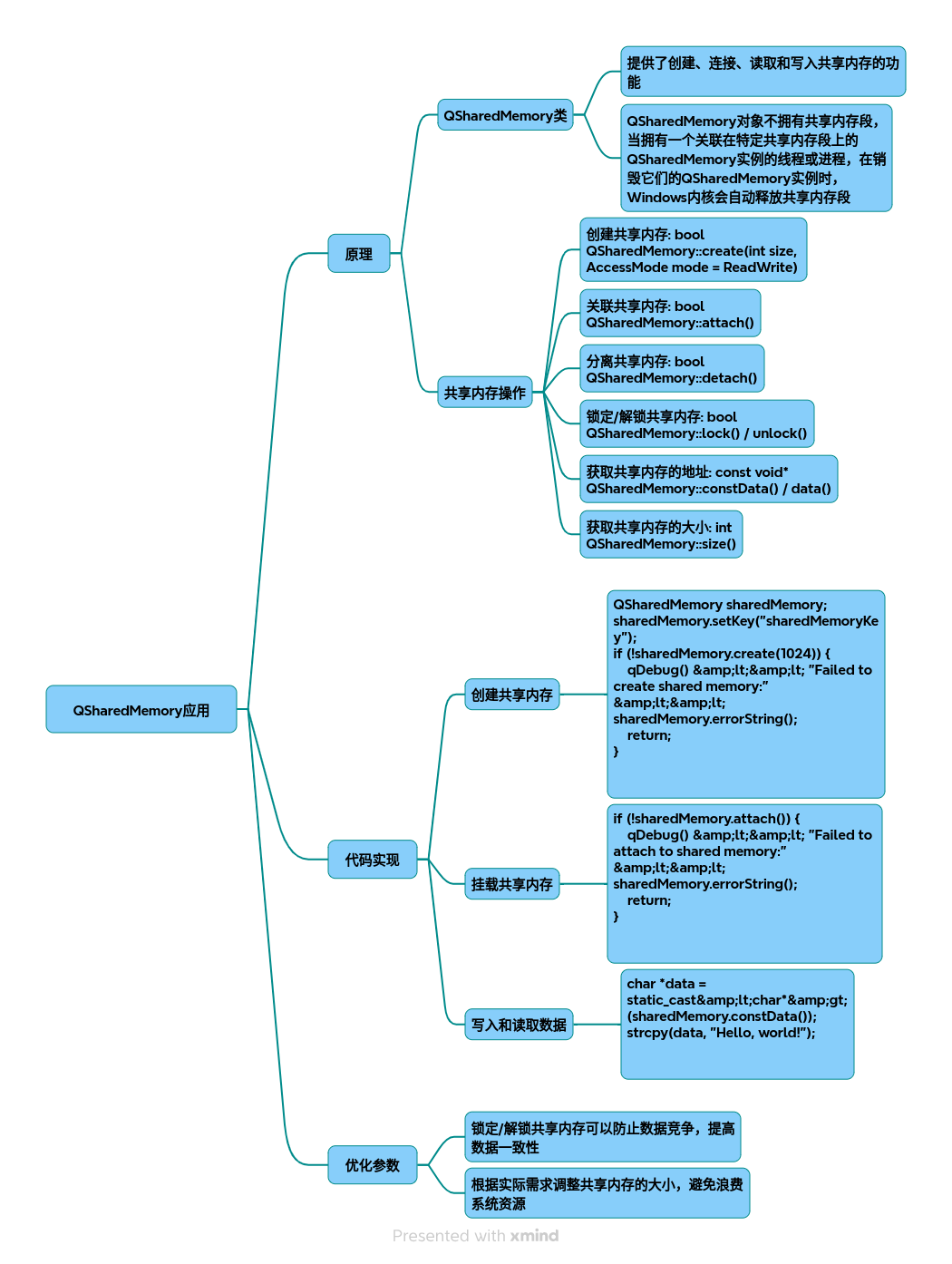
034-QSharedMemory
QSharedMemory 以下为针对 QSharedMemory 的技术调研及实现方案,包含原理、优化策略、完整代码实现及流程图解: 一、QSharedMemory 核心原理 1.1 共享内存机制 共享内存流程图 (注:此处应为共享内存IPC流程图,因文本…...

在 Ubuntu 上离线安装 Prometheus 和 Grafana
在 Ubuntu 上离线安装 Prometheus 和 Grafana 的步骤如下: 一.安装验证 二.安装步骤 1.准备离线安装包 在一台可以访问互联网的机器上下载 Prometheus 和 Grafana 的二进制文件。 Prometheus 下载地址:Prometheus 官方下载页面Grafana 下载地址&#…...
Ansible:playbook的高级用法
文章目录 1. handlers与notify2. tags组件3. playbook中使用变量3.1使用 setup 模块中变量3.2在playbook 命令行中定义变量3.3在playbook文件中定义变量3.4使用变量文件3.5主机清单文件中定义变量主机变量组(公共)变量 1. handlers与notify Handlers&am…...

【C++进阶九】继承和虚继承
【C进阶九】继承和虚继承 1.什么是继承2.继承关系2.1protected和private的区别2.2通过父类的函数去访问父类的private成员2.3默认继承 3.基类和派生类对象的赋值转换4.继承中的作用域5.子类中的默认成员函数6.继承与静态成员7. 菱形继承8.虚继承9.继承和组合 1.什么是继承 继承…...

近日八股——计算机网络
一.c. TCP握手为什么三次、不能是二次、或四次? i.不能是两次: 防止已经失效的连接报文突然又传到了服务端,产生错误 如果不采用三次握手,服务端直接建立连接,会白白浪费资源 三次握手告诉服务端,客户端有没有收这个数据&#…...

HOW - Axios 拦截器特性
目录 Axios 介绍拦截器特性1. 统一添加 Token(请求拦截器)2. 处理 401 未授权(响应拦截器)3. 统一处理错误信息(响应拦截器)4. 请求 Loading 状态管理5. 自动重试请求(如 429 过载)6…...
)
自适应信号处理任务(过滤,预测,重建,分类)
自适应滤波 # signals creation: u, v, d N = 5000 n = 10 u = np.sin(np.arange(0, N/10., N/50000...
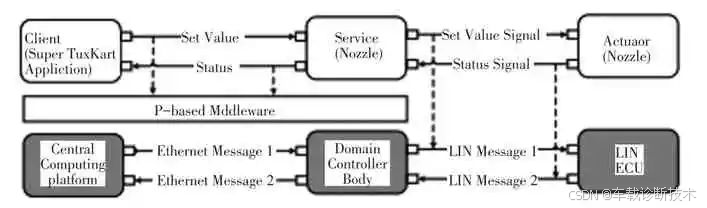
电子电气架构 --- 面向服务的体系架构
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁&am…...

TypeScript 装饰器类型详解
TypeScript 装饰器类型详解 一、类装饰器 // 参数:类的构造函数 function ClassDecorator(constructor: Function) {Object.defineProperty(constructor.prototype, timestamp, {value: Date.now()}); }ClassDecorator class DataService {// 装饰后自动添加times…...

Nyquist内置函数-杂项函数
1 Nyquist内置函数-杂项函数 1.1 杂项函数 这些函数对于日常使用来说都是安全且推荐的。 1.1.1 to-mono(sound) [SAL] (to-mono sound) [LISP] 如果 sound 是多声道声音,返回其所有声道的总和;如果 sound 本身就是单声道声音,则直接返回&…...
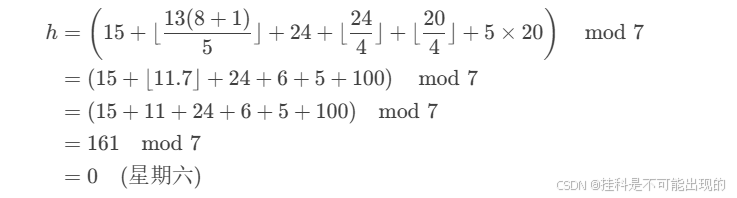
基姆拉尔森计算公式
基姆拉尔森计算公式(Zellers Congruence 的变体)是一种快速根据公历日期计算星期几的数学公式。其核心思想是通过对年月日的数值进行特定变换和取模运算,直接得到星期几的结果。 公式定义 对于日期 年-月-日,公式如下:…...

5 分钟用满血 DeepSeek R1 搭建个人 AI 知识库(含本地部署)
最近很多朋友都在问:怎么本地部署 DeepSeek 搭建个人知识库。 老实说,如果你不是为了研究技术,或者确实需要保护涉密数据,我真不建议去折腾本地部署。 为什么呢? 目前 Ollama 从 1.5B 到 70B 都只是把 R1 的推理能力…...
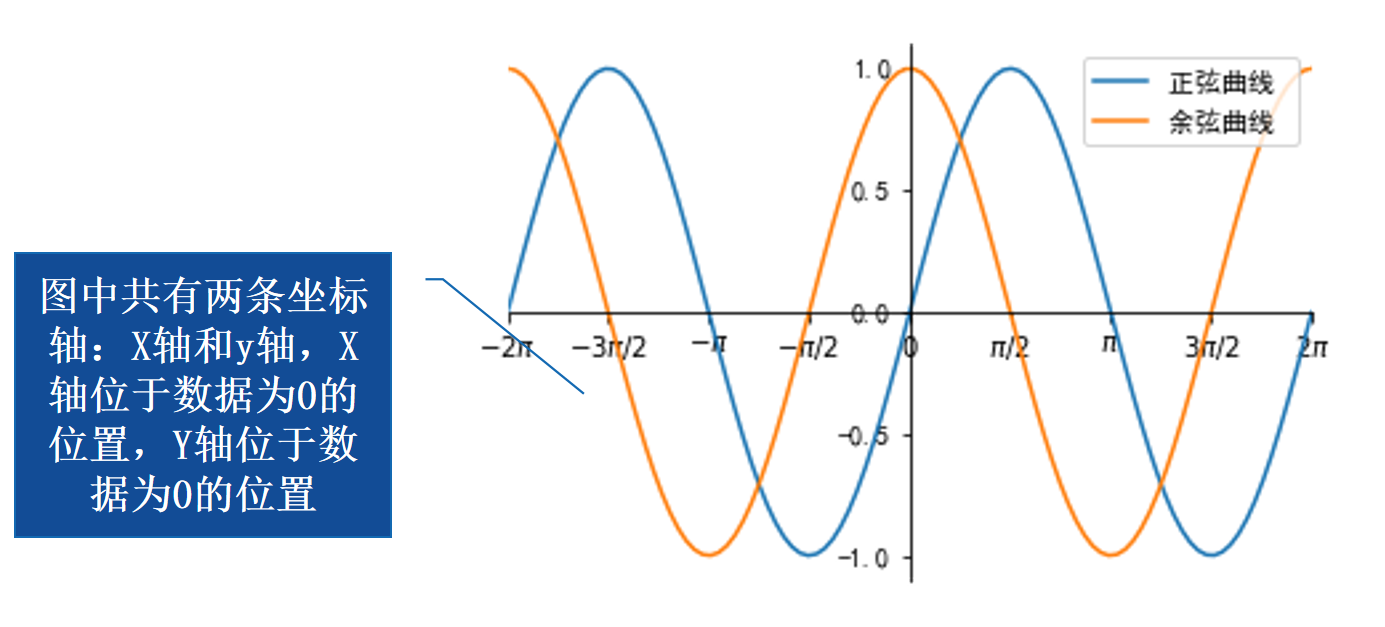
Python数据可视化-第6章-坐标轴的定制
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第6章 坐标轴的定制 本章主要介绍了坐标轴的定制,包括向任意位置添加坐标轴、定制刻度、隐藏轴脊和移动轴脊。 参考 第…...

18认识Qt坐标系
平面直角坐标系(笛卡尔坐标系) 数学上的坐标系 右手坐标系 计算机中的坐标系 左手坐标系 坐标系的原点(0,0) 就是屏幕的左上角 /窗口的左上角 给 Qt 的某个控件,设置位置,就需要指定坐标.对于这个控件来说, 坐标系原点就是相对于父窗口/控件的. QPushButton 的父元素/父控件/父…...

动态循环表单+动态判断表单类型+动态判断表单是否必填方法
页面效果: 接口请求到的数据格式: list: [{demandType: "设备辅助功能要求",demandSettingList: [{id: "1907384788664963074",name: "测试表单",fieldType: 0,contentValue: "",vaildStatus: 0, // 0 非必填&a…...

keep-alive缓存
#keep-alive缓存动态路由的使用指南# 代码如下图 : <router-view v-slot"{ Component }"> <keep-alive :include"[Hot, Notifications, User, Setting, Test]"> <component :is"Component" …...
25.4.3学习总结【Java】
又是一道错题: 1. 班级活动https://www.lanqiao.cn/problems/17153/learning/?page1&first_category_id1&sortdifficulty&asc1&second_category_id3 问题描述 小明的老师准备组织一次班级活动。班上一共有 n 名 (n 为偶数) 同学,老师…...
:语句)
Python入门(3):语句
目录 1 基本语句 1.1 表达式语句 1.2 赋值语句 2 控制流语句 2.1 条件语句 2.2 循环语句 while循环: for循环: 2.3 流程控制语句 1. break语句:退出整个循环体 2. continue语句:只跳过本次循环,还会进…...

运维之 Centos7 防火墙(CentOS 7 Firewall for Operations and Maintenance)
运维之 Centos7 防火墙 1.介绍 Linux CentOS 7 防火墙/端口设置: 基础概念: 防火墙是一种网络安全设备,用于监控和控制网络流量,以保护计算机系统免受未经授权的访问和恶意攻击。Linux CentOS 7操作系统自带了一个名为iptables的…...

开发一个小程序需要多久时间?小程序软件开发周期
开发一个小程序所需时间受多种因素影响,以下为你详细列举: 一、需求复杂度。若只是简单展示类小程序,如企业宣传、产品介绍,功能单一,大概 1 - 2 周可完成。若涉及复杂交互,像电商小程序,涵盖商…...

【数据结构篇】算法征途:穿越时间复杂度与空间复杂度的迷雾森林
文章目录 【数据结构篇】算法征途:穿越时间复杂度与空间复杂度的迷雾森林 一、 什么是算法1. 算法的定义1.1 算法的五个特征1.2 好算法的特质 2. 时间复杂度3. 空间复杂度 【数据结构篇】算法征途:穿越时间复杂度与空间复杂度的迷雾森林 💬欢…...

新增帧能耗指标|UWA Gears V1.0.9
UWA Gears 是UWA最新发布的无SDK性能分析工具。针对移动平台,提供了实时监测和截帧分析功能,帮助您精准定位性能热点,提升应用的整体表现。 本次版本更新主要新增帧能耗指标,帮助大家对每一帧的能耗进行精准监控,快速…...

蓝桥杯嵌入式16届———LCD模块
LCD有官方给我们提供的库,我们使用其非常简单,唯一要注意的就是LCD和LED的引脚冲突。 引脚状况 STM32CubeMX 端口配置 使能 比赛给的选手 资源数据包中有以下三个文件,(除去led相关的),将他们复制到自己…...

Ubuntu服务器挂载之前的数据硬盘
这里假设在挂载硬盘之前,您的硬盘从之前的服务器上正确卸载下来。请注意,以下任何操作不当都有可能导致硬盘数据丢失或损坏,如果您的数据非常重要,请及时备份。 1. 确认硬盘分区信息 使用以下命令查看磁盘信息,找到要…...
CMake在Windows环境下Visual Studio Code的使用
1,安装下载 地址:Visual Studio Code - Code Editing. Redefined 双击安装 选择安装路径 可勾选微软的AI工具 2,环境介绍 2.1 ,界面介绍 2.2中文包的安装 下载中文简体 汉化后的界面 2.3 配置C/C环境 VSCode安装好之后…...

注意力机制在大语言模型中的原理与实现总结
注意力机制在大语言模型中的原理与实现总结 1. 章节介绍 在大语言模型的学习中,理解注意力机制至关重要。本章节旨在深入剖析注意力机制的原理及其在大语言模型中的应用,为构建和优化大语言模型提供理论与实践基础。通过回顾神经网络基础及传统架构的局…...